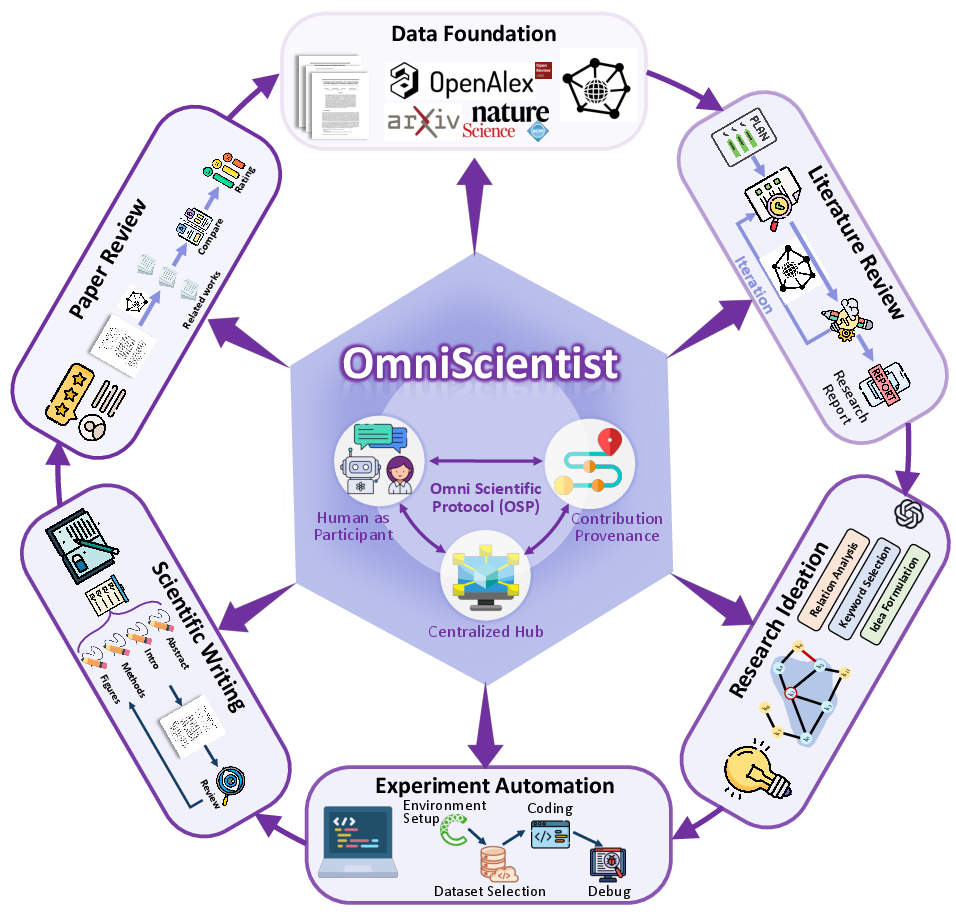
OmniScientist: Toward a Co-evolving Ecosystem of Human and AI Scientists
Abstract: With the rapid development of LLMs, AI agents have demonstrated increasing proficiency in scientific tasks, ranging from hypothesis generation and experimental design to manuscript writing. Such agent systems are commonly referred to as "AI Scientists." However, existing AI Scientists predominantly formulate scientific discovery as a standalone search or optimization problem, overlooking the fact that scientific research is inherently a social and collaborative endeavor. Real-world science relies on a complex scientific infrastructure composed of collaborative mechanisms, contribution attribution, peer review, and structured scientific knowledge networks. Due to the lack of modeling for these critical dimensions, current systems struggle to establish a genuine research ecosystem or interact deeply with the human scientific community. To bridge this gap, we introduce OmniScientist, a framework that explicitly encodes the underlying mechanisms of human research into the AI scientific workflow. OmniScientist not only achieves end-to-end automation across data foundation, literature review, research ideation, experiment automation, scientific writing, and peer review, but also provides comprehensive infrastructural support by simulating the human scientific system, comprising: (1) a structured knowledge system built upon citation networks and conceptual correlations; (2) a collaborative research protocol (OSP), which enables seamless multi-agent collaboration and human researcher participation; and (3) an open evaluation platform (ScienceArena) based on blind pairwise user voting and Elo rankings. This infrastructure empowers agents to not only comprehend and leverage human knowledge systems but also to collaborate and co-evolve, fostering a sustainable and scalable innovation ecosystem.
First 10 authors:








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces OmniScientist, a system that tries to turn AI from a simple helper into a real “team player” in science. Instead of treating research like a single puzzle to solve, OmniScientist builds an entire mini scientific world for AI and humans to work together—complete with shared knowledge, teamwork rules, fair credit, and a way to judge results.
In short: it’s a blueprint for an AI-and-human research ecosystem that can plan ideas, run experiments, write papers, and get reviewed—much like real science works today.
What questions are the authors trying to answer?
The paper focuses on a few big questions:
- How can AI do science in a way that matches how humans actually do science—collaboratively, with shared knowledge, clear credit, and peer review?
- How can we give AI a strong “map” of scientific knowledge so it understands not just facts but how ideas connect and evolve?
- How can AI and humans work together smoothly, with clear roles and fair attribution?
- How should we evaluate open-ended research ideas from AI in a fair and transparent way?
How did they build OmniScientist?
