AInstein: Assessing the Feasibility of AI-Generated Approaches to Research Problems
Abstract: LLMs demonstrate impressive capabilities across a wide range of tasks, yet it remains unclear whether such success reflects genuine reasoning or sophisticated recall. We introduce AInstein, a framework for testing whether LLMs can generate valid solutions to AI research problems using only their pretrained parametric knowledge -- without domain-specific fine-tuning, retrieval augmentation, or other external aids. Our approach extracts distilled problem statements from high-quality ICLR 2025 submissions, then tasks specialized solver agents with proposing and refining technical solutions through iterative critique loops, mimicking the cycles of proposal, review, and revision central to scientific inquiry. We evaluate AInstein on 1,214 ICLR papers stratified by acceptance tier (Oral, Spotlight, Poster), using an LLM-as-a-judge paradigm guided by a structured rubric, complemented by targeted manual checks. Performance is assessed with three metrics: Success Rate (does the solution address the problem?), Rediscovery (does it align with human-proposed methods?), and Novelty (does it yield valid, original approaches?). Our results reveal that while LLMs can rediscover feasible solutions and occasionally propose creative alternatives, their problem-solving ability remains fragile and highly sensitive to framing. These findings provide the first large-scale evidence on the extent to which LLMs can act as autonomous scientific problem-solvers, highlighting both their latent potential and their current limitations.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a big, simple question: Can today’s AI LLMs come up with real solutions to research problems on their own, using only what they already “know,” and not by looking things up?
To study this, the authors built a testing system called AInstein. It takes real research ideas from many AI papers, turns each idea into a clean, puzzle-like question, and then asks AI models to propose and improve solutions—much like scientists draft, get feedback, and revise their work.
The big questions they asked
The study focuses on three easy-to-understand goals:
- Can an AI propose a solution that actually addresses the research problem?
- Does the AI rediscover the same kind of solution humans used in the original paper?
- If it doesn’t match the original, can it still invent a different but valid solution (something truly new and sensible)?
How did they test it?
Think of AInstein like a science fair for AIs, with two phases and reviewers.
Phase 1: Turning papers into puzzles
The system reads scientific abstracts (short summaries of papers) and rewrites each into a clear “problem statement” without giving away the original solution. This is like taking a math word problem and removing the hint that spoils the answer.
- Why do this? To make sure the AI can’t just copy the known solution. It has to reason from the problem alone.
Phase 2: Asking AI to solve the puzzle
A separate AI model gets only the problem statement and must propose a technical solution. Then, just like schoolwork, it goes through drafts and feedback to make the solution better.
The “review loops” (like peer review, but faster)
There are two kinds of feedback:
- An internal critic: a quick, self-check loop where the AI reviews and revises its own draft multiple times.
- An external critic: a stronger second reviewer (another AI) that gives tougher feedback. If it still isn’t good enough, the AI revises again.
This repeats a limited number of times, just like revising essays until they’re solid.
How they judged the results
To score the solutions, the authors used:
- An AI “judge” guided by a clear rubric (set of rules) and backed up by spot-checks from humans.
- Three main metrics:
- Success Rate: Does the solution make sense and cover what’s needed?
- Rediscovery: Is it essentially the same idea humans used in the original paper?
- Novelty: Is it a new, valid idea that humans didn’t propose?
They tested this on 1,214 real AI research papers from ICLR 2025 (a top AI conference), across different acceptance levels (Oral, Spotlight, Poster). They also made sure the models couldn’t have read these papers before (no peeking), and they did extra checks like text similarity and even a tournament with human judges to rank the best AI configurations.
What did they find?
Here are the main takeaways, explained simply:
- The self-checker matters most. The “internal” model doing the drafting and self-critique was the biggest driver of good results. Stronger internal models made much better solutions than weaker ones, no matter who the external critic was.
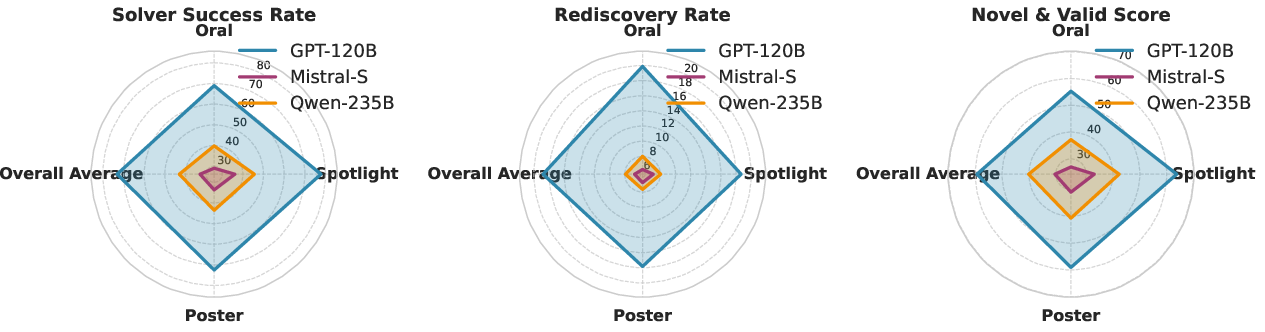
- AIs are good at making workable solutions, but perfect copies are rare. The best systems often proposed solutions that addressed the problems well (think: about three-quarters of the time). However, when judged strictly on “did you exactly rediscover the human authors’ method,” the rate dropped a lot (down to a small fraction, like 15–20%). In other words, exact matches are hard.
