LLMind: Bio-inspired Training-free Adaptive Visual Representations for Vision-Language Models
Abstract: Vision-LLMs (VLMs) typically assume a uniform spatial fidelity across the entire field of view of visual inputs, dedicating equal precision to even the uninformative regions. By contrast, human vision is neither uniform nor static; it is adaptive, selective, and resource-efficient. In light of this, we present the first systematic analysis of bio-inspired visual representation methods, providing insights for more efficient and adaptive VLMs. We propose LLMind (Looking Like the Mind), a novel training-free framework that mimics foveated encoding and cortical magnification in human vision to achieve adaptive, efficient representations for VLMs under tight pixel budgets. Our key idea is to explore a Bio-inspired Adaptive Sampling Strategy (BASS), enabling a Mobius-parameterized module that performs non-uniform sampling while preserving global scene structure. On top of BASS, we introduce closed-loop semantic feedback (CSF) via test-time adaptation to align perceptual saliency with textual information from the frozen VLM. We evaluate LLMind against uniform and other sampling baselines across diverse scene-level and region-guided visual question answering benchmarks. The results show dramatic gains, with average improvements of +20% on VQAv2, +38% on Seed-Bench, and +37% on A-OKVQA compared to uniform sampling under tight pixel budgets. More surprisingly, LLMind retains up to 82%, 92%, and 97% of the full-resolution performance using only 1%, 3%, and 5% of the pixels, respectively. Moreover, LLMind is lightweight, plug-and-play, and compatible with existing VLMs without requiring architectural changes.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and open issues that remain unresolved and could guide future research.
- Semantic feedback requires ground-truth answers at test time to compute the text loss, which is unrealistic in deployment. How to replace this with label-free signals (e.g., confidence/entropy, self-consistency, agreement across prompts/models, log-prob APIs) without degrading gains?
- Black-box SPSA incurs high query cost and latency (~4.75 s/iter reported) with multiple model calls per update. What are the accuracy–query trade-offs, query budgets, and early-stopping policies under typical API rate limits and pricing?
- Claimed black-box compatibility is not demonstrated with actual closed-source APIs (e.g., GPT-4V, Gemini, Claude). Does the method remain effective when only short-form answers are returned and no log-probs are exposed?
- End-to-end efficiency is unquantified: the sampled image is upsampled back to full resolution, so the VLM still processes the same number of tokens. Does the method reduce real compute, latency, memory, or energy inside the VLM, and how could token counts be reduced to realize actual savings?
- The MLP that predicts Möbius parameters is under-specified (inputs, architecture, initialization, optimizer/schedule). How sensitive is performance to these choices, and can one amortize adaptation across images without per-image optimization?
- The Möbius transform is parameterized with four real scalars (effectively a low-DOF global warp). This likely limits flexibility (e.g., rotations requiring complex coefficients, arbitrary fixation placement, rich deformations). Would complex coefficients, higher-DOF warps (TPS, spline grids), or piecewise/mixture warps improve performance?
- Single global warp cannot create multiple high-acuity zones. Can the approach be extended to sequential multi-fixation (saccadic) policies or multi-fovea layouts under the same pixel budget?
- No comparison to strong practical baselines:
- Crop-and-resize using provided region boxes (for region-guided tasks).
- Off-the-shelf saliency/grounding (e.g., GroundingDINO, SAM, CLIP/Grad-CAM) to place fixations.
- Entropy/uncertainty-guided tiling or adaptive zoom baselines.
- Dynamic token pruning/patch selection at matched FLOPs or wall-clock.
- Potential label leakage and overfitting: the CSF uses ground-truth answers on evaluation data for test-time optimization. Was adaptation performed per-image only? Is there a clean protocol with a held-out adaptation split?
- CSF depends on having multiple questions per image; real deployments often have a single query. How does performance degrade with one question, and how robust is the question-weighting scheme?
- Lack of hyperparameter sensitivity analysis: effects of α, β, γ (perceptual loss weights), SPSA step size δ, iteration count t, question-weighting η, and the β that balances image/text gradients are not reported.
- Stability and constraints of Möbius warping are not characterized: how are degenerate cases (ad−bc≠0), boundary handling, mapping outside image bounds, and anti-aliasing controlled? What are the failure modes?
- Assumptions about “information-matched images” (equal sampled pixels) do not address compressed bitrate/entropy or actual transmission budgets. How do results change under fixed file size or bandwidth constraints?
