CDE: Curiosity-Driven Exploration for Efficient Reinforcement Learning in Large Language Models
Published 11 Sep 2025 in cs.CL, cs.AI, and cs.LG | (2509.09675v1)
Abstract: Reinforcement Learning with Verifiable Rewards (RLVR) is a powerful paradigm for enhancing the reasoning ability of LLMs. Yet current RLVR methods often explore poorly, leading to premature convergence and entropy collapse. To address this challenge, we introduce Curiosity-Driven Exploration (CDE), a framework that leverages the model's own intrinsic sense of curiosity to guide exploration. We formalize curiosity with signals from both the actor and the critic: for the actor, we use perplexity over its generated response, and for the critic, we use the variance of value estimates from a multi-head architecture. Both signals serve as an exploration bonus within the RLVR framework to guide the model. Our theoretical analysis shows that the actor-wise bonus inherently penalizes overconfident errors and promotes diversity among correct responses; moreover, we connect the critic-wise bonus to the well-established count-based exploration bonus in RL. Empirically, our method achieves an approximate +3 point improvement over standard RLVR using GRPO/PPO on AIME benchmarks. Further analysis identifies a calibration collapse mechanism within RLVR, shedding light on common LLM failure modes.
The paper introduces CDE, which integrates PPL-based actor curiosity and multi-head critic variance to overcome premature convergence and entropy collapse in RL for LLMs.
It demonstrates that the incorporation of tailored exploration bonuses leads to significant performance improvements, with up to +10 points gain on AIME Pass@16 benchmarks.
It offers a theoretically grounded and efficient framework with implementation guidelines to integrate curiosity-driven signals into existing RLVR systems.
Curiosity-Driven Exploration for Efficient RL in LLMs
Introduction
The paper introduces Curiosity-Driven Exploration (CDE), a framework for improving exploration in Reinforcement Learning with Verifiable Rewards (RLVR) for LLMs. RLVR directly optimizes models using correctness signals from final answers, bypassing the need for reward models. However, RLVR methods such as GRPO and PPO suffer from premature convergence and entropy collapse, limiting their ability to explore diverse reasoning paths. CDE addresses these issues by leveraging intrinsic curiosity signals from both the actor (policy) and the critic (value function), formalizing these signals as exploration bonuses to guide learning.
Limitations of Count-Based Exploration in LLMs
Traditional count-based exploration methods, such as UCB and LSVI-UCB, incentivize agents to visit rarely explored state-action pairs. These approaches require expressive representations and computationally expensive operations (e.g., matrix inversion), which are impractical for high-dimensional, long-chain reasoning in LLMs. Hash-based pseudo-counts using SimHash were evaluated, but most responses clustered into a few hash buckets, failing to distinguish diverse reasoning patterns and rendering count-based exploration ineffective for RLVR.
Actor Curiosity: Perplexity-Based Exploration Bonus
CDE models actor curiosity as the uncertainty of the policy over its own actions, quantified by the perplexity (PPL) of generated responses. The actor curiosity bonus is defined as the negative average log-probability of a response:
Bactor(q,o)=−T1t=1∑Tlogπ(ot∣o<t,q)
This bonus is added to the original reward, but is adaptively clipped to prevent reward hacking and over-exploration:
r~(q,o)=r(q,o)+ωtmin(κ∣r(q,o)∣,αBactor(q,o))
Hyperparameters ωt (annealed over training), κ (clipping ratio), and α (scaling factor) control the magnitude and stability of the bonus. Theoretical analysis (Theorem 1) shows that the PPL bonus penalizes overconfident errors and promotes diversity among correct responses, improving calibration and exploration.
