Beyond Correctness: Exposing LLM-generated Logical Flaws in Reasoning via Multi-step Automated Theorem Proving
Abstract: LLMs have demonstrated impressive reasoning capabilities, leading to their adoption in high-stakes domains such as healthcare, law, and scientific research. However, their reasoning often contains subtle logical errors masked by fluent language, posing significant risks for critical applications. While existing approaches like fact-checking, self-consistency methods, and rule-based validation provide partial solutions, they fail to detect complex logical flaws in multi-step reasoning. To overcome these challenges, we present MATP, an evaluation framework for systematically verifying LLM reasoning via Multi-step Automatic Theorem Proving. MATP translates natural language reasoning into First-Order Logic (FOL) and applies automated theorem provers to assess step-by-step logical validity. This approach identifies hidden logical errors and provides fine-grained classifications of reasoning correctness. Evaluations on a benchmark comprising 10,830 reasoning instances generated by 10 LLMs across tasks from PrOntoQA-OOD, ProofWriter, and FOLIO show that MATP surpasses prompting-based baselines by over 42 percentage points in reasoning step verification. It further reveals model-level disparities, with reasoning models generating more logically coherent outputs than general models. These results demonstrate MATP's potential to enhance the trustworthiness of LLM-generated reasoning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how to check the logic behind answers that LLMs give. LLMs can write smooth, convincing explanations, but sometimes their step-by-step reasoning is secretly wrong. The authors built a tool called MATP (Multi-step Automated Theorem Proving) that turns an LLM’s natural-language reasoning into formal logic and then uses a logic-checking program to verify each step. The goal is to catch hidden mistakes and better judge whether a model’s explanation truly makes sense.
Key Questions the Paper Tries to Answer
- Can we reliably check the correctness of each step in an LLM’s reasoning, not just whether the final answer is right?
- Can we separate “coincidental” correct answers (lucky guesses) from answers backed by valid, step-by-step logic?
- Do some models reason more coherently than others, and what kinds of mistakes do they typically make?
How the Researchers Did It (Simple Explanation)
Think of an LLM’s explanation like a chain of dominoes: each sentence is a domino that should correctly knock over the next one. MATP checks whether each domino is set up properly and whether the chain actually leads to the final conclusion.
Here’s the process in everyday terms:
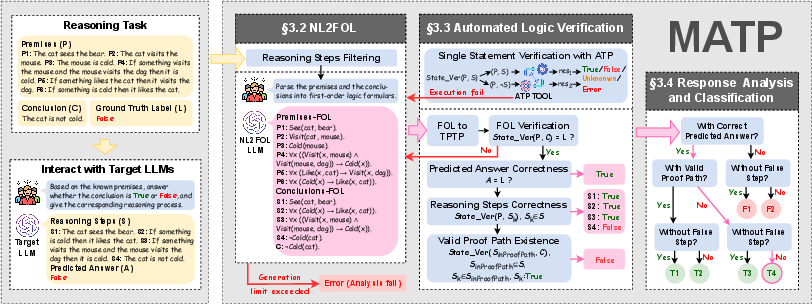
- Translate words into symbols: LLMs write explanations in normal sentences. MATP converts those sentences into First-Order Logic (FOL), a formal way to write facts and rules using symbols. For example, “All birds can fly” might look like “for all x, if x is a bird, then x can fly.”
- Use a logic judge: MATP then calls an Automated Theorem Prover (ATP), a specialized program (they use one called Vampire) that acts like a strict judge of logical arguments. It checks whether each step truly follows from the given facts.
- Check steps one by one: For every sentence in the LLM’s reasoning, MATP asks:
- Is this step provably true from the known facts? (True)
- Is it actually contradicted by the facts? (False)
- Or is there not enough information to tell? (Unknown)
- Look for a real proof path: Even if some steps are correct, MATP looks for a subset of steps that, when combined, genuinely lead to the final conclusion. This helps tell whether the model reached the answer through valid logic or just got lucky.
- Classify the explanation: MATP groups the model’s responses into categories, such as:
- Correct answer with a fully valid chain of reasoning.
