- The paper presents a multi-agent NL-to-test generation framework that decomposes natural language descriptions into BDD-style blocks for structurally complex testing.
- It uses specialized agents for grounding, code synthesis, and iterative validation, achieving 50–78% higher compilability and 38–66% improved coverage over baselines.
- The approach is scalable, cost-effective, and extensible to other statically-typed languages, marking a significant advancement in automated test generation.
Sakura: Multi-Agent NL-to-Test Generation for Structurally Complex Scenarios
Motivation and Problem Statement
Automated test generation has historically focused on unit tests targeting individual methods or classes, and API/UI-centric test suites, leaving a substantial gap relative to the structural complexity of developer-written tests in real-world codebases. Empirical evidence reveals that manually constructed tests frequently involve multi-class/multi-method interactions, complex setup/teardown procedures, and dense assertion logic, which most ATG tools—including conventional LLM-driven agents—fail to capture (Pan et al., 30 Sep 2025). The mismatch is evident in the stark divergence between generated and developer-written tests with respect to focal method coverage, behavioral fidelity, and assertion naturalness.
Initiating test generation from natural language (NL) descriptions of developer intent, rather than code-centric heuristics, offers a path toward bridging this gap. However, standard LLM-based agentic tools (e.g., Gemini CLI) lack structural grounding mechanisms, often producing semantically plausible but syntactically invalid or behaviorally incorrect test cases. Addressing this, Sakura introduces a multi-agent system with coordinated decomposition, grounding, code synthesis, and iterative validation, thereby enabling the generation of structurally complex tests directly from NL input.
Framework Architecture
Sakura operationalizes NL-driven test generation through a pipeline consisting of: code index creation, NL decomposition, and an agentic workflow combining localization, composition, and supervisory coordination.
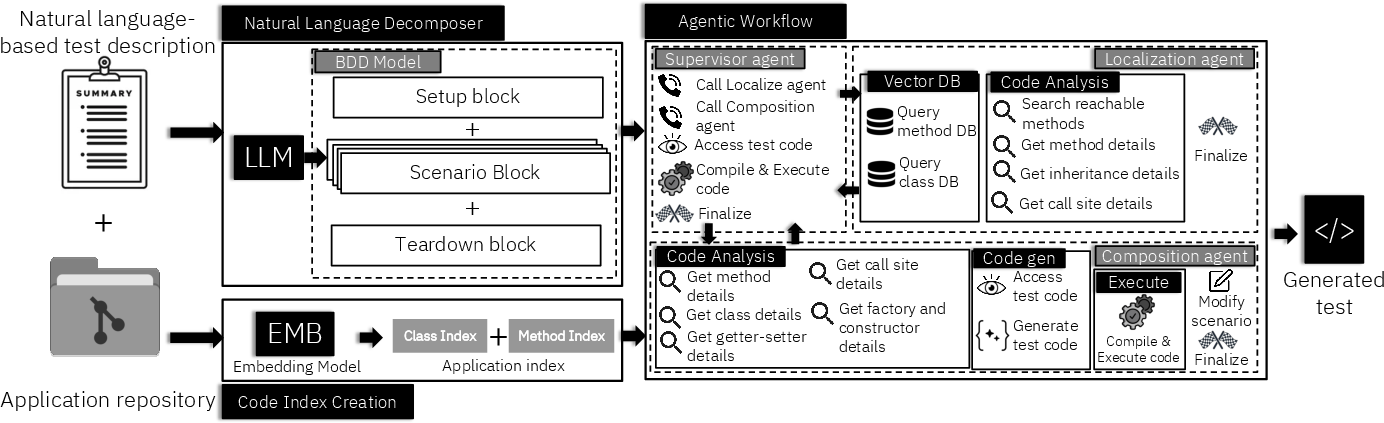
Figure 1: The Sakura framework converts NL test descriptions into BDD-style blocks and synthesizes executable, structurally complex test code via specialized agents.