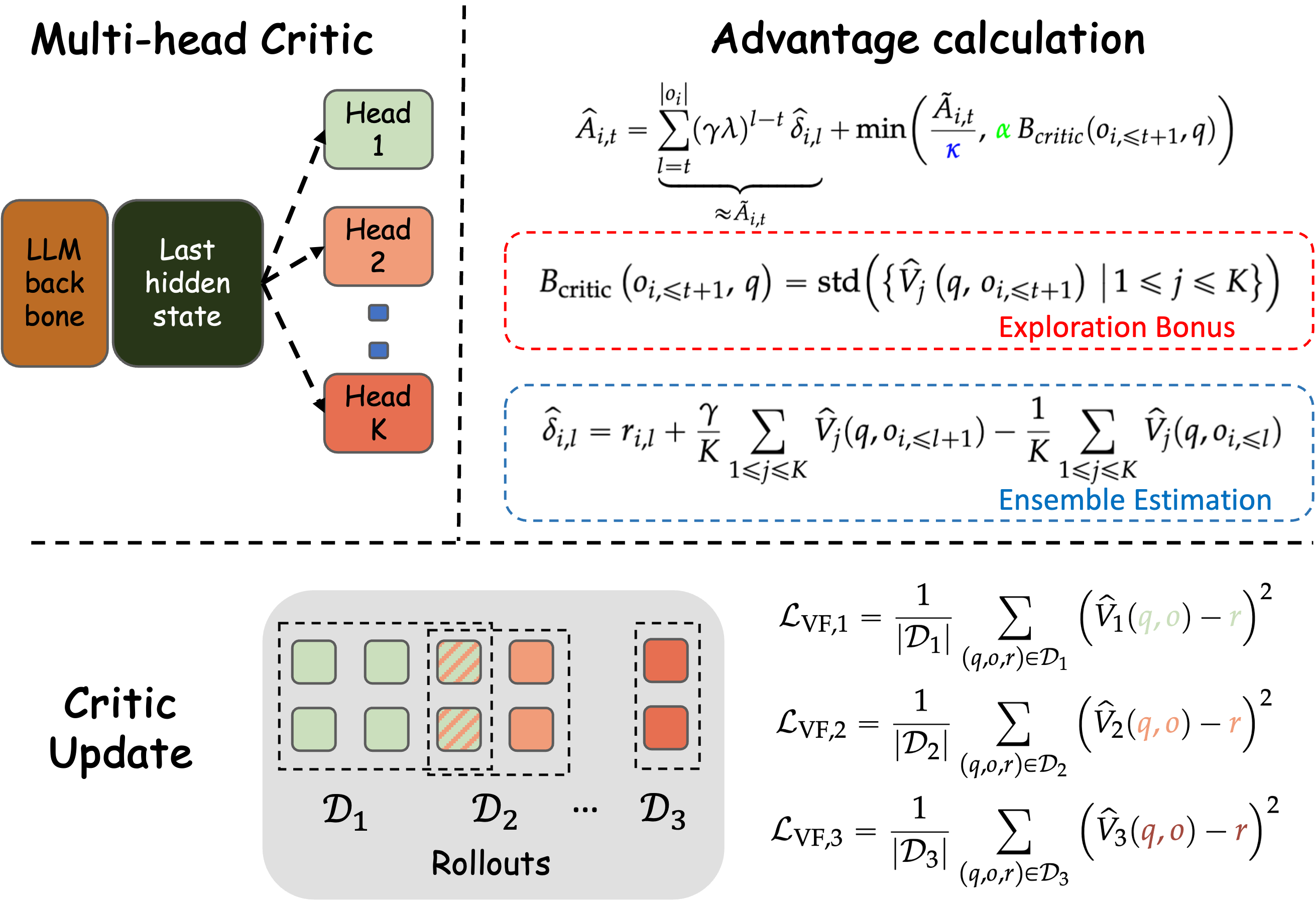
Critic Curiosity: Multi-Head Value Function Variance
CDE extends PPO with a multi-head critic architecture, where K value heads are trained on bootstrapped subsets of data. The standard deviation across these heads serves as a curiosity signal:
Bcritic(q,oi,≤t+1)=std({Vj(q,oi,≤t+1)}j=1K)
This bonus is incorporated into the advantage estimation, encouraging the policy to visit regions with high epistemic uncertainty. Theoretical results (Theorem 2) establish that, under linear MDP assumptions, the multi-head critic variance is a consistent estimator of the classical count-based exploration bonus.
Figure 1: Illustration of the multi-head critic framework.
