Meta-Reinforcement Learning with Self-Reflection for Agentic Search
Abstract: This paper introduces MR-Search, an in-context meta reinforcement learning (RL) formulation for agentic search with self-reflection. Instead of optimizing a policy within a single independent episode with sparse rewards, MR-Search trains a policy that conditions on past episodes and adapts its search strategy across episodes. MR-Search learns to learn a search strategy with self-reflection, allowing search agents to improve in-context exploration at test-time. Specifically, MR-Search performs cross-episode exploration by generating explicit self-reflections after each episode and leveraging them as additional context to guide subsequent attempts, thereby promoting more effective exploration during test-time. We further introduce a multi-turn RL algorithm that estimates a dense relative advantage at the turn level, enabling fine-grained credit assignment on each episode. Empirical results across various benchmarks demonstrate the advantages of MR-Search over baselines based RL, showing strong generalization and relative improvements of 9.2% to 19.3% across eight benchmarks. Our code and data are available at https://github.com/tengxiao1/MR-Search.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper presents MR-Search, a new way to train AI “search agents” so they get better by learning from their own past attempts. Think of a student who tries to answer a tough question, writes a quick note about what worked or didn’t, then tries again using those notes. MR-Search teaches AI to do exactly that: try, reflect, and improve across several rounds.
What questions are the researchers asking?
They focus on three simple questions:
- How can we help AI search agents explore more effectively when they only find out at the very end whether an answer is right or wrong?
- Can an agent learn to use its own reflections (notes to itself) to guide better future attempts?
- Can we train this behavior so the agent keeps improving during testing, not just during training?
How does MR-Search work? (In everyday terms)
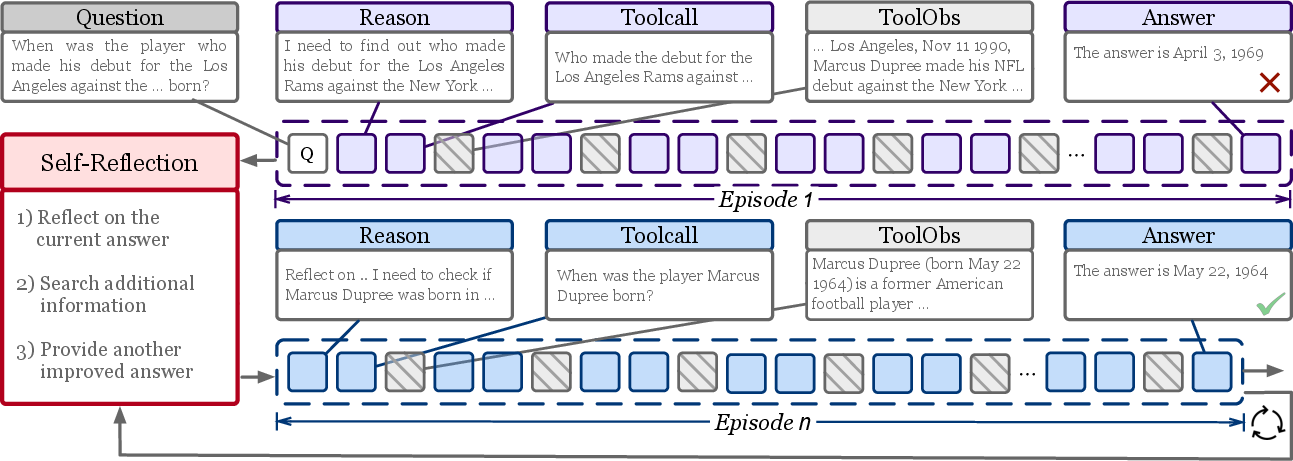
Imagine you’re researching an answer online:
- You make your first attempt: think, search, read, and write an answer.
- You then pause to reflect: what helped, what was a dead end, what should you try next?
- You try again, but this time you use both your previous attempt and your reflection as a guide.
- You repeat this for a few rounds, building on what you’ve learned.