- Fresh, valid ideas are common. Even when the AI didn’t rediscover the original solution, it often came up with a different approach that still made sense technically. That’s creativity, not just memorization.
- “How you ask” matters. The AI’s success was sensitive to how the problem was written (the “framing”). Careful, clear problem statements helped unlock better reasoning.
- Difficulty tier didn’t break the AI. The AI performed fairly consistently whether the problem came from very prestigious papers (Orals) or more typical ones (Posters). That suggests the models can handle a wide range of research challenges if framed well.
- Results were robust across judges. Switching the AI judge to a different model gave similar conclusions, and human judges in a head-to-head tournament agreed with the ranking: the setups with the strongest internal model were best.
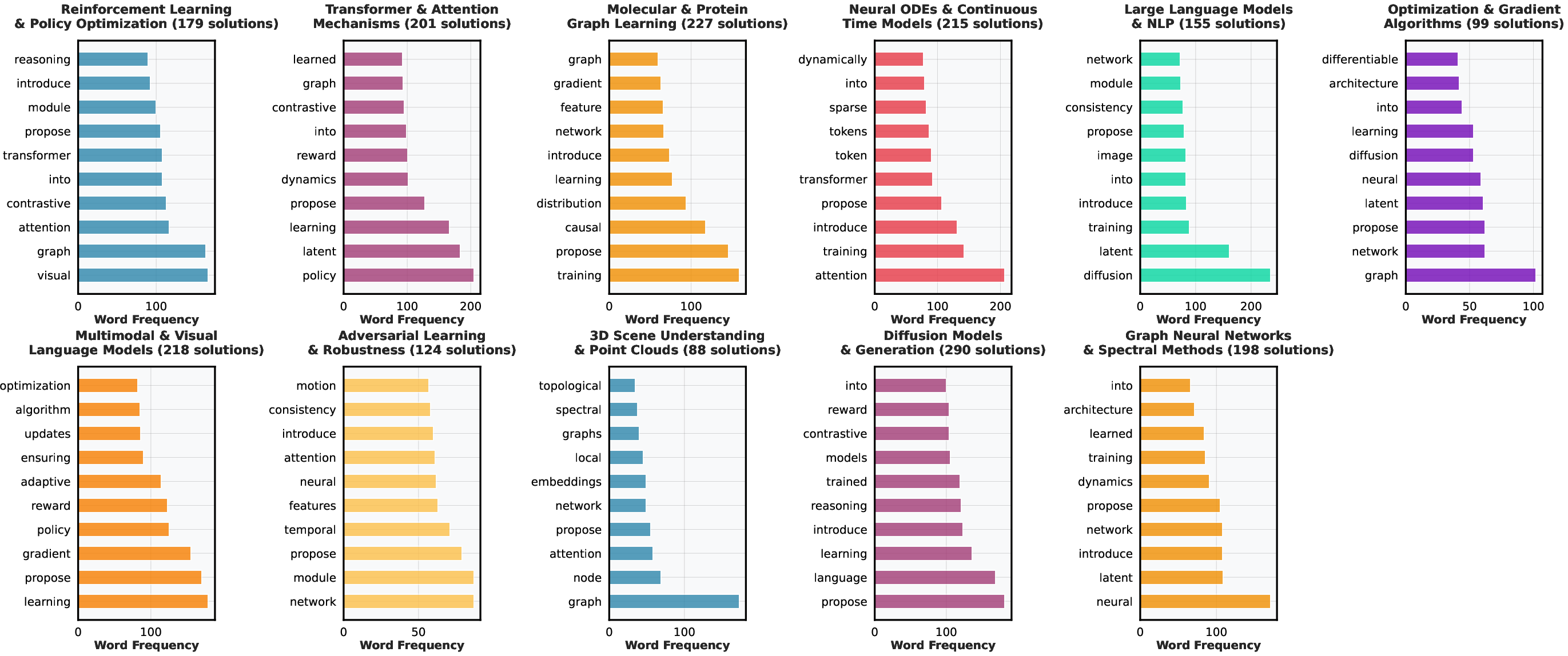
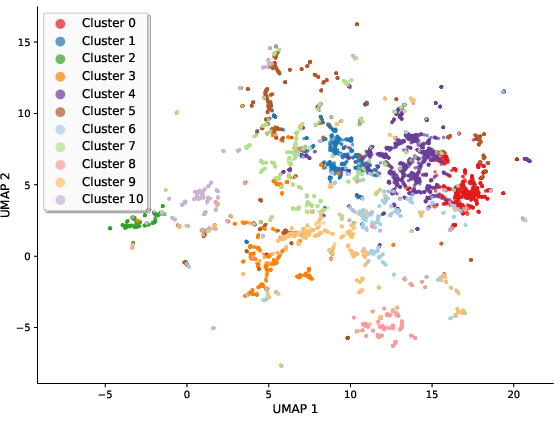
- The AI explored many research styles. When the authors clustered the AI’s solutions, they saw a wide spread: ideas about transformers, reinforcement learning, 3D scenes, molecular modeling, and more. This shows the AI wasn’t just repeating the same template—it explored different “families” of ideas.