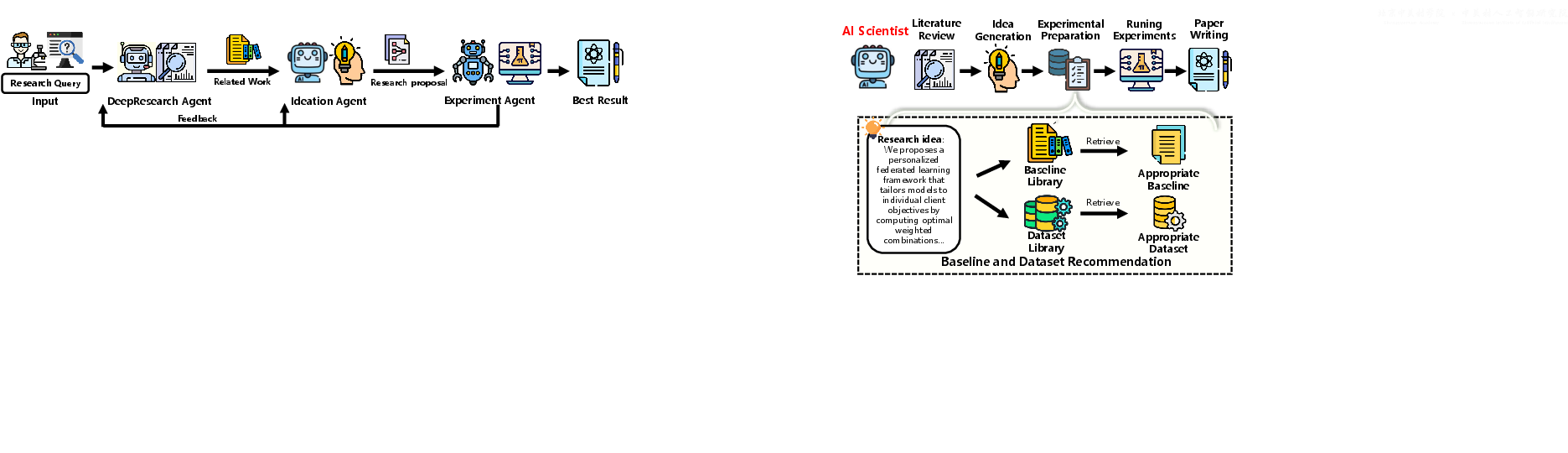
The authors built OmniScientist as a full workflow, plus the “infrastructure” that real science needs. Think of it like building both the lab and the rules for how researchers cooperate.
Here are the main parts, explained in everyday language:
- A structured knowledge map (like a city map of science)
- They collected millions of research papers (from places like OpenAlex and arXiv).
- They connected papers, authors, ideas (concepts), and resources (datasets, models, code) into a giant network—like a map where lines show who cites whom and which ideas go together.
- They didn’t just track “who cites who,” but also the reason why (the citation context). That’s like noting not only that someone mentioned you, but whether they agreed, disagreed, or compared methods.
- Multiple AI “agents” constantly tidy and improve this map: one checks quality, one searches for missing info, one standardizes names, one edits the database, and one reviews changes.
- Deep literature review (finding the right papers, not just similar words)
- Instead of simple keyword search on the web, the system searches inside its verified scientific database.
- It uses both semantic search and the network of citations to follow idea “family trees,” much like a researcher tracing how a concept evolved across papers.
- Specialized agents plan the search, gather papers, judge relevance and quality (like venue and citations), parse PDFs, and write a structured review.
- Idea generation (like guided brainstorming with a map)
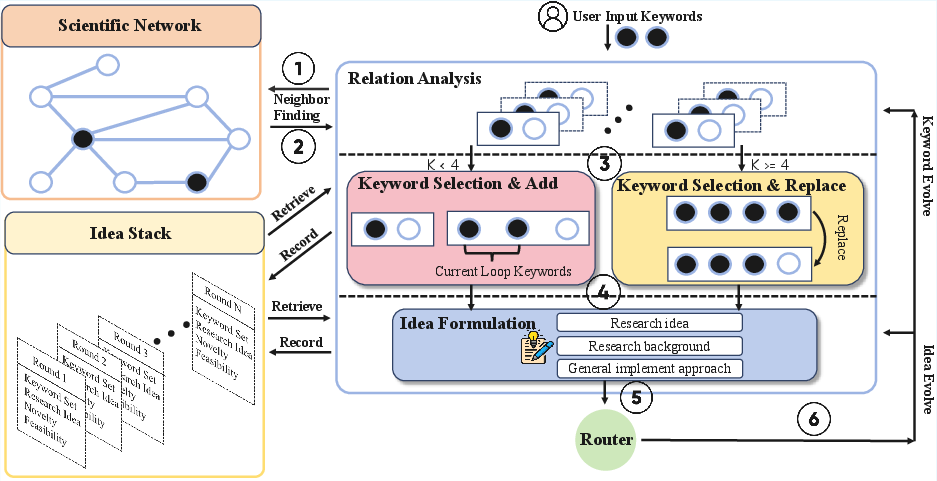
- The system builds a “concept network” from keywords that co-occur in papers.
- It explores related keywords, selects promising ones, and combines them into well-formed research ideas (not just word mashups).
- It keeps an “Idea Stack” to track how ideas evolve over time and uses a critic model to give expert-style feedback on novelty and feasibility.
- Experiment automation (finding the right datasets and baselines, then iterating)
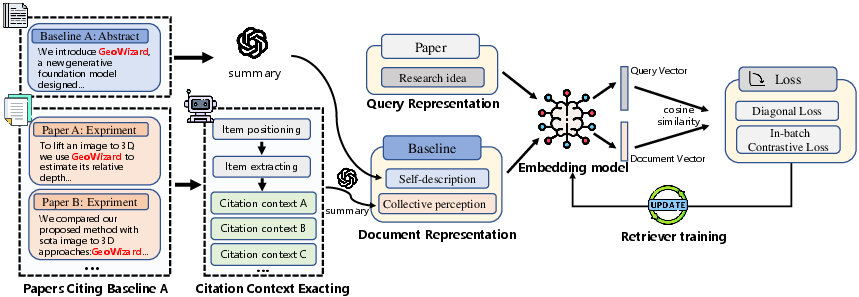
- Before running tests, it recommends which datasets and baseline methods are best—using both the item’s self-description and how other papers describe it (the “collective perception” from citations).
- It then builds reasoning chains through the knowledge map (for example: your paper → shared dataset → another paper → baseline) to make explainable choices.
- A multi-agent loop evolves code, runs experiments, measures results, and learns from errors—like a team doing repeated trial-and-error improvements.
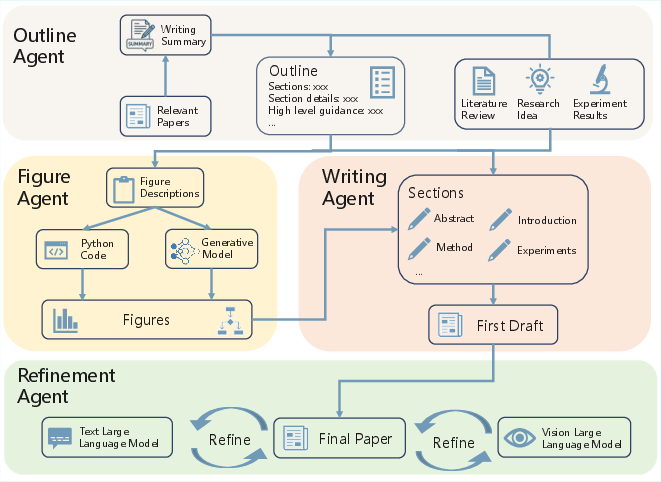
- Scientific writing and review (turning results into papers, then checking quality)
- The system drafts papers with proper structure and style and can generate figures and explain methods clearly.
