- The paper demonstrates that VLMs rely on semantic anchors, neglecting pixel-level details despite retaining rich internal visual features.
- Methodologies such as chain-of-thought reasoning and Logit Lens analysis reveal that semantic bias stems from training paradigms rather than architectural limitations.
- Results indicate that task-specific fine-tuning and assigning arbitrary names can mitigate this bias, enhancing VQA accuracy and out-of-distribution generalization.
VLMs Need Words: Vision LLMs Ignore Visual Detail In Favor of Semantic Anchors
Motivation and Problem Statement
The paper "VLMs Need Words: Vision LLMs Ignore Visual Detail In Favor of Semantic Anchors" (2604.02486) interrogates the architecture and behavior of vision-LLMs (VLMs) in fine-grained visual reasoning tasks. Although VLMs demonstrate high performance in a range of multimodal problems, they systematically fail at tasks requiring detailed pixel-level perception, despite retaining visual information internally. The central claim is that these failures stem not from architectural limitations but from training paradigms that bias VLMs toward mediating visual reasoning through discrete semantic anchors in the language space.
Semantic Anchoring and Visual Correspondence Paradigm
The authors frame their analysis around visual correspondence tasks, where entities in two images must be matched — an archetype for numerous vision-centric applications. Entities can be either nameable (semantically anchored) or unnameable (sub-semantic or novel). The evaluation employs multiple-choice VQA, chain-of-thought (CoT) prompting, and representation probing.
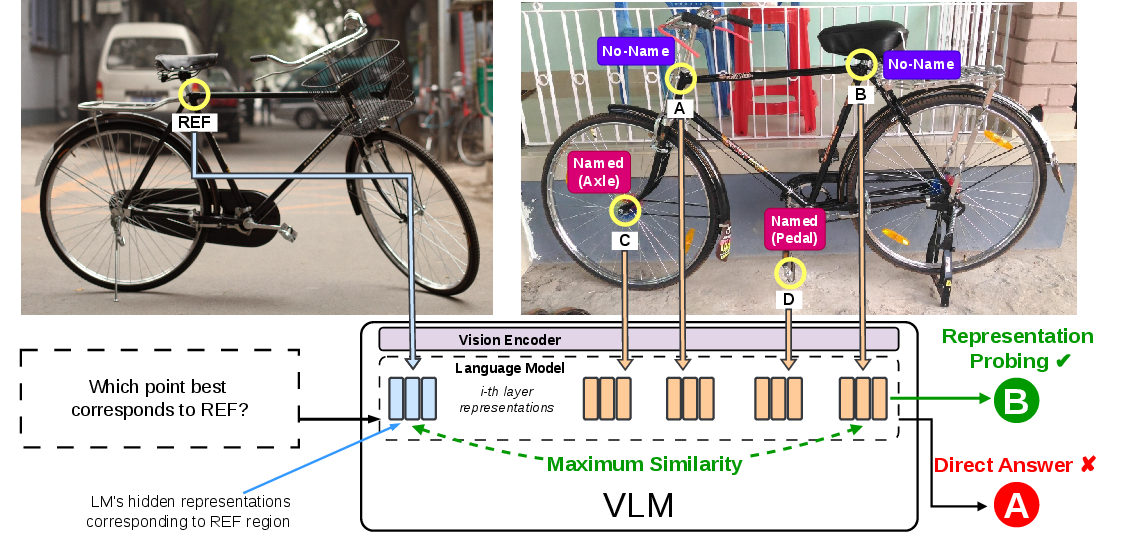
Figure 1: The correspondence task—match a reference point labeled "REF" with one of four candidates, evaluated using Direct answer, Chain-of-Thought, and Representation Probing.
Empirical results indicate that across semantic, shape, and face correspondence, VLMs consistently achieve higher accuracy when the reference entity is nameable. Representation probing reveals that internal features do contain sufficient information to solve these tasks, but the models’ textual output remains bottlenecked unless a semantic anchor is available.
Chain-of-Thought and the Mechanism of Semantic Anchoring
Chain-of-Thought reasoning is found to disproportionately benefit named entities, confirming that VLMs convert visual tasks into verbal string-matching when possible. Qualitative inspection of CoT reveals that models explicitly surface semantic entity labels during intermediate steps, routing their reasoning through language.

Figure 2: Chain-of-Thought reasoning with and without semantic anchors; hallucination occurs when points cannot be crisply labeled.
Synthetic Tasks and Controlled Demonstrations
Synthetic shape and face correspondence tasks further isolate semantic anchoring effects. Procedurally generated "squiggles" or AI-generated faces lack semantic labels, and the performance gap between textual response and internal probing becomes more pronounced in these cases. CoT reasoning is observed to degrade performance for unnameable entities by introducing hallucinated descriptions.

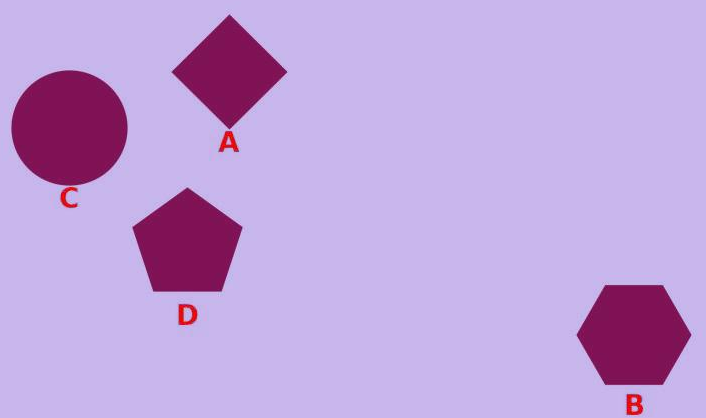
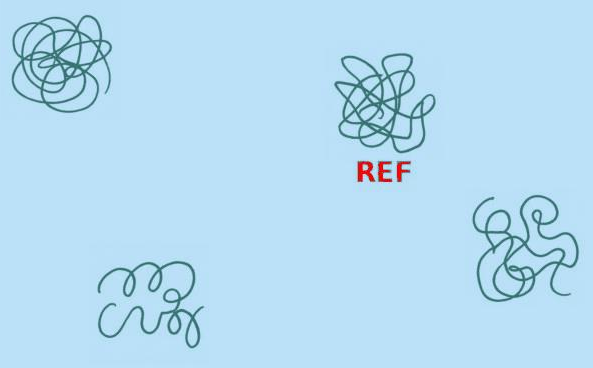
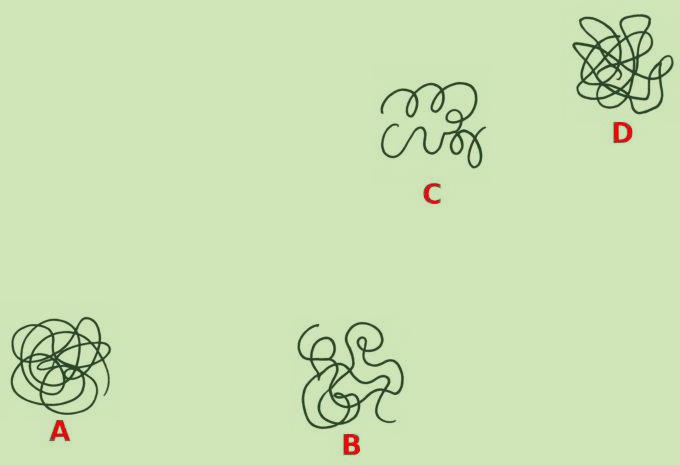
Figure 3: Evaluation on synthetic shape correspondence tasks reveals amplified performance gaps for unknown references.
Logit Lens Analysis: Layerwise Semantic Recovery
By employing Logit Lens, the authors decode hidden representations of visual tokens throughout the LM layers. For nameable entities, the token trajectory evolves from noise to approximate descriptors to exact labels, then higher-level associations in deeper layers. Unknown entities remain semantically indiscernible.