Why is this important?
This study gives large-scale, careful evidence about what AI LLMs can do on their own:
- They can be useful scientific “thinkers” that propose detailed, technically sound approaches.
- They are not simply parroting; they can generate new, valid ideas.
- But their reasoning can be fragile—small changes in how you describe a problem can affect results a lot.
- The core reasoning ability of the model (its internal “brain” that drafts and self-corrects) is crucial.
What could this mean for the future?
If refined and used responsibly, AI systems like AInstein could:
- Help researchers brainstorm alternatives faster, spot blind spots, and explore multiple solution paths.
- Lower the barrier to entry for complex fields by providing structured, step-by-step solution plans.
- Speed up early-stage research, while humans provide judgment, testing, and ethical oversight.
At the same time:
- We still need human experts. The AI’s solutions need checking, and perfect rediscovery of human methods is rare.
- Better problem framing and evaluation methods will be key.
- Future work should test beyond AI (e.g., biology, physics) and continue to reduce bias in “AI-as-a-judge” scoring.
In short, AInstein shows that today’s LLMs can act a bit like junior scientists: they can understand a well-posed research puzzle, propose solid plans, and sometimes even invent new ones—but they still benefit from clear instructions, strong self-review, and human oversight.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps, limitations, and open questions that remain unresolved and can guide future research.
- Quantify and control data contamination: despite pre-ICLR-2025 knowledge cutoffs, assess whether models have parametric exposure to preprints or similar prior work (e.g., arXiv versions) and measure how contamination affects Rediscovery and Novelty.
- Validate “parametric-only” claims: explicitly audit that no external retrieval or fine-tuning signals leak through prompts, system instructions, or toolchains; document temperatures, sampling settings, and context windows to rule out hidden aids.
- Strengthen problem extraction fidelity: move beyond abstracts to full-paper-derived problem formulations, with human-authored and independently verified versions to minimize leakage, ambiguity, and information loss.
- Establish a human baseline: have domain experts attempt to solve the abstracted problems without seeing the full papers to calibrate task difficulty and contextualize LLM performance (Success Rate, Rediscovery, Novelty).
- Formalize novelty assessments: define operational criteria for “valid and original” with reproducible standards (e.g., taxonomy-based distance, method components, invariants), and measure inter-rater agreement across multiple expert judges.
- Upgrade Rediscovery measurement: replace rubric-only judgments with method-graph alignment, component-level matching, or code-level functional equivalence checks to distinguish near-misses from true rediscovery.
- Execute solutions empirically: implement and test model-generated solutions (code, experiments) to verify technical feasibility and performance claims beyond textual plausibility.
- Report ablations on refinement loops: isolate the contributions of internal vs. external critics (Mi vs. Me), loop depth (MaxInternalAttempts, MaxExternalAttempts), and critique prompt structure via systematic ablations.
- Characterize prompt sensitivity: formally measure “conceptual activation energy” by mapping performance as a function of prompt complexity, constraints, exemplars, and role framing; fit curves to quantify sensitivity.
- Benchmark across more models: extend beyond three families to include frontier proprietary and open models, smaller and larger scales, and diverse pretraining regimes; analyze scaling trends for reasoning vs. recall.
- Analyze task difficulty beyond tiers: derive a problem-complexity score (e.g., number of constraints, required math formality, domain breadth) and correlate with Success Rate, Rediscovery, and Novelty.
- Increase human evaluation robustness: expand evaluator pool, ensure true double-blinding (including stylistic masking), report inter-rater reliability (e.g., Cohen’s κ), and increase ELO sample sizes for stable rankings.
- Mitigate LLM-judge circularity: avoid self-judgment by diversifying evaluators (cross-model, human experts), calibrate rubric thresholds (τ) via pilot studies, and report sensitivity of conclusions to judge choice.
