- The paper introduces Active-Look, an adaptive verification mechanism that mitigates object-existence hallucinations via dual-expert conflict-driven evidence selection.
- The methodology employs a Think-with-Images paradigm using zoom-in and highlight operators to balance global context with local detail for scale-dependent efficiency.
- Experimental results show improved accuracy (up to +4.94%) and significant reductions in hallucination metrics across benchmarks in large vision-language models.
Adaptive Visual Grounding for Hallucination Mitigation in LVLMs: A Technical Essay
Introduction
The paper "Global Context or Local Detail? Adaptive Visual Grounding for Hallucination Mitigation" (2604.24396) addresses the persistent object-existence hallucination problem in Large Vision-LLMs (LVLMs). Traditional LVLMs encode images in a single, static pass, decoupling subsequent multimodal reasoning from the evolving visual evidence. This leads to model-generated outputs referencing objects or attributes that are visually absent. The paper proposes an adaptive verification paradigm—Active-Look—built on Think-with-Images (TwI) strategies, allocating visual computational resources dynamically according to uncertainty via dual expert grounding and selective evidence rendering.
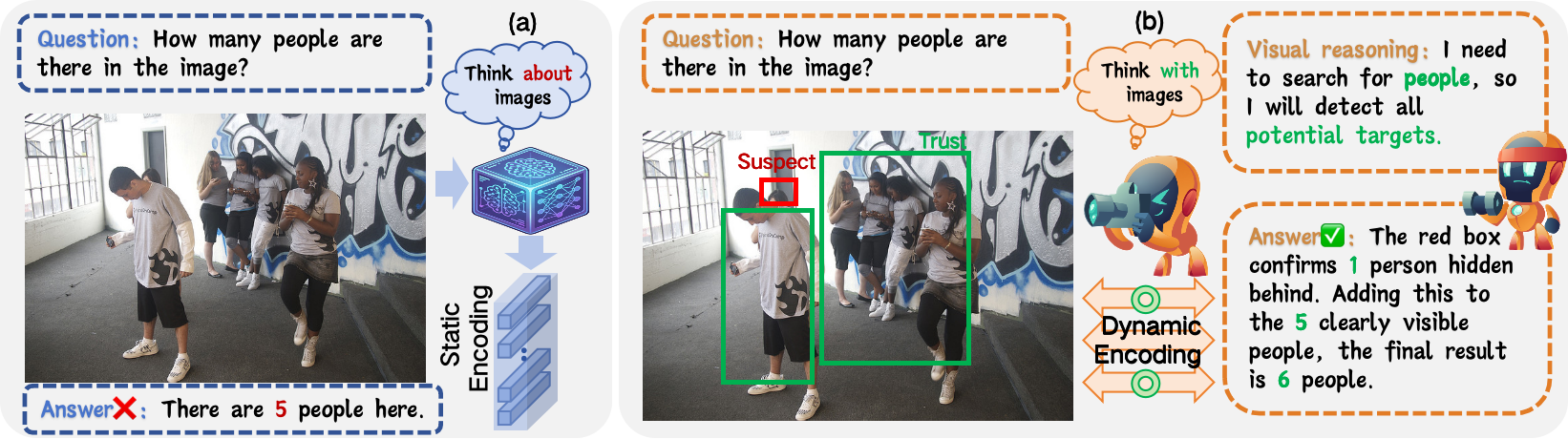
Figure 1: (a) Static image encoding in traditional LVLMs; (b) Active-Look transforms the image into a real-time observation object, generating auxiliary visual inputs for enhanced reasoning.
Think-with-Images Paradigm and Failure Modes
TwI reframes inference as budgeted active visual evidence acquisition, iteratively generating auxiliary views (highlight, zoom-in) of regions of interest through proposal-selection-render cycles. The two principal operators reveal a granularity-context trade-off: zoom-in enhances detail but disrupts global context, while highlight retains topology but often lacks the necessary resolution for small or ambiguous targets.
