Think Outside the Policy: In-Context Steered Policy Optimization
Abstract: Existing Reinforcement Learning from Verifiable Rewards (RLVR) methods, such as Group Relative Policy Optimization (GRPO), have achieved remarkable progress in improving the reasoning capabilities of Large Reasoning Models (LRMs). However, they exhibit limited exploration due to reliance on on-policy rollouts where confined to the current policy's distribution, resulting in narrow trajectory diversity. Recent approaches attempt to expand policy coverage by incorporating trajectories generated from stronger expert models, yet this reliance increases computational cost and such advaned models are often inaccessible. To address these issues, we propose In-Context Steered Policy Optimization (ICPO), a unified framework that leverages the inherent in-context learning capability of LRMs to provide expert guidance using existing datasets. ICPO introduces Mixed-Policy GRPO with Implicit Expert Forcing, which expands exploration beyond the current policy distribution without requiring advanced LRM trajectories. To further stabilize optimization, ICPO integrates Expert Region Reject Sampling to filter unreliable off-policy trajectories and Annealed Expert-Bonus Reward Shaping to balance early expert guidance with later autonomous improvement. Results demonstrate that ICPO consistently enhances reinforcement learning performance and training stability on mathematical reasoning benchmarks, revealing a scalable and effective RLVR paradigm for LRMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to help AI models think better, especially on math problems. The method is called ICPO (In-Context Steered Policy Optimization). It teaches a model to explore smarter by using short examples inside the prompt (like “showing your work” examples) rather than depending on a bigger, more powerful model to guide it. The goal is to make training cheaper, more stable, and more effective.
What questions are the researchers trying to answer?
- How can we get AI models to explore more diverse solutions, instead of repeating the same types of answers they already prefer?
- Can we use the model’s built-in ability to learn from examples in the prompt (in-context learning) to give it helpful “expert” hints without calling a bigger model?
- How do we filter out bad hints so training doesn’t get confused?
- Can we balance early guidance (strong hints) with later independence (letting the model figure things out on its own)?
How did they do it? (Methods explained simply)
Think of training an AI like trying to solve a maze:
- The “policy” is the model’s usual way of picking paths.
- “Exploration” means trying new paths to find better solutions.
- “Rewards” are points the model earns when it reaches the correct exit.
Here’s what ICPO adds to this process:
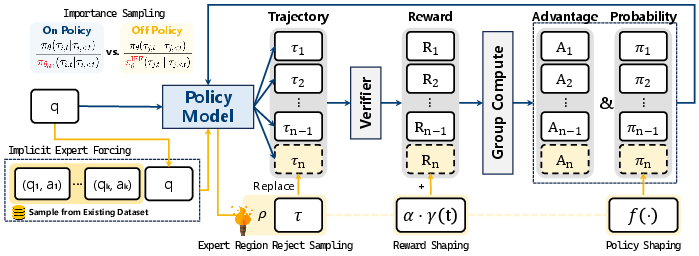
- Implicit Expert Forcing (IEF): Instead of asking a bigger model for help, they put a few solved examples directly into the prompt. This is like writing a quick demo on the board before you start your homework. The model then tries to solve the new problem using these hints. This creates “expert-guided” attempts without changing the model’s internal weights at that moment.
- Mixed-Policy GRPO: GRPO is a training rule that helps the model learn from multiple attempts per question. “Mixed-policy” means mixing the model’s normal attempts with the expert-guided attempts from IEF in the same training batch. So the model learns both from what it usually does and from the hint-steered versions.
- Expert Region Reject Sampling (ERRS): Not every hint-led attempt is good. ERRS acts like a filter: it only keeps the expert-guided attempts that actually lead to correct or reliable answers. This prevents bad examples from confusing the model.
- Annealed Expert-Bonus Reward Shaping (RS): Early on, they give extra points to good expert-guided answers to encourage the model to follow strong guidance. Over time, they slowly reduce this bonus so the model becomes more independent. Think of training wheels that you gradually take off.
