- The paper introduces a novel supervision-free RL framework integrating SSL-inspired puzzles with dynamic curriculum weighting to enhance visual reasoning.
- It employs graded rewards and RAC monitoring to ensure alignment between the model’s stepwise rationale and its final answers.
- Empirical results demonstrate robust performance improvements on diverse visual benchmarks alongside effective benchmark data auditing.
Puzzle Curriculum GRPO: Supervision-Free Reinforcement Learning for Visual Reasoning
Introduction and Motivation
Recent developments in Vision LLMs (VLMs) have centered on reinforcement learning post-training, particularly via Group-Relative Policy Optimization (GRPO) and its variants, which induce chain-of-thought (CoT) reasoning. However, GRPO training faces three convergent limitations: (1) dependence on costly/noisy hand-crafted annotations or external verifiers, (2) sparse or flat reward signals with weak difficulty discrimination, and (3) logical inconsistency between the model's reasoning trace and its predicted answer. The "Puzzle Curriculum GRPO" (PC-GRPO) framework directly addresses these issues by introducing a supervision-free RL with Verifiable Rewards (RLVR) pipeline for vision-centric reasoning tasks that eschews human labels and external judges.
Methodology
PC-GRPO comprises three tightly integrated components that tackle data verification, reward sparsity, and reasoning faithfulness:
- Self-Supervised Puzzle Environments: Training rewards are programmatically generated using three SSL-inspired puzzles: PatchFit (masked patch identification), Rotation (fixed angle prediction), and Jigsaw (grid permutation reconstruction). PatchFit and Rotation provide binary rewards; Jigsaw introduces graded partial rewards proportional to correct tile placements, directly mitigating reward sparsity seen in prior RLVR paradigms.
