Toward Guarantees for Clinical Reasoning in Vision Language Models via Formal Verification
Abstract: Vision-LLMs (VLMs) show promise in drafting radiology reports, yet they frequently suffer from logical inconsistencies, generating diagnostic impressions unsupported by their own perceptual findings or missing logically entailed conclusions. Standard lexical metrics heavily penalize clinical paraphrasing and fail to capture these deductive failures in reference-free settings. Toward guarantees for clinical reasoning, we introduce a neurosymbolic verification framework that deterministically audits the internal consistency of VLM-generated reports. Our pipeline autoformalizes free-text radiographic findings into structured propositional evidence, utilizing an SMT solver (Z3) and a clinical knowledge base to verify whether each diagnostic claim is mathematically entailed, hallucinated, or omitted. Evaluating seven VLMs across five chest X-ray benchmarks, our verifier exposes distinct reasoning failure modes, such as conservative observation and stochastic hallucination, that remain invisible to traditional metrics. On labeled datasets, enforcing solver-backed entailment acts as a rigorous post-hoc guarantee, systematically eliminating unsupported hallucinations to significantly increase diagnostic soundness and precision in generative clinical assistants.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making sure AI systems that write radiology reports (based on chest X‑ray images) are not just fluent, but logically correct. The authors build a “math-based checker” that reads what the AI says in the Findings and Impression sections, and then proves whether each diagnosis is truly supported by the evidence the AI itself reported.
Objectives
The paper sets out to do three simple things:
- Create a way to check the logic of an AI‑written report, even when there’s no official “correct” report to compare against.
- Turn the AI’s free‑text Findings into a structured checklist of facts, then use medical rules to see if the Impression (diagnoses) must follow.