- Distortion-sensitive tasks (OCR, charts, diagrams, fine-grained part geometry) are not evaluated. Do warping and inverse-warping harm text legibility or geometric reasoning?
- Hallucination and grounding claims are not validated with targeted benchmarks (e.g., POPE, CHAIR, AMBER, GAVIE). Does adaptive sampling measurably reduce hallucinations or improve grounding metrics?
- Generalization beyond VQA remains untested: image captioning, retrieval, detection/segmentation, visual grounding, referring expressions, embodied tasks, and instruction following.
- Robustness under distribution shift/adversarial conditions (occlusion, clutter, lighting, viewpoint, artistic styles) is unknown. How resilient is the method to saliency misfires or ambiguous questions?
- Aspect ratio and resolution extremes (panoramas, ultra-wide/tall, fisheye) and the suitability of spherical stereographic mapping for perspective images are not analyzed.
- Perceptual artifacts from the warp–sample–inverse pipeline (ringing, aliasing, interpolation blur) are not quantified beyond training-time IQA metrics. Any human studies or task-specific IQA beyond VSI/DISTS?
- Calibration and uncertainty are unstudied: does adaptive sampling improve or degrade probability calibration and selective prediction/abstention?
- Compute/energy feasibility on real edge hardware is unclear: results are on 4×RTX 5090; no CPU/mobile profiling, power measurements, or latency budgets under realistic constraints.
- API privacy/cost implications of iterative black-box querying are not considered; strategies for cost-aware or privacy-preserving optimization are missing.
- Region-guided evaluation omits a simple “ground-truth crop” baseline that is a natural upper bound for many region-specific queries; including it would clarify where BASS adds value beyond cropping.
- No detailed analysis of failure cases (e.g., targets lies in compressed periphery, misleading saliency, complex scenes with multiple small objects). When does LLMind underperform and why?
- Theoretical grounding is limited: no information-theoretic analysis of why cortical magnification analogs improve VQA under budgets, nor bounds relating warp parameters to task-relevant information retention.
- Extension to video/3D is listed as future work, but open questions remain on temporally consistent sampling, recurrent saccade policies, camera-motion-aware warps, and coupling with 3D neural rendering pipelines.
- Reproducibility gaps: several implementation details (exact iteration counts, learning rates, seeds, data splits, pre/post-processing) are unspecified; code/data for full replication are not confirmed.
Practical Applications
Practical Applications of LLMind (Bio-inspired, Training-free Adaptive Visual Representations for VLMs)
The paper introduces LLMind, a plug-and-play, training-free front end for Vision-LLMs (VLMs) that adaptively allocates pixel budgets using a bio-inspired, Möbius-parameterized sampling module (BASS) and closed-loop semantic feedback (CSF) via gradient-free SPSA. It consistently retains 55–80%+ of full-resolution accuracy with only 1–5% of pixels and can surpass full-resolution performance on region-guided tasks by suppressing distractors. It works with existing white-box and black-box VLMs (no architectural changes), and is especially compelling for small/edge models.
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations, grouped by immediacy.
Immediate Applications
These can be deployed now with existing VLMs/APIs, using BASS alone for low-latency or with CSF in latency-tolerant or offline settings.
- Healthcare (tele-triage, mobile imaging support)
- Application: Low-bandwidth, on-device visual Q&A for telemedicine intake (e.g., “What’s visible in this rash image?”, “Is the wound dressing intact?”), remote eldercare monitoring prioritizing salient regions.
- Tools/workflow: A mobile SDK wrapping black-box VLM APIs; BASS pre-processor to downsample to 1–5% pixels and upscale before upload; optional CSF in batch/offline post-processing to refine policies.
- Assumptions/dependencies: Not for clinical diagnosis without validation; human-in-the-loop; adherence to privacy and medical regulations; image questions available at inference (for CSF) or use proxy rewards (answer consistency) when ground truth is unavailable.
- Robotics and Drones (resource-constrained perception)
- Application: Region-guided VQA for pick-and-place, inventory inspection, UAV reconnaissance—focus pixels on task-specified ROIs; suppress background to reduce hallucinations and improve grounding.
- Tools/workflow: ROS node/plugin applying BASS on camera frames before passing to a small VLM; ROI prompts from planner; run no-CSF mode for real-time; cache/adapt parameters offline with CSF.
- Assumptions/dependencies: Tight real-time budgets may preclude frequent SPSA; requires ROI/waypoint integration from planner; safety fallback to uniform sampling for critical frames.