- Correct answer but missing or flawed steps (maybe a lucky guess).
- Wrong answer even though the steps seemed fine (the chain didn’t actually prove the conclusion).
- Wrong answer with clearly wrong steps.
To make this work well, the authors designed careful prompts to control how the LLM translates sentences into logic, added rules to keep symbols consistent (like reusing the same “Tom” across steps), and retried translations when the logic-checking program detected formatting errors.
Main Findings and Why They Matter
- MATP is much better at verifying reasoning steps than simple prompting baselines. Across 10,830 test cases from three datasets (PrOntoQA-OOD, ProofWriter, and FOLIO), MATP beat prompting-only methods by over 42 percentage points when judging step correctness.
- The logic translation works very well on structured tasks. On the more “formula-like” datasets (PrOntoQA-OOD and ProofWriter), the natural language to logic (NL2FOL) conversion had over 99% syntactic accuracy. It was still good on the more natural, everyday language found in FOLIO, though a bit lower.
- MATP can tell apart fine-grained reasoning types. On a controlled test set built by the authors, MATP reached 99% accuracy distinguishing “fully sound” chains from “partly flawed” or “invalid” ones.
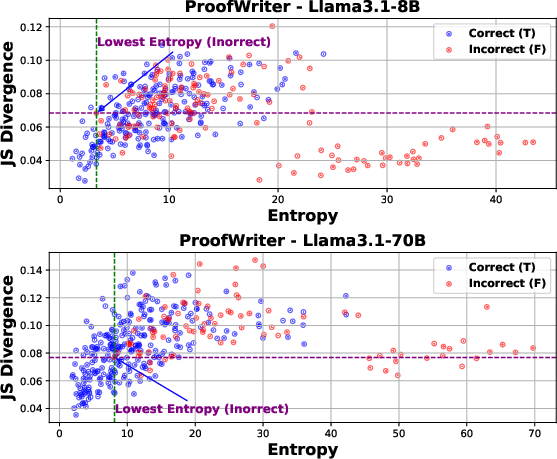
- Reasoning-focused models tend to produce more coherent logic chains. Models designed for reasoning (like DeepSeek-R1) generally had more logically consistent explanations than general-purpose models, even when final answer accuracy looked similar.
- Most failures come from the translation step. When things went wrong, it was often because converting complex or casual sentences into precise logic was tricky. The paper lists common translation errors to help improve future systems.
These results matter because they show that it’s possible to go beyond “is the final answer right?” and rigorously check the reasoning itself. That’s critical in areas like healthcare, law, and science, where subtle logical errors can be dangerous.
What This Means Going Forward
- Safer AI in high-stakes areas: MATP can help ensure that AI systems not only give correct answers but also provide sound reasoning, reducing risks from hidden logical mistakes.
- Better model development: The fine-grained categories and error patterns can guide model designers to fix specific weaknesses (for example, improving how models handle quantifiers like “for all” or “there exists”).
- More trustworthy explanations: Users, teachers, and researchers can use tools like MATP to verify whether an explanation is truly logical, not just well-written.
- Stronger evaluation standards: This work pushes the field toward evaluating “how” models think, not just “what” they conclude—making AI more reliable and transparent.
In short, MATP turns LLM explanations into formal logic, checks them step by step, and clearly labels whether the reasoning is solid. This makes it easier to trust AI in real-world, critical situations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes MATP for post-hoc verification of LLM-generated deductive reasoning via NL2FOL translation and automated theorem proving. While promising, several aspects remain missing or unresolved. Future work could address the following:
- NL2FOL translator dependence and bias:
- The pipeline relies on a single LLM (GPT‑4o) to formalize premises, intermediate steps, and conclusions. How robust are results to the choice of translator model, decoding strategy, or translation prompts? Evaluate cross-translator consistency (e.g., Claude, Llama, Qwen) and introduce deterministic, grammar-driven or parser-assisted NL2FOL conversions to reduce variance.
- Investigate whether the translator’s predicate naming conventions systematically favor certain target LLM output styles, potentially biasing cross-model comparisons.
