- The paper proposes a two-stage Actor–Meta-Refiner architecture that locally corrects errors in search-integrated reasoning.
- It introduces a hybrid reward system combining outcome-level and process-level signals to enhance both accuracy and sample efficiency.
- Empirical results on multiple QA datasets demonstrate up to a 25.3% improvement, validating the approach's robustness and efficiency.
Search-R2: Actor-Refiner Collaboration for Enhanced Search-Integrated Reasoning
Introduction and Motivation
Search-integrated reasoning agents, which interleave LLMs with search engines, have emerged as the paradigm for knowledge-intensive tasks such as open-domain and multi-hop question answering. Despite progress, these agents remain hampered by brittle credit assignment: reinforcement learning (RL) agents typically receive only sparse, trajectory-level rewards, which fail to differentiate efficient, logically coherent reasoning from fortuitous guessing. This leads to error propagation and sample inefficiency, particularly as intermediate missteps are not directly diagnosed or corrected. The "Search-R2: Enhancing Search-Integrated Reasoning via Actor-Refiner Collaboration" (2602.03647) paper tackles these issues by proposing a two-stage Actor–Meta-Refiner architecture, enabling localized correction and denser, process-sensitive reward shaping.
The Search-R2 framework decomposes trajectory generation into an Actor (responsible for generating initial reasoning and search queries) and a Meta-Refiner (responsible for error diagnosis and causal correction via a "cut-and-regenerate" mechanism). The Actor's outputs—reasoning traces interleaved with search tool invocations—are first globally validated by a Discriminator for coherence. If errors are detected, a Trimmer localizes the first flawed step, truncates subsequent tokens, and regenerates only the erroneous suffix, preserving the verified prefix.

Figure 1: Comparison of Search-R1 and Search-R2. The latter halts error propagation by cut-and-regenerate at the point of failure.
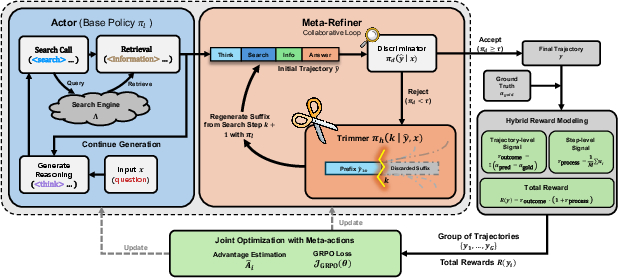
Figure 2: Detailed overview of Search-R2 architecture, showing joint optimization of Actor and Meta-Refiner policies with hybrid reward.
This approach departs from prior methods based on trajectory-level rejection sampling or monolithic RL optimization, which are both sample-inefficient and insensitive to the provenance of errors.
Hybrid Reward and Joint Optimization
A primary innovation in Search-R2 is the introduction of a hybrid reward, comprising both an outcome-level signal (Exact Match with gold answer) and a process-level reward measuring the evidence density and informativeness of retrieved chunks in the reasoning trace. Critically, the process reward is computed only for correct trajectories, preventing reward hacking by retrieval spamming.
Joint optimization of the Actor and Meta-Refiner is performed using Group Relative Policy Optimization (GRPO). This allows credit to flow not only to generation steps but also to decisions about when to intervene and how to localize errors, subsuming both exploration and exploitation in a principled policy improvement framework.
Theoretical Guarantees
The paper provides a rigorous formalization of the Actor–Meta-Refiner interaction as a smoothed mixture policy, quantifying the net reward improvement (ΔJ) over base actors and rejection sampling baselines. This decomposition reveals three governing factors:
- Selection Precision: The discriminator's ability to accept high-reward trajectories and reject low-reward ones.
- Trimming Skill: The trimmer’s accuracy at localizing effective cut-points that, upon regeneration, yield higher expected reward.
- Intervention Volume: The proportion of trajectories subject to intervention; optimization must balance correcting enough errors with not incurring unnecessary editing overhead.
Under mild assumptions (positive covariance between meta-refiner actions and local reward increments), the collaborative model guarantees a strict performance improvement over conventional rejection sampling.
Empirical Results
Experimental evaluation is conducted on seven QA datasets (NQ, TriviaQA, PopQA, HotpotQA, 2WikiMultiHopQA, Musique, and Bamboogle) with multiple LLM backbones ranging from 7B to 32B parameters. Results demonstrate substantial gains across all settings:
- EM Performance: On complex tasks (e.g., Bamboogle), Search-R2 achieves up to 25.3% relative gain over prior search-integrated RL baselines at comparable model scale. For instance, with Qwen2.5-32B, Search-R2 attains 56.4 Average EM on Bamboogle, clearly outperforming all baselines.