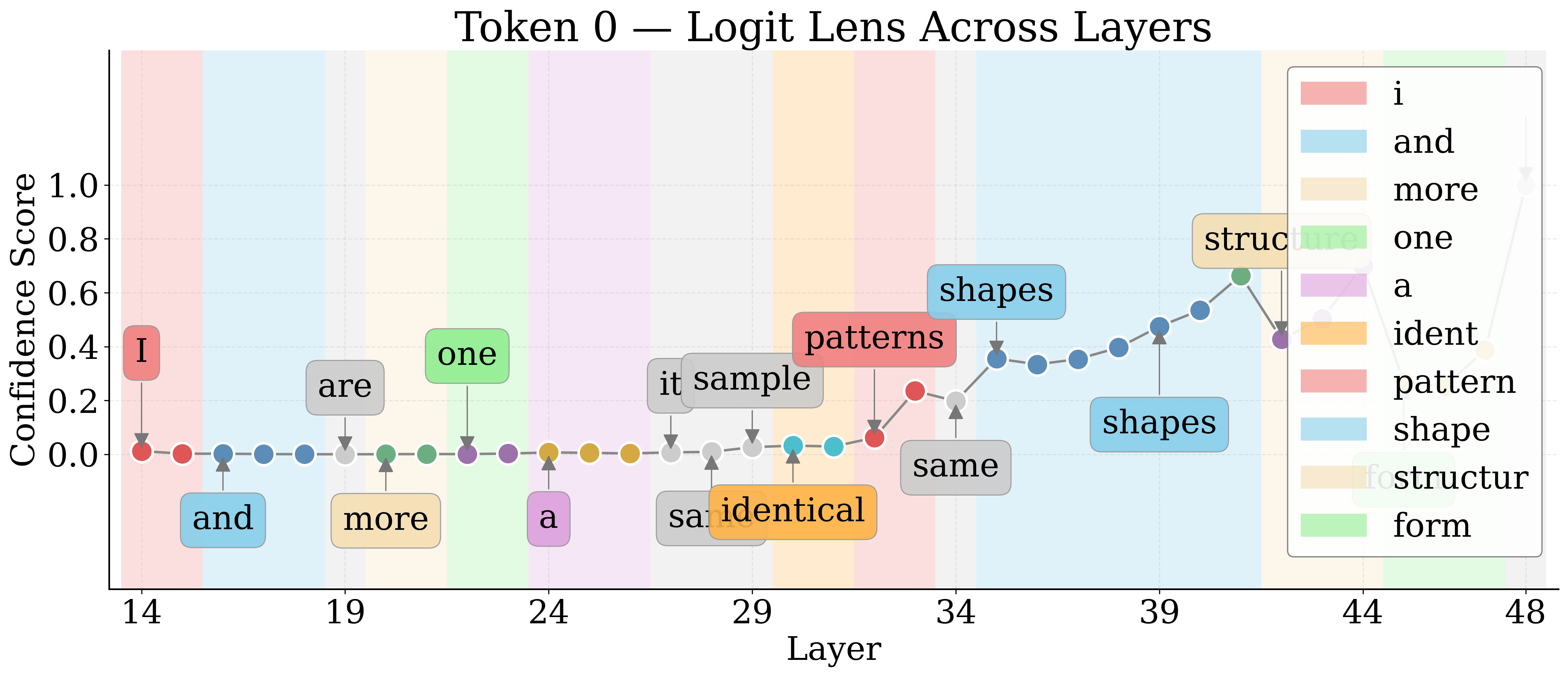
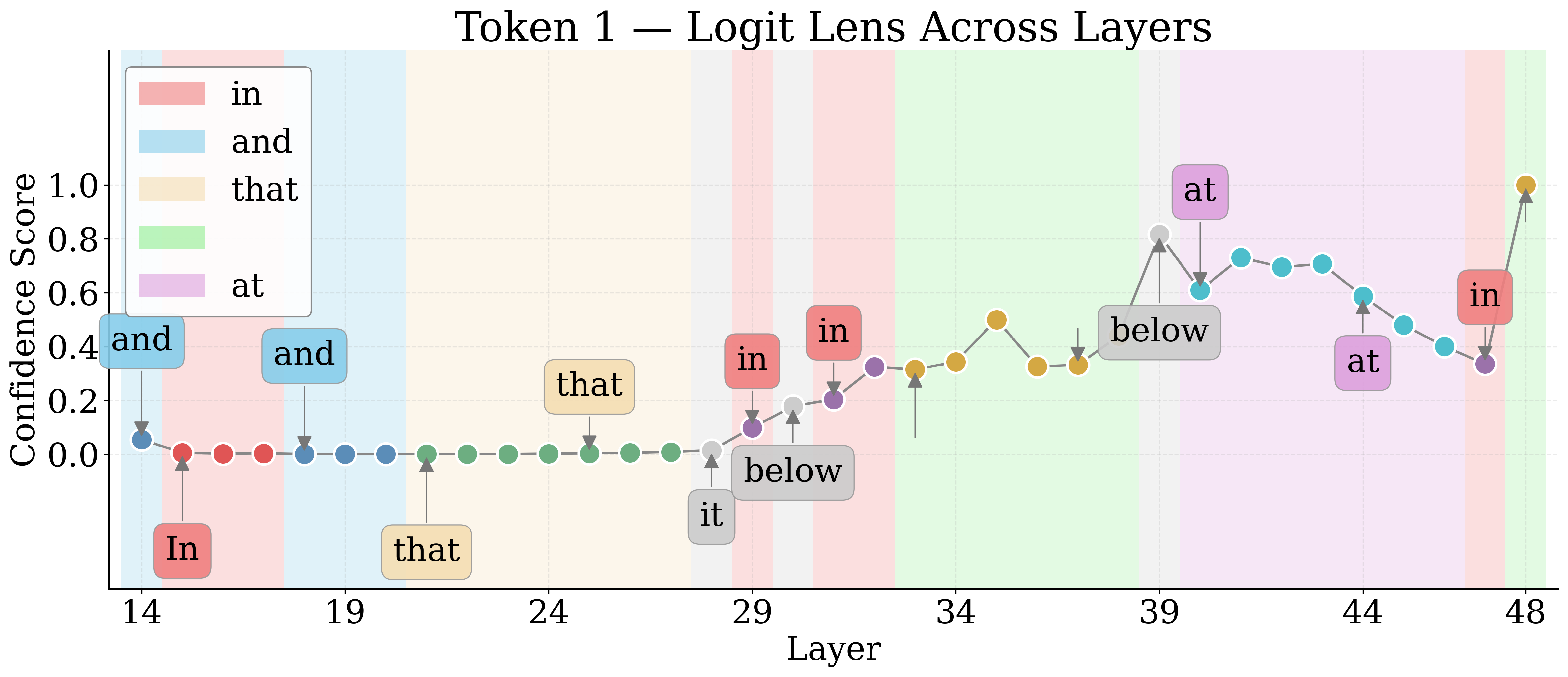
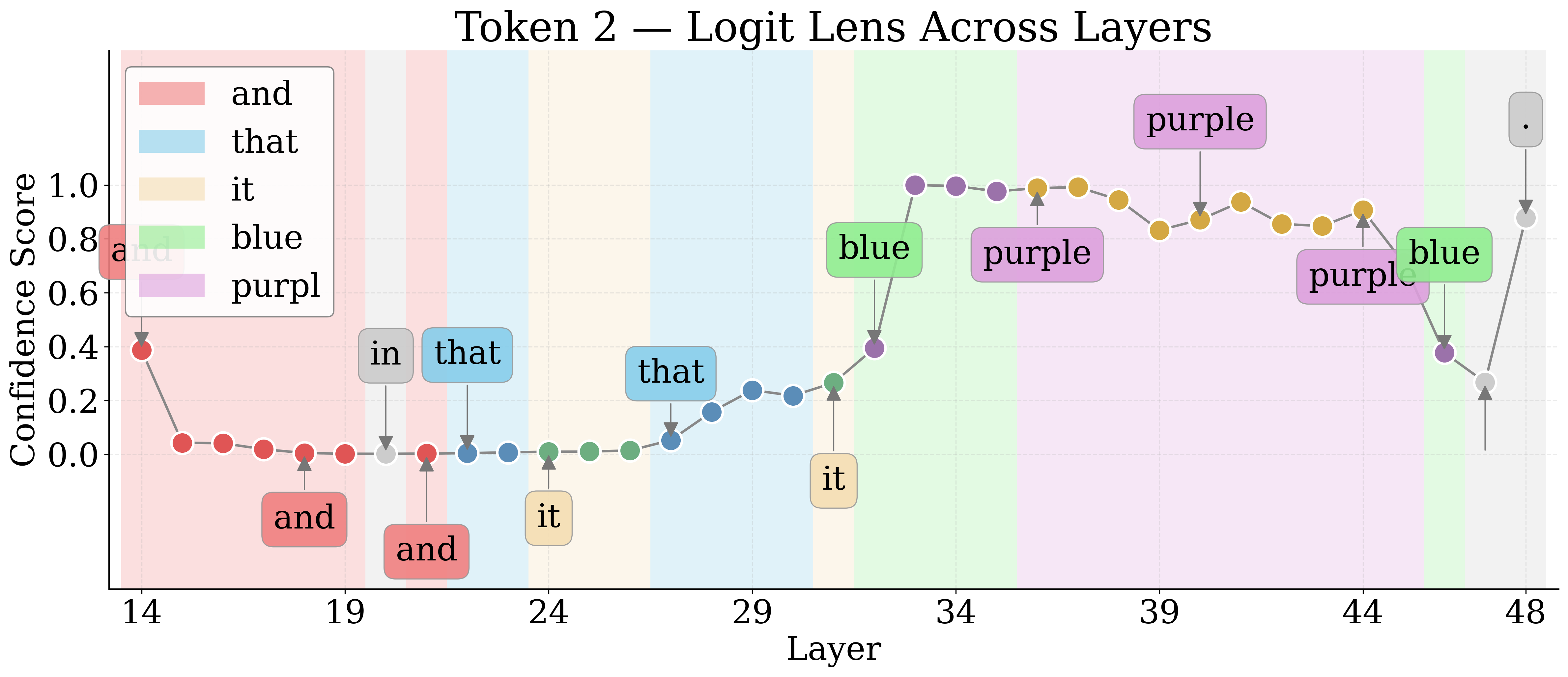
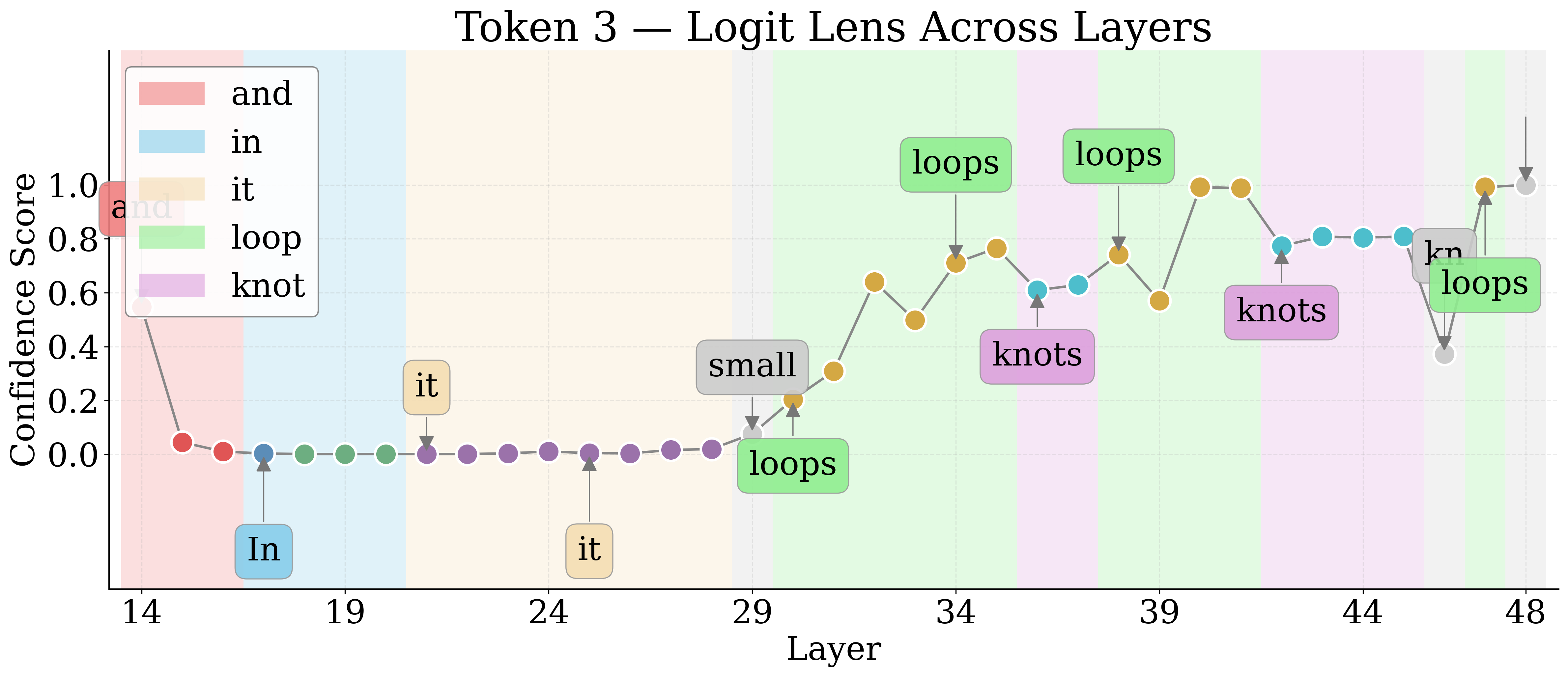
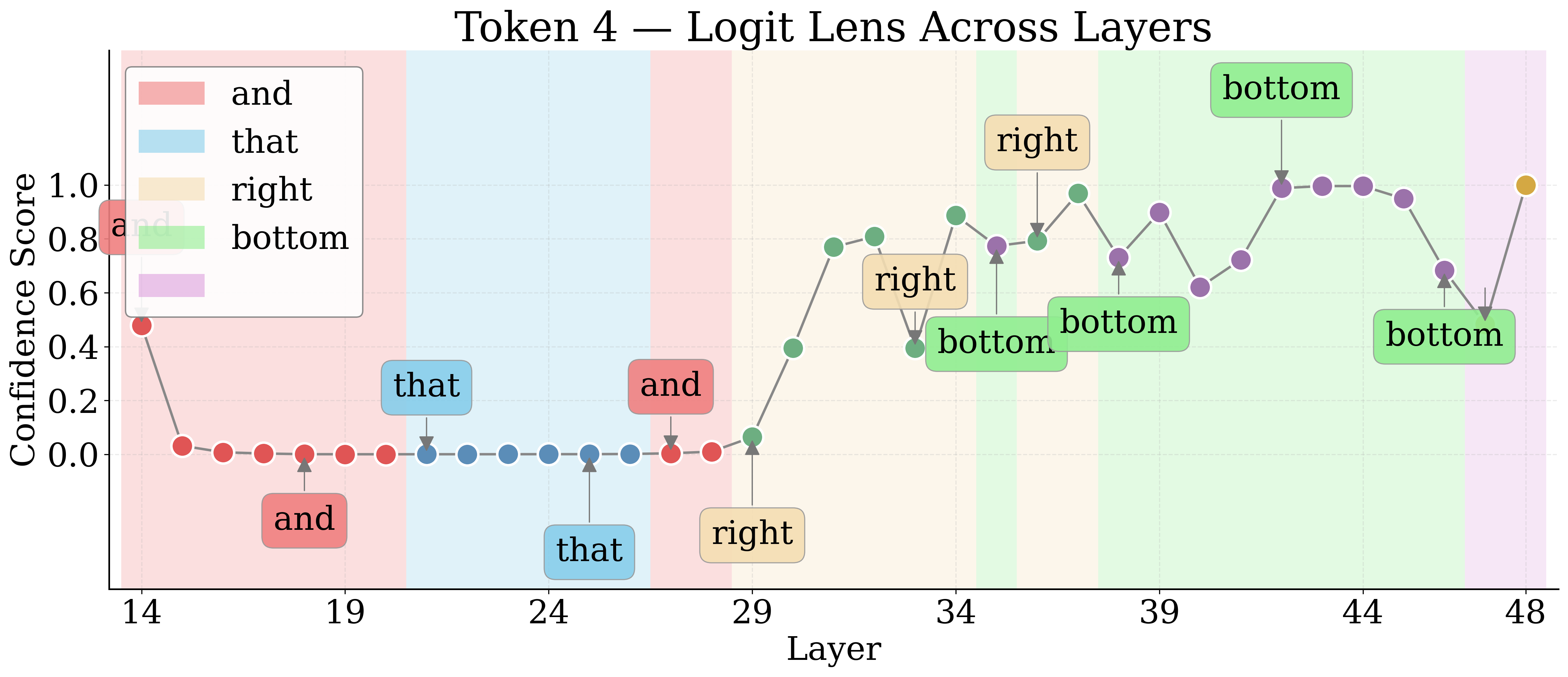
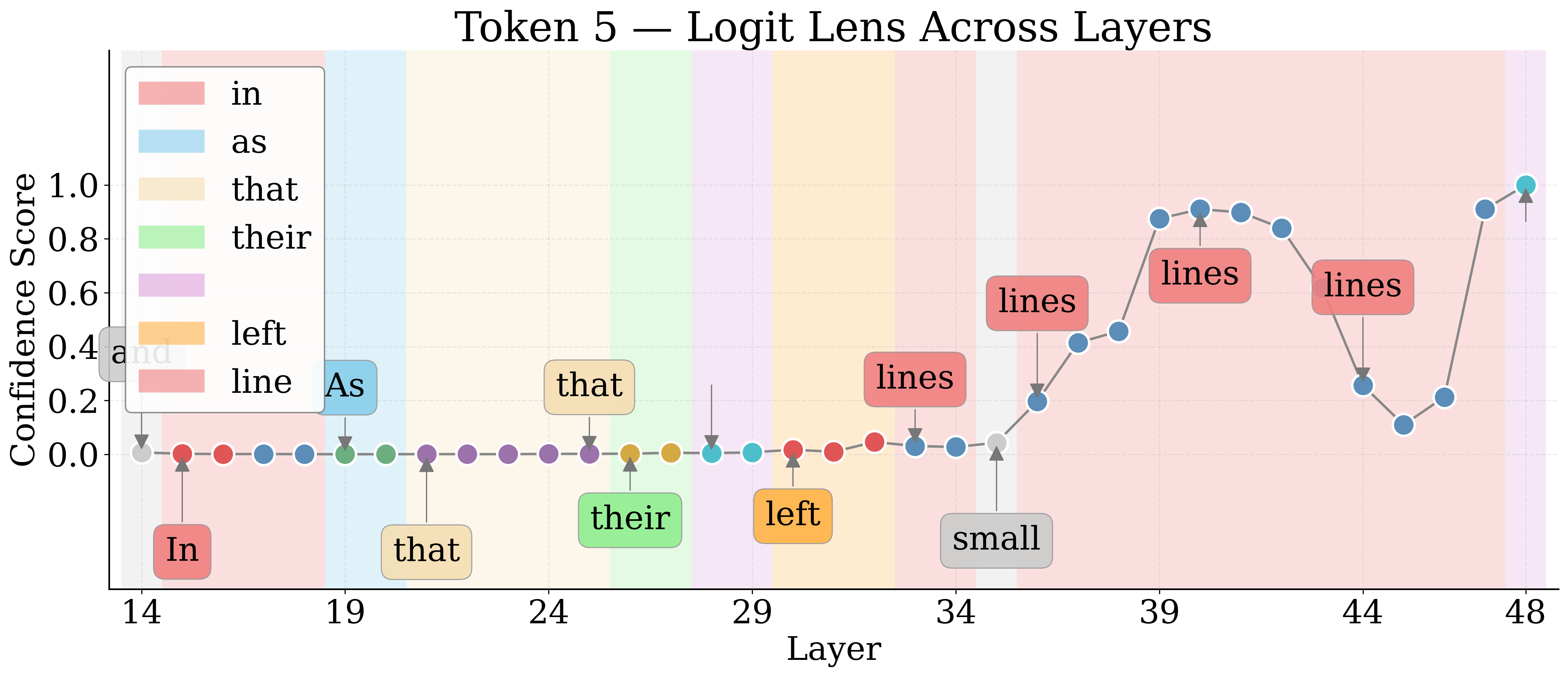
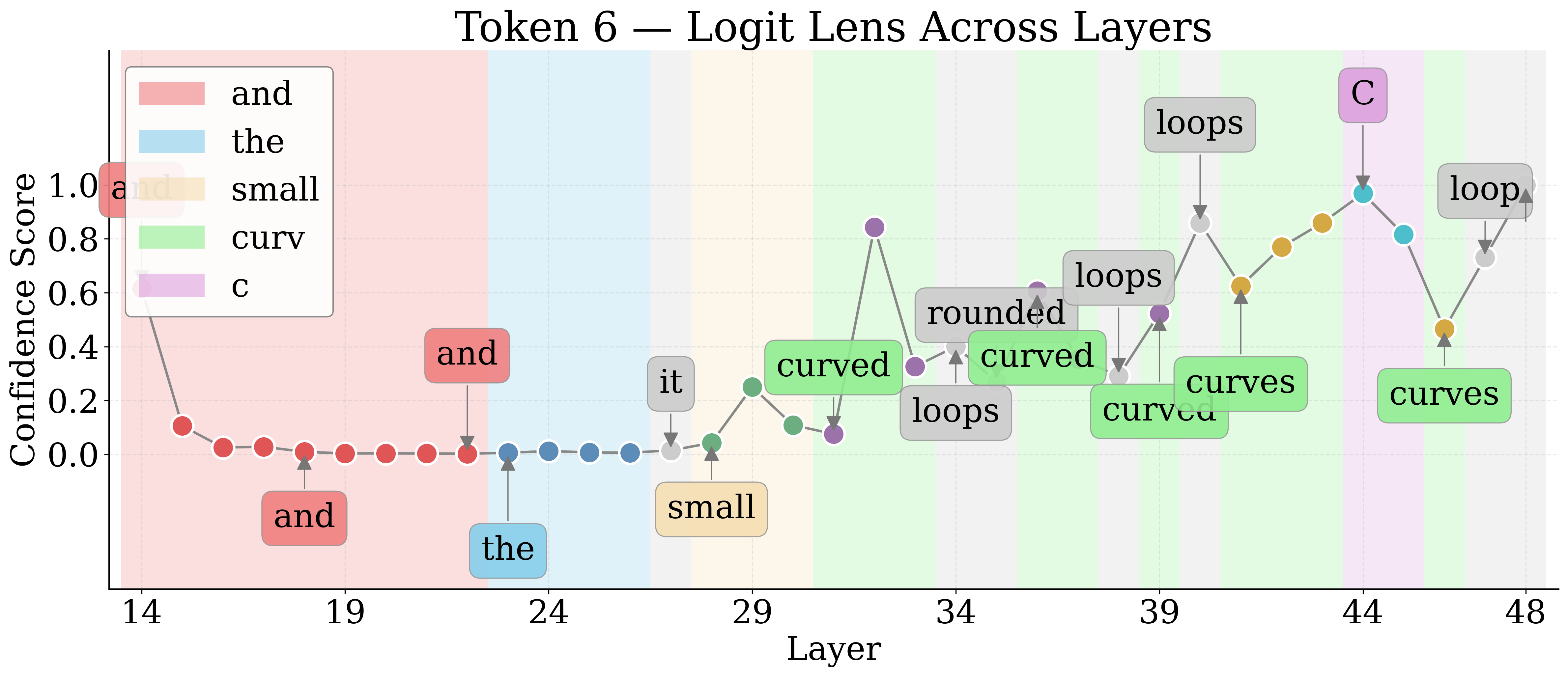
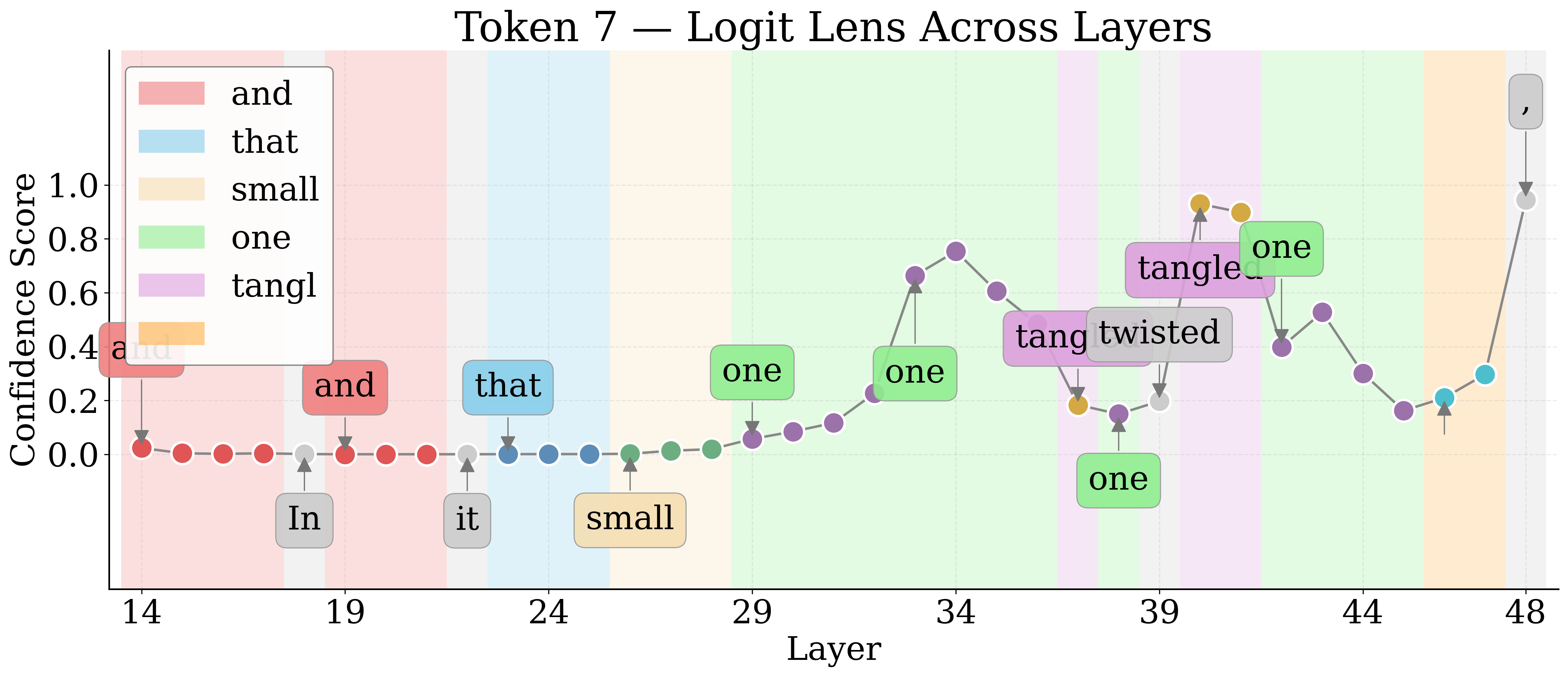
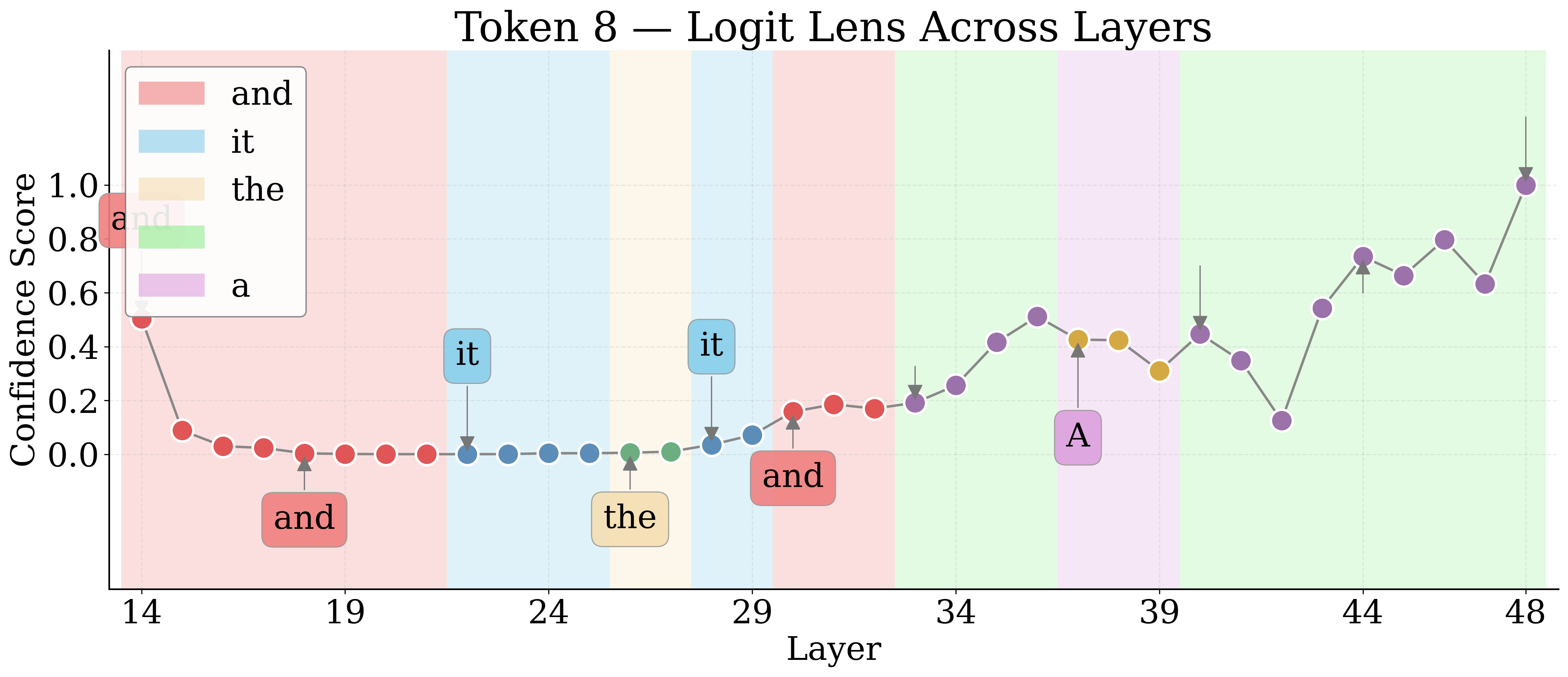
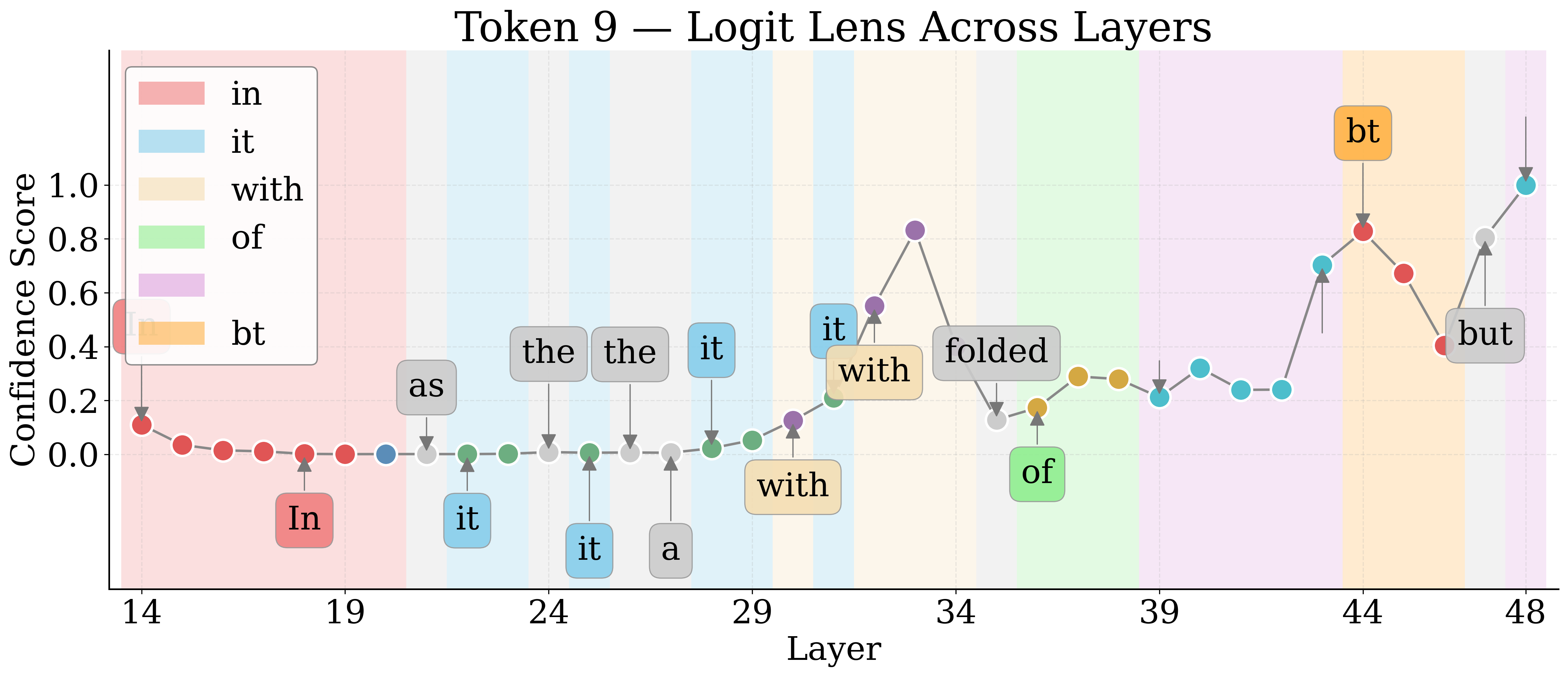
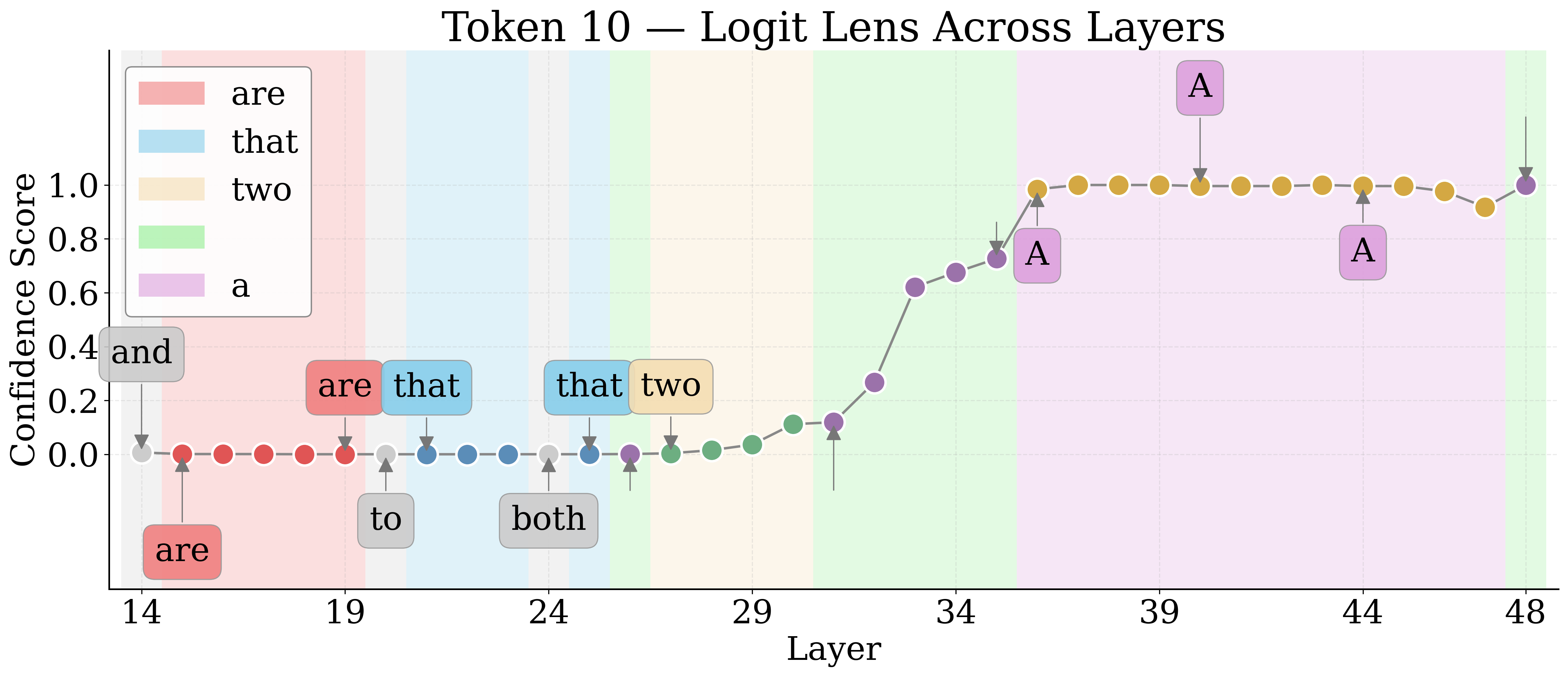
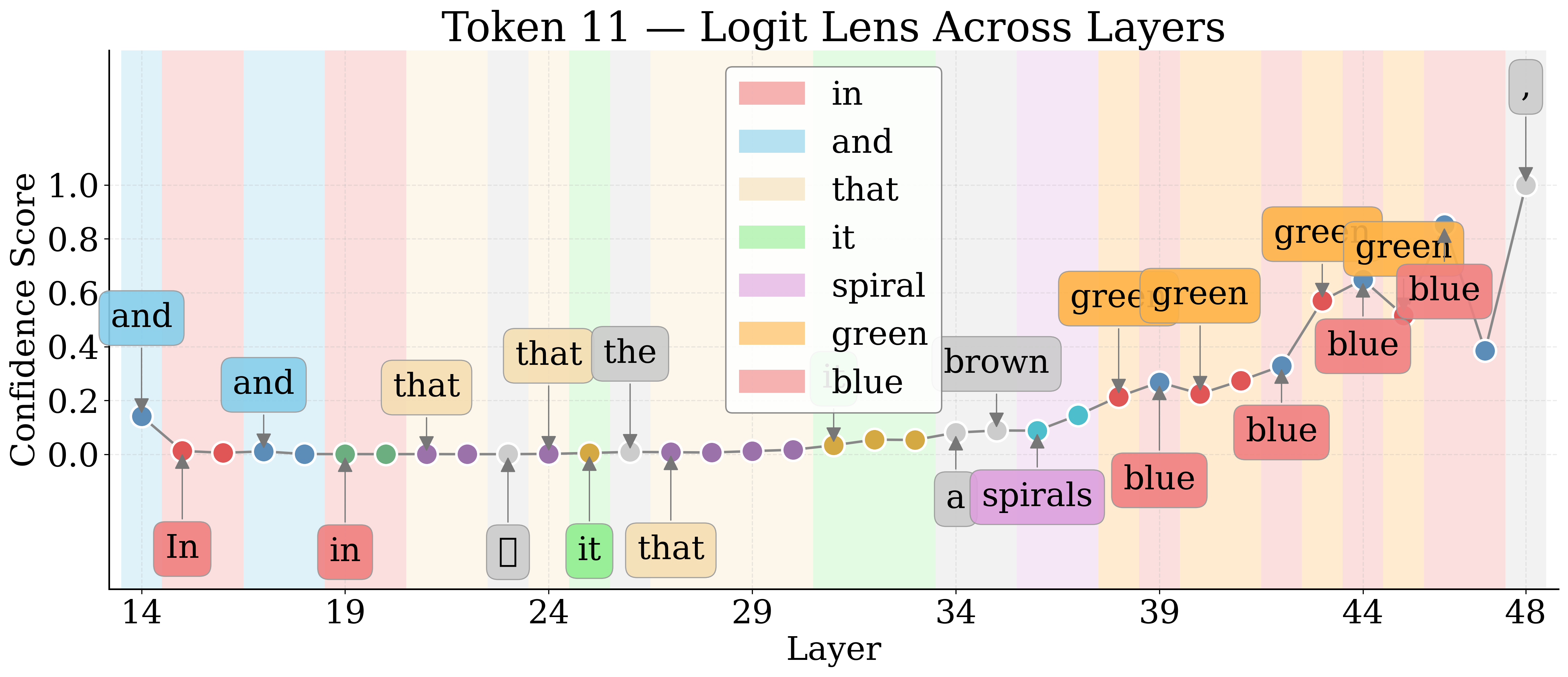
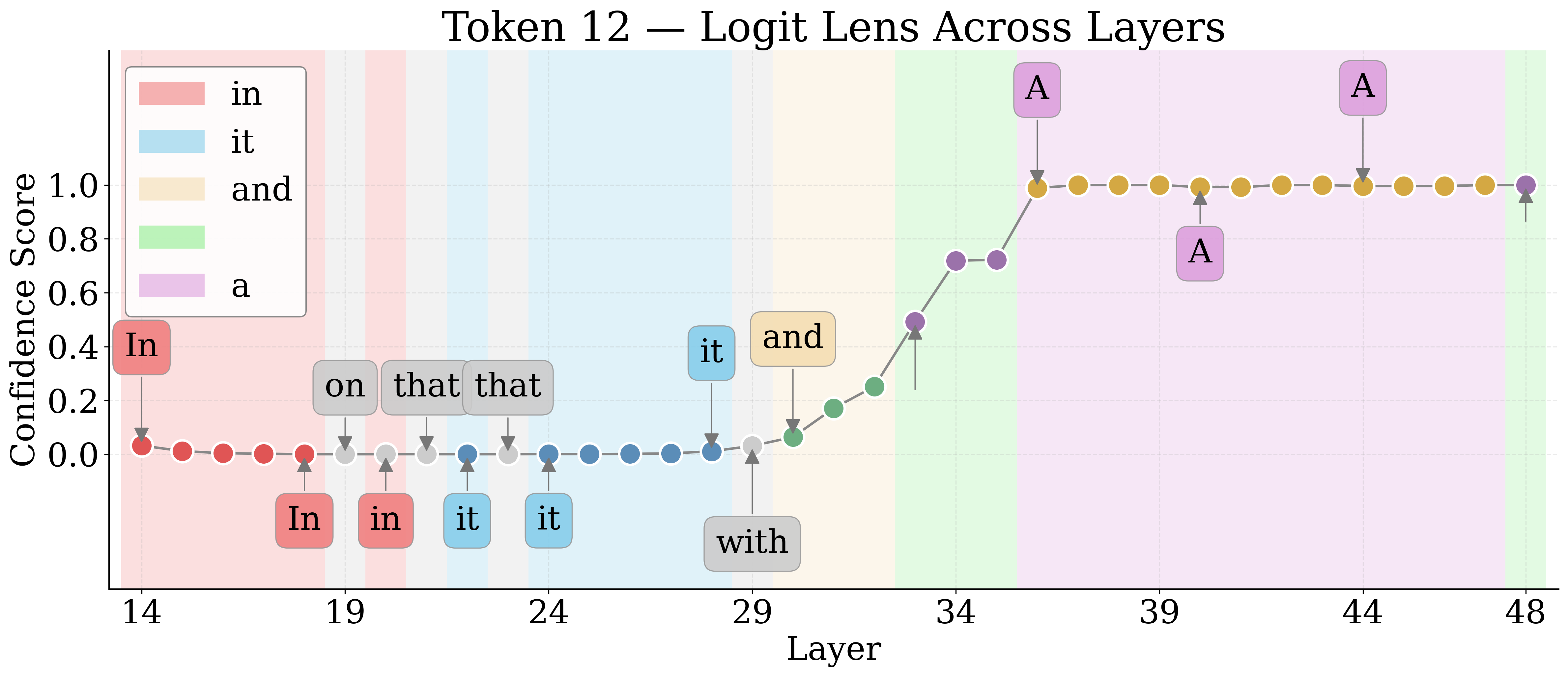
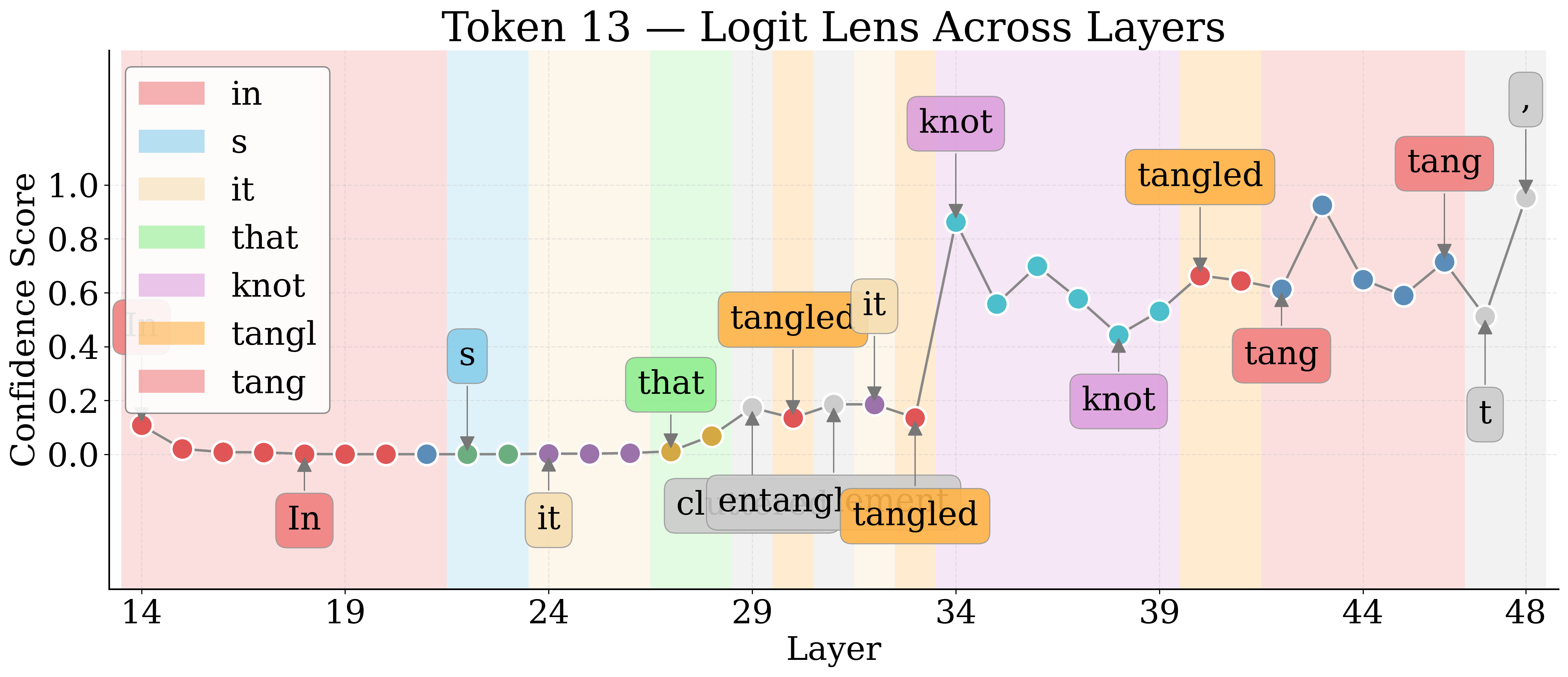
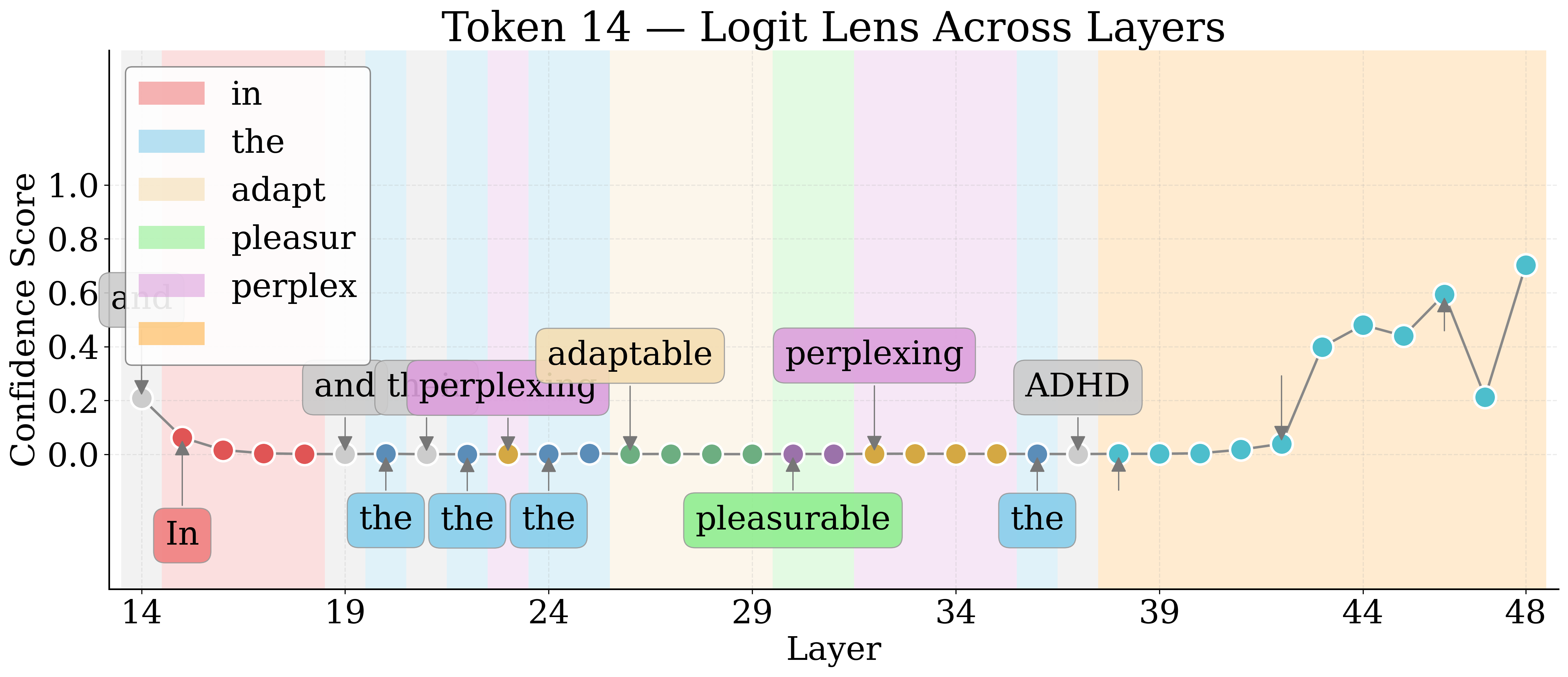
Figure 4: Layerwise Logit Lens tokens for an unknown shape—revealing the lack of semantic discernibility for unnameable entities.
