- The paper presents a neuro-symbolic pipeline that formalizes LLM chain-of-thought steps into first-order logic to enable detailed logical verification.
- It leverages automated premise generation alongside a Z3 solver for consistency and entailment analysis, addressing key reasoning failures.
- Empirical evaluations show significant gains in verification pass rates and corrected outcomes through inference-time self-reflection and fine-tuning.
Neuro-Symbolic Chain-of-Thought Validation via Logical Consistency Checks: A Detailed Technical Analysis of VeriCoT
Introduction and Motivation
VeriCoT presents a neuro-symbolic verification pipeline for dissecting and validating multi-step reasoning in LLM-generated Chain-of-Thought (CoT) traces by formalizing each step in first-order logic (FOL), anchoring logical arguments to well-grounded premises from context, source documents, and commonsense, and performing consistency/entailment analysis via a symbolic solver (Z3 on SMT-LIB). The system addresses two core failure modes in LLM-generated CoT: (1) producing correct final answers amidst invalid intermediate reasoning, and (2) failing to surface the implicit assumptions and dependencies in reasoning steps, which jeopardizes faithfulness and trust for high-stakes domains such as legal or biomedical QA.
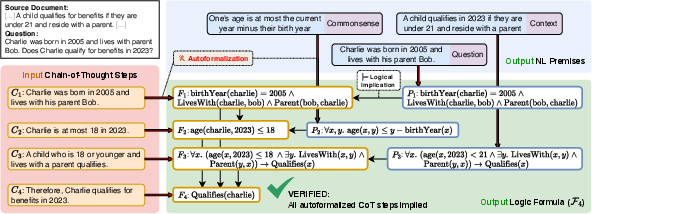
Figure 1: VeriCoT verification of a Chain-of-Thought for legal reasoning, highlighting symbolic mapping, premise sourcing, and step-wise logical validation.
VeriCoT Pipeline: Architecture and Technical Components
Autoformalization employs LLMs in a two-stage translation protocol. Initial attempts leverage previously established vocabulary to map NL reasoning steps (Ci) into FOL expressions (Fi) within SMT-LIB syntax. When vocabulary coverage is insufficient, subsequent prompts extend the logical schema, introducing new sorts, functions, and constants to accommodate domain-specific concepts. This loop ensures maximal expressiveness with minimal unsupported fragments. Failure to produce syntactically stable, semantically meaningful formulas after several iterations categorizes the step as “untranslatable.”
Schema Example
A representative translation sequence from “Charlie is at most 18 years old in 2023” yields declarations such as:
1
2
3
4
5
6
|
; current year for calculation
(declare-const current_year Int)
; age of a person in a given year
(declare-fun age_in_year (Person Int) Int)
(assert (= current_year 2023))
(assert (<= (age_in_year charlie current_year) 18)) |
This modular expansion supports robust logical grounding and facilitates stepwise constraint propagation.
Premise Generation and Attribution
When Fi is neither entailed nor contradicted by existing knowledge (Fi−1), VeriCoT invokes premise generation using LLM prompts, sourcing candidate premises from context/document/commonsense and formalizing them into logic fragments. Each premise Pi is validated for consistency (Fi−1∧Pi is satisfiable) before being conjoined into the overall premise formula. This design explicitly surfaces which context elements or knowledge types each reasoning step depends upon.
Solver-Driven Logical Checking
VeriCoT leverages the Z3 solver for two forms of logical analysis:
- Consistency Checking: Determines if newly proposed Fi contradicts established knowledge.
- Entailment Analysis: Tests whether Fi−1⊨Fi (i.e., if the step follows necessarily), or whether additional premises are needed.
The system returns explicit error types for failures:
- Ungrounded (missing premises)
- Contradiction (inconsistent logic)
- Untranslatable (semantic/syntactic failures)
LLM-as-Judge (LLMaj) Evaluation
To counter LLM confabulation errors in premise generation, VeriCoT employs a secondary LLM to adjudicate premise quality. For context-derived premises, the judge model compares against source text for attribution; for commonsense, it evaluates necessity and acceptability. Empirical premise evaluations show high rates of quality (Tables in Text), further fortifying the interpretability of CoT validation.