- Sample Efficiency: Even when compared against Search-R1 with doubled rollout budgets, Search-R2 (single-revision) is both more accurate and more computationally efficient.
- Ablation Analysis: Both the Meta-Refiner and hybrid process reward contribute distinct and complementary improvements, with joint optimization providing the largest gains.
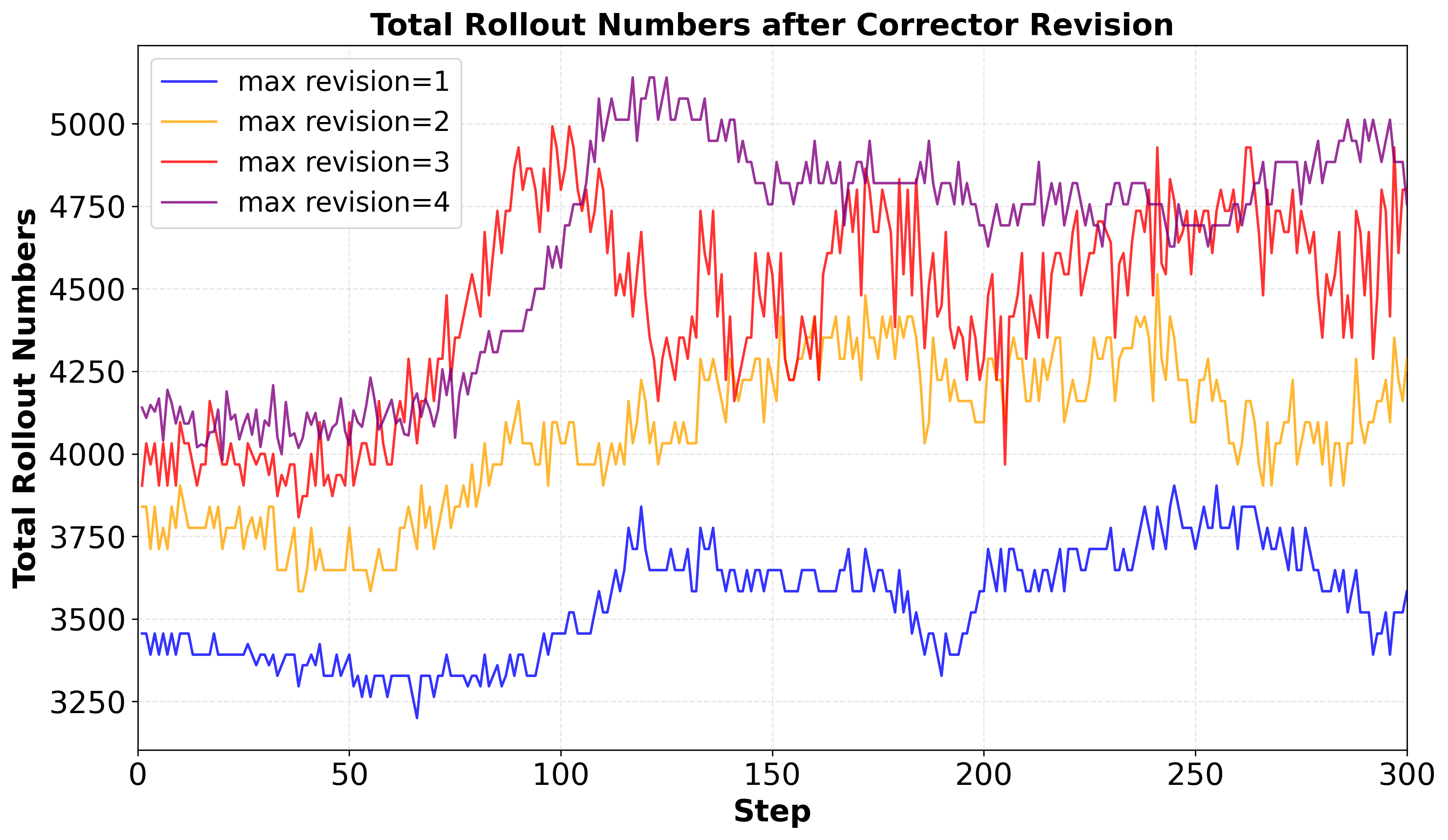
Figure 3: Total rollout counts for various maximum revision settings, demonstrating high sample efficiency even with single-step refinements.