- Show that this checking step can remove unsupported claims (“hallucinations”) and make AI assistants safer and more reliable.
Methods (explained with everyday language)
Here’s the basic idea: the AI looks at a chest X‑ray and writes two parts of a report:
- Findings: what the AI notices (for example, “blunted costophrenic angle”).
- Impression: the diagnoses or conclusions (for example, “pleural effusion”).
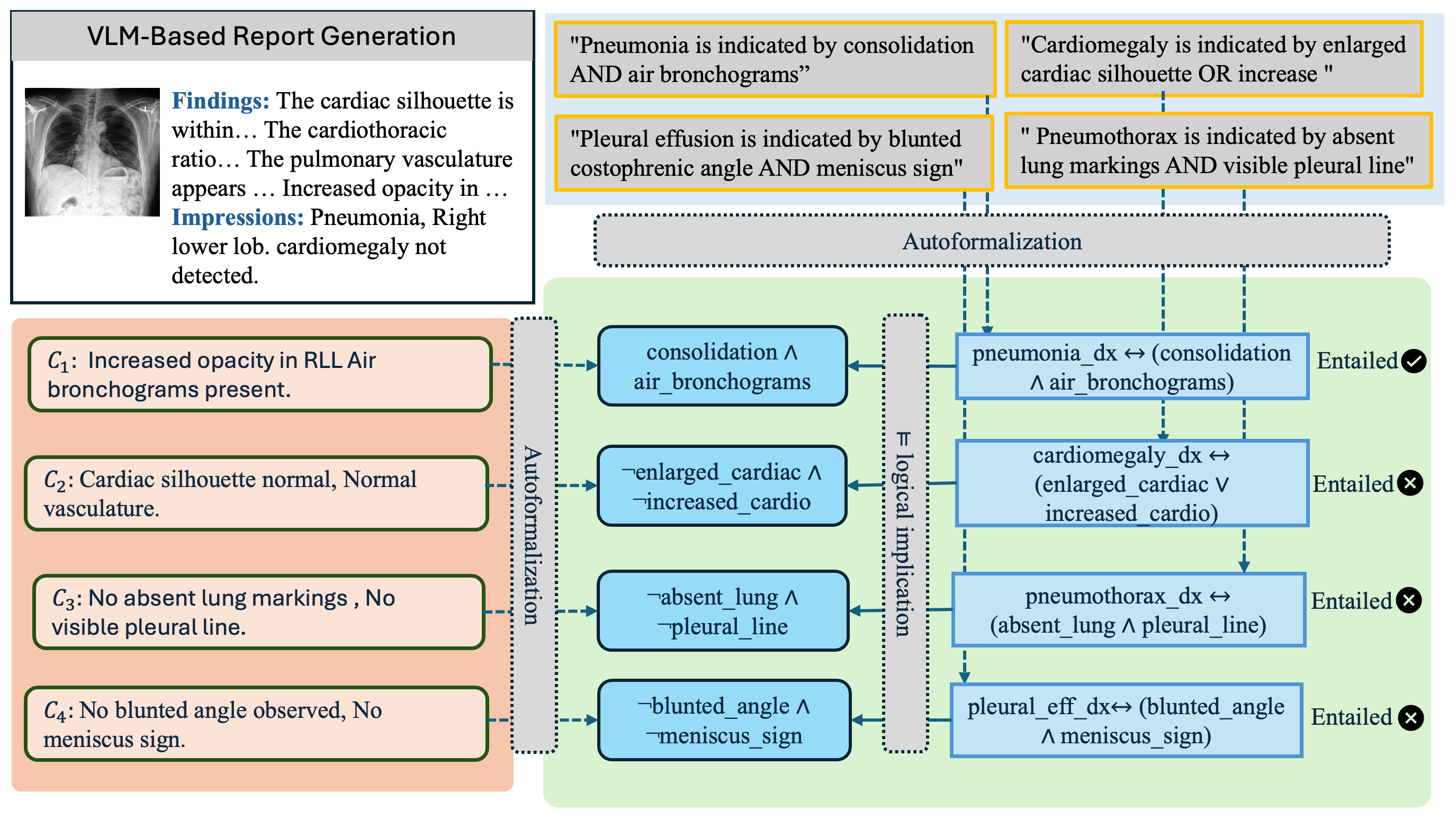
The authors then run the AI’s text through a neurosymbolic verification pipeline. Think of this as a referee that uses clear rules and math to judge whether the conclusions are truly backed by the observations.
How the pipeline works:
- Autoformalization: The free‑text Findings are turned into a structured checklist (yes/no facts). Example: “costophrenic_blunting = yes.” If a finding isn’t mentioned, it’s treated as “no” (this mirrors clinical writing: if a major finding isn’t stated, it’s assumed absent).
- Medical rulebook (knowledge base): A curated set of medical rules says which findings are enough to imply which diagnoses. Example (simplified): “If costophrenic_blunting is present, that’s enough to support pleural_effusion.” It also includes rules that prevent contradictions.
- SMT solver (Z3): This is a math “puzzle solver” that checks whether the facts and rules force a diagnosis to be true. If the solver says there’s no way the facts could be true without the diagnosis also being true, then the diagnosis is “entailed” (fully supported). If there is at least one way the facts could be true and the diagnosis false, the diagnosis is “unsupported.”
What gets checked:
- Supported (entailed): The diagnosis must follow from the stated findings.
- Unsupported (hallucinated): The diagnosis doesn’t necessarily follow from the findings.
- Missed (omitted): The findings mathematically force a diagnosis, but the AI forgot to mention it in the Impression.
- Correctly excluded: The findings don’t force the diagnosis, and the AI didn’t claim it.