- Verifiable Rewards (RLVR): The model’s math answers are checked automatically by a program. If the final boxed answer matches the correct solution, it gets a reward. This makes training accurate and fair because the reward doesn’t come from human judgment—it’s programmatically checked.
What did they find, and why does it matter?
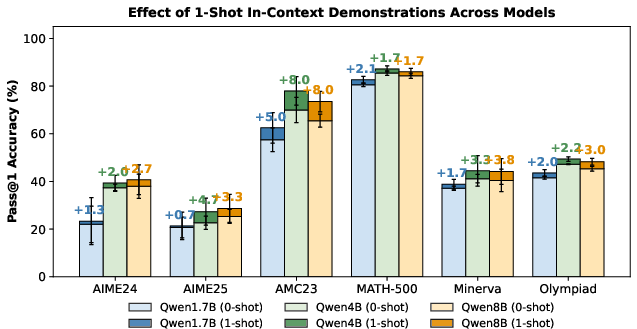
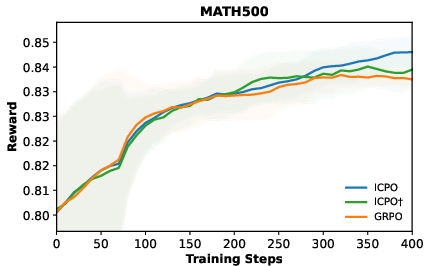
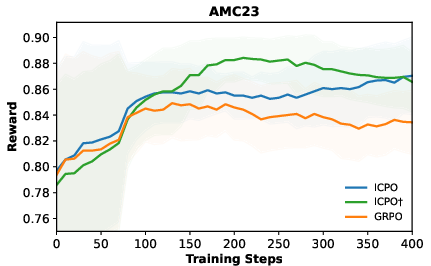
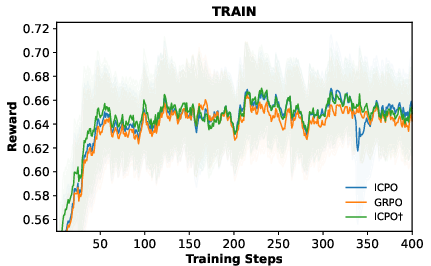
- Better performance on math reasoning: On several math benchmarks (like MATH-500, AIME, AMC), their method improved scores compared to the standard approach. In some cases, the average improvement was around 4 points.
- No need for a bigger “teacher” model: Many other methods depend on strong, expensive models to generate expert examples. ICPO uses short examples from existing datasets instead, making training more accessible and less costly.
- More diverse, stronger exploration: The model tried more varied reasoning paths and reached correct answers more often, especially on harder problems. The in-context hints led to targeted exploration—not just random guessing.
- Stable training: Filtering bad hint-led attempts and slowly reducing the expert bonus helped the model learn reliably without getting confused or stuck.
- Generalization: The improvements mostly carried over to other test sets beyond the training distribution, especially with larger models. This suggests the method helps the model think better in general, not just on the exact problems it saw during training.
Why is this important?
This work shows a practical, scalable way to make reasoning-focused AI models smarter:
- It reduces dependence on expensive external models.
- It leverages the model’s own ability to learn from context, which is built into modern LLMs.
- It improves both exploration (trying new ideas) and stability (learning reliably).
- It can help build better math and reasoning assistants that learn efficiently from existing resources.
Overall, ICPO is a step toward training AI models that can think more deeply and flexibly using simple, accessible guidance, making advanced reasoning more achievable without heavy compute or exclusive tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
- Domain scope: ICPO is only evaluated on mathematical reasoning with verifiable rewards; it is unclear how well it transfers to other domains (e.g., code, logic, science QA, multi-step tool use) or modalities.
- Reliance on verifiers: The approach assumes reliable, binary verifiable rewards; extensions to non-verifiable, noisy, or preference-based rewards (RLHF) and to partial-credit verifiers remain unexplored.