- Operationalize leakage detection: develop automated detectors for solution hints in problem statements (e.g., pattern-based heuristics, embedding similarity to original methods) and quantify leakage rates.
- Calibrate embedding-based metrics: validate that embedding similarity reflects problem-solution alignment rather than surface style; test multiple embedding models and report stability across seeds and instruction prefixes.
- Assess cluster stability: evaluate robustness of KMeans++ clusters and UMAP projections across seeds, embedding choices, and dimensionality reductions; quantify cluster validity (e.g., silhouette scores).
- Explore mechanistic links: connect behavioral success/failure to model internals (circuits, features) via mechanistic interpretability; identify which subcircuits correlate with successful scientific reasoning.
- Investigate failure modes: categorize systematic failures (e.g., causal reasoning, formal proofs, experimental design, statistical validity) and map them to specific prompt features, domains, or model families.
- Evaluate generalizability to other sciences: port AInstein to biology, physics, and chemistry; adjust rubrics and validation to domain norms (e.g., simulation, theorem proving, empirical protocols) and compare cross-domain transfer.
- Introduce stronger baselines: compare against retrieval-augmented pipelines, tool-using agents (code execution, theorem provers), and hybrid human-AI co-design to quantify gains attributable to parametric reasoning alone.
- Measure compute–quality trade-offs: relate loop iteration counts and model size to marginal quality improvements and cost; identify efficient regimes and diminishing returns in refinement.
- Standardize and release artifacts: publish the curated problem statements, prompts, judgments, and code under reproducible licenses; provide detailed rubrics, calibration data, and versioned model configs.
- Address ethical and attribution issues: define policies for authorship credit, plagiarism detection, and responsible use when LLMs generate research solutions that resemble or extend human work.
- Examine stylistic confounds: detect whether judge preferences are influenced by linguistic sophistication (e.g., Flesch scores) rather than substantive technical merit; normalize style in evaluation.
- Differentiate “near-miss” creativity: create a taxonomy for alternative valid solutions (e.g., architectural substitutions, optimization strategies, theoretical reframings) and quantify their distance from original methods.
- Control for abstract length and structure: study how abstract length, density, and writing style impact generalization quality and solver success; normalize inputs or stratify analyses accordingly.
- Validate strict-threshold criteria: justify and test the choice of τ=4 vs. τ=5 thresholds; provide gold-standard equivalence tests and measure how conclusions shift under alternative strictness levels.
- Probe role pairing effects: analyze whether using same-family vs. cross-family pairings for Generalizer, Solver, Mi, and Me introduces biases or complementarities; identify optimal heterogeneity configurations.
- Test long-horizon reasoning: create multi-step problems that require formal derivations, experimental design, and iteration across subproblems; assess persistence and planning under parametric-only constraints.
- Quantify domain coverage: map the 1,214-paper corpus by subfield and ensure balanced representation; report performance differences across subdomains (e.g., vision, RL, theory, systems).
Practical Applications
Practical Applications of “AInstein: Assessing the Feasibility of AI-Generated Approaches to Research Problems”
Below are actionable applications that flow directly from the paper’s framework (problem distillation, solver agents with dual critique loops, LLM-as-a-judge metrics) and findings (strong dependence on internal model capability, framing sensitivity, high rate of valid-but-non-identical solutions, robustness to evaluator choice, cluster-based landscape analysis). Items are grouped by deployment horizon and annotated with relevant sectors, potential tools/workflows, and key dependencies/assumptions.
Immediate Applications
- Research problem distillation and leak-free benchmark creation
- What: Use the Generalizer to convert abstracts into solution-free, high-fidelity problem statements for challenges, exams, and benchmarks.
- Sectors: Academia, software/AI evaluation.
- Tools/Workflows: “Problem distiller” service; benchmark curation pipelines (avoids solution leakage; rubric-based screening).
- Dependencies/Assumptions: Access to capable LLMs; rubric quality; manual spot checks to mitigate subtle leakage and ambiguity.
- Agentic ideation assistant for AI/ML R&D
- What: Deploy the Solver with internal/external critique loops to generate and refine candidate technical approaches to a research problem.
- Sectors: Software/AI, enterprise R&D, robotics, finance analytics.
- Tools/Workflows: Multi-proposal ideation sprints; iterative critique loops embedded in research notebooks (e.g., Jupyter + API).
- Dependencies/Assumptions: Strong internal model; guardrails for feasibility and safety; human-in-the-loop vetting.
- Capability evaluations for scientific reasoning in model procurement
- What: Use AInstein’s Success, Rediscovery, and Novelty metrics to rank LLMs before adoption in R&D or decision-support roles.
- Sectors: Industry AI Ops, MLOps, AI safety, procurement.
