ZipMap: Linear-Time Stateful 3D Reconstruction with Test-Time Training
Abstract: Feed-forward transformer models have driven rapid progress in 3D vision, but state-of-the-art methods such as VGGT and $π3$ have a computational cost that scales quadratically with the number of input images, making them inefficient when applied to large image collections. Sequential-reconstruction approaches reduce this cost but sacrifice reconstruction quality. We introduce ZipMap, a stateful feed-forward model that achieves linear-time, bidirectional 3D reconstruction while matching or surpassing the accuracy of quadratic-time methods. ZipMap employs test-time training layers to zip an entire image collection into a compact hidden scene state in a single forward pass, enabling reconstruction of over 700 frames in under 10 seconds on a single H100 GPU, more than $20\times$ faster than state-of-the-art methods such as VGGT. Moreover, we demonstrate the benefits of having a stateful representation in real-time scene-state querying and its extension to sequential streaming reconstruction.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
ZipMap: A simple explanation for teens
What is this paper about?
This paper introduces ZipMap, a computer program that can quickly turn lots of photos or a video into a 3D model of the scene. It figures out where the camera was for each picture (camera pose), how far away things are (depth), and a cloud of 3D points that represent the scene (point cloud). The big deal: it does this very fast, even with hundreds of images, while keeping high quality.
What questions were the researchers trying to answer?
The authors focused on three main questions:
- Can we reconstruct 3D scenes from many images much faster than current top methods, without losing accuracy?
- Is there a way to avoid comparing every image with every other image (which is slow) and still keep the whole scene consistent?
- Can the system keep a useful “memory” of the scene so you can ask it questions later, like “What would the scene look like from a new viewpoint?” in real time?
How does ZipMap work? (In everyday language)
Think of reading a long set of photos like reading a big book:
- Old methods try to compare every page with every other page to understand the whole story. That’s like checking every pair of pages, which explodes in cost as the book gets longer.
- ZipMap skims each page carefully and then “zips” the important information into a compact memory so it can recall the whole story quickly, without re-reading every page against every other.
Here are the main ideas, with simple analogies:
- Turning images into tokens: Each image is broken into small pieces (patches) and turned into “tokens” (numbers that represent visual features), like turning a page into a set of meaningful notes.
- Local attention within each image: The model looks within each image to understand patterns and shapes (like focusing on one page at a time).
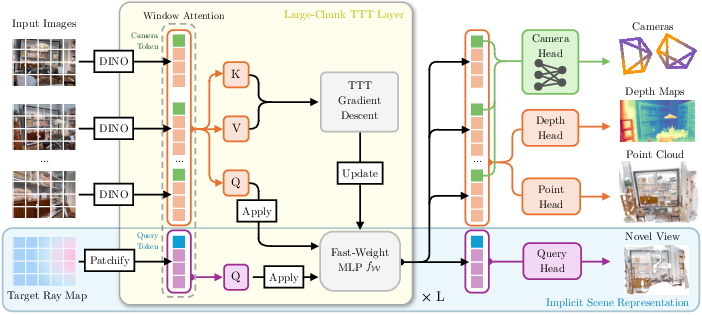
- Test-Time Training (TTT) layers = zipping the scene: As the model reads all images once, it updates a small set of internal numbers called “fast weights.” This is like a notepad the model writes on while it’s reading. These fast weights store the whole scene’s gist in a compact way. Crucially, the cost grows only with the number of images (linear), not with the number of image pairs (quadratic).
- One-pass predictions: In a single run, ZipMap outputs:
- Camera poses (where the camera was and where it was pointing),
- Depth maps (how far each pixel is),
- Point maps/point clouds (3D points for the scene).