- Demonstration source sensitivity: Few-shot demonstrations are sampled randomly from MATH; the impact of demo quality, difficulty, topical relevance, and retrieval strategies (e.g., similarity search) on ICPO performance is not studied.
- Number of shots k: The paper does not report or ablate the choice of the few-shot count k, nor quantify the compute/throughput trade-offs and performance sensitivity to k.
- Context-length overhead: Adding demonstrations increases prompt length and memory footprint; there is no analysis of latency, throughput, truncation rates (given 8192-token limits), or cost relative to GRPO/LUFFY.
- Compute efficiency: While ICPO avoids external expert rollouts, the net compute (8 rollouts per prompt, IEF log-prob evaluations for importance weights) is not benchmarked against baselines; wall-clock and token-level efficiency are missing.
- Off-policy correction validity: The “expert-conditioned importance weight” uses πθ and πθIEF defined on different contexts/histories; the statistical correctness, bias, and variance properties of the mixed-policy GRPO objective are not theoretically characterized.
- Convergence guarantees: No formal analysis is provided for stability or convergence under mixed on-/off-policy GRPO with clipping, KL regularization, shaping f(x), and ERRS filtering.
- Advantage normalization across mixed distributions: Standardizing returns jointly over on- and off-policy groups may bias advantages; the impact of this design versus per-branch normalization is not analyzed.
- ERRS thresholding: ERRS accepts only high-reward (δ=1.0) expert-conditioned trajectories; sensitivity to δ, acceptance rates, and the exploration-diversity trade-off induced by aggressive filtering are not evaluated.
- Reward shaping schedule: The annealed expert bonus uses a fixed linear schedule and α=1; alternatives (adaptive schedules, curriculum-based annealing, per-domain tuning) and hyperparameter sensitivities are not explored.
- Replacement policy design: Accepted IEF trajectories replace a random on-policy rollout; alternative integration strategies (e.g., weighting, adding extra samples, prioritized inclusion) and their effect on bias/variance are untested.
- Off-policy ratio: The fixed 1 off-policy to 7 on-policy rollout ratio is not ablated; optimal ratios for different model sizes, datasets, and training stages are unknown.
- KL-regularization interplay: The interaction between IEF-driven exploration and the KL penalty to a reference model (coefficient selection, adaptive KL control) remains underexplored.
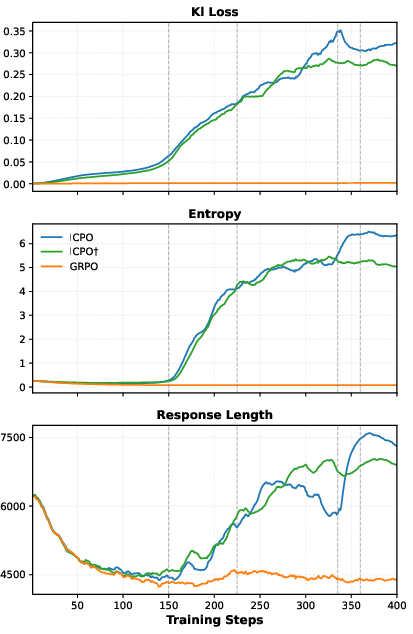
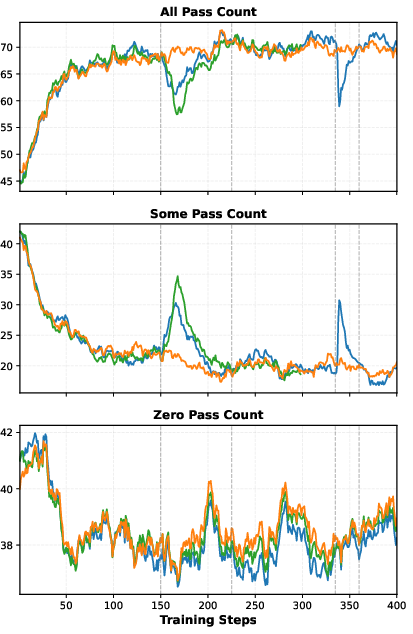
- Exploration metrics: Evidence for improved exploration is limited to entropy/KL and length; more direct measures (coverage, novelty, diversity vs. correctness trade-offs, trajectory clustering) and failure modes are not provided.