Empirical Evaluation
Datasets and Benchmarks
VeriCoT is evaluated on ProofWriter (synthetic logico-linguistic reasoning), BioASQ (biomedical QA), and SARA from LegalBench (statutory tax law reasoning). Each domain presents distinct types of premise and formalization challenges, from rule-tree chaining to nuanced regulatory inference.
Baselines
- Explanation-Refiner (ER): Iterative autoformalization with theorem-prover guidance (originally for NLI).
- Direct SMT Baseline (DSB): FOL translation with type-aware step decomposition, consistency/entailment checks.
- VeriCoT-NoPrem: Verification only—omits explicit premise generation.
Verification Metrics
Core metrics include:
- Verification Pass Rate: Proportion of CoTs fully validated.
- Verifier Precision: Rate of correctness among validated CoTs.
- Verified Correct Answer Rate (VCAR): End-to-end metric blending pass rate and correctness.
- Task Accuracy: Raw label-level correctness.
VeriCoT achieves the highest pass rates and VCAR in all benchmarks, notably surpassing task accuracy in verifier precision—a strong empirical claim for its reliability as an indicator of genuinely correct reasoning.
Failure Mode Analysis
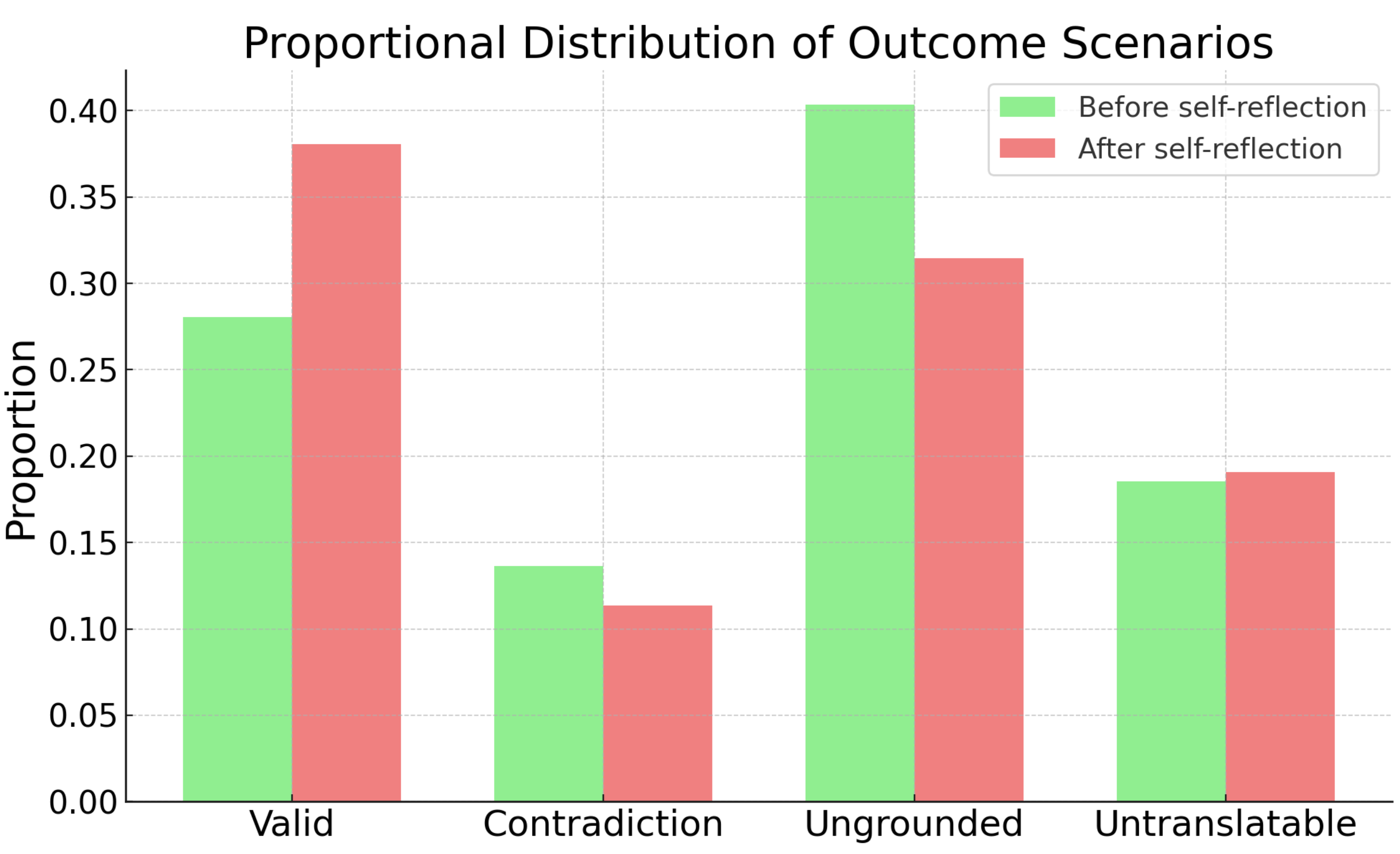
Figure 2: Distribution of verification outcomes: “Valid”, “Ungrounded”, “Contradiction”, and “Untranslatable”, before/after self-reflection. Self-reflection via VeriCoT reduces error rates, especially “Ungrounded” and “Contradiction”.