- Limited error diagnosis and regeneration:
- Regeneration is blind (no feedback) and conflates label mismatches with translation errors. Develop counterexample-guided repair by using ATP proof objects, unsat cores, or minimal inconsistent subsets to pinpoint and correct specific translation faults.
- Add instrumentation to distinguish between ground-truth label errors and NL2FOL misformalization (e.g., independent human-curated FOL for a subset, or direct prover checks on gold FOL).
- Step-level verification ignores dependency context:
- Each step is verified only w.r.t. premises P, not w.r.t. P ∪ previously derived steps. This can mislabel legitimate intermediate derivations as Unknown/False. Extract and verify step dependencies (e.g., build a dependency graph or require models to cite premises/earlier steps) and assess steps under the appropriate context.
- Proof-path search heuristic lacks completeness and premises:
- The proof-path construction includes True steps that add “new facts,” but checks entailment against S_inProofPath alone (excluding premises P). This may reject valid paths relying on P or miss minimal subsets. Formalize proof-path search with completeness guarantees (e.g., subset selection via SAT/ILP, A* over proof graphs) and ensure P is included in the entailment context.
- “Unknown” outcome conflates multiple failure modes:
- Unknown currently mixes ATP timeouts, resource limits, NL2FOL ambiguity, and genuine indeterminacy. Break down Unknown into subcategories by logging ATP resource usage, try multiple ATPs/strategies, and add bounded model checks to disentangle algorithmic limits from logical undecidability.
- Handling inconsistent premises:
- If both S and ¬S are provable, MATP returns Error, assuming P must be consistent. Real-world data can be inconsistent. Explore paraconsistent logics or inconsistency-tolerant reasoning to assess reasoning chains under conflicting premises.
- Logical expressiveness constraints:
- FOL/FOF (TPTP) lacks explicit support for arithmetic, temporal, modal, probabilistic, or higher-order constructs often needed in real tasks. Quantify coverage gaps and integrate SMT (e.g., Z3 for arithmetic), temporal/modal logics, or HOL provers (e.g., Isabelle/HOL, HOL Light) for richer reasoning.
- Ambiguity and semantic phenomena in NL2FOL:
- No systematic analysis of failure cases in quantifier scope, anaphora/coreference, negation scope, plurals/collectives, conditional/contraposition, presuppositions, or bridging inferences. Build an error taxonomy and targeted prompt rules or parsing modules (e.g., semantic role labeling, coreference resolution, scoped quantifier assignment) to reduce these errors.
- Predicate/ontology alignment:
- Predicate naming and re-use are only encouraged by prompts; there is no canonicalization or ontology alignment across steps. Introduce predicate canonicalization, synonym clustering, or mapping to domain ontologies to ensure step coherence and reduce spurious symbol proliferation.
- Treatment of uncertainty and reflective reasoning:
- Filtering removes statements containing uncertainty (e.g., “possibly,” “not necessarily”), potentially discarding meaningful meta-reasoning. Consider formalizing uncertainty via modal/probabilistic logics rather than filtering, and evaluate how uncertainty should affect proof-path validity.
- Dataset coverage and sampling bias:
- Benchmarks are synthetic or controlled (PrOntoQA-OOD, ProofWriter) and a subset of FOLIO; Unknown labels are excluded, and max-hop subsets are favored. Assess generalization to high-stakes, noisy, long-document domains (e.g., clinical notes, legal cases) and reintroduce Unknown to reflect realistic non-entailment scenarios.
- Measure the impact of sampling choices on label balance, linguistic diversity, and reasoning structures.
- Cross-prover robustness:
- Verification uses Vampire only. Compare across provers (e.g., E, Prover9, iProver, Z3) and strategies, set time/memory budgets explicitly, and report agreement rates and sensitivity to prover configurations.
- Scalability, latency, and cost:
- The paper does not report end-to-end runtime, ATP timeouts, or costs of repeated NL2FOL calls for 10,830 instances. Provide throughput and cost profiles, identify bottlenecks, and evaluate feasibility for real-time or large-scale deployment.
