- The paper introduces an automated framework that extracts LLM reasoning as formal predicates and verifies them using program analysis tools.
- It categorizes key error modes in LLM code reasoning and demonstrates the efficacy of iterative formalization across MSAN bugs and program equivalence queries.
- Empirical results show that the verifier catches 75% of LLM hallucinations and increases recall through repeated predicate synthesis, enhancing trust in automated code reviews.
Motivation and Problem Statement
LLMs and LLM-powered agents have demonstrated significant capabilities in code reasoning tasks, including bug explanation, code review, and program equivalence queries. However, their propensity for hallucination and incorrect reasoning undermines their utility in high-precision software engineering contexts. Manual verification of LLM-generated explanations is labor-intensive and impedes developer productivity. This paper introduces a framework for automatically validating the reasoning steps of LLM-based code agents by extracting formal representations of their explanations and verifying them using program analysis and formal verification tools.
Error Taxonomy in LLM Code Reasoning
The authors systematically categorize errors in LLM code reasoning into three primary classes: (a) incorrect assumptions about code semantics, (b) failure to consider all relevant aspects of a problem, and (c) unwarranted assumptions about library behavior. Empirical analysis on CRQBench and custom benchmarks reveals that LLMs frequently misinterpret control flow, neglect edge cases (e.g., null pointers, negative indices), and overgeneralize library function semantics. These error modes motivate the need for post hoc formal verification of agent claims.
The proposed framework consists of three core components:
- AgentClaims: Extraction of the agent's reasoning steps as formal predicates, typically in Datalog.
- CodeSemantics: (Deferred in this work) Ground truth semantics of the code, ideally extracted via static analysis tools such as CodeQL.
- VerificationCondition: Task-specific formal properties to be checked, e.g., existence of uninitialized variable flows or program equivalence.
The agent's explanation is deemed correct if CodeSemantics⇒AgentClaims and AgentClaims⇒VerificationCondition. The current implementation focuses on verifying AgentClaims⇒VerificationCondition.
The formalization pipeline is instantiated for two code reasoning tasks: uninitialized variable errors (MSAN bugs) and program equivalence queries.
Agent explanations for MSAN bugs are converted into formal predicates representing allocation, data flow, usage, and uninitialized status. The process involves:
- Filling in missing code snippets from the agent's explanation.
- Extracting a concrete execution trace.
- Generating a formal representation using a fixed predicate vocabulary.
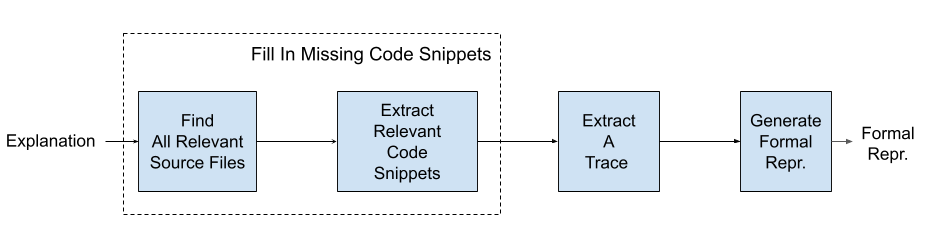
Figure 1: Generating a formal representation for MSAN bugs from the agent's explanation.
Verification is performed by checking for the existence of a data flow from an uninitialized variable to a usage site, as specified by the verification condition.
For program equivalence queries, the pipeline comprises:
- Analyzer: LLM-based agent retrieves relevant code snippets and provides a natural language explanation.
- Formalizer: LLM converts the explanation and code into logical predicates capturing def-use chains, data/control dependencies, and variable correspondences.
- Verifier: Souffl Datalog engine checks if the predicates satisfy the equivalence verification condition.
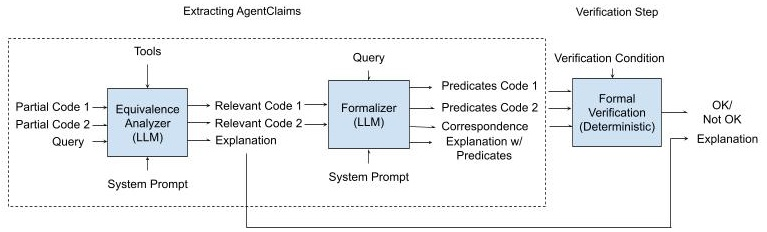
Figure 2: Equivalence queries pipeline: Analyzer → Formalizer → Verifier.
