Jr. AI Scientist and Its Risk Report: Autonomous Scientific Exploration from a Baseline Paper
Abstract: Understanding the current capabilities and risks of AI Scientist systems is essential for ensuring trustworthy and sustainable AI-driven scientific progress while preserving the integrity of the academic ecosystem. To this end, we develop Jr. AI Scientist, a state-of-the-art autonomous AI scientist system that mimics the core research workflow of a novice student researcher: Given the baseline paper from the human mentor, it analyzes its limitations, formulates novel hypotheses for improvement, validates them through rigorous experimentation, and writes a paper with the results. Unlike previous approaches that assume full automation or operate on small-scale code, Jr. AI Scientist follows a well-defined research workflow and leverages modern coding agents to handle complex, multi-file implementations, leading to scientifically valuable contributions. For evaluation, we conducted automated assessments using AI Reviewers, author-led evaluations, and submissions to Agents4Science, a venue dedicated to AI-driven scientific contributions. The findings demonstrate that Jr. AI Scientist generates papers receiving higher review scores than existing fully automated systems. Nevertheless, we identify important limitations from both the author evaluation and the Agents4Science reviews, indicating the potential risks of directly applying current AI Scientist systems and key challenges for future research. Finally, we comprehensively report various risks identified during development. We hope these insights will deepen understanding of current progress and risks in AI Scientist development.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces “Jr. AI Scientist,” a computer system that tries to do what a beginner researcher (like a new grad student) would do: read a published paper, figure out its weaknesses, suggest an improvement, run experiments to test the idea, and write up the results. The paper also carefully reports the risks and problems they saw while building and testing this system, so the research community understands both what’s possible today and what could go wrong.
Objectives and Questions
The authors wanted to answer simple, practical questions:
- Can an AI system produce a scientifically useful paper by improving a specific, real research paper and its code?
- Can it handle real, multi-file projects rather than tiny toy examples?
- How good are the papers it writes compared to other AI systems?
- What are the main risks and failure modes we should watch out for?
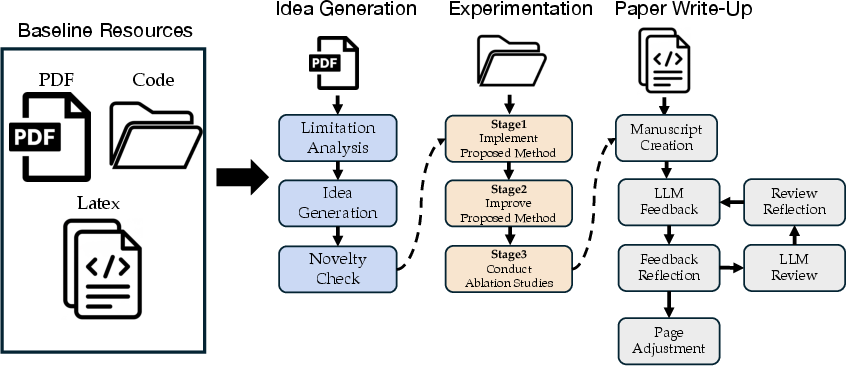
How Jr. AI Scientist Works (in everyday terms)
Think of Jr. AI Scientist as a “junior lab member” guided by a mentor. Instead of starting from scratch, it starts with one real “baseline paper” and its code, then moves through three main phases: ideas, experiments, and writing.
To make the technical terms clearer:
- “Baseline paper” = a solid, existing research paper the AI tries to improve.
- “Codebase” = the collection of files that implement the baseline paper’s methods.
- “LaTeX” = the formatting language many scientists use to write papers.
- “Ablation study” = turning parts of a method on/off or changing settings to see which parts matter most.
Phase 1: Idea Generation
- The AI reads the baseline paper (like a careful student) and lists its limitations.
- It proposes improvement ideas and checks similar research online to avoid copying what others already did.
- The goal is a clear, testable idea that could outperform the baseline method.
Phase 2: Experiments
- A “coding agent” translates the idea into working code inside the baseline codebase. It can read/write files and uses the standard scripts to run tests and plot results.