- Adversarial robustness:
- It remains unknown whether attackers can craft reasoning chains that systematically fool NL2FOL or ATP (e.g., predicate aliasing, obfuscation, misleading quantifier structures). Design adversarial tests and defense mechanisms (e.g., symbol canonicalization, anomaly detection).
- Multilingual and domain adaptation:
- The pipeline is English-centric. Test NL2FOL and ATP performance on multilingual inputs and domain-specific jargon (e.g., biomedical, legal), and incorporate domain ontologies/controlled vocabularies for improved mapping.
- Step segmentation and atomicity:
- Sentence-based splitting may not correspond to atomic propositions, leading to mixed claims within a single “step.” Develop methods to extract atomic claims (e.g., clause splitting, dependency parsing) and verify at the right granularity.
- Deduplication side effects:
- Deduplication after FOL conversion can remove semantically distinct but syntactically identical steps (e.g., reassertions that serve structural roles). Quantify the impact and consider keeping duplicates when they serve inferential dependencies.
- Equality, sorts, and typing:
- The method does not discuss equality axioms or sorts/types, which matter for domains mixing people, places, quantities. Evaluate whether adding typed logics or sort discipline improves translation and provability.
- Using MATP signals to improve models:
- MATP is purely evaluative. Explore using step-level correctness and proof-path feedback for training/finetuning (e.g., RL, rejection sampling, constitutional objectives) to reduce logical errors.
- Mapping reasoning categories to actionability:
- The T1–T4/F1–F2 taxonomy is informative but lacks operational thresholds for trust decisions in high-stakes domains. Define decision rules (e.g., when T2 is acceptable), quantify risk, and calibrate user-facing confidence.
- Variability and self-consistency:
- Experiments fix temperature to 0 (except GPT‑o4‑mini). Examine whether self-consistency or diverse sampling improves reasoning quality and MATP’s classifications, and how variability interacts with formal verification.
- Reproducibility of metrics:
- The paper introduces metrics (e.g., Logical Equivalence) but truncates details. Precisely define and open-source metric computations (including ATP configurations) to ensure comparability across studies.
- Representativeness of the classification dataset:
- The controlled perturbation dataset supports MATP’s classification evaluation, but its realism relative to organic LLM errors is unclear. Release the dataset and report how its error modes compare to those observed in the benchmark and in-the-wild outputs.
Glossary
- Adversarial attacks: Deliberate input perturbations designed to mislead model reasoning. "LLM reasoning remains vulnerable to adversarial attacks, where minor input perturbations can systematically corrupt reasoning chains"
- Automated theorem prover (ATP): A software system that automatically checks the validity of logical statements. "applies automated theorem provers to assess step-by-step logical validity"
- Axiom: A statement taken as true within a formal system, used as a basis for deriving other statements. "role specifies whether it is an axiom or a conjecture"
- Completeness (logic): A property of a logical system where all semantically valid statements are syntactically provable. "Due to the completeness of FOL, finding such a proof provides a definitive confirmation of the original semantic entailment "
- Conjecture: A statement proposed to be proven within a theorem-proving task. "role specifies whether it is an axiom or a conjecture"
- Exclusive disjunction: A logical connective true when exactly one of its operands is true (xor). "exclusive disjunction is rewritten as "
- Existential instantiation: Referring consistently to an entity introduced by an existential quantifier across steps. "To ensure cross-step coherence in existential instantiation, we enforce rule constraints to consistently reference entities and their predicate attributes introduced in earlier steps"
- Existential quantifier: A quantifier indicating that there exists at least one object satisfying a property. "quantifiers ( for
for all'', forthere exists'')" - First-Order Logic (FOL): A formal language for expressing statements with predicates, variables, and quantifiers. "translates natural language reasoning into First-Order Logic (FOL)"
- FOF format: A TPTP representation style for first-order formulas. "Each formula is translated into TPTP’s FOF format: ``fof(name, role, formula)''"
- Logical consequence: A relation where a conclusion must be true if the premises are true. "A conclusion is a logical consequence of a set of premises , denoted as "