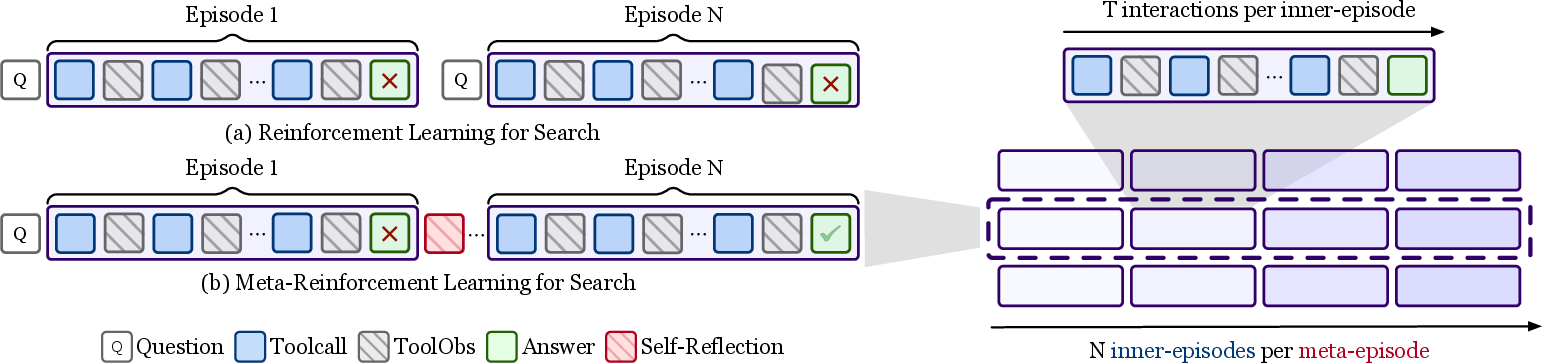
That’s MR-Search. In the paper’s terms:
- Each complete try is an “episode.”
- A short written “self-reflection” follows each episode.
- A chain of several episodes plus reflections is a “meta-episode.”
Training MR-Search:
- The agent practices on many questions. For each question, it tries multiple times in a row, writing reflections between tries.
- After each try, it gets a simple score: did the final answer match the correct one?
- Instead of only judging at the very end, MR-Search compares the quality of each try to other tries for the same question. This helps the agent figure out which specific rounds and reflections were useful.
- It then nudges the model to prefer the kinds of steps and reflections that led to better later answers.
Why is this helpful?
- Traditional training only gives a “right/wrong” at the end. That’s like doing a long maze and only hearing “yes” or “no” at the exit—not very helpful for learning which turns were good.
- MR-Search spreads credit across the rounds, so the agent learns which parts of its process helped, and which didn’t.
- It does this without needing a separate human or another model to judge every step. The agent uses its own comparisons and reflections to learn.
What did they find?