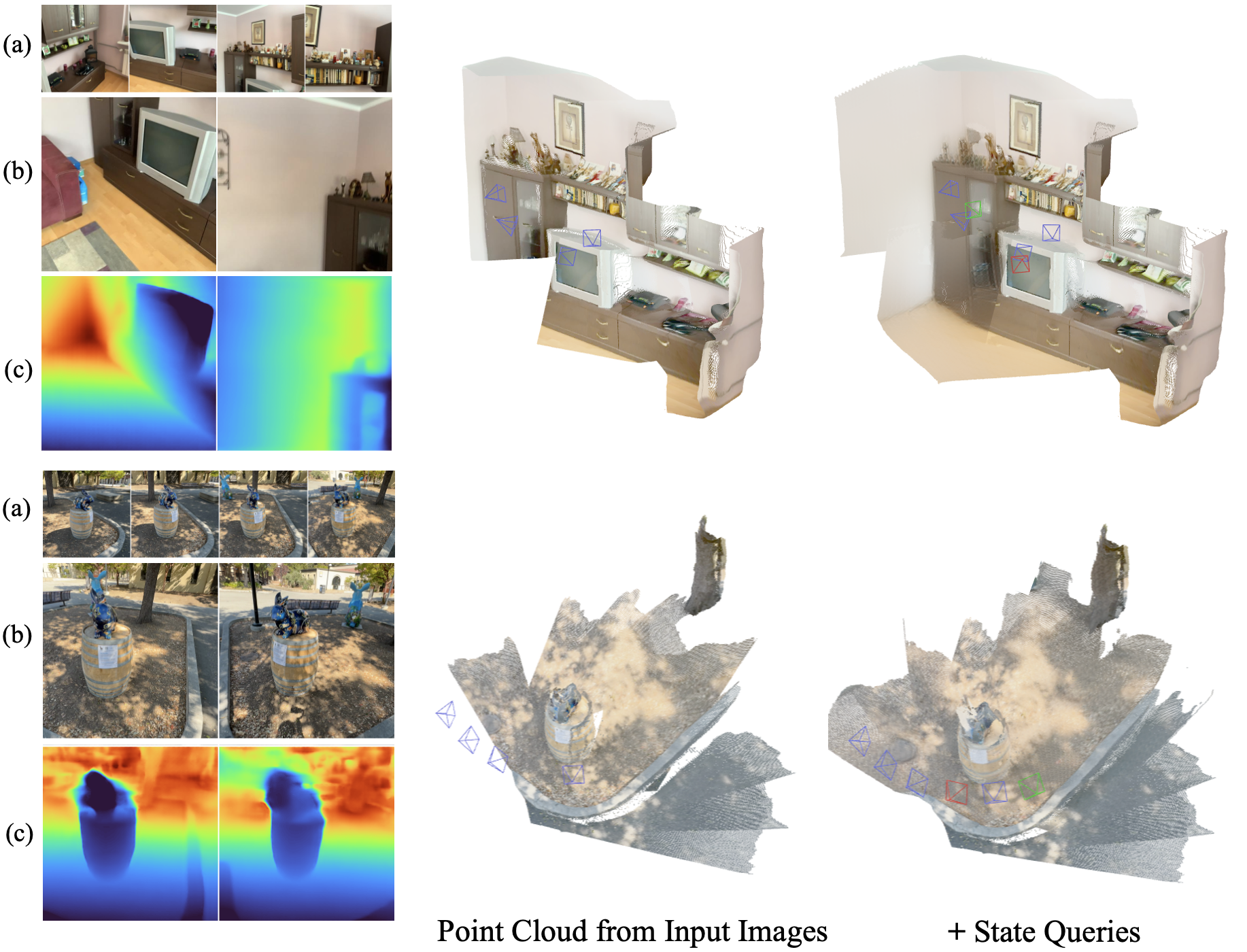
- Querying the scene: Because the model has a compact “scene memory,” you can give it a new, imaginary camera position, and it can quickly guess what that view would look like (the geometry and even color) in real time.
- Streaming: If images arrive one by one (like a live video), ZipMap can update its memory as it goes, keeping the 3D model fresh without starting over.
Key term check:
- 3D reconstruction: Building a 3D model from 2D pictures.
- Depth map: An image where each pixel tells you how far away that point is.
- Point cloud: Lots of tiny 3D dots that outline the scene.
- Camera pose: The position and direction of the camera when a photo was taken.
- Linear vs. quadratic time: Linear means if you double the number of images, the time roughly doubles. Quadratic means if you double the images, the time roughly quadruples—which gets slow very fast.
What did they find, and why is it important?