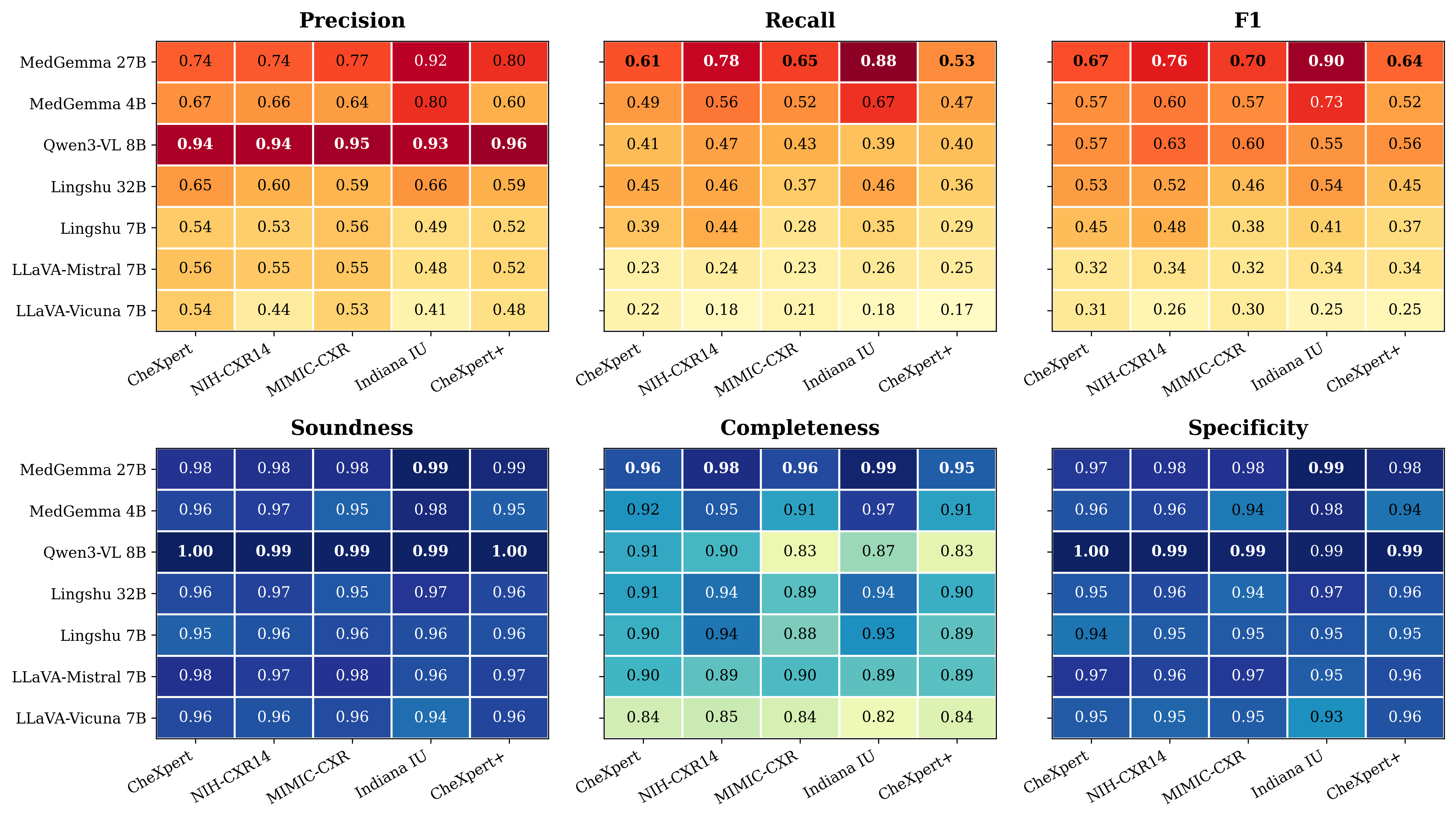
How they judge reliability:
- Soundness: Of the diagnoses the AI actually claimed, what fraction are logically supported?
- Completeness: Of the diagnoses that are logically forced by the findings, what fraction did the AI remember to say?
The team tested seven different vision‑LLMs (VLMs) on five chest X‑ray datasets. They also showed why common text scores like BLEU and ROUGE (which measure word overlap) miss logical mistakes. Those scores punish paraphrasing and don’t check whether the Impression matches the Findings.
Main Findings and Why They Matter
Key results:
- Word‑overlap scores (BLEU/ROUGE) were very low and didn’t reflect clinical reasoning quality. Two different but clinically valid phrasings get penalized, and these scores can’t tell if the Impression is logically supported by the Findings.
- The logical checker revealed three behavior patterns in models:
- Balanced reasoners: Some medical models consistently made diagnoses that matched their own findings and rarely missed forced conclusions.
- Conservative observers: Some models almost never hallucinated, but often failed to state diagnoses that their own findings implied.
- Hallucination‑prone: Some models often stated diagnoses not supported by their findings.