- Mobile and Wearables (AR/VR assistants, smart glasses)
- Application: On-device multimodal assistants answering scene questions under strict power/compute limits (e.g., “Where is the exit sign?”); foveated capture aligned to user intent or gaze.
- Tools/workflow: Edge pipeline with BASS for adaptive sampling; optional gaze-to-fovea mapping if eye-tracking is available; black-box VLM API wrapper with budget control.
- Assumptions/dependencies: Gaze data optional; CSF increases latency (use low-iteration or scheduled adaptation); UI for user intent prompts.
- Retail and e-Commerce
- Application: Product Q&A and visual search on consumer devices (e.g., “Is this the 500 ml bottle?”) by allocating detail to SKU regions; shelf audit and planogram checks with drones/carts.
- Tools/workflow: BASS pre-processor in mobile app or store camera system; region prompts from detection/landmarks; API calls to small VLMs to reduce cloud spend.
- Assumptions/dependencies: Integration with existing SKU detection/ROI providers improves reliability; lighting/domain shifts may require periodic CSF fine-tuning offline.
- Document Understanding and OCR-centric VQA
- Application: Receipt/form question answering by concentrating samples on text blocks, tables, stamps/seals; reduces OCR and VLM compute while preserving key fields.
- Tools/workflow: BASS guided by layout detectors (e.g., text boxes) or question keywords; plug-in for doc-VLMs; answer consistency as a CSF proxy.
- Assumptions/dependencies: Requires layout detection or initial pass to propose ROIs; black-box VLM image limits (upload size, format) must be respected.
- Content Moderation and Trust & Safety
- Application: ROI-focused scanning for faces, logos, or unsafe elements in UGC to cut inference cost without missing key evidence.
- Tools/workflow: BASS driven by detector-derived ROIs; cascaded pipeline with quick filters → foveated VLM analysis; adjustable pixel budgets per risk.
- Assumptions/dependencies: Compliance with platform policies; occasional full-res sampling for audit; calibrated thresholds to manage false negatives.
- Network- and Cost-Efficient Cloud API Use
- Application: Reduce bandwidth/latency and API costs by sending foveated, upsampled images that retain salient evidence; relevant for pay-per-token/pixel multimodal APIs.
- Tools/workflow: A thin client-side library applying BASS; dynamic pixel budget based on network or SLA; optional CSF during low-traffic windows to refine parameters per task.
- Assumptions/dependencies: API must accept images post-upsampling; SPSA-based CSF implies extra queries—use sparingly or with cached perturbations.
- Smart Cameras/IoT and Remote Monitoring
- Application: Bandwidth-aware transmission from edge cameras (parking, logistics, agriculture) with task-driven foveation (e.g., count vehicles; detect crop stress).
- Tools/workflow: Camera firmware or edge gateway with BASS; schedule-dependent CSF; backend VLM or lightweight classifier for task feedback.
- Assumptions/dependencies: Legal/ethical constraints (e.g., surveillance); intermittent connectivity may favor BASS-only; define task prompts upstream.
- Research and Education
- Application: Fair benchmarking under equal information budgets (“information-matched” comparisons); coursework and labs on bio-inspired perception.
- Tools/workflow: Open-source BASS/CSF pre-processor; evaluation harness for 1–5% pixel budgets; scripts for black-box SPSA.
- Assumptions/dependencies: Clear reproducibility protocols; cover diverse domains to avoid overfitting to VQA.
- Media Compression and Pre-Processing
- Application: Compression-aware pipelines that preserve ROI detail before JPEG/AV1 encoding (e.g., thumbnails for e-commerce, news, or social feeds).
- Tools/workflow: BASS front end feeding an encoder; per-asset pixel budget tuned by downstream KPI (CTR, OCR accuracy).
- Assumptions/dependencies: Interplay with encoder rate-control; maintain global structure to avoid user-visible artifacts.
Long-Term Applications
These require further research, engineering, scaling, or validation (e.g., hardware integration, regulatory approvals, generalized reward signals).
- Hardware-Integrated Foveated Sensors and ISPs
- Application: Camera hardware that supports non-uniform pixel readout (cortical magnification profiles) to reduce energy and bandwidth at the sensor.
- Tools/workflow: ISP firmware implementing Möbius-like warps; driver-level ROI control; co-design with downstream VLMs.
- Assumptions/dependencies: New sensor/ISP designs; ecosystem support in mobile SoCs; calibration and QA pipelines.
- Real-Time Video and Streaming Foveation
- Application: Continuous, task- or gaze-driven foveated video for AR telepresence, remote assistance, robotics teleoperation, and collaborative MR.