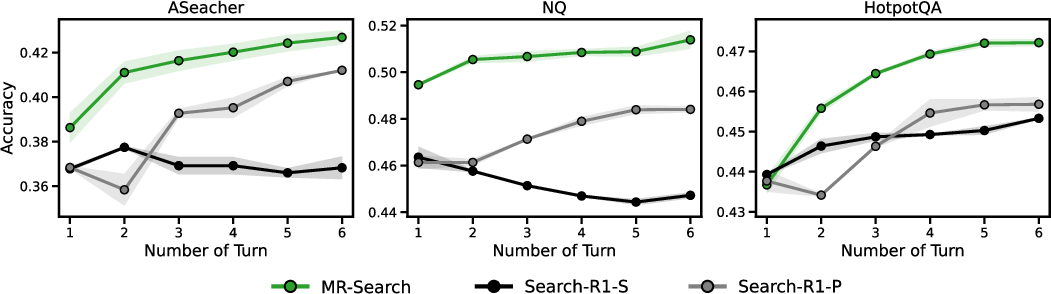
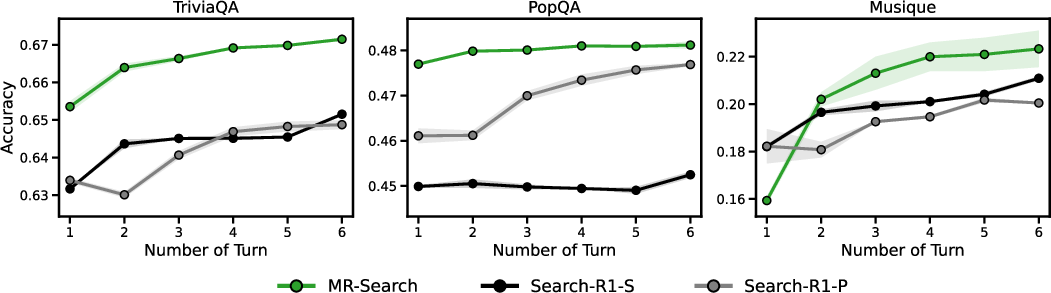
The researchers tested MR-Search on eight question-answering benchmarks, including “single-hop” questions (one fact) and tougher “multi-hop” questions (requiring multiple pieces of evidence). They used open-source LLMs and a Wikipedia search tool.
Key takeaways:
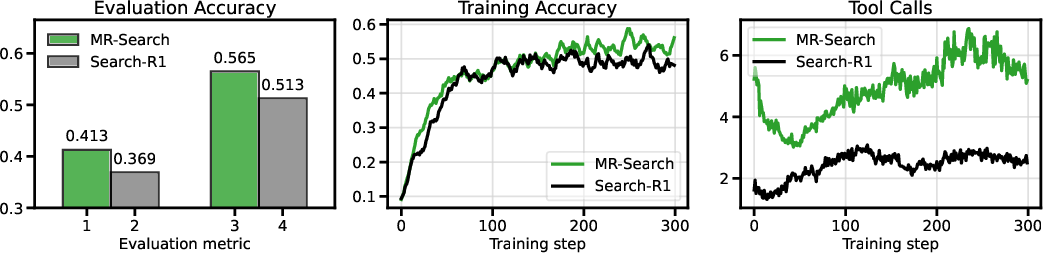
- MR-Search consistently beat strong baselines that used standard reinforcement learning, with relative improvements of about 9% to 19% on average across the benchmarks.
- It especially helped on harder, multi-step tasks where exploration and adjustments matter more.
- It worked well even for smaller models, which often struggle with complex searches.
- When the agent was allowed more reflection rounds at test time, MR-Search kept improving—showing it learned how to use extra “thinking time” effectively.
Why this matters:
- The agent learns how to explore smarter, avoid repeating mistakes, and use past attempts to guide future ones.
- It reduces the need for expensive step-by-step labels or external judges to score every tiny action.
What could this mean going forward?
- Better research assistants: AI that can search the web or a database, reflect on progress, and refine results over several tries—like a diligent student.
- Less reliance on costly supervision: It’s hard and expensive to label every step of a complex process. MR-Search shows a path to learn good processes from simple final checks.
- Scales with extra thinking time: If you let the agent take more rounds to try and reflect, it keeps improving.
Simple caveats and future ideas:
- The paper focuses on question answering with a search tool; future work could add more tools (like browsing full websites).
- It doesn’t tackle very long essay-style answers, where judging correctness is harder.
- Managing long histories of attempts and reflections can be tricky; the authors discuss ways to keep only the most useful recent context.
Overall, MR-Search teaches AI to learn not just answers, but how to learn from its own attempts—turning trial-and-error into steady improvement.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a focused list of concrete gaps and questions that remain open, intended to guide follow-up research.
- Long-form generation evaluation is missing:
- How does MR-Search perform on long-form answers where exact-match (EM) is inadequate?
- What verifiers or progress signals reliably assess multi-paragraph reasoning and citation quality?
