Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training
Abstract: LLMs, despite being trained on text alone, surprisingly develop rich visual priors. These priors allow latent visual capabilities to be unlocked for vision tasks with a relatively small amount of multimodal data, and in some cases, to perform visual tasks without ever having seen an image. Through systematic analysis, we reveal that visual priors-the implicit, emergent knowledge about the visual world acquired during language pre-training-are composed of separable perception and reasoning priors with unique scaling trends and origins. We show that an LLM's latent visual reasoning ability is predominantly developed by pre-training on reasoning-centric data (e.g., code, math, academia) and scales progressively. This reasoning prior acquired from language pre-training is transferable and universally applicable to visual reasoning. In contrast, a perception prior emerges more diffusely from broad corpora, and perception ability is more sensitive to the vision encoder and visual instruction tuning data. In parallel, text describing the visual world proves crucial, though its performance impact saturates rapidly. Leveraging these insights, we propose a data-centric recipe for pre-training vision-aware LLMs and verify it in 1T token scale pre-training. Our findings are grounded in over 100 controlled experiments consuming 500,000 GPU-hours, spanning the full MLLM construction pipeline-from LLM pre-training to visual alignment and supervised multimodal fine-tuning-across five model scales, a wide range of data categories and mixtures, and multiple adaptation setups. Along with our main findings, we propose and investigate several hypotheses, and introduce the Multi-Level Existence Bench (MLE-Bench). Together, this work provides a new way of deliberately cultivating visual priors from language pre-training, paving the way for the next generation of multimodal LLMs.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explores a surprising idea: big text-based AI models (called LLMs, or LLMs) can learn a lot about how the visual world works just by reading text, even if they never see a single picture during training. The authors call this hidden knowledge “visual priors.” Later, when you connect these models to an image encoder (like giving them “eyes”) and do a small amount of training with images, the models can do visual tasks very well—and sometimes they can even handle visual logic without any images at all.
What questions did the researchers ask?
The paper asks simple but deep questions:
- What kinds of “visual knowledge” do LLMs pick up from text alone?
- Where does this knowledge come from—what kinds of text help most?
- Is this visual knowledge one big skill, or a mix of different abilities?
- How can we design better training recipes to build LLMs that are strong at both language and vision?
- How do these abilities transfer when you add different “eyes” (vision encoders), and how much does extra image-based training matter?
How did they study it?
Think of the process like training a student in stages:
- Pre-training on text:
- The team trained LLMs of various sizes (from about 340 million to 13 billion parameters) on huge amounts of text (from 0 to 1 trillion tokens). Tokens are like word pieces.
- The text came from 16 sources (like code, math, literature, web pages, and encyclopedias).
- Connecting “eyes” and aligning vision:
- They attached a frozen vision encoder to the LLM and used a small neural “adapter” to align image features with the LLM. This is like teaching the student how to understand what the eyes are sending to the brain.
- Instruction tuning with images and text:
- They fine-tuned the combined model with a curated mix of image–text and text-only instructions so it could follow multimodal directions well.
- Testing on many benchmarks:
- They tested across 16 public benchmarks grouped into four types:
- General visual tasks: basic perception plus common sense
- Knowledge-heavy tasks: science/math problems that involve images
- OCR and charts: reading text in images and understanding charts
- Vision-centric tasks: spatial thinking, object counting, and visual IQ-like puzzles
- They tested across 16 public benchmarks grouped into four types:
- Special analyses:
- They compared how image features and text features line up statistically (like checking whether the AI groups similar images and similar descriptions in similar ways).
- They ran over 100 controlled experiments (about 500,000 GPU hours) to isolate exactly what causes improvements.
Technical terms explained in everyday words:
- LLM: A powerful text predictor trained on huge amounts of writing.
- Visual prior: Hidden visual understanding learned from text alone—like learning what “a red ball on a table” probably looks like from descriptions.
- Vision encoder: The “eyes” of the system that turn images into features the model can understand.
- Instruction tuning: Extra training that teaches the model to follow directions and answer questions in a helpful way.
What did they find?
Here are the main findings, explained simply:
1) Visual skills split into two parts: perception and reasoning
- Perception prior: The ability to notice and read details in images (like recognizing objects, colors, or text in pictures).
- Reasoning prior: The ability to think logically about what’s in an image (like solving puzzles, doing math or science questions with diagrams, and understanding spatial relationships).
- These two abilities are partly independent. Getting better at one doesn’t automatically make the other equally better.
2) Where each prior comes from
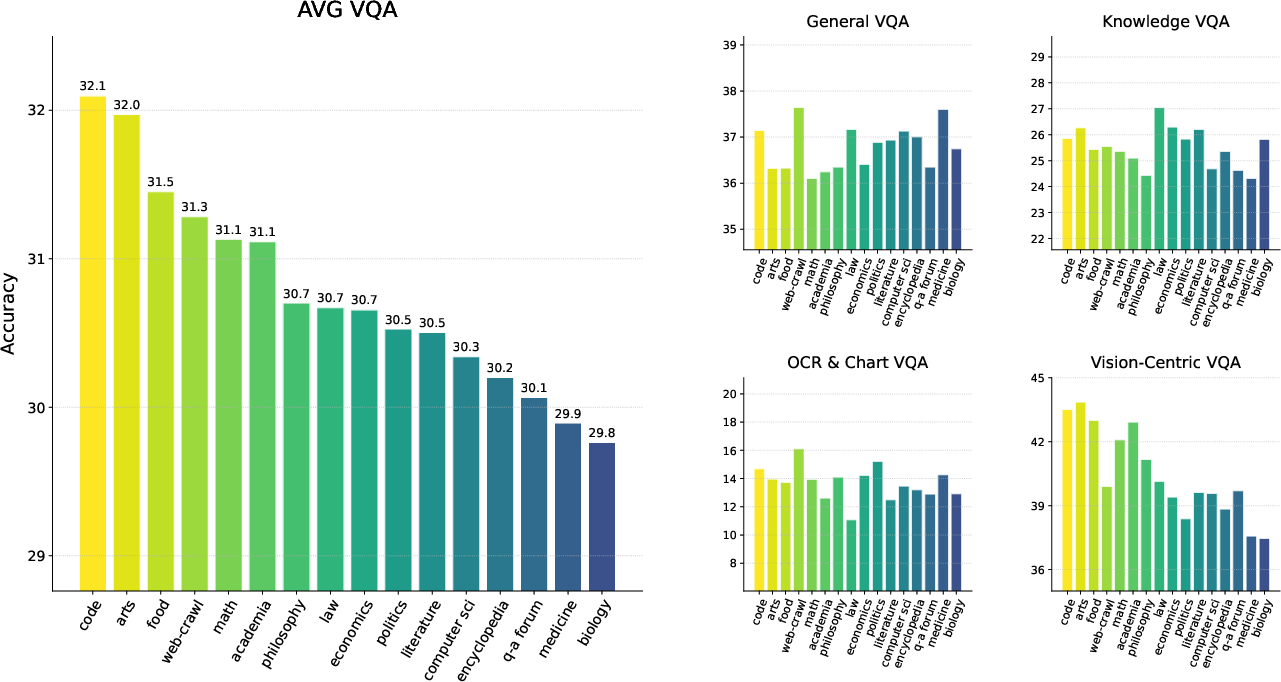
- Reasoning prior mainly comes from “reasoning-centric” text, such as code, math, and academic writing. The more of this kind of text the model reads, the better it gets at visual reasoning—even before seeing images.