- Tools/workflow: Temporal extensions of BASS; predictive/track-aware foveation; video codecs that reserve bits for ROI.
- Assumptions/dependencies: Low-latency gaze tracking or task predictors; robust temporal stability; codec-level integration.
- Safety-Critical Autonomy (Automotive, Aviation)
- Application: Foveated visual reasoning for driver assistance or UAV navigation, prioritizing salient hazards while conserving compute.
- Tools/workflow: Certified pipelines combining BASS with redundant full-res checks; formal verification of foveation policies.
- Assumptions/dependencies: Rigorous validation and certification; fail-safes; explainability and audit trails.
- Clinical Diagnostics and Regulatory-Grade Healthcare
- Application: Diagnostic support focusing on lesion ROIs (radiology, pathology) under strict compute/bandwidth budgets.
- Tools/workflow: Co-designed, validated foveation policies per modality; integration with PACS; clinician-in-the-loop AI.
- Assumptions/dependencies: Prospective trials; regulatory clearance; robust, label-free CSF proxies (e.g., radiomics priors).
- 3D-Aware Multimodal Tasks and Neural Rendering
- Application: Compression-aware 3D VQA, object-centric descriptions, neural rendering pipelines with task-driven sampling of rays/regions.
- Tools/workflow: BASS analogs over rays/voxels; CSF with 3D rewards (e.g., reprojection error + semantic consistency).
- Assumptions/dependencies: New objective functions; joint optimization over space-time; benchmarks and tooling.
- Co-Training and Joint Optimization with VLMs
- Application: Training VLMs to be robust to non-uniform, foveated inputs—smaller models with stronger grounding under tight budgets.
- Tools/workflow: Curriculum that mixes pixel budgets; reinforcement or self-supervised signals for sampling policy; co-learning with token pruning.
- Assumptions/dependencies: Compute and data; stability of joint optimization; evaluation standards for fairness.
- Generalized, Label-Free CSF (Production-Friendly)
- Application: Replace ground-truth-dependent CSF with reward models (e.g., self-consistency across rephrasings, entailment, CLIP- or VLM-based answer-image alignment) for deployment at scale.
- Tools/workflow: Reward model APIs; confidence-weighted SPSA; cache-and-reuse of sampling parameters per task/domain.
- Assumptions/dependencies: Robustness of proxy rewards; bias and failure analysis; monitoring and rollback.
- Standards and Policy for Energy-Efficient Multimodal AI
- Application: Procurement and compliance guidelines that include “pixel budget” and “information-matched” metrics; incentives for green AI deployment.
- Tools/workflow: Benchmarks and auditing tools for foveation efficacy and fairness; shared leaderboards under fixed budgets.
- Assumptions/dependencies: Industry and regulator buy-in; alignment with privacy and safety frameworks.
- Cross-Modal Foveation and Sensor Fusion
- Application: Coordinated ROI allocation across camera/LiDAR/radar, or vision–audio for egocentric assistants and robots.
- Tools/workflow: Joint policies that adapt sampling across sensors; uncertainty-driven ROI arbitration.
- Assumptions/dependencies: Synchronization and calibration; new fusion models tolerant to non-uniform inputs.
- Developer Products and MLOps Tooling
- Application: SDKs that wrap OpenAI/Gemini/Qwen/Claude vision APIs with adaptive pixel budgets, budget-aware routing, and cost/latency dashboards.
- Tools/workflow: Policy engines for when to run CSF; hybrid heuristics + SPSA; per-tenant cost controls.
- Assumptions/dependencies: API rate limits; governance for perturbation-based optimization; privacy and logging policies.
Notes on feasibility across applications:
- Latency/cost trade-offs: CSF (SPSA) adds query overhead; use BASS-only or limited-iteration CSF for real-time paths; batch/offline CSF for periodic adaptation.
- Supervision at inference: Paper’s CSF uses ground-truth for semantic loss in experiments; deployments should employ label-free proxies (e.g., answer self-consistency, entailment checks, VLM confidence) or human feedback.
- Black-box integration: Works with proprietary APIs—no gradient/model access required; however, perturbation-based CSF increases API calls.
- Domain transfer: Strong results in VQA; extensions to detection, captioning, or video likely but need validation and tailored rewards.
- Ethics and privacy: Foveation can reduce capture of bystanders/PII, but ROI choices must be auditable; maintain fairness and avoid systematic bias against underrepresented features.