Code Indexing
A onetime vectorization of the application codebase using Qwen3 Embedding 8B enables retrieval of relevant methods/classes. It tracks both declaring and containing classes for method context, facilitating accurate resolution of inherited, overloaded, and context-sensitive behavioral elements.
NL Decomposer
Leveraging LLM prompting, Sakura transforms free-form NL descriptions into BDD-inspired structured blocks, distinguishing setup, scenario (with precondition/action/assertion), and teardown phases. Each block records task description, explicit data flow, and flags for external dependencies.
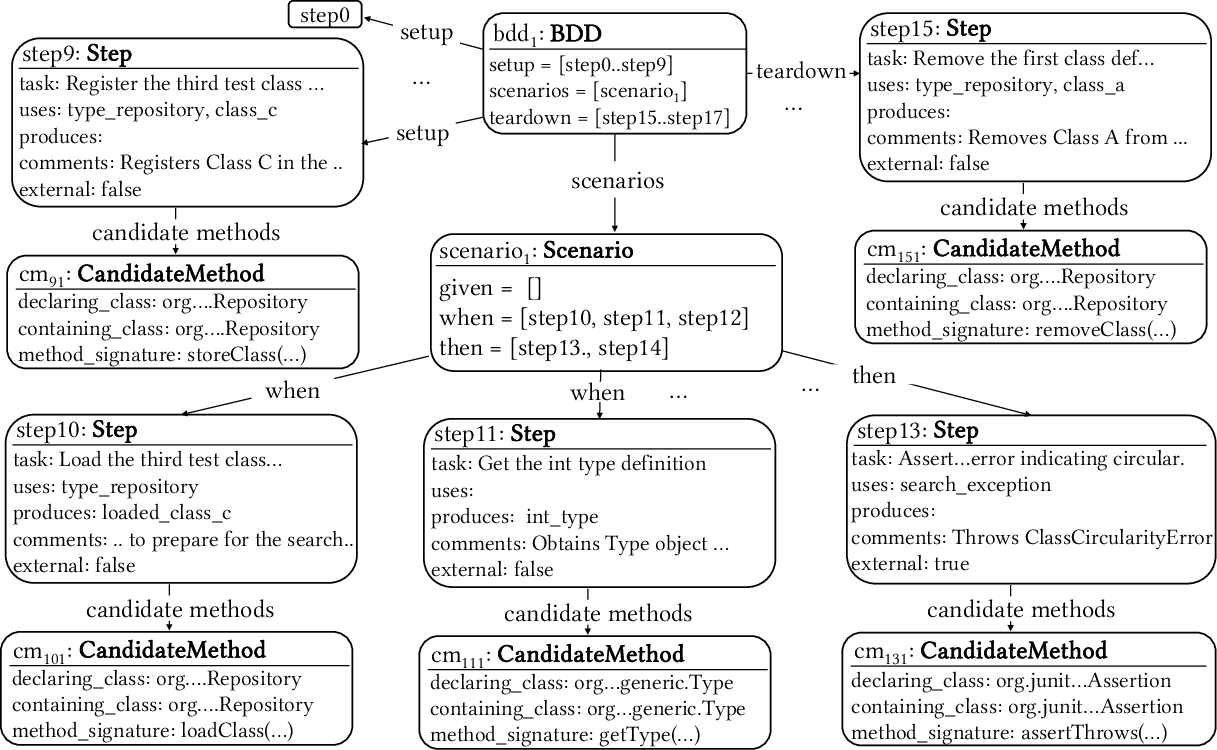
Figure 2: BDD-style decomposition of a circular inheritance test scenario, showing separation of setup, scenario, and teardown steps.
Multi-Agent Workflow
Localization Agent
Grounds each BDD step in candidate classes/methods via semantic search, static analysis, and code inspection. It annotates uncertainty and ensures external dependencies are handled robustly.
Composition Agent
Synthesizes and validates Java test code iteratively, using build-system feedback (compilation/exception/assertion reports) to refine code and correct errors (e.g., type mismatches, missing imports, assertion faults).