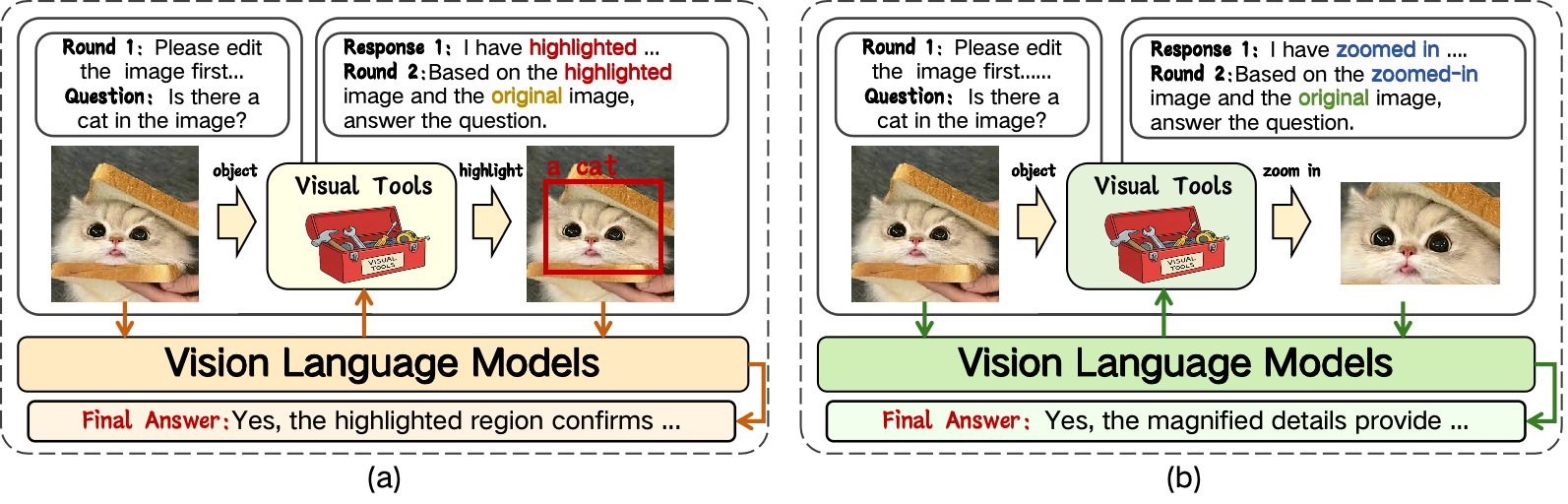
Figure 2: Highlight operator preserves global context; zoom-in increases detail but removes context.
Empirical diagnosis shows TwI’s effectiveness is scale-dependent: zoom-in is beneficial for small objects, highlight for large ones. Critically, TwI is fragile under noisy proposals—erroneous region selection leads to over-trust, where misguided evidence can dominate reasoning, degrading performance below static prompting baselines.
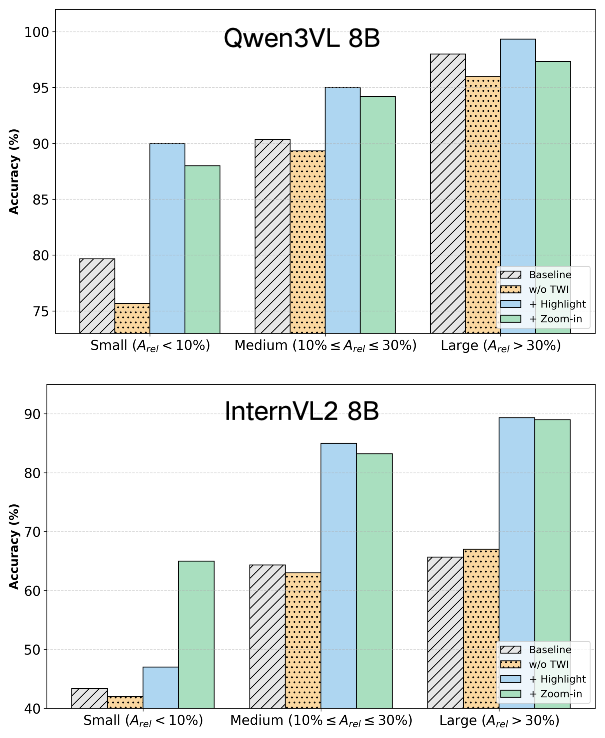
Figure 3: Operator performance varies by object scale, showing the bifurcation in TwI gains.