- Difficulty-Aware Curriculum: Reward weights are dynamically modulated to prioritize samples exhibiting medium difficulty. For binary tasks, instance difficulty is estimated via mean group success rates; for combinatorial Jigsaw puzzles, a permutation-based diversity metric quantifies difficulty. Curriculum weighting ensures that gradient updates preferentially target groups most informative for optimization, counteracting vanishing group-relative advantages.
- Reasoning–Answer Consistency (RAC) Monitoring: A novel metric, RAC, tracks the alignment between the model's stepwise rationale and its predicted answer during training. RAC dynamics, measured via an open-source VLM judge, reveal an early-stage rise followed by late-stage decline under vanilla GRPO; PC-GRPO's curriculum and consistency-aware reward schemes delay and dampen this decline. RAC correlates with downstream accuracy, though optimal checkpoints rarely coincide with final training iterations.
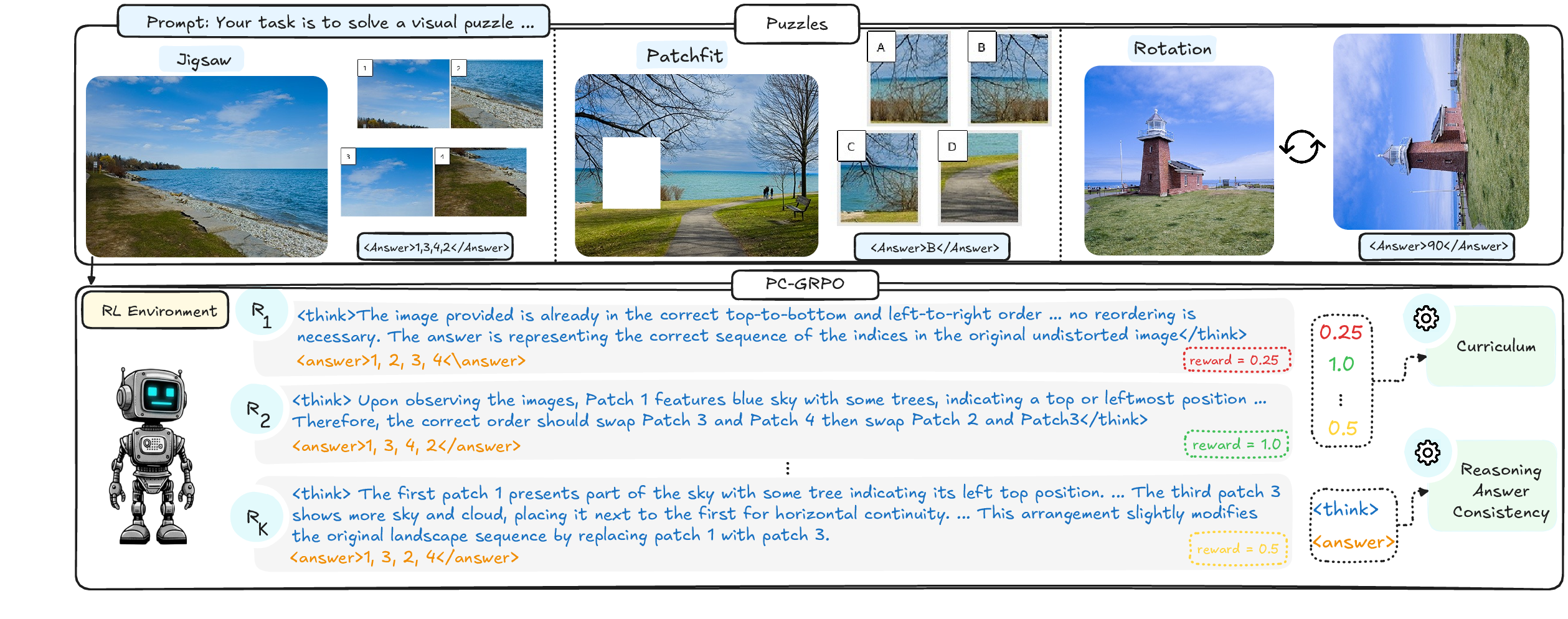
Figure 1: Overview of the PC-GRPO post-training framework, highlighting curriculum-weighted puzzle sampling, iterative token-level GRPO optimization, and RAC evaluation.
Empirical implementation leverages Qwen-VL family backbones, with no additional image preprocessing, to isolate the contributions of RLVR and curriculum selection.
Empirical Analysis
Benchmark Results
PC-GRPO demonstrates strong performance across diverse visual reasoning benchmarks, outperforming annotation-free and gamified-task RL baselines, and remaining competitive with GRPO-CARE approaches that utilize annotated data. Its effectiveness persists across tasks with high perceptual complexity and in the absence of human supervision.
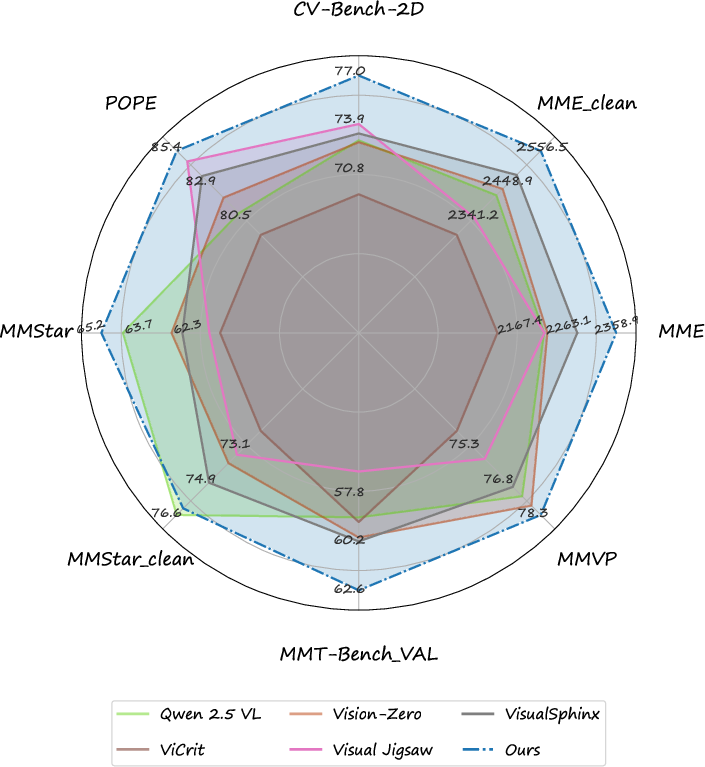
Figure 2: Comparative performance of PC-GRPO variants against state-of-the-art baselines on vision-centric reasoning benchmarks; the curriculum and consistency measures yield stable gains and reveal significant annotation noise within popular datasets.