Glossary
- A-OKVQA: A visual question answering dataset that requires integrating external/world knowledge beyond the image. "Additionally, we evaluate LLMind on A-OKVQA dataset, which requires integrating external, world-based knowledge for comprehensive visual understanding."
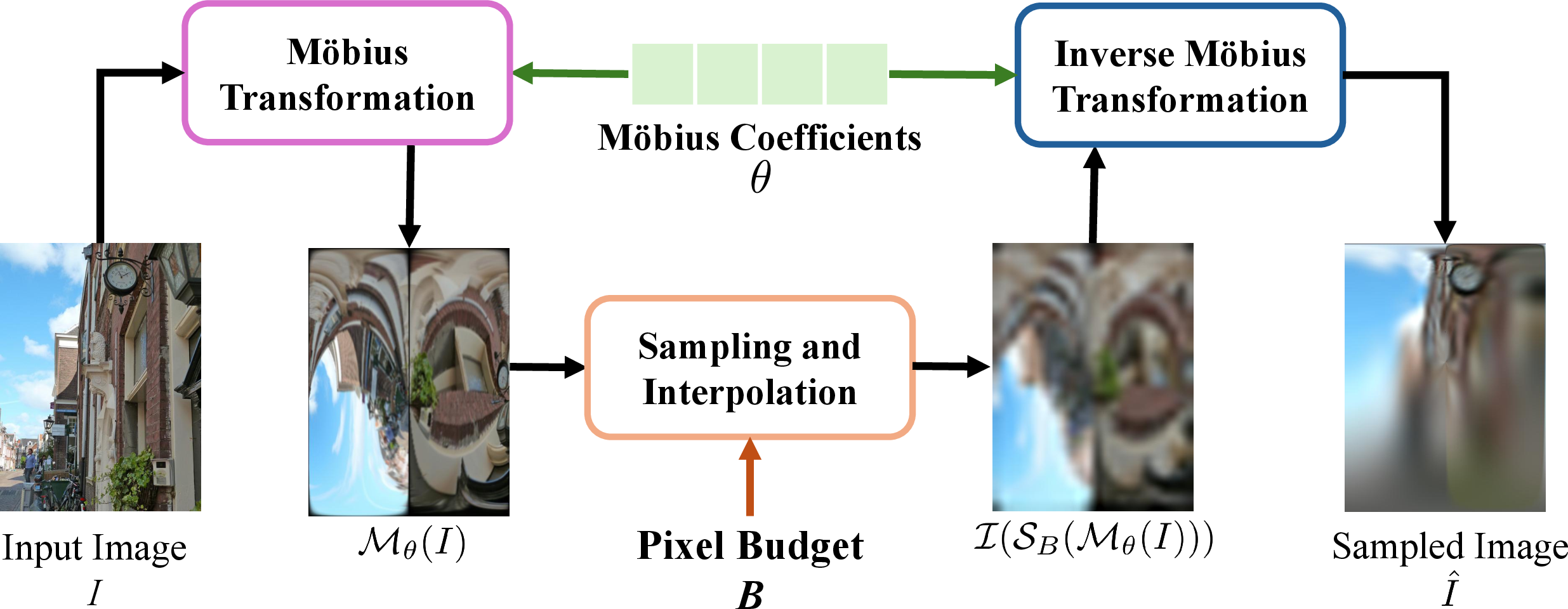
- Bio-inspired Adaptive Sampling Strategy (BASS): The paper’s adaptive, non-uniform sampling mechanism that reallocates resolution toward salient regions, inspired by human vision. "Our key idea is to explore a Bio-inspired Adaptive Sampling Strategy (BASS)."
- bilinear sampling: An interpolation method that computes pixel values via linear interpolation along two image axes. "where denotes bilinear sampling"
- black-box VLMs: Vision-LLMs whose internal parameters/gradients are inaccessible to the user. "compatible with both white-box and black-box VLMs (Sec.~\ref{sec:csl})."
- Closed-Loop Semantic Feedback (CSF): A test-time feedback mechanism that uses semantic signals from a VLM to steer the sampling process. "we introduce closed-loop semantic feedback (CSF) via test-time adaptation"
- cognitive window: A specified image region that defines where the model should concentrate its analysis. "Each question is associated with a bounding region that defines a cognitive window."
- conformal mapping: A transformation that preserves local angles and shapes (locally), used here to warp sampling while keeping geometry consistent. "As a conformal mapping on the spherical plane, Möbius transformations perform smooth mappings of the image space (\ie rotation, translation, scaling, inversion) while preserving local geometry."