Jaccard Distance between Logit Lens token sets quantifies semantic discernibility. Known entities yield higher distances, confirming more unique semantic tokens relative to unknowns.
Teaching Arbitrary Names and Task-Specific Finetuning
The paper demonstrates that teaching VLMs arbitrary names for unknown shapes—be they ordinary, human, or random strings—increases VQA accuracy and closes the semantic discernibility gap.
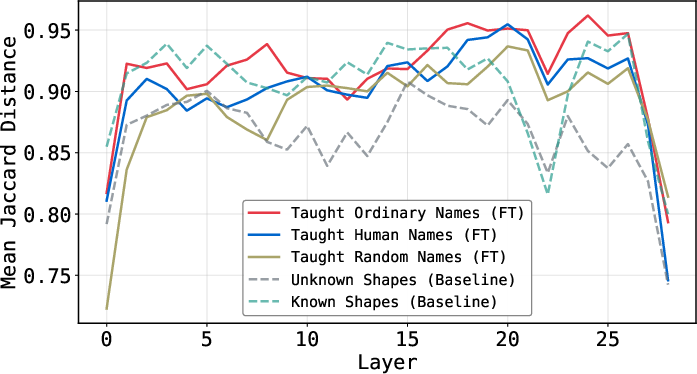
Figure 5: VQA accuracy on shape correspondence after learning arbitrary names; finetuned models close the performance gap.
Figure 6: Examples of generated squiggles for teaching arbitrary names.