Fine-grained failure breakdown demonstrates that most errors arise from ungrounded steps owing to over-claimed, unsupported NL reasoning. The introduction of inference-time self-reflection (revising reasoning based on error diagnostics) yields substantial gains across metrics, with up to 46% relative improvements in pass rate and 41% relative gains in verified task outcomes.
Premise Quality
Detailed LLMaj analysis shows that contextual and commonsense premises are robustly grounded and deemed acceptable, with “necessary” commonsense premises also presenting high acceptability scores, documenting the effectiveness of VeriCoT in sourcing and formalizing dependencies.
Model Enhancement via VeriCoT Signals
Inference-Time Self-Reflection
Upon verification failures, models are prompted to self-correct by revisiting and revising flawed CoT steps, informed by detailed logical error signals and structured premise lists. This recursive process “denoises” reasoning and leads to consistently higher rates of verifiable and correct CoT traces.
Supervised Fine-Tuning (SFT)
The system curates high-fidelity reasoning datasets by filtering for CoTs passing both symbolic verification and premise acceptability (LLMaj). Models fine-tuned on these verified CoTs outperform those trained on random traces, particularly when gold answers are unavailable, establishing VeriCoT verification as a potent supervision signal.
Preference Fine-Tuning (DPO)
Stepwise verification signals are repurposed as rewards in Direct Preference Optimization (DPO), facilitating fine-grained correction of reasoning. Empirically, this yields significant improvements (e.g., >18% relative verification pass rate gain, >17% VCAR improvement), guiding the model to prioritize more logically sound reasoning sequences.
Limitations
Core constraints of the system arise from the reliance on LLMs for autoformalization/premise inference, leading to latent translation errors or ungrounded premises when NL steps fall outside supported FOL/SMT-LIB fragments. Thus, ultimate correctness hinges on the representational and translational capacities of underlying LLMs.
Theoretical and Practical Implications
VeriCoT offers a modular neuro-symbolic system architecture capable of procedural stepwise validation across diverse NL reasoning domains. The approach elevates the standard for model transparency, surface-level faithfulness, and actionable error analysis—critical for domains where reasoning validity outweighs mere final-answer correctness. The pipeline demonstrates effective feedback loops for inference-time correction, training signal distillation, and fine-tuning via structured logical supervision.
Future Directions
Immediate research opportunities emerge in expanding supported fragments of formal logic (beyond SMT-LIB FOL), improving LLM translation robustness via structured prompts or hybrid symbolic-LLM models, and integrating VeriCoT-style solvers with user-in-the-loop deployment scenarios. Additionally, addressing the limits of premise attribution in open-world contexts and investigating transferability across languages and regulatory frameworks remain key challenges. Scaling the system for interactive systems or high-throughput deployment in legal/biomedical QA is also viable.
Conclusion
VeriCoT establishes a coherent, solver-integrated framework for validating and improving LLM-generated CoT reasoning by combining state-of-the-art neuro-symbolic translation, premise sourcing, and logical verification. Its capability to surface ungrounded, inconsistent, or non-formalizable reasoning steps, high precision in verifying correctness, and enhancement of downstream LLM reasoning performance through explicit signals positions it as a robust and scalable approach for both research and deployment contexts in distant-from-code/math NL domains.