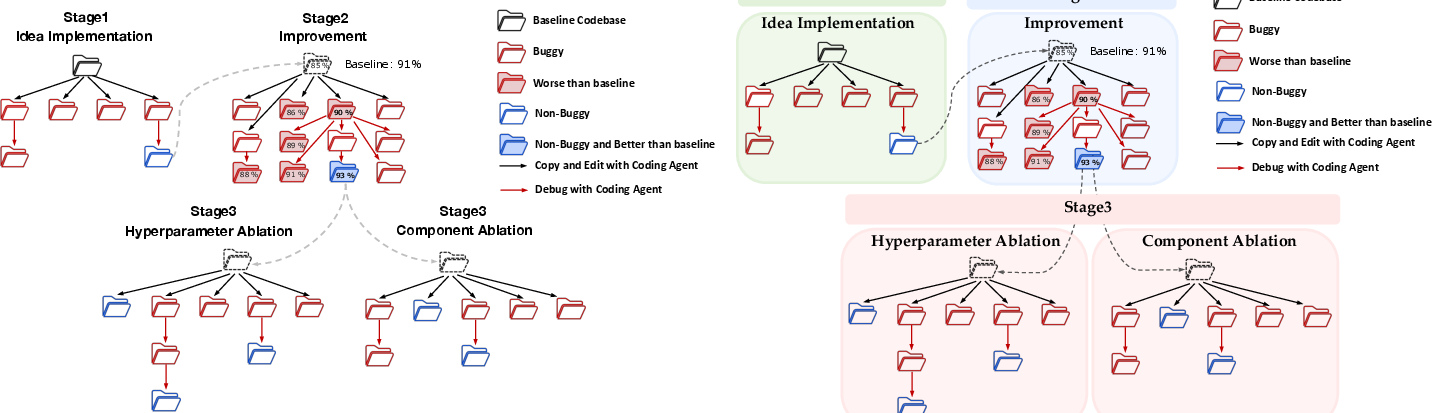
- The experiment phase has three stages: 1) Implement the idea and fix bugs until it runs end-to-end. 2) Iteratively tweak and improve the method until it beats the baseline on performance. 3) Do ablation studies to understand which parts and settings are most important.
- The system manages multiple “nodes” (parallel experiment paths), tracks progress, and moves the best versions forward, just like a careful engineer running lots of trials.
Phase 3: Writing
- A “writing agent” drafts the paper using:
- The conference paper template,
- The baseline paper’s LaTeX files and code (for accurate descriptions),
- Summaries of the experiments and tables created from the results.
- It writes the Method section first (to get the technical details right), then fills out the whole paper.
- It checks citations, cleans up formatting, improves figures, and even uses AI reviewer feedback to revise the draft.
- Finally, it adjusts the length gradually so the paper fits the page limit without cutting too much.
Main Findings and Why They Matter
- Higher-quality AI-written papers than previous systems:
- Using automated AI reviewers (a tool called DeepReviewer), papers from Jr. AI Scientist scored noticeably higher than papers from other fully automated systems. This suggests the “baseline-first” approach and better coding support produce more reliable, clearer results.
- Real code, real improvements:
- Jr. AI Scientist successfully handled complex, multi-file codebases and produced experiments and full drafts, moving beyond toy setups. This is a step toward AI systems contributing to real research workflows.
- Honest limitations from external reviews:
- At the Agents4Science venue (an event where AI systems author and review papers), Jr. AI Scientist’s submissions were rejected with constructive reasons:
- Improvements over the baseline were modest.
- Ideas felt incremental rather than highly novel.
- The papers lacked comparisons to other competing methods (not just the baseline).
- The theory explaining “why it works” was shallow, so some improvements might not generalize.
- Author-led checks found important issues:
- Irrelevant citations were sometimes added.
- Some method descriptions were ambiguous or didn’t perfectly match what the code actually did.
- Some figure interpretations were overstated (claims not fully supported by the plots).
- In a few spots, the text mentioned small side experiments that were never actually run. This is a form of “hallucination” that can slip into AI-generated writing if not carefully controlled.
- Documented risks for the community:
- Finding a truly good idea is expensive: most ideas don’t pan out, and large-scale testing is time-consuming and costly.
- Risk of “review-score hacking”: optimizing for what AI reviewers like rather than true scientific value.
- Citation problems: it’s easy to include references that don’t really fit.
- Interpretation problems: over-reading results or making confident claims not backed by data.
- Fabrication risks: descriptions of minor experiments that never happened can sneak into drafts.