- Robustness to adversarial/poor demonstrations: The method assumes benign demos; effects of misleading, adversarially chosen, or out-of-domain demonstrations on stability and safety are not analyzed.
- Data contamination and leakage: Using MATH demos while evaluating on MATH-500 risks overlap or near-duplicate leakage; the paper does not report decontamination procedures or overlap statistics.
- Generalization breadth: OOD evaluation is limited (ARC, GPQA, MMLU) with mixed results for smaller models; broader OOD coverage (other math sets, reasoning datasets, multilingual settings) is absent.
- Scaling beyond 8B: Results are reported for 1.7B and 8B only; whether gains persist, saturate, or change qualitatively for larger models (e.g., 14B–70B) is unknown.
- Baseline coverage: Empirical comparisons omit several recent SFT+RL and hinting methods cited (e.g., SRFT, ReLIFT, BREAD, Prefix Sampling); stronger baselines and controlled conditions are needed for fair attribution.
- Seed variance and statistical significance: The paper does not report multiple runs, confidence intervals, or significance testing; training stability claims lack variance estimates across seeds.
- Sample efficiency: ICPO is trained for T=400 steps; learning curves, data efficiency comparisons, and early-stopping behavior relative to GRPO/LUFFY are not analyzed.
- Partial credit and intermediate supervision: ICPO uses binary correctness; leveraging verifier-derived intermediate signals (step-level checks, unit tests, symbolic constraints) to densify rewards is an open avenue.
- Applicability beyond math verifiers: Adapting ERRS and IEF to domains without deterministic verifiers (e.g., open-ended reasoning, dialogue, safety) remains open.
- Architecture dependence: Only Qwen3 models are evaluated; portability to other architectures (Llama/Mixtral/GPT-NeoX) is untested.
- Hyperparameter sensitivity: Core settings (ε clip, β KL, λ in f(x), temperature, group size N) are fixed; systematic sensitivity/robustness studies are missing.
- Theoretical link to task vectors: The paper cites task-vector theory to motivate IEF but does not empirically verify or quantify task-vector representations induced by demonstrations in this setting.
- Safety and misuse: There is no analysis of potential safety regressions (e.g., jailbreak susceptibility, hallucinations) induced by in-context steering or mixed-policy updates.
- Error analysis: The paper lacks qualitative failure case studies (problem types that do/don’t improve), making it hard to target data or algorithmic refinements.
- Practical demo selection: Real-world deployment would require a retriever/controller to select demos; learning or optimizing such a component within ICPO is left unexplored.
Practical Applications
Practical Applications of “Think Outside the Policy: In-Context Steered Policy Optimization (ICPO)”
Below are actionable applications that translate the paper’s methods—Implicit Expert Forcing (IEF), Mixed-Policy GRPO, Expert Region Reject Sampling (ERRS), and Annealed Expert-Bonus Reward Shaping—into real-world impact. Each item includes sectors, potential tools/workflows, and key dependencies or assumptions.
Immediate Applications
These can be adopted now with existing tooling, especially where verifiable rewards and example demonstrations already exist.
- Higher-accuracy math and STEM tutoring systems
- What: Train small-to-mid LLMs for step-by-step, competition-grade math reasoning using public solution banks as few-shot demonstrations, without relying on expensive expert models.
- Sectors: Education, EdTech, Test prep
- Tools/Workflows: Mixed-policy GRPO trainer; IEF sampler that injects few-shot demos from curated solution banks (e.g., MATH); ERRS gate using auto-graders (Math-Verify); annealed bonus scheduler to boost early guided learning.
- Dependencies/Assumptions: Availability of high-quality solved problems; robust verifiers for correctness; models with sufficient ICL capacity and context length; appropriate data licensing.