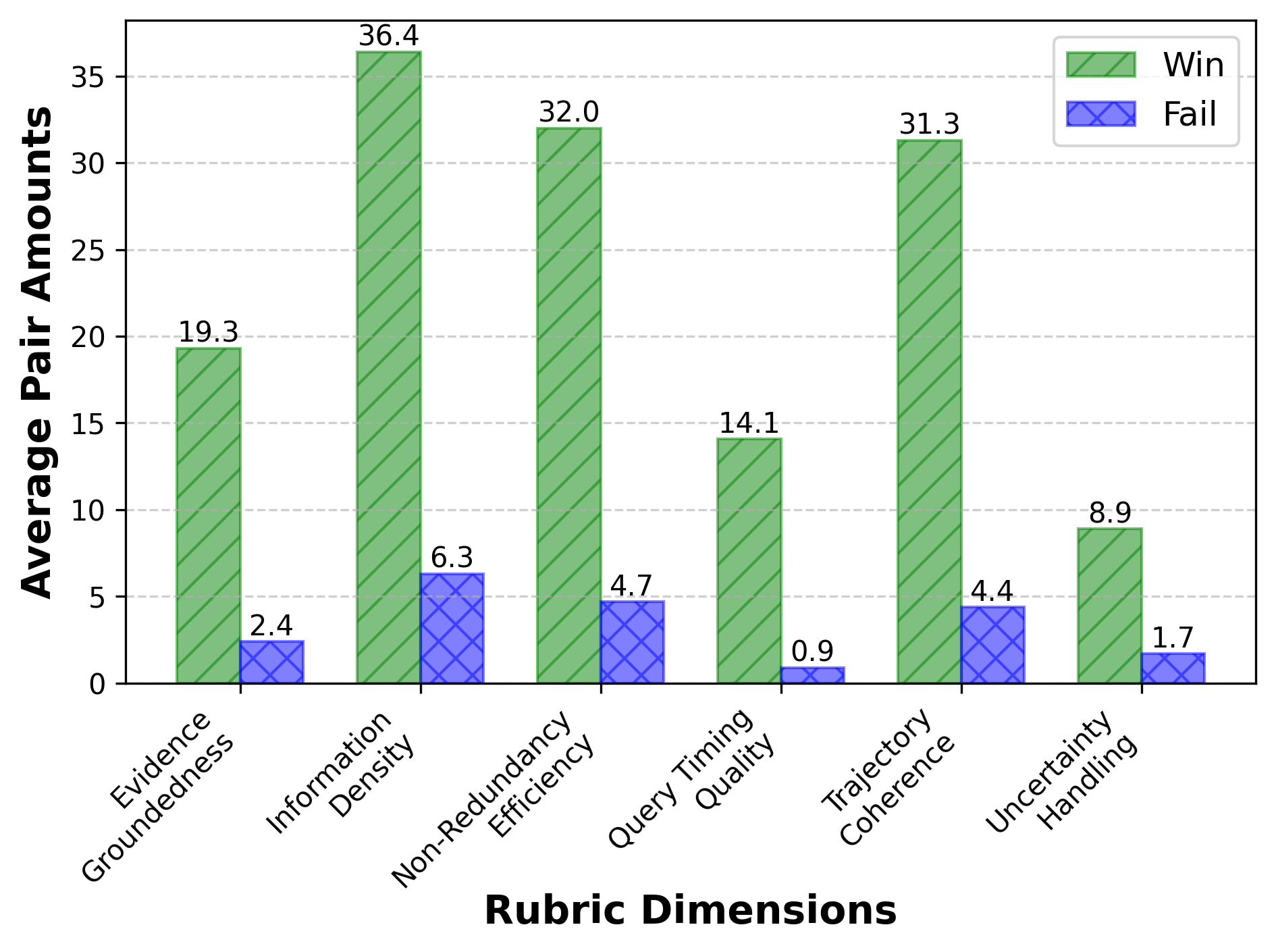
Figure 4: Win/loss analysis of Search-R2 versus Search-R1 across multiple datasets and rubric dimensions.