Logit Lens confirms that semantic labeling via arbitrary names strengthens a linguistic shortcut; accuracy and the mean Jaccard Distance are positively correlated.
Direct Visual Comparison vs. Semantic Anchoring
Task-specific finetuning achieves even stronger generalization. When finetuned directly on visual correspondence tasks using one shape family (e.g., squiggles), models generalize to unseen shapes, including mazes—indicating the acquisition of genuinely transferable visual comparison skills that do not rely on semantic labeling.
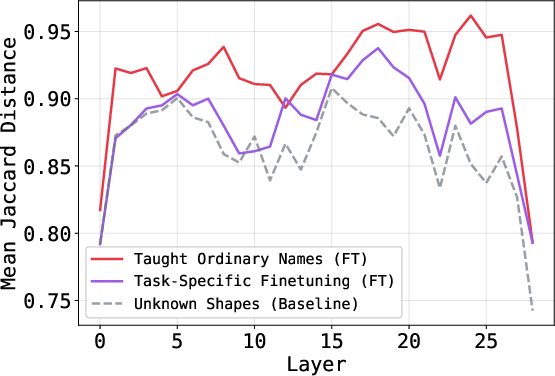
Figure 7: Near-perfect OOD generalization to unseen shapes and mazes following finetuning; accuracy degrades gracefully with complexity.
