- The paper presents a novel MedCEG framework that uses critical evidence graphs to enforce structured and verifiable clinical reasoning in LLMs.
- It combines cold-start graph-linearized supervision with CEG-guided reinforcement learning, improving diagnostic accuracy and logical coherence.
- The method outperforms baselines on key reasoning metrics, ensuring transparent and evidence-driven clinical decision-making.
Reinforcing Verifiable Clinical Reasoning in LLMs with Critical Evidence Graphs
Motivation and Problem Statement
The clinical deployment of LLMs demands not only performant, but also transparent and logically rigorous reasoning processes to engender practitioner trust and regulatory acceptance. Current RL paradigms for model alignment—particularly those relying on outcome-centric rewards—encourage shortcut solutions, wherein models optimize for answer accuracy while eliding the logical rigor essential for real-world clinical applications. These flaws manifest as superficial or circular explanations, deficient causal linkage, and reasoning chains that are unfit for evidence-based practice. "MedCEG: Reinforcing Verifiable Medical Reasoning with Critical Evidence Graph" (2512.13510) addresses this deficit by introducing a framework for explicit, verifiable alignment of reasoning pathways via graph supervision, specifically focusing on the Critical Evidence Graph (CEG) as the primary reward source.

Figure 1: Comparison between a flawed, superficial reasoning process and a structured, evidence-driven pathway guided by the Critical Evidence Graph (CEG).
MedCEG introduces a curated corpus of 10,000 challenging clinical cases, selected via ensemble-based filtering across MedQA, MedCaseReasoning, and JAMA Challenge datasets. Gemini-2.5-Pro is used under a rejection sampling protocol to generate rationale/answer triplets, ensuring only instances requiring robust multi-step clinical reasoning remain.
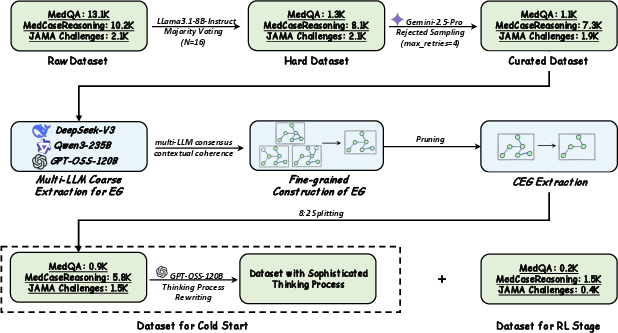
Figure 2: Detailed Construction Pipeline of Training Data.
The Evidence Graph (EG) abstraction is constructed for each instance by extracting subject-predicate-object triplets using a committee of LLMs with high inter-model agreement, yielding robust, normalized reasoning graphs—each edge structurally and semantically vetted. A subsequent semantic and topological refinement yields the CEG: a parsimonious, backward-traced, and transitively-reduced subgraph from the EG, focused on precisely those entities and relations indispensable for the final diagnosis. This process ensures coverage of all causal dependencies and eliminates inferential shortcuts.
Learning Framework: Progressive Graph-Supervised Policy Optimization
Cold-Start Pretraining with Graph-Linearized Supervision
The initial model bootstrapping phase ("Cold-Start") involves supervised fine-tuning on text sequences linearized from EGs. This step instills explicit, stepwise reasoning competence as the model learns to generate rationales faithful to the underlying graph structure, ensuring that base-level clinical arguments are both structured and comprehensive.
CEG-Guided Reinforcement Learning
For reinforcement, MedCEG replaces outcome-dominated reward with a composite Clinical Reasoning Procedure (CRP) reward derived directly from the CEG. The CRP integrates three axes:
- Node Coverage: Quantifies semantic inclusion of all CEG nodes in the model-generated explanation.
- Structural Correctness: Assesses the recall of ground-truth CEG triplets in the extracted graph of the generation.
- Chain Completeness: Measures whether recovered triplets are logically connected in a single, unbroken inferential chain.
This composite reward is combined with final answer correctness and output-format adherence to yield an RL signal. Optimization is performed with Group Relative Policy Optimization (GRPO), allowing efficient and stable policy alignment without value model overhead or preference reward model (PRM) collection, which are barriers for large-scale clinical alignment.
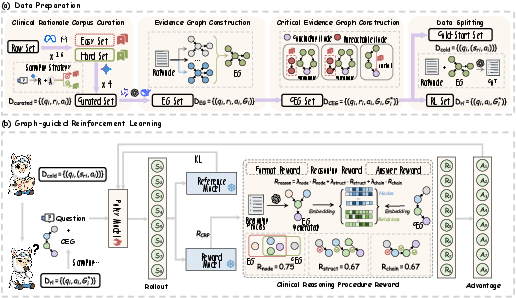
Figure 3: Overview of the MedCEG pipeline. (a) Data curation and graph construction; (b) Two-stage progressive learning with graph-guided RL.
Empirical Evaluation
MedCEG establishes new performance ceilings across all established medical QA and diagnostic reasoning benchmarks.