Empirical Results
Experiments were conducted on four mathematical reasoning benchmarks (MATH, AMC23, AIME24, AIME25) using the Qwen3-4B-Base model. CDE was compared against vanilla GRPO and PPO, as well as their variants with PPL bonus and multi-head critics. Key findings include:
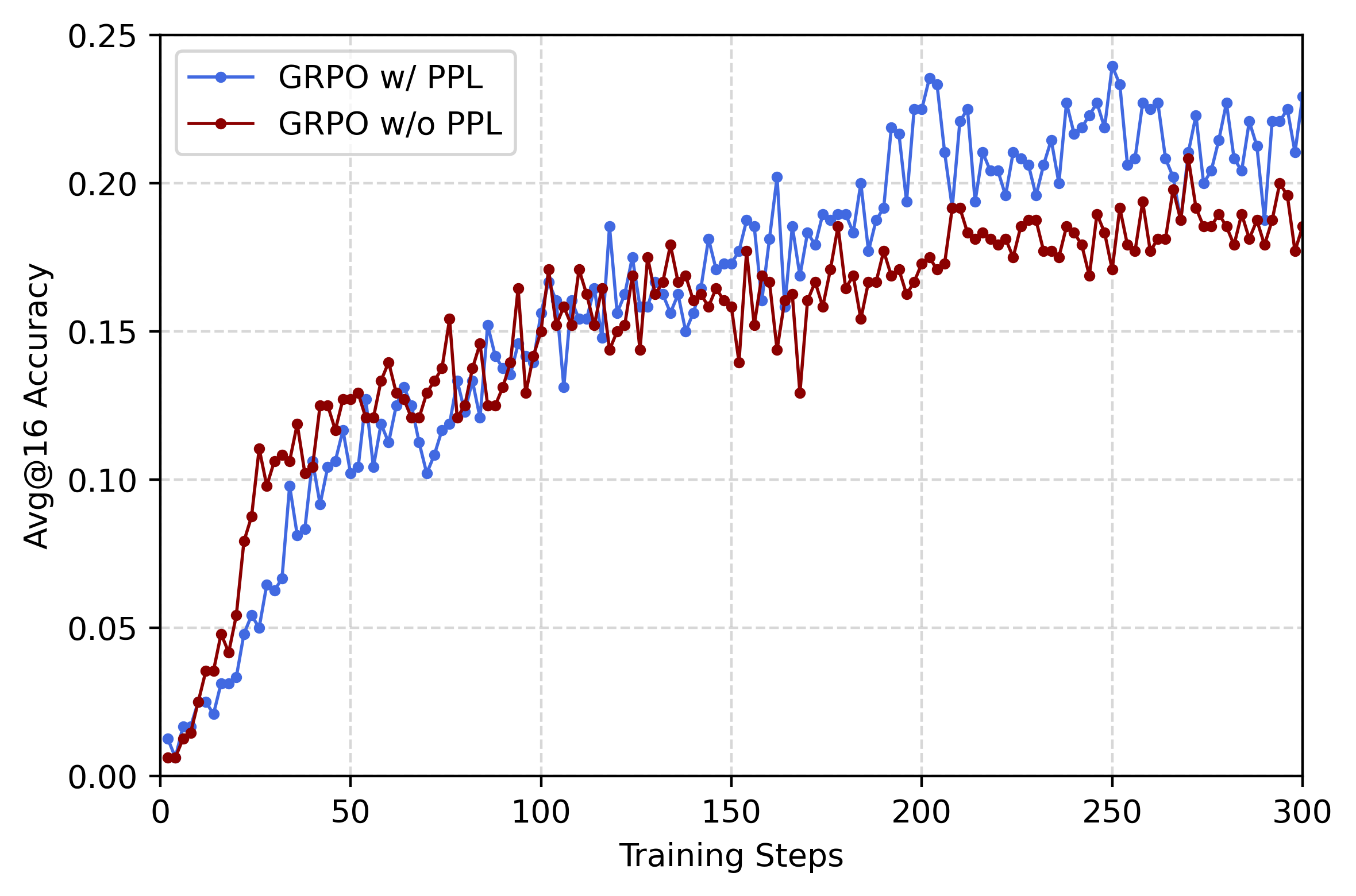
PPL bonus improves GRPO by +2.4 points on average, with up to +8 points on AIME24 Pass@16.