- Cost-efficient code generation and debugging with verifiable rewards
- What: Improve code reasoning by training on unit-test-verified rewards; leverage IEF with few-shot code snippets (patterns, idioms) from existing repos; use ERRS to accept only passing trajectories.
- Sectors: Software, DevTools, MLOps
- Tools/Workflows: RLVR-ICPO pipeline integrated with unit test harnesses (pytest/JUnit); demo bank of code exemplars; ERRS plug-in to filter off-policy samples; annealed bonus to transition from imitation to autonomous improvement.
- Dependencies/Assumptions: High-coverage unit tests; stable sandboxing; curated few-shot exemplars; CI/CD integration.
- Data analytics copilots that generate correct SQL/ETL with automatic verification
- What: Train assistants to produce SQL queries/data transforms verified against held-out expected outputs or invariants; use IEF to condition rollouts on relevant query exemplars.
- Sectors: Enterprise analytics, Business intelligence, Finance operations
- Tools/Workflows: Verifier adapters (result diffing, constraint checks); demo libraries of SQL patterns; ERRS to keep only verifiably-correct off-policy samples; GRPO mix for exploration.
- Dependencies/Assumptions: Gold outputs or constraint-based verifiers; secure data handling; sufficient ICL context.
- Troubleshooting and procedural assistants with scriptable success checks
- What: Train support bots to follow multi-step runbooks where success is verifiable (service health checks, log assertions, config comparisons); IEF conditions exploration on known successful playbooks.
- Sectors: IT Ops, Customer support, DevOps/SRE
- Tools/Workflows: Scripted verifiers (health endpoints, log patterns); runbook snippet bank as context; ERRS to accept only successful trajectories; reward annealing for stability.
- Dependencies/Assumptions: Programmatic success criteria; access to runbooks; controlled environments for safe execution.
- Resource-lean post-training for internal or domain-specific LLMs
- What: Organizations fine-tune their in-house models for reasoning using ICPO without calling stronger proprietary models; use existing domain datasets as demonstrations.
- Sectors: Cross-industry (legal ops, insurance, operations research), Academia/Research labs
- Tools/Workflows: ICPO trainer with mixed-policy GRPO; demonstration bank builder; verifier catalog (unit tests, constraints, solvers); logging dashboards for ERRS acceptance rates.
- Dependencies/Assumptions: Verifiable reward design per task; curated demo banks; compute for RL updates (but no external model sampling).
- Quality filtering and data curation via ERRS as a standalone module
- What: Use ERRS with verifiers to reject noisy, misleading trajectories in existing RL or SFT+RL pipelines, improving stability and convergence.
- Sectors: MLOps, Data engineering, Research
- Tools/Workflows: ERRS plug-in API; verifier registry; acceptance threshold tuning; training telemetry for acceptance ratios.
- Dependencies/Assumptions: Meaningful verifiable signals; compatible reward scales; careful threshold calibration.
- Benchmarking and reproducibility improvements for reasoning RL
- What: Standardize training setups that separate exploration (IEF) and reliability (ERRS + annealed RS), enabling smaller teams to replicate reasoning gains.
- Sectors: Academia, Open-source AI
- Tools/Workflows: Reference configs and scripts; prebuilt demo banks; verifier packs; ablation-friendly pipelines.
- Dependencies/Assumptions: Access to public datasets; model checkpoints; open verifiers.
Long-Term Applications
These require additional research, domain-specific verifiers, safety validation, or scaling.
- Robotics planning with simulation-verified rewards
- What: Train policy-LLMs for task planning using sim pass/fail as verifiable rewards; few-shot demos come from prior trajectories/logs; ERRS filters unstable off-policy sequences.
- Sectors: Robotics, Manufacturing, Logistics
- Tools/Workflows: Simulator verifiers (success metrics, collision-free constraints); demonstration libraries from teleop/human runs; sim-to-real curriculum with annealed guidance.
- Dependencies/Assumptions: High-fidelity simulators; verifiers correlating with real-world success; safety protocols; domain adaptation.
