AI Can Learn Scientific Taste
Abstract: Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem. For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas. For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact. Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: can an AI learn “scientific taste” — the skill of spotting and creating research ideas that are likely to matter? The authors show that the answer is yes. They build two AIs:
- Scientific Judge, which learns to tell which research ideas are more likely to have a big impact.
- Scientific Thinker, which learns to propose stronger, higher-impact research ideas.
They train these AIs using signals from the scientific community, especially citations (how often a paper is referenced by other papers), which work a bit like “likes” on social media for research.
What questions did the researchers ask?
The paper focuses on two big questions:
- Can an AI learn to judge which research ideas will be more important in the long run?
- Can an AI be trained to generate better research ideas by learning what the scientific community tends to value?
How did they do it?
Think of this like training a good food critic and then using that critic to train a great chef.
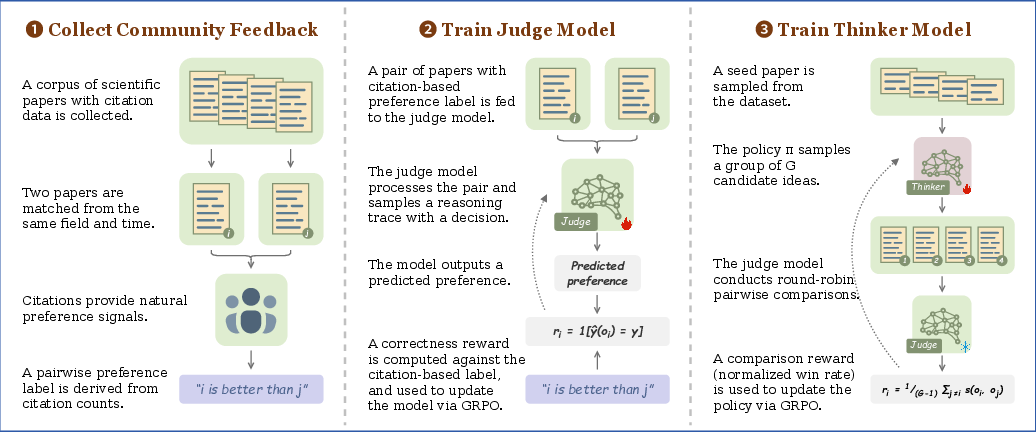
Step 1: Collecting community feedback (the “likes”)
Citations are used as a simple, large-scale way to measure impact — more citations usually mean the work influenced more people. But raw citation counts can be unfair across fields or over time (older papers and certain fields naturally get more citations). To fix this, the authors:
- Paired papers from the same field and published around the same time.
- Labeled each pair by which paper got more citations later.
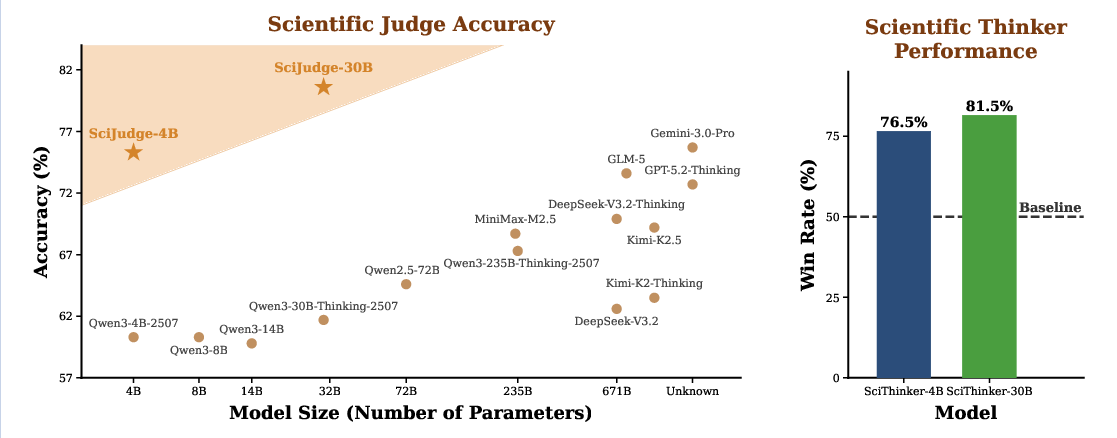
- Built a huge training set of about 700,000 such pairs (called SciJudgeBench).
This turns messy, long-term community behavior into many small, fair comparisons: “Between A and B (same field, similar time), which did the community value more?”