- Tools/Workflows: Pre-deployment “capability eval” suite; per-task agent configuration leaderboard.
- Dependencies/Assumptions: Representative problem sets; standardized scoring rubrics; awareness of judge-model bias.
- Editorial triage and meta-review support
- What: Apply LLM-as-a-judge rubrics to pre-screen or assist meta-reviews for conferences/journals (triage, summarization, structure checks).
- Sectors: Scholarly publishing.
- Tools/Workflows: Review assistant dashboards; rubric-aligned feedback drafts; duplicate/near-miss detection via rediscovery signals.
- Dependencies/Assumptions: Ethical policies; transparency to authors; human decision authority to counter bias.
- Grant and proposal scaffolding with novelty checks
- What: Generate multiple plausible solution paths for a problem, clustering alternatives and highlighting “novel-valid” vs “rediscovery-like” paths.
- Sectors: Academia, government labs, corporate R&D.
- Tools/Workflows: Proposal ideation assistants; “novelty heatmaps” across proposed methods.
- Dependencies/Assumptions: Non-retrieval setting can miss known constraints; human literature review remains essential.
- Curriculum and training for scientific inquiry
- What: Teach problem formulation, peer-review cycles, and iterative refinement using the paper’s dual-loop critique paradigm.
- Sectors: Education (undergrad/grad ML, research methodology).
- Tools/Workflows: Classroom exercises to distill abstracts to problems; student-solutions critiqued by internal/external agents; reflective rubrics.
- Dependencies/Assumptions: Instructor oversight; domain alignment beyond AI requires adapted rubrics.
- A/B testing of agent configurations with human-verified ELO
- What: Use ELO tournaments to compare agent stacks (e.g., internal/external pairings) for a target domain/task.
- Sectors: Product teams, applied research groups, platform engineering.
- Tools/Workflows: Pairwise comparison interfaces; anonymized head-to-heads; model selection dashboards.
- Dependencies/Assumptions: Sufficient human raters; consistent task distributions; tournament design to prevent leakage.
- Research landscape mapping and whitespace analysis
- What: Cluster generated solutions to reveal thematic archetypes and “white space” ideas not commonly explored by humans.
- Sectors: Strategy/innovation, VC/tech scouting, corporate R&D portfolio planning.
- Tools/Workflows: Embedding + clustering pipeline; UMAP/keyword dashboards; “trend velocity” trackers.
- Dependencies/Assumptions: Quality of embeddings; interpretability of clusters; ongoing human validation.
- Prompting playbooks and framing ensembles
- What: Operationalize the finding that performance is highly framing-sensitive by deploying prompt ensembles and re-framing strategies.
- Sectors: AI product, applied research, consulting.
- Tools/Workflows: Prompt libraries; re-framing orchestrators; automatic sensitivity sweeps.
- Dependencies/Assumptions: Compute budget for multiple attempts; monitoring for prompt-induced bias.
- Early-stage IP novelty triage
- What: Use “novel-valid” vs “rediscovery” signals as a lightweight screen for potential obviousness before legal review.
- Sectors: IP strategy, tech transfer.
- Tools/Workflows: Internal novelty dashboards; parametric-only ideation comparisons.
- Dependencies/Assumptions: Not a legal determination; must be paired with prior-art searches; beware training data contamination.
- Safer agent workflows via dual-loop critique
- What: Apply internal/external critics to reduce hallucinations and improve rigor in technical drafts, analyses, and model design docs.
- Sectors: Healthcare documentation, finance reporting, safety-critical software.
- Tools/Workflows: Reviewer-agent plugins in writing/coding IDEs; model card generation with critique loops.
- Dependencies/Assumptions: Does not replace domain audit; requires tailored rubrics and risk controls.
- Model selection for internal vs external critic roles
- What: Optimize which models serve as internal self-critic vs external reviewer to maximize solution quality at given cost.
- Sectors: Enterprise AI platform teams, MLOps.
- Tools/Workflows: Cost–quality trade-off dashboards; hybrid open/closed model pairings.
- Dependencies/Assumptions: Stable APIs; reproducible evaluation harness; sensitivity to updates and cutoffs.
Long-Term Applications
- Autonomous cross-domain research agents
- What: Extend AInstein to biology, materials, energy, and robotics with tool use (retrieval, code execution, lab automation) to propose and test hypotheses.
- Sectors: Biotech, materials discovery, energy optimization, robotics control.
- Tools/Workflows: Integrated “design–simulate–test” loops; lab-in-the-loop automation.
- Dependencies/Assumptions: Domain safety guardrails, validated simulators/automation, provenance tracking, regulatory compliance.
- Policy standards for capability evaluations in scientific discovery
- What: Adopt AInstein-like tests as a regulatory capability eval to assess autonomous scientific problem-solving before model release.