- Perception prior comes more diffusely from large, diverse text (like web pages) that includes lots of everyday descriptions of the visual world. It’s less tied to any single category of text.
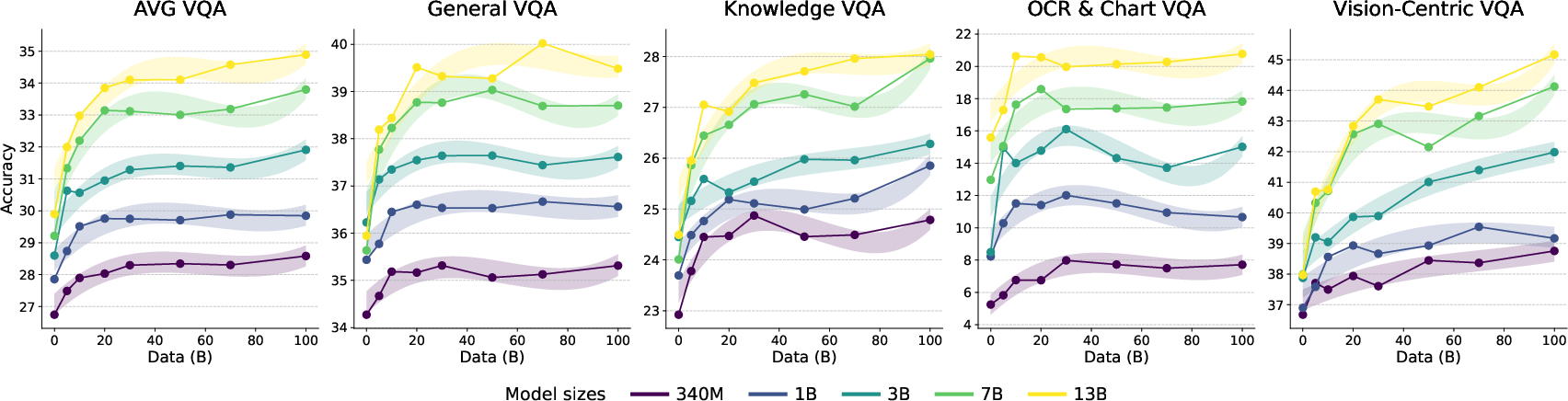
3) Bigger models + more data usually help, but not equally for all skills
- Making models larger and feeding them more text generally improves performance, but different visual tasks scale differently:
- Knowledge and general tasks improve smoothly with more size and data.
- OCR and chart reading are more sensitive to model size than just more data.
- Vision-centric reasoning shows especially strong gains for the largest models when trained on more data.
4) The right training mix matters
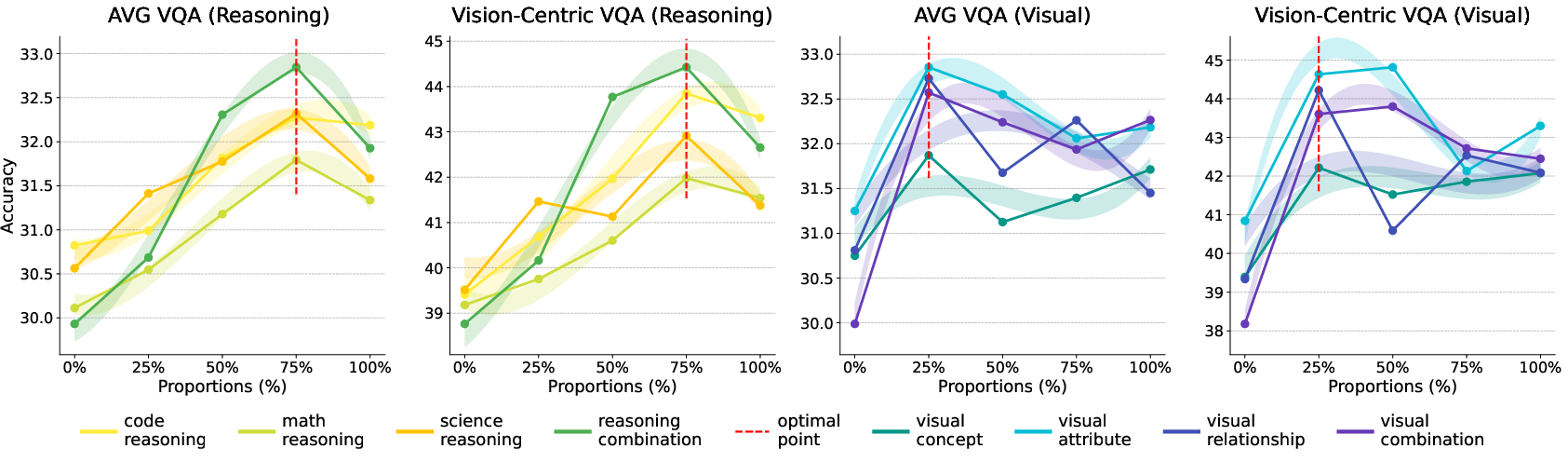
- A small amount of text that explicitly describes the visual world helps early, but its benefits saturate quickly.
- Increasing reasoning-centric text keeps helping visual reasoning and continues to pay off up to around 75% of the mix.
- Through grid searches, a mix around 60% reasoning and 15% visual-world text worked best for vision tasks.
- The best balanced recipe they found (called “mix6”) improved vision ability while keeping strong language skills.
5) Reasoning prior is universal; perception depends more on the “eyes” and extra vision training
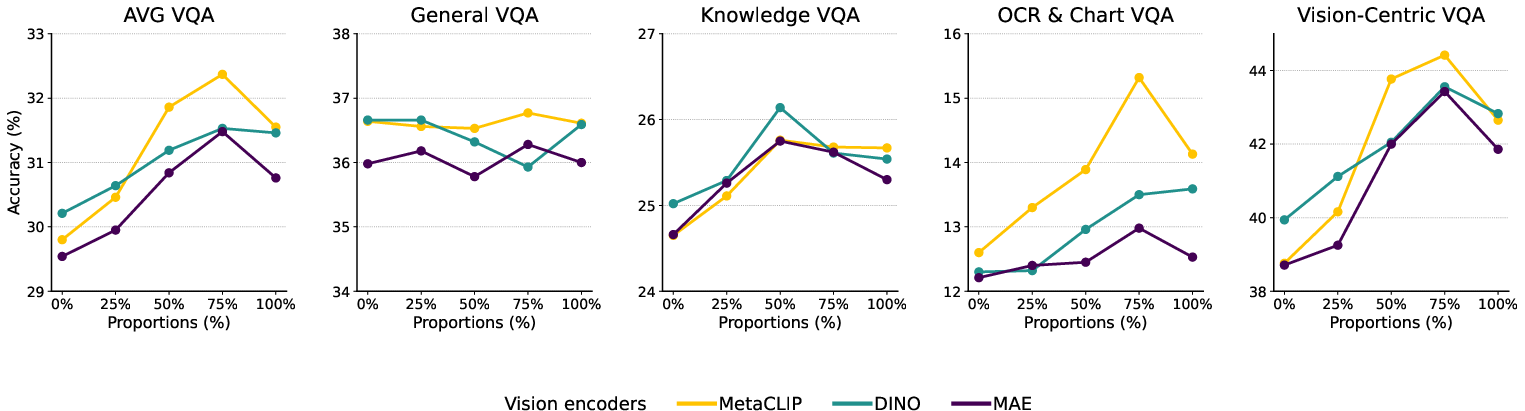
- The visual reasoning skills learned from text transfer across different vision encoders. That means this prior is robust and general.