- Reward design beyond EM:
- Can partial-credit or semantic-verification metrics (e.g., F1, entailment, string variants, attribution correctness) improve turn-level credit assignment?
- How sensitive is learning to mis-specified verifiers (e.g., false negatives on paraphrases)?
- Reflection content quality and format:
- Which reflection formats (bullet summaries, error analyses, plans, critique vs. revise) yield the best downstream gains?
- How to detect and penalize low-quality or hallucinated reflections that degrade future turns?
- Adaptive halting and compute control:
- How to learn a stopping policy that decides the number of reflection turns per example under a test-time compute budget?
- What are the diminishing returns curves and optimal early-stopping criteria across tasks?
- Context-length scaling and memory:
- How does performance and cost scale with longer N (number of episodes/turns) as context grows linearly?
- Which context management strategies (summarization, retrieval over past turns, memory slots) preserve performance while reducing context size?
- Grouped RLOO hyperparameters and stability:
- What is the sensitivity to group size G (number of meta-episodes per question) and how does it trade off variance, bias, and compute?
- How do clipping parameters and advantage broadcasting choices affect stability and token-level credit misattribution?
- Discount factor scheduling:
- Is there an optimal (discount over episodes) or schedule (e.g., increasing/decreasing with turn index or difficulty)?
- Can adaptive discounting tied to reflection trustworthiness improve credit assignment?
- Token-level incentives and verbosity:
- Does broadcasting turn-level advantages to all tokens incentivize longer “Thought” outputs or verbosity?
- Would per-token or segment-wise attribution (e.g., thought vs. action) reduce undesired behaviors?
- Exploration–exploitation design:
- How should exploration and exploitation turns be allocated or adaptively chosen per instance?
- Can the exploration mask be learned, and does adaptive exploration improve outcomes over fixed schedules?
- Step-level (micro-episode) extension:
- When does step-level meta-RL help or hurt relative to episode-level (as mixed results appear in Table ~\ref{tab:app-variants})?
- How to robustly define and verify step-level intermediate targets outside synthetic settings?
- Compute- and cost-matched baselines:
- How does MR-Search compare to parallel sampling/ensembling under matched FLOPs/latency budgets?
- What is the trade-off between reflection turns and number of parallel samples for the same cost?
- Generalization across domains and tasks:
- Does MR-Search transfer to math, code, planning, and tool-rich tasks beyond QA?
- How does it behave in domains where ground-truth labels are ambiguous or unavailable?
- Tool ecosystem breadth:
- How does MR-Search extend to multi-tool settings (e.g., web search + browsing + APIs) with heterogeneous observations and delays?
- What tool-selection policies and reflection prompts are needed for effective multi-tool coordination?
- Knowledge sources and retrieval choices:
- How sensitive are gains to a specific retriever (E5) and Wikipedia-2018 vs. web-scale/index freshness?
- Do improvements persist under noisy or adversarial retrieval results?
- Base-model and family diversity:
- Do the findings hold for other model families (e.g., Llama, Mistral) and larger scales (≥13B/70B)?
- Are there emergent benefits or failure modes when scaling MR-Search with stronger base models?
- Robustness and failure modes:
- How resilient is MR-Search to compounding reflection errors, misleading evidence, or contradictory sources?
- Can uncertainty estimation or confidence-aware reflections mitigate self-confirmation or drift?
- Real-world and online settings:
- How can MR-Search operate when ground-truth rewards are unavailable even during training (e.g., online/deployment)?
- Can preference learning or human-in-the-loop signals be integrated without external “process reward” models?
- Theoretical underpinnings:
- Why and when does in-context meta-RL with reflection outperform parallel exploration theoretically (bias/variance/credit pathways)?
- Are there convergence guarantees or bounds for RLOO-based, critic-free multi-turn optimization?
- Reproducibility and variance:
- How large is the run-to-run variance across seeds/hardware, and which components (reflection prompt, retriever noise) dominate it?
- What best practices stabilize training across datasets?
- Safety and factuality:
- Does reflection amplify exposure to or reuse of misinformation obtained via search?
