Search Self-play: Pushing the Frontier of Agent Capability without Supervision
Abstract: Reinforcement learning with verifiable rewards (RLVR) has become the mainstream technique for training LLM agents. However, RLVR highly depends on well-crafted task queries and corresponding ground-truth answers to provide accurate rewards, which requires massive human efforts and hinders the RL scaling processes, especially under agentic scenarios. Although a few recent works explore task synthesis methods, the difficulty of generated agentic tasks can hardly be controlled to provide effective RL training advantages. To achieve agentic RLVR with higher scalability, we explore self-play training for deep search agents, in which the learning LLM utilizes multi-turn search engine calling and acts simultaneously as both a task proposer and a problem solver. The task proposer aims to generate deep search queries with well-defined ground-truth answers and increasing task difficulty. The problem solver tries to handle the generated search queries and output the correct answer predictions. To ensure that each generated search query has accurate ground truth, we collect all the searching results from the proposer's trajectory as external knowledge, then conduct retrieval-augmentation generation (RAG) to test whether the proposed query can be correctly answered with all necessary search documents provided. In this search self-play (SSP) game, the proposer and the solver co-evolve their agent capabilities through both competition and cooperation. With substantial experimental results, we find that SSP can significantly improve search agents' performance uniformly on various benchmarks without any supervision under both from-scratch and continuous RL training setups. The code is at https://github.com/Alibaba-Quark/SSP.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a way to train AI “search agents” to get better at finding trustworthy information online and answering tough questions—without needing humans to label tons of training data. The method is called Search Self‑play (SSP). It lets one LLM play two roles: it creates challenging search questions and also tries to solve them. By competing and cooperating with itself, the AI steadily improves its searching, reasoning, and checking skills.
Key Objectives
The paper tries to solve three problems:
- How can we train AI agents that use web search to answer complex questions without relying on a huge amount of human-made training data?
- How can we make sure the AI’s self-made questions are correct and fair, so training doesn’t go off track?
- Can this self-play approach actually improve performance across different models and tasks?
Methods and Approach
Think of SSP like two classmates using the internet to study:
- One classmate (the “proposer”) builds tricky quiz questions by searching the web.
- The other classmate (the “solver”) tries to answer those questions using careful reasoning and more searching.
- They learn by competing (the proposer tries to stump the solver) and cooperating (they share the sources so answers can be verified).
Here’s how it works in simple steps:
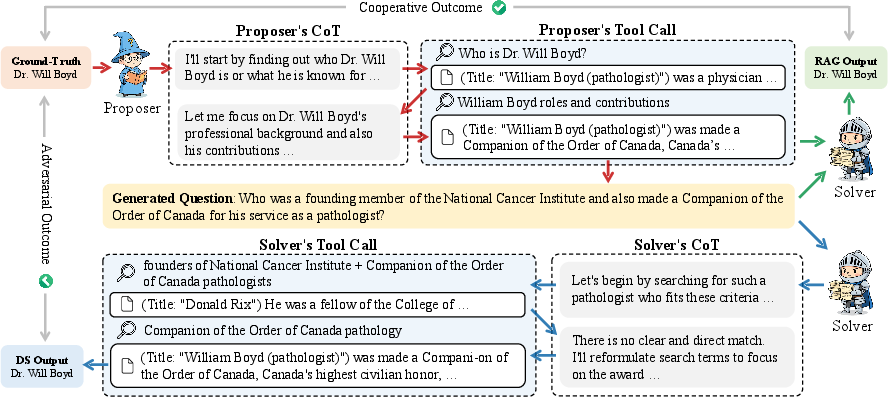
Step 1: The AI creates a question (Proposer)
- The proposer starts with a known correct answer (called the “ground truth”).
- It uses a search engine multiple times to gather facts, then writes a question that can be answered using those facts.
- It must follow clear formatting rules (so the question is easy to read and use).
Step 2: Verify the question using the gathered evidence (RAG)
- RAG stands for Retrieval-Augmented Generation. In everyday terms, it means “answer the question using the documents you found.”
- To make sure the question is valid, the solver must be able to answer it correctly using only the proposer’s collected search results (like a “cheat sheet” of sources).
- The system also mixes in a few unrelated documents to ensure the question isn’t just “too easy” when the context is artificially clean. This prevents cheating and encourages solid evidence.
Step 3: The AI solves the question (Solver)
- Now the solver does the full search-and-reasoning process (like a real student investigating online) and tries to produce the final answer.
- The system checks whether the solver’s answer matches the ground truth (using an “LLM-as-a-judge,” which is a careful comparison by another LLM).
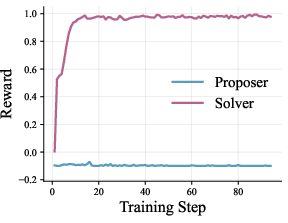
Step 4: Learning signals
- If the solver gets the answer right, the solver gets a positive reward.
- If the solver gets it wrong, the proposer gets a reward (because it posed a tough question).
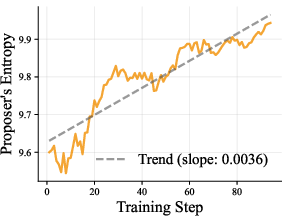
- Over time, both improve: the proposer learns to create well-formed, harder questions, and the solver learns stronger search and reasoning strategies.