- Perception performance varies more with which vision encoder you use and how much image-based instruction tuning you do. Removing perception-focused image instructions causes larger drops in perception-heavy tasks than removing reasoning-focused ones.
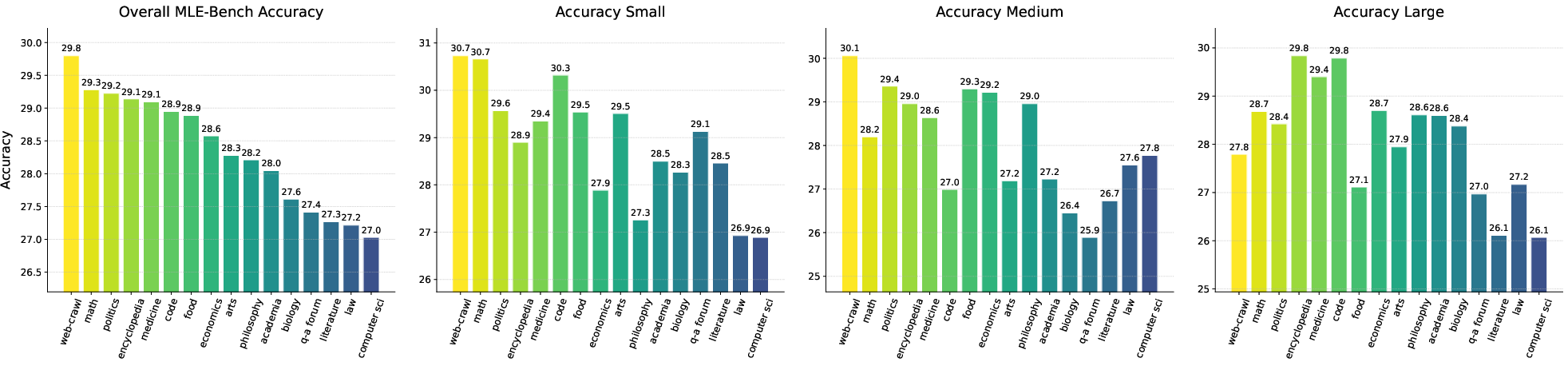
6) New benchmark: MLE-Bench
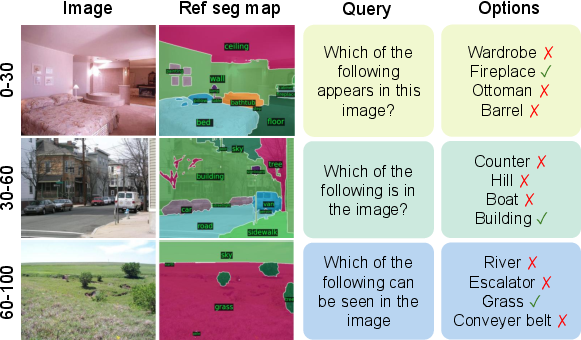
- They introduced the Multi-Level Existence Bench (MLE-Bench), which tests whether a model can tell if an object exists in an image across different object sizes (small, medium, large).
- Results suggest the perception prior from diverse text is especially helpful for recognizing smaller and medium-sized objects.
Why does this matter?
Simple impacts and implications:
- Better multimodal AI without massive image training: If LLMs can learn visual logic from text, we can build strong vision-LLMs more efficiently, saving time and computing power.
- Smarter training recipes: This paper provides a data-centric blueprint—use lots of reasoning-focused text plus a smaller amount of visual-world descriptions—to grow an LLM that adapts quickly to vision tasks.
- Clearer understanding of “world models”: The results support the idea that as models get powerful, they learn a shared internal model of reality from different “projections” (text and images). This is related to the “Platonic Representation Hypothesis.”
- Practical guidance: If you want a model that reads charts and text in images, focus on perception tuning and the choice of vision encoder. If you want a model that solves visual puzzles or science problems, heavily include reasoning-centric text in pre-training.
- New tools for the community: MLE-Bench helps researchers test fine-grained perception; “blind visual instruction tuning” is a useful trick to probe and improve visual adaptation.
In short, the paper shows that language-only training can plant strong seeds of visual understanding. With the right data mix and a little image-based tuning, those seeds grow into powerful multimodal skills. This could make the next generation of AI models more capable, cheaper to train, and better at understanding the world across both text and images.
Knowledge Gaps
Below is a single, actionable list of the paper’s knowledge gaps, limitations, and open questions that remain unresolved.
- Causal identification of priors: The paper largely reports correlations (e.g., between reasoning-heavy pre-training and visual reasoning performance) without causal tests; interventions that isolate and manipulate only the hypothesized causal factor (e.g., counterfactual data swaps, synthetic controlled corpora) are needed to establish causality.
- Noise in data categorization: The reasoning/visual-world labels are assigned by a 32B LLM on 1024-token segments; the paper does not quantify label accuracy, inter-rater reliability, or the impact of misclassification on downstream results.
- Generality across architectures: All core results are based on decoder-only Transformers (Llama-3–like); the paper does not assess whether findings hold for encoder-decoder, MoE, retrieval-augmented, or hybrid multimodal architectures.
- Tokenizer and context length effects: A single tokenizer (~32k vocab) and 2048 context length are used; the sensitivity of visual priors to tokenization choices, longer contexts, or subword vs. byte-level tokens is unexplored.
- Limited exploration of pre-training scale: While the abstract mentions results up to 1T tokens, the main analyses and grids are centered on 30–50B tokens; systematic scaling laws for visual priors beyond 100B and at 1T are not presented.
- Stability and variance: All experiments fix seed=42 and report point estimates; the paper does not provide variance across runs, confidence intervals, or statistical significance, making robustness and reproducibility uncertain.
- Confounds in data mixtures: Mixture grids emphasize proportions but not dataset quality (duplication, contamination, topical skew, readability); the role of data cleanliness and deduplication on priors is not isolated.
- Saturation of “visual-world” text: The paper claims rapid saturation of visual-world text benefits; whether this saturation persists at larger LLM scales, with higher-quality visual descriptions, or under different instruction-tuning curricula remains open.