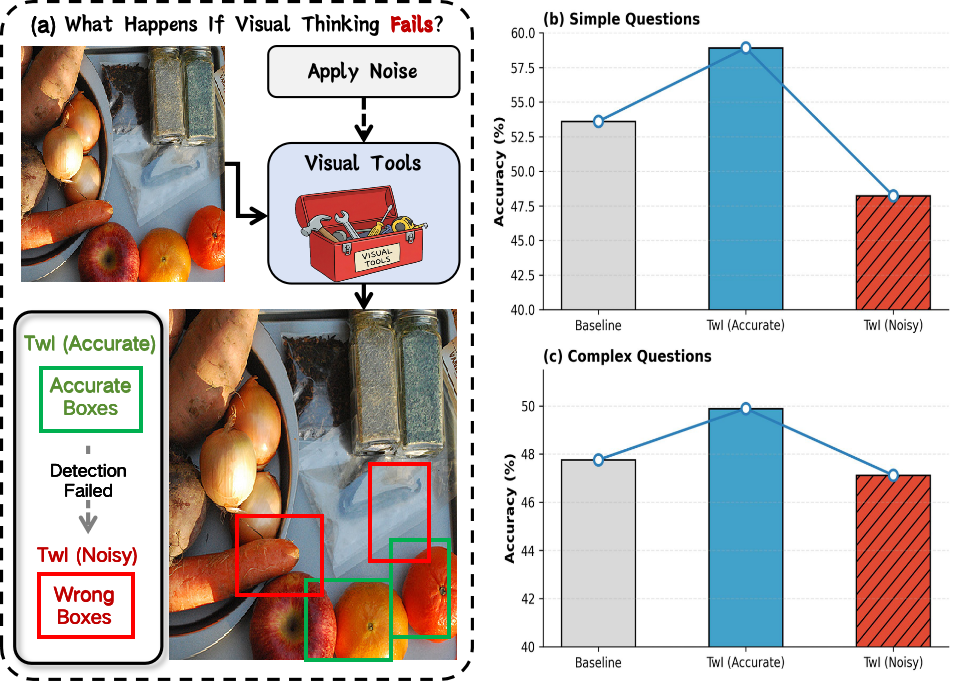
Figure 4: Impact of proposal noise—InternVL2-8B suffers performance drops on TallyQA when region guidance is unreliable.
Active-Look: Conflict-Driven Evidence Verification
Active-Look implements a robust TwI instantiation, utilizing dual heterogeneous grounding experts (e.g., GroundingDINO, OWLv2) for proposal generation, and consensus arbitration for evidence selection. Cross-expert disagreement provides a principled proxy for answer uncertainty, triggering selective verification only for ambiguous regions. Hybrid rendering combines global highlighting with targeted zoom-in according to the allocated budget, maintaining compositional integrity while resolving local granularity.
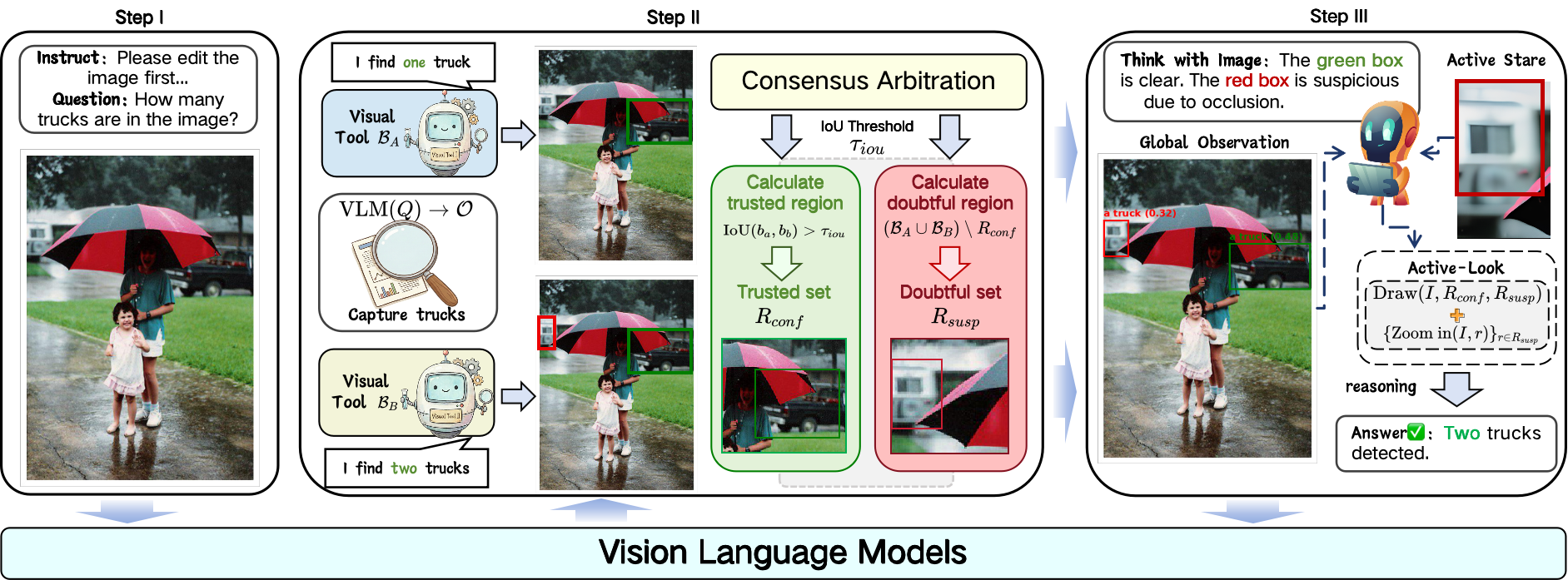
Figure 5: Active-Look overview: dual proposals feed into arbitration that partitions regions for global context and local verification.
Algorithmically, Active-Look decomposes the process as follows:
- Hypothesis-driven perception extracts visual targets and proposals from both experts.
- Consensus partitioning (IoU-based) separates trusted from doubtful regions, with budget prioritization for verification.
- Hybrid rendering generates multi-view evidence: highlighted scene and zoomed-in crops of suspicious regions.
- Multi-view inference conditions the LLM on both global and verified local embeddings for final response generation.
Experimental Evaluation
Active-Look is validated on standard hallucination and multimodal reasoning benchmarks, including POPE, MME, and CHAIR, encompassing binary existence queries, attribute reasoning, spatial relationships, and captioning. Through controlled ablations, Active-Look is demonstrated to consistently outperform baselines and prior mitigation methods (VCD, OPERA, VAF), both in hallucination suppression and recall enhancement.