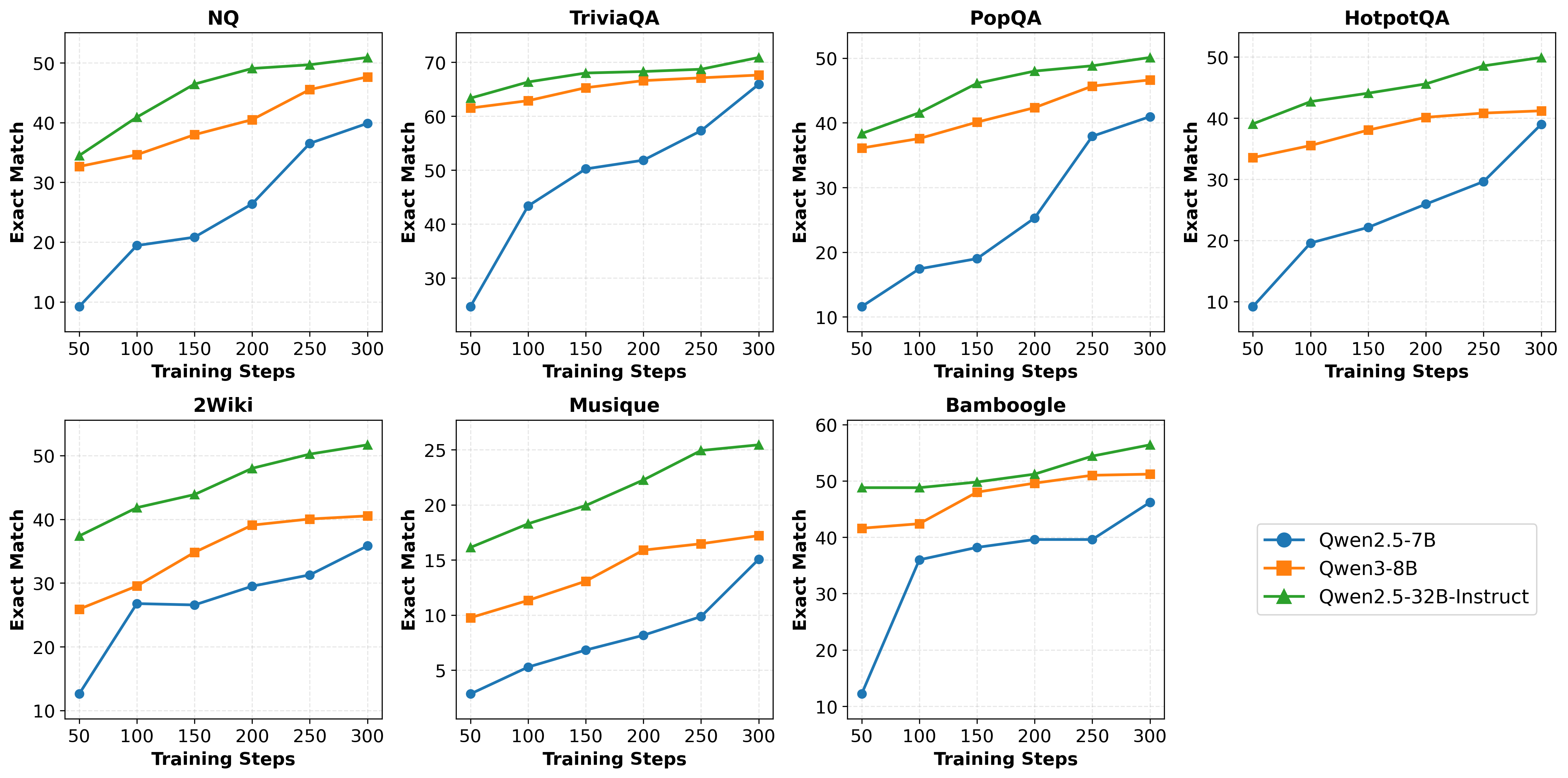
Figure 5: Convergence dynamics of Search-R2 on all datasets, showing consistent optimization progress regardless of model backbone.
Human and LLM-based rubric evaluations confirm improvements in evidence groundedness, information density, non-redundancy, query timing, trajectory coherence, and uncertainty handling.
Implications and Future Prospects
Search-R2 advances the methodology for search-augmented reasoning in at least three directions:
- Robustness: By actively correcting the reasoning chain at localized error points, error propagation loops are interrupted early, substantially mitigating hallucination cascades caused by retrieval noise.
- Sample Efficiency: Preservation of valid prefixes (rather than full re-sampling) minimizes computational waste and enables accurate models even at smaller model scales.
- Fine-Grained Credit Assignment: Jointly optimizing not only what to generate but how and when to intervene allows for end-to-end credit assignment at all levels of the agent's interaction trajectory.
Practically, this framework provides a blueprint for scalable multi-agent LLM systems in which self-correction and self-refinement are deeply integrated, applicable to autonomous web agents, biomedical QA, and long-horizon agentic workflows. Theoretically, it lays groundwork for new RL training algorithms that go beyond sparse endpoint rewards and monolithic optimization.
Likely future directions include extending the multi-stage refinement process to fully hierarchical agent architectures, incorporating uncertainty estimation and active exploration for improved meta-refiner policies, or integrating more expressive process rewards (such as structural coverage or logic consistency).
Conclusion
Search-R2 (2602.03647) introduces an Actor–Meta-Refiner collaboration paradigm for dynamic search-integrated reasoning, addressing bottlenecks in credit assignment and robustness plaguing current LLM-driven agents. Its principled use of trajectory-localized interventions and hybrid rewards achieves strong empirical and theoretical advances, setting a new standard for interactive, search-augmented language agents.