- Adding the solver as a “filter” (keeping only diagnoses that are logically supported by the Findings) made the AI’s outputs more trustworthy:
- Soundness and precision increased: Fewer unsupported claims.
- Completeness and recall slightly decreased: A small number of correct diagnoses were not stated, usually because the supporting finding wasn’t clearly written or extracted.
Why this matters:
- In medicine, being correct and consistent is more important than sounding fluent. This pipeline focuses on internal logic, not just word matching, making AI reports safer.
- The checker works without needing a “gold‑standard” report, so it can be used in real clinical settings where ground truth isn’t available during reporting.
Implications and Impact
This work shows a practical path to safer AI in radiology:
- It separates “seeing” (the AI’s visual description) from “thinking” (the diagnoses) and then proves that the thinking is justified.
- It helps catch and eliminate unsupported diagnoses before they reach clinicians, reducing time spent “debugging” AI reports.
- It shifts AI evaluation from “Does the text look similar?” to “Is the reasoning correct?”, which is what matters in patient care.
Important note: The guarantees depend on two things being reasonable:
- The Findings must accurately describe what’s in the image (radiologists can review this).
- The translation from text to the structured checklist and the medical rulebook must be correct (the team had clinicians audit the rules and checked translations).
Overall, this research moves AI reporting closer to the kind of reliability doctors need, by making the AI’s logic checkable, explainable, and more trustworthy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to guide actionable future research.
- End-to-end clinical correctness: The framework guarantees internal logical consistency conditioned on the model’s own Findings and the curated knowledge base, but does not quantify how often logically “sound” impressions are clinically correct when the Findings themselves are perceptually wrong. Evaluate the relationship between solver-backed soundness and true clinical accuracy using image-level gold standards.
- Autoformalization fidelity at scale: Only a 100-sample spot check was reported for text-to-SMT translation. Conduct large-scale, annotation-based audits of the autoformalization pipeline (precision/recall for predicate extraction, negation, uncertainty handling, synonyms, and coreference), and quantify error propagation into the verifier’s decisions.
- Closed-World Assumption (CWA) risks: The pipeline treats unmentioned findings as absent. Measure the impact of CWA on false negatives, compare against open-world or partial-evidence semantics, and develop principled strategies (e.g., default/defeasible logic) to handle underspecification typical in clinical prose.
- Knowledge base (KB) correctness and completeness: The KB is curated per dataset and audited by clinicians but lacks formal guarantees. Perform formal analyses of KB consistency, completeness, and coverage (including mutual exclusivity, necessary vs. sufficient conditions, severity thresholds, laterality, and anatomical localization), and release standardized benchmarks to test KB quality across institutions.
- Robust impression extraction: Diagnoses in the Impression are obtained via strict string matching, which likely misses paraphrases and compositional diagnoses. Replace with ontology-backed canonicalization (e.g., RadLex/UMLS mappings), and measure downstream effects on Soundness and Completeness.
- Handling uncertainty and graded evidence: The verifier uses binary predicates, ignoring CheXpert’s uncertainty labels, severity, and confidence levels. Extend the logic to three-valued, probabilistic, or fuzzy semantics and assess how graded reasoning affects clinical reliability and failure modes.
- Spatial and temporal reasoning: Current rules do not model laterality (left/right), localization (e.g., lobar), distribution (diffuse/focal), or longitudinal progression across serial exams. Incorporate spatial predicates and temporal logic (e.g., LTL) for multi-view, multi-timepoint studies.
- Integration with generation (beyond post-hoc filtering): The approach is purely post-hoc. Investigate constrained decoding, solver-in-the-loop generation, and training objectives that optimize entailment (e.g., RL with logical rewards) to proactively prevent hallucinations rather than only filter them.
- Direct evidence extraction from images: Verification depends on textual Findings rather than direct perceptual evidence. Explore image-to-symbol pipelines (detectors/classifiers yielding
f_i) to reduce reliance on the VLM’s narrative and quantify the trade-offs between text-derived and image-derived evidence. - Latency, scalability, and deployment: Solver runtime, memory footprint, and throughput are not studied. Benchmark verification latency for large KBs, long reports, and batch workloads; define operational budgets for PACS/EHR integration and real-time clinical use.