Supervisor Agent
Coordinates agentic execution, orchestrating subagent calls, managing decomposition state, and terminating upon successful test compilation/execution. It diagnoses failures and triggers targeted re-localization or composition correction.
Evaluation Dataset
Sakura’s evaluation dataset comprises 1,464 NL test descriptions at three abstraction levels paired with 488 developer-written tests from 20 Apache Commons projects. The descriptions are generated post-training cutoff dates of evaluated LLMs to eliminate data leakage and synthesized via Sonnet 4.5 for abstraction stratification.
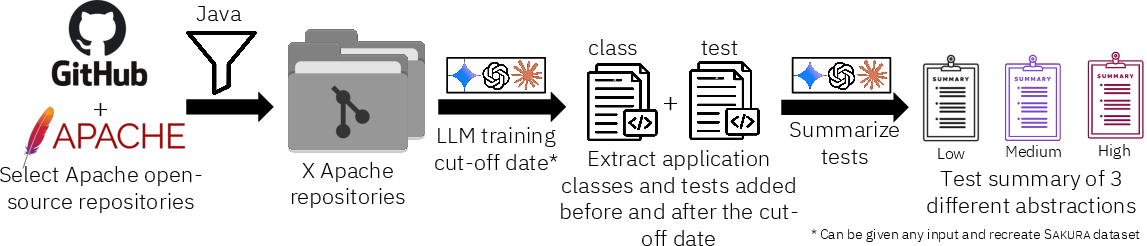
Figure 3: Three-phase pipeline for dataset creation—repository filtering, static context extraction, and abstraction-level NL generation.
The dataset is notable for its structural complexity (median 2 focal methods per test), supporting evaluation along specificity and behavioral diversity axes.
Empirical Results
Sakura is evaluated against Gemini CLI (baseline) using both proprietary (Gemini 2.5 Pro/Flash) and open-source (Qwen3-Coder, Devstral Small 2) models. Metrics include compilability, coverage overlap, structural fidelity, abstraction/complexity sensitivity, tool invocation patterns, and cost.
Compilability
Sakura attains 50–78% higher compilability than Gemini CLI, achieving 97.3% for Gemini 2.5 Pro and 85.4% with Devstral Small 2. Open-source models under Sakura outperform proprietary Gemini CLI settings.
Coverage Overlap
Sakura yields 38–66% higher coverage overlap than baseline, with Qwen3-Coder achieving 73.2% branch coverage versus 46.3% for Gemini CLI with Gemini 2.5 Pro.
Structural Fidelity
Recall for instantiated types, assertion types, invoked methods, and focal methods is 31–72% higher for Sakura. Assertion recall is robust across abstraction levels, whereas focal method recall degrades under high abstraction but remains superior (45.5% vs. 18.2% for Gemini CLI).
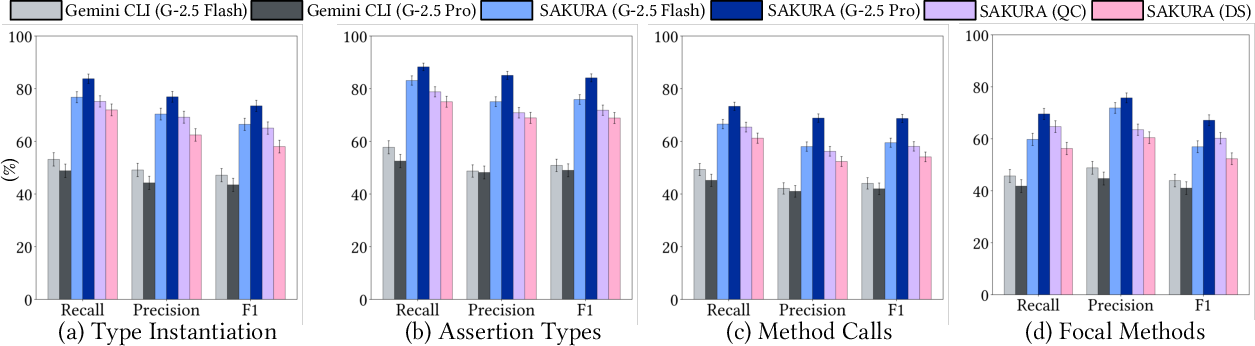
Figure 4: Structural fidelity metric comparison for recall across test properties.
