- The paper introduces RLVMR, a framework that provides dense, verifiable meta-reasoning rewards to improve exploration in long-horizon tasks.
- The framework combines supervised fine-tuning with a reinforcement learning phase that uses explicit meta-reasoning tags to balance outcome and process-level rewards.
- The study demonstrates that integrating meta-reasoning rewards reduces repetitive actions, enhances training efficiency, and significantly boosts generalization on unseen tasks.
Introduction and Motivation
The paper introduces RLVMR, a reinforcement learning (RL) framework that addresses the persistent issue of inefficient exploration in long-horizon LLM agents. Standard RL approaches, such as Group Relative Policy Optimization (GRPO), optimize for final task success but inadvertently reinforce suboptimal, repetitive, or illogical intermediate reasoning steps. This leads to brittle policies that generalize poorly to unseen tasks and environments. RLVMR proposes a paradigm shift: instead of rewarding only outcomes, it provides dense, verifiable rewards for explicit meta-reasoning behaviors—planning, exploration, reflection, and monitoring—operationalized via structured tags in the agent’s reasoning process.
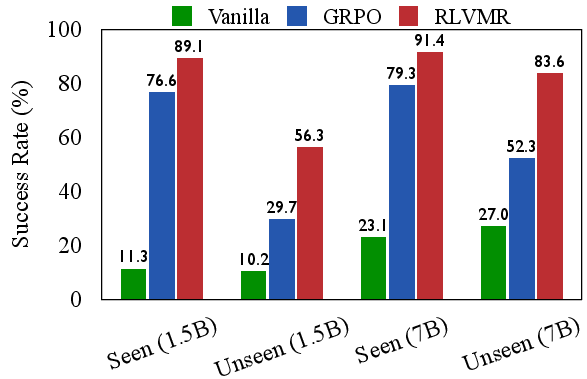
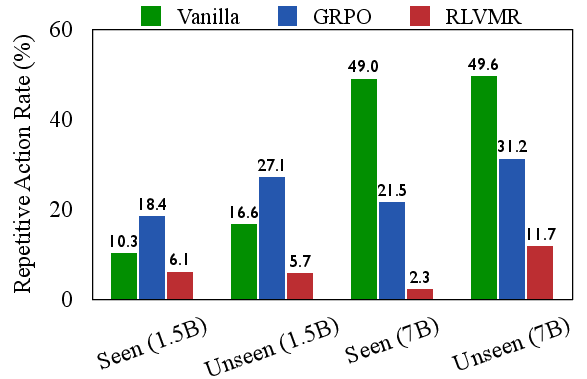
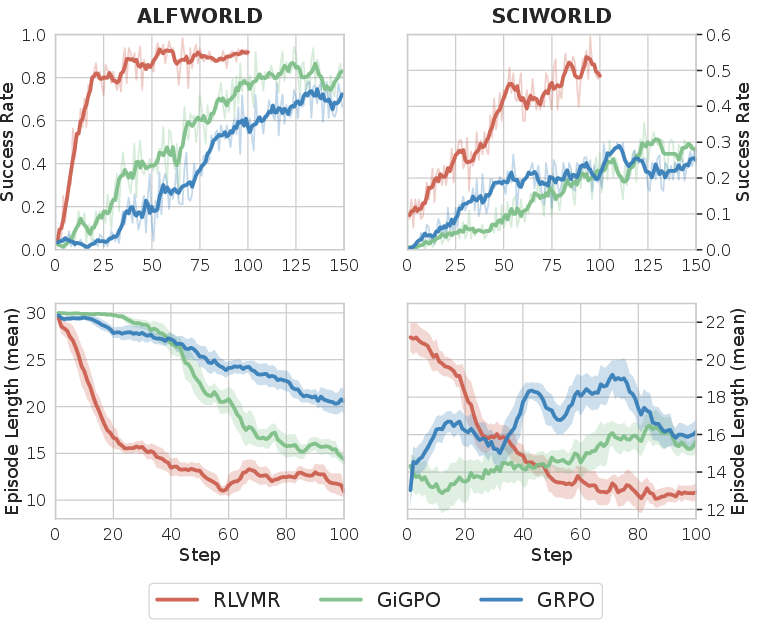
Figure 1: RL with outcome-only rewards (e.g., GRPO) improves over vanilla models but fosters inefficient exploration, while RLVMR directly mitigates this, improving both success rates and generalization.