- It includes a review mechanism to compare with prior work and give actionable feedback.
- Collaboration protocol and fair credit (how people and AIs work together)
- OSP (Omni Scientific Protocol) is a set of rules and tools so multiple AI agents—and humans—can cooperate smoothly.
- It tracks who contributed what (ideas, code, datasets, results), so credit and responsibility are clear.
- Open evaluation platform (like a science tournament)
- ScienceArena is a public evaluation platform where human experts compare anonymous outputs in pairs (A vs. B) and vote which is better.
- It uses Elo ratings (like chess) to rank quality over time, reflecting community standards.
What did they find, and why does it matter?
The authors report early but encouraging results:
- Cleaner, smarter knowledge base:
- Metadata completeness improved (from 0.965 to 1.000) and correctness improved (from 0.951 to 0.997).
- On a test of questions about relationships between papers, retrieval accuracy improved from 0.70 to 0.88.
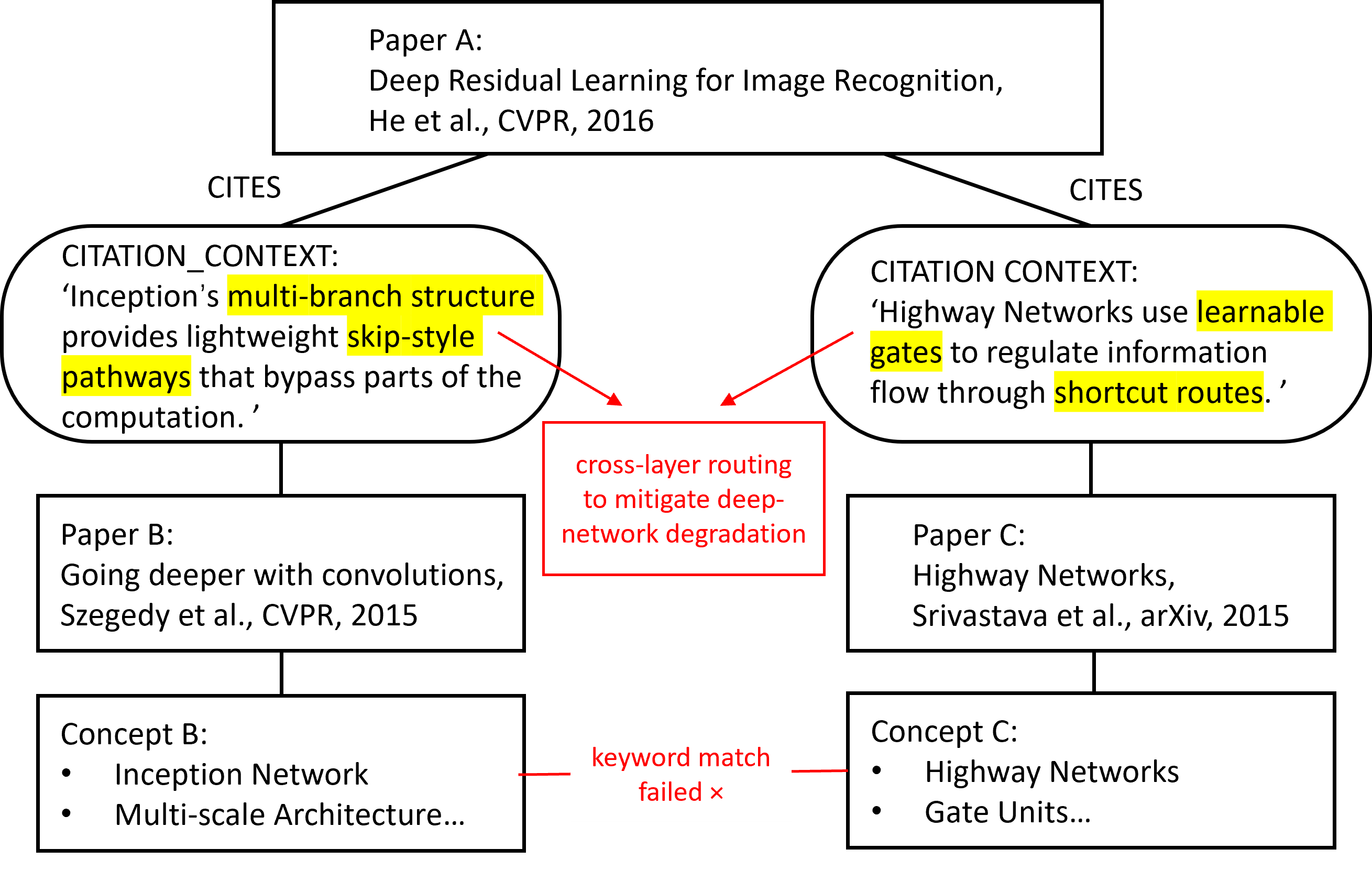
- A case study showed the system can reveal hidden links between ideas that simple keyword search misses—for example, two papers that use different tricks but share a deeper concept (like both enabling “shortcut” information flows in neural networks).
- Better literature reviews with relation-aware retrieval:
- In a comparison, reviews built using the citation network (not just keywords) were more complete, deeper, and more logically consistent.
- Main lesson: high-quality retrieval—especially using relationships in the knowledge map—is the main driver of better scientific writing by AI.
- More grounded idea generation and experiment planning:
- The “Deep Ideation” process uses the concept network to grow ideas in a controlled way, with feedback and evolution.
- The experiment tool recommends datasets and baselines not just by description, but by how the field actually uses them, and explains recommendations via reasoning chains.
Why this matters:
- The system doesn’t just do tasks; it behaves more like a member of the scientific community—aware of norms, credit, and quality control.
- It shows that adding the “social structure” of science (citations, peer review, collaboration) makes AI research outputs more trustworthy and useful.
What’s the bigger impact?
