- The paper presents a transformer-based model that integrates diverse geometric inputs for robust metric 3D reconstruction.
- The model employs a factored scene representation and an alternating-attention mechanism to effectively fuse multi-view information.
- Performance evaluations demonstrate state-of-the-art results on dense multi-view and two-view benchmarks across varied scenarios.
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
MapAnything presents a transformer-based model designed to address diverse 3D reconstruction challenges robustly. The architecture supports a variety of input configurations, allowing it to process not only raw images but also optional geometric inputs such as camera intrinsics, poses, depth maps, and partial reconstructions.
Model Architecture
MapAnything leverages a novel factored representation of the scene geometry. This includes depth maps, local ray directions, camera poses, and a metric scale factor. This approach standardizes local reconstructions into a globally consistent metric frame, allowing the model to effectively integrate diverse geometric inputs to enhance the reconstruction quality. An alternating-attention transformer mechanism fuses multi-view information and facilitates the generation of detailed metric 3D outputs.
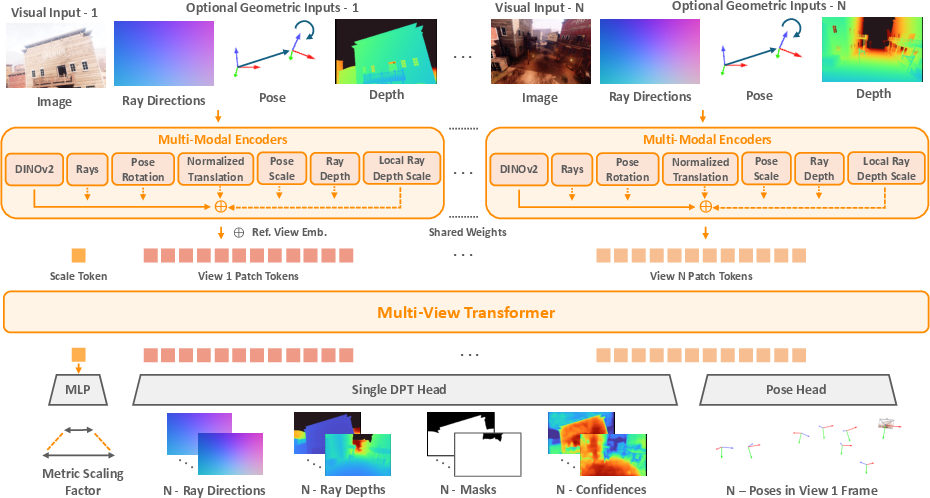
Figure 1: Overview of the Map Architecture.
Implementation and Training
The model employs a flexible input scheme capable of integrating different geometric modalities whenever available. For image encoding, MapAnything uses the DINOv2 model, which is fine-tuned for optimal performance and convergence. The model is trained with multiple datasets, encompassing indoor, outdoor, and in-the-wild scenarios. Training involves a multi-task setup where various input combinations are randomly sampled, ensuring robust performance across different scene configurations.
MapAnything is trained using a combination of losses tailored to predict the structured geometric outputs effectively. The key loss components address pose estimation, depth prediction, and scale invariance, ensuring robust generalization across metrics.
MapAnything demonstrates state-of-the-art performance in dense multi-view and two-view 3D reconstruction benchmarks. It surpasses or matches the quality of expert models in several metrics while offering a more flexible and unified framework.
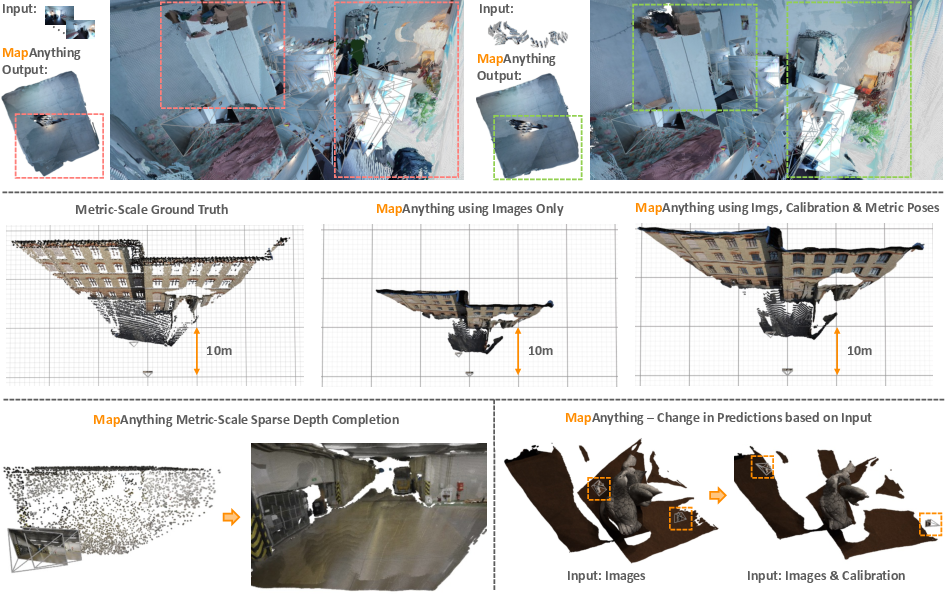
Figure 2: Auxiliary geometric inputs improve feed-forward performance of Map.
The model's ability to utilize optional geometric input enables significant performance gains, particularly when calibrated information is available. Its factored scene representation design provides accurate scene reconstructions, even when constrained to use only image inputs.

Figure 3: Qualitative comparison of Map to VGGT using only in-the-wild images as input.
Discussion
MapAnything marks a significant progression towards creating a universal 3D reconstruction backbone. It efficiently handles multiple 3D vision tasks without requiring task-specific adaptations, streamlining pipeline deployment in practical applications. The model's extensibility supports future research directions, including dynamic scene reconstruction and enhanced uncertainty modeling.

Figure 4: Map provides high-fidelity dense geometric reconstructions across varying domains and number of views.
Conclusion
MapAnything introduces a robust, flexible transformer-based model that supports a wide array of 3D reconstruction tasks through a unified architecture. Its capability to process diverse inputs and deliver consistent, high-quality reconstructions positions it as a versatile tool for researchers and practitioners in the field of computer vision. Future work should explore the integration of additional input modalities and further optimizations in understanding dynamic environments.