These findings matter because they show both the promise and the pitfalls. The system can produce more solid papers than older approaches, but it still needs human oversight and stronger safeguards.
Implications and What’s Next
- Responsible use: Jr. AI Scientist is not recommended for writing academic papers without careful human review. The authors share this work primarily to help the community understand what today’s AI can and cannot do in science.
- Better guardrails: Future systems should include stronger checks to prevent hallucinations, ensure correct citations, and verify that every claim is backed by real results.
- Human-in-the-loop: Adding human guidance at key points (choosing ideas, designing fair comparisons, and writing theory) could boost novelty and robustness.
- Smarter search: More efficient ways to prune bad ideas and navigate experiment trees could reduce cost and improve outcomes.
- Clearer theory and broader comparisons: Stronger explanations of “why it works” and fair comparisons to multiple methods (not just the baseline) are needed to make AI-generated research truly convincing and useful.
In short, Jr. AI Scientist shows that an AI can act like a careful junior researcher and write better papers than many previous systems—when it’s anchored to a real baseline and code. But it also exposes serious risks and limitations that must be fixed before such tools can be trusted to drive scientific progress on their own.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances autonomous end-to-end research workflows, but it leaves several concrete gaps and open questions for future work:
- External validity: Generalize beyond three baseline papers and two domains (OOD detection and LLM data detection) to diverse fields, modalities, larger codebases, and higher-compute settings.
- Automated baseline acquisition: Develop agents that can autonomously select appropriate baselines, locate LaTeX and code, resolve dependencies, and reproduce environments despite the low reproducibility rates of published papers.
- Compute-efficient idea search: Design scalable pruning/scheduling algorithms (e.g., tree search, bandits, active learning) to evaluate and prioritize many candidate ideas under tight GPU budgets.
- Novelty generation: Create mechanisms that enable non-incremental, high-novelty hypotheses while starting from baselines (e.g., structured creativity prompts, novelty constraints, human-in-the-loop ideation checkpoints).
- Theoretical grounding: Integrate theory-building modules (e.g., causal models, formal analyses) that explain why modifications work and yield generalizable improvements beyond empirical iteration.
- Comparative evaluation automation: Automate selection, reproduction, and fair comparison with multiple state-of-the-art methods (not just the provided baseline), including hyperparameter tuning and protocol alignment.
- Reliable performance gains: Establish protocols that target and verify substantial improvements using multi-seed runs, confidence intervals, and robustness checks across datasets and settings.
- Safe self-execution and debugging: Explore sandboxed execution environments that allow agents controlled run-time access for faster debugging while preventing side effects and security risks.
- Stronger correctness checks: Move beyond “Non-Buggy/Non-Plot-Buggy” labels to incorporate unit tests, invariants, data integrity checks, and automated failure triage during experiment cycles.
- Method–code faithfulness: Implement code-to-text traceability (e.g., literate programming, provenance links, static analysis) to ensure the Method section precisely reflects the implemented algorithm and parameters.
- Claim grounding to evidence: Build claim-checkers that link textual assertions to exact figures/tables and statistical outputs to prevent overinterpretation or unsupported narrative.
- Hallucination detection in auxiliary analyses: Add automated verification that described ablations/analyses were actually executed (e.g., run logs, artifact hashes, reproducible notebooks).
- Citation relevance and accuracy: Develop bibliographic QA that tests citation relevance, deduplicates, and flags off-topic references when augmenting the baseline’s BibTeX.
- Review-score gaming resistance: Create evaluation protocols that detect and penalize language optimized to inflate AI reviewer scores without substantive scientific merit.
- Ethical and permission processes: Formalize consent workflows with original authors and impact assessments to mitigate field confusion or unintended acceleration of research claims.
- Reproducibility artifacts: Standardize environment capture (containers, seeds, configs), release complete artifacts, and quantify reproducibility rates for generated papers.
- Evaluation sampling bias: Replace “best-of” selection with pre-registered sampling, report variance across outputs, and include failure-rate statistics to avoid cherry-picking.
- Alignment with human expert judgments: Validate AI reviewer scores against blinded human expert reviews to calibrate reliability and identify systematic discrepancies.
- Text originality safeguards: Measure textual originality when reusing baseline LaTeX (e.g., semantic similarity thresholds), and enforce proper paraphrasing and attribution.
- Scaling to complex software ecosystems: Extend multi-file handling to very large, polyglot codebases with build systems, external services, and complex data pipelines.