Main results, in clear terms:
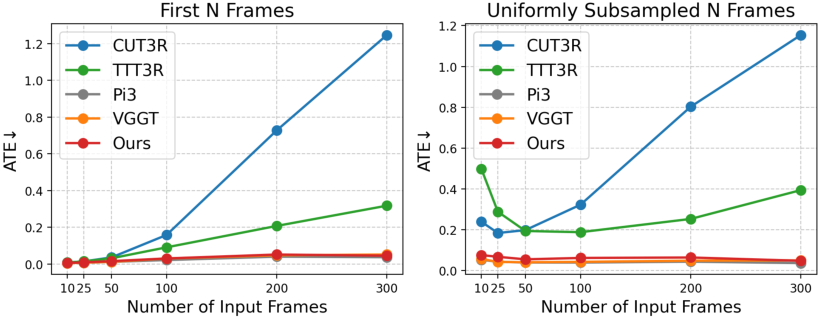
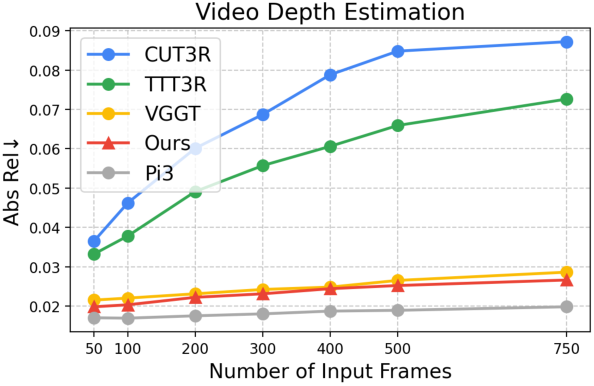
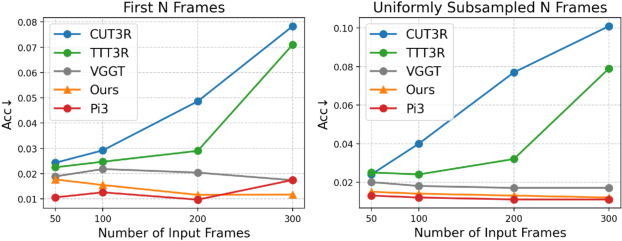
- Much faster at large scales: ZipMap processes 700+ frames in under 10 seconds on a high-end GPU, more than 20× faster than some leading models that use slower, pairwise comparisons.
- Keeps high quality: Even though it’s faster, ZipMap matches or beats the accuracy of top systems on tasks like estimating camera poses, depth, and dense 3D geometry.
- Scales smoothly: As you give it more images, it stays stable and accurate, unlike some other fast methods that lose quality with longer sequences.
- Real-time scene queries: Because it stores a compact scene memory, you can ask, “What does the scene look like from here?” and get an answer at around 100 frames per second.
- Sensible guesses in unseen areas: It can extrapolate likely structures (like walls or floors) even where cameras didn’t directly see them, thanks to learned scene priors.
Why this matters:
- Large collections become practical: City tours, museum scans, and long videos can be turned into 3D much more quickly.
- Real-time uses: It’s useful for AR/VR, robotics, and drones—anything that needs fast, accurate understanding of the environment.
- Efficiency: Faster processing means less waiting and potentially lower energy use.
What’s the bigger impact?
ZipMap points toward a future where:
- Phones, robots, and glasses can build and update 3D maps on the fly.
- Creators can reconstruct detailed scenes from long videos quickly, helping in filmmaking, game design, or virtual tours.
- Research can handle bigger, messier image collections without huge compute costs.
Simple takeaway: ZipMap “zips” a scene into a smart memory during one fast pass through the images. That lets it build accurate 3D models quickly and even answer new-view questions in real time, making large-scale 3D understanding much more practical.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and open questions that remain after this paper, intended to guide follow-up research:
- Quantitative evaluation of the queryable scene state is missing: there are no PSNR/SSIM/LPIPS or geometric-consistency metrics for novel-view predictions from the implicit state, nor analyses of multi-view consistency across multiple queried views.
- Capacity and saturation of the TTT fast-weight memory are not characterized: how accuracy scales with state size (e.g., d, number of layers) and how performance degrades when the number of input views grows to thousands has not been measured.
- Memory footprint and deployability are underexplored: the fast-weight state is large (e.g., ≈6d2 per layer with d=1024, across 24 layers), yet there is no profiling on commodity GPUs/CPUs, mixed precision, or memory/latency trade-offs for edge or mobile deployment.
- Linear-time scaling is shown up to ~700 frames on an H100, but it is unclear whether constant factors or memory impede scaling to orders of magnitude larger collections (e.g., 5k–50k images) or city-scale internet photo sets.
- Lack of direct comparisons to large-scale classical pipelines: there is no systematic accuracy/runtime comparison against COLMAP/GLOMAP on true internet photo collections with extreme baselines and sparse overlap at scale.