Step 2: Teaching the “critic” — Scientific Judge
Scientific Judge learns to pick the higher-impact paper in each pair. Instead of just memorizing, it practices like an athlete:
- It tries to choose the better paper.
- It gets a simple feedback signal: “right” or “wrong.”
- It adjusts itself to make better choices next time.
This training style is called reinforcement learning. You can think of it as “learn by trying and getting feedback.” Over many attempts, the Judge learns patterns that often lead to higher impact: clarity, generality, usefulness, novelty that others can build on, and so on.
Step 3: Teaching the “creator” — Scientific Thinker
Next, the authors train Scientific Thinker to come up with high-impact ideas. Here’s how:
- Give the Thinker a paper (title and abstract).
- It proposes several new follow-up ideas.
- The Judge compares these ideas pairwise and picks the best ones.
- The Thinker is rewarded when its ideas “win” in these comparisons and learns to produce more like them.
This is like holding a mini tournament between different idea drafts and using the Judge to decide which drafts are better. The Thinker gradually gets better at proposing strong ideas that the Judge (standing in for the community’s taste) thinks are promising.
What did they find, and why is it important?
Here are the main results, explained simply:
- The Judge beats strong AI baselines
- Scientific Judge did better than many advanced LLMs at predicting which paper in a pair would be more impactful.
- It wasn’t just memorizing. It generalized:
- To papers published in later years (predicting future impact patterns).
- To fields it wasn’t trained on.
- Even to peer-review preferences (when “impact” was measured by review scores instead of citations).
- The Thinker proposes better ideas after training
- Using the Judge’s feedback, Scientific Thinker generated follow-up research ideas that were judged (by multiple strong AI evaluators) to be better than ideas from the same base models before training.
- It even competed well with some top commercial models in head-to-head comparisons.
Why this matters:
- It shows that “scientific taste” isn’t a magical human-only sense — it can be learned from large-scale community behavior.
- It’s a step toward AI tools that don’t just search or run experiments, but also help scientists choose better problems and directions.
What does this mean for the future?
This approach — Reinforcement Learning from Community Feedback (RLCF) — suggests a broad path forward:
- Instead of relying only on human labels (which are slow and expensive) or tasks with “right answers” (like math problems), AI can learn from community signals that appear naturally over time, like citations.
- This could be used in other areas where community preference matters (for example, design, education resources, or open-source software ideas).
That said, there are limits:
- Citations aren’t perfect. Some great ideas are slow to be noticed, and different fields have different citation habits.
- The Thinker’s ideas weren’t physically tested in labs; they were evaluated by other models or by proxy signals.
- The Judge mostly read titles and abstracts; richer paper sections might improve judgment.
Even with these caveats, the core message is exciting: by paying attention to what the scientific community actually values over time, AI can learn better scientific judgment and propose more meaningful ideas.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, structured to guide concrete follow‑up research.
Community feedback signal and labeling
- Citation validity and construct alignment: To what extent do citation counts reflect “potential impact” versus popularity, venue prestige, network effects, or topical fads? Quantify how much variance in labels is explained by non-scientific factors.
- Delayed recognition and temporal bias: No model of sleeping beauties or long-tail delayed impact is incorporated. Explore time-series models of citation dynamics and evaluate whether predictions favor short-term gains over long-term impact.
- Confounding factors not controlled: Pairing by (coarse) field and year does not account for venue, subfield micro-trends, author reputation/h-index, institution, team size, collaboration networks, funding, or open-source releases. Add deconfounding (e.g., causal adjustment or stratification) and ablation to assess sensitivity.
- Field taxonomy granularity: Current field categories are coarse. Assess whether finer-grained subfield clustering materially changes pairwise labels and model performance.
- Source and integrity of citation data: The data source(s) for citation counts and the treatment of variants (e.g., arXiv preprint vs. published version), version merges, and updates are unspecified. Document sources, deduplication, and validation of citation counts.
- Self-citations and negative citations: No explicit handling of self-citations, citation farming, or negative citations. Evaluate the impact of excluding self-citations and weighting citations by sentiment or context.
- English/arXiv-centric bias: Training primarily on arXiv abstracts may limit generality to non-English or non-arXiv disciplines (e.g., humanities, clinical medicine). Expand to multilingual and domain-diverse corpora (Scopus, PubMed, SSRN, etc.) and measure transfer.