- Parsing and evaluation bias: The “robust parsing strategy” for free-form VQA answers is placed in the appendix and not validated; risks remain that language priors “hack” evaluation (answer formatting shortcuts) rather than reflecting genuine perception.
- Benchmark coverage: VQA-heavy evaluation may conflate language recall with perception; the paper does not include controlled, perception-only tasks free of textual priors (e.g., forced-choice with minimal text, occlusion/perturbation stress tests).
- Alignment metrics: LLM–vision alignment is assessed via mutual nearest neighbors on WIT; results are not compared to other metrics (e.g., CKA, SVCCA, CCA) nor linked to downstream performance via predictive or causal analyses.
- Vision encoder sensitivity: Perception priors vary across MetaCLIP/DINOv2/MAE, but the paper does not analyze which encoder characteristics (patch size, positional embeddings, resolution, training objective) most affect perception (e.g., small-object recognition).
- Projector and token budget: Visual features are uniformly resized to 576 tokens and passed through an MLP projector with frozen backbones; the effects of token budget, projector architecture, and unfreezing strategies on priors are untested.
- End-to-end multimodal training: The study uses frozen LLM and vision encoder during alignment; whether joint training strengthens or distorts the identified priors (especially perception) is not assessed.
- Instruction-tuning regimen: Tuning uses a single epoch, fixed LR schedules, and curated subsets; the effect of curriculum design, scaling the number of epochs, RLHF, or task-balanced sampling on cultivating perception vs. reasoning is not explored.
- Source-specific biases: The 16 source categories (e.g., web-crawl, academia, code) are broad and heterogeneous; the paper does not analyze subdomain effects (e.g., diagrams vs. prose in academia) or identify minimal subsets that maximize priors.
- Cross-lingual generalization: The work does not test whether priors transfer across languages, scripts, and OCR for non-Latin text, limiting claims of universality of visual reasoning and perception priors.
- Modality generalization: Universality claims for reasoning priors are tested only across image encoders; transfer to video, audio, 3D point clouds, or robotics perception/decision tasks remains open.
- Task granularity and disentanglement: The perception/reasoning split is supported by moderate correlations; a more granular taxonomy (color/texture, spatial relations, numeracy, geometric reasoning) and targeted probes are needed to cleanly disentangle capabilities.
- Small-object perception: MLE-Bench hypothesizes scale-dependent perception benefits (small/medium objects), but the presented section is incomplete; full results, public release, and stress tests (occlusions, clutter, contrast) are needed to validate the hypothesis.
- Benchmark scope and size: MLE-Bench is relatively small (1,861 images); the paper does not address dataset bias, coverage, leakage, or whether performance correlates with other perception-specific benchmarks.
- Data mixture optimality: The balanced recipe (mix6) is selected via a coarse grid; systematic optimization (e.g., Bayesian optimization) and dynamic mixtures that adjust with model size or training stage are not explored.
- Interaction with model scale: Most mixture experiments fix model size to 3B; whether the optimal proportions for reasoning/visual-world data shift with model size (340M–13B) is unresolved.
- Long-term retention: The paper does not test whether visual priors persist or degrade under further language-only fine-tuning or domain specialization, nor whether catastrophic forgetting affects perception skills.
- Generalization vs. memorization: The work does not differentiate improvements driven by memorized patterns (e.g., template answers) from genuine generalization, especially in knowledge-heavy VQA and chart/OCR tasks.
- Safety and bias: The effects of data mixtures on social bias, hallucination, and unsafe outputs in multimodal contexts are not analyzed; trade-offs between priors and responsible AI constraints are unaddressed.
- Prompt sensitivity: The evaluation uses temperature=0 and fixed prompts; sensitivity to prompt variations and instruction style, especially for smaller models prone to formatting errors, is not quantified.
- Efficiency and compute: The data-centric recipe is validated with substantial compute (500k GPU-hours); the paper does not provide lightweight approximations (e.g., distilled mixtures) or guidance for resource-constrained labs.
- Release and reproducibility: Details on public availability of models, data classification tools, and MLE-Bench are limited; without code/data release, reproducibility and external validation of priors remain constrained.
- Theoretical grounding: The connection to the Platonic Representation Hypothesis is suggestive but not theoretically formalized; open questions include the conditions under which text-only training yields convergent representations with vision, and how alignment emerges mechanistically.
- Robustness to distribution shift: The paper does not test priors under adversarial or out-of-distribution visual inputs (synthetic renderings, medical images, satellite imagery), limiting confidence in generality.
- Comprehensive ablations: While ablations remove subsets of instruction-tuning data, comprehensive factorial designs that jointly vary pre-training mixture, encoder choice, projector, and tuning curriculum are missing and could reveal interaction effects.
Practical Applications
Immediate Applications
Below are concrete ways practitioners can apply the paper’s findings now. Each item names the primary sectors, suggests tools/workflows, and calls out assumptions/dependencies that affect feasibility.
- Data-centric pretraining to boost multimodal reasoning (AI/Software)
- What: Rebalance text-only pretraining toward reasoning-centric corpora (code, math, science, academia) to unlock stronger visual reasoning after light multimodal adaptation. Target a vision-favorable ratio near ~60% reasoning + ~15% visual-world text (or the “balanced” mix approximated by mix6 in the paper: ~52% reasoning + ~15% visual).
- Tools/workflows: Data-mixing grids; LLM-based corpus classifier to tag sources as reasoning/visual; standard Llama-style pretraining; two-stage MLLM alignment/SFT pipelines (e.g., 1M image-caption alignment + ~2–4M V-L SFT).
- Assumptions/dependencies: Access to large, licensed reasoning corpora; results generalize beyond 3B–13B scales; mixture may need re-tuning per domain and model size; training budget.
- Cost-efficient multimodal product bootstrapping (Startups, Product Teams)
- What: Build VQA/chat-vision products by first training an LLM on reasoning-heavy text, then aligning with a comparatively small image-text set (rather than costly multimodal pretraining).
- Tools/workflows: Frozen encoder + projector alignment; curated instruction tuning with a balanced mix of language-only and V-L instructions; robust answer parsing for evaluation.
- Assumptions/dependencies: High-quality alignment/SFT datasets; careful parsing and prompt formats; strong base LLM.
- Instruction-tuning portfolio design for perception vs reasoning (AI/Software, MLOps)
- What: Allocate vision instruction data by target capability: perception-heavy tasks need more perception SFT, whereas reasoning-heavy tasks benefit most from the LLM’s reasoning prior plus modest reasoning SFT.
- Tools/workflows: Dataset triage into “perception/ reasoning/other”; stepwise ablation analysis to tune proportions; task-driven SFT schedules.
- Assumptions/dependencies: Reliable task labeling; availability of domain-specific perception data (e.g., OCR/ChartQA).
- Vision encoder strategy informed by “universal” reasoning prior (AI/Software, Edge AI)
- What: Swap/upgrade vision encoders without losing visual reasoning gains from the LLM; specialize encoder choice to target perception (e.g., OCR, small-object detail).