- User-centered evaluation: No human factors study is presented. Assess radiologist trust, cognitive load, error mitigation, and automation bias reduction with solver explanations (e.g., unsat cores, proof traces), and test the clinical utility in reader studies or simulated workflows.
- Explainability and correction UX: The solver’s decisions are not surfaced as actionable feedback. Design interfaces that present minimal edits to achieve entailment, highlight missing evidence, and provide rationale-level explanations that can be quickly validated.
- Benchmarking against alternative safeguards: Compare neurosymbolic verification to neural fact-checkers, entailment classifiers, retrieval-based knowledge grounding, and causal consistency checks; perform ablations on KB size/quality and autoformalizer variants.
- KB evolution and governance: Clinical guidelines evolve. Develop procedures for KB versioning, conflict detection/resolution, provenance tracking, and automated audits to maintain consistency as rules are updated or expanded to new conditions.
- Modalities and domains beyond chest X-ray: The evaluation focuses on chest radiography. Validate the framework on CT, MRI, ultrasound, and other specialties (e.g., neuro, MSK), including pediatric and ICU populations, and assess generalization across institutions and devices.
- Fairness and distribution shift: No analysis of demographic, device, or site variability is provided. Audit performance across subgroups, quantify robustness to domain shift, and test whether KB-derived rules introduce systematic biases.
- Contradiction handling within sections: The verifier checks Findings-to-Impression entailment but does not detect contradictions within Findings or within Impression. Add intra-section consistency checking and conflict resolution strategies.
- Necessary vs. sufficient conditions: KB rules encode sufficient conditions but may not capture necessity, risking false “support” for diagnoses that should require additional evidence. Separate and evaluate necessary vs. sufficient rule sets.
- Multi-diagnosis interactions and non-monotonicity: Comorbid conditions and exceptions often require non-monotonic reasoning. Investigate answer-set programming, default logic, or conditional constraints to model exception-rich clinical rules.
- Coreference and discourse phenomena: The autoformalizer may miss coreference, hedging, temporality (e.g., “no change”), and context (e.g., post-operative status). Evaluate discourse-aware parsing and its impact on entailment outcomes.
- Reproducibility and artifact release: The paper does not state release of code, KBs, prompts, or ontologies. Provide public artifacts, detailed schemas, and evaluation protocols to enable replication and community benchmarking.
- Safety thresholds and policy: The target Soundness ≥ 0.99 is not clinically justified. Derive policy thresholds from risk models, perform sensitivity analyses, and propose operating points aligned with clinical safety requirements.
- Adversarial and ambiguous text robustness: Assess how the verifier responds to adversarial phrasing, ambiguous statements, contradictory cues, and rare synonyms; harden the autoformalizer and extraction against such inputs.
- Multi-lingual and cross-lingual generalization: The pipeline assumes English reports. Evaluate multilingual autoformalization, cross-lingual KB mapping, and performance on non-English corpora.
- Label uncertainty in evaluation datasets: CheXpert and NIH-CXR labels contain uncertainty and weak supervision. Quantify how label noise and uncertainty affect measured Soundness/Completeness and develop evaluation protocols that account for label imperfections.
- Use of solver outputs for model improvement: The paper filters diagnoses but does not leverage solver feedback to improve model perception or reporting. Explore training-time curriculum, data curation, and counterfactual augmentation based on verification outcomes.
Practical Applications
Below are the practical, real‑world applications that follow from the paper’s neurosymbolic verification framework (autoformalized findings → SMT/Z3-backed entailment checks → soundness/completeness metrics and post‑hoc filtering). Each item notes sector(s), potential tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Radiology report consistency checker embedded in PACS/RIS/EHR (Healthcare)
- What: A UI plug‑in that flags each Impression statement as Supported/Unsupported/Missed based on Z3 proofs from the model’s own Findings, with concise “why” explanations.
- Tools/workflows: Ontology-backed autoformalizer, Z3 engine, clinician-audited KB, in-report badges and proof panes, audit logs.
- Assumptions/dependencies: Coverage and accuracy of the knowledge base (KB); accurate extraction of Findings; closed‑world assumption (unmentioned findings treated as absent) fits local reporting style; acceptable solver latency; clinician oversight for exceptions.