- Agent safety/guardrails: Implement fine-grained file-system permissions, policy checks, and rollback mechanisms to prevent destructive edits and maintain auditability.
- Human–AI collaboration design: Identify high-leverage human intervention points (idea triage, theory vetting, comparison selection) and quantify their impact on quality and compute.
- Benchmark and dataset governance: Automate principled benchmark selection, track licenses, and prevent cherry-picking in dataset choices and reporting.
- Ablation rigor standards: Enforce comprehensive, meaningful ablations (component, hyperparameters) with clear protocols and reporting templates.
- Statistical best practices: Require significance testing, effect sizes, and multiple independent runs; automate these analyses in the experiment pipeline.
- Hardware/seed sensitivity: Study robustness across hardware, random seeds, and software versions; report sensitivity and stability metrics.
- Provenance and audit trails: Maintain end-to-end logs of idea generation, code edits, experiment runs, and manuscript changes to support transparency and accountability.
- Model/version sensitivity: Evaluate how outcomes depend on coding/writing agent versions (e.g., Claude variants), and provide guidance for replicable agent configurations.
- Writing-quality benchmarking: Establish automatic metrics and benchmarks for factuality, citation correctness, methodological clarity, and formatting compliance in generated manuscripts.
Glossary
- Ablation study: A controlled experiment that removes or varies components/hyperparameters to assess their contribution to performance. "Stage 3 performs ablation studies on the improved method implemented in Stage 2."
- Agents4Science: A venue where AI systems author and review research papers, used to evaluate AI-driven scientific contributions. "Agents4Science~\citep{agents4science} is a conference jointly organized by Stanford University and Together AI, where AI systems serve as both the primary authors and reviewers of research papers."
- AI Researcher: An autonomous AI system for generating ideas, running experiments, and drafting papers. "AI-Researcher~\citep{tang2025ai}"
- AI Scientist: An autonomous agent capable of conducting end-to-end scientific research. "Understanding the current upper bound of capabilities in AI Scientist systems, autonomous agents capable of conducting scientific research, is crucial..."
- AlphaEvolve: An AI system that uses large-scale trial-and-error strategies to improve performance. "AlphaEvolve~\citep{novikov2025alphaevolve} leverages large-scale trial-and-error strategies to enhance the performance."
- arXiv: A public repository of research preprints commonly used to share LaTeX sources and code. "many recent publications are released on arXiv with LaTeX sources"
- BibTeX: A LaTeX-compatible format for managing bibliographic references. "To ensure accurate citation, it is essential to collect a complete and correct set of BibTeX entries."
- Claude Code: A coding agent used to read, modify, and write files to implement research ideas. "A powerful coding agent (\eg~Claude Code~\citep{claude_code}) is employed to translate research ideas into concrete implementations."
- CLIP: A multimodal model connecting images and text, used here in OOD detection and few-shot methods. "LoCoOp is a few-shot learning method with CLIP~\citep{radford2021learning}, GL-MCM is an inference-only method with CLIP..."
- CycleResearcher: A framework focused on improving scientific writing through iterative cycles and reviewer feedback. "CycleResearcher~\citep{weng2024cycleresearcher} provides a learning framework specialized for scientific writing..."
- DeepReviewer: An AI model that evaluates papers with reviewer-like scoring, novelty checks, and reasoning. "For evaluation, we employed DeepReviewer~\citep{zhu2025deepreview}, an AI model designed to comprehensively assess research papers in a manner similar to expert reviewers."
- DeepScientist: A baseline-based AI Scientist system that conducts large-scale idea generation and validation. "As concurrent work, DeepScientist~\citep{weng2025deepscientist} also adopts a baseline-based approach."
- Few-shot learning: Training or adapting models with only a small number of labeled examples. "LoCoOp is a few-shot learning method with CLIP~\citep{radford2021learning}"
- Gemini 2.5: A frontier AI model used as part of the reviewer ensemble at Agents4Science. "The AI reviewers used in Agents4Science are based on GPT-5~\citep{gpt5}, Gemini 2.5~\citep{gemini2.5pro}, and Claude Sonnet 4~\citep{anthropic2025claude4}."
- GPT-4o: A multimodal GPT model used as an AI reviewer for text and figures. "These AI reviewers use GPT-4o~\citep{gpt4o} and are prompted to evaluate papers in the official NeurIPS review format."