If systems like OmniScientist mature, a few important shifts could happen:
- Faster, fairer, and more reliable science:
- AI can help researchers navigate huge literatures, generate solid ideas, pick the right benchmarks, and write clearer papers.
- Transparent credit tracking encourages healthy collaboration between humans and AI.
- A co-evolving community:
- With platforms like ScienceArena, the broader research community can steer AI’s direction by voting on quality and novelty.
- The AI agents can learn from community feedback, improving over time.
- A new role for AI in science:
- AI moves from “smart tool” to “responsible collaborator” that respects scientific norms—peer review, citations, and accountability.
In essence, OmniScientist is a step toward an AI-human research ecosystem that feels like real science: connected, collaborative, self-correcting, and focused on building trustworthy knowledge.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, formulated as concrete, actionable items for future research.
- End-to-end validation: Provide systematic, task-level benchmarks demonstrating that OmniScientist can take a topic from ideation through experiments to a publication-quality manuscript, including success rates, time-to-result, and comparisons to human-only and other AI-scientist baselines.
- Human expert evaluation: Replace or complement LLM-based survey scoring (e.g., Gemini-2.5-pro) with blinded human expert assessments; report inter-rater reliability, statistical significance, and error analyses.
- Cross-domain generalization: Quantify performance outside AI (e.g., biomedicine, physics, social science), including domains with limited arXiv coverage, non-English literature, monographs, and patents.
- Data licensing and access: Clarify handling of paywalled content, license compliance, and provenance for full texts; define policies for restricted or sensitive datasets.
- Retractions and corrections: Implement and evaluate mechanisms to detect and propagate retractions, errata, and updates across the knowledge graph; measure latency and impact.
- Knowledge graph coverage: Expand schema beyond Paper/Author/Concept/Resource to include Institutions, Funders, Methods, Tasks, Venues, and experimental apparatus; assess how richer ontologies affect retrieval and ideation.
- Entity disambiguation and synonymy: Quantitatively evaluate normalization and disambiguation (authors, datasets, baselines, concepts) with gold standards; report precision/recall for alias merging.
- Citation-context reliability: Validate LLM-synthesized citation contexts against human annotations; measure hallucination rates, bias, and the impact on downstream retrieval/ideation.
- Temporal dynamics: Define update cadence, versioning, and reproducible snapshots of the knowledge graph; measure drift effects on retrieval and ideation quality over time.
- Bias and epistemic diversity: Audit and mitigate biases (e.g., venue prestige, citation counts, geography, language) introduced by network-augmented retrieval; evaluate whether BFS along citation links amplifies echo chambers.
- Retrieval metrics: Report precision/recall, nDCG, and coverage for literature retrieval against curated ground-truth corpora; ablate the contribution of network augmentation vs. embeddings vs. keyword search.
- Parameterization transparency: Justify and evaluate choices for BFS depth, expansion heuristics, and weighting across metadata fields; provide sensitivity analyses and default recommendations.
- Cross-disciplinary link discovery: Test whether the system can identify relevant work across fields lacking direct citation links (e.g., via conceptual analogies); measure novel connection discovery rates.
- Formalization of ideation function g: Specify the aggregation function g and the criteria used in the Relation Analysis Module; provide theoretical justification or empirical calibration.
- Ideation quality metrics: Develop and report standardized measures of novelty, feasibility, and significance (e.g., expert scoring rubrics, subsequent citation outcomes, acceptance rates); include baselines (random recombinations, semantic similarity-only methods).
- Avoiding trivial recombination: Detect and penalize superficial keyword recombinations; measure rates of genuinely novel conceptual synthesis vs. incremental variations.
- Ontology integration: Incorporate structured concept hierarchies (e.g., UMLS, MeSH, CSO) to reduce polysemy and improve keyword selection; benchmark improvements.
- IP and plagiarism controls: Implement plagiarism detection, prior-art checks, and IP risk assessments in ideation and writing; report false positive/negative rates.
- Baseline/dataset recommendation metrics: Provide quantitative evaluation (e.g., nDCG, MAP, Recall@k) against labeled “appropriate baseline/dataset” pairs; include ablations of self-description vs. citation-context representations.
- Chain extraction reliability: Measure precision/recall of “paper–dataset–paper–baseline” chain extraction; validate with human-curated evidence and assess robustness to noisy metadata.
- Generalization across tasks: Test recommendation quality across diverse domains (vision, NLP, reinforcement learning, materials science) and time periods; assess model obsolescence handling.
- Experiment execution safety: Detail sandboxing, resource constraints, and security for code generation/execution; report rates of runtime errors, unsafe calls, and reproducibility across runs.
- Wet-lab and robotics integration: Specify interfaces to physical experiments (protocol translation, instrument control, safety); provide case studies and failure analyses.
- Optimization overfitting: Monitor and mitigate overfitting to benchmarks during iterative experiment loops; include hold-out validation and preregistration-like safeguards.
- Scientific writing fidelity: Evaluate factual consistency, citation accuracy (quote and reference grounding), and figure correctness; include checks for data-to-text fidelity and conceptual diagram clarity.
- Venue compliance: Test automatic formatting, ethics statements, and author contributions per journal/conference policies; measure acceptance-ready compliance.
- Authorship and credit attribution: Formalize OSP’s contribution tracking (weights, granularity, dispute resolution); define authorship policies and align with journal guidelines and legal constraints.
- Collaboration protocol specification: Publish OSP’s formal spec (API, data formats, role definitions, access control, audit trails); evaluate conflict resolution mechanisms and governance models.
- Incentives and accountability: Define incentives for human participation (credit, reputation), accountability for errors, and mechanisms to prevent gaming or free-riding within OSP.
- ScienceArena methodology: Detail reviewer recruitment, expertise verification, rubric design, and bias mitigation; report inter-rater reliability and calibration across domains.
- Elo rating validity: Justify Elo for scientific quality assessment; compare with Bayesian preference models; test robustness to gaming, collusion, and non-transitive preferences.
- External comparability: Calibrate ScienceArena scores against real-world outcomes (acceptance decisions, citation impact); study predictive validity and domain transferability.
- Safety and dual-use risks: Establish red-teaming, content filters, and escalation protocols for sensitive domains (e.g., bio, chem); report coverage and effectiveness metrics.
- Transparency and provenance: Ensure complete provenance logs (ideas, data, code, decisions); expose audit tools to external reviewers; evaluate their usability and completeness.