- What guardrails (fact-checkers, toxicity filters) or reflection auditing are needed?
- Stopping criteria for incorrect-but-informative turns:
- Can the system recognize when an incorrect episode still contains useful evidence and preserve it effectively?
- How to explicitly score “reflection usefulness” independent of final correctness?
- Data and environment leakage:
- Are there risks that training on NQ/HotpotQA and evaluating on related distributions inflates gains via overlap?
- How does MR-Search perform under deliberately shifted distributions or time-sensitive knowledge?
- Efficiency metrics missing:
- What is the average number of tool calls, latency, and memory usage per question across benchmarks?
- How does MR-Search’s compute footprint compare to baselines at equal accuracy targets?
- Prompt sensitivity and template design:
- How robust are results to reflection prompt wording, placement, and length?
- Can learned reflection modules (e.g., adapters or small policy heads) replace static prompts for better consistency?
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage MR-Search’s core ideas—cross-episode self-reflection, turn-level (dense) credit assignment via RLOO, and multi-turn search agents—without requiring external process reward models.
- Enterprise knowledge search copilots (internal RAG assistants)
- Sectors: software, enterprise IT, operations
- What: Deploy self-reflective search agents for internal wikis, IT docs, policy manuals, and SOPs to improve retrieval accuracy and reduce hallucinations by iteratively revising answers across episodes.
- Tools/products/workflows: E5/other dense retrievers + vector DB (e.g., FAISS, pgvector), ReAct-style tool use, MR-Search-style reflection loop (N=2–4), answer/citation normalizers, exact-match or rule-based verifiers for training.
- Assumptions/dependencies: High-quality retriever over curated corpora; manageable latency budgets for multi-turn; context management to control context-window growth; ground-truth answers for training tasks.
- Customer support copilots for knowledge bases
- Sectors: software, telecom, consumer electronics, e-commerce
- What: Agents use multi-turn search over FAQs, manuals, and ticket histories to refine proposed resolutions and reduce escalations.
- Tools/products/workflows: Ticket integration, tool-call logging, MR-Search-style advantage training, reflection logs exposed as “reasoning traces.”
- Assumptions/dependencies: Reliable, up-to-date KB; stable verifiers (exact match, rule-based checklists); human-in-the-loop escalation paths.
- Analyst research assistants (market/competitive/finance intel)
- Sectors: finance, consulting, marketing
- What: Iteratively aggregates evidence across sources (reports, filings, news) with cross-episode reflections that prune dead-ends and consolidate findings.
- Tools/products/workflows: Web search + document retrieval; per-episode notes; test-time compute controller to add reflection turns when uncertainty is high.
- Assumptions/dependencies: Source reliability and bias handling; citation tracking; safe browsing/scraping policies.
- Legal and compliance Q&A over internal policy and public statutes
- Sectors: legal, compliance, public sector
- What: Multi-hop retrieval over statutes, prior opinions, and policy documents with reflective re-evaluation and auditable reasoning trails.
- Tools/products/workflows: Doc indexing (chunking + embeddings), MR-Search reflection memory, turn-level logs for audit.
- Assumptions/dependencies: Strict human oversight; conservative deployment; exact-match verifiers replaced by rule-based/keyword verifiers or curated QA sets; access controls and redaction.
- Scientific literature triage and mini-reviews
- Sectors: academia, biotech, pharma
- What: Rapid, self-reflective literature scans that refine hypotheses across episodes and produce answer-plus-citations summaries.
- Tools/products/workflows: PubMed/semantic scholar APIs; iterative evidence tables; MR-Search reflection prompts tailored to “weighing evidence.”
- Assumptions/dependencies: Coverage of literature indices; verification via curated benchmark questions or proxy metrics; careful caveating to avoid overclaiming.
- Code/documentation search assistants
- Sectors: software, DevRel
- What: Cross-episode refinement over API docs, release notes, and forum posts to answer “how-to” questions and resolve errors.