Step 5: Preventing cheating and keeping quality high
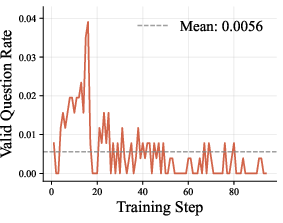
- The system filters out bad questions (like ones with no searches, ones that secretly include the answer, or ones too short to be interesting).
- The RAG check must succeed (the question must be answerable from the proposer’s sources), or the question is rejected.
- This keeps training honest and focused on real skills.
Main Findings
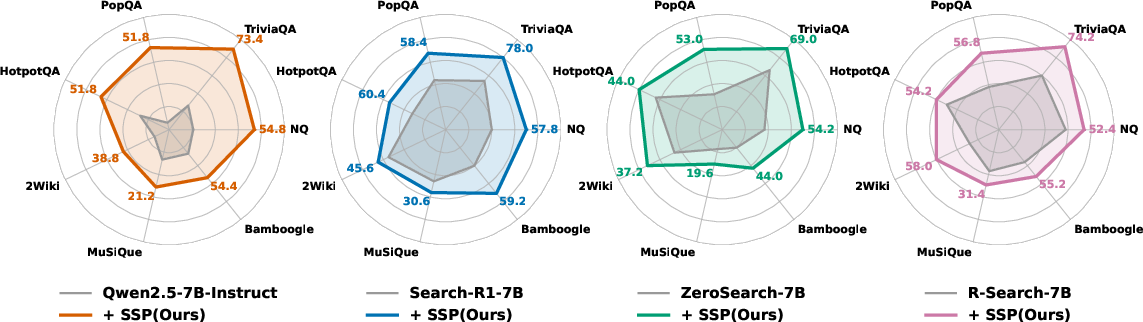
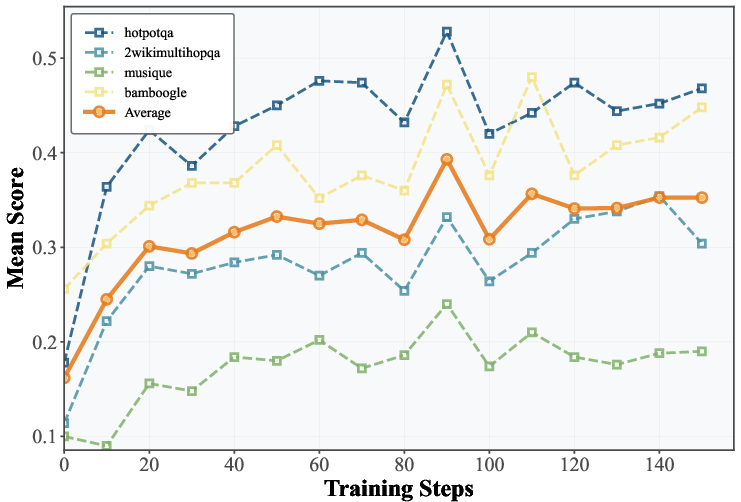
Across many tests, SSP made search agents better—without any human-annotated data.
A few highlights:
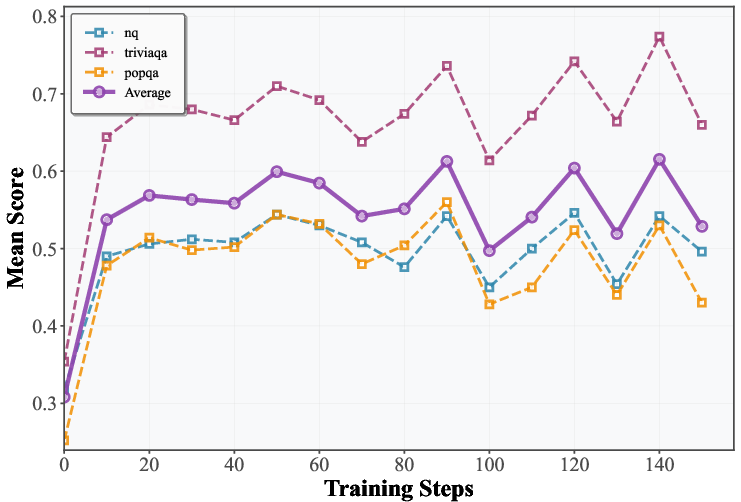
- From scratch, SSP gave big gains, especially for base (untuned) models. For example, on TriviaQA, one 7B model improved by over 40 points.
- It worked across different AI families (like LLaMA and Qwen models), showing the approach is general.
- Even models already trained for search (like Search‑R1 or R‑Search) improved further with SSP.
- Larger models also benefited, reaching state-of-the-art results on several benchmarks.