Problem Analysis: Inefficient Exploration in LLM Agents
The authors empirically demonstrate that SFT-trained agents are efficient but brittle, excelling on seen tasks but failing to generalize. In contrast, RL with outcome-only rewards (GRPO) improves generalization but at the cost of severe inefficiency, as evidenced by high rates of repetitive and invalid actions. Scaling model size does not resolve these deficiencies; larger models can exploit flawed strategies more effectively, but do not inherently develop more coherent reasoning.
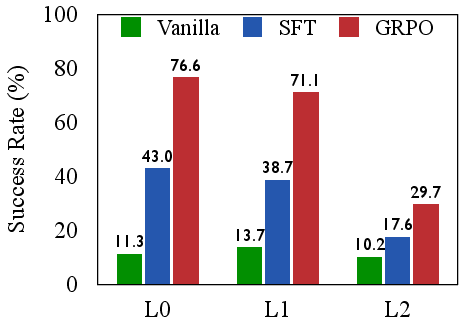
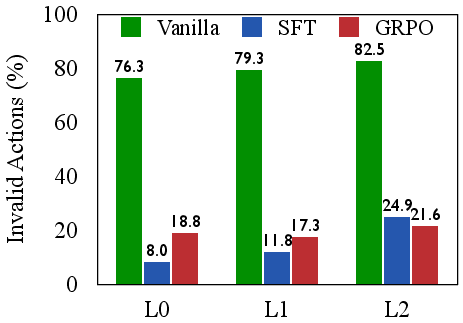
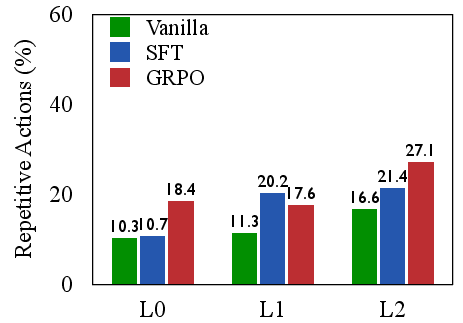
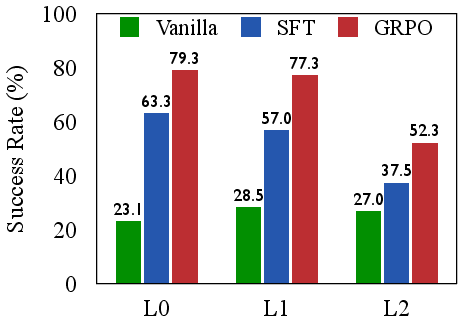
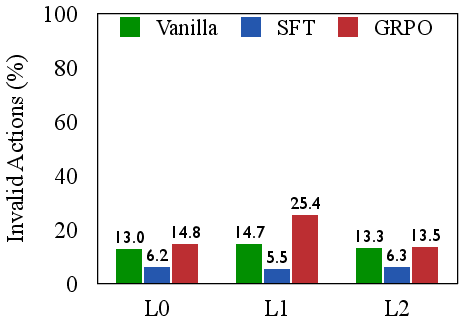
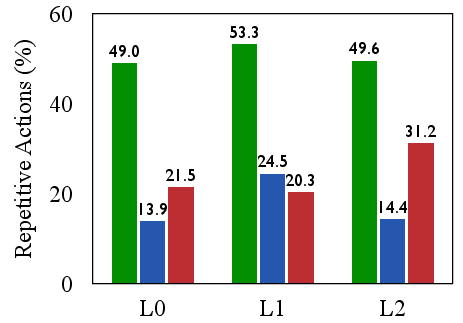
Figure 2: SFT excels on seen tasks but fails to generalize; GRPO generalizes better but is inefficient, highlighting a trade-off between brittle efficiency and inefficient generalization.
This analysis motivates the need for process-level supervision that directly rewards high-quality reasoning steps, not just successful outcomes.