Strong numerical results include:
- On POPE, Active-Look improves accuracy and F1 across all tested backbones, e.g., +4.45% accuracy on LLaVA-7B, +4.94% on Qwen3-VL-8B.
- MME results reveal significant gains in count and position subtasks, validating enhanced fine-grained perceptual reasoning.
- CHAIR evaluations indicate marked reductions in sentence/object-level hallucinations (e.g., CS drop from 53.0 to 15.0 for LLaVA-1.5-7B).
- Ablations confirm the necessity of conflict-aware arbitration; naive proposal union leads to increased false positives and lower accuracy.
Case Studies and Interpretability
Three archetypal regimes are illustrated:
- High-confidence validation: proposals align with visual evidence, yielding efficient corroboration.

Figure 6: Case I—confirmation of a baseball bat with strong tool-grounding; model validates efficiently.
- Ambiguity resolution: selective zoom-in converts detector uncertainty into decisive true positives.

Figure 7: Case II—ambiguous suspect region for “person” is resolved with zoom-in, boosting recall.
- Noise rejection: verification filters false positives, suppressing hallucinations.

Figure 8: Case III—spurious “person” proposal over a chair is rejected after local inspection.
Trigger analysis shows conflict-driven verification is concentrated on problematic samples (conflict partition error rate nearly 3x consensus samples), supporting the efficiency claims.
Parameter Sensitivity and Scalability
Parameter sweeps indicate that increasing zoom-in scale improves accuracy and F1, and consensus IoU thresholds have a well-defined optimal range, balancing over-merging against over-splitting. Results on larger LVLM backbones (InternVL2-14B, Qwen3-VL-32B) confirm Active-Look’s persistent gains, distinguishing its efficacy from mere scaling of backbone capacity.
