- The paper introduces the Be My Eyes framework that decouples visual perception from language reasoning using a small VLM and a frozen LLM in a multi-agent setup.
- It employs synthetic supervision and iterative multi-turn dialogue to optimize agent collaboration, achieving state-of-the-art performance on benchmarks like MathVista and MathVision.
- The modular design eliminates the need for full LLM retraining, enabling scalable, low-cost modality extensions across diverse domains.
Extending LLMs to New Modalities via Multi-Agent Collaboration: The Be My Eyes Framework
Introduction
"Be My Eyes: Extending LLMs to New Modalities Through Multi-Agent Collaboration" (2511.19417) addresses the challenge of efficiently equipping LLMs with multimodal (especially vision-language) reasoning abilities without the need for full-scale retraining or architectural modifications. The core proposition is a modular framework in which a small, adaptable VLM acts as a perceiver agent, processing non-textual input and translating it into detailed textual descriptions. A separate, powerful, and frozen LLM then serves as the reasoner agent, leveraging these descriptions to perform advanced reasoning—thereby decoupling perception from reasoning. This architecture enables open- or closed-source text-only LLMs to attain SOTA performance on multimodal benchmarks, matching or surpassing proprietary VLMs such as GPT-4o, without exposure to raw pixel data or task-specific retraining.
Framework Architecture
The Be My Eyes framework is explicitly modular, comprising a perceiver agent (VLM) and a reasoner agent (LLM) that interact via orchestrated multi-turn dialogue. The perceiver is responsible for extracting all relevant visual context and communicating it proactively and responsively to the reasoner, which queries for clarification and iteratively builds its reasoning trace. Importantly, only the perceiver accesses non-textual data; the reasoner remains frozen and unimodal. This strict separation ensures that advances in either LLMs or VLMs can be independently leveraged.
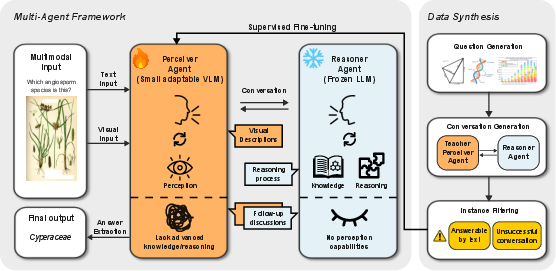
Figure 1: Overview of the Be My Eyes framework, showing the perceiver (VLM) extracting and summarizing visual information and the reasoner (LLM) engaging in multi-turn conversation without parameter changes.
To optimize this pipeline, the authors construct a synthetic supervision dataset: multi-turn conversations between perceiver and reasoner agents are generated (with a strong teacher VLM role-playing both sides), filtered to ensure true multimodal dependence, and then used for supervised fine-tuning (SFT) of the perceiver. This enables deliberately trained context-aware visual description and role-consistent interaction.
Experimental Results
Be My Eyes was evaluated on a suite of challenging benchmarks: MMMU, MMMU Pro, MathVista, and MathVision, all requiring complex visual reasoning and advanced subject domain knowledge.
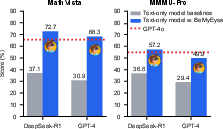
Figure 2: Be My Eyes enables DeepSeek-R1 and GPT-4 to achieve SOTA on multimodal benchmarks—surpassing even closed-source GPT-4o—without any parameter change or retraining of the reasoner.
Key findings include:
- DeepSeek-R1, a pure text-only LLM, when paired with Qwen2.5-VL-7B as perceiver, outperforms GPT-4o (a large-scale multimodal LLM) on all evaluated benchmarks. Performance margins are especially large on MathVista (+7.1%) and MathVision (+12.1%).
- The modularity and robustness of Be My Eyes is validated by comparable gains when substituting InternVL3-8B or Lingshu-7B as the perceiver agent—highlighting that the framework generalizes across model families and domains, including medical imagery.
- Detailed ablations show both SFT and conversational multi-turn interaction are essential:
- Removing SFT or restricting to single-turn summarization substantially reduces accuracy.
- SFT of the perceiver does not improve the VLM’s isolated performance (standalone inference), indicating the gains derive from enhanced collaborative alignment and communication, not better captioning per se.
- Be My Eyes provides a consistent means of extending state-of-the-art LLMs to new modalities with minimal additional cost and engineering.
Error Analysis
An error breakdown on MMMU Pro reveals fine-grained interaction dynamics:
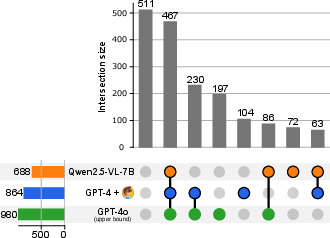
Figure 3: Error analysis across single-perceiver, single-reasoner-with-vision, and Be My Eyes settings, measuring the nature and frequency of successes and failures across modalities and collaborations.
- The majority of items are either trivially solved or universally challenging for all models.
- A large subset is only solved correctly in the collaborative Be My Eyes setting—the reasoner (text-only LLM) draws on the perceiver’s contextualized visual evidence to outperform either model in isolation.
- There exist failure cases where collaborative interaction introduces novel errors: either due to communicative deficiencies in the perceiver or overreliance on textual cues.
Overall, this analysis demonstrates that multi-agent collaboration is able to synthesize the complementary strengths of perception and reasoning agents, but can also introduce failure modes not found in single-model architectures.
Implications and Future Directions
Be My Eyes systematically decouples modality extension into perception and reasoning, offering a mechanism for rapid, low-cost, and highly flexible multimodal grounding for any high-performing LLM. Several crucial implications follow:
- The approach eliminates the need to retrain large LLMs for every new modality or domain, reducing computational and data requirements to the scale of fine-tuning small VLMs.
- Modality extension (including non-vision modalities) becomes an engineering problem of designing appropriate perceivers, potentially one-per-domain, and training them via synthetic collaborative data.
- The strict separation of perception and reasoning mitigates knowledge conflicts and language bias effects seen in monolithic VLMs, as confirmed by performance and error analyses.
Potential research directions include extending to video and audio, integrating reinforcement learning-based collaborative fine-tuning, and developing specialized diagnostic datasets to further disentangle perception-reasoning errors.
Conclusion
The Be My Eyes framework presents a modular, general, and empirically validated paradigm for modality extension of LLMs (2511.19417). Through explicit multi-agent orchestration, context-aware perception, and iterative reasoning, this method allows text-only LLMs to achieve—and at times surpass—the performance of large-scale, closed-source multimodal foundation models across a variety of knowledge-intensive reasoning benchmarks. The results establish modular multi-agent collaboration as an efficient alternative to end-to-end multimodal pretraining, with significant implications for future research on scalable, domain-adaptive, and generalizable artificial intelligence.