- Logical entailment: The formal implication that one set of statements implies another within a logic. "ATPs are specialized tools designed to automatically determine the validity of logical entailments in formal systems like FOL"
- Logical equivalence: Two statements that are true under the same interpretations. "LE (Logical Equivalence)"
- Logical validity: The property that a conclusion is true in all models that satisfy the premises. "The central criterion for evaluating such reasoning is logical validity"
- Macro F1-score: An evaluation metric averaging F1 scores across classes, treating each equally. "by more than 42 percentage points in macro F1-score"
- Model (in logic): An interpretation assigning meaning to symbols that makes certain statements true. "every model (i.e., every possible interpretation of the symbols)"
- Neuro-symbolic AI: Approaches combining neural networks with symbolic reasoning methods. "Large Reasoning Models (LRMs) that augment LLMs with neuro-symbolic AI, reinforcement learning, and causal inference"
- Predicate: A function or relation expressing properties or relationships among objects. "predicates representing properties or relations"
- Proof by refutation: Establishing validity by showing that assuming the negation leads to contradiction. "primarily operate on the principle of proof by refutation"
- Proof path: A sequence of reasoning steps that together entail a conclusion. "searches for a valid proof path within the reasoning chain"
- Propositional logic: A simpler logic using propositions without quantifiers or predicates. "It extends propositional logic with predicates and quantified variables"
- Quantifier scope: The extent of a formula over which a quantifier applies. "Parentheses are applied to complex statements to define quantifier scopes and avoid ambiguity"
- Refutable: A statement that contradicts the premises and can be shown false given them. "There are three possible outcomes for : provable...; refutable, which means contradicts "
- Semantic entailment: The notion () that a conclusion is true in all models of the premises. "this semantic entailment () is equivalent to syntactic provability ()"
- Soundness (logic): A property where all syntactically provable statements are semantically valid. "In sound and complete logical systems like FOL"
- Syntactic provability: The derivability of a statement using formal inference rules (). "this semantic entailment () is equivalent to syntactic provability ()"
- TPTP (Thousands of Problems for Theorem Provers): A standardized format and library for theorem-proving problems. "translated FOL formulas into the standardized TPTP (Thousands of Problems for Theorem Provers) format"
- Unsatisfiability: The property that no interpretation can make a set of formulas all true. "unsatisfiability of "
- Vampire: A state-of-the-art automated theorem prover for first-order logic. "including Vampire~\cite{kovacs2013vampire} used in our work"
Practical Applications
Below is a concise mapping from the paper’s findings and methods (MATP: NL→FOL translation + ATP-based step-wise verification + proof-path extraction + fine-grained classification) to practical applications. Items are grouped by deployment horizon and, where helpful, tied to concrete sectors with example tools/workflows and feasibility notes.
Immediate Applications
Industry (cross-sector guardrails, QA, and LLMOps)
- LLM reasoning guardrail for deductive tasks
- What: Post-hoc verification of step-by-step reasoning for tasks that can be expressed as premises → conclusion (e.g., policy/rule application, knowledge-base Q&A, eligibility checks).
- Where: Customer support (policy compliance), internal policy assistants, regulated workflows requiring strict rule-following.
- Tools/workflows: Middleware API that captures the model’s steps, translates them to FOL, runs Vampire, and returns step labels (True/False/Unknown) and proof-path status; “reject or revise” loops when invalid.
- Dependencies: Reasoning steps must be available (model must output steps); premises must be explicit; domain logic must be FOL-expressible; NL2FOL accuracy degrades on noisy or very complex text; ATP timeouts on large inputs.
- LLMOps evaluation and model selection
- What: Systematic, model-level comparison using MATP’s fine-grained categories (T1–T4/F1–F2) to pick more logically consistent models for specific tasks.
- Where: Platform evaluation, procurement, and regression testing across model updates.
- Tools/workflows: Evaluation dashboards; CI checks that track macro F1 on step verification and proof-path rates; routing to “reasoning models” for tasks detected as deductive.
- Dependencies: Benchmark tasks must resemble deployment logic; coverage limited to deductive reasoning; NL2FOL/ATP infra availability.