Abstraction Sensitivity
While lower abstraction descriptions yield higher quality, Sakura maintains substantial performance advantages at all levels. With high abstraction, focal method recall remains above twice that of Gemini CLI.
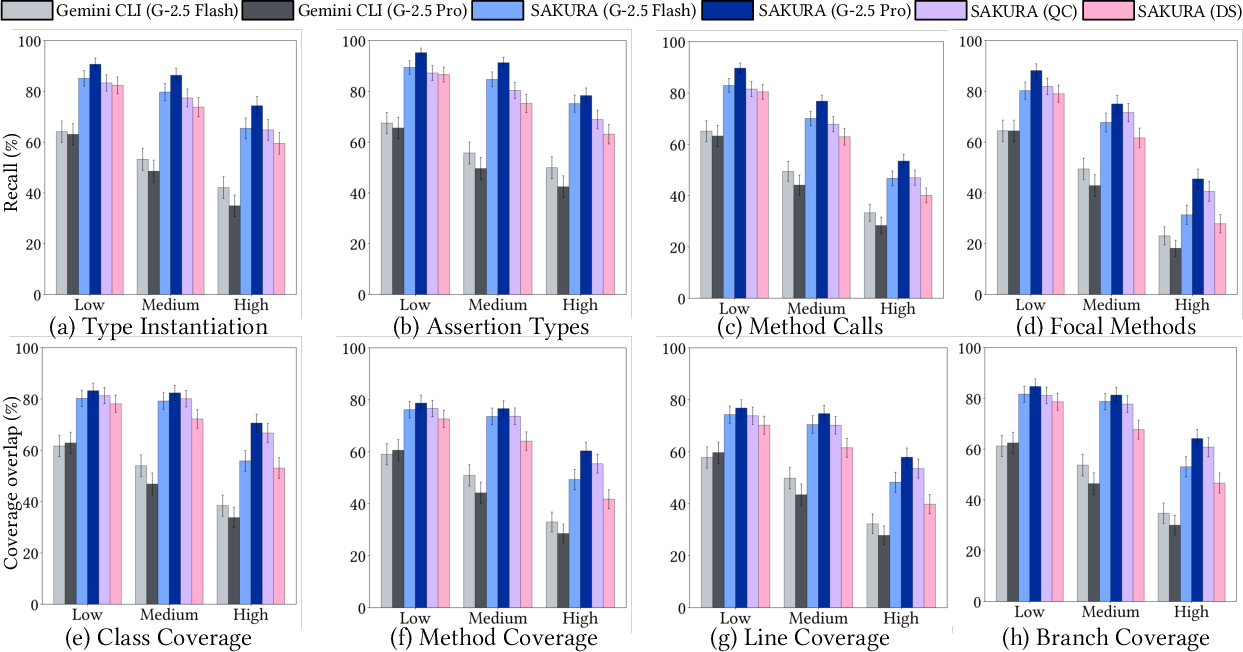
Figure 5: Robustness of coverage and structural fidelity across abstraction levels.
Complexity Sensitivity
Performance stability under focal method count demonstrates Sakura’s resilience: 5+ focal tests achieve 64–85% recall/coverage with Gemini 2.5 Pro, compared to 29–37% for Gemini CLI.