- Tools/workflows: Plug-and-play encoders (CLIP, DINOv2, MAE variants) with a lightweight projector; regression testing on perception-heavy benchmarks.
- Assumptions/dependencies: Interface consistency (tokens, projector training); encoder licensing and hardware constraints.
- Benchmarking and capability auditing with MLE-Bench (Academia, Industry, Policy)
- What: Use the Multi-Level Existence Bench to profile perception across object size scales (small/medium/large), complementing general, knowledge, OCR/Chart, and vision-centric benchmarks.
- Tools/workflows: Add MLE-Bench to CI for model promotion; report separate perception vs reasoning metrics; use robust answer parsing.
- Assumptions/dependencies: Community acceptance; dataset licensing; consistent evaluation harnesses.
- Document and chart understanding pipelines with stronger reasoning (Finance, Enterprise, Government, Education)
- What: Combine external OCR/chart parsers with a reasoning-primed LLM to improve chart/table Q&A, slide understanding, and report analytics.
- Tools/workflows: OCR + structured extraction + MLLM reasoning; retrieval-augmented generation for documents; provenance logging.
- Assumptions/dependencies: OCR accuracy; regulatory/compliance constraints for sensitive documents; prompt hygiene for long contexts.
- Accessibility aides that reason over everyday visuals (Consumer, Accessibility)
- What: Smartphone assistants that interpret displays/signage, summarize appliance panels, or explain simple diagrams using reasoning-heavy LLMs plus light vision alignment.
- Tools/workflows: On-device or edge-served MLLMs; camera input → encoder tokens → LLM reasoning; user feedback loops.
- Assumptions/dependencies: On-device constraints (memory/latency); privacy; varied lighting and camera quality.
- Synthetic data generation via programmatic scene rendering (CV/Graphics, Education)
- What: Use code-generating LLMs to produce 2D/3D scenes (e.g., Blender, three.js) and diagrams, creating synthetic training sets for perception or diagram-understanding models.
- Tools/workflows: Prompt chains for scene code; domain randomization; sim-to-real fine-tuning.
- Assumptions/dependencies: Bridging sim-to-real gaps; alignment with downstream task distributions.
- “Blind” visual instruction tuning as a diagnostic (AI/Software, Research)
- What: Train/evaluate with masked visual inputs to detect when models “hack” tasks using language priors; identify tasks over-reliant on textual cues.
- Tools/workflows: Training variants with masked images; error analysis dashboard; data quality checks.
- Assumptions/dependencies: Clear task taxonomies; availability of alternative evaluation prompts.
- Representation alignment checks for training governance (Research, MLOps)
- What: Track cross-modal kernel alignment (mutual nearest neighbor on WIT) as a training health signal for when text and visual representations “converge.”
- Tools/workflows: Periodic alignment probes; early stopping/gating for multimodal adaptation readiness.
- Assumptions/dependencies: Correlation of alignment with downstream metrics; compute overhead for probes.
- Model/dataset procurement planning (Enterprise, Policy)
- What: Source reasoning-centric corpora (code/math/academic) and a smaller tranche of visual-world descriptive text to cost-effectively meet multimodal KPIs.
- Tools/workflows: Data inventory scoring; supplier contracts; compliance reviews for licensing and PII.
- Assumptions/dependencies: Legal access to code/math corpora; reproducibility of the paper’s mixture benefits at larger scales.
Long-Term Applications
These applications likely require additional research, scaling, engineering, or regulation before broad deployment.
- Text-first domain visual models (Healthcare, Manufacturing, Geospatial)
- What: Pretrain on domain reasoning corpora (e.g., radiology reports, SOPs, scientific protocols) to cultivate a robust visual reasoning prior; then adapt with limited, high-value images.
- Tools/workflows: Domain corpus curation; minimal image fine-tuning; clinician-in-the-loop validation.
- Assumptions/dependencies: Access to de-identified, high-quality corpora; regulatory clearance; rigorous evaluation for safety.
- Reasoning-heavy robot autonomy with lean perception (Robotics)
- What: Use textual pretraining to endow agents with spatial/physics reasoning, then couple with compact perception modules for manipulation, navigation, or assembly tasks.
- Tools/workflows: World-model prompting; E2E simulation curricula; hardware-in-the-loop testing.
- Assumptions/dependencies: Robust low-level control; safety and reliability standards; real-time constraints.
- LLMs as universal encoders across modalities (Software, Edge/AR)
- What: Productize LLM layers repurposed for visual/audio encoding, unifying model stacks and reducing bespoke backbones.
- Tools/workflows: Multi-head adapters; shared token spaces; latency-aware compilation.
- Assumptions/dependencies: Demonstrated superiority/cost parity vs. domain-specific encoders; hardware support.
- Standard-setting: separate perception vs reasoning reporting (Policy, Standards Bodies)
- What: Require disclosure of disaggregated metrics (e.g., General/OCR vs Knowledge/Vision-Centric vs MLE-Bench scales) in public model cards, bids, and certifications.
- Tools/workflows: Reference test suites; conformance audits; procurement checklists.
- Assumptions/dependencies: Community consensus; maintenance of open, bias-aware benchmarks.
- Automated data-mix optimization services (AI/Data Marketplaces)
- What: Platforms that auto-classify corpora into reasoning/visual categories and propose mixtures to hit target capability profiles under compute budgets.
- Tools/workflows: Mixture search with multi-objective optimization; observability dashboards.
- Assumptions/dependencies: Reliable labeling at web scale; IP/licensing verification; alignment with organization-specific KPIs.
- On-device multimodal assistants via distillation of reasoning priors (Consumer Electronics)
- What: Distill large reasoning-primed LLMs into compact models for phones, wearables, AR glasses to interpret scenes locally.
- Tools/workflows: Multimodal distillation pipelines; quantization; edge caching.
- Assumptions/dependencies: Acceptable accuracy/latency post-distillation; privacy-safe telemetry.
- Safety frameworks that exploit separable priors (Policy, Trust & Safety)
- What: Design red-teaming and monitoring that independently stress-tests perception and visual reasoning to catch hallucinations and over-reliance on textual priors.
- Tools/workflows: Stress tests for size-dependent perception; adversarial chart/diagram probes.
- Assumptions/dependencies: Clear harm taxonomies; secure sandboxing.
- Greener multimodal training (Energy/Sustainability)
- What: Cut emissions by shifting from image-heavy pretraining to text-first strategies, then adding small, targeted visual SFT.
- Tools/workflows: Carbon accounting; data-mix optimizers; efficiency-aware scheduling.
- Assumptions/dependencies: Confirmed parity of performance at production scales; policy incentives.
- Next-gen STEM tutors for visual problem solving (Education)
- What: Tutors that solve math/science items involving diagrams, plots, and multi-step reasoning with minimal task-specific vision training.
- Tools/workflows: Chain-of-thought with diagram parsers; interactive diagram generation; formative feedback.
- Assumptions/dependencies: Robust diagram understanding; fairness and accessibility compliance.