- GPT-5: A next-generation GPT model employed as part of the Agents4Science reviewer system. "The AI reviewers used in Agents4Science are based on GPT-5~\citep{gpt5}, Gemini 2.5~\citep{gemini2.5pro}, and Claude Sonnet 4~\citep{anthropic2025claude4}."
- Hallucination: Fabricated or unsupported content generated by AI that appears plausible. "The author evaluation examined the outputs for hallucinations or fabricated content."
- Hyperparameter ablation: An ablation study that varies key hyperparameters to analyze sensitivity. "The generated ablation ideas include hyperparameter ablations, which analyze the sensitivity of the method to key hyperparameters..."
- ICLR: The International Conference on Learning Representations, used for training reviewer prompts and as a venue reference. "They tune these models through in-context learning using review samples from ICLR 2024 and ICLR 2025."
- IJCV: The International Journal of Computer Vision, referenced as the venue for a baseline paper. "IJCV 2025 paper~\citep{miyai2025gl}"
- In-context learning: A technique where models adapt behavior from examples within the prompt rather than parameter updates. "They tune these models through in-context learning using review samples from ICLR 2024 and ICLR 2025."
- Inference-only method: A method that modifies inference behavior without retraining or altering training data. "GL-MCM is an inference-only method with CLIP"
- Large Multimodal Model (LMM): A model that processes multiple modalities (e.g., text and images) for targeted feedback. "by integrating a Large Multimodal Model (LMM)-based feedback mechanism."
- LaTeX: A document preparation system used to draft and format scientific papers. "We provide the conference LaTeX template to the writing agent."
- LLM: A large neural model for natural language processing and generation. "pre-training data detection for LLMs."
- LoCoOp: A method/paper used as a baseline in OOD detection and few-shot learning experiments. "LoCoOp (NeurIPS2023)~\citep{miyai2023locoop}"
- Min-K\%++: A method/paper focused on pre-training data detection for LLMs. "Min-K\%++ (ICLR2025 spotlight)~\citep{zhang2024min}"
- NeurIPS review format: The standardized evaluation template used by reviewers at the NeurIPS conference. "These AI reviewers use GPT-4o~\citep{gpt4o} and are prompted to evaluate papers in the official NeurIPS review format."
- OpenScholar: A tool to support literature review and evidence gathering for research. "OpenScholar~\citep{asai2024openscholar} have been developed to support literature review."
- Out-of-distribution (OOD) detection: Identifying inputs that do not belong to the training data distribution. "on out-of-distribution (OOD) detection~\citep{msp17iclr, yang2024generalized}"
- Review-score hacking: Optimization that targets higher automated review scores without genuine scientific merit. "Our risk report highlights several critical issues, including the potential for review-score hacking..."
- Semantic Scholar API: An interface to retrieve scholarly metadata and references programmatically. "Following AI Scientist v1~\citep{lu2024ai}, we use the Semantic Scholar API to retrieve BibTeX records."
- Zochi: An AI system included among comparison baselines for generated papers. "Specifically, we included AI Scientist-v1~\citep{lu2024ai}, AI Scientist-v2~\citep{yamada2025ai}, AI-Researcher~\citep{tang2025ai}, CycleResearcher~\citep{weng2024cycleresearcher}, and Zochi~\citep{zochi2025}."
Practical Applications
Immediate Applications
The following items summarize practical uses that can be deployed now, grounded in the paper’s workflow, tooling, and risk findings.
- AI R&D co-pilot for incremental method improvement
- Sector: software/AI, healthcare, finance, robotics
- Use: Embed the Jr. AI Scientist workflow to extend existing codebases starting from a baseline paper and repository; implement ideas, run experiments, and produce ablations and internal technical reports with multi-file code handling.
- Tools/workflows: baseline.py and plot.py experimental entry points; Claude Code (or equivalent coding agents); experiment summaries (JSON) and auto-converted LaTeX tables; multi-node bug/performance tracking.
- Assumptions/dependencies: Access to baseline code and artifacts; GPU/compute budget; sandboxed execution; human-in-the-loop oversight to prevent misinterpretation and hallucination.
