- The paper introduces a training-free method to precisely control object positions in multimodal diffusion transformers using LLM-based prompt decomposition and bounding box generation.
- It employs attention masking and latent-space cutout to enforce regional generation, significantly improving positional accuracy across complex spatial tasks.
- The approach achieves substantial performance gains on the PosEval benchmark without retraining, enhancing applicability in design, robotics, and content creation.
Introduction
"Stitch: Training-Free Position Control in Multimodal Diffusion Transformers" (2509.26644) addresses a persistent limitation in state-of-the-art text-to-image (T2I) generation: the inability of modern models to reliably follow complex spatial instructions in prompts. While recent advances in image quality and diversity have been substantial, even leading models struggle with spatial relations such as "2" "3" or more intricate multi-object arrangements. The paper introduces black, a training-free, test-time method for position control in Multi-Modal Diffusion Transformer (MMDiT) architectures, and proposes PosEval, a comprehensive benchmark for evaluating positional understanding in T2I models.

Figure 1: (a) black boosts position-aware generation, training-free, (b) by generating objects in LLM-made bounding boxes (dashed lines) and using attention heads for tighter latent segmentation mid-generation (filled). (c) Our PosEval benchmark extends GenEval with 5 new positional tasks.
Methodology: The black Approach
Overview
black is a modular, training-free pipeline that augments MMDiT-based T2I models (e.g., Qwen-Image, FLUX, SD3.5) with explicit position control. The method leverages LLMs to decompose prompts into object-specific sub-prompts and generate corresponding bounding boxes, then constrains the generative process to respect these spatial assignments. The approach is entirely test-time and does not require model retraining or architectural modification.
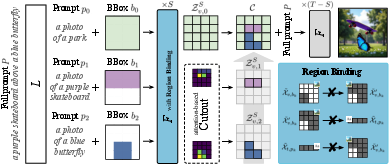
Figure 2: black: Multimodal LLM L splits full prompt P into object prompts pk and bounding boxes bk, along with full-image background prompt p0.
Pipeline Details
- Prompt Decomposition and Bounding Box Generation: An LLM (e.g., GPT-5) parses the input prompt, identifies individual objects, and assigns each a bounding box on a fixed grid. A separate background prompt is also generated.
- Region Binding via Attention Masking:
For the initial S diffusion steps, the model applies three attention-masking constraints:
- Block attention from inside to outside each bounding box.
- Block attention from outside the bounding box to the sub-prompt text.
- Block attention from the sub-prompt text to outside the bounding box.
This ensures that each object is generated independently within its designated region.
- Cutout: Foreground Extraction Using Attention Heads:
After S steps, the method identifies attention heads that encode object localization. It extracts foreground latent tokens by thresholding attention weights, producing a mask that isolates the object in latent space. This mask is smoothed via max pooling.

Figure 3: Segmentation head maps for SD3.5.
- Stitching and Final Refinement: The extracted object latents are composited with the background latents to form a single latent representation. The model then continues unconstrained generation for the remaining T−S steps, allowing for global refinement and seamless blending.
Implementation Considerations
black is compatible with any MMDiT-based model that exposes attention maps and supports latent-space manipulation.
- Attention Head Selection:
The optimal attention head for Cutout is determined empirically by maximizing IoU with ground-truth segmentations (e.g., via SAM).
The number of constrained steps S, attention threshold η, and pooling kernel size κ are tuned per model for optimal trade-off between positional accuracy and image coherence.
Computational Overhead
The method introduces negligible computational overhead, as all operations (attention masking, Cutout) are performed in latent space and require no additional training or external segmentation models.
PosEval: A Comprehensive Benchmark for Positional Generation
The paper introduces PosEval, a benchmark extending GenEval with five new tasks that probe various aspects of positional understanding:
- 2 Obj: Standard two-object spatial relations.
- 3 Obj / 4 Obj: Multi-object chains with multiple spatial relations.
- Positional Attribute Binding (PAB): Attribute-object pairs with spatial relations.
- Negative Relations (Neg): Prompts specifying where objects should not be.
- Relative Relations (Rel): Relations defined relative to other objects' positions.
PosEval uses automated evaluation (Mask2Former-based detection and procedural verification) and is validated via human studies for alignment.
Experimental Results
black delivers substantial improvements in positional accuracy across all tested models and tasks. Notably:
Qualitative Analysis
black enables models to generate semantically and spatially coherent images for complex prompts, including those with multiple objects, attributes, and negative or relative relations.

Figure 5: black excels at complex positional prompts.

Figure 6: Qualitative examples for black + SD3.5.

Figure 7: Additional qualitative examples for black + Qwen-Image (QwenI).

Figure 8: Additional qualitative examples for black + FLUX.
Ablation Studies
Theoretical and Practical Implications
Theoretical Insights
- The discovery that specific attention heads encode object localization in latent space, even mid-generation, suggests that MMDiT architectures inherently learn spatial disentanglement, which can be exploited for controllable generation.
- The success of training-free, test-time interventions challenges the necessity of retraining or fine-tuning for spatial control, at least in the context of MMDiT models.
Practical Applications
- black can be deployed as a plug-in for existing T2I pipelines, enabling precise spatial control for applications in design, robotics, and content creation without retraining.
- The method is robust to prompt complexity and scales to multi-object, attribute-rich, and negative/relative spatial instructions.
Limitations and Future Directions
- The approach relies on the quality of LLM-generated bounding boxes and prompt decomposition; errors here can propagate.
- The method is currently tailored to MMDiT architectures; generalization to other architectures (e.g., U-Net-based diffusion) may require adaptation.
- Future work could explore dynamic or learned attention head selection, integration with 3D spatial reasoning, and further automation of prompt decomposition.
Conclusion
"Stitch" demonstrates that training-free, attention-based interventions can substantially enhance the positional understanding of state-of-the-art T2I models. By leveraging LLMs for prompt decomposition and bounding box generation, and exploiting the spatial information encoded in MMDiT attention heads, black achieves state-of-the-art results on a challenging new positional benchmark, PosEval. The method is computationally efficient, model-agnostic within the MMDiT family, and preserves both image quality and diversity. This work provides a practical pathway for integrating fine-grained spatial control into high-fidelity generative models and sets a new standard for evaluating and improving positional reasoning in T2I generation.