The predicate vocabulary is designed to capture dataflow, control dependencies, expression semantics, and variable mappings, enabling precise reasoning about program equivalence beyond observational equivalence.
Empirical Evaluation
MSAN Bugs
On a benchmark of 20 MSAN bugs (5 runs per bug, 100 total), manual evaluation found 88 valid agent explanations. The formal verifier validated 18/88 explanations in a single formalization iteration, with recall increasing to 36/88 after five iterations, covering 13/20 unique bugs.
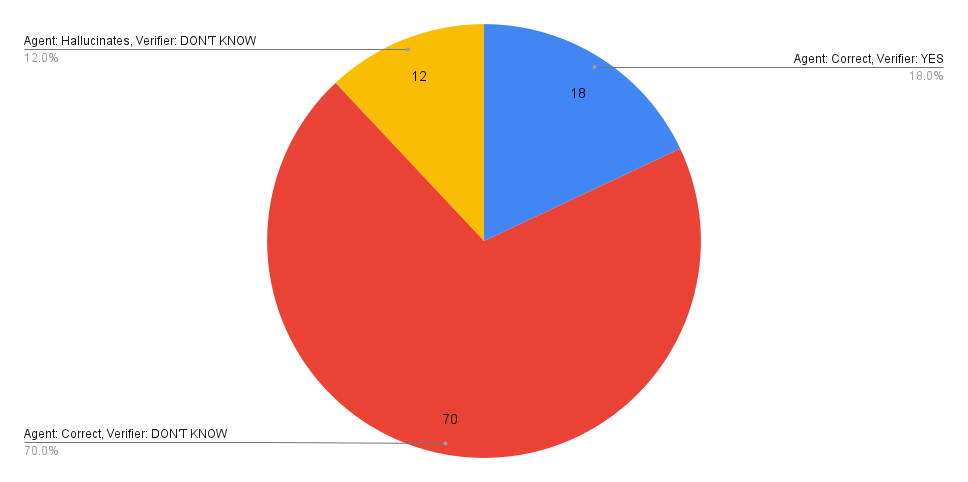
Figure 3: Results of formal verification for MSAN bugs with one formalization iteration.
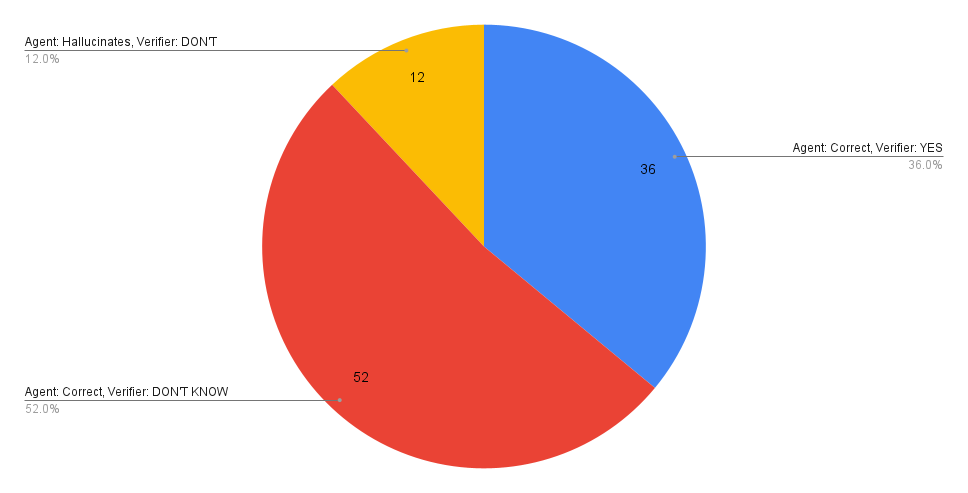
Figure 4: Results of formal verification for MSAN bugs with five formalization iterations.
Program Equivalence
On 20 program equivalence queries (CRQBench and Fbounds-Safety), the agent hallucinated in 8/20 cases, with the verifier catching 6/8 (75%) of these errors. The verifier validated correct agent claims in 9/20 cases. In 3/20 cases, the verifier failed due to predicate set incompleteness, and in 2/20 cases, both agent and verifier missed equivalence due to incomplete code retrieval.