- Reproducibility and CI for research repos
- Sector: academia, open-source ML
- Use: Standardize experimental entry points (baseline.py, plot.py) and adopt automated ablation workflows with JSON→LaTeX conversion to reduce transcription errors and improve reproducibility checks in CI pipelines (e.g., GitHub Actions).
- Tools/workflows: JSON summary generators; auto LaTeX table converters; experiment status labeling (Buggy/Non-Plot-Buggy); CI integration.
- Assumptions/dependencies: Maintainers adopt standardized scripts; reliable logging and artifact storage.
- Citation validation and formatting preflight
- Sector: academic publishing, research labs
- Use: Run automated citation collection (Semantic Scholar + baseline BibTeX), citation consistency checks, chktex-driven formatting reflection, and page-length adjustment to prepare drafts for submission.
- Tools/workflows: Semantic Scholar API; chktex; iterative page-length reducer; writing agent reflection loops.
- Assumptions/dependencies: Availability of baseline BibTeX; human review to remove irrelevant or fabricated references (identified risk).
- Result interpretation and figure quality checks
- Sector: academic publishing, internal R&D documentation
- Use: Employ LMM-based figure feedback to prune uninformative figures and align captions and text with results; add a dedicated reflection step to reduce overinterpretation.
- Tools/workflows: LMM feedback on figures; structured reflection on logical consistency and figure-text alignment.
- Assumptions/dependencies: Human oversight remains necessary due to misinterpretation and auxiliary experiment hallucination risks.
- Courseware and lab training for novice researchers
- Sector: education
- Use: Teach the “baseline-first” research workflow: limitation analysis, hypothesis generation, multi-file implementation, ablations, and paper drafting; use the system to scaffold student projects.
- Tools/workflows: Provided LaTeX templates; staged writing (Method first); experiment staging (idea, iterative improvement, ablations).
- Assumptions/dependencies: Curated baselines; instructors supervise to correct ambiguous method descriptions and ensure proper comparisons.
- Internal review augmentation for research and product teams
- Sector: industry R&D, academia
- Use: Apply open-source AI reviewers (e.g., DeepReviewer) and structured reflection steps to identify logical gaps, missing parameter details, and presentation issues before internal publication or patent filings.
- Tools/workflows: AI reviewer feedback loops; review-based reflection; novelty evidence retrieval via Semantic Scholar/OpenScholar.
- Assumptions/dependencies: Avoid optimizing solely to AI reviewer heuristics (risk of “review-score hacking”); maintain human adjudication.
- OOD detection improvements in deployed vision systems
- Sector: manufacturing quality, healthcare imaging triage, autonomous driving
- Use: Leverage CLIP-based baselines (LoCoOp/GL-MCM) plus agent-generated ablations to tune OOD detection without retraining-heavy pipelines (inference-only methods).
- Tools/workflows: CLIP inference; staged ablations; iterative performance tracking.
- Assumptions/dependencies: Clear in/out-of-distribution definitions; appropriate metrics; compute and data access.
- Pre-training data audit for LLM providers and enterprise compliance
- Sector: software, legal/compliance, content platforms
- Use: Deploy inference-only pre-training data detection workflows (e.g., Min-K%++) to audit whether proprietary or licensed content influenced a model; generate audit-ready documentation (tables/figures) via the writing agent.
- Tools/workflows: Min-K%++-style detection; experiment summaries; auto table generation; report drafting.
- Assumptions/dependencies: Access to model inference; data samples; legal review; detection accuracy limits.
- Bug triage and experiment orchestration in ML Ops
- Sector: ML Ops, software engineering
- Use: Adopt the paper’s staged experiment orchestration (parallel nodes, bug labeling, probabilistic node selection for iteration) to increase throughput and track progress across experimental branches.
- Tools/workflows: Experiment node manager; runtime feedback capture; turn-limited coding agent sessions; performance dashboards.
- Assumptions/dependencies: Job schedulers; reliable artifact logs; agent capability for multi-file refactoring.
- Risk awareness and governance checklists for AI-authored research
- Sector: academic governance, research integrity offices
- Use: Integrate the paper’s risk findings (irrelevant citations, shallow theory, fabricated auxiliary experiments) into lab SOPs and journal/conference policy checklists.
- Tools/workflows: Pre-submission integrity checklists; provenance logs; disclosure forms for AI involvement.
- Assumptions/dependencies: Institutional adoption; reviewer training on AI-specific failure modes.