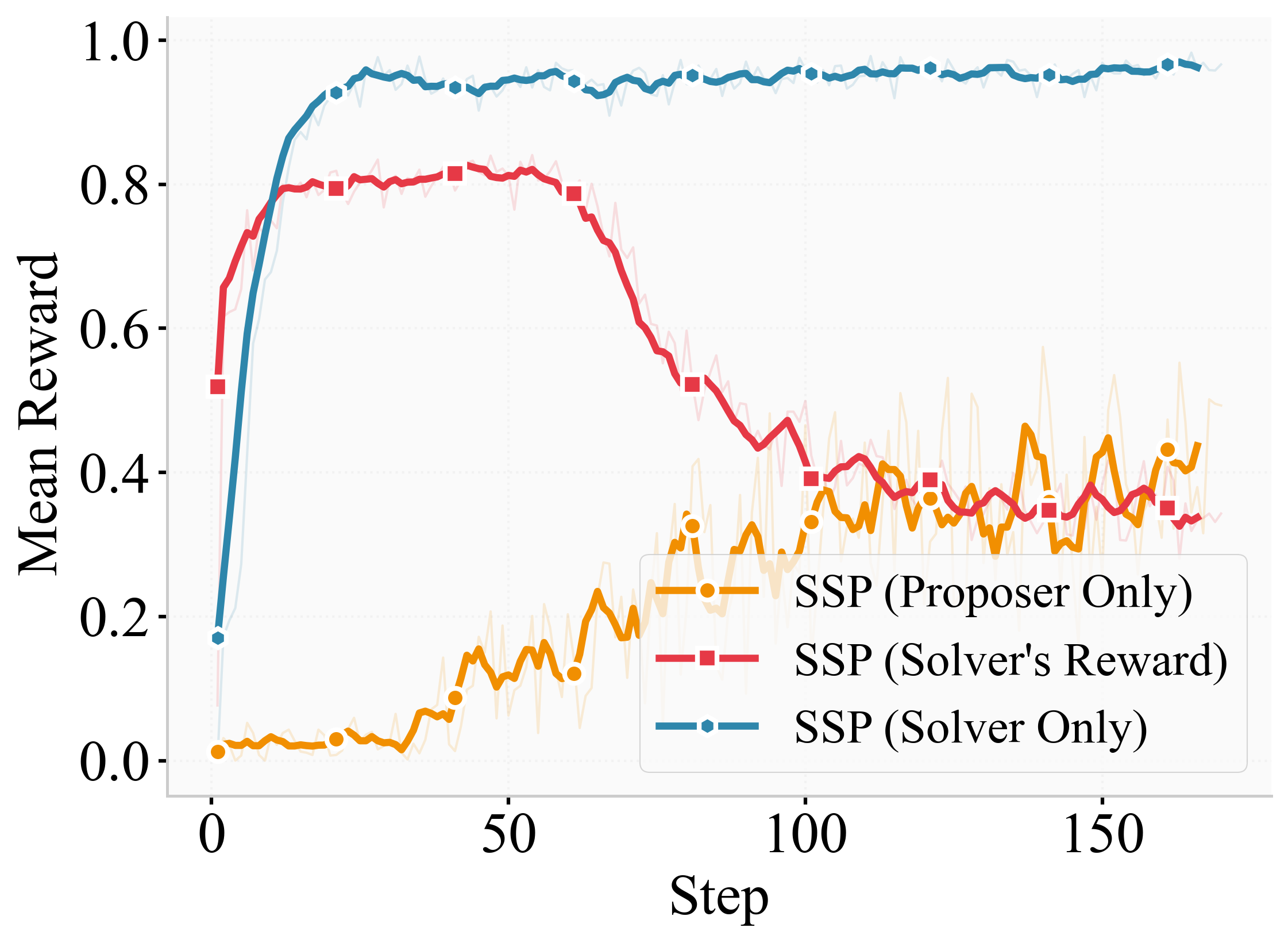
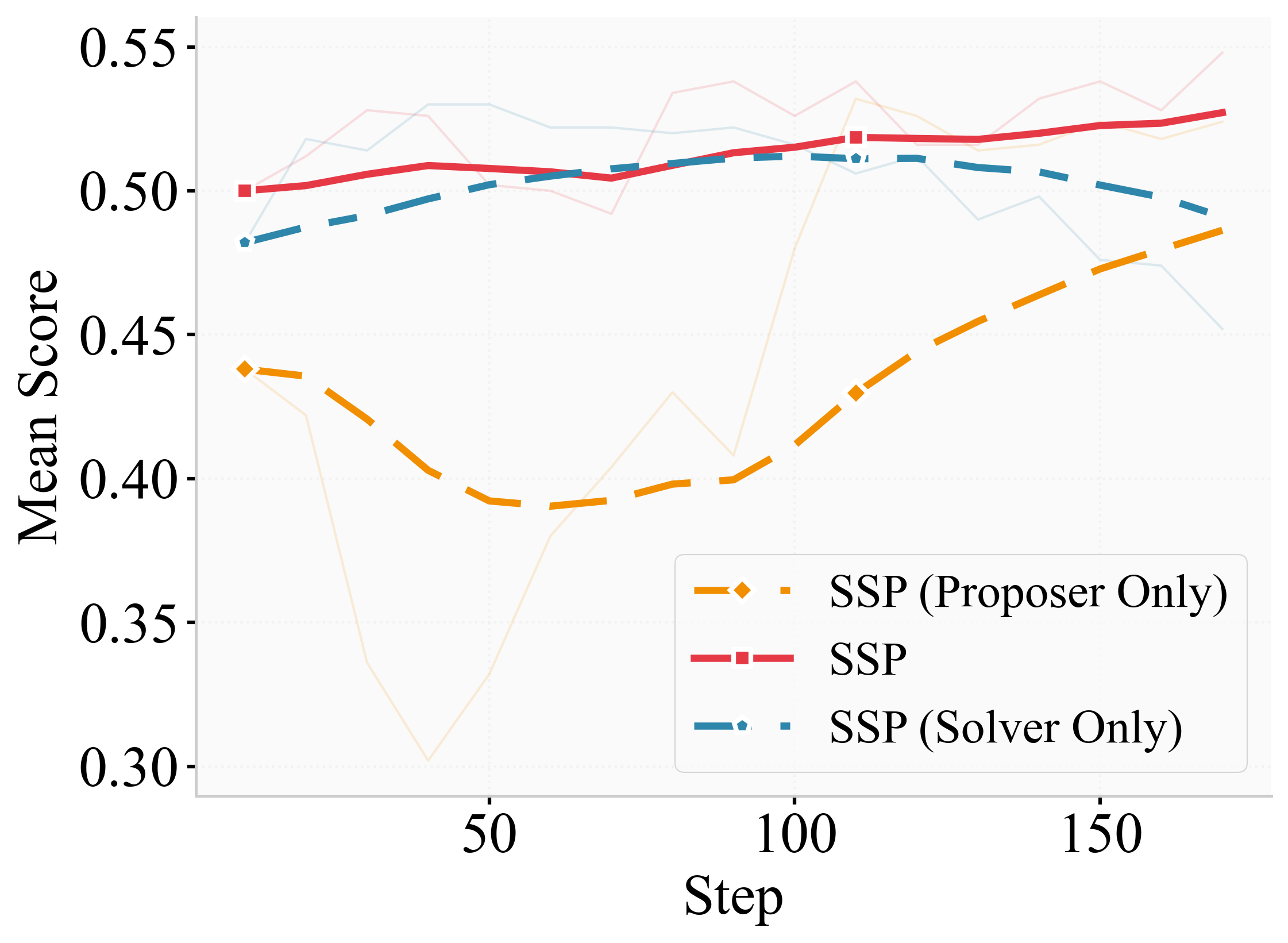
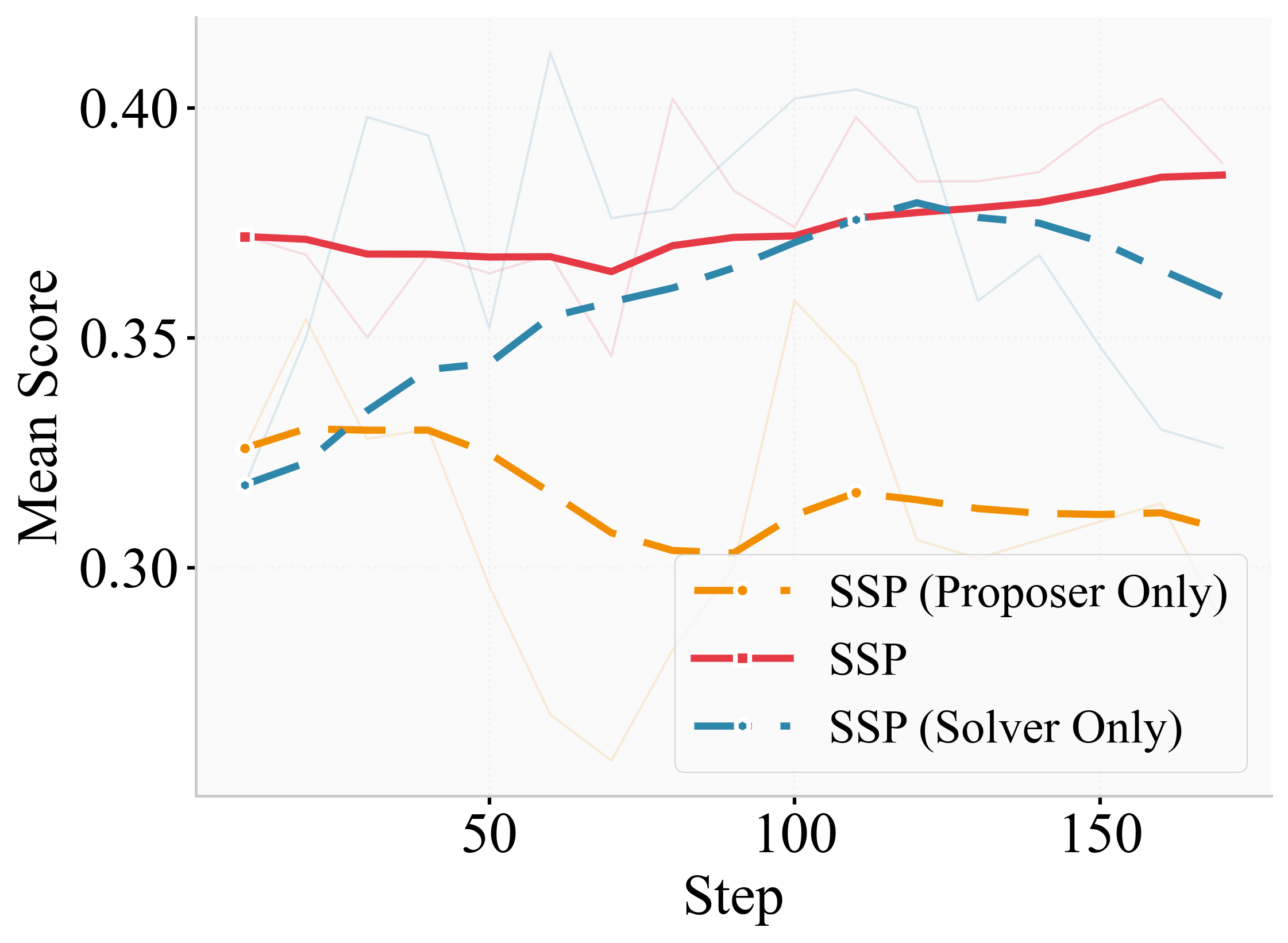
- An important ablation (a test where you remove parts of the method) showed:
- True self‑play (both roles learning) beat “fixed opponent” training (only the solver or only the proposer learns).