Reasoning Dynamics
Detailed rollouts reveal characteristic VLM reasoning failures under traditional RLVR, such as shortcutting minimal reasoning, overthinking irrelevant details, or answer–trace mismatch. PC-GRPO consistently produces more faithful and visually grounded explanations, substantiated by elevated RAC scores.
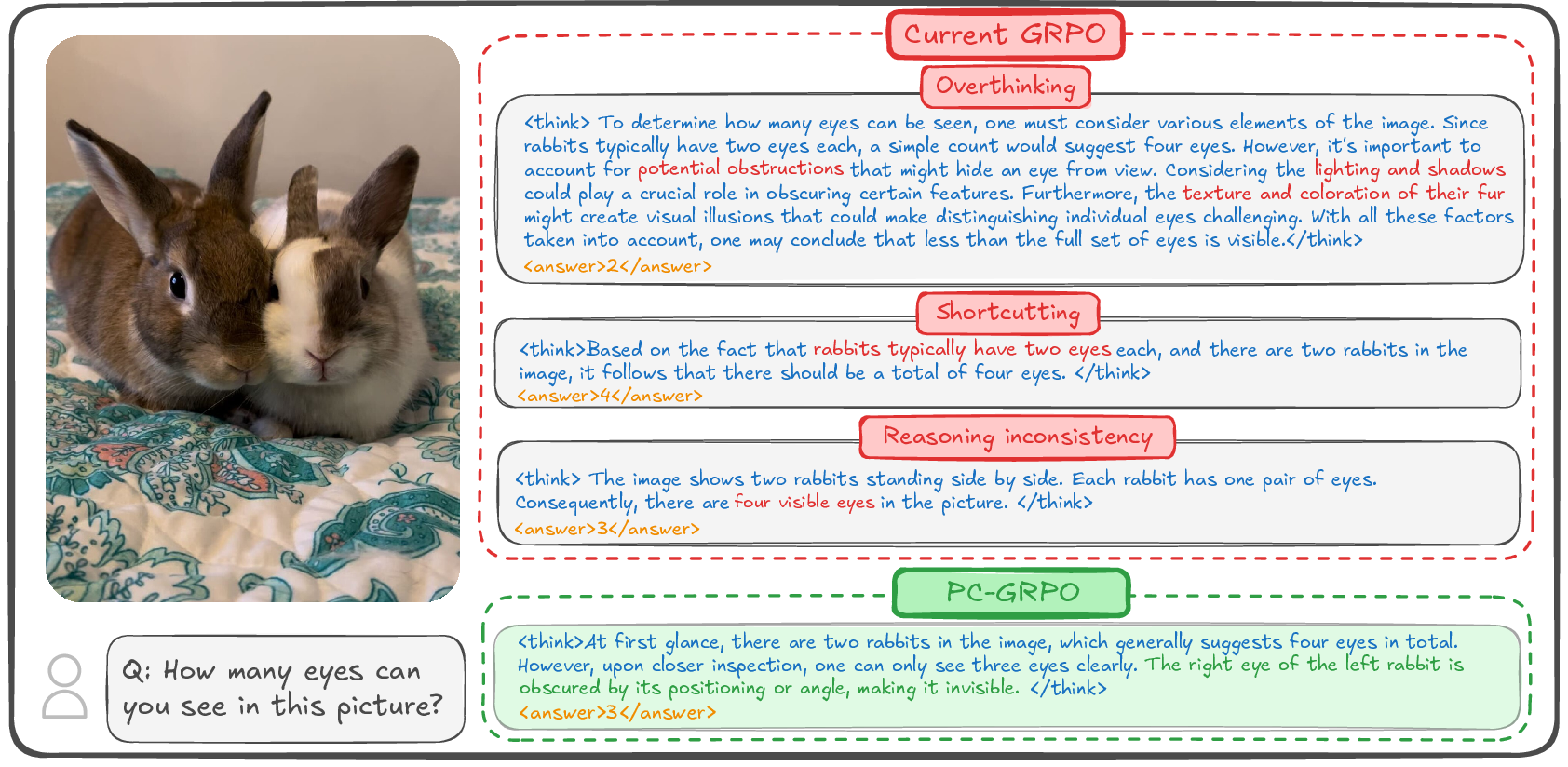
Figure 3: PC-GRPO's reasoning outputs compared against standard GRPO-tuned models on basic visual puzzles; PC-GRPO aligns rationale and answer, whereas baselines exhibit incoherent or statistically biased responses.
