Radiology's Last Exam (RadLE): Benchmarking Frontier Multimodal AI Against Human Experts and a Taxonomy of Visual Reasoning Errors in Radiology (2509.25559v1)
Abstract: Generalist multimodal AI systems such as LLMs and vision LLMs (VLMs) are increasingly accessed by clinicians and patients alike for medical image interpretation through widely available consumer-facing chatbots. Most evaluations claiming expert level performance are on public datasets containing common pathologies. Rigorous evaluation of frontier models on difficult diagnostic cases remains limited. We developed a pilot benchmark of 50 expert-level "spot diagnosis" cases across multiple imaging modalities to evaluate the performance of frontier AI models against board-certified radiologists and radiology trainees. To mirror real-world usage, the reasoning modes of five popular frontier AI models were tested through their native web interfaces, viz. OpenAI o3, OpenAI GPT-5, Gemini 2.5 Pro, Grok-4, and Claude Opus 4.1. Accuracy was scored by blinded experts, and reproducibility was assessed across three independent runs. GPT-5 was additionally evaluated across various reasoning modes. Reasoning quality errors were assessed and a taxonomy of visual reasoning errors was defined. Board-certified radiologists achieved the highest diagnostic accuracy (83%), outperforming trainees (45%) and all AI models (best performance shown by GPT-5: 30%). Reliability was substantial for GPT-5 and o3, moderate for Gemini 2.5 Pro and Grok-4, and poor for Claude Opus 4.1. These findings demonstrate that advanced frontier models fall far short of radiologists in challenging diagnostic cases. Our benchmark highlights the present limitations of generalist AI in medical imaging and cautions against unsupervised clinical use. We also provide a qualitative analysis of reasoning traces and propose a practical taxonomy of visual reasoning errors by AI models for better understanding their failure modes, informing evaluation standards and guiding more robust model development.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: Can today’s advanced AI chatbots correctly read tricky medical images like expert radiologists can? To find out, the authors created a tough “final exam” for radiology called Radiology’s Last Exam (RadLE). They tested several popular AI models on 50 challenging cases (like unusual X-rays, CTs, and MRIs) and compared their answers to those of human experts and trainees.
The main takeaway: Even the best AI models did much worse than real radiologists on hard, real-world cases. The authors also analyzed the types of mistakes AI makes and suggested ways to evaluate and improve these systems.
Key Objectives (in simple terms)
The paper set out to:
- See how well top AI chatbots can diagnose tough medical images compared to human radiologists and trainees.
- Test AI “reasoning” modes (when the AI spends more time “thinking”) to see if that actually helps.
- Check how consistent AI answers are if you run the same case multiple times.
- Carefully paper the AI’s mistakes and organize them into a clear list (a “taxonomy”) of common error types.
Methods (how they did it, explained simply)
Think of RadLE like a tough quiz:
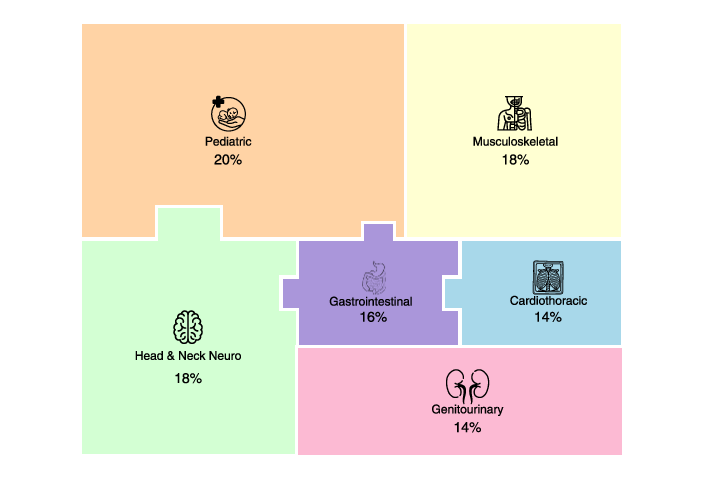
- The team collected 50 hard “spot diagnosis” cases (each case is a single image where you must name the one correct disease).
- These cases covered different imaging types (X-ray, CT, MRI) and body systems (like brain, chest, bones, kids’ cases).
- Four expert radiologists and four radiology trainees took the quiz.
- Five advanced AI models also took the quiz: OpenAI o3, OpenAI GPT-5, Gemini 2.5 Pro, Grok-4, and Claude Opus 4.1. The AI models were tested through their normal web apps, like a user would.
How answers were graded:
- Exact match = 1.0 point
- Partly right (close, but not the exact diagnosis) = 0.5 point
- Wrong = 0 points
They also:
- Ran each AI model three times on the same cases to see if it gives consistent answers.
- Tried different “effort” levels for GPT-5 through its programming API: low, medium, and high effort (like short thinking vs long thinking).