- The RAG verification step was critical—without it, performance dropped.
- Adding a small amount of unrelated “noise” documents during verification improved robustness (four extra docs was best).
Why this matters: SSP creates an adaptive curriculum. As the solver gets better, the proposer makes harder questions. This avoids overfitting and drives continuous improvement.
Implications and Impact
This approach shows that AI agents can teach themselves to be better researchers:
- It reduces the need for expensive human-labeled data, making training cheaper and more scalable.
- It builds stronger skills in searching, reasoning, and self‑checking—important for tasks like fact‑checking, legal analysis, and scientific review.
- It’s flexible: the ideas behind SSP could be extended to other agent types (like coding or GUI automation) that need reliable tool use.
- The careful verification step (RAG with noise) makes the training more trustworthy, pushing the AI to rely on solid evidence rather than shortcuts.
In short, Search Self‑play offers a practical path to building AI agents that get smarter on their own, using the web like a careful researcher—asking better questions, finding reliable information, and delivering accurate answers.
Knowledge Gaps
Below are the key knowledge gaps, limitations, and open questions that remain unresolved and could guide future research:
- The training setup uses a local E5 retriever on Wiki-2018 with only top-3 documents; generalization to open-web search, different retrievers, larger corpora, and dynamic content is untested.
- RAG verification depends on documents retrieved by the proposer; if those documents are misleading or contain errors, incorrect questions may still pass verification—robustness to noisy or adversarial evidence is not analyzed.
- The number and selection strategy of RAG noise documents is fixed (four random docs) and tuned empirically; adaptive or principled noise-injection strategies and their impact on both proposer behavior and solver robustness remain unexplored.
- Rewarding correctness via a single LLM-as-a-judge introduces potential bias and systematic errors; cross-judge validation, calibration, and sensitivity to judge choice are not reported.
- The binary reward function provides no step-wise credit assignment or trajectory-level shaping; improved reward designs (e.g., tool-use validity, citation fidelity, multi-hop consistency) are not explored.
- The proposer is conditioned on a ground-truth answer and learns to generate questions around known answers; whether this leads to unnatural task distributions or training artifacts compared to real-world queries with unknown answers is not examined.
- Filtering rules (e.g., “do not include the answer in the question”) and RAG verification ensure format and answerability, but do not assess clarity, non-ambiguity, logical soundness, or novelty of proposed questions—no human or external quality assessment is provided.
- The cooperative constraint is enforced via rejection sampling, which can be sample-inefficient; alternative constrained RL methods (e.g., Lagrangian approaches, CPO, dual optimization) are not investigated.
- The min-max objective uses REINFORCE for the proposer and GRPO for the solver; the sensitivity to optimization algorithms, baselines, variance reduction techniques, and hyperparameters is only partially ablated.
- Training stability over longer horizons, non-stationarity in co-evolution, catastrophic forgetting, and curriculum dynamics beyond the reported 150–200 steps are not studied.
- Benchmarks are evaluated on small subsets (typically 500 samples, all 125 for Bamboogle); statistical robustness, variance across seeds, and significance testing are not reported.
- The evaluation metric is pass@1 accuracy judged by an LLM; coverage of multi-answer cases, entity normalization, temporal reasoning, and citation grounding are not rigorously measured.
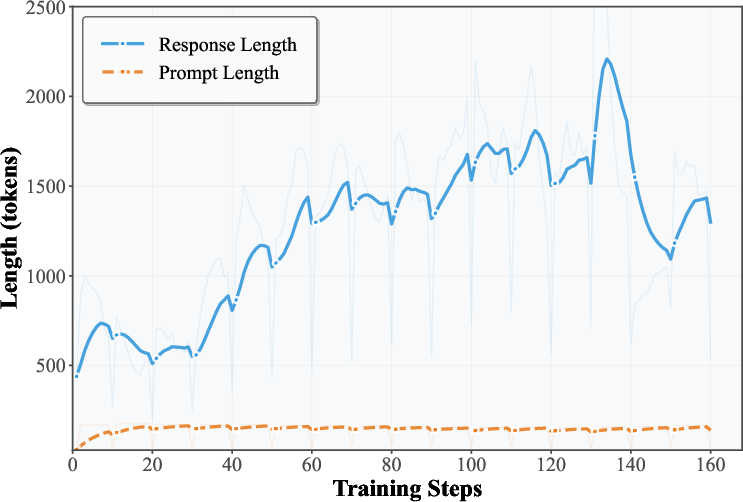
- Computational costs (tokens, tool calls per episode, wall-clock time, scaling behavior) and efficiency trade-offs of SSP (two agents performing multi-turn search per batch) are not quantified.