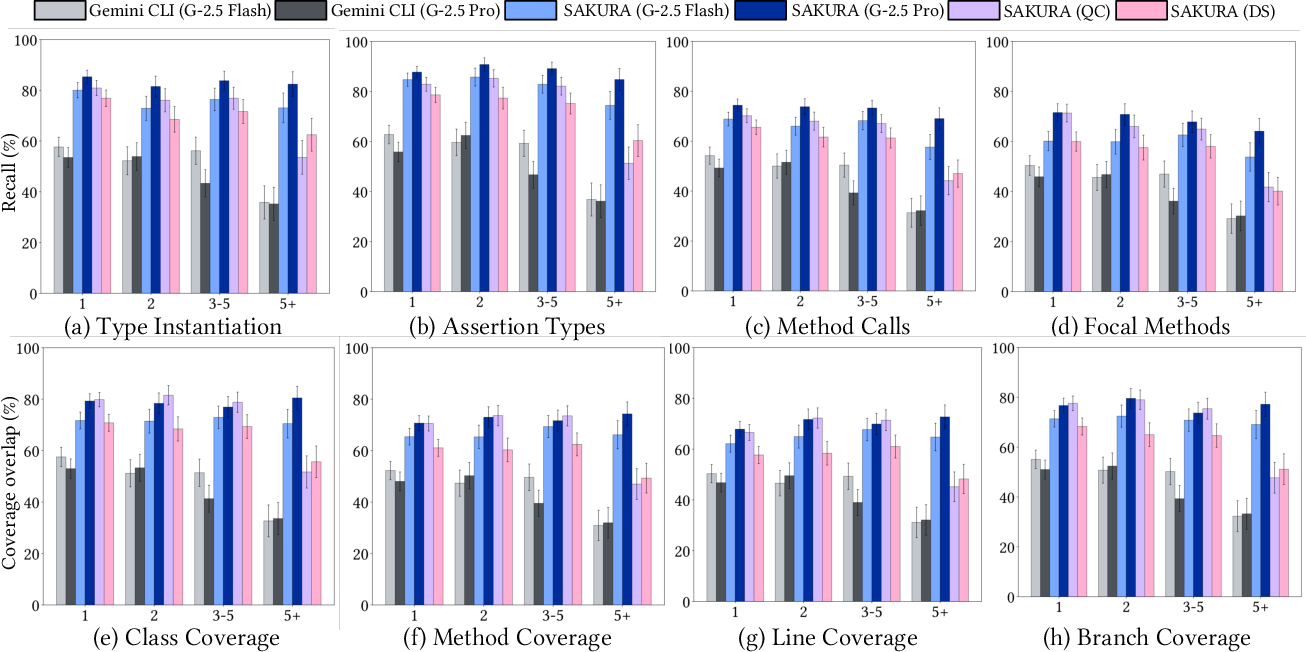
Figure 6: Complexity sensitivity analysis as focal method count increases.
Sakura’s tool utilization is balanced across categories (retrieval, inspection, generation, validation, orchestration) irrespective of model, in contrast to Gemini CLI’s model-dependent skew.
Cost analysis reveals Sakura with Qwen3-Coder costs half as much per test as Gemini CLI with Gemini 2.5 Pro, with empirical performance advantages, validating the multi-agent decomposition’s efficiency/capacity tradeoff.
Implications and Future Directions
Sakura demonstrates the efficacy of domain-specific, multi-agent decomposition for NL-to-code test generation, enabling smaller LLMs to outperform larger commodity agents when aligned with curated toolsets and explicit workflow scaffolding. This has practical implications for scalable, cost-effective automated testing deployment, particularly in CI/CD ecosystems.
The architecture is theoretically extensible to other statically-typed languages and NL-driven API or bug-report-based test generation. Future work can explore uncertainty quantification, fine-tuning/merging of smaller models, adaptive decomposition strategies, and broader domain adaptation.
Conclusion
Sakura provides a scalable, empirically validated approach for generating structurally complex Java tests from NL descriptions, outperforming baseline LLM agentic tools in compilability, behavioral fidelity, and cost efficiency. Structured multi-agent pipelines and code-grounded decomposition are essential for advancing NL-to-test generation beyond unit-method scope, with implications for future research in test automation, REPL-based validation, and agentic software engineering benchmarks (2606.00530).