Dataset construction and evaluation splits
- Pair construction thresholds: The minimum citation gap for “higher vs lower” is not detailed. Investigate how varying thresholds affects label reliability and learning.
- Small test sets and statistical power: In-domain (728 pairs) and OOD sets are limited. Report confidence intervals, conduct power analyses, and scale up evaluation to thousands of pairs per condition.
- Prospective validation: “Future-year” tests are still retrospective. Run a pre-registered, prospective study predicting citations for newly published papers over 12–24 months to test real-time generalization and reduce post-hoc biases.
- Biology/general science transfer: Biology OOD evaluation is small (160 pairs) and performance remains modest. Expand cross-domain tests (life sciences, social sciences, engineering) with larger, balanced sets.
- Leakage and temporal integrity: Clarify safeguards against training–test leakage (e.g., revisions, cross-listing) and ensure all training data precede evaluation windows in all sources.
Modeling choices and training
- Reward model domain shift: Scientific Judge is trained on paper abstracts but applied to compare generated “idea proposals,” which may differ stylistically and structurally. Calibrate or fine-tune the reward model on idea-style texts and test sensitivity to formatting, length, and stylistic artifacts.
- Binary correctness rewards in GRPO: The reward for judge training is 0/1 correctness, ignoring confidence and difficulty. Explore margin-based or calibrated rewards, pairwise ranking losses, and curriculum via hard-negative mining.
- Comparison-based GRPO design: The choice of group size G, round-robin structure, and win-rate aggregation is not ablated. Analyze stability, sample efficiency, and alternative tournament or listwise ranking schemes.
- Baseline breadth: No comparison to classical bibliometric or textual models (e.g., gradient boosting on metadata, topic features), or SFT on the same labels. Implement strong non-LLM baselines and controlled SFT vs RL ablations.
- Interpretability of “taste”: The model’s criteria are opaque. Develop rubric extraction, feature attribution, or concept-based explanations to understand what signals drive judgments (novelty, generality, clarity, method rigor, etc.).
- Calibration and uncertainty: Reported metrics are accuracy only. Measure confidence calibration, score margins, and reliability curves to assess when the judge is uncertain or overconfident.
Robustness, bias, and Goodhart risks
- Reward hacking and over-optimization: Optimizing ideation against a learned reward model risks producing ideas that exploit model idiosyncrasies (buzzwords, trendy topics, verbosity). Conduct adversarial/red-team evaluations and measure robustness to stylistic perturbations.
- Bias amplification: Citations encode structural inequities (geography, institution prestige, gender). Audit for disparate impact in judgments across author demographics, regions, institutions, and subfields; design debiasing objectives or constraints.
- Mode collapse vs diversity: Aligning to “community taste” may encourage safe, incremental ideas at the expense of originality. Quantify diversity/novelty of generated ideas, and explore multi-objective optimization for impact and diversity.
- Feedback loops and ecosystem effects: Using the model to rank newborn papers or drive ideation could entrench existing trends. Simulate and monitor feedback loops and develop countermeasures (e.g., exploration incentives, diversity quotas).
- Adversarial and distributional robustness: Evaluate susceptibility to prompt injection, exaggerated claims, or domain shifts (e.g., experimental vs theoretical papers); test multilingual robustness and non-standard abstract styles.
Evaluation of ideation quality
- Reliance on LLM judges: Idea quality is judged by SOTA LLMs, not human experts, introducing circularity. Run blinded expert panel evaluations across fields and compare inter-rater reliability and agreement with the model.
- Real-world validation: No downstream execution or tracking of idea uptake. Pilot studies implementing a subset of generated ideas, or measure proxy outcomes (e.g., expert ratings, workshop acceptances) over time.
- Cross-reward sensitivity: Show that ideation improvements persist when using alternative reward models (e.g., peer-review trained RMs, ensemble RMs) to rule out overfitting to a single judge.
- Safety and dual-use: High-impact ideas can include dual-use risks. Add safety filters and human-in-the-loop gates; evaluate for generation of harmful or unethical research directions.
Generalization claims and scope
- Stronger, longer-horizon OOD tests: Temporal OOD limited to 2025; validate across multiple future years and in less-related disciplines (e.g., clinical trials, economics).
- Transfer across evaluation criteria: ICLR peer-review transfer is shown, but many venues and criteria differ. Evaluate on other conferences/journals and alternative metrics (acceptance decisions, awards, downstream code/data reuse).