- Potential reward hacking remains a risk (e.g., generating questions that are RAG-easy but deep-search-hard); beyond adding noise docs, formal detection/mitigation strategies and failure case taxonomies are missing.
- The approach is limited to search agents; extension to other tool-augmented agents (GUI, code, APIs) and the modifications needed for verification and reward design are not demonstrated.
- Generalization across languages, domains beyond Wikipedia, and specialized corpora (e.g., legal, biomedical) is not evaluated.
- The retriever and search pipeline are fixed; ablations on retrieval depth (top-k), query reformulation strategies, and document ranking quality are absent.
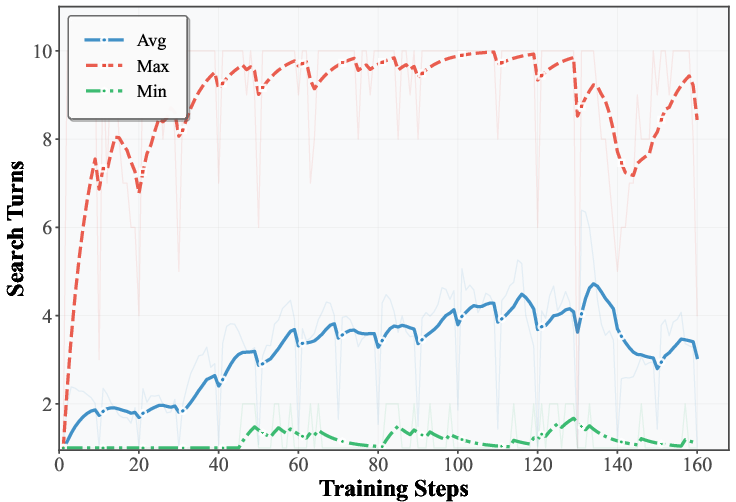
- No analysis of how SSP affects search behavior itself (e.g., number of hops, query diversity, tool-use correctness, citation fidelity); improvements are reported only in final accuracy.
- The answer set used to seed proposer generation is not fully characterized; possible overlap or leakage with evaluation sets and its influence on outcomes is unclear.
- Human-in-the-loop evaluation (e.g., rating question quality, reasoning transparency, and evidence sufficiency) is absent, limiting interpretability of the gains.
- Safety and ethics are unaddressed: SSP could synthesize sensitive or misleading questions; content filters, misinformation safeguards, and responsible-use policies are not discussed.
- The use of masked <information> segments during training may impact learning from tool feedback; the effect of masking policies on stability and capability is not examined.
- Replay-buffer strategies are briefly discussed but not deeply analyzed; long-term reuse vs. novelty trade-offs, buffer curricula, and their effects on proposer/solver co-evolution remain open.
- The method assumes verifiable ground truths for training; pathways to self-play without pre-specified answers, or to bootstrap answer sets with external validation, are not explored.
- Comparisons against stronger proprietary agents or cross-lab baselines are absent; the competitive positioning of SSP in realistic deployments is uncertain.
Practical Applications
Overview
Below are practical, real-world applications that stem from the paper’s findings, methods, and innovations around Search Self-play (SSP)—a self-supervised, verifiable-reward reinforcement learning framework for deep search agents. Applications are grouped into immediate and long-term categories, with links to relevant sectors, potential tools/products/workflows, and feasibility notes.
Immediate Applications
These applications can be deployed now with the provided SSP codebase and standard RAG/search infrastructure.
- Self-supervised training for enterprise RAG assistants
- Sector: software, customer service, enterprise knowledge management
- What: Use SSP to continuously fine-tune internal search/chat assistants without human labels by synthesizing multi-hop queries from known answers (e.g., FAQs, resolution codes), verifying via RAG, and updating policies (solver via GRPO, proposer via REINFORCE).
- Tools/products/workflows: SSP training loop (VeRL/SGLang), retriever (e.g., E5), LLM-as-a-judge, nightly fine-tuning pipelines
- Dependencies/assumptions: Curated ground-truth answer sets; adequate retriever coverage; compute budgets; guardrails (rule-based filters, noisy RAG) to avoid reward hacking
- Evidence-grounded answer auditing for RAG pipelines
- Sector: enterprise AI, compliance
- What: Integrate SSP’s RAG verification step into QA/CI to ensure answers are supported by retrieved documents; flag unsupported outputs.
- Tools/products/workflows: “RAG Verifier” module using LLM-as-a-judge, offline verification jobs, audit logs
- Dependencies/assumptions: Reliable judge model; access to full retrieval context; policy for handling flagged outputs
- Adaptive curriculum generation for academic QA benchmarks
- Sector: academia (NLP, IR)
- What: Use the proposer to generate progressively harder, multi-hop questions anchored on ground-truth answers; verify with RAG; build new evaluation sets or training curricula.
- Tools/products/workflows: SSP open-source repo; dataset creation scripts; benchmark hosting
- Dependencies/assumptions: Ground-truth pools; permissions to crawl/cite sources; reproducible judge prompts
- Mining query rewriting and search strategies
- Sector: search/information retrieval
- What: Analyze proposer trajectories to extract effective multi-turn search strategies (query reformulation, page selection, evidence chaining) and feed them into production search systems.
- Tools/products/workflows: Strategy extraction from tool logs; heuristics deployment; A/B testing
- Dependencies/assumptions: High-quality interaction logs; retriever quality; safe tool invocation sandbox
- Continual learning for consumer research assistants
- Sector: consumer software
- What: Embed SSP for periodic self-improvement of personal research assistants (news/literature summaries) using user’s document collections as RAG sources.