- Data curation for training and RLHF/RLAIF
- What: Filter and label model rationales; keep T1 traces (valid proof paths) and downweight T4/F2 traces to improve training data quality.
- Where: Model training pipelines; “proof-grounded” dataset creation.
- Tools/workflows: Offline batch scoring of rationale datasets; tags propagate into curriculum or reward functions.
- Dependencies: Cost of large-scale NL2FOL+ATP; assumes rationale disclosure; curation signal best for deductive tasks.
- Software engineering (spec-adjacent reasoning checks)
- What: Verify AI-generated explanations, bug analyses, or requirement-to-test mappings when these can be phrased as premises and entailments.
- Where: Code review, requirements engineering, safety-critical documentation.
- Tools/workflows: GitHub Action/CI gate that fails PRs when explanations contain invalid steps or lack a valid proof path; issue templates with “premises” and “conclusion” sections.
- Dependencies: Explanations must be structured; engineering claims must be (at least approximately) FOL-expressible; ATP scale limits.
- Internal compliance and audit trails
- What: Attach “proof of reasoning” artifacts to high-stakes LLM outputs (who/what/why entailed), enabling audits.
- Where: Finance (policy rule application), HR (eligibility), procurement.
- Tools/workflows: Store TPTP and proof-path IDs with decisions; dashboards listing invalid steps and contradiction points.
- Dependencies: Organizational acceptance of FOL-backed evidence; premise extraction and normalization; chain-of-thought governance.
Academia (evaluation, benchmarking, and teaching)
- Fine-grained benchmarking of reasoning systems
- What: Use MATP to compare models across datasets and tasks beyond final accuracy.
- Tools/workflows: Leaderboards reporting step validity and proof-path rates; ablation on NL2FOL variants.
- Dependencies: Access to an ATP and robust NL2FOL prompts; tasks must be deductive.
- Proof and logic education assistants
- What: Autograding and feedback on step-by-step proofs/logic problems (math olympiad-style, LSAT logic games, discrete math).
- Tools/workflows: Tutor that flags unsupported or contradictory steps and highlights minimal proof paths.
- Dependencies: Student submissions structured into premise/step/conclusion; domain mapped to FOL.
Policy and Governance (internal)
- Risk assessments for AI features
- What: Pre-deployment reviews where high-stakes features must pass step-wise consistency checks on representative cases.
- Tools/workflows: Conformance tests with MATP-backed verdicts; “pass/fail” thresholds on proof-path coverage.
- Dependencies: Representative test suites; staff able to interpret Unknown/translation errors; deductive scope.
Daily Life (lightweight logic checking)
- Argument/logic checkers for structured tasks
- What: Basic tools for checking the internal consistency of short, rule-based arguments (e.g., puzzle solving, study aids).
- Tools/workflows: Browser or note-taking plugin that extracts premises/steps and runs a quick entailment check.
- Dependencies: Short inputs; clear premises; limited language ambiguity.
Long-Term Applications
Healthcare
- Clinical decision support with proof-carrying recommendations
- What: Verify that diagnostic/therapeutic suggestions deductively follow from codified guidelines and patient facts.
- Tools/products: EHR-integrated “reasoning validator” that annotates which steps are supported and where logic breaks.
- Dependencies: Formalization of guidelines and patient context into FOL; robust NL2FOL for medical language; handling uncertainty and probabilistic evidence (beyond FOL); strict latency and safety requirements.
Law and Public Policy
- Legal reasoning verification and compliance automation
- What: Validate that conclusions (e.g., contract interpretations, tax determinations) logically follow from statutes/clauses and case facts.
- Tools/products: Contract-review assistants flagging unsupported steps; compliance engines with proof-path certificates.
- Dependencies: Translating statutes/clauses into formal logic (often needs deontic/defeasible/temporal logics beyond FOL); domain nuance and exceptions; high translation fidelity.
- Regulatory “proof of reasoning” standards
- What: Certification regimes requiring machine-consumable reasoning proofs for automated decisions.
- Tools/products: Auditable reasoning logs in TPTP/standard formats; third-party verifiers.
- Dependencies: Standardization across logics; acceptance by regulators; scalability; privacy of reasoning traces.