- Scalability and cost: Quantify computational costs, latency, and carbon footprint; analyze trade-offs between retrieval depth, ideation iterations, and evaluation throughput.
- Continuous learning and stability: Describe how agents co-evolve without mode collapse or catastrophic forgetting; report stability across updates and mechanisms for safe lifelong learning.
- Community integration: Clarify pathways from OmniScientist outputs to mainstream publication, peer review compliance, and community acceptance; pilot collaborations with journals and conferences.
- Legal and ethical compliance: Address data protection, privacy (e.g., author emails, affiliations), and regional regulations; provide audits and compliance reports.
- Reproducibility package: Release code, data snapshots, prompts, and evaluation scripts to enable independent replication; include seeds and environment specs.
- Failure mode taxonomy: Catalog common errors across modules (retrieval gaps, spurious chains, experiment failures, writing hallucinations); provide diagnostics and mitigation strategies.
Practical Applications
Immediate Applications
Below are practical applications that can be deployed now, based on the paper’s implemented modules (knowledge graph, literature review, ideation, experiment automation, scientific writing), collaboration protocol (OSP), and evaluation platform (ScienceArena).
- Research-grade literature review co-pilot for R&D teams
- Sectors: software/ML, healthcare, materials, energy
- Tools/workflows: OmniScientist Literature Agent + Elasticsearch + relation-aware BFS over the scientific network; structured PDF parsing and Sketchboard drafting
- Use cases: topic scoping, state-of-the-art surveys, replication checks, competitor analyses
- Assumptions/dependencies: access to curated full-text corpora (OpenAlex/arXiv/conference PDFs); adequate compute; domain coverage is strongest in AI-related fields; human review for final quality
- Baseline–dataset recommender for ML experimentation
- Sectors: software/ML, applied AI in industry
- Tools/workflows: collective perception retriever (self-description + citation-context synthesis) + chain-based LLM reranker; integrates with experiment trackers (e.g., MLflow)
- Use cases: picking appropriate benchmarks and baselines for new models; avoiding mismatched datasets; improving comparability and rigor
- Assumptions/dependencies: accurate resource linking in the knowledge graph; access to code repositories; retriever/reranker tuned for target domain
- Automated experiment evolution loop for code optimization and benchmarking
- Sectors: software/ML engineering
- Tools/workflows: Evolution Agent (method variants), Evaluation Agent (execution/metrics), Feedback Agent (error analysis), Sample Agent (prompt/context construction)
- Use cases: hyperparameter tuning, ablation studies, iterative method improvements, CI-like “research pipelines”
- Assumptions/dependencies: secure execution sandbox; reproducible environments; test suites and metrics; guardrails for data/IP usage
- Contribution provenance and credit tracking via OSP
- Sectors: academia, corporate research, open-source communities
- Tools/workflows: Omni Scientific Protocol (OSP) with granular contribution logging mapped to agents and humans; integrates with authoring and experiment logs
- Use cases: transparent authorship attribution (aligned to CRediT-like roles), internal audit trails, dispute resolution
- Assumptions/dependencies: organizational adoption; policy alignment with journals and institutions; clear mapping to existing contribution taxonomies
- Peer evaluation and ranking through ScienceArena for internal reviews
- Sectors: academia, corporate labs, grant committees
- Tools/workflows: ScienceArena blind pairwise voting + Elo rating; anonymized outputs; living leaderboard
- Use cases: triaging internal proposals, comparing alternative approaches, post hoc quality assurance
- Assumptions/dependencies: a pool of qualified reviewers; safeguards against gaming; appropriate scopes per domain
- Reproducibility auditing and resource discovery
- Sectors: software/ML research, publishing
- Tools/workflows: KG explorer linking Papers ↔ Datasets/Models/Tools with citation_context attributes; semantic relation capture
- Use cases: locating missing artifacts, verifying claimed baselines/datasets, assembling replication packages
- Assumptions/dependencies: coverage and correctness of graph edges; access to code/data; license constraints
- Competitive intelligence and trend mapping dashboards
- Sectors: finance (VC), corporate strategy, policy analysis
- Tools/workflows: conceptual bridges via citation_contexts; network analytics for topic evolution; venue/citation metrics
- Use cases: identifying emerging subfields, detecting methodological shifts, strategic investment decisions
- Assumptions/dependencies: up-to-date ingest; calibrated influence metrics (venue prestige, citation impact); domain-tailored semantic models
- Academic manuscript drafting and survey generation assistance
- Sectors: academia, education
- Tools/workflows: Writing Agent with structured parsing, cross-paper synthesis, Sketchboard drafting; figures and related work integration
- Use cases: thesis chapter drafts, literature reviews, workshop papers; classroom assignments
- Assumptions/dependencies: instructor/journal guidelines; human editing for originality, style, and ethics; anti-plagiarism checks
- Grant proposal scoping and gap analysis
- Sectors: academia, public funding agencies, corporate R&D
- Tools/workflows: Literature Agent + Deep Ideation (explore–expand–evolve) to surface gaps and novelty; structured synthesis of prior art
- Use cases: problem framing, risk identification, novelty claims grounded in network relations
- Assumptions/dependencies: domain coverage; calibrated novelty/feasibility evaluation; human PI oversight
- Course-integrated “Research OS” for student projects
- Sectors: education
- Tools/workflows: end-to-end pipeline (review → ideation → experiment → writing), contribution logging via OSP for team projects
- Use cases: capstones, research methods courses, replication competitions
- Assumptions/dependencies: institutional policies on AI use; grading rubrics adapted to AI-augmented workflows; academic integrity controls
Long-Term Applications
Below are applications that require further research, scaling, integration with external systems (e.g., robotics), or broader adoption and governance.