- ControlMLLM: A training-free framework that optimizes attention-related variables at inference to focus on regions of interest. "ControlMLLM~\cite{wu2024controlmllm}, for example, optimized latent variables over attention maps at test time to guide focus toward region-of-interest cues."
- cortical magnification: The principle that more cortical area is devoted to processing the fovea than the periphery, yielding higher detail in attended regions. "This mechanism reflects the principle of cortical magnification, where perceptually salient regions occupy disproportionately large representational space in the visual cortex"
- Deep Image Structure and Texture Similarity (DISTS): A perceptual image similarity metric that compares structure and texture in feature space. "a Deep Image Structure and Texture Similarity (DISTS)~\cite{ding2020image} metric to enforce perceptual alignment in feature space"
- dynamic tokenization: Techniques that adaptively select or prune tokens/features based on input content to improve efficiency. "Although dynamic tokenization \cite{bolya2022token, rao2021dynamicvit} has recently been introduced to address such issues, it still requires full-resolution input, which limits its suitability for edge systems."
- foveated encoding: A visual representation emphasizing high resolution near a fixation point and lower resolution in the periphery. "mimics foveated encoding and cortical magnification in human vision"
- foveation strategy: The biological approach where the visual system samples densely at the point of gaze and sparsely in the periphery. "the human visual system employs a hierarchical, attention-driven foveation strategy:"
- frozen VLM: A vision-LLM used without updating its parameters during optimization. "guided by the semantic output of the frozen VLM."
- information-matched images: A comparative setup where different sampling methods use the same number of pixels to control for information content. "We adopt the concept of information-matched images proposed by Gizdov et al.~\cite{gizdov2025seeing}"
- log-polar sampling: A variable-resolution sampling scheme that increases sampling density near a fixation point using log-polar coordinates. "using log-polar sampling to generate variable-resolution inputs."