- Measured how long the AI took to answer (latency) and whether taking longer led to better accuracy.
Explaining key terms:
- “Benchmark”: A tough, standardized test to compare performance.
- “Spot diagnosis”: You get one image and must give one final, specific diagnosis.
- “Modality”: The type of scan (X-ray, CT, MRI).
- “Reasoning mode”: When the AI is set to spend more time and steps thinking through the problem.
Main Findings (what they discovered and why it matters)
The authors describe the results clearly: human experts are still far ahead of AI on hard medical images.
- Human performance:
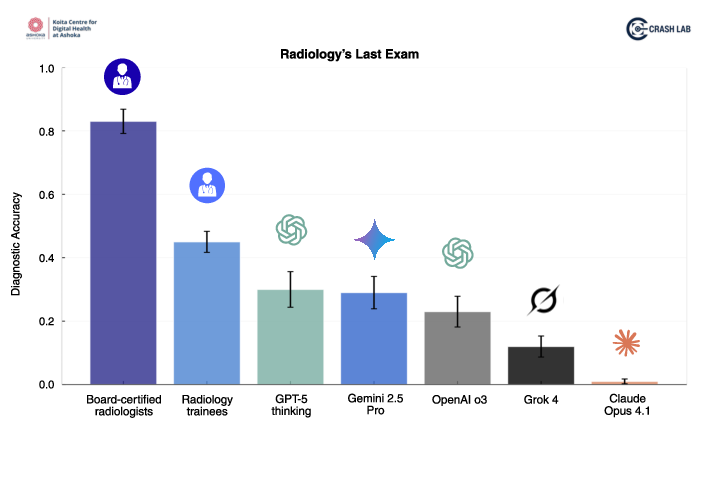
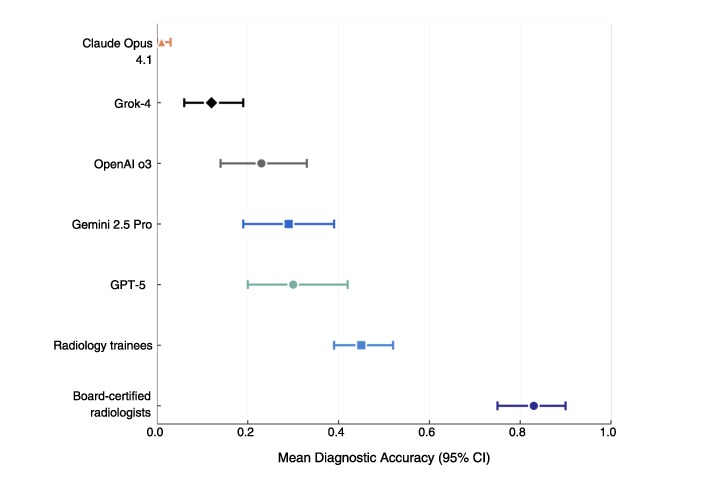
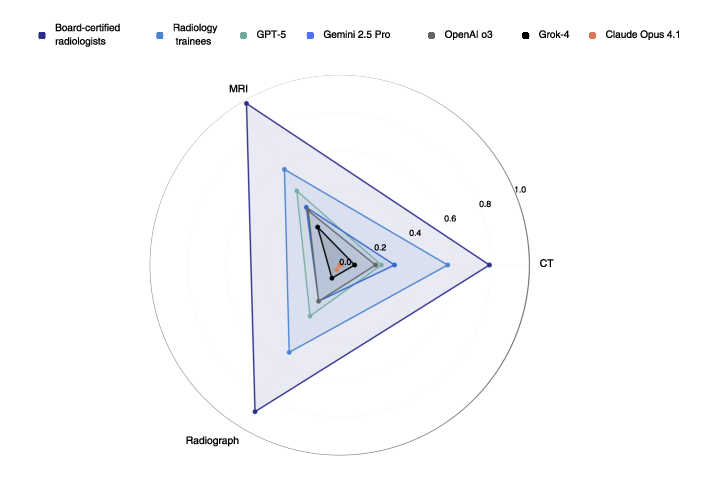
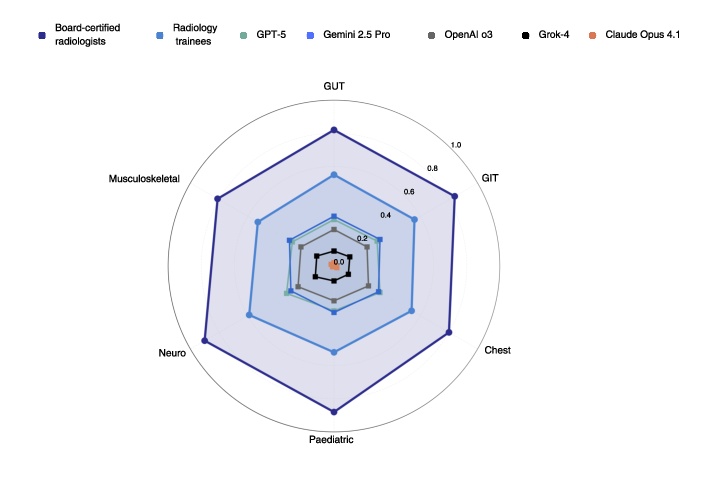
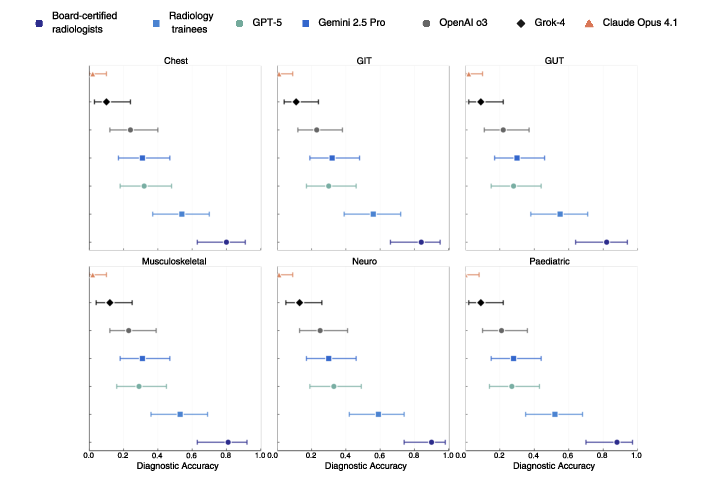
- Expert radiologists: about 83% correct
- Trainees: about 45% correct
- AI performance (best to worst):
- GPT-5: about 30% correct
- Gemini 2.5 Pro: about 29%
- OpenAI o3: about 23%
- Grok-4: about 12%
- Claude Opus 4.1: about 1%
Other key findings:
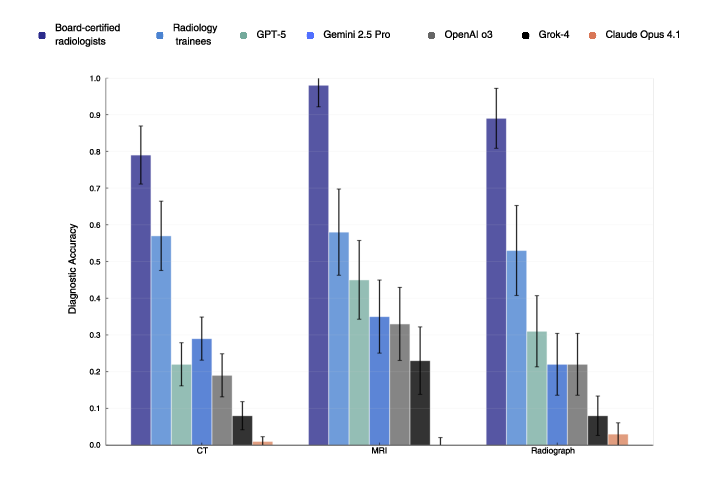
- Differences by scan type:
- AI did best on MRI but still far below experts.
- Radiologists were strong across all types (CT, MRI, X-ray).
- “Reasoning” modes didn’t help much:
- GPT-5’s high-effort mode only improved accuracy by about 1% compared to low effort.
- High-effort answers took about 6 times longer (around 66 seconds vs 10 seconds) without real accuracy gains.
- Consistency:
- GPT-5 and o3 gave more consistent answers across repeated tries than the others, but still not perfect.
- Error patterns:
- The team identified common ways AI goes wrong, like:
- Missing important findings in the image (under-detection).
- Seeing things that aren’t there (over-detection/hallucination).
- Spotting a problem but in the wrong location (mislocalization).
- Linking correct visual clues to the wrong disease (misinterpretation).
- Ending the reasoning too early (premature closure).
- Saying one thing in the details and concluding something different (communication mismatch).
- They also saw familiar thinking traps (biases), like anchoring too early on one idea, focusing on common diagnoses (availability), ignoring parts of the image (inattentional), and being pushed by the prompt format (framing effects).
Why this matters:
- Many AI tools are being used by trainees and even patients to interpret scans.
- On hard, subtle cases—exactly where mistakes are risky—the AI systems fell short.
- The detailed error list helps developers and hospitals understand and fix failure points.
Implications (what this means for the future)
- Don’t use general-purpose AI chatbots as stand-alone radiologists. They are not yet safe or reliable for tough diagnostic cases, especially without human supervision.
- Hospitals and regulators should require tough tests like RadLE, not just easy datasets with common diseases, before approving AI for clinical use.
- Developers should focus on:
- Better detection of subtle image findings.
- Stronger, more stable reasoning tied to medical knowledge.