- Inference‑time “entailment filter” for VLM reporting tools (Healthcare, Software)
- What: A post‑hoc filter that automatically removes or suppresses Impression diagnoses not entailed by the generated Findings; optionally prompts the user to add missing evidence or downgrade certainty.
- Tools/workflows: Z3 gating API at inference; configurable precision/recall trade‑offs per service line.
- Assumptions/dependencies: Reliable autoformalization; small but expected recall drop; clinical acceptance of conservative behavior; monitoring for over‑filtering.
- Model evaluation and procurement dashboards using soundness/completeness (Healthcare IT, AI Vendors, Academia)
- What: Reference‑free benchmarking of candidate VLMs using Soundness, Completeness, Specificity to select safer models and gate model updates.
- Tools/workflows: CI/CD checks with solver-based tests; heatmaps and trend dashboards; acceptance criteria (e.g., Soundness ≥ 0.99).
- Assumptions/dependencies: Representative ontologies per modality/task; standardized prompts for Findings/Impression; compute budget for batch verification.
- Regulatory submission artifact generator with proof logs (Policy/Regulatory Affairs, Industry)
- What: Produce solver certificates, entailment audit trails, and consistency metrics to accompany FDA/CE submissions or internal safety cases.
- Tools/workflows: Exportable proof objects, dataset‑wide reports, versioned KB/ontology snapshots.
- Assumptions/dependencies: Regulator acceptance of assume‑guarantee style proofs; traceability across model versions; robust documentation practices.
- Dataset labeling and quality audit via entailment (Academia, Industry)
- What: Derive or validate weak labels from reports by extracting entailed diagnoses; flag contradictory or low‑quality reports for curation.
- Tools/workflows: Batch autoformalization + verification; curator queues with evidence traces.
- Assumptions/dependencies: Report quality and consistency; KB coverage of target label set; human-in-the-loop validation.
- Resident education and assessment tool (Education, Healthcare)
- What: Case-based learning that shows which diagnoses are forced, unsupported, or omitted given the Findings, with interactive rule inspection.
- Tools/workflows: Curriculum-aligned ontologies; “explain the proof” teaching mode; formative quizzes based on entailment outcomes.
- Assumptions/dependencies: Instructor-reviewed KB; alignment with local reporting norms; acceptance of the closed‑world convention in training.
- Post‑deployment model monitoring and drift detection (Healthcare Operations)
- What: Track Soundness and Completeness over time to detect model/data drift and flag sudden increases in unsupported claims.
- Tools/workflows: Telemetry pipelines, alerting thresholds, release rollback hooks tied to soundness regressions.
- Assumptions/dependencies: Logging infrastructure; privacy/security safeguards; stable ontologies across versions.
- Cross‑specialty pilots with scoped KBs (Pathology, Dermatology, Ophthalmology)
- What: Run small, high‑value pilots where rule sets are tractable (e.g., diabetic retinopathy staging, common derm findings).
- Tools/workflows: Compact ontologies; scoped solver checks; clinician co‑design.
- Assumptions/dependencies: Effort to author specialty KBs; availability of structured exemplars; workflow integration.
- Verifier‑as‑a‑Service API for third‑party apps (Software, Health IT)
- What: A secure REST endpoint that takes Findings/Impression text and returns Supported/Unsupported/Missed with proofs and metrics.
- Tools/workflows: Multi‑tenant service, rate-limited; versioned KBs; SLA on latency.
- Assumptions/dependencies: HIPAA/GDPR compliance; throughput constraints; standardized input schemas.
Long‑Term Applications
- End‑to‑end verifiable VLMs trained with entailment‑aware objectives (Healthcare, Software)
- What: Models jointly optimized for fluency and logical entailment (e.g., loss terms for unsupported claims; reinforcement from verification).
- Tools/workflows: Differentiable proxies for solver feedback; neurosymbolic training loops; self‑verification during decoding.
- Assumptions/dependencies: Scalable training with verification in‑the‑loop; stable, comprehensive KBs; advances in program‑of‑thought methods.