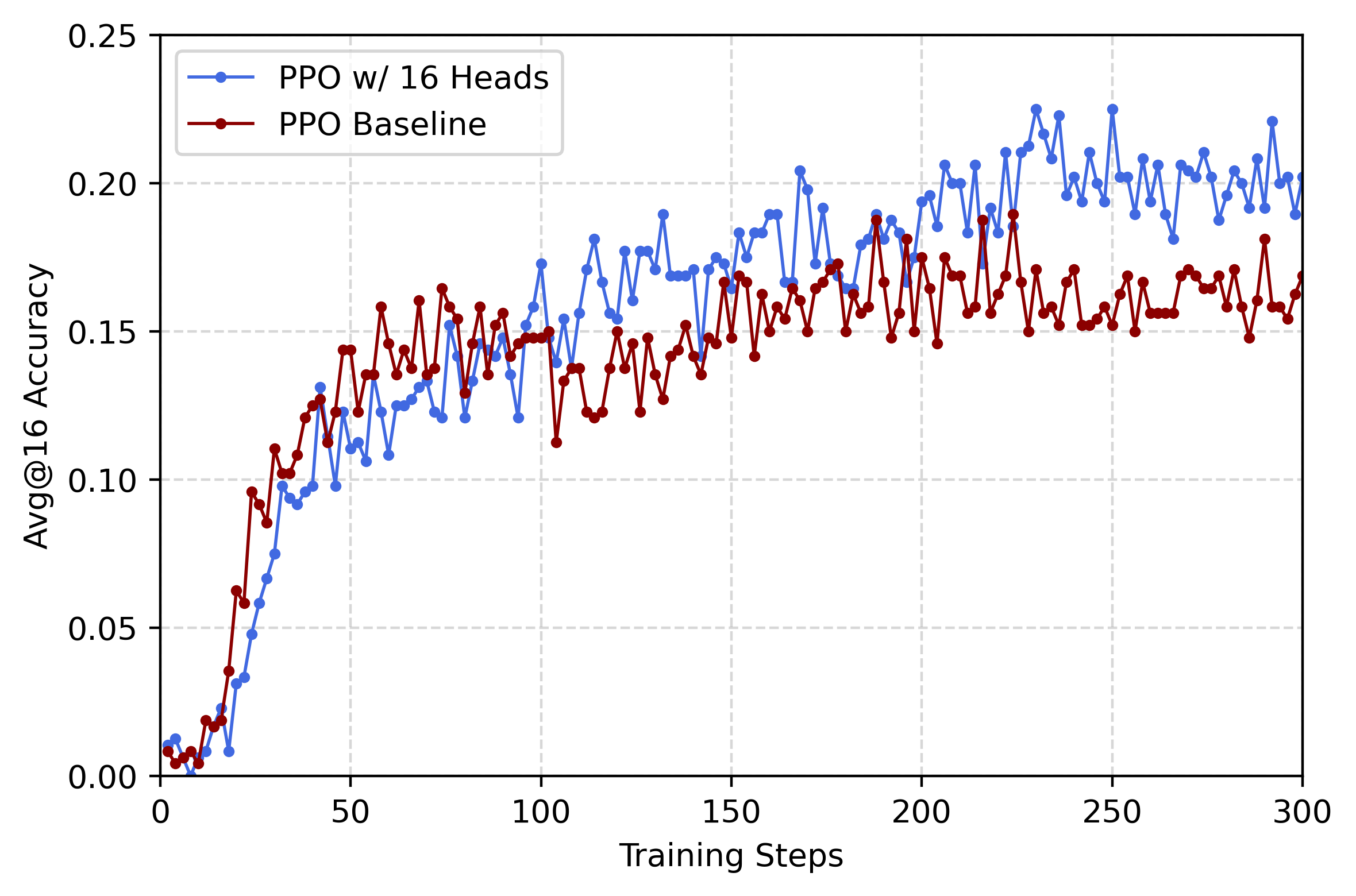
Multi-head PPO outperforms vanilla PPO, with K=4 and K=16 heads yielding +2 points average gain and up to +10 points on AIME Pass@16.
Performance increases with the number of heads, plateauing at K≥4.
CDE methods exhibit slower initial accuracy growth but ultimately surpass baselines, consistent with enhanced exploration and delayed exploitation.
Figure 2: Comparison of Avg@16 accuracy on AIME25 over training of vanilla GRPO and PPO (Baseline methods) and GRPO with PPL bonus and 16 head multi-head PPO (CDE methods).
Analysis of Exploration and Calibration
Decay schedules for the bonus weight ωt were evaluated, with staircase decay yielding the best results by sustaining strong exploration early and enabling stable convergence later. Entropy dynamics show that the PPL bonus mitigates entropy collapse, maintaining higher policy entropy and supporting exploration.