RLVMR Framework: Methodology and Architecture
RLVMR augments the standard RL pipeline with explicit meta-reasoning supervision. The agent’s interaction is formalized as an MDP, with states, actions, and observations represented as natural language. The core innovation is the introduction of meta-reasoning tags—<planning>, <explore>, <reflection>, <monitor>—which structure the agent’s cognitive process. These tags are programmatically verifiable, enabling the assignment of dense, step-level rewards.
The training pipeline consists of two phases:
- Cold Start (SFT): The agent is fine-tuned on a small set of expert trajectories annotated with meta-reasoning tags, bootstrapping its ability to generate structured reasoning.
- Reinforcement Learning: The agent is trained with a composite reward signal: a sparse outcome reward for task success and dense meta-reasoning rewards for beneficial cognitive behaviors. The policy is optimized using a variant of GRPO (GRPO-MR), which computes step-level advantages by combining global trajectory performance with local, tag-specific reasoning quality.
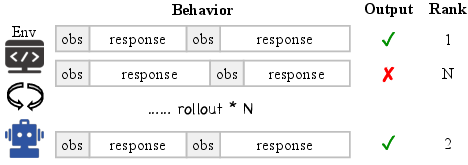
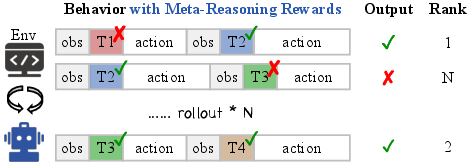
Figure 3: Standard RL (a) reinforces inefficient reasoning; RLVMR (b) provides dense, verifiable rewards for beneficial meta-reasoning behaviors, shaping a more robust reasoning process.
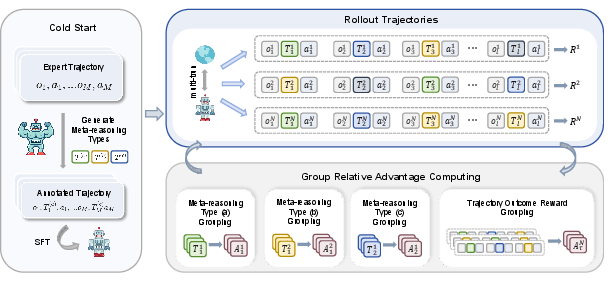
Figure 4: Schematic of RLVMR: cold start SFT phase followed by RL with rule-verifiable feedback for meta-reasoning behaviors.
Experimental Results and Analysis
RLVMR is evaluated on ALFWorld and ScienceWorld, two challenging long-horizon benchmarks. The results demonstrate:
- State-of-the-art performance: RLVMR achieves 91.4% success on seen ALFWorld tasks and 83.6% on the hardest unseen split (L2) with a 7B model, outperforming all baselines, including much larger models such as GPT-4o and DeepSeek-V3/R1.
- Superior generalization: RLVMR’s gains are most pronounced on unseen tasks, validating the hypothesis that process-level rewards foster robust, transferable reasoning.
- Efficiency and robustness: RLVMR drastically reduces invalid and repetitive actions compared to SFT and GRPO, directly mitigating inefficient exploration.