- Clinical decision support with guideline and rule-based verification
- What: Reasoning assistants trained to propose plans that pass guideline/contraindication checkers; IEF leverages curated clinical exemplars; ERRS ensures only guideline-conformant trajectories update the policy.
- Sectors: Healthcare
- Tools/Workflows: CDS rule engines as verifiers; EHR-compatible de-identification; human-in-the-loop review; governance for updates.
- Dependencies/Assumptions: High-precision clinical verifiers; robust safety and audit trails; regulatory approvals; bias assessments.
- Financial strategy and risk reasoning with backtesting verifiers
- What: Use verifiable backtests and risk constraints as rewards; IEF conditions on canonical strategies; ERRS filters overfit or non-robust rollouts; annealing reduces reliance on exemplars over time.
- Sectors: Finance, Quant research, FinOps
- Tools/Workflows: Backtesting engines; risk and compliance constraints as verifiers; scenario stress tests; data versioning and leakage controls.
- Dependencies/Assumptions: Non-stationary markets require robust verifiers; out-of-sample validation; strong governance.
- Compliance-aware document drafting and policy validation
- What: Train models to produce contracts, privacy notices, or policy drafts that pass rule checkers/linters (GDPR/PCI/HIPAA heuristics); use IEF with precedent exemplars; ERRS guards against non-compliant updates.
- Sectors: Legal/Compliance, Public policy, RegTech
- Tools/Workflows: Regulatory rule engines and checklists as verifiers; precedent libraries for IEF; explainability traces for audits; annealed bonuses for progressive autonomy.
- Dependencies/Assumptions: Accurate, up-to-date rule libraries; jurisdictional variation; human legal oversight.
- Scientific reasoning and automated theorem proving with mechanized verifiers
- What: Train models that propose proofs/derivations validated by proof assistants or numerical checkers; IEF uses exemplar proofs; ERRS ensures only validated reasoning updates the model.
- Sectors: Research, Formal methods, Engineering design
- Tools/Workflows: Proof assistant integration (e.g., Lean/Coq) or numeric validation suites; curated theorem/lemma exemplars; curriculum schedules.
- Dependencies/Assumptions: Reliable verifier integration; coverage of target domains; computational cost of verification.
- Energy and operations research assistants with constraint verifiers
- What: Optimize schedules/load forecasts subject to hard constraints; verifiers enforce feasibility; IEF uses canonical patterns (e.g., unit commitment examples).
- Sectors: Energy, Supply chain, Transportation
- Tools/Workflows: OR solvers as verifiers (MILP, CP-SAT); reference exemplars of feasible solutions; ERRS for feasibility-only acceptance; annealed schedules for autonomy.
- Dependencies/Assumptions: Faithful constraints and cost models; high-quality historical exemplars; scenario variability.
- Multimodal reasoning (vision-language-action) with verifiable tasks
- What: Extend ICPO to tasks where success is programmatically checked (e.g., visual QA with exact-answer sets, scene graph constraints, manipulation success).
- Sectors: Robotics, AR/VR, Assistive tech
- Tools/Workflows: Multimodal verifiers (e.g., success detectors, scene constraints); demo curation for IEF; cross-modal context packing strategies.
- Dependencies/Assumptions: Reliable multimodal verifiers; long-context handling; dataset alignment.
- Privacy-preserving or federated ICPO for on-device specialization
- What: Train models locally with user-specific demonstration banks and on-device verifiers (e.g., personal finance checks, calendar logic), reducing server-side dependence.
- Sectors: Mobile/Edge, Consumer apps
- Tools/Workflows: Lightweight ICPO loops; on-device verifiers; secure demo selection; differential privacy/FHE for verifier signals where needed.
- Dependencies/Assumptions: Efficient on-device RL; privacy guarantees; small-model ICL strength.
- Verifier and demonstration “marketplaces” powering reasoning RL ecosystems
- What: Standardized registries of verifiers and demo packs that plug into ICPO-compatible trainers, enabling rapid domain adaptation by third parties.