- More consistent results (so the same input gives the same output).
- Domain-specific models trained and validated for radiology, rather than general chatbots.
- For now, human experts should stay in the loop. AI might help with routine tasks or act as a second reader, but final decisions—especially for tricky cases—should remain with trained radiologists.
In short: This paper shows that today’s advanced AI is impressive, but not ready to replace radiologists on difficult, real-world diagnostic images. The new benchmark and error taxonomy give a roadmap for making future medical AI safer, smarter, and more trustworthy.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
The following list captures what remains missing, uncertain, or unexplored in the paper, framed as concrete and actionable items for future research:
- Dataset scale and representativeness: Expand RadLE beyond 50 cases and include routine, non-challenging cases to assess performance across the full clinical spectrum, not only “upper-limit” spot diagnoses.
- Modalities and subspecialties coverage: Add underrepresented imaging types (ultrasound, mammography, nuclear medicine/PET, angiography, fluoroscopy, echocardiography) and subspecialty tasks (e.g., breast, cardiac, interventional) to test generalization.
- Multi-image and multi-sequence evaluation: Incorporate complete studies (e.g., multi-slice CT volumes, multi-sequence MRI, multi-view radiographs) rather than single images to reflect real-world diagnostic context.
- DICOM fidelity and windowing control: Evaluate models on native DICOM with controlled window/level settings, resolution, and metadata; quantify how compression and format conversions (e.g., PNG/JPEG) affect perceptual accuracy.
- Clinical context integration: Systematically test performance with varying levels of clinical history, lab values, and prior studies to quantify gains from context and identify failure modes specific to context-free inference.
- Ontology-standardized scoring: Replace subjective partial-credit scoring with SNOMED/RadLex/RSNA ontologies, consistent synonym handling, and explicit criteria for “partial correctness”; report inter-rater reliability for scoring decisions.
- Error taxonomy quantification and reliability: Move from qualitative taxonomy to quantitative prevalence and severity of each error type; report inter-rater agreement for error labeling and stratify errors by modality/system/case difficulty.
- Hallucination metrics and localization accuracy: Define and measure hallucination rate and mislocalization frequency with standardized benchmarks (e.g., finding-level precision/recall, IoU for localization) rather than diagnosis-only accuracy.
- Calibration, abstention, and uncertainty: Assess whether models can reliably abstain or express calibrated confidence; measure Brier scores, ECE/MCE, and impact of abstention thresholds on safety.
- Prompt sensitivity and interaction design: Systematically vary prompts (e.g., allowing differentials, multi-turn questioning, tool use) to quantify prompt-induced framing effects and identify safer, more reliable interaction patterns.
- Reasoning-mode transparency across models: Replicate API-based reasoning-effort comparisons for all models (not only GPT-5), with controlled decoding parameters (temperature, top-p), to isolate the effect of “thinking” modes.
- Decoding and determinism controls: Quantify the impact of sampling parameters, deterministic settings, and version drift on accuracy and reliability; establish reproducible configurations and report them alongside results.
- Computational cost and latency benchmarking: Extend latency and resource-use measurements to all models and modes; include monetary costs (API billing), throughput, and clinical workflow acceptability thresholds.
- Specialist vs generalist models: Compare generalist chatbots to domain-specific radiology models (fine-tuned VLMs, dedicated CV models) to identify gaps solvable by specialization and training on medical imaging corpora.
- Human–AI collaboration effects: Evaluate whether AI assistance improves trainee/expert performance (e.g., decision support, triage, second read), including time-to-diagnosis and error reduction.
- Outcome and safety studies: Move beyond accuracy to measure clinical impact (e.g., simulated management decisions, missed critical findings), near-miss frequency, and patient safety implications.
- Dataset transparency and reproducibility: Provide a public subset with anonymized DICOM, clear ground-truth provenance, and evaluation scripts to enable external replication without training contamination (e.g., via controlled access).
- Case selection bias and diversity: Document and mitigate spectrum and institution bias; diversify case sources geographically and demographically, and report demographic attributes where appropriate to paper fairness.
- Adversarial robustness and image quality: Test robustness to artifacts, motion, noise, contrast variations, and adversarial perturbations common in clinical imaging.
- Localization, measurement, and reporting tasks: Extend beyond single best diagnosis to evaluate detection of individual findings, anatomical localization, measurements (e.g., lesion size), and structured report generation quality.
- Longitudinal and temporal generalization: Assess consistency across model version updates, temporal drift, and maintenance of performance over time in consumer-facing platforms.
- Ground-truth adjudication rigor: Report how reference diagnoses were established (e.g., multi-expert adjudication, histopathology, follow-up), and measure inter-expert agreement for ground truths.
- MRI sequence and CT phase specificity: Examine model sensitivity to specific MRI sequences (e.g., T1/T2/FLAIR/DWI) and CT phases (arterial/venous/portal), including the ability to infer phase/sequence from image characteristics.