- Tools/products/workflows: Local indexers, nightly self-play jobs, configurable prompts for proposer/solver
- Dependencies/assumptions: User consent and privacy controls; compute availability; judge reliability
- Coverage expansion of FAQs and knowledge bases
- Sector: customer support
- What: Generate diverse paraphrases and multi-hop formulations for existing answers; verify grounding; enrich KB indexing and training data.
- Tools/products/workflows: “Evidence-Verified Query Synthesizer”; KB curation pipeline
- Dependencies/assumptions: High-quality canonical answers; deduplication; governance for content updates
- Reduced-annotation training pipelines for startups building search agents
- Sector: AI startups, developer tools
- What: Bootstrap search agents with SSP to minimize supervised data collection while maintaining verifiable rewards.
- Tools/products/workflows: SSP repo, GRPO/REINFORCE training recipes, cloud training
- Dependencies/assumptions: Compute budget; basic retrieval infrastructure; standardized judge prompts
- Robustness checks with noisy RAG contexts
- Sector: ML operations
- What: Adopt SSP’s noisy-document injection during verification to prevent models from exploiting narrow contexts and to test resilience to irrelevant information.
- Tools/products/workflows: Noise mixing scheduler (optimal ~4 docs per paper’s ablation), verification harness
- Dependencies/assumptions: Data mixing pipeline; monitoring to balance verification difficulty vs false negatives
Long-Term Applications
These applications require additional research, scaling, domain adaptation, or governance to be production-ready.
- Autonomous, evidence-backed research agents
- Sector: scientific R&D, legal, finance, healthcare
- What: SSP-based co-evolving agents that continuously propose research questions, gather evidence, and learn to solve complex tasks (literature triage, case law synthesis, market analyses) with minimal human labels.
- Tools/products/workflows: “Autonomous Researcher” platform; domain-specific retrieval (PubMed, case law); claim verification modules
- Dependencies/assumptions: High-coverage, domain-specific corpora; robust verifiable reward design beyond QA; human oversight for high-stakes use
- Extension of SSP to GUI and coding agents
- Sector: software automation, RPA, developer tools, robotics
- What: Generalize self-play with verifiable rewards to tool-rich agents (GUI navigation, IDE assistants) to reduce label needs and scale training across tasks.
- Tools/products/workflows: Verifiable outcomes (unit tests, UI states, screenshots); tool APIs; multi-modal prompts
- Dependencies/assumptions: Well-defined reward functions; reliable environment simulators; safety constraints
- Government and public-sector information services
- Sector: public administration
- What: Scale citizen-facing chatbots with evidence-grounded responses and continuous self-improvement using SSP; ensure transparency and auditability.
- Tools/products/workflows: Documented RAG audit trails; public record retrieval; oversight dashboards
- Dependencies/assumptions: Governance frameworks; fairness and accessibility standards; data provenance controls
- Personalized education and adaptive tutoring
- Sector: education/edtech
- What: Tutors that self-generate and verify progressively harder questions from textbooks/lecture notes and adapt curricula to student performance.
- Tools/products/workflows: Course material indexers; nightly SSP runs; pedagogy-aligned question templates
- Dependencies/assumptions: Licensed content; student privacy; pedagogical validation; explainability requirements
- Enterprise knowledge gap discovery
- Sector: knowledge management
- What: Use proposer-generated questions that fail RAG verification to identify missing/outdated content; trigger curation and documentation workflows.
- Tools/products/workflows: “Knowledge Gap Detector”; editorial pipeline; content freshness metrics
- Dependencies/assumptions: Editorial resources; clear escalation policies; version control
- Compliance and risk auditing in regulated industries
- Sector: finance, healthcare, law
- What: SSP-driven adversarial QA to probe weaknesses and enforce evidence standards (e.g., every claim must map to a retrieved document).
- Tools/products/workflows: “Adversarial Evidence Auditor”; compliance dashboards; red-teaming cycles
- Dependencies/assumptions: Regulatory mapping; immutable logs; human-in-the-loop review
- Misinformation detection and fact-checking at scale
- Sector: media platforms, research NGOs
- What: Train agents resilient to irrelevant/noisy info and capable of verifying claims with multi-hop evidence; prioritize unique, strongly supported answers.
- Tools/products/workflows: Claim extraction; source ranking; SSP training with domain corpora
- Dependencies/assumptions: High-quality, trustworthy corpora; bias mitigation; transparency tooling
- Standardized verifiable-reward frameworks for agent training
- Sector: AI standards/policy, tooling
- What: Community tools that encode RAG-based reward checks and judge protocols for agentic RL (beyond QA), enabling reproducible, auditable training.
- Tools/products/workflows: Open judge prompt libraries; benchmark governance; certification processes
- Dependencies/assumptions: Cross-industry consensus on metrics; interoperability standards
- Cost-efficient scaling of self-supervised agent training
- Sector: cloud/compute
- What: Optimize SSP training for long contexts and tool use (e.g., mixed precision, curriculum schedules, replay buffers) to lower costs while maintaining gains.