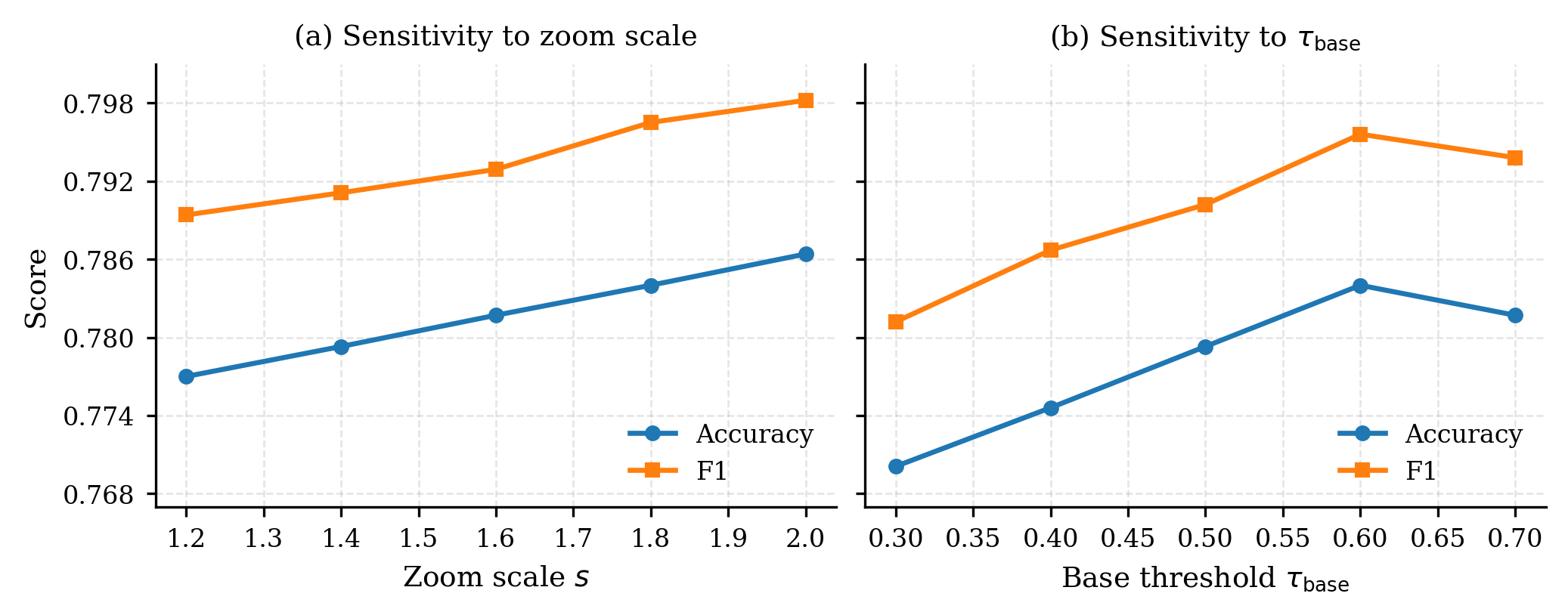
Figure 9: Sensitivity analysis—zoom-in scale and IoU threshold impact on accuracy and F1.
Practical and Theoretical Implications
Active-Look delivers inference-time hallucination mitigation in a plug-and-play, training-free manner. It is compatible with diverse LVLM architectures and external grounding tools. The framework circumvents the single-pass encoding bottleneck, redistributing visual attention dynamically and efficiently. Theoretically, it operationalizes uncertainty-driven verification, positioning consensus/arbitration as a mechanism for robust multimodal reasoning.
From a practical deployment perspective, Active-Look trades controlled computational overhead for improved reliability. Verification is triggered on disagreement, localizing extra computation to challenging inputs. This renders the system scalable and efficient compared to uniform proposal/exhaustive cropping.
The paper acknowledges limitations: dependency on grounding expert recall, focus on visual token economy (not latency), and current optimization for object existence and attribute verification. Extending arbitration to spatial and temporal domains is proposed as a future direction.
Conclusion
"Global Context or Local Detail? Adaptive Visual Grounding for Hallucination Mitigation" presents mechanistically grounded diagnoses of TwI in LVLMs, revealing scale-dependent efficacy and over-trust failures under proposal noise. Active-Look, via dual-expert conflict-driven evidence verification and hybrid rendering, achieves robust hallucination mitigation. The approach is numerically validated across multiple benchmarks and model scales, reinforcing dynamic, budgeted visual grounding as an essential inference-time protocol for reliable multimodal reasoning. Further work on end-to-end active perception and broader reasoning tasks is anticipated to extend the paradigm.