- Beyond abstracts: The judge ignores methods, results, and figures. Test whether adding sections (methods, related work) or structured metadata (venue, code links) improves judgment while controlling for confounds.
Reproducibility and reporting
- Detailed data pipeline: Provide full documentation for field assignment, pair matching, citation window, de-duplication, and thresholds; release code and (where licenses permit) paired IDs and labels.
- Compute and efficiency: Report training costs and scaling efficiency; explore lighter-weight techniques (e.g., preference distillation) to democratize use.
Conceptual scope of “scientific taste”
- Feasibility and execution-aware criteria: Current formulation focuses on predicted impact, not feasibility, rigor, reproducibility, or resource constraints. Extend the definition and training signals to include feasibility and risk.
- Multi-signal community feedback: Integrate additional community signals beyond citations (e.g., code/data reuse, downstream benchmarks, clinical uptake, patents, educational adoption) and study their interactions via multi-objective RL.
- Normative considerations: Clarify whether “community preference” should be the optimization target when it may diverge from societal value or scientific risk appetite; propose governance and oversight mechanisms.
Practical Applications
Overview
The paper introduces Reinforcement Learning from Community Feedback (RLCF), a training paradigm that turns large-scale community signals (citations) into pairwise preferences to teach LLMs “scientific taste” (the ability to judge and generate high-potential-impact research ideas). It delivers:
- Scientific Judge: a generative reward model trained on 700K field- and time-matched citation pairs to predict which idea/paper will be more impactful, generalizing across years, fields, and to peer-review signals.
- Scientific Thinker: a policy trained via comparison-based GRPO to propose high-impact follow-up research ideas, using Scientific Judge as the reward model, outperforming strong baselines.
Below are practical applications derived from these findings, methods, and innovations.
Immediate Applications
These can be deployed now with modest integration and guardrails.
- Scientific impact forecasting for preprints and submissions (Academia; Publishing)
- Use Scientific Judge to score/rank titles+abstracts of preprints or submissions, aiding editors, area chairs, and conference triage (desk review, fast-track flags).
- Tools/workflows: “ImpactRank” API for arXiv/SSRN overlays, journal dashboards, conference chair side-panels.
- Assumptions/dependencies: Citations correlate with “impact” in the target domain; field/time-matched pairwise training generalizes to the venue; human-in-the-loop oversight to avoid bias amplification.
- Reviewer assistance and calibration (Academia)
- Provide structured rubrics and comparative judgments on paper pairs to help reviewers calibrate, surface blind spots, and flag potentially undervalued work.
- Tools/workflows: Reviewer copilots that propose comparative arguments and counterpoints; calibration pools scored by Scientific Judge.
- Assumptions/dependencies: Citations as a proxy for community value; careful UX to avoid anchoring; compliance with venue policies.
- Idea-generation copilot for researchers and students (Academia; Education; Daily life)
- Use Scientific Thinker to propose high-impact follow-up ideas given a seed paper, including title, abstract, and suggested methods.
- Tools/workflows: “Follow-up Idea” button in Zotero/Notion/Obsidian; lab brainstorming assistants; course project ideation aides.
- Assumptions/dependencies: Quality relies on seed abstracts and domain alignment; human vetting for feasibility/novelty; avoid overfitting to mainstream ideas.
- Strategic literature scouting and watchlists (Industry R&D; Tech transfer; VC/Deep tech)
- Rank incoming literature to prioritize reading and identify emerging high-impact directions aligned with product or investment theses.
- Tools/workflows: Portfolio scout dashboards; alerts for “likely-to-influence” papers; integration with internal knowledge bases.
- Assumptions/dependencies: Domain transfer from academic citations to industry-relevant impact; need fine-grained field filters.
- Grant and internal proposal triage (Funding agencies; University departments; Corporate R&D)
- First-pass ranking and clustering of proposals/pitches by predicted community value to allocate expert attention.
- Tools/workflows: Triage queues; panel preparation packets with side-by-side comparisons (pairwise justification).
- Assumptions/dependencies: Training on analogous corpora (past funded proposals and outcomes) improves accuracy; maintain fairness/DEI constraints and novelty exploration quotas.
- Benchmarking and post-training for open-ended tasks (AI/Software)
- Adopt SciJudgeBench and comparison-based GRPO to train alignment objectives for other open-ended outputs (e.g., research summaries that peers engage with).