- Absolute metric scale remains unresolved: the method uses scale-invariant losses and scale alignment; recovering metric scale from monocular inputs (or fusing IMU/altitude cues) is not addressed.
- Camera intrinsics modeling is incomplete: only “two intrinsics” are predicted; support for full intrinsics (fx, fy, cx, cy, skew) and lens distortion (radial/tangential, fisheye/omni-directional) is untested.
- Robustness to low-overlap, wide-baseline, and challenging photometric conditions (non-Lambertian surfaces, HDR, night, weather, motion blur, rolling shutter) is not systematically evaluated.
- Order sensitivity and stability in streaming mode are open: catastrophic forgetting, drift, and robustness when processing arbitrarily long, out-of-order, or looped streams need empirical study and mitigation strategies (e.g., memory refresh, replay, or loop-closure mechanisms).
- Loop closure and long-horizon drift without global optimization are not analyzed: behavior on kilometer-scale trajectories or long closed loops remains unclear.
- Occlusion reasoning and view-dependent effects in queries are limited: the query head directly regresses color/depth per view without an explicit volumetric/radiance representation, raising questions about occlusion handling, multi-view consistency, and specularities.
- Dynamic scenes are not explicitly modeled: although trained with some dynamic data, there is no motion segmentation, dynamic object tracking, or analysis of how moving objects affect pose and geometry.
- Uncertainty is only modeled for depth; there is no uncertainty quantification for camera poses/points or for query predictions, nor calibration analyses of predicted confidences.
- Theoretical guarantees of the TTT K–V reconstruction objective are absent: formal connections to attention (e.g., approximation error bounds), memory capacity, and failure modes of fast-weight updates are not provided.
- Sensitivity to the TTT update schedule is unexplored: number of gradient steps, token batching, optimizer choices (beyond Newton–Schulz orthonormalization), and per-token learning rate designs are not ablated beyond a small study.
- Training data composition and domain bias are opaque: the paper references 29 datasets without a breakdown of their contributions; generalization to strongly OOD domains (e.g., underwater, IR/thermal, aerial, endoscopy) is untested.
- Failure case taxonomy is missing: the paper lacks qualitative/quantitative analyses of where ZipMap underperforms (e.g., thin structures, reflective surfaces, textureless regions, extreme FOVs) and why.
- Persistence and reuse of the scene state are not addressed: it is unclear how to serialize, compress, or merge fast-weight states for long-term mapping, relocalization, or collaborative scenarios.
- Integration with multi-modal sensing is unexplored: fusing IMU, wheel odometry, LiDAR, or events to improve scale, robustness, and dynamics has not been studied.
- Resolution and tokenization effects are not analyzed: how input image resolution, patch size, and token count affect accuracy, speed, and memory is not documented.
- End-to-end latency for real-time/streaming settings is not reported: per-frame latency, throughput under varying batch sizes, and pipeline-level delays (including TTT updates) remain unclear.
- Adversarial and robustness aspects are unexamined: sensitivity to corrupted inputs (noise, dropped frames, misordered frames, outliers) and outlier rejection strategies are not evaluated.
- Comparison to linear-time sequence models (e.g., Mamba/RWKV/DeltaNet) as alternative backbones is absent: trade-offs between TTT-based fast weights and modern state-space models for 2D×N inputs are not assessed.
- Downstream task readiness is unproven: the utility of ZipMap outputs for SLAM, AR occlusion, navigation, or scene editing—and the constraints required (e.g., real-time relocalization, map updates)—is not demonstrated.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with today’s infrastructure, leveraging ZipMap’s linear-time, stateful 3D reconstruction, real-time scene querying, and streaming updates.
- 3D scene capture for virtual production and VFX (Media/Entertainment, Software)
- What: Rapid camera tracking, depth, and dense point-cloud generation from long takes for matchmoving, previz, and 3D-aware editing. Real-time querying enables on-set virtual scouting and shot planning.
- Tools/workflows/products: Blender/Maya/Unreal/Unity plugins; a “ZipMap Studio” tool for ingesting footage (hundreds of frames) and exporting calibrated cameras, depth, and point clouds; Nuke/After Effects nodes for depth-aware compositing.
- Assumptions/dependencies: Access to a capable GPU (server or workstation); image coverage/overlap; generalization to studio lighting and dynamic actors; integration into existing DCC pipelines.