- Synthetic 2D/3D data engines for rare visual concepts (CV, Robotics)
- What: Close data gaps with LLM-driven programmatic generation and curriculum design for rare classes, small objects, or specialized scenes.
- Tools/workflows: Procedural asset libraries; active learning; domain adaptation.
- Assumptions/dependencies: Transferability to real-world conditions; scalable rendering infrastructure.
- Multimodal enterprise search and analytics (Enterprise, BI)
- What: Unified search/Q&A over slides, dashboards, whiteboard photos, and documents leveraging the model’s visual reasoning prior.
- Tools/workflows: Vision-text indexing; retrieval fusion; provenance and model-citation features.
- Assumptions/dependencies: Data governance and access control; integration with enterprise stacks.
- Public-sector accessibility and transparency tools (Government, Civil Society)
- What: Services that interpret charts/infographics in budgets, public-health dashboards, and planning documents for citizens and oversight bodies.
- Tools/workflows: Web scrapers + OCR + reasoning MLLM; plain-language explanations; multilingual support.
- Assumptions/dependencies: Open-data availability; accessibility standards; robustness to diverse layouts.
Notes on cross-cutting assumptions and dependencies:
- Mixture ratios are not universal constants; they depend on model size, domain, and data quality. The reported sweet spots (e.g., ~60% reasoning + ~15% visual-world in a broad pool; “mix6” in a practical source set) are starting points.
- Perception performance is sensitive to the chosen vision encoder and to the quantity/quality of perception-focused SFT. Upgrading encoders and targeted SFT remains important.
- Licensing, privacy, and IP compliance for code/math/academic corpora are nontrivial; enterprise deployments need procurement and legal workflows.
- Evaluation should report disaggregated metrics across perception and reasoning categories, and include MLE-Bench for size-scale perception checks, to avoid overclaiming capability.
Glossary
- ablation studies: Controlled experiments that systematically remove or vary components to measure their effects on performance. "Our methodology is centered on controlled ablation studies~\citep{allen2024icml}, where we deconstruct the sources of different visual capabilities."
- AdamW optimizer: A variant of the Adam optimizer that decouples weight decay from gradient updates to improve training stability. "Training is performed using the AdamW optimizer~\citep{loshchilov2017decoupled} with a peak learning rate of , following a cosine decay schedule and a warm-up over the first 1024 steps."
- ADE: A semantic segmentation dataset (ADE20K) commonly used to evaluate scene parsing. "COCO~\citep{lin2014microsoft}, ADE~\citep{zhou2019semantic}, and Omni3D~\citep{brazil2023omni3d} are proposed as CV-Bench from Cambrian-1~\citep{tong2024cambrian}."
- AI2D: A diagram understanding dataset evaluating scientific diagram comprehension. "It covers ScienceQA~\citep{lu2022learn}, MMMU~\citep{yue2023mmmu}, AI2D~\citep{hiippala2021ai2d}, and MathVista~\citep{lu2023mathvista}."
- ARC: The AI2 Reasoning Challenge, a benchmark for science exam-style questions. "including PIQA~\citep{bisk2020piqa}, HellaSwag~\citep{zellers2019hellaswag}, WinoGrande~\citep{sakaguchi2021winogrande}, ARC~\citep{arc-ce}, Copa~\citep{reddy2019coqa}, SciQA~\citep{SciQA2023}, OpenbookQA~\citep{openbookqa}, and BoolQA~\citep{clark2019boolq}."
- Blink: A vision-centric benchmark testing quick visual reasoning/perception. "It uses benchmarks including RealWorldQA~\citep{grok}, Blink~\citep{fu2024blink}, COCO, ADE, and Omni3D."
- BoolQA: A yes/no question answering dataset evaluating reading comprehension (known as BoolQ). "including PIQA~\citep{bisk2020piqa}, HellaSwag~\citep{zellers2019hellaswag}, WinoGrande~\citep{sakaguchi2021winogrande}, ARC~\citep{arc-ce}, Copa~\citep{reddy2019coqa}, SciQA~\citep{SciQA2023}, OpenbookQA~\citep{openbookqa}, and BoolQA~\citep{clark2019boolq}."
- Cambrian-1: A prior multimodal LLM framework/pipeline used as a reference for adaptation and evaluation. "We adopt a two-stage adaptation strategy following Cambrian-1~\citep{tong2024cambrian} and Web-SSL~\citep{fan2025scaling}, consisting of visual alignment and supervised fine-tuning."
- ChartQA: A visual question answering dataset focused on charts and plots. "It comprises TextVQA~\citep{sidorov2020textcaps}, ChartQA~\citep{masry2022chartqa}, and OCRBench~\citep{liu2023hidden}."
- CLIP-Huge: A large-scale vision-LLM used as a strong vision backbone for feature alignment. "The final alignment score for a given LLM is reported as the average of its scores against three strong vision backbones: ViT-Large~\citep{dosovitskiy2020image} (trained on ImageNet-21K~\citep{deng2009imagenet}), DINOv2-Giant~\citep{oquab2023dinov2}, and CLIP-Huge~\citep{radford2021learning}."
- COCO: A widely-used dataset for object detection, segmentation, and captioning (Common Objects in Context). "COCO~\citep{lin2014microsoft}, ADE~\citep{zhou2019semantic}, and Omni3D~\citep{brazil2023omni3d} are proposed as CV-Bench from Cambrian-1~\citep{tong2024cambrian}."
- cosine decay schedule: A learning rate schedule that decays the learning rate following a cosine function. "Training is performed using the AdamW optimizer~\citep{loshchilov2017decoupled} with a peak learning rate of , following a cosine decay schedule and a warm-up over the first 1024 steps."
- CV-Bench: A curated set of computer vision benchmarks used for evaluating perception and reasoning. "COCO~\citep{lin2014microsoft}, ADE~\citep{zhou2019semantic}, and Omni3D~\citep{brazil2023omni3d} are proposed as CV-Bench from Cambrian-1~\citep{tong2024cambrian}."
- decoder-only Transformer: A Transformer architecture using only the decoder stack, optimized for autoregressive language modeling. "We follow standard practices and pre-train a suite of decoder-only Transformer models that closely adhere to the Llama-3 architecture~\citep{grattafiori2024llama}, spanning five model scales: 340M, 1B, 3B, 7B, and 13B parameters."
- DINOv2-Giant: A high-capacity self-supervised vision transformer backbone. "The final alignment score for a given LLM is reported as the average of its scores against three strong vision backbones: ViT-Large~\citep{dosovitskiy2020image} (trained on ImageNet-21K~\citep{deng2009imagenet}), DINOv2-Giant~\citep{oquab2023dinov2}, and CLIP-Huge~\citep{radford2021learning}."
- effective global batch size: The total number of samples processed across all devices per optimizer step. "All models are trained with a context length of 2048 tokens and an effective global batch size of 1024."