- Tools/workflows: “Taste-aligned” reward modeling for summarization, tutorial writing, or design suggestions using community signals (stars, upvotes).
- Assumptions/dependencies: Availability of reliable community feedback and pairwise conversion; compute for GRPO; monitoring for Goodharting.
- Meta-research and field trend analysis (Science policy; Bibliometrics)
- Use Scientific Judge to study cross-field patterns of “taste,” temporal shifts, and alignment between citations and peer review.
- Tools/workflows: Dashboards comparing predicted vs. realized impact; bias audits across subfields.
- Assumptions/dependencies: Access to longitudinal metadata; careful interpretation to avoid equating impact solely with popularity.
- Academic reading list prioritization (Education; Daily life)
- Personalized reading queues ranked by predicted long-term influence and relevance to learning goals.
- Tools/workflows: Browser extensions for arXiv/Scholar; course syllabi generators highlighting “foundation + likely-to-influence” readings.
- Assumptions/dependencies: Alignment to learner’s domain; controls for recency and diversity.
Long-Term Applications
These require additional research, scaling, domain adaptation, or governance.
- AI co-scientist with end-to-end “taste” (Academia; Industry R&D)
- Integrate Scientific Judge/Thinker into closed-loop systems: idea → experimental design → execution → analysis → write-up, with community-aligned taste guiding choices.
- Tools/workflows: Lab co-pilots tied to ELNs/LIMS; iterative RLCF loops as community reaction accrues.
- Assumptions/dependencies: Reliable proxies beyond citations (replication, practical adoption); robust safety and attribution governance.
- Funding portfolio optimization and policy design (Science policy; Philanthropy)
- Portfolio-level decision support balancing risk/novelty and expected community value; simulation of topic allocations.
- Tools/workflows: “Taste-aware” portfolio optimizers with diversity/novelty constraints; scenario planning.
- Assumptions/dependencies: Broader feedback signals (societal/clinical impact); governance to avoid homogenization and systemic bias.
- Cross-domain RLCF for product/design “taste” (Software; Product; Open source)
- Train “taste” models using community signals like GitHub stars, npm downloads, PR acceptance, StackOverflow upvotes to guide PR triage, API design, and doc generation.
- Tools/workflows: Maintainer dashboards; PR/issue ranking assistants; code review copilots with community-aligned heuristics.
- Assumptions/dependencies: High-quality, de-biased signals; pairwise construction preserving temporal/contextual confounders.
- Education content and pedagogy optimization (Education)
- Learn “pedagogical taste” from engagement and learning-gain signals to propose better exercises, explanations, and curricula.
- Tools/workflows: Courseware authoring copilots; A/B-tested lesson evolution guided by community feedback.
- Assumptions/dependencies: Ethical data collection; outcomes-based signals (learning gains) preferred to popularity metrics.
- Clinical and translational research prioritization (Healthcare; Biomedicine)
- Predict which studies or trial designs are likely to produce clinically meaningful and adoptable outcomes, beyond academic citations.
- Tools/workflows: Trial design advisors; translational pipeline triage integrating guideline adoption and real-world evidence signals.
- Assumptions/dependencies: Shift from citations to clinical endpoints, safety and equity constraints; stringent validation and regulatory oversight.
- Journal and conference process reform (Publishing; Academia)
- Semi-automated triage and panel formation; reviewer-paper matching emphasizing diversity of ideas and fields while forecasting impact.
- Tools/workflows: Multi-objective triage (impact × novelty × field diversity); reviewer calibration games.
- Assumptions/dependencies: Community consent; transparency mechanisms; guardrails against anchoring and trend-chasing.
- National/sectoral foresight and technology roadmapping (Policy; Energy; Robotics; AI)
- Long-horizon forecasts of which research directions cascade into standards, open-source ecosystems, or industrial adoption.
- Tools/workflows: Foresight simulators; policy briefs prioritizing infrastructure and education investments.
- Assumptions/dependencies: Incorporate heterogeneous signals (standards citations, patent families, deployment metrics); uncertainty reporting.
- Enterprise knowledge management with internal signals (Industry; Knowledge ops)
- Learn “organizational taste” from usage of docs, dashboards, and resolved tickets to propose higher-value internal content and projects.
- Tools/workflows: Internal RLCF pipelines using access logs and feedback; proposal ranking for roadmaps.
- Assumptions/dependencies: Privacy-preserving data use; bias controls (team size, visibility effects).