Notably, task-specific finetuning yields lower mean Jaccard Distance than teaching names, indicating less reliance on semantic anchors while achieving higher downstream accuracy. This substantiates the existence of two distinct mechanisms: semantic labeling is sufficient but not necessary for closing the gap between internal visual evidence and model output.
Implications and Future Directions
The findings challenge assumptions regarding the unimodal integration in VLMs. The prevailing pretraining and SFT paradigms induce shortcut behavioral patterns where language mediation supersedes pixel-level reasoning. This limits the utility of VLMs in domains with sub-semantic entities—medical imaging, anomaly detection, or abstract visual reasoning—unless explicit semantic annotation or task-specific supervision is available.
Theoretically, the results imply that the representation-output gap is not inherent to the underlying multimodal transformer architectures; rather, it arises from training objectives that encourage alignment of vision with language at the cost of fine-grained detail. Practically, adapting VLMs for vision-centric domains requires either advanced finetuning strategies that promote direct visual comparison or interventions that expand vocabulary and semantic grounding for novel entities.
Future work should focus on architectural and pretraining modifications to reduce reliance on semantic anchoring. Unsupervised visual reasoning objectives, enhanced patch-level probing, or multimodal contrastive learning targeting sub-semantic features may allow VLMs to operate efficiently at finer granularities. Mechanistic interpretability tools, such as Logit Lens, will be invaluable for tracking model evolution across layers and isolating semantic-vs.-visual circuits. Benchmarking future VLMs on systematically controlled correspondence tasks is essential for diagnosing learned shortcuts and ensuring general-purpose multimodal reasoning.
Conclusion
The paper establishes that current VLM failures in visual discrimination tasks stem from a learned shortcut favoring semantic anchoring—mapping visual entities to language whenever possible. Performance markedly improves for nameable entities, while representation probing confirms that internal visual features remain available even when output fails. Teaching arbitrary names and direct task finetuning demonstrate that language mediation is not fundamentally required for high performance, suggesting VLMs can acquire pixel-level skills if the training regime permits. These insights call for reconsideration of VLM training standards to support genuinely multimodal, vision-driven reasoning in future AI systems.