- Möbius transformation: A complex-plane fractional linear mapping used to implement smooth, geometry-preserving spatial warps. "we use Möbius transformation~\cite{arnold2008mobius, olsen2010geometry}, a mathematical tool that is parameterized to simulate cortical magnification."
- north-pole stereographic projection: A projection from the sphere to the complex plane using the north pole as the projection point. "using north-pole stereographic projection , yielding ."
- perceptual loss: A loss function that prioritizes human-perceived quality or structure rather than just pixel-wise differences. "We optimize the BASS parameters in a training-free loop using a perceptual loss, guided by the semantic output of the frozen VLM."
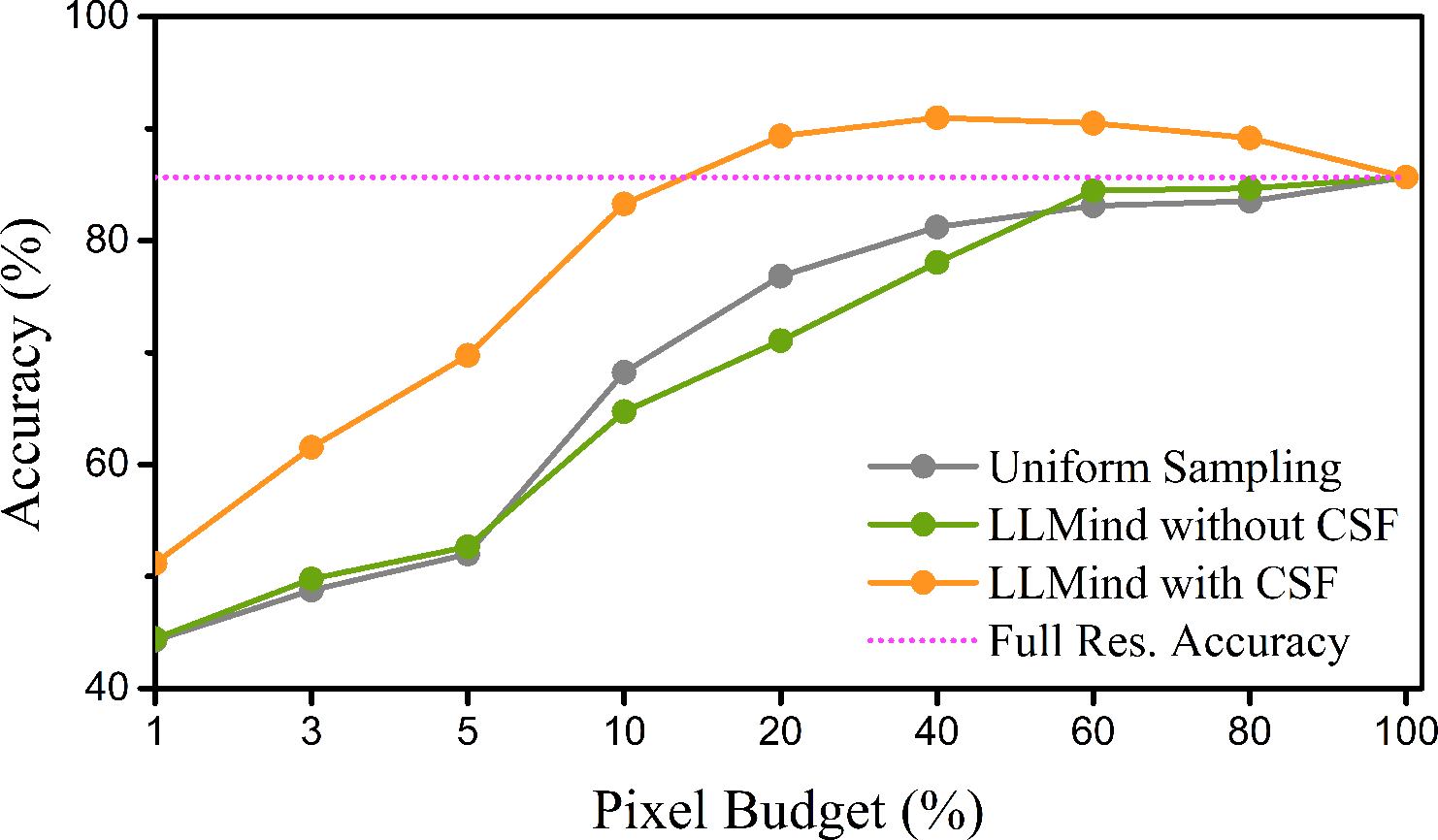
- pixel budget: A constraint limiting the number or fraction of pixels that can be sampled/processed. "performs uniform sampling at a controlled pixel budget "
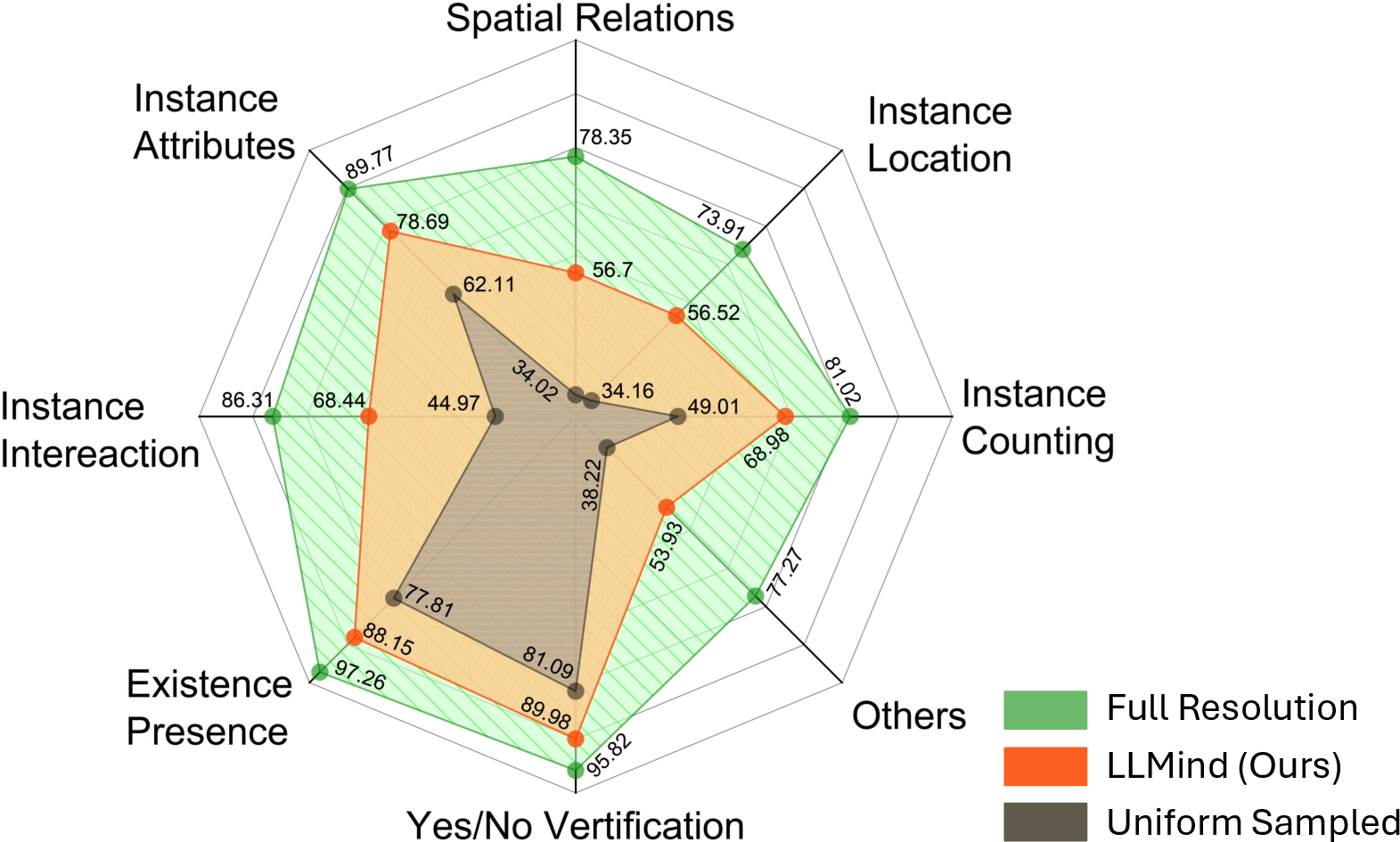
- Region-guided VQA: A VQA setting that provides spatial prompts or regions to focus the model’s reasoning. "For region-guided VQA, LLMind achieves an average gain of 35\% over uniform sampling"
- region-specific classification (RSC): Classification restricted to a specified region of the image rather than the entire scene. "The questions require interpreting spatial cues to perform region-specific classification (RSC) within the defined cognitive window."
- saccadic movements: Rapid eye movements that reposition the fovea to different parts of a scene. "Through rapid saccadic movements, the visual system dynamically repositions this high-resolution window"
- Seed-Bench: A benchmark for evaluating multimodal reasoning capabilities across varied tasks. "We conduct experiments on 5000+ question-answer pairs from VQAv2 and 2000+ pairs from Seed-Bench to evaluate general scene-level reasoning capabilities for LLMind."
- Sentence Transformer: A model that produces sentence-level embeddings for semantic similarity. "where denotes normalized embeddings obtained from a Sentence Transformer (MiniLM~\cite{wang2020minilm})."