Finance
- Rule-driven risk/compliance systems with formal audits
- What: Validate LLM-assisted policy application (KYC/AML, underwriting criteria) and maintain defensible audit trails.
- Tools/products: “Reasoning firewall” in decision pipelines; post-hoc audit systems that reconstruct proof paths.
- Dependencies: High-throughput ATP; precise mapping of policies to logic; evolving rules; adversarial inputs.
Software, Robotics, and Autonomous Agents
- Proof-guided agents and planning
- What: Agents that generate candidate plans/reasoning steps and iteratively repair them until a proof path exists; verify goal entailment before execution.
- Tools/products: Planner integrating NL2FOL, domain models (e.g., PDDL-to-logic bridges), and ATP; “proof-carrying actions.”
- Dependencies: Domain models and action semantics in compatible logic; need for temporal/modal logics; real-time constraints.
- Proof-carrying code explanations/specifications
- What: Require LLMs to attach verifiable reasoning to code transformations or spec updates.
- Tools/products: IDE plugins that accept only proofs with valid reasoning chains; spec conformance checkers.
- Dependencies: Formal specs; large-scale ATP; mapping code semantics to logic.
Education and Research
- Large-scale reasoning data generation and training
- What: Use MATP labels to bootstrap “sound reasoning” corpora for training next-gen reasoning models and to design reasoning curricula.
- Tools/products: Data pipelines that auto-select T1 traces, synthesize counterexamples, and construct challenge sets.
- Dependencies: Compute costs; generalization beyond curated deductive sets; balance with inductive/abductive capabilities.
- Multi-logic, high-fidelity verification
- What: Extend beyond FOL to temporal, probabilistic, deontic, and non-monotonic logics needed in real-world domains.
- Tools/products: Flexible translation layer; portfolio of provers; meta-reasoners picking the right logic.
- Dependencies: Research and tooling maturity; evaluation standards; complexity management.
Safety, Security, and AI Governance
- Adversarial robustness testing for reasoning
- What: Systematically perturb inputs and use MATP to detect brittle or shortcut reasoning; build red-team suites.
- Tools/products: “Reasoning fuzzers” generating perturbed premises; dashboards tracking failure modes.
- Dependencies: Perturbation frameworks; ground-truthable tasks; compute for repeated ATP runs.
- Privacy-preserving “proof-of-reasoning”
- What: Cryptographic or abstracted proofs that certify logical validity without full chain-of-thought disclosure (meeting IP/privacy constraints).
- Tools/products: Zero-knowledge or summarized proof artifacts; policy-compliant logging layers.
- Dependencies: Research into privacy-preserving verification; standard formats; provider cooperation.
Key Assumptions and Dependencies (affecting feasibility across applications)
- NL2FOL translation quality: Strong on structured, synthetic tasks; lower on linguistically complex or domain-specific text (e.g., medicine, law). Pronouns, scope, quantifiers, and modality are common pitfalls.
- Availability of reasoning steps: Many providers restrict chain-of-thought exposure; internal deployments may allow rationale capture, but public APIs may not.
- Suitability for deductive tasks: MATP targets deductive validity; abductive/inductive or probabilistic reasoning requires other formalisms.
- Premise completeness and correctness: Real-world use demands robust premise extraction/normalization; missing or implicit knowledge limits verification.
- Prover scalability and latency: ATPs can time out on large or complex inputs; engineering is needed for batching, caching, and time budgets.
- Adversarial robustness: Inputs can be phrased to confound translation; defenses (sanity checks, regeneration, predicate normalization) are needed.
- Governance and acceptance: Organizations/regulators must accept formal-proof artifacts; standards for proof formats and auditability will accelerate adoption.
Taken together, MATP’s contribution can be deployed immediately as a high-precision evaluator and guardrail for well-bounded deductive tasks, while its broader promise lies in long-term, proof-grounded AI systems across healthcare, law, finance, software/robotics, and governance—contingent on advances in translation fidelity, domain formalization, and multi-logic support.
Collections
Sign up for free to add this paper to one or more collections.