- Bias analysis and mitigation linkage: Quantify cognitive bias patterns (anchoring, availability) across models and test targeted mitigations (e.g., counterfactual prompts, debiasing training) with pre–post comparisons.
- Abstention triggers and safety guardrails: Explore mechanisms for safe fallback (e.g., “uncertain—refer to radiologist”), define thresholds and policies, and measure their effect on error rates and workflow.
- Generalization across institutions and devices: Evaluate performance across scanners, vendors, acquisition protocols, and sites to establish hardware/protocol robustness.
- Legal/regulatory benchmarking alignment: Map evaluation design to regulatory expectations (FDA/CE/RSNA AI safety frameworks), including documentation standards, auditability, and post-market surveillance plans.
- Training contamination checks: Beyond reverse image search, implement stronger provenance checks (hash matching, private datasets) to rule out memorization and leakage, and report the methodology.
- Frequency and impact of specific failure modes: Identify high-risk errors (e.g., missed life-threatening findings) and prioritize mitigation; weight errors by clinical severity rather than treating all misclassifications equally.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s benchmark (RadLE v1), evaluation methods, privacy practices, and error taxonomy to improve safety, education, governance, and product quality.
- Healthcare (Hospital AI governance) — Use RadLE-like “complex-case” benchmarks to gate the use of generalist multimodal AI in radiology
- Tools/workflows: Internal benchmarking harness; model cards including accuracy on high-complexity cases; reproducibility metrics (kappa/ICC) and latency budgets
- Assumptions/dependencies: Access to the RadLE submission schema via the authors; clinical governance approval; results generalize to local case mix only with caution
- Healthcare (Clinical policy) — Institute “no unsupervised diagnostic use” policies for consumer chatbot interpretations of medical images
- Tools/workflows: Policy templates for radiology departments; patient-facing disclaimers; oversight procedures for any AI-assisted interpretation
- Assumptions/dependencies: Alignment with local regulations and medico-legal counsel; organizational training and compliance
- Healthcare IT/Security — Adopt the paper’s privacy practices when clinicians interact with public AI interfaces (disable data sharing, use temporary sessions, delete histories)
- Tools/workflows: Privacy checklist; configuration playbooks for web-based AI tools used in hospitals
- Assumptions/dependencies: Clinician adherence; provider transparency about data retention; institutional audit processes
- Software (AI product QA) — Integrate the error taxonomy into QA pipelines to detect common failure modes in model outputs
- Tools/workflows: “LLM output linter” that flags findings–summary discordance; heuristics for under-/over-detection and mislocalization; structured error reporting dashboards
- Assumptions/dependencies: Access to reasoning traces or intermediate outputs; modest engineering to implement rule-based checks
- Software/MLOps (Evaluation engineering) — Track reproducibility and latency as first-class SLOs for clinical AI features
- Tools/workflows: Automated kappa/ICC computation across repeated runs; latency monitoring per “reasoning effort”; alerting when variability exceeds thresholds
- Assumptions/dependencies: Stable model versioning; control over decoding parameters in API mode
- Education (Residency and CME) — Use the error taxonomy and curated complex cases in case conferences and OSCE-style assessments
- Tools/workflows: “RadLE rounds” and failure-mode teaching sessions; bias-awareness drills (anchoring, availability, inattentional, framing)
- Assumptions/dependencies: Access to de-identified images; alignment with program directors; respect for spectrum bias (focus on difficult cases)
- Academia/Startups (External benchmarking) — Submit model outputs to CRASH Lab using the provided schema to obtain blinded scoring on RadLE v1
- Tools/workflows: External benchmarking protocol; comparative performance reports; error-mode breakdowns
- Assumptions/dependencies: NDAs or collaboration agreements; inability to access ground truths; potential delays due to manual expert scoring
- Policy (Health authorities, payers) — Issue advisories that approval and procurement should include high-complexity benchmarks beyond common-pathology datasets
- Tools/workflows: Procurement checklists requiring performance on complex-case sets; model labeling that discloses limitations; minimum reproducibility criteria
- Assumptions/dependencies: Stakeholder buy-in; alignment with existing regulatory pathways; readiness of vendors to supply evidence
- Daily life (Patient safety communications) — Educate patients not to rely on chatbots for scan interpretation and to prioritize expert consultations
- Tools/workflows: Patient FAQ sheets; website banners on portal uploads; safeguards in consumer apps
- Assumptions/dependencies: Communication channels with patients; partnerships with consumer platforms to display warnings
- Software/UX (Prompt hygiene) — Reduce framing effects by revising prompts that force single diagnoses; encourage uncertainty and differential listing in non-exam settings
- Tools/workflows: Prompt templates for clinical decision support; UI toggles for “exploratory differential” vs “single best answer”
- Assumptions/dependencies: Product willingness to reconfigure prompts; clinician preference for richer outputs in practice
- Healthcare (Operational planning) — Avoid high-effort “reasoning” modes for time-sensitive tasks due to negligible accuracy gains and large latency costs
- Tools/workflows: Effort/latency profiles documented in model cards; workflow routing rules (e.g., low effort for triage queries)
- Assumptions/dependencies: The measured latency-accuracy trade-off generalizes to current model versions; task-specific performance monitoring
- Finance/Insurance (Risk assessment for AI adoption) — Use benchmark results to set risk premiums or coverage conditions for AI-assisted imaging services
- Tools/workflows: Risk scoring frameworks that incorporate complex-case performance, reproducibility, and latency
- Assumptions/dependencies: Payer access to benchmarking data; actuarial models calibrated to clinical risk
Long-Term Applications
These applications require further research, scaling, dataset expansion, technical development, and/or regulatory alignment before deployment.