Puzzle Transferability
Generalization studies indicate that puzzle-specific training boosts in-domain performance but exhibits poor transfer to other puzzle types, underscoring the necessity of mixed-puzzle curricula for robust cross-task reasoning induction.
Training Metrics
Quantitative monitoring of reward variance, trajectory length, and RAC during training reveals direct links between curriculum weighting, consistency enforcement, and downstream improvements.
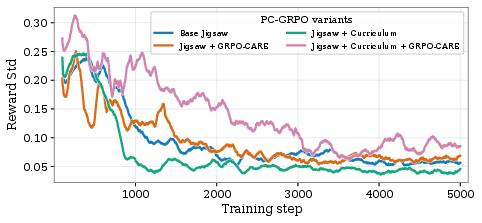
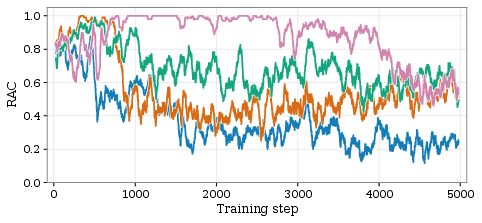
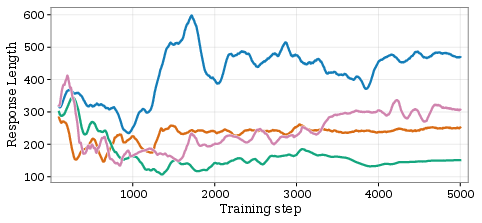
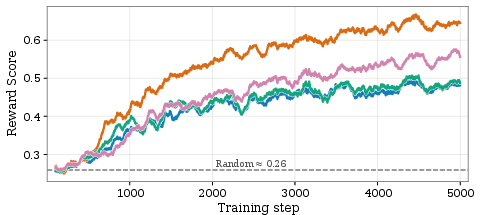
Figure 4: Training curve diagnostics for PC-GRPO, illustrating variance in rewards, consistency rates, response lengths, and partial credit distributions throughout post-training epochs.
Benchmark Auditing and Data Quality
Interpretability gain from PC-GRPO's CoT rationale enables systematic auditing of well-established vision benchmarks. User studies and proxy expert VLM committees reveal that 10–20% of benchmark samples contain label errors or underspecified prompts, posing substantial obstacles for reliable evaluation and progress.

Figure 5: Representative annotation noise from three popular vision datasets; examples display incorrect labels, ambiguous task descriptions, and context insufficiency.
PC-GRPO's data cleaning protocol uses expert committee agreement to flag and remove noisy samples, yielding cleaner benchmark subsets and improved model evaluation scores.