- Creative and cultural content guidance (Media; Creative industries)
- Adapt RLCF to learn audience-aligned taste (responsibly) from engagement signals for scientific communication, educational media, or public-interest explainers.
- Tools/workflows: Explainer topic selection; editorial calendars guided by long-term engagement, not clicks.
- Assumptions/dependencies: Prefer deep engagement/retention over vanity metrics; editorial ethics.
- Generalized comparison-based GRPO for open-ended alignment (AI/ML)
- Apply the paper’s comparison-based GRPO broadly to tasks without ground-truth labels (e.g., policy drafts, UX copy, safety-critical suggestions) using domain-appropriate reward models.
- Tools/workflows: Alignment suites with pairwise tournament rewards; plug-in reward models per domain.
- Assumptions/dependencies: Robustness to reward misspecification; continuous auditing to prevent Goodharting.
Cross-cutting assumptions and dependencies
- Signal quality and bias: Citations and similar community signals are imperfect; pairwise field/time matching mitigates, but does not eliminate, bias toward popular topics or well-resourced fields.
- Domain adaptation: Best performance requires training on domain-matched data and signals (e.g., peer-review scores, adoption metrics, clinical outcomes).
- Governance and ethics: Systems must support diversity and novelty, report uncertainty, and avoid becoming self-fulfilling filters that homogenize research.
- Human-in-the-loop: Applications should augment—not replace—expert judgment, with transparent rationales and contestability.
- Technical requirements: Access to large-scale metadata, compute for GRPO, and monitoring for over-optimization against proxy rewards.
Glossary
- Advantage (normalized): In policy gradient methods, the advantage estimates how much better an action is than the baseline; normalizing advantages within a batch stabilizes learning. "Within each group, advantages are normalized:"
- Clipped surrogate objective: A PPO-style objective that clips the policy update to prevent overly large changes and improve stability. "by maximizing a clipped surrogate objective with a KL penalty toward a reference policy"
- Comparison-Based GRPO: A variant of GRPO where rewards are computed from pairwise comparisons among multiple sampled outputs instead of absolute scores. "We therefore design Comparison-Based GRPO"
- Cross-field transfer: The ability of a model trained in one field to generalize its learned judgments to other scientific fields. "This cross-field transfer is notable because different disciplines vary substantially in knowledge, style, and data distribution, yet still exhibit shared patterns of scientific value that can be learned and transferred."
- Cross-metric transfer: Generalization of learned preferences across different evaluation metrics (e.g., from citations to peer-review scores). "This cross-metric transfer indicates that citation-trained models capture community preference patterns that extend beyond the specific feedback signal used during training."
- Cumulative expected impact: The total expected long-term influence of a paper, defined as the sum over expected future citations. "The cumulative expected impact of paper is defined as:"
- Field- and time-matched pairs: Pairing items from the same field and publication period to control for biases when creating preference labels. "train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers"
- Generative reward model: A reward model that produces judgments (often with reasoning traces) which are used as scalar rewards in RL training. "we train Scientific Judge, a generative reward model"
- Group Relative Policy Optimization (GRPO): A policy optimization algorithm that uses group-sampled outputs and relative (normalized) advantages within the group. "using Group Relative Policy Optimization (GRPO)"
- Ideation capability: A model’s ability to generate research ideas with high potential impact. "The ideation capability of a model is characterized by the expected impact of the ideas it proposes."
- Importance ratio: The likelihood ratio between current and old policies for an output, used for importance sampling in policy gradient updates. "where $\rho_i = \pi_\theta(o_i \mid x)\,/\,\pi_{\mathrm{old}(o_i \mid x)$ is the importance ratio"
- In-domain: Data that follows the same distribution as the training data; used to distinguish from out-of-domain evaluations. "Main results on SciJudgeBench (in-domain test set)."