- Healthcare/Software (Specialized radiology models) — Develop fine-tuned, multi-modality radiology VLMs with localization supervision and clinical context integration
- Tools/products: Radiology-specific VLM++ with anatomy-aware attention, multi-view fusion, and structured outputs (findings, localization, confidence)
- Assumptions/dependencies: Expert-annotated datasets; regulatory clearance; significant compute; robust data governance
- Software/ML Research (Taxonomy-aware training) — Encode the error taxonomy into training objectives and evaluation criteria to reduce perceptual and interpretive failures
- Tools/products: Loss functions penalizing mislocalization/discordance; self-consistency checks; adversarial curricula targeting under-/over-detection
- Assumptions/dependencies: Access to reasoning traces; algorithmic advances that connect textual “reasoning” with visual grounding
- Healthcare (Bias guardrails in PACS/RIS) — Deploy “cognitive bias checkers” that nudge clinicians and AI away from anchoring, availability, and inattentional blind spots
- Tools/products: Bias-aware decision support plug-ins with checklists and counterfactual prompts; selective surfacing of alternative patterns
- Assumptions/dependencies: Human factors validation; seamless workflow integration; acceptance by radiologists
- Policy/Regulation (Complex-case benchmarks in approvals) — Require validated, high-complexity diagnostic benchmarks and reproducibility metrics for market authorization
- Tools/products: Regulatory benchmark registries; model cards with complex-case accuracy, kappa/ICC, latency distributions; post-market surveillance plans
- Assumptions/dependencies: Harmonization across agencies (e.g., FDA, CDSCO, EMA); participation by vendors and independent labs
- Academia (Global RadLE expansion) — Build a larger, multi-institutional complex-case dataset with public subsets, standardized ontology, and open evaluation servers
- Tools/products: RadLE Challenge and leaderboard; shared scoring APIs; consensus ontology for partial credit and exact matches
- Assumptions/dependencies: Funding; IRB approvals; international data-sharing agreements; contamination safeguards
- Education (Simulation platforms) — Create interactive training environments where residents learn to anticipate and correct AI failure modes and cognitive biases
- Tools/products: Simulation labs with scenario generators; mixed human–AI reading challenges; feedback on taxonomy-linked errors
- Assumptions/dependencies: Curriculum design; collaboration between educators and ML teams; longitudinal assessment
- Software (Consistency and determinism engineering) — Innovate decoding and reasoning architectures that improve output reproducibility for identical inputs
- Tools/products: Deterministic inference modes; stability-enhanced sampling; ensemble self-consistency with localization verification
- Assumptions/dependencies: Advances in inference algorithms; trade-offs with diversity/creativity managed for medical use
- Healthcare (Report consistency auditor at scale) — Integrate NLP auditors into dictation systems to automatically catch findings–summary discordance across reports
- Tools/products: Real-time “consistency checks” in radiology reporting; cross-sentence contradiction detectors; clinician feedback loops
- Assumptions/dependencies: High-precision NLP tuned for medical language; acceptance and minimal alert fatigue
- Software/Operations (Latency-aware scheduling) — Build schedulers that adapt “reasoning effort” to clinical priority, cost constraints, and task type
- Tools/products: Dynamic effort controllers; SLAs that balance turnaround time and accuracy; cost-aware routing
- Assumptions/dependencies: Reliable latency profiles across model versions; orchestration integration with clinical IT
- Policy/Legal (Liability frameworks) — Define accountability and safe-harbor provisions for AI-assisted imaging, including disclosure, human-in-the-loop requirements, and audit trails
- Tools/products: Legal templates; auditability standards for consumer platforms; incident reporting procedures
- Assumptions/dependencies: Legislative action; stakeholder consensus; alignment with malpractice insurers
- Finance (Value-based AI procurement) — Tie reimbursement or purchasing decisions to performance on complex-case benchmarks and post-deployment consistency metrics
- Tools/products: Contracts with performance clauses; pay-for-performance models; risk-sharing agreements
- Assumptions/dependencies: Transparent evidence; ongoing independent evaluations; payer/provider collaboration
- Consumer Health (Safe triage bots for imaging) — Replace image “interpretation” in consumer apps with triage pathways that guide users to appropriate clinical care
- Tools/products: Non-diagnostic triage assistants; appointment scheduling; urgency education based on symptoms (not image uploads)
- Assumptions/dependencies: Integration with provider networks; clear UX that avoids diagnostic claims; regulatory guidance on scope
Cross-cutting assumptions and dependencies
- Results are based on a deliberately challenging, spectrum-biased 50-case benchmark and may not generalize to routine cases.