- AR/VR mapping from mobile video (Consumer Apps, Mapping, Software)
- What: Fast room/scenario reconstructions from phone video for instant AR occlusion, anchoring, and novel-view previews, with state querying to render novel viewpoints at interactive rates.
- Tools/workflows/products: Mobile SDK + cloud API (“ZipMap-as-a-Service”) that accepts short videos and returns camera poses, depth maps, and point clouds; integration with ARKit/ARCore for anchors and occlusion.
- Assumptions/dependencies: Likely server-side inference due to mobile compute limits; privacy safeguards for user video; robust handling of varying intrinsics and rolling shutter.
- Robotics navigation and perception (Robotics, Industrial Automation)
- What: Low-latency 3D perception from monocular or multi-camera streams for navigation, obstacle avoidance, and scene understanding; streaming fast-weights enable online updates without quadratic growth.
- Tools/workflows/products: ROS node for online reconstruction; integration with SLAM stacks as a drop-in geometry/pose module; planners that query the scene state for alternative viewpoints.
- Assumptions/dependencies: Sufficient on-robot compute (or edge offload); calibration stability; robustness to motion blur and lighting shifts; safety testing for deployment.
- Drone surveying and site inspection (AEC, Infrastructure, Geospatial)
- What: Near-real-time processing of long flyover sequences to produce dense point clouds and camera trajectories for construction progress monitoring, asset inventory, and defect pre-screening.
- Tools/workflows/products: Field-deployable pipeline that converts drone footage to site-aligned point clouds; integration with BIM/CAD viewers; dashboards for progress deltas.
- Assumptions/dependencies: GPS/IMU fusion desirable for georeferencing; adherence to accuracy thresholds; handling large-scale scenes (tiling or chunking as needed).
- E-commerce asset and room digitization (Retail, Cultural Heritage)
- What: Fast conversion of product/room photo collections into 3D previews, turntables, and point clouds; querying enables quick novel-view generation without full mesh extraction.
- Tools/workflows/products: Merchant-facing web pipeline to upload photos and receive 3D assets; museum digitization toolkit for gallery scans; batch processing over large catalogs.
- Assumptions/dependencies: Photographic coverage, lighting variability; limits with highly reflective/transparent surfaces; potential need for mesh post-processing.
- Post-production video effects and analytics (Media Analytics, Security)
- What: Depth-aware stabilization, relighting, and 3D-aware effects; crime/incident scene reconstructions from bodycam or surveillance video; fast turn-around on long sequences.
- Tools/workflows/products: Video editing plugins leveraging per-frame depth and camera; forensic reconstruction pipelines delivering point clouds and trajectories for reports.
- Assumptions/dependencies: Scale ambiguity management (if metric accuracy is required); privacy/chain-of-custody compliance; resilience to dynamic scenes and occlusions.
- Research acceleration and dataset curation (Academia, R&D)
- What: Rapid generation of camera/depth/point maps for large image collections, long sequences, and internet photo sets; fast initializations for neural rendering (e.g., 3DGS/NeRF) and geometry distillation.
- Tools/workflows/products: Python API for batch processing; integration as a preprocessor for NeRF/3DGS pipelines; triage tools to check scene coverage and quality.
- Assumptions/dependencies: Availability of open-source weights or licensed binaries; reproducibility across domains; compute budget for very large datasets.
- Interior planning and real estate listing enhancements (Real Estate, Consumer)
- What: Quick 3D reconstructions for floor plan verification, virtual tours, and furnishing previews; querying for synthesized viewpoints.
- Tools/workflows/products: Realtor apps to capture a walkthrough and receive navigable 3D assets; staging apps that overlay virtual furniture using predicted depth.
- Assumptions/dependencies: Accurate room coverage; acceptable precision for floor plan measurements; legal disclosure where depth-derived measurements are used.
- Education and interactive visualization (Education, STEM Outreach)
- What: Classroom demos reconstructing scenes from videos in seconds; interactive lab exercises on multi-view geometry without long training or slow pipelines.
- Tools/workflows/products: Educational notebooks with sample datasets; lightweight GUIs for students to load videos/images and visualize cameras and point clouds.
- Assumptions/dependencies: Access to GPU-backed lab machines or cloud credits; curated datasets for safe/domain-appropriate content.
Long-Term Applications
These require further research, optimization, domain adaptation, or integration with larger systems and processes.