- Judgement capability: A model’s accuracy in predicting which of two research items has higher potential impact. "The judgement capability is:"
- Kullback–Leibler (KL) penalty: A regularization term that penalizes divergence from a reference policy to stabilize optimization. "with a KL penalty toward a reference policy"
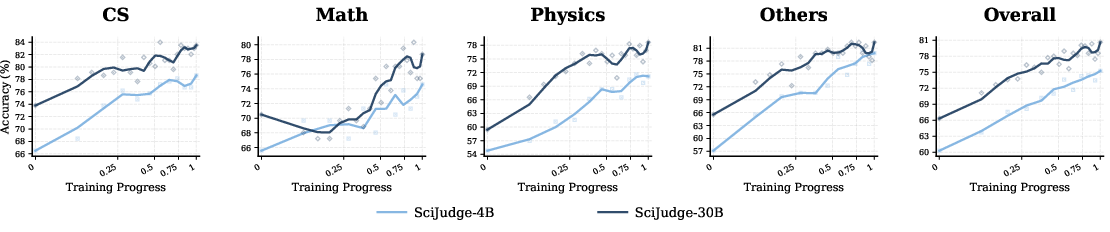
- Log-linear relationship: A relation where performance increases approximately linearly with the logarithm of data size. "The learning curves indicate an approximately log-linear relationship between data scale and performance."
- Metric OOD (ICLR): Out-of-domain evaluation where the target metric differs from training (e.g., peer-review scores at ICLR vs. citation counts). "Metric OOD (ICLR): 611 pairs from ICLR submissions (2017--2026), where preferences are determined by peer review scores instead of citations"
- Out-of-Domain (OOD): Evaluation on data that differs from the training distribution (e.g., different time periods, fields, or metrics). "Temporal OOD results on papers published in 2025, after the training period."
- Pairwise comparisons: Comparing two items to derive a preference label, often more reliable than absolute scoring for open-ended tasks. "we convert absolute feedback into matched pairwise comparisons"
- Peer-review preference: Preferences derived from expert review scores rather than citations or other community signals. "and generalizes to future-year test, unseen fields, and peer-review preference."
- Policy model: The model being optimized to generate outputs (e.g., ideas) that maximize rewards from a reward model. "we train a policy model, Scientific Thinker, to propose research ideas with high potential impact."
- Position bias: The tendency of evaluators (or models) to prefer items based on their presented order; mitigated by swapping positions during evaluation. "To mitigate position bias, we evaluate each pair twice by swapping paper order (AB) and score a prediction as correct only if consistent across both orderings"
- Position-swap consistency: An evaluation criterion where predictions must remain correct after swapping the positions of compared items. "We report pairwise accuracy (\%) with position-swap consistency for predicting which paper has higher citations."
- Preference alignment: Training a policy to align its outputs with preferences captured by a reward model. "For preference alignment, using Scientific Judge as a reward model, we train a policy model"
- Preference modeling: Learning a model (reward model) that can predict which of two items the community prefers. "For preference modeling, we train Scientific Judge"
- Reference policy: A fixed or slowly changing policy used as a baseline in KL-regularized optimization. "toward a reference policy $\pi_{\mathrm{ref}$"
- Reinforcement Learning from Community Feedback (RLCF): An RL paradigm that uses large-scale community signals (e.g., citations) as supervision for preference learning. "we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision"
- Reinforcement Learning from Human Feedback (RLHF): An RL paradigm that learns from human preference annotations via a reward model. "Reinforcement Learning from Human Feedback (RLHF) collects human preference annotations, trains a reward model to capture human preferences, and then optimizes a policy model with that reward"
- Reinforcement Learning with Verifiable Reward (RLVR): An RL paradigm that relies on verifiable signals like ground-truth answers or unit tests to compute rewards. "Reinforcement Learning with Verifiable Reward (RLVR) instead leverages verifiable rewards provided by ground-truth answers, unit tests, or formal checkers"
- Reward model: A model that assigns scalar rewards (often via preference judgments) used to train a policy. "using Scientific Judge as a reward model, we train a policy model"
- Round-robin tournament: A comparison scheme where each sampled output is compared against all others to derive relative rewards. "We conduct a round-robin tournament judged by the reward model."
- Supervised fine-tuning (SFT): Training a model directly on labeled examples to imitate desired outputs, as opposed to optimizing via RL. "typically uses supervised fine-tuning (SFT) to train models on reviewer feedback"
- Temporal extrapolation: Assessing whether learned judgments generalize to future time periods beyond the training window. "We evaluate Scientific Judge under three complementary settings that test in-domain judgment, temporal extrapolation, and cross-metric transfer."
- Verifiable reward: A reward that can be deterministically checked against objective criteria (e.g., unit tests), instead of subjective preferences. "leverages verifiable rewards provided by ground-truth answers, unit tests, or formal checkers"
- Win rate: The fraction of pairwise matchups an output wins within a group, used as a scalar reward in comparison-based training. "The comparison-based reward for is the research idea's win rate within the group"
Collections
Sign up for free to add this paper to one or more collections.