- Autonomous wet lab integration for hypothesis testing
- Sectors: biotechnology, chemistry, materials science
- Tools/workflows: OmniScientist planning + lab robots/ELNs/LIMS; dataset/baseline recommendation extended to assay selection
- Potential products: “AI Co-Scientist” lab orchestration suite
- Assumptions/dependencies: reliable robotic interfaces; safety and compliance; high-fidelity experimental protocols; domain-specific LLMs
- National/regional science planning dashboards
- Sectors: government/policy, funding agencies
- Tools/workflows: macro-level knowledge graph analytics; ScienceArena-style community evaluation signals; topic evolution forecasting
- Potential products: policy intelligence platforms for priority setting
- Assumptions/dependencies: cross-domain corpora (beyond AI), governance frameworks, stakeholder buy-in, bias mitigation
- Journal-scale dynamic peer review augmentation
- Sectors: scholarly publishing
- Tools/workflows: ScienceArena integrated with editorial systems; blind pairwise assessments complementing traditional reviews
- Potential products: “Living” journal leaderboards; review load balancing tools
- Assumptions/dependencies: publisher adoption, ethical safeguards, reviewer incentives, standards for integration
- Standardized AI-human co-authorship governance via OSP
- Sectors: academia, research policy
- Tools/workflows: OSP provenance aligned to CRediT/ICMJE; automated contribution audits
- Potential products: credit certification layer; machine-readable author contribution statements
- Assumptions/dependencies: consensus among journals/funders; legal clarity on AI authorship; cross-institution interoperability
- Marketplace for agent contributions and micro-credits
- Sectors: software, open science ecosystems
- Tools/workflows: OSP-based provenance and attribution; escrowed review via ScienceArena; micropayment or tokenized rewards
- Potential products: agent task exchanges; “research gig” platforms
- Assumptions/dependencies: fraud prevention; quality assurance; payment infrastructure; IP/licensing norms
- Clinical evidence synthesis and policy impact analysis
- Sectors: healthcare and public health
- Tools/workflows: relation-aware retrieval across trial registries and guidelines; ideation to propose testable hypotheses; policy simulation
- Potential products: clinical decision evidence hubs; HTA support tools
- Assumptions/dependencies: access to EHRs/trial data; robust de-identification and privacy; medical expert oversight; regulatory compliance
- Enterprise-wide “Research OS” integrated with data lakes
- Sectors: cross-industry R&D (energy, manufacturing, telecom)
- Tools/workflows: end-to-end pipelines (review → ideation → experiment → reporting), provenance tracking, internal ScienceArena for portfolio review
- Potential products: research operating systems with governance dashboards
- Assumptions/dependencies: data/model governance, IP protection, security accreditation, change management
- Community-driven alternative metrics to impact factors
- Sectors: publishing, research assessment
- Tools/workflows: longitudinal Elo ratings; field-specific panels; transparency dashboards
- Potential products: open, dynamic impact indices
- Assumptions/dependencies: broad community participation; robust anti-manipulation mechanisms; field normalization
- Curriculum-level integration for inquiry-based education
- Sectors: education
- Tools/workflows: scaffolded ideation and peer review experiences; reproducibility assignments using the KG; contribution tracking in teams
- Potential products: courseware and LMS plugins
- Assumptions/dependencies: pedagogical research on AI-augmented learning; assessment redesign; equity and access considerations
- ESG and energy innovation scanning using concept networks
- Sectors: energy, finance (ESG), climate tech
- Tools/workflows: mapping innovation pathways (materials, storage, grid optimization) via co-occurrence and citation-context analysis
- Potential products: ESG innovation trackers; risk/impact analytics
- Assumptions/dependencies: domain corpora (patents, standards); alignment with regulatory taxonomies; continual ingest updates
- Regulatory audit tools for AI-generated research
- Sectors: government, compliance
- Tools/workflows: OSP audit trails; reproducibility checks via KG resource linkage; ScienceArena external validation
- Potential products: certification frameworks for AI research outputs
- Assumptions/dependencies: accepted standards; independent audit bodies; legal frameworks for accountability and redress
Glossary
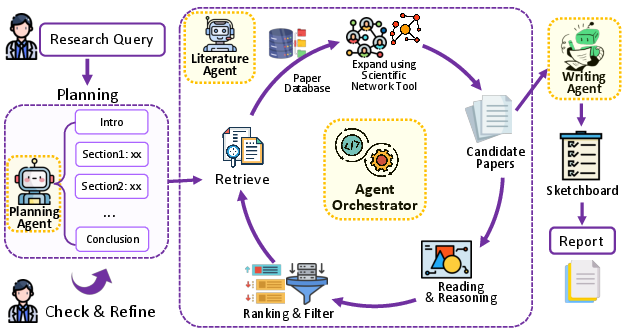
- Agent Orchestrator: A coordinating component that schedules tasks, manages dependencies, and enforces quality across agents. "coordinated by a top-level Agent Orchestrator responsible for dependency management, task scheduling, and global quality control."
- arXiv: An open-access repository of research papers widely used for disseminating preprints, especially in AI and CS. "we integrate the arXiv open-access paper repository, providing approximately 2.6 million PDF full-text documents, covering over 90\% of AI-related publications."
- Bayesian optimization problem: A probabilistic framework for optimizing functions with limited evaluations, often used to tune strategies or experiments. "formalizing scientific discovery as a Bayesian optimization problem, enabling the AI to refine its actions through multi-level experimental loops."
- bi-encoder retriever: A retrieval model that encodes queries and candidates separately into a shared embedding space for efficient matching. "We finetune a bi-encoder retriever on these concatenated representations using a contrastive loss objective, training it to pull a query towards its true associated baselines and datasets."