- Frontier model performance and latency characteristics can change rapidly with version updates; continuous re-benchmarking is required.
- RadLE v1 ground truths are withheld to avoid model contamination; external benchmarking relies on collaboration with the authors.
- Integration into clinical environments requires regulatory clearance, robust data governance, and clinician acceptance.
- Error taxonomy and evaluation protocols benefit from further validation on larger datasets and multi-institutional studies.
Glossary
- Acromioclavicular dislocation: Separation of the acromioclavicular joint between the clavicle and acromion, often seen on shoulder imaging. "In a case of acromioclavicular dislocation, GPT-5 attempted to ascertain the relationship between the distal clavicle and acromion, and successfully identified clavicular elevation."
- Adrenal hematoma: Hemorrhage within the adrenal gland, typically due to trauma or coagulopathy. "- Adrenal hematoma"
- Anchoring bias: A cognitive bias where early hypotheses unduly influence subsequent reasoning and interpretation. "Confirmation bias / anchoring bias was observed as early fixation on initial diagnostic hypotheses"
- Autosomal Dominant Polycystic Kidney Disease: A hereditary disorder characterized by numerous renal cysts and progressive kidney enlargement. "Autosomal Dominant Polycystic Kidney Disease."
- Availability bias: Over-reliance on familiar or frequently seen diagnoses, leading to skewed interpretation. "Availability bias manifested as apparent overweighting of diagnoses potentially over-represented in training data."
- Board-certified radiologists: Radiologists who have passed professional board examinations and hold certification. "Board-certified radiologists achieved the highest diagnostic accuracy (83%)"
- Calcaneonavicular coalition: Abnormal fusion between the calcaneus and navicular bones in the foot, limiting motion and causing pain. "both talocalcaneal and calcaneonavicular coalitions"
- Cardiothoracic ratio: The ratio of heart width to chest width on a frontal chest radiograph, used to assess cardiac enlargement. "slender heart with a low cardiothoracic ratio"
- Central Pontine Myelinolysis: Demyelination of the central pons commonly associated with rapid correction of hyponatremia. "concluded Central Pontine Myelinolysis"
- CheXpert: A large-scale chest X-ray dataset with labeled pathologies used for machine learning benchmarking. "such as CheXpert or MIMIC-CXR"
- Cognitive bias modifiers: Factors that shape or influence the manifestation of diagnostic reasoning errors. "Cognitive bias modifiers"
- Computed Tomography (CT): Cross-sectional imaging modality using X-rays and computer reconstruction. "Computed Tomography (CT)"
- Confirmation bias: Tendency to favor information that confirms preexisting beliefs or hypotheses. "Confirmation bias / anchoring bias was observed"
- Developmental dysplasia of the hip: Abnormal development of the hip joint resulting in instability or dislocation. "finally concluded it as developmental dysplasia of the hip."
- Findingsâsummary discordance: Inconsistency where described observations conflict with the final diagnosis. "Findingsâsummary discordance identifies internal inconsistencies within reasoning traces"
- Framing effects: Changes in decisions and interpretations caused by how information or prompts are presented. "Framing effects occurred when prompt structure appeared to bias interpretation toward specific diagnostic categories."
- Friedman rank test: A non-parametric statistical test comparing differences across multiple related groups. "Friedman rank test."
- Holm adjustment: A stepwise multiple comparison correction method controlling family-wise error rate. "Wilcoxon signed-rank tests with Holm adjustment."
- Hydatid cyst: Parasitic cyst (Echinococcus) that can occur in organs, including rare cardiac involvement. "a right atrium hydatid cyst"
- ICC(2,1) (Intraclass correlation coefficient): A reliability metric for agreement among measurements using a two-way random-effects model, single measurement. "intraclass correlation coefficients [ICC(2,1)]"
- Inattentional bias: Missing relevant findings due to attentional focus elsewhere. "Inattentional bias presented as neglect of relevant anatomical regions or findings"
- IVU (intravenous urogram): Contrast-enhanced radiographic exam of the urinary tract to visualize kidneys, ureters, and bladder. "on IVU despite its clear visibility"
- Joubert's syndrome: A congenital disorder with characteristic midbrain–hindbrain malformations and the molar tooth sign. "In one case of Joubert's syndrome, GPT-5 concluded Central Pontine Myelinolysis"
- Kendall's W: A coefficient of concordance assessing agreement among rankings. "Kendall's W = 0.56 (large effect size)."