- Sectors: AI tooling, Platforms/Marketplaces
- Tools/Workflows: Verifier APIs, evaluation leaderboards, licensing and provenance tracking; auto-annealing recipes by domain.
- Dependencies/Assumptions: Community standards for reward schemas; trust and validation of verifiers; governance for updates.
Notes on feasibility and transferability across items:
- The central assumption is the existence of verifiable rewards (binary or shaped) and suitably curated demonstration banks for IEF. Domains with clear pass/fail criteria (math, code, SQL, simulation, formal verification) are immediately tractable; domains lacking precise verifiers (open-ended writing, subjective preferences) need further research or proxy verifiers.
- Models must possess sufficient in-context learning capacity and context windows to benefit from IEF; long-context efficiency matters.
- ERRS thresholding and annealed bonus schedules are key stability levers; miscalibration can reduce exploration or entrench bias.
- Even where OOD generalization is preserved in the paper’s results, domain drift risks persist; periodic re-verification and verifier health checks are recommended.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a short definition and a verbatim usage example.
- Advantage normalization: Standardizing trajectory returns within a group to compute advantages with reduced variance for policy updates. "the normalized advantage is computed by:"
- Annealed expert bonus: A time-decayed additional reward applied to expert-aligned trajectories to encourage early guidance without long-term over-reliance. "Annealed Expert-Bonus Reward Shaping to balance early expert guidance with later autonomous improvement."
- Clipping function (CLIP): A variance-reduction mechanism that limits the impact of large importance ratios in policy gradients. "is the clipping function for variance reduction."
- Entropy coefficient: A hyperparameter controlling the strength of entropy regularization that promotes exploration in RL. "the entropy coefficient is set to 0.0 to stabilize training."
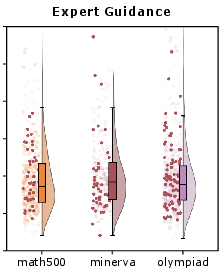
- Expert Region: The subset of states where expert conditioning yields superior guidance beyond the model’s native distribution. "We define an Expert Region as the subset of states where expert conditioning yields superior guidance"
- Expert Region Reject Sampling (ERRS): A filtering strategy that discards low-quality off-policy trajectories, retaining only expert-aligned ones for updates. "ICPO employs Expert Region Reject Sampling (ERRS), which filters out noisy or low-quality off-policy trajectories"
- Expert-conditioned rollouts: Trajectories generated by conditioning the model on expert demonstrations within the input context. "expert-conditioned rollouts are generated through few-shot ICL guidance"
- Explicit expert forcing: Directly constraining a policy to match an expert policy via imitation or KL-based regularization. "expert forcing explicitly constrains the policy to align with an expert policy "
- Few-shot ICL: In-context learning with a small number of demonstrations to steer model behavior without parameter updates. "Few-shot ICL provides a gradient-free way to inject expert priors through the input context."
- Group Relative Policy Optimization (GRPO): An on-policy RL algorithm for LLMs that computes token advantages group-wise without a critic. "Group Relative Policy Optimization (GRPO) is an efficient On-Policy optimization algorithm tailored for RL in LLMs"
- Hypothesis-class view of ICL: A perspective that models ICL as selecting functions from a hypothesis class via task vectors computed from demonstrations. "Following the hypothesis-class view of ICL"
- In-Context Learning (ICL): The ability of a model to adapt behavior using examples provided in the input context instead of parameter updates. "Few-shot ICL provides a gradient-free way to inject expert priors through the input context."
- In-Context Steered Policy Optimization (ICPO): A unified RLVR framework that leverages ICL for expert guidance without external models. "we propose In-Context Steered Policy Optimization (ICPO)"
- Implicit Expert Forcing (IEF): Using in-context demonstrations to implicitly steer generation toward expert-like regions without explicit optimization. "Mixed-Policy GRPO with Implicit Expert Forcing (IEF)"
- Importance ratio: The likelihood ratio between new and old policies used to weight updates in PPO/GRPO. "is the importance ratio"
- Importance sampling: A technique to correct distribution mismatch when using off-policy samples by weighting them with likelihood ratios. "incorporates SFT trajectories as off-policy samples using importance sampling."