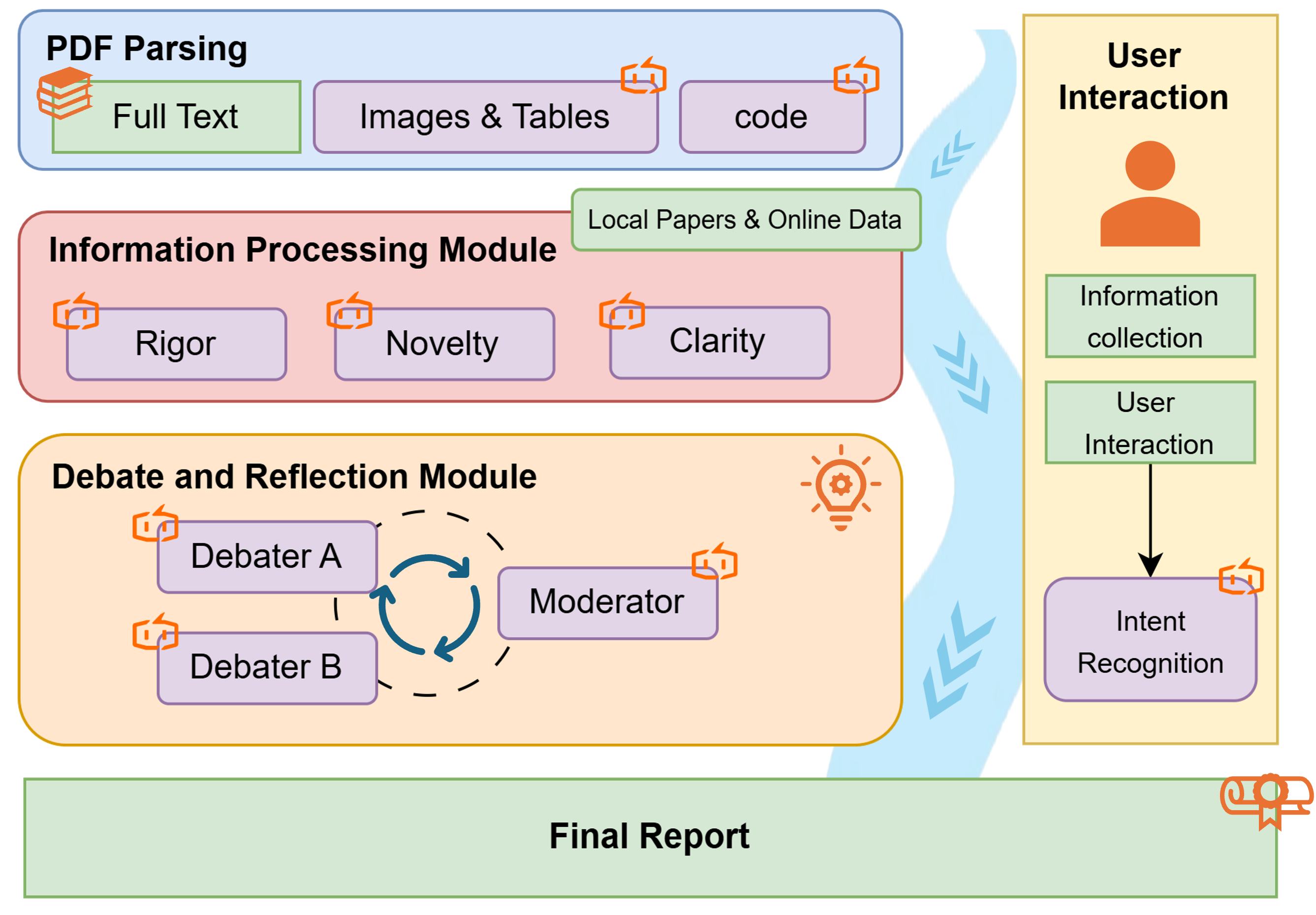
- blind pairwise user voting: An evaluation method where anonymized outputs are compared in pairs without revealing authorship, to reduce bias. "an open evaluation platform (ScienceArena) based on blind pairwise user voting and Elo rankings."
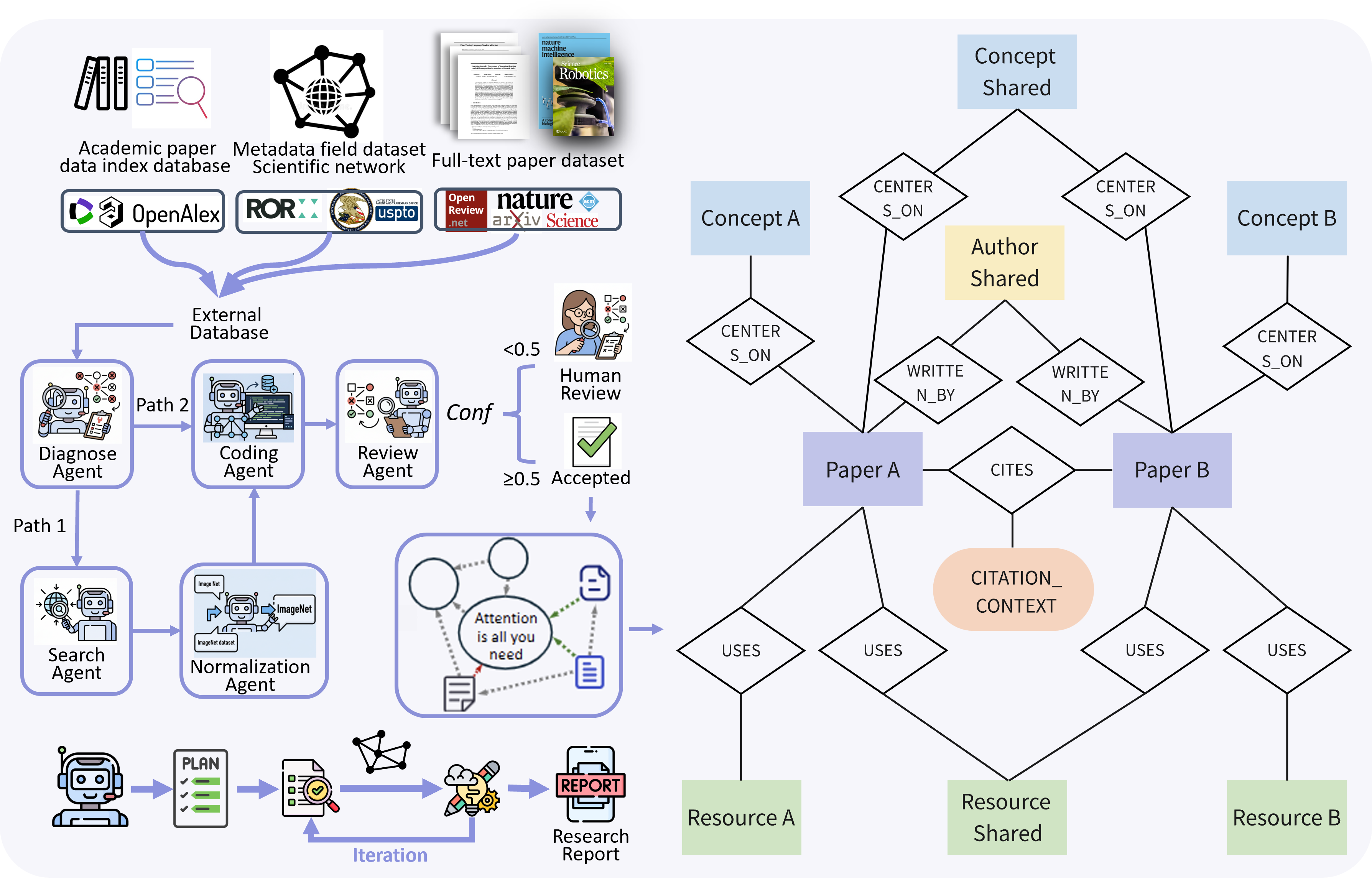
- CENTERS_ON: A knowledge-graph edge type linking a paper to the concept it focuses on. "edges such as CITES (Paper to Paper), WRITTEN_BY (Paper to Author), USES (Paper to Resource), and CENTERS_ON (Paper to Concept)."