- On-device, persistent “scene memory” for AR cloud anchors (Mobile AR, Platforms)
- What: Store and share compact fast-weight scene states as persistent anchors across sessions/users for multi-user AR and location-based experiences.
- Tools/workflows/products: Edge/phone inference with quantized models; cloud state sync services; privacy-preserving state sharing.
- Assumptions/dependencies: Robustness to revisits, lighting/day-night changes, furniture rearrangements; compact and secure serialization of fast weights; cross-device calibration.
- Real-time multi-view sports and event volumetric capture (Broadcast, Live Entertainment)
- What: Combine many camera feeds to reconstruct stadium/stage volumes for free-viewpoint playback; query state for interactive viewpoints.
- Tools/workflows/products: Edge clusters at venues; operator dashboards; broadcast plugins for instant replay rendering.
- Assumptions/dependencies: Multi-camera synchronization and calibration; handling extreme motion and occlusions; very high throughput and latency constraints.
- Autonomy-grade mapping and perception for vehicles (Automotive, Robotics)
- What: Integrate ZipMap with LiDAR/IMU for accurate, scalable urban mapping and online perception; exploit linear scaling for long trajectories.
- Tools/workflows/products: Fusion modules that combine camera reconstructions with LiDAR for metric accuracy; map update pipelines; loop closure and drift correction add-ons.
- Assumptions/dependencies: Safety certification; rigorous failure analysis; domain adaptation to weather/night; compute-power envelopes in vehicles.
- Medical endoscopy/laparoscopy 3D guidance (Healthcare)
- What: 3D reconstruction from endoscopic video for intra-operative navigation and tool tracking; streaming updates for real-time guidance.
- Tools/workflows/products: OR-integrated reconstruction modules; visualization UIs for surgeons; API for robot-assisted surgery systems.
- Assumptions/dependencies: Domain shift (medical imagery differs from training data); sterilizable, latency-bounded hardware; clinical validation and regulatory approval (FDA/CE).
- Infrastructure monitoring and energy asset inspection (Energy, Utilities, Public Works)
- What: Near-real-time reconstruction of turbines, transmission lines, bridges, pipelines from drone/bodycam video; anomaly pre-screening and maintenance planning.
- Tools/workflows/products: Field kits with rugged edge compute; GIS-integrated dashboards; automated defect detection models on reconstructed geometry.
- Assumptions/dependencies: Extreme-scale scenes require tiling and memory-aware batching; accurate georeferencing; compliance with inspection standards and data retention policies.
- Large-scale city modeling and digital twins (Smart Cities, Urban Planning)
- What: Fast ingestion of municipal camera networks, drones, and street-level imagery to maintain up-to-date 3D city models; interactive querying for planning and simulation.
- Tools/workflows/products: Cloud pipelines orchestrating ingestion from heterogeneous sources; twin platforms that expose real-time state queries for analytics.
- Assumptions/dependencies: Data governance and privacy policies; cross-sensor calibration and synchronization; sustained compute budgets and storage.
- Policy and standards for ML-based photogrammetry (Policy/Regulation)
- What: Develop benchmarks and procurement standards for ML reconstruction in public works (accuracy, robustness, privacy), enabling replacement or augmentation of classical photogrammetry.
- Tools/workflows/products: Conformance test suites; audit trails for model runs; guidelines for data handling and bias mitigation.
- Assumptions/dependencies: Stakeholder consensus; reproducible baselines; clear definitions of metric vs. scale-aligned accuracy.
- Insurance and finance claim automation (Insurance, Finance)
- What: Rapid 3D reconstructions of damage scenes (homes, vehicles) from phone/bodycam video to speed estimation and fraud detection.
- Tools/workflows/products: Claim intake apps that capture guided video; automated estimation with geometry-informed models; adjuster dashboards.
- Assumptions/dependencies: Legal acceptance of ML-derived measurements; handling adverse conditions (smoke, rain); safeguards against adversarial or low-quality inputs.
- Developer ecosystem and integration with neural rendering (Software Platforms)
- What: Use ZipMap outputs as strong initializations for 3D Gaussian Splatting/NeRF training; expose a unified API for camera/geometry/novel-view queries in content creation tools.
- Tools/workflows/products: “ZipMap Engine” libraries (Python/C++), Unity/Unreal packages, ROS integrations; pipeline recipes that reduce NeRF/3DGS training time via good initialization.
- Assumptions/dependencies: Stable interfaces and licenses; mesh extraction and refinement where required; continued improvements for thin structures/specularities.