- “Proof‑carrying reports” as a standard (Policy, Standards, Healthcare)
- What: Industry standards requiring Soundness thresholds and embedding proof artifacts into DICOM SR/HL7 messages.
- Tools/workflows: ASTM/ISO profiles, IHE integration; EHR viewers that render proofs and flags.
- Assumptions/dependencies: Consensus across vendors and providers; regulator endorsement; governance for KB versions.
- Community‑maintained ontologies and KBs across modalities (Academia/Industry Consortia)
- What: Open, versioned, peer‑reviewed rule sets spanning CXR, CT, MRI, ultrasound, with provenance and change logs.
- Tools/workflows: Collaborative authoring platforms; rule testing with unit cases; automated consistency checks.
- Assumptions/dependencies: Funding and clinician time; stewardship models; multilingual extensions.
- Interactive co‑pilot with live proof obligations (Healthcare Workflow)
- What: As clinicians dictate Findings, the system suggests entailed Impressions and highlights missing evidence in real time.
- Tools/workflows: Speech-to-structured-Findings; low‑latency verification; inline recommendations with explain‑why links.
- Assumptions/dependencies: Sub‑second solver response; UI ergonomics; mitigation of alert fatigue.
- Multi‑institutional safety monitoring networks (Policy, Healthcare Operations)
- What: Privacy‑preserving aggregation of soundness metrics to benchmark and catch systemic shifts across hospitals/vendors.
- Tools/workflows: Federated analytics; standardized telemetry schemas; public dashboards.
- Assumptions/dependencies: Data‑sharing agreements; differential privacy; neutral conveners.
- Cross‑domain adoption in finance, legal, and robotics (Finance, LegalTech, Robotics, Energy)
- What: Verify LLM/VLM outputs (e.g., risk summaries, contract clauses, mission plans) against structured evidence/constraints to prevent hallucinated claims or unsafe plans.
- Tools/workflows: Domain‑specific ontologies (e.g., regulatory rules, policy libraries, safety constraints); solver-backed checkers; audit trails for compliance.
- Assumptions/dependencies: High‑quality domain KBs; strict schemas for “evidence” extraction; acceptance by regulators and safety engineers.
- Automated rule induction with formal guarantees (Academia, Software)
- What: Learn candidate rules from data with LLMs, then formally validate consistency and align with clinician/legal expert feedback.
- Tools/workflows: Synthesis + counterexample‑guided refinement; continuous KB evolution pipelines.
- Assumptions/dependencies: Advances in autoformalization and inductive synthesis; scalable human review; robust version control.
- Patient‑facing verified lay summaries (Consumer Health)
- What: Generate patient‑friendly explanations where each claim links to Findings and machine‑checked logic.
- Tools/workflows: Plain‑language templates; explainers grounded in proofs; portal integration.
- Assumptions/dependencies: Health literacy design; careful risk communication; clinician approval of patient‑visible content.
- Edge verification for point‑of‑care imaging (Hardware/Software, Global Health)
- What: Portable ultrasound/X‑ray devices that output impressions only if entailed by on‑device verified findings.
- Tools/workflows: Lightweight solvers; compressed ontologies; offline operation.
- Assumptions/dependencies: Resource constraints; robust on‑device NLP/vision; update mechanisms for KBs.
- Cross‑lingual verification and global ontologies (Global Health, Education)
- What: Multilingual autoformalizers and aligned ontologies to support non‑English reporting and training.
- Tools/workflows: Cross‑lingual terminology mapping; localization pipelines; evaluator parity tests.
- Assumptions/dependencies: High‑quality multilingual corpora; culturally adapted KBs; consistent semantics across languages.
Glossary
- Assume-guarantee paradigm: A formal methods approach where system guarantees are proven under explicit assumptions about components or inputs. "Deductive guarantees follow a formal assume-guarantee paradigm, conditioned on the VLM's visual grounding of and the translational fidelity of ."