- CITES: A knowledge-graph edge type representing a citation from one paper to another. "edges such as CITES (Paper to Paper), WRITTEN_BY (Paper to Author), USES (Paper to Resource), and CENTERS_ON (Paper to Concept)."
- citation_contexts: Textual rationales attached to citation edges that capture why a work was cited and how it is compared. "we attach citation_contexts to CITES edges, preserving the textual rationale behind citations."
- citation networks: Graphs modeling papers and their citation links to trace the lineage and influence of ideas. "a structured knowledge system built upon citation networks and conceptual correlations;"
- collective perception signal: A synthesized summary of how the broader literature describes a target, derived from citation contexts. "We introduce a collective perception signal by first extracting all citation contexts for a given target from the experimental sections of papers in our corpus."
- contrastive loss objective: A training objective that pulls semantically related representations closer and pushes unrelated ones apart. "We finetune a bi-encoder retriever on these concatenated representations using a contrastive loss objective, training it to pull a query towards its true associated baselines and datasets."
- decoupled multi-agent architecture: An agent system design where specialized agents operate modularly with clear role separation. "This workflow is supported by a decoupled multi-agent architecture composed of a Planning Agent, a Literature Agent, and a Writing Agent"
- directed, labeled graph: A graph whose edges have directions and types, used to model structured relationships in a knowledge base. "The knowledge base is organized as a directed, labeled graph comprising four core node types: Paper, Author, Concept, and Resource (datasets, models, tools)."
- Elasticsearch: A scalable search engine enabling multi-field, weighted retrieval across structured text. "we build an Elasticsearch service on top of the local database, enabling multi-field querying across titles, abstracts, author metadata, and other structured fields."
- Elo ratings: A relative skill-rating system originally from chess, used here to rank research outputs based on pairwise preferences. "By aggregating these preferences into dynamic Elo ratings, the platform establishes a living leaderboard that reflects evolving community standards"
- embedding-based Elasticsearch search: Retrieval that leverages vector embeddings to find semantically similar papers via Elasticsearch. "the initial set of candidate papers is obtained from the embedding-based Elasticsearch search."
- epistemic structures: The norms and frameworks governing how knowledge is produced, validated, and organized in science. "By mirroring the protocols and epistemic structures of human scientific research, our data foundation sets the stage for an AI research ecosystem capable of cumulative innovation and sustained interaction with the human scientific community."
- graph schema: The formal specification of node and edge types and their properties in a knowledge graph. "in alignment with the graph schema."
- Idea Stack: A structured memory tracking keyword evolution, idea development, and evaluations across iterations. "the Idea Stack tracks the progression of ideas, offering an overarching perspective on the evolving research process"
- listwise reranker: A ranking model that considers a set of candidates jointly to produce an ordered list. "We then finetune a LLM as a listwise reranker, training it to take the query, the candidate, and its evidential chains as input."
- living leaderboard: A continuously updated ranking that reflects evolving community judgments or performance. "establishes a living leaderboard that reflects evolving community standards"
- multi-agent refinement pipeline: A sequence of specialized agents that audit, enrich, and validate a knowledge graph iteratively. "We therefore deploy a multi-agent refinement pipeline (Figure~\ref{fig:pipeline}, left) that continuously diagnoses, enriches, and validates the graph."
- Omni Scientific Protocol (OSP): A standardized collaboration framework for coordinating AI agents and human researchers with contribution tracking. "we propose the Omni Scientific Protocol (OSP), a standardized collaboration backbone designed to orchestrate the complex interactions between multiple AI agents and human researchers."
- OpenAlex: A large open-access academic graph containing paper metadata and citation relationships. "we incorporate the OpenAlex open-access academic graph, one of the most comprehensive scholarly knowledge networks."
- provenance: Recorded origin and lineage of ideas, datasets, and results for attribution and accountability. "This mechanism records the provenance of every idea, dataset, and experimental result"
- reasoning chain: An explicit justification sequence linking evidence to a recommendation or conclusion. "The model's task is to generate an explicit reasoning chain that justifies the candidate's relevance, resulting in a final, interpretable, and precise ranking."
- reasoning-augmented reranker: A reranking model enhanced with evidential chains and generated reasoning to improve relevance judgments. "our objective is to leverage the synergistic relationship between baselines and datasets using a reasoning-augmented reranker, see Figure~\ref{experiment2}."
- ScienceArena: An open benchmarking platform simulating community validation through blind pairwise evaluation and Elo ratings. "ScienceArena employs a blind, pairwise voting mechanism where human experts evaluate anonymized research outputs based on scientific rigor and novelty."
- science of science: The quantitative and theoretical study of how science progresses and is organized. "leverages principles from the science of science~\cite{Fortunato2018ScienceOS}"
- Scientific Network: A graph of co-occurring concepts from literature used to analyze relationships and guide ideation. "The Scientific Network is constructed based on the co-occurrence relationship of concepts in the literature."
- Sketchboard Writing: A structured drafting workspace for iterative synthesis and refinement of literature insights. "Draft Construction via Sketchboard Writing."
- SOTA: Acronym for state-of-the-art, indicating top-performing methods or results at the time. "The system has achieved SOTA performance in several AI-related tasks"
- USES: A knowledge-graph edge type indicating a paper’s use of a resource such as a dataset or model. "edges such as CITES (Paper to Paper), WRITTEN_BY (Paper to Author), USES (Paper to Resource), and CENTERS_ON (Paper to Concept)."
- venue prestige: A measure of the scholarly reputation and impact of a publication venue. "factors such as citation impact, venue prestige, and empirical rigor."
- WRITTEN_BY: A knowledge-graph edge type connecting a paper to its author(s). "edges such as CITES (Paper to Paper), WRITTEN_BY (Paper to Author), USES (Paper to Resource), and CENTERS_ON (Paper to Concept)."
Collections
Sign up for free to add this paper to one or more collections.