- Sectors: Public policy, AI governance, standards bodies.
- Tools/Workflows: Public benchmark suites; third-party audit protocols; model cards with Success/Rediscovery/Novelty scores.
- Dependencies/Assumptions: Multi-stakeholder consensus; judge-model independence; periodic refresh to avoid overfitting.
- Patent office “obviousness” stress tests (research-phase signal)
- What: Use parametric-only agents to probe whether a solution is easily rediscovered under controlled prompts as a weak signal in patent examination.
- Sectors: IP law, patent offices.
- Tools/Workflows: Examination assistants; structured rediscovery trials.
- Dependencies/Assumptions: Significant legal/ethical vetting; strict safeguards against training data leakage; cannot substitute human/legal judgment.
- Dual-use risk red-teaming via parametric-only discovery
- What: Evaluate whether models can independently propose harmful protocols (e.g., bio/chem) without retrieval, informing access controls and mitigations.
- Sectors: Biosecurity, AI safety, national security.
- Tools/Workflows: Secure sandboxes; escalation policies; automated mitigation scoring.
- Dependencies/Assumptions: Expert oversight; containment policies; alignment with safety frameworks.
- End-to-end R&D co-pilots
- What: From problem distillation to proposal, code generation, experiment plans, and iterative refinement with autonomous critiques.
- Sectors: Software/AI, robotics, energy systems, quantitative finance.
- Tools/Workflows: “AInstein Studio” platform; continuous evaluation pipelines; data/version governance.
- Dependencies/Assumptions: Integration with compute, data, simulators; human review gates; cost management.
- Adaptive education systems that teach scientific inquiry
- What: Personalized tutors that guide students through problem formulation, hypothesis generation, critique, and revision.
- Sectors: Education (K–12, higher ed, professional training).
- Tools/Workflows: Tutor agents with rubric-driven feedback; mastery learning loops; instructor dashboards.
- Dependencies/Assumptions: Curriculum alignment; fairness/bias auditing; accessible compute.
- Peer-review augmentation platforms
- What: Institutionalize internal/external critique loops as review co-pilots to improve clarity, rigor, and reproducibility.
- Sectors: Scholarly publishing, open science platforms.
- Tools/Workflows: Structured review templates; reproducibility checklists; reviewer-aid bots.
- Dependencies/Assumptions: Clear boundaries of assistance; conflict-of-interest and transparency policies.
- Synthetic training data and traces for reasoning improvements
- What: Use critique-loop traces to train next-gen models (e.g., Reinforcement Learning from Critique, iterative self-improvement).
- Sectors: Foundation model development.
- Tools/Workflows: Trace harvesting; preference/critique datasets; RLHF/RLAIF variants.
- Dependencies/Assumptions: Data quality and diversity; privacy; non-circular evaluation.
- Domain-specialized AInstein variants with safety and compliance
- What: Tailor the framework for biomed, clinical decision support, and regulated sectors with domain-specific rubrics and guardrails.
- Sectors: Healthcare, pharma, regulated finance, aerospace.
- Tools/Workflows: Domain reviewers; compliance logging; conservative deployment modes.
- Dependencies/Assumptions: Regulatory approvals; validated knowledge bases; strict human oversight.
- Funding portfolio forecasting and roadmap planning
- What: Use solution clusters and novelty dynamics to forecast emerging areas, identify redundancies, and prioritize funding.
- Sectors: Funding agencies, corporate strategy, national R&D planning.
- Tools/Workflows: Cluster evolution dashboards; “white space” opportunity maps; risk-adjusted prioritization.
- Dependencies/Assumptions: Representative corpora; drift monitoring; expert calibration.
- Governance gating keyed to discovery capability
- What: Tie model access levels (e.g., API tiers) to scientifically relevant AInstein scores to reduce misuse while enabling beneficial R&D.
- Sectors: AI platforms, cloud providers, regulators.
- Tools/Workflows: Capability-based access control; continuous monitoring; red-team regression tests.
- Dependencies/Assumptions: Accurate, tamper-resistant evals; periodic re-testing; transparent policies.
- Cross-disciplinary challenge datasets and competitions
- What: Extend problem distillation to physics, economics, and social sciences to drive robust, retrieval-resistant benchmarks and grand challenges.
- Sectors: Academia, public–private innovation ecosystems.
- Tools/Workflows: Curated problem banks; standardized judging protocols; prize-backed challenges.
- Dependencies/Assumptions: Expert-curated rubrics; fair access; careful scope to avoid safety risks.
Notes on key feasibility factors across applications:
- Internal model quality dominates outcomes; budget for stronger internal critics yields large gains.
- Framing sensitivity requires prompt ensembles and multiple trials; compute costs scale with critique depth.