- Input-conditioned off-policy method: An off-policy scheme where differing input contexts (with demonstrations) induce an alternative sampling distribution. "our mixed-policy GRPO with IEF operates as an input-conditioned off-policy method."
- KL divergence: A measure of difference between the learned policy and a reference policy, often used as a regularizer. "we observe that introducing IEF into mixed-policy GRPO drives the policy to deviate further from the reference distribution than vanilla GRPO, reflected by clear rises in entropy and KL divergence"
- KL regularization: Penalizing divergence from a reference model to stabilize training and constrain updates. "we retain the KL regularization term $\beta \cdot D_{\text{KL}[\pi_\theta || \pi_{\text{ref}]$"
- Large Reasoning Models (LRMs): LLMs optimized for multi-step reasoning tasks like mathematics. "Large Reasoning Models (LRMs) excel at solving complex mathematical problems"
- Local optima: Suboptimal solutions in parameter space where training can get stuck due to limited exploration. "resulting in limited trajectory diversity and might convergence to local optima"
- Mixed-Policy GRPO: Extending GRPO to optimize jointly over on-policy and expert-conditioned off-policy trajectories. "ICPO introduces Mixed-Policy GRPO with Implicit Expert Forcing"
- Off-policy rollouts: Trajectories sampled from a distribution different from the current policy, used to broaden exploration. "incorporating them indiscriminately as off-policy rollouts can mislead policy updates"
- On-policy sampling: Collecting trajectories from the current policy’s distribution to compute updates. "GRPO-based methods rely on on-policy sampling"
- Out-of-distribution (OOD) benchmarks: Evaluation datasets that differ from the training distribution to test generalization. "On out-of-distribution benchmarks, ICPO also outperforms vanilla GRPO by up to +2.37 points."
- Proximal Policy Optimization (PPO): A policy gradient method that uses clipped objectives to stabilize RL updates. "Analogous to PPO"
- Policy support: The set of trajectories that the current policy can generate with non-zero probability. "balances exploitation within the current policy support"
- Reference model: A fixed or slowly updated model used to regularize and monitor policy drift in training. "To prevent the learned policy from drifting too far from the reference model"
- Reject sampling: A procedure that accepts or discards samples based on a criterion (e.g., reward threshold) before training. "we define a reject sampling operator that selectively retains trajectories within the Expert Region."
- Reward shaping (RS): Modifying rewards to guide learning, often to accelerate or stabilize optimization. "ICPO further incorporates an annealed expert bonus into the Reward Shaping (RS) design"
- Shaping function: A transformation applied to importance ratios or rewards to bias learning toward desired behaviors. "The shaping function follows prior work and is defined as "
- Supervised fine-tuning (SFT): Training a model on labeled data to improve specific behaviors, often combined with RL for reasoning. "combining Supervised Fine-Tuning (SFT) with Reinforcement Learning (RL)"
- Task vector: A representation derived from demonstrations that modulates a transformer to perform a specific task during ICL. "maps demonstrations to a task vector "
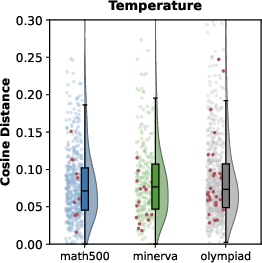
- Temperature-based sampling: Adjusting sampling temperature to control randomness and diversity in generated trajectories. "compared with temperature-based sampling"
- Trajectory diversity: The variability among sampled reasoning paths; crucial for effective exploration. "resulting in narrow trajectory diversity."
- Verifiable reward: A binary or structured reward computed by checking the correctness of outputs with a task-specific verifier. "The verifiable reward function evaluates the model output by extracting the final answer enclosed within '\boxed{}' and comparing it against the predefined ground-truth answer."
Collections
Sign up for free to add this paper to one or more collections.