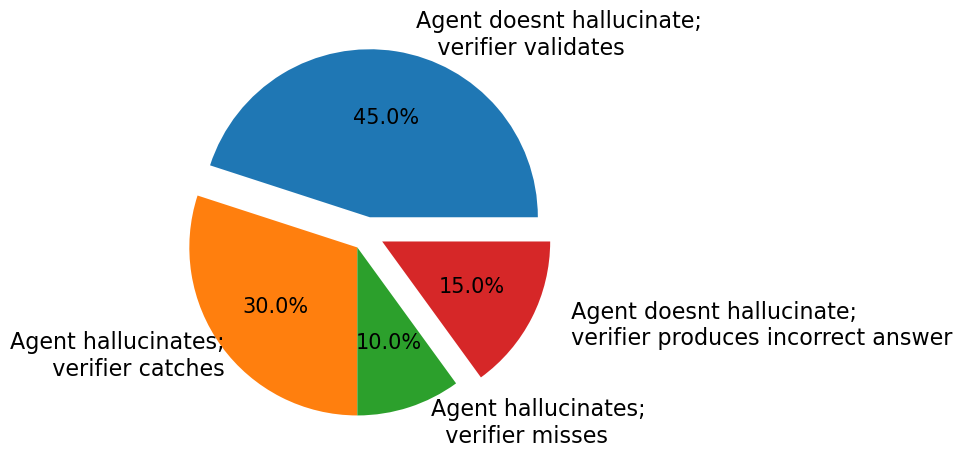
Figure 5: Fraction of problems by agent/verifier outcome; 40% agent hallucination rate, 75% caught by verifier.
Iterative formalization was essential for completeness; a single run often omitted necessary predicates, leading to inconclusive verification.
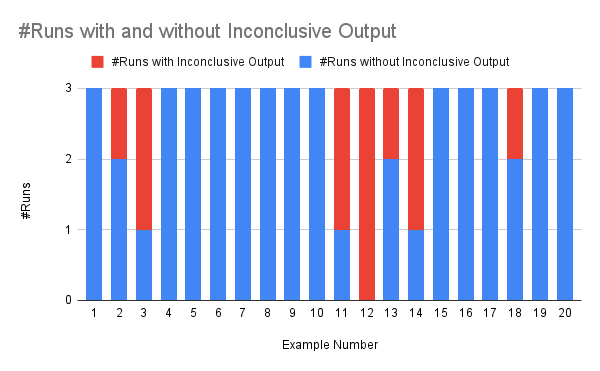
Figure 6: Number of times the agent failed to generate all required predicates, resulting in inconclusive verifier output.
Implementation Considerations
- Predicate Design: The expressiveness and granularity of the predicate vocabulary directly impact verification precision. Modeling expressions as unary/binary functions and explicit variable mappings is critical for equivalence tasks.
- Iterative Formalization: Multiple LLM calls are required to synthesize missing predicates, especially for complex code snippets.
- Verifier Limitations: The approach inherits the undecidability and conservativeness of static analysis; false negatives and false positives persist when predicate sets are incomplete or code retrieval is insufficient.
- Model Selection: Stronger LLMs (e.g., Gemini 2.5 Pro) improve formalization consistency and recall.
Implications and Future Directions
This framework demonstrates that post hoc formal verification of LLM agent reasoning can substantially increase trust in code explanations and equivalence judgments. The approach is modular, allowing for improved predicate design, prompt engineering, and integration of more powerful verifiers. Future work should address automatic extraction of code semantics, dynamic inference of verification conditions, and fine-tuning LLMs for verifiable explanations. The methodology is extensible to other code reasoning domains, including specification adherence, security analysis, and automated code review.
Conclusion
The paper presents a principled method for validating LLM-based code reasoning agents by formalizing their explanations and verifying them against task-specific conditions. Empirical results show that the verifier can catch a significant fraction of agent hallucinations and validate correct reasoning in nontrivial cases. The framework highlights the necessity of formalization, iterative predicate synthesis, and careful predicate design for reliable automated code reasoning. This work lays the foundation for more trustworthy LLM-powered developer tools and suggests promising avenues for integrating formal methods with neural code intelligence.