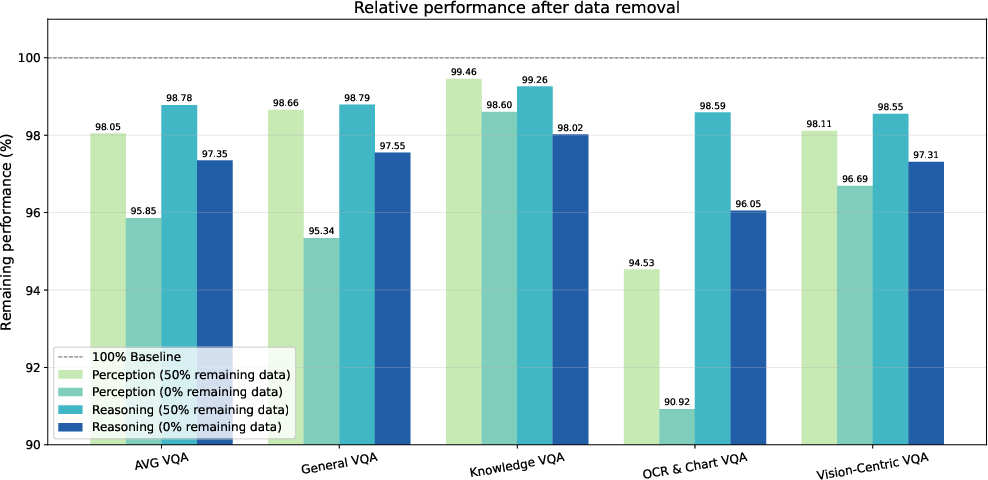
- General VQA: A VQA category emphasizing visual perception combined with commonsense knowledge rather than complex reasoning. "Performance on General VQA and Knowledge VQA demonstrates a similar scaling trend, consistently improving with both model and data size."
- GQA: A visual question answering dataset focusing on compositional reasoning. "It includes GQA~\citep{hudson2019gqa}, MME~\citep{fu2023mme}, MMBench~\citep{liu2023mmbench}, and SEED~\citep{ge2023planting}."
- grid search: An exhaustive search procedure over combinations of hyperparameters or mixture ratios. "Specifically, we perform a grid search across 24 data blends constructed by sampling from a space where the reasoning combination ranges from 50\% to 85\% and the visual combination ranges from 5\% to 30\%."
- HellaSwag: A benchmark for commonsense reasoning with adversarially mined choices. "including PIQA~\citep{bisk2020piqa}, HellaSwag~\citep{zellers2019hellaswag}, WinoGrande~\citep{sakaguchi2021winogrande}, ARC~\citep{arc-ce}, Copa~\citep{reddy2019coqa}, SciQA~\citep{SciQA2023}, OpenbookQA~\citep{openbookqa}, and BoolQA~\citep{clark2019boolq}."
- ImageNet-21K: A large-scale image dataset with ~21,000 categories used for pretraining vision models. "ViT-Large~\citep{dosovitskiy2020image} (trained on ImageNet-21K~\citep{deng2009imagenet})"
- instruction tuning: Fine-tuning a model on instruction-following data to improve its ability to respond to prompts. "With a vision encoder, high-level reasoning emerges from instruction tuning on a small scale of image-text pairs, bypassing the need for massive multimodal pretraining~\citep{alayrac2022flamingo,liu2023visual,li2023blip,grattafiori2024llama,tong2024cambrian,bai2025qwen2}."
- kernel: A similarity matrix computed from model representations, often via inner products. "Given an image and its caption , we compute vision and language kernels, $K_{\text{vision}$ and $K_{\text{lang}$, from their respective model representations, $f_{\text{vision}$ and $f_{\text{lang}$:"
- Knowledge VQA: A VQA category requiring multi-step reasoning connecting visual information to scientific or mathematical knowledge. "Performance on General VQA and Knowledge VQA demonstrates a similar scaling trend, consistently improving with both model and data size."
- LLMs: High-capacity neural models trained on large text corpora to predict next tokens and perform diverse tasks. "LLMs, despite being trained on text alone, surprisingly develop rich visual priors."
- LAMBADA: A dataset testing long-range context understanding in language modeling. "For raw language modeling quality, we report the averaged perplexity (ppl) across Wikitext~\citep{merity2016pointer} and LAMBADA~\citep{paperno2016lambada}."
- linear warm-up: A training technique that gradually increases the learning rate linearly at the start of training. "Both the alignment and instruction tuning stages use the AdamW optimizer with a cosine learning rate schedule and linear warm-up, and models are trained for a single epoch."
- Llama-3 architecture: A specific open LLM architecture used as the base model design. "We follow standard practices and pre-train a suite of decoder-only Transformer models that closely adhere to the Llama-3 architecture~\citep{grattafiori2024llama}"
- MAE-H: A high-capacity Masked Autoencoder vision backbone variant. "We apply two more vision encoders (DINOv2-G~\citep{oquab2023dinov2} and MAE-H~\citep{he2022masked}) other than our default MetaCLIP-B/16."
- MathVista: A benchmark for visual math reasoning tasks. "It covers ScienceQA~\citep{lu2022learn}, MMMU~\citep{yue2023mmmu}, AI2D~\citep{hiippala2021ai2d}, and MathVista~\citep{lu2023mathvista}."
- MetaCLIP-B/16: A specific CLIP-derived vision encoder configuration used in the study. "Unless otherwise specified, we use MetaCLIP-B/16~\citep{xu2023demystifying} as the default vision encoder."
- MLE-Bench: The Multi-Level Existence Bench, a benchmark for fine-grained evaluation of perceptual abilities. "Along with our main findings, we propose and investigate several hypotheses, and introduce the Multi-Level Existence Bench (MLE-Bench)."
- MLP-based projector: A multi-layer perceptron used to map visual features into the LLM’s embedding space. "we train an MLP-based projector on top of a frozen vision encoder and LLM to align visual features with the LLM."
- MME: A multimodal evaluation benchmark for perception and general understanding. "It includes GQA~\citep{hudson2019gqa}, MME~\citep{fu2023mme}, MMBench~\citep{liu2023mmbench}, and SEED~\citep{ge2023planting}."
- MMBench: A benchmark suite evaluating multimodal understanding and reasoning. "It includes GQA~\citep{hudson2019gqa}, MME~\citep{fu2023mme}, MMBench~\citep{liu2023mmbench}, and SEED~\citep{ge2023planting}."
- mutual nearest-neighbor (mNN) metric: An alignment metric measuring overlap in nearest-neighbor sets across modalities. "We then assess the alignment between these kernels using the mutual nearest-neighbor () metric, which calculates the average overlap of the -nearest neighbor sets (with ) for each pair."
- OCRBench: A benchmark focused on optical character recognition within images. "It comprises TextVQA~\citep{sidorov2020textcaps}, ChartQA~\citep{masry2022chartqa}, and OCRBench~\citep{liu2023hidden}."
- Omni3D: A dataset for 3D scene understanding and object detection. "COCO~\citep{lin2014microsoft}, ADE~\citep{zhou2019semantic}, and Omni3D~\citep{brazil2023omni3d} are proposed as CV-Bench from Cambrian-1~\citep{tong2024cambrian}."