- Consumer-grade room scanning and floor plan automation (Consumer, PropTech)
- What: In-app, near-real-time 3D floor plan and room model generation that works across diverse devices and lighting; instant AR previews and measurements.
- Tools/workflows/products: On-device accelerated models with fallback to cloud; UX for capturing sufficient coverage; CAD export tools.
- Assumptions/dependencies: Robustness to clutter, mirrors, and textureless walls; precise scale recovery (fusion with phone IMU/ToF where available); privacy and data minimization.
Notes on feasibility across applications:
- Compute: Results reported on H100-class GPUs; production may require scaling down (quantization, pruning) or offloading to cloud/edge.
- Inputs: Quality and overlap of imagery significantly affect results; intrinsics/extrinsics may need estimation or device metadata.
- Accuracy: Metrics are often scale-aligned; applications needing metric accuracy may require sensor fusion (IMU/GPS/LiDAR) or post-alignment.
- Dynamics: The model handles some dynamic scenes but cannot hallucinate high-frequency details; explicit handling of moving objects may be required for certain tasks.
- Data governance: For cloud-based services, privacy, security, and compliance must be addressed (especially in healthcare, public sector, and insurance).
Glossary
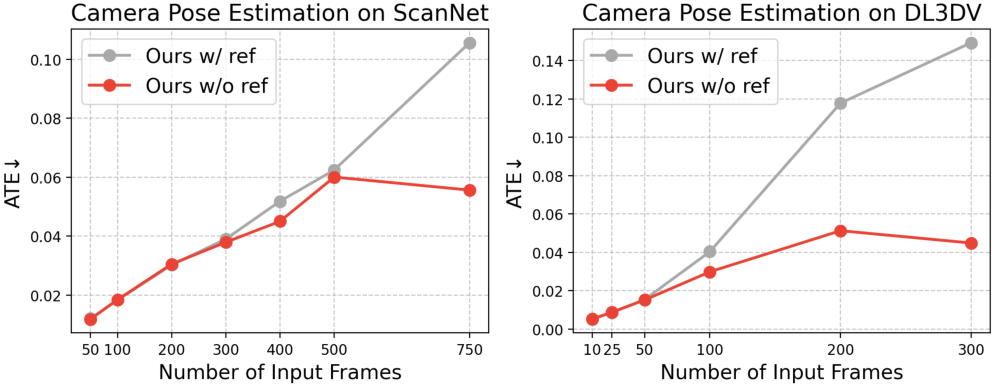
- Absolute Trajectory Error (ATE): A metric that measures the difference between predicted and ground-truth camera trajectories, often used to evaluate pose accuracy. "final Absolute Trajectory Error (ATE) on ScanNetV2~\cite{dai2017scannet}"
- Affine-invariant camera loss: A supervision loss for camera parameters that is invariant to affine transformations, improving robustness to global scale/shift. "switch to an affine-invariant camera loss (inspired by ~\cite{wang2025pi3})."
- Associative memory: A mechanism that stores key–value mappings so the model can retrieve values given keys; here implemented via fast-weight updates during TTT. "This virtual objective is unrelated to the 3D reconstruction loss; it is optimized once per layer to build an in-context associative memory~\cite{wang2025test}."
- DINOv2 encoder: A pretrained vision transformer used to extract per-image features that are flattened into tokens. "We first tokenize each input image using a pretrained DINOv2 encoder~\cite{oquab2023dinov2}."
- DPT-style head: A dense prediction transformer-style decoder head used to predict maps such as depth and points. "We use a DPT-style head~\cite{DPT_Ranftl2021} for the point, depth, and query heads."
- Extrinsic and intrinsic parameters: Camera parameters describing, respectively, pose in world coordinates and internal calibration (focal length, principal point). "The ray map input is computed from the target camera's extrinsic and intrinsic parameters."
- Fast weights: Rapidly updated model parameters that store task- or context-specific information at inference time. "compresses the entire image collection into a compact hidden state (i.e., into the ``fast-weights" of an MLP) in a single forward pass."
- Global attention: A transformer mechanism attending across all tokens, enabling global context integration but with quadratic cost. "as they rely on expensive global attention mechanisms to establish geometric consistency."