- lme4 package: An R package for fitting linear and generalized linear mixed-effects models. "lme4 package for mixed-effects modeling"
- Magnetic Resonance Imaging (MRI): Imaging modality using magnetic fields and radiofrequency to generate detailed soft-tissue images. "Magnetic Resonance Imaging (MRI)"
- Mediastinum: Central compartment of the thoracic cavity containing the heart, great vessels, trachea, and esophagus. "a cystic lesion within the mediastinum"
- MIMIC-CXR: A large public chest radiograph dataset with labels and associated clinical data. "such as CheXpert or MIMIC-CXR"
- Misinterpretation (misattribution): Correct visual finding identified but linked to the wrong diagnosis or mechanism. "Misinterpretation or misattribution of findings occurs when visual patterns are correctly identified but incorrectly linked to pathophysiological processes"
- Mislocalization: Correct pattern recognition but incorrect anatomical site, side, or compartment. "Mislocalization represents correct identification of pathological patterns but incorrect spatial attribution"
- Mixed-effects modeling: Statistical models incorporating both fixed and random effects to account for hierarchical or repeated measures data. "lme4 package for mixed-effects modeling"
- Non-parametric tests: Statistical methods that do not assume a specific distribution of the data. "Base functions for non-parametric tests"
- Over-detection: Reporting findings not supported by image evidence, often reflecting hallucination. "Over-detection captures confident identification of pathological findings not visually supported by the image evidence"
- Portal Hypertension: Elevated pressure in the portal venous system, commonly due to liver cirrhosis, with collateral formation. "In a case of Portal Hypertension with esophageal varices, shrunken liver and splenomegaly"
- Premature diagnostic closure: Ending diagnostic reasoning too early, failing to consider reasonable alternatives. "Incomplete reasoning or premature diagnostic closure captures instances where initial diagnostic impressions are accepted without adequate consideration of alternatives"
- Proximal femoral deficiency: Congenital absence or hypoplasia of the proximal femur. "features of proximal femoral deficiency"
- Pulmonary arteriovenous malformation: Abnormal direct connections between pulmonary arteries and veins, risking hypoxemia and paradoxical emboli. "with diagnosis varying from pulmonary arteriovenous malformation, Scimitar syndrome etc.,"
- Quadratic-weighted kappa: Agreement measure weighting disagreements by their squared distance, used for ordinal ratings. "Quadratic-weighted kappa coefficients were calculated for every pair of runs"
- Radiograph (X-ray): Two-dimensional projection imaging using ionizing radiation. "Radiograph (X-ray)"
- Radiology trainees: Resident physicians in training to become radiologists. "Radiology trainees followed with 45\% accuracy"
- RSNA Case of the Day: Radiology teaching and assessment cases curated by the Radiological Society of North America. "RSNA Case of the Day challenges"
- Scimitar syndrome: Congenital cardiopulmonary anomaly with anomalous pulmonary venous return to the IVC. "pulmonary arteriovenous malformation, Scimitar syndrome etc.,"
- Segond fracture: Avulsion fracture of the anterolateral tibial plateau, often associated with ACL injury. "- Segond fracture"
- Spectrum bias: Bias arising when a paper sample over-represents certain case complexities or severities, affecting performance estimates. "Spectrum Bias Considerations"
- Talocalcaneal coalition: Abnormal fusion between the talus and calcaneus bones of the hindfoot. "both talocalcaneal and calcaneonavicular coalitions"
- Tarsal coalition: Congenital fusion of two or more tarsal bones, limiting foot motion and causing pain. "In a case of tarsal coalition which included both talocalcaneal and calcaneonavicular coalitions"
- Under-detection: Failure to identify visible findings present in the image. "Under-detection occurs when reasoning traces fail to identify or describe visible pathological findings"
- Ureterocele: Cystic dilation of the distal ureter protruding into the bladder lumen. "left ureterocele"
- Vision LLMs (VLMs): AI models that jointly process and reason over visual and textual inputs. "vision LLMs (VLMs) are increasingly accessed by clinicians and patients alike for medical image interpretation"
- Von Hippel-Lindau syndrome: Hereditary tumor syndrome with hemangioblastomas and visceral cysts/tumors. "- Von Hippel-Lindau syndrome"
- Wilcoxon signed-rank tests: Paired non-parametric test for comparing median differences across matched samples. "Wilcoxon signed-rank tests with Holm adjustment."
- Wilson 95% confidence intervals: Binomial proportion confidence intervals using the Wilson score method. "Wilson 95\% confidence intervals."
Collections
Sign up for free to add this paper to one or more collections.