- Simultaneous Perturbation Stochastic Approximation (SPSA): A gradient-free optimization algorithm that estimates gradients via random perturbations. "using Simultaneous Perturbation Stochastic Approximation~\cite{spall2002multivariate} to estimate gradients"
- stereographic projection: A mapping from the sphere to the plane preserving angles, used to move between spherical and planar coordinates. "We apply a Möbius transformation to the input images via stereographic projection."
- sunflower phyllotaxis: A spiral arrangement pattern in nature, used here to design a sampling layout. "following the sunflower phyllotaxis model proposed by Killick \etal~\cite{killick2023foveation}."
- test-time adaptation: Adjusting parameters or inputs during inference to improve task performance. "we introduce closed-loop semantic feedback (CSF) via test-time adaptation"
- training-free: An approach that does not require updating model weights through training. "We propose LLMind (Looking Like the Mind), a novel training-free framework"
- variable-resolution sampling: Sampling the image at non-uniform resolutions to allocate more detail where needed. "demonstrated that variable-resolution sampling improves VQA and detection accuracy in existing Large multimodal models (LMM) under tight pixel budgets."
- Vision-LLMs (VLMs): Models that jointly process and reason over visual and textual inputs. "Vision-LLMs (VLMs) have recently demonstrated impressive progress in multimodal reasoning and visual question answering (VQA)"
- Visual Question Answering (VQA): A task where a model answers natural-language questions about an image. "Vision-LLMs (VLMs) have recently demonstrated impressive progress in multimodal reasoning and visual question answering (VQA)"
- Visual Saliency-Induced Index (VSI): A perceptual similarity metric emphasizing human-attentive regions. "a Visual Saliency-Induced Index (VSI)~\cite{zhang2014vsi} term to prioritize human-attentive regions"
- white-box setting: An evaluation/setup where internal model states or gradients are accessible. "thus operating in a white-box setting."
Collections
Sign up for free to add this paper to one or more collections.