- Implicit scene representation: A scene description encoded in the model’s internal state rather than an explicit 3D data structure, enabling querying from novel viewpoints. "it serves as an implicit scene representation that can be queried to produce pixel-aligned geometry and appearance at novel viewpoints in real time"
- Key–value reconstruction: An auxiliary objective that trains a function to map keys to values, enabling associative memory in fast weights. "with a virtual test-time training objective based on key–value reconstruction."
- LaCT: A large-chunk TTT approach that updates nonlinear MLP fast weights per chunk to efficiently integrate bidirectional context. "Following this, LaCT~\cite{zhang2025test} updates nonlinear MLP fast weights once per large token chunk, improving hardware efficiency and enabling bidirectional context integration."
- Laplacian distribution: A probability distribution whose negative log-likelihood corresponds to an L1 loss; used to justify uncertainty-weighted depth loss. "equivalently to the negative log-likelihood of a Laplacian distribution."
- Large-Chunk TTT layer: A test-time training block applied over large token chunks to build a compact global memory with linear complexity. "Global Large-Chunk TTT Layer inspired by LaCT~\cite{zhang2025test}, is the key to both our model's linear scaling and its adaptive implicit scene representation."
- Local window attention: Self-attention restricted to local spatial windows within each view to capture intra-image structure efficiently. "Local Window Attention operates on the tokens of each view (image or ray map) independently."
- LPIPS: Learned Perceptual Image Patch Similarity, a perceptual metric used to supervise image predictions. "We set "
- Muon optimizer: An optimization method that employs Newton–Schulz-based orthonormalization of gradients for stability. "Following the Muon~\cite{jordan2024muon} optimizer, we apply the NewtonâSchulz orthonormalization procedure to the gradient $#1{g}$, then update the fast weights followed by L2 normalization to maintain stability:"
- Newton–Schulz normalization: A normalization technique based on the Newton–Schulz iteration, used here to stabilize fast-weight updates. "As shown in Tab.~\ref{tab:ttt_abla}, Newton--Schulz normalization (Eq.~4) and gated unit (Eq.~7) are crucial; removing either degrades performance."
- Quaternion: A 4D rotation representation used to parameterize camera orientation without singularities. "as a 4D rotation quaternion, 3D translation, and two intrinsics"
- Ray map: A per-pixel representation encoding camera rays (origins, directions, and cross-products) for novel-view queries. "The ray map input is computed from the target camera's extrinsic and intrinsic parameters."
- RMSNorm: Root-mean-square normalization, a normalization layer variant used to stabilize activations. "#1{o}_i = \operatorname{RMSNorm}(#1{o}\prime_i)\cdot \operatorname{SiLU} ( {W}_g #1{o}\prime_i ) \,."
- Rotary positional encoding: A method to inject position via rotations in query/key space for attention. "It uses standard self-attention with rotary positional encoding~\cite{su2024rope} to capture local spatial relationships within each view."
- Scale-invariant local point reconstruction loss: A loss on predicted point maps that is invariant to global scale, improving robustness across scenes. "we use a scale-invariant local point reconstruction loss:"
- Self-attention: The transformer operation where tokens attend to each other to aggregate context. "It uses standard self-attention with rotary positional encoding~\cite{su2024rope} to capture local spatial relationships within each view."
- Structure-from-Motion (SfM): Classical pipelines that recover camera motion and sparse 3D structure from images. "Structure-from-Motion (SfM) pipelines."
- SwiGLU-MLP: An MLP that uses the SwiGLU gated activation for improved expressivity and training stability. "implemented as a SwiGLU-MLP~\cite{shazeer2020glu}:"
- Test-Time Training (TTT): Adapting a subset of model parameters during inference to capture in-context information and improve performance. "Test-Time Training (TTT) layers~\cite{sun2024learning, zhang2025test} have emerged as a powerful framework for linear-complexity sequence models."
- Tokenization: Converting images or ray maps into sequences of tokens for transformer processing. "After the tokenization, the image tokens are $\{#1{x}_i\}_{i=1}^{N}$ with $#1{x}_i\in\mathbb{R}^{p\times d}$"
- Uncertainty map: A predicted per-pixel confidence (or scale) used to weight depth errors and stabilize training. "This is the loss between the scale-normalized depth prediction and the ground truth depth modulated by the predicted uncertainty map "
- Virtual objective: An auxiliary optimization objective used only to adapt fast weights for memory (not directly tied to the main task loss). "The key-value pairs from all input image tokens define a virtual objective function:"
Collections
Sign up for free to add this paper to one or more collections.