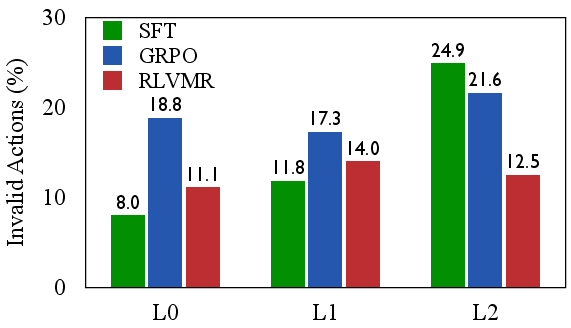
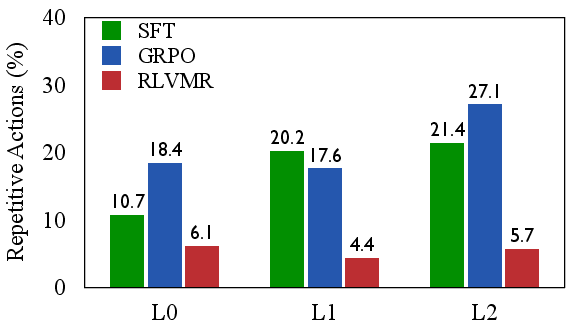
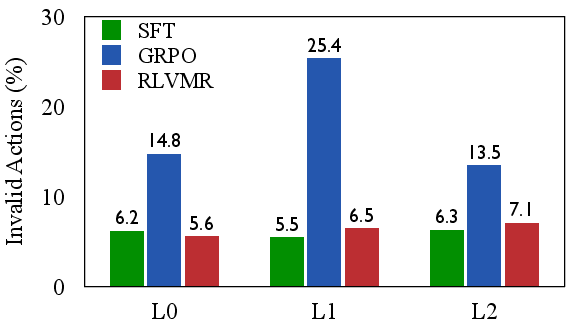
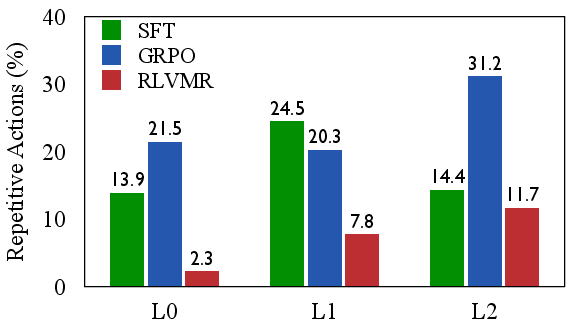
Figure 5: RLVMR consistently reduces invalid and repetitive actions across all generalization levels and model sizes, demonstrating effective mitigation of inefficient exploration.
Ablation studies confirm that both the meta-reasoning reward and the outcome reward are indispensable. Removing either leads to substantial performance degradation, underscoring the necessity of combining process-level and outcome-level supervision.
Implementation Considerations
- Tagging and Reward Assignment: Meta-reasoning tags are inserted into the agent’s output and verified via lightweight, programmatic rules. Rewards are assigned for planning steps that lead to success, exploration steps that discover new states, and reflection steps that correct prior mistakes. A format penalty is applied for outputs that do not conform to the expected tag structure.
- Policy Optimization: The GRPO-MR algorithm computes advantages at both the trajectory and tag-group levels, balancing global outcome and local reasoning quality via a tunable hyperparameter α.
- Data Efficiency: The cold start phase requires only 200 annotated trajectories, making the approach practical for real-world deployment.
- Scalability: RLVMR is model-agnostic and can be applied to both small and large LLMs. The framework is compatible with standard RL infrastructure and does not require additional critic models.
Theoretical and Practical Implications
RLVMR demonstrates that dense, verifiable process-level rewards can substantially improve the robustness, efficiency, and generalization of LLM agents in long-horizon tasks. The explicit operationalization of meta-reasoning aligns with cognitive science principles and provides a pathway for more interpretable and controllable agent behavior. The results challenge the prevailing assumption that outcome-only RL is sufficient for developing generalizable agents and highlight the limitations of scaling alone.
The framework’s modularity and reliance on lightweight, programmatic supervision make it amenable to extension into multi-modal domains, hierarchical planning, and real-world applications such as robotics and software engineering. The explicit separation of reasoning and acting also facilitates downstream analysis and debugging of agent behavior.
Future Directions
Potential avenues for further research include:
- Extending RLVMR to multi-modal and embodied environments.
- Developing adaptive or learned reward mechanisms for meta-reasoning behaviors.
- Integrating RLVMR with hierarchical or memory-augmented architectures for even longer-horizon reasoning.
- Applying RLVMR to domains requiring high reliability and interpretability, such as scientific discovery or autonomous systems.
Conclusion
RLVMR establishes a new paradigm for training robust, generalizable LLM agents by integrating verifiable meta-reasoning rewards into the RL loop. The framework achieves strong empirical results, directly addresses the problem of inefficient exploration, and provides a scalable, interpretable approach to process-level supervision. This work has significant implications for the design of future autonomous agents, emphasizing the importance of reasoning quality over mere outcome optimization.