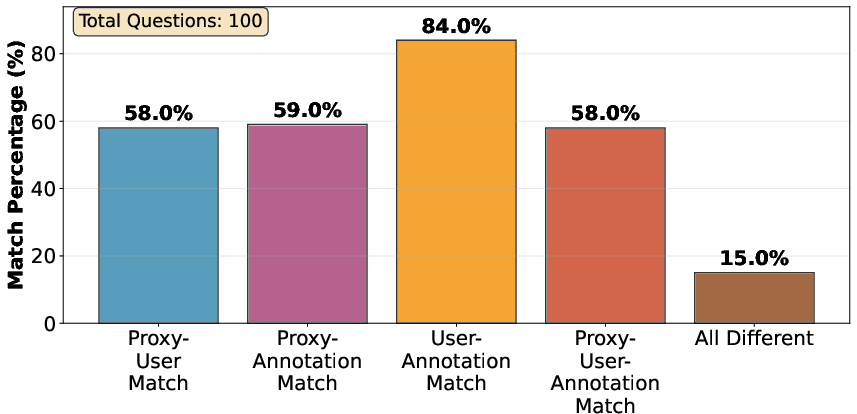
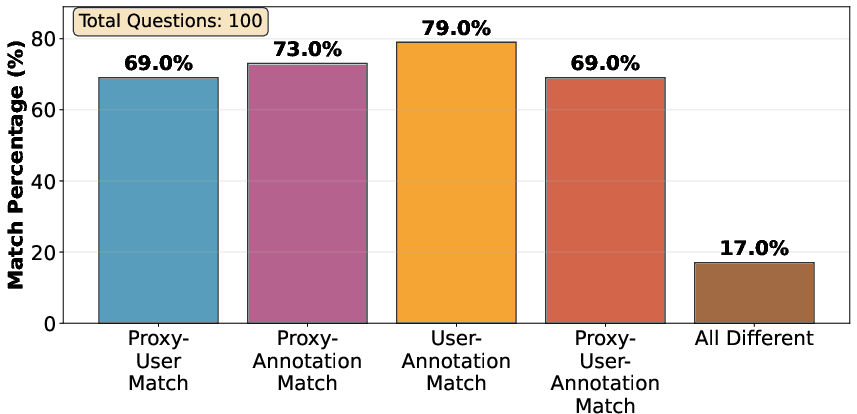
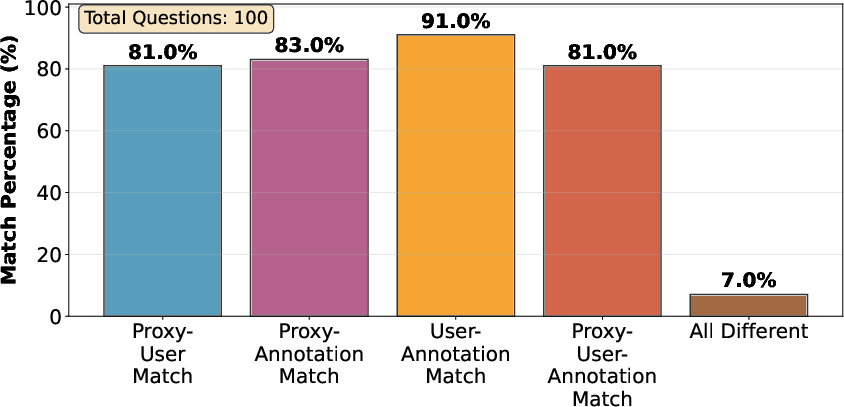
Figure 6: Quantitative validation of the human judgment proxy for benchmark cleanup, with proxy–user agreement rates substantially exceeding those of raw annotation labels.
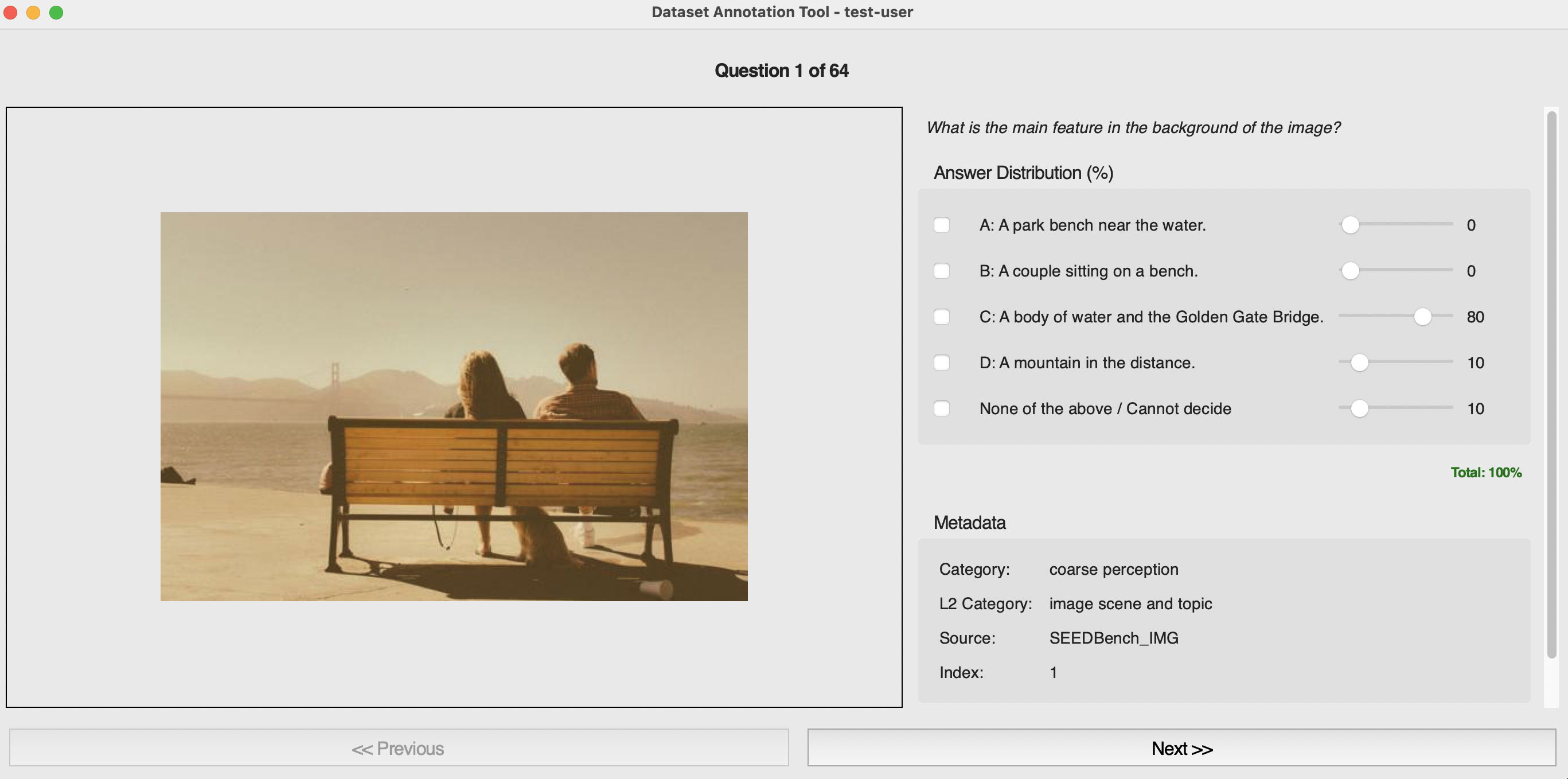
Figure 7: Auditing user study interface, where participants allocate answer probabilities to gauge human ambiguity and benchmark soundness.
Implications and Future Directions
PC-GRPO provides a scalable, interpretable framework for RL post-training in multimodal reasoning without human annotations or external teacher models. The graded-puzzle curriculum and RAC monitoring demonstrate effective alleviation of reward sparsity, difficulty-blindness, and reasoning faithfulness issues endemic to VLM RL optimization. The data auditing procedures supply the broader community with practical tools and cleaned benchmarks, contributing to higher-fidelity multimodal validation pipelines.
From a theoretical perspective, the graded signal design and curriculum weighting strategies in PC-GRPO may generalize to other RLVR instantiations, while the observed transfer limitations of puzzle-centric skills suggest further lines of work in meta-curriculum induction and compositional reasoning augmentation. The protocol's dependence on RAC for checkpoint selection highlights open questions in diagnostic-driven model tuning and interpretability metrics.
Conclusion
Puzzle Curriculum GRPO presents a unified response to persistent challenges in RL-driven visual reasoning: supervision-free reward construction, dynamic curriculum for difficulty calibration, and chain-of-thought–answer consistency maximization. These advances yield robust improvements in vision-centric reasoning, scalable training stability, and more reliable benchmark evaluation via integrated auditing. The approach sets a precedent for annotation-free, interpretable reinforcement learning in large-scale VLMs and offers methodological tools applicable to both research and practical deployment in multimodal AI.