- LLM-as-a-judge introduces bias; use multi-judge ensembles and human verification for high-stakes settings.
- Parametric-only constraints reduce leakage but can miss domain constraints; pair with retrieval/simulation and expert oversight in production.
- IP, safety, and regulatory concerns mandate human-in-the-loop governance, provenance tracking, and transparent disclosures.
Glossary
- Catastrophic forgetting: Abrupt loss of previously learned knowledge when learning new tasks or in changing environments. "How can an online RL agent learn in non-stationary environments and prevent catastrophic forgetting, given only a continuous stream of experience without task labels?"
- Conceptual activation energy: The minimum prompt complexity needed to trigger specific reasoning abilities in an LLM. "Our concept of ``conceptual activation energy'' provides a complementary perspective, focusing on the minimum prompt complexity required to trigger specific reasoning capabilities rather than model scale."
- Cosine Similarity: A measure of angular similarity between two vectors, commonly used to compare text embeddings. "From these embeddings, we compute Cosine Similarity as our primary metric, along with Euclidean distance."
- Data leakage: Unintended access to information that can inflate performance estimates or compromise evaluation validity. "To prevent data leakage and ensure our evaluation tests reasoning rather than retrieval,"
- Deficit score: An aggregate penalty capturing the quality loss in a problem formulation along dimensions like fidelity, abstraction, ambiguity, and leakage. "we calculate a deficit score (d) based on four criteria: Fidelity to the original challenge, Abstraction from implementation details, lack of Ambiguity, and avoidance of solution Leakage."
- ELO rating: A competitive ranking system based on pairwise comparisons, used here to rate agent configurations. "we compute an ELO rating for each agent configuration."
- Embeddings: Vector representations of text used to measure semantic relationships. "For semantic coherence, we generate 4096-dimensional embeddings using Qwen3-Embedding-8B."
- Emergent capabilities: Abilities that appear suddenly as models scale, not predictably extrapolated from smaller models. "The study of emergent capabilities in LLMs has revealed that certain abilities appear suddenly as models scale"
- Euclidean distance: A standard geometric distance between vectors, used here on text embeddings. "From these embeddings, we compute Cosine Similarity as our primary metric, along with Euclidean distance."
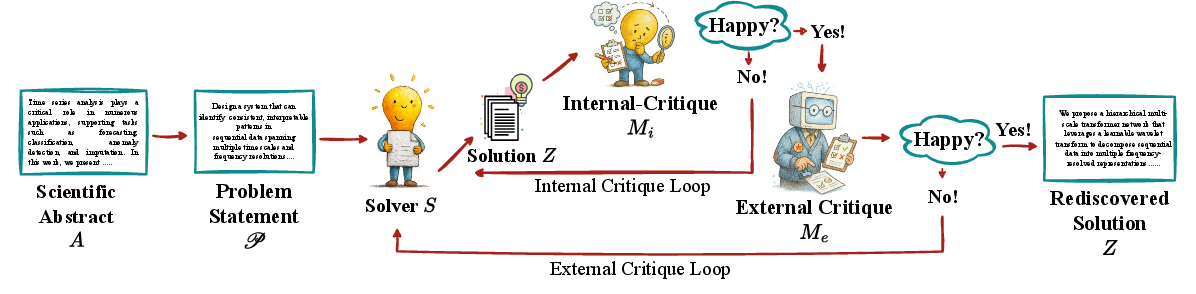
- External Critique Loop: An outer, higher-fidelity review stage using a stronger model to evaluate and refine outputs. "External Critique Loop (Model $\mathcal{M_e$):} The outer loop provides a higher-fidelity review from a stronger external model ."
- Flesch-Kincaid Grade Level: A readability metric estimating U.S. grade level needed to understand a text. "We also assess textual complexity using standard readability scores (e.g., Flesch-Kincaid Grade Level)."
- Generalizer agent: An LLM role that abstracts a scientific abstract into a distilled problem statement without leaking the solution. "a Generalizer agent (an LLM prompted with a specific role) produces a distilled problem statement ."
- Generative replay: A continual learning method that prevents forgetting by generating pseudo-experiences of past tasks. "augments each expert with a lightweight generative replay model."
- Grokking: A learning phenomenon where models abruptly shift from memorization to generalization after extended training. "Similarly, the phenomenon of ``grokking''--where models suddenly transition from memorization to generalization--suggests that understanding and recall exist on a spectrum rather than as binary states"
- Hypernetwork: A network that outputs parameters for another network, enabling dynamic adaptation. "a lightweight hypernetwork predicts, for each token and layer, a sparse subset (e.g., 2-4) of expert feed-forward networks."