- Tools/products/workflows: Training orchestration; adaptive batch completion; caching retriever results
- Dependencies/assumptions: Hardware availability; efficient memory management; profiling
- Security hardening of AI systems
- Sector: cybersecurity
- What: Use proposer to generate adversarial retrieval tasks (prompt injection, poisoned context, ambiguous evidence) and harden solver against them.
- Tools/products/workflows: Threat modeling playbooks; adversarial SSP tasks; defensive prompting and filtering
- Dependencies/assumptions: Secure tool sandboxes; continuous monitoring; incident response readiness
Glossary
- Advantage (policy gradient): The baseline-adjusted measure of how much a sampled action’s return exceeds the average, used to reduce variance in policy-gradient updates. "where the advantage \hat{A}ij = r{\text{solve},i}j - \frac{1}{n}\sum_{k=1}n r_{\text{solve},i}k"
- Agentic reinforcement learning (RL): Reinforcement learning applied to tool-using LLM agents to improve task-solving, distinct from supervised instruction tuning. "leverage agentic reinforcement learning (RL) to enhance question-answering capabilities"
- Auto-regressive next-token prediction policy: A model that generates text by predicting one token at a time conditioned on the previous tokens. "An auto-regressive next-token prediction policy of LLM iteratively outputs next-token "
- Batch Sampling Strategy: The policy for filling training batches (e.g., with resampling or replay) when some proposed items are filtered out. "Batch Sampling Strategy & Replay Buffer (Periodic Reset)"
- Co-evolution: Mutual improvement of multiple learning components (e.g., proposer and solver) that adapt to each other during training. "The co-evolution of the proposer and solver is critical for pushing the frontier of agent capability."
- Deep search agents: LLM-driven systems that perform iterative search, retrieval, and reasoning to answer complex queries. "Deep search agents leverage the power of search engines and the reasoning capacities of LLMs to conduct multi-turn retrievals and analyses"
- Dynamic Resampling: A batch-completion tactic that keeps generating new valid items until the batch is full. "Dynamic Resampling: The proposer continues to generate new questions until a full batch of valid problems is collected."
- E5 retriever: A dense retrieval model used to fetch relevant documents given a query. "A local E5 retriever with a Wiki-2018 corpus is incorporated in our training and evaluation"
- Group Relative Policy Optimization (GRPO): A policy-gradient method that uses group-average rewards as baselines to reduce variance across sampled trajectories. "A natural updating method for the solver's policy is Group Relative Policy Optimization (GRPO)"
- KL divergence (KL): A measure of how one probability distribution diverges from a reference distribution, used as a regularization term in RL fine-tuning. " - \beta \nabla_\theta \text{KL}[\pi_\theta || \pi_\text{ref}]"
- LLM-as-a-judge: Using a LLM to grade or verify outputs (e.g., correctness of answers) during training or evaluation. "we implement with an LLM-as-a-judge function"
- Markov decision process (MDP): A formal framework for sequential decision-making with states, actions, transitions, and rewards. "We model the search agent exploration as a token-level Markov decision process ."
- Multi-hop reasoning: Reasoning that requires combining information across multiple sources or steps to reach an answer. "deep search agents employ multi-hop reasoning, dynamic query reformulation, and self-guided exploration"
- pass@1 accuracy: The proportion of tasks correctly solved on the first attempt, commonly used in LLM evaluation. "All results are reported in terms of pass@1 accuracy."
- RAG verification: Validating a proposed question and answer by checking if the answer is derivable from the retrieved documents provided to the solver. "Another key component of our SSP framework is the RAG verification, which validates each proposed question is correct and answerable"
- REINFORCE: A classic policy-gradient algorithm that updates policies based on sampled returns without value-function baselines. "We use the REINFORCE algorithm to update the proposer's policy ."
- Replay buffer: A memory of previously generated valid items used to populate batches and stabilize training. "We maintain a replay buffer of all previously generated valid questions."
- Rejection sampling: A sampling strategy that discards invalid or low-quality items and keeps sampling until constraints are satisfied. "we leverage rejection sampling for the cooperative objective instead."
- Reinforcement learning with verifiable rewards (RLVR): RL where rewards are computed from objective, checkable criteria (e.g., matching ground-truth answers). "Reinforcement learning with verifiable rewards (RLVR) has become the mainstream technique for training LLM agents."
- Retrieval-Augmented Generation (RAG): Generating answers conditioned on retrieved external documents to improve accuracy and grounding. "In contrast to traditional Retrieval-Augmented Generation (RAG) methods"
- Reward hacking: Exploiting the reward function in unintended ways that improve the metric without real capability gains. "could lose its effectiveness due to the reward hacking"
- Search Self-play (SSP): A training framework where a single LLM alternates between proposing search tasks and solving them, with verifiable outcomes. "In this search self-play (SSP) game, the proposer and the solver co-evolve their agent capabilities through both competition and cooperation."
- Tool-integrated rollout: An execution trace that interleaves model reasoning with tool calls and tool observations. "Tool-integrated rollout is an interactive sequence of reasoning and tool invocation, with the search tool providing external information."
- Token-level action generation: Treating each emitted token as an action within an RL formulation of language generation. "The action space is equivalent to the vocabulary set for token-level action generation."
- Zero-sum adversarial game: A competitive setup where one agent’s gain is another agent’s loss, used to drive mutual improvement. "the search self-play can be regarded as a zero-sum adversarial game."
Collections
Sign up for free to add this paper to one or more collections.