- Tools/products/workflows: Doc retrievers + code search; MR-Search reflection to test alternate approaches across episodes; final answer with links/snippets.
- Assumptions/dependencies: High-quality indexing; guardrails to avoid executing untrusted code; latency budgets.
- Education study assistants for factual/multi-hop questions
- Sectors: education/edtech
- What: Multi-turn QA with citations; reflective cycles help correct earlier misinterpretations.
- Tools/products/workflows: Curriculum-aligned corpora, multi-hop QA templates, reflection after each episode, student-facing confidence indicators.
- Assumptions/dependencies: Age-appropriate content filtering; ground-truth QA sets for fine-tuning; explainability demands.
- Government/citizen information desks
- Sectors: public sector
- What: Accurate, cited answers to policy and service questions via iterative retrieval from agency guidance.
- Tools/products/workflows: Agency document retrieval, MR-Search reflection logs for accountability, rate limits for test-time turns.
- Assumptions/dependencies: Up-to-date content; strict safety and privacy policies; clear disclaimers.
- Test-time compute scheduler for production agents
- Sectors: software, platforms
- What: Deploy a policy that adjusts the number of reflection turns based on uncertainty or question complexity to balance cost and accuracy.
- Tools/products/workflows: Uncertainty heuristics (e.g., answer agreement, retrieval diversity), budget-aware controller, MR-Search-trained agent.
- Assumptions/dependencies: Latency/cost constraints; reliable uncertainty signals.
- Developer tooling for RL fine-tuning of agents
- Sectors: AI platforms, MLOps
- What: Integrate turn-level RLOO advantage estimation and multi-turn PPO-style objectives into RL pipelines for agentic tasks (no critic, lower overhead).
- Tools/products/workflows: Training library implementing grouped RLOO, token masking for tool output, reflection prompts, exploration/exploitation masking.
- Assumptions/dependencies: Curated training sets with verifiable answers; experiment tracking for turn-level metrics; careful hyperparameter tuning.
- Auditable reasoning trails (“chain-of-reflection”)
- Sectors: finance, legal, public sector
- What: Provide users/regulators with per-episode reflection notes and sources to increase trust and support post-hoc audits.
- Tools/products/workflows: Persisted episode histories, signed logs, PII scrubbing, export to case-management systems.
- Assumptions/dependencies: Privacy/security controls; policy for log retention and redaction.
- Personal browser extensions for research, shopping, and travel
- Sectors: consumer software
- What: Iteratively compare products, fares, or itineraries across sources and revise recommendations with explicit reflections and citations.
- Tools/products/workflows: Lightweight web search tooling, configurable number of reflection iterations, “why” sections.
- Assumptions/dependencies: Website terms compliance; cost/user patience for multi-turn runs.
Long-Term Applications
These extensions need additional research, scaling, or domain-specific verification to be production-ready.
- Multi-tool autonomous agents (search + browsing + forms + APIs)
- Sectors: software, e-commerce, travel, enterprise ops
- What: Extend MR-Search beyond search to heterogeneous tools (web navigation, data extraction, form submission) with cross-episode reflections.
- Dependencies: Robust tool simulators or safe sandboxes; reliable process verifiers beyond exact match; strong safety filters; hierarchical context management.
- Clinical evidence retrieval and decision support
- Sectors: healthcare
- What: Multi-episode synthesis of guidelines, trials, and patient context with explicit self-reflection to surface uncertainties and alternatives.
- Dependencies: FDA/CE compliance, domain-specific verifiers (e.g., guideline conformance), clinician-in-the-loop workflows, bias and safety audits.
- Contract analysis and regulatory impact assessment
- Sectors: legal, public policy
- What: Cross-episode exploration of clauses and precedents with reflective error correction; highlight conflicts and missing references.
- Dependencies: Document-level verifiers; institution-specific policy templates; strict access control and provenance.