- Autoformalization: Automatically converting natural-language text into a formal, machine-checkable representation. "Our pipeline autoformalizes free-text radiographic findings into structured propositional evidence"
- Automation bias: The tendency of humans to overtrust automated systems, potentially overlooking errors. "A system that generates a fluent but self-contradictory report poses a severe risk of automation bias"
- Autoregressive objective function: A modeling objective where each token is generated by conditioning on prior tokens (and possibly inputs), optimizing next-token likelihood. "The core technical barrier to building verifiable VLMs lies in their autoregressive objective function"
- Closed-world assumption (CWA): The assumption that facts not explicitly stated are considered false or absent. "under a closed-world assumption (CWA), mirroring the clinical reporting standard where significant findings not mentioned are implicitly deemed absent."
- Clinical knowledge base: A curated set of formal clinical rules and relationships used to support logical reasoning about diagnoses. "utilizing an SMT solver (Z3) and a clinical knowledge base to verify whether each diagnostic claim is mathematically entailed, hallucinated, or omitted."
- Conservative observation: A failure mode where models avoid making diagnostic claims unless strongly supported, favoring safety over completeness. "such as conservative observation and stochastic hallucination"
- Costophrenic angle: The angle formed by the diaphragm and rib cage on chest X-rays; “blunting” is a radiographic sign often associated with pleural effusion. "blunted costophrenic angle"
- Decision procedure: An algorithm that deterministically decides the truth/satisfiability of a given logical formula. "and use the Z3 solver as a deterministic decision procedure"
- Deductive reliability: The degree to which a model’s conclusions are logically supported by its stated evidence. "we formally define two novel reference-free metrics to quantify a model's deductive reliability."
- Deductive validity: Whether conclusions follow logically from premises, independent of empirical similarity. "Compounding this issue, current evaluation paradigms are entirely empirical and fail to capture deductive validity."
- Findings (radiology): The section of a radiology report describing observed evidence and visual observations. "A VLM generates Findings and Impression text"
- Formal ontology: A structured, formal specification of concepts (predicates) and their relationships used for reasoning. "we define a lightweight formal ontology ."
- Formal verification: The use of mathematical methods to prove properties or correctness of systems. "explicit assume-guarantee conditions common in the domain of formal verification."
- Grammar entropy: A quantified measure of uncertainty in structured, grammar-constrained model outputs. "autoformalization uncertainty is quantified and surfaced via grammar entropy"
- Impression (radiology): The section of a radiology report that summarizes diagnostic conclusions derived from the findings. "comprising a Findings section and an Impression section ."
- Logical entailment: A relationship where the evidence and rules logically force a conclusion to be true. "verify whether each diagnostic claim is mathematically entailed, hallucinated, or omitted."
- Neurosymbolic verification: Combining neural models with symbolic logic to deterministically audit and guarantee consistency. "Toward guarantees for clinical reasoning, we introduce a neurosymbolic verification framework"
- Ontological grounding: Anchoring free-text content to a formal ontology to enable computable reasoning. "Ontological Grounding and Autoformalization"
- Pleural effusion: Accumulation of fluid in the pleural space around the lungs, often inferred from radiographic signs. "``pleural effusion''"
- Satisfiability (SAT) problem: Determining whether there exists an assignment that makes a propositional formula true. "We frame report verification as a formal satisfiability (SAT) problem."
- Satisfiability Modulo Theories (SMT): Extending SAT by reasoning under additional theories (e.g., arithmetic), typically solved by SMT solvers. "utilizing an SMT solver (Z3)"
- SMT constraints: Logic constraints expressed in a form suitable for SMT solvers to check satisfiability under theories. "We compile into SMT constraints"
- Sat (solver outcome): The solver result indicating that a formula is satisfiable under the given constraints. "the check is Sat."
- Specificity: The true-negative rate; the proportion of negatives correctly identified. "Precision, recall, F1, soundness, completeness, and specificity quantify how well Impression diagnoses are logically supported by generated Findings."
- Stochastic hallucination: Random, unsupported generation of diagnostic claims or content by a model. "such as conservative observation and stochastic hallucination"
- Unsat (solver outcome): The solver result indicating that a formula is unsatisfiable, often used to prove entailment by contradiction. "the check is Unsat."
- Z3: A state-of-the-art SMT solver used to check logical consistency and entailment. "use the Z3 solver as a deterministic decision procedure"
Collections
Sign up for free to add this paper to one or more collections.