- In-context learning: The ability of LLMs to adapt to tasks via examples in the prompt without parameter updates. "Work on in-context learning has shown that models can adapt to new tasks through careful example selection and prompt design"
- Internal Critique Loop: An inner self-review stage where a model iteratively evaluates and revises its own drafts. "Internal Critique Loop (Model $\mathcal{M_i$):} The inner loop simulates fast, low-cost self-correction."
- Iterative critique loops: Cycles of proposal, feedback, and revision used to refine problem statements and solutions. "proposing and refining technical solutions through iterative critique loops, mimicking the cycles of proposal, review, and revision central to scientific inquiry."
- Knowledge cutoff: The latest point in time for which a model has been trained on data, after which it lacks new information. "all models used in our experiments have knowledge cutoffs that predate the ICLR 2025 submission deadline."
- KMeans++: An improved initialization method for k-means clustering that enhances convergence and cluster quality. "We first grouped all solutions into semantically coherent clusters via KMeans++ on their Qwen-8B embeddings."
- Latent knowledge: Information represented implicitly within a model’s parameters that can be selectively activated. "Investigations into models' latent knowledge have revealed that these systems often maintain multiple, sometimes contradictory, representations of the same concept"
- LLM-as-a-judge: An evaluation setup where an LLM scores or judges outputs according to a rubric. "we adopt an LLM-as-a-judge paradigm, where the LLM outputs are reviewed against a structured rubric,"
- Mechanistic interpretability: The study of how models implement computations internally, often by analyzing circuits or features. "The growing field of mechanistic interpretability seeks to understand how models perform specific tasks by analyzing their internal computations"
- Meta-learning: Learning to learn; training systems to rapidly adapt to new tasks from limited data. "integrates a meta-learning component with dual episodic and semantic memory modules."
- Mixture-of-Experts (MoE): Architectures or policies that route inputs to specialized sub-models (experts) via a learned gating mechanism. "routes state-action decisions through a mixture-of-experts policy where gating weights are computed by a softmax over the context"
- Neural implicit reconstruction: Recovering scene geometry or fields with continuous neural representations without explicit meshes. "neural implicit reconstruction via volume rendering"
- Non-stationary environments: Settings where the data distribution changes over time, challenging continual learning. "How can an online RL agent learn in non-stationary environments and prevent catastrophic forgetting"
- Novelty: A metric assessing whether a solution is original and valid relative to human-proposed methods. "Novelty (does it yield valid, original approaches?)."
- Parametric knowledge: Information stored in a model’s parameters from pretraining, used without external tools. "using only their pretrained parametric knowledge---without domain-specific fine-tuning, retrieval augmentation, or other external aids."
- Prompt engineering: Crafting prompts to elicit desired behaviors or improve performance from LLMs. "The sensitivity of LLMs to prompt formulation has been extensively documented, with small changes in wording capable of drastically altering performance"
- Rediscovery: A metric for whether a model independently converges on solutions similar to human ones. "Rediscovery (does it align with human-proposed methods?)"
- Self-play configuration: Using the same model in multiple roles (e.g., both generator and critic) within an evaluation setup. "the GPT-OSS-120B self-play configuration emerging as the clear top performer (ELO 1119)"
- Semantic coherence: The degree to which a solution is semantically aligned with its problem statement. "For semantic coherence, we generate 4096-dimensional embeddings using Qwen3-Embedding-8B."
- Semantic distance: A quantitative measure of dissimilarity between texts based on their embeddings. "Semantic distance and readability metrics by model configuration."
- Signed-distance-function (SDF): A continuous function giving the distance to the nearest surface, used for geometry representation. "a smooth signed-distance-function (SDF) backbone"
- Solver agent: An LLM role that proposes and refines a technical solution to a distilled problem. "A Solver agent (a separate LLM instance) receives only the problem statement and proposes a technical solution ."
- Solution leakage: Inclusion of hints or elements of the original solution in the problem formulation, biasing evaluation. "while minimizing ambiguity and solution leakage (as defined in our evaluation criteria)."
- Success Rate: A metric indicating whether the proposed solution is feasible and complete for the problem. "Success Rate: does the proposed solution address the problem statement?"
- TF-IDF: A term-weighting scheme highlighting words that are informative for a document relative to a corpus. "Each cluster was then assigned an interpretable label using its most characteristic TF-IDF keywords."
- UMAP: A nonlinear dimensionality reduction technique for visualizing high-dimensional data. "The UMAP projection illustrates the distinct grouping of solutions, with each color corresponding to a unique thematic cluster."
- Uncertainty-Guided Sampling (UGS): A sampling strategy that allocates computation based on predicted uncertainty to improve reconstruction or inference. "we employ a differentiable Uncertainty-Guided Sampling (UGS) module"
- Volume rendering: A technique to render 3D fields by integrating densities and colors along rays, used with neural implicit representations. "neural implicit reconstruction via volume rendering"
Collections
Sign up for free to add this paper to one or more collections.