- Long-form report generation with process-aware verification
- Sectors: journalism, consulting, research
- What: Use micro-episodes to reward intermediate milestones (outlines, evidence sections), enabling finer credit assignment in long outputs.
- Dependencies: Robust process reward proxies; anti–reward-hacking safeguards; scalable evaluation beyond exact match.
- Persistent memory across sessions for organization-wide learning
- Sectors: enterprise IT, KM
- What: Summarize and compress reflection histories into durable “memories” that improve future search episodes.
- Dependencies: Summarization fidelity; memory governance; drift detection; storage and privacy policies.
- Dynamic compute budgets and cost-aware agent orchestration
- Sectors: cloud platforms, AI infra
- What: Meta-RL policies that learn when to explore vs. exploit and how many reflection turns to allocate under SLAs and budgets.
- Dependencies: Reliable cost/latency signals; scheduler integration; monitoring for pathological looping.
- Safety- and compliance-first agent frameworks with auditable reflections
- Sectors: finance, healthcare, public sector
- What: Process-level oversight that approves or rejects episodes, with MR-Search encouraging safe exploration and documented rationale.
- Dependencies: Oversight tooling; red-team evaluations; data governance; policy-aligned refusal criteria.
- Step-level micro-episode training for complex tool interactions
- Sectors: software automation, RPA, robotics-adjacent digital agents
- What: Treat each tool call as a micro-episode with local rewards to improve fine-grained decision quality and reduce error propagation.
- Dependencies: Stepwise verifiers; fine-grained logging; careful credit assignment to avoid spurious correlations.
- Cross-domain meta-RL for procedural and decision workflows
- Sectors: energy (grid ops), logistics, manufacturing
- What: Use turn-level advantages and cross-episode reflections for planning tasks (e.g., incident triage, scheduling) where sparse outcome rewards hamper learning.
- Dependencies: Simulators or offline logs with proxy rewards; safe deployment; organizational change management.
- Managed training platforms for agentic meta-RL
- Sectors: AI platforms, MLOps
- What: Cloud services providing MR-Search training pipelines, grouped-advantage objectives, exploration masks, and test-time scaling knobs.
- Dependencies: Standardized verifier libraries, dataset onboarding, cost control, privacy guarantees.
- AI governance with standardized “reasoning dossiers”
- Sectors: regulators, audit, risk
- What: Normalize and standardize reflection logs for compliance, enabling explainability and reproducibility across organizations.
- Dependencies: Interoperable schemas, legal frameworks, secure attestation, retention policies.
Notes on Feasibility and Dependencies (cross-cutting)
- Verifiers: The paper trains with outcome-based verifiers (e.g., exact match). Real deployments often require robust, domain-specific verifiers (checklists, rules, weak supervision, or human review). Insufficient verifiers can cause reward hacking and degrade reliability.
- Retrieval quality: MR-Search depends on high-quality retrieval (e.g., E5 embeddings) and well-indexed corpora. Poor retrieval reduces benefits of reflection.
- Compute/latency: Multi-turn reflection improves accuracy but increases cost and response time. Production systems need test-time compute controllers.
- Context management: Context grows with episodes; summarization, memory pruning, or “keep last episode” strategies are necessary.
- Safety and compliance: Reflection reduces errors but does not eliminate them. Sensitive domains require human-in-the-loop, content filters, and audit trails.
- Model capability: Results are demonstrated on 3B–7B models; complex tasks may require larger models or specialized fine-tuning.
- Generalization: Training requires tasks with ground-truth answers; transferring to open-ended tasks demands new reward proxies and validation strategies.
Glossary
- Agentic search: Training or deploying language-model agents to perform multi-step information-seeking with tools. Example: "agentic search with self-reflection."
- Clipped surrogate off-policy objective: A PPO-style objective that constrains policy updates using ratio clipping while allowing off-policy optimization. Example: "a clipped surrogate off-policy objective in PPO"
- Credit assignment: The problem of determining which actions or steps deserve responsibility for outcomes in long trajectories. Example: "enabling fine-grained credit assignment on each episode."