- OpenbookQA: A question answering benchmark requiring application of open-book knowledge. "including PIQA~\citep{bisk2020piqa}, HellaSwag~\citep{zellers2019hellaswag}, WinoGrande~\citep{sakaguchi2021winogrande}, ARC~\citep{arc-ce}, Copa~\citep{reddy2019coqa}, SciQA~\citep{SciQA2023}, OpenbookQA~\citep{openbookqa}, and BoolQA~\citep{clark2019boolq}."
- Perception prior: An implicit visual capability focusing on perceptual acuity that emerges in LLMs. "The learned visual prior is not a single entity but decomposes into at least a perception prior and a reasoning prior with different origins."
- Perplexity (ppl): A metric of LLM uncertainty; lower values indicate better modeling. "For raw language modeling quality, we report the averaged perplexity (ppl) across Wikitext~\citep{merity2016pointer} and LAMBADA~\citep{paperno2016lambada}."
- PIQA: A benchmark for physical commonsense reasoning about everyday actions. "including PIQA~\citep{bisk2020piqa}, HellaSwag~\citep{zellers2019hellaswag}, WinoGrande~\citep{sakaguchi2021winogrande}, ARC~\citep{arc-ce}, Copa~\citep{reddy2019coqa}, SciQA~\citep{SciQA2023}, OpenbookQA~\citep{openbookqa}, and BoolQA~\citep{clark2019boolq}."
- Platonic Representation Hypothesis: The hypothesis that model representations converge toward a shared world model across modalities. "They lend strong empirical support to the Platonic Representation Hypothesis~\citep{huh2024position,jha2025harnessing}"
- RealWorldQA: A benchmark evaluating visual reasoning in real-world scenarios. "It uses benchmarks including RealWorldQA~\citep{grok}, Blink~\citep{fu2024blink}, COCO, ADE, and Omni3D."
- Reasoning-centric data: Pretraining data heavily focused on reasoning domains like code and math. "We show that an LLM's latent visual reasoning ability is predominantly developed by pre-training on reasoning-centric data (e.g., code, math, academia) and scales progressively."
- Reasoning prior: An implicit reasoning capability learned during language pretraining that transfers to visual tasks. "This reasoning prior acquired from language pre-training is transferable and universally applicable to visual reasoning."
- ScienceQA: A multimodal benchmark combining visual information with scientific knowledge and reasoning. "It covers ScienceQA~\citep{lu2022learn}, MMMU~\citep{yue2023mmmu}, AI2D~\citep{hiippala2021ai2d}, and MathVista~\citep{lu2023mathvista}."
- SEED: A multimodal benchmark evaluating general visual understanding and commonsense grounding. "It includes GQA~\citep{hudson2019gqa}, MME~\citep{fu2023mme}, MMBench~\citep{liu2023mmbench}, and SEED~\citep{ge2023planting}."
- Spearman correlation matrix: A rank-based correlation analysis across variables/tasks. "We then compute the Spearman correlation matrix across the four VQA performance categories to identify which abilities scale together and which diverge."
- supervised fine-tuning: Training on labeled data to improve specific task performance after pretraining. "In the second stage, we perform supervised fine-tuning on a mixture of vision-language and language-only instruction data to enhance the model’s multimodal instruction-following ability."
- TextVQA: A VQA task focusing on reading and understanding text within images. "It comprises TextVQA~\citep{sidorov2020textcaps}, ChartQA~\citep{masry2022chartqa}, and OCRBench~\citep{liu2023hidden}."
- tokenizer: A component that splits text into discrete tokens for model input. "We use a tokenizer with a vocabulary size of approximately 32000."
- ViT-Large: A large Vision Transformer model used as a strong vision backbone. "The final alignment score for a given LLM is reported as the average of its scores against three strong vision backbones: ViT-Large~\citep{dosovitskiy2020image} (trained on ImageNet-21K~\citep{deng2009imagenet}), DINOv2-Giant~\citep{oquab2023dinov2}, and CLIP-Huge~\citep{radford2021learning}."
- vision encoder: A model that converts images into feature embeddings compatible with LLMs. "Unless otherwise specified, we use MetaCLIP-B/16~\citep{xu2023demystifying} as the default vision encoder."
- visual alignment: The process of aligning visual features to the LLM’s representation space. "We adopt a two-stage adaptation strategy following Cambrian-1~\citep{tong2024cambrian} and Web-SSL~\citep{fan2025scaling}, consisting of visual alignment and supervised fine-tuning."
- visual instruction tuning: Fine-tuning with vision-language instructions to improve multimodal capabilities. "In contrast, the perception prior emerges more diffusely from broad corpora, and perception ability is more sensitive to the vision encoder and visual instruction tuning data."
- Visual Question Answering (VQA): A task where models answer questions about visual content in images. "Performance on General VQA and Knowledge VQA demonstrates a similar scaling trend, consistently improving with both model and data size."
- Vision-Centric VQA: A VQA category that emphasizes abstract visual reasoning and coarse perception. "Meanwhile, Vision-Centric VQA also presents a unique pattern where the largest models benefit disproportionately from more data, while smaller models plateau much earlier."
- Web-SSL: A web-scale self-supervised learning data pipeline used for multimodal adaptation. "We adopt a two-stage adaptation strategy following Cambrian-1~\citep{tong2024cambrian} and Web-SSL~\citep{fan2025scaling}, consisting of visual alignment and supervised fine-tuning."
- Wikitext: A language modeling dataset based on Wikipedia articles. "For raw language modeling quality, we report the averaged perplexity (ppl) across Wikitext~\citep{merity2016pointer} and LAMBADA~\citep{paperno2016lambada}."
- WinoGrande: A large-scale commonsense reasoning dataset focusing on pronoun resolution. "including PIQA~\citep{bisk2020piqa}, HellaSwag~\citep{zellers2019hellaswag}, WinoGrande~\citep{sakaguchi2021winogrande}, ARC~\citep{arc-ce}, Copa~\citep{reddy2019coqa}, SciQA~\citep{SciQA2023}, OpenbookQA~\citep{openbookqa}, and BoolQA~\citep{clark2019boolq}."
- WIT dataset: The Wikipedia-based Image Text dataset of image–caption pairs for cross-modal analysis. "For this analysis, we use image-caption pairs from the Wikipedia-based Image Text (WIT) dataset~\citep{srinivasan2021wit}."
- warm-up ratio: The fraction of training steps reserved for gradually increasing the learning rate. "During alignment, we use a learning rate of with a warm-up ratio of 6\%."
- zero-shot performance: Evaluation without task-specific fine-tuning, relying solely on pretrained capabilities. "For reasoning, we evaluate zero-shot performance on a diverse suite of commonsense and question-answering tasks, including PIQA~\citep{bisk2020piqa}, HellaSwag~\citep{zellers2019hellaswag}, WinoGrande~\citep{sakaguchi2021winogrande}, ARC~\citep{arc-ce}, Copa~\citep{reddy2019coqa}, SciQA~\citep{SciQA2023}, OpenbookQA~\citep{openbookqa}, and BoolQA~\citep{clark2019boolq}."
Collections
Sign up for free to add this paper to one or more collections.