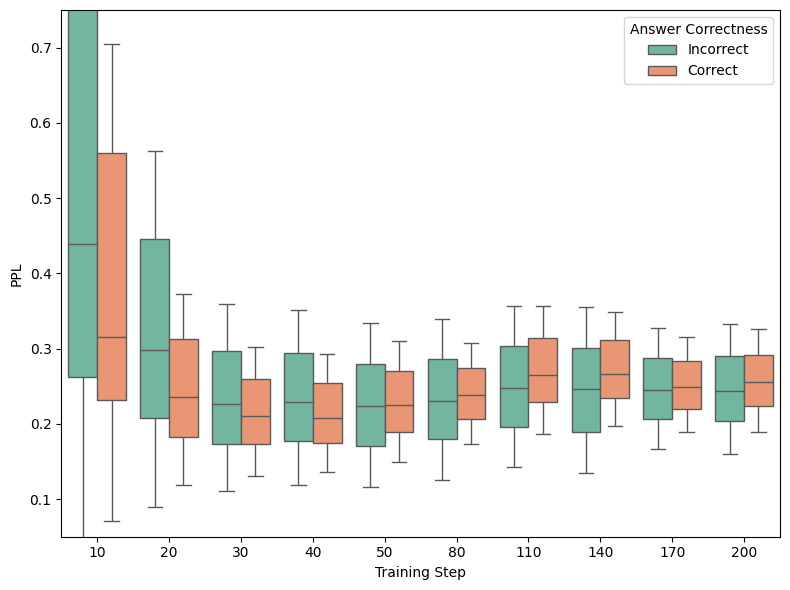
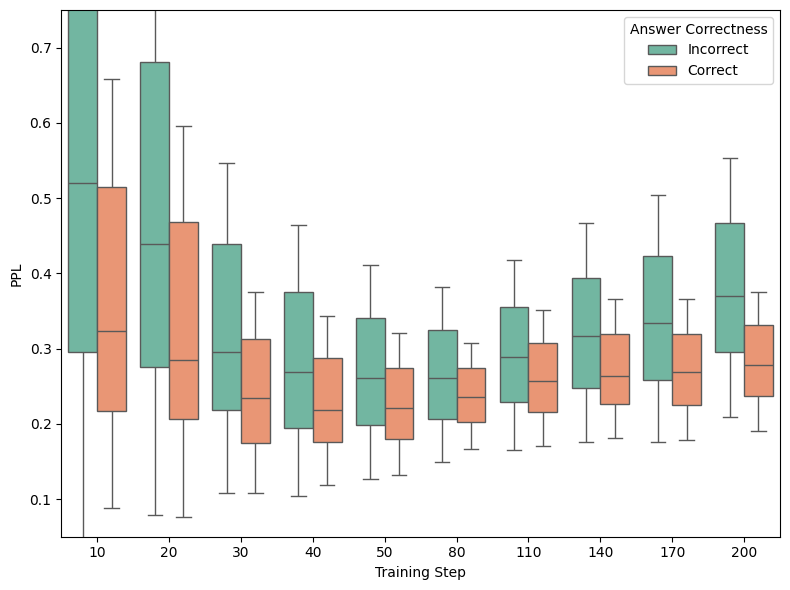
Figure 3: GRPO without PPL bonus.
Calibration analysis reveals that naive GRPO suffers from calibration collapse, where model confidence decouples from correctness. The PPL bonus preserves the separation between correct and incorrect response perplexity, improving calibration and interpretability.
Multi-Head Critic Dynamics
The average multi-head critic bonus Bcritic decreases over training, reflecting increased coverage and reduced uncertainty. Cross-dataset analysis shows higher critic disagreement on out-of-domain data, supporting the interpretation of Bcritic as a proxy for exploration in under-sampled regions. The sub-sample fraction ζ for critic heads was found to have limited impact on performance, indicating robustness of the multi-head approach.
Implementation Considerations
Actor curiosity bonus: Requires only minor modifications to the reward function and can be implemented efficiently using standard log-probability computations.
Multi-head critic: Extends the value function with K heads, each trained on bootstrapped data. This can be implemented with minimal architectural changes and parallelized for efficiency.
Hyperparameter tuning: Annealing schedules for ωt, choice of K, and clipping/scaling parameters are critical for balancing exploration and exploitation.
Resource requirements: Multi-head critics increase memory and compute linearly with K, but empirical results suggest K=4 suffices for most gains.
Deployment: CDE is compatible with existing RLVR frameworks and can be integrated into large-scale LLM training pipelines.
Implications and Future Directions
CDE provides a principled, lightweight approach to exploration in RLVR for LLMs, improving both accuracy and calibration. The framework is theoretically grounded and empirically validated, with strong performance on challenging reasoning tasks. The calibration collapse mechanism identified in RLVR training has implications for understanding LLM hallucination and suggests that multi-perspective reward designs (e.g., PPL bonus) can guide more robust learning.
Future work may explore extensions to multi-modal reasoning, more expressive curiosity signals, and integration with process-based supervision. The connection between exploration, calibration, and hallucination in LLMs warrants further investigation, particularly in the context of reward design and uncertainty estimation.
Conclusion
Curiosity-Driven Exploration (CDE) enhances RLVR training for LLMs by incorporating actor and critic curiosity signals as exploration bonuses. The approach is efficient, theoretically justified, and empirically effective, yielding consistent improvements over strong baselines. CDE advances the state of exploration in LLM RL, with implications for calibration, robustness, and future research in reasoning-focused LLMs.