- Cross-episode exploration: Leveraging information from prior episodes to guide exploration in subsequent ones. Example: "performs cross-episode exploration by generating explicit self-reflections"
- Critic-free: Optimization without learning a separate value (critic) function. Example: "remains critic-free and eliminates the need for auxiliary value models compared to PPO"
- Discount factor: A scalar in RL that down-weights future rewards relative to immediate ones. Example: "γ ∈ (0,1] is the discount factor accounting for future returns."
- Exact Match (EM): An evaluation metric that checks if a predicted answer exactly equals a ground-truth answer. Example: "compute Exact Match (EM) score."
- GRPO: A policy optimization algorithm variant used for RL with LLMs (e.g., in DeepSeekMath). Example: "such as PPO~\citep{schulman2017proximal} or GRPO~\citep{shao2024deepseekmath}"
- In-context exploration: Exploration behavior that improves within the model’s input context across attempts at test time. Example: "allowing search agents to improve in-context exploration at test-time."
- In-context meta-reinforcement learning: Meta-RL that adapts a policy using histories encoded in the prompt/context rather than parameter updates. Example: "in-context meta-reinforcement learning methods"
- Leave-One-Out (RLOO) estimation: A variance-reduced, unbiased advantage estimator that subtracts the mean reward of other samples as a baseline. Example: "apply Leave-One-Out (RLOO) estimation"
- LM judges: External LLMs used to evaluate or score intermediate reasoning steps or outputs. Example: "or LM judges"
- Meta-episode: A sequence of multiple episodes treated as a higher-level unit for meta-RL training. Example: "A sequence of episodes forms a meta-episode."
- Meta-reinforcement learning: Learning to learn: training policies that adapt quickly to new tasks or contexts using experience within episodes. Example: "which formulates meta-reinforcement learning by feeding in-context episodes into a recurrent neural network"
- Micro-episode: A fine-grained sub-trajectory (e.g., a tool-interaction step) treated as its own episode for supervision or credit assignment. Example: "each tool-interaction step can be treated as a micro-episode."
- Parallel sampling: Generating multiple independent solution attempts simultaneously at inference time. Example: "Parallel sampling generates multiple answers independently"
- Process reward models: Models that score intermediate reasoning/process steps rather than only the final answer. Example: "using process reward models"
- Proximal Policy Optimization (PPO): A widely used RL algorithm that stabilizes policy gradients via clipped updates. Example: "PPO~\citep{schulman2017proximal}"
- ReAct paradigm: A framework where LLMs interleave reasoning (Thought) with tool use (Action) and observations. Example: "ReAct paradigm~\citep{yao2022react}"
- Relative advantage: An advantage estimate computed relative to a baseline (e.g., group mean), often to reduce variance. Example: "estimates a dense relative advantage at the turn level"
- Retriever: A system that fetches relevant documents/passages to support question answering or reasoning. Example: "E5~\citep{wang2022text} as the retriever."
- Reward hacking: Gaming a learned or proxy reward signal in ways that do not align with true task success. Example: "lead to reward hacking and bias"
- Self-reflection: A mechanism where the model analyzes its own prior attempts to refine subsequent reasoning or actions. Example: "explicit self-reflections after each episode"
- Sequential refinement: Iteratively improving answers by conditioning each attempt on previous attempts. Example: "sequential refinement generates answers sequentially"
- Sparse rewards: Rewards provided only at the end or infrequently, making learning and credit assignment harder. Example: "sparse rewards at the end of each trajectory"
- Test-time scaling: Increasing computation or iterative attempts at inference time to improve reasoning quality. Example: "Test-time Scaling."
- Turn-level advantage: An advantage signal computed per interaction turn/step for finer credit assignment. Example: "turn-level grouped advantage formulation"
- Verifier: A rule-based or learned evaluator that checks the correctness of an answer or step. Example: "represents either a rule-based or model-based verifier."
Collections
Sign up for free to add this paper to one or more collections.