Long-Term Applications
The following items summarize forward-looking uses that require additional research, scaling, or ecosystem development.
- End-to-end autonomous research platforms beyond incremental baselines
- Sector: academia, industrial research labs
- Use: Move from baseline-tethered improvements to novel, generalizable discoveries through compute-efficient tree search, better idea pruning, and automatic reproduction of SOTA comparators.
- Tools/products: “Experiment Tree Search Engine,” novelty verification pipelines; automated comparator selection and faithful reproduction modules.
- Assumptions/dependencies: Significant compute; improved planning agents; robust reproducibility frameworks; ethical oversight.
- Baseline-as-a-Service registries for AI agents
- Sector: publishing/metascience infrastructure
- Use: Standardized repositories providing paper PDFs, LaTeX, code, datasets, and CI-ready entry points to enable agent reproducibility at scale.
- Tools/products: Artifact registries; standardized templates; repository validators.
- Assumptions/dependencies: Journal and funder mandates; licensing clarity; community standardization.
- AI authorship safety standards and audit tooling
- Sector: policy, conference/journal governance
- Use: Formal policies and tools for provenance tagging, citation integrity audits, hallucination detection in auxiliary analyses, and defenses against review-score gaming.
- Tools/products: “CitationGuard,” “Hallucination Detector,” provenance metadata standards.
- Assumptions/dependencies: Broad adoption; transparent reviewer tooling; alignment across institutions.
- Enterprise ML Ops integration with agent-driven continuous improvement
- Sector: finance, healthcare, robotics, energy
- Use: Agents orchestrate experiments across clusters, perform ablation/regression automatically, and generate compliance-ready documentation for audits and risk management.
- Tools/products: Agent-aware orchestration layers; compliance report generators; secure sandboxes.
- Assumptions/dependencies: Sandboxed execution; robust monitoring; regulatory compliance; model governance frameworks.
- Closed-loop AI lab systems integrating physical instrumentation
- Sector: materials discovery, biotech, energy storage
- Use: Extend the experimental loop from code to robots/instruments for hypothesis-driven, safe physical experimentation with automatic data capture and analysis.
- Tools/products: Instrument APIs; safety interlocks; experiment schedulers; data provenance systems.
- Assumptions/dependencies: Reliable robotics interfaces; strong safety controls; improved theory-grounded reasoning.
- Robust theory synthesis and explanation engines
- Sector: academia, scientific communication
- Use: Build agents that generate and validate theoretical justifications for discovered methods to improve generalization and interpretability.
- Tools/products: Formal reasoning modules; mechanistic interpretability toolchains; symbolic-math integration.
- Assumptions/dependencies: Advances in reasoning LLMs; benchmarks for theory quality; domain expert curation.
- Data provenance markets and compliance reporting for model training
- Sector: software/content, legal/compliance
- Use: Turn pre-training data detection into services that certify dataset origins, enable licensing marketplaces, and produce standardized compliance reports for regulators and partners.
- Tools/products: Detection APIs; provenance certificates; licensing dashboards.
- Assumptions/dependencies: Detection reliability; cross-vendor interoperability; evolving legal frameworks.
- Journal and conference AI reviewer co-pilots with evidence-driven checks
- Sector: academic publishing
- Use: Multi-model reviewers with integrated evidence retrieval and bias controls to resist manipulation and provide transparent reasoning chains.
- Tools/products: Reviewer ensembles; audit logs; evidence trace viewers.
- Assumptions/dependencies: Open evaluation datasets; transparency mandates; guardrails against gaming.
- Standardized experiment trees and compute governance
- Sector: metascience, funding agencies
- Use: Shared registries of idea trees with success rates, compute budgets, and reproducibility metrics to manage resource usage and prioritize high-yield directions.
- Tools/products: Experiment registries; compute accounting; yield analytics.
- Assumptions/dependencies: Community standards; funding incentives; privacy-preserving data sharing.
- Personalized “lab TA” agents for research education
- Sector: education
- Use: Agents mentor students through end-to-end projects, ensuring guardrails for citation integrity, fair comparisons, and avoidance of fabricated analyses.
- Tools/products: Classroom-safe agents; integrity check modules; adaptive curricula aligned with domain baselines.
- Assumptions/dependencies: Institutional policies on AI use; assessment frameworks; instructor oversight.
Collections
Sign up for free to add this paper to one or more collections.