Final Outcome Metrics
On in-distribution tasks, MedCEG achieves an average accuracy of 58.59%, and on out-of-distribution benchmarks, 64.09%, outperforming the previous best (Huatuo-o1-8B) by +10.29 and +1.68 points, respectively. Notably, in MedCase—an open-ended diagnostic reasoning benchmark requiring free-form justification—MedCEG achieves 31.55% where several competitive methods fail to yield any valid outputs.
Reasoning Quality Assessment
Rather than optimizing solely for answer correctness, MedCEG is explicitly superior on fine-grained reasoning metrics. Across five dimensions (Logical Coherence, Factual Accuracy, Evidence Faithfulness, Interpretability, and Information Utilization), MedCEG yields a composite reasoning score of 8.64, outperforming the best baseline (MedReason-8B) by 9.5%. Human-LMM consistency analysis shows 73.6% reliability between automated and expert scoring, substantiating the chosen evaluation paradigm.
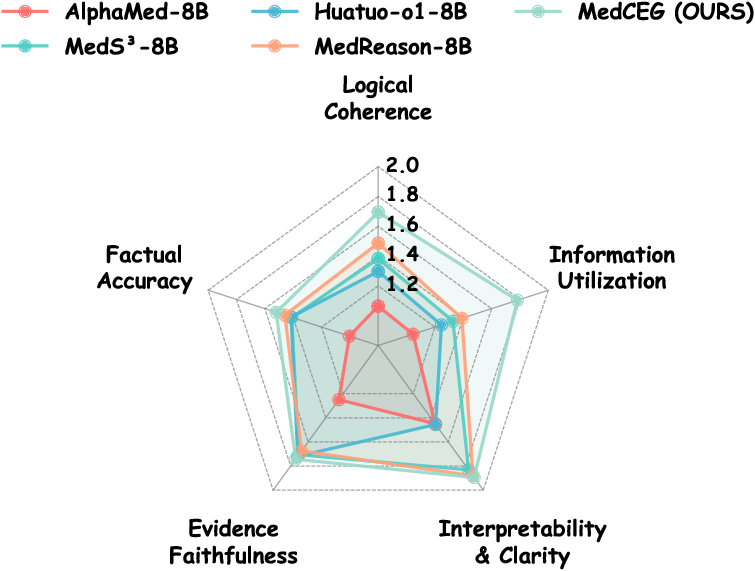
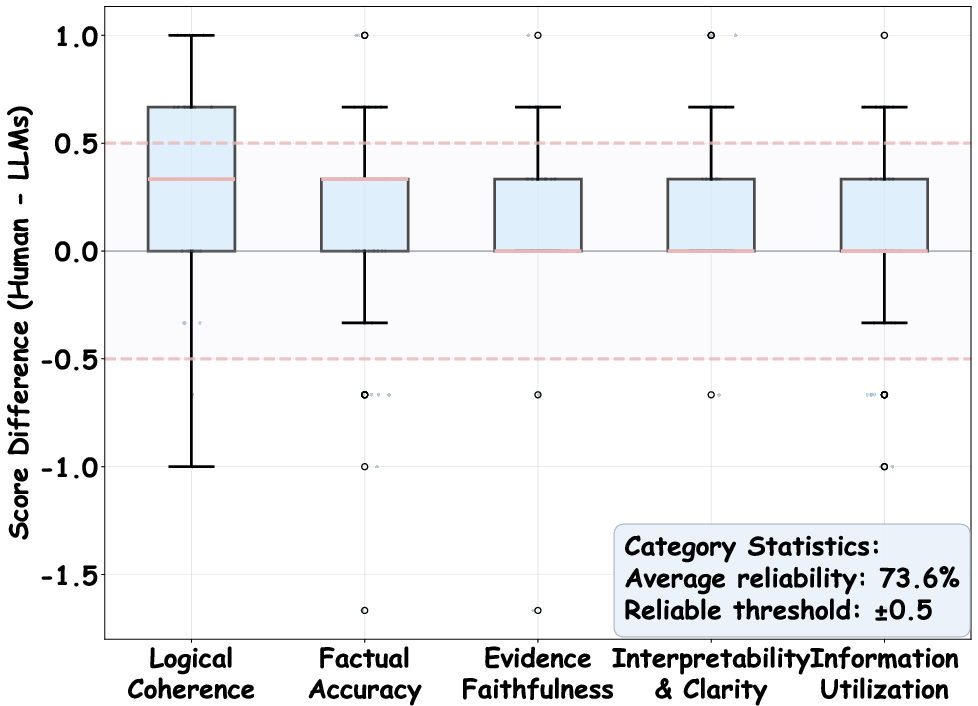
Figure 4: Multi-dimensional evaluation of the reasoning process for MedCEG vs. four baselines.
Qualitative analysis illustrates that MedCEG generates stepwise causal chains that are not only factually sound but also make explicit the pivotal diagnostic cues—especially when contrasted with outcome-oriented RL models, which often regress toward superficial or tautological explanations.
Ablation Analyses
Removal of any CRP reward component (especially Chain Completeness) results in significant accuracy and reasoning quality degradation. Relying exclusively on the EG (over-regularization) or omitting process supervision yields only marginal improvements over SFT and can induce performance collapse. The approach generalizes in effect across foundation models (e.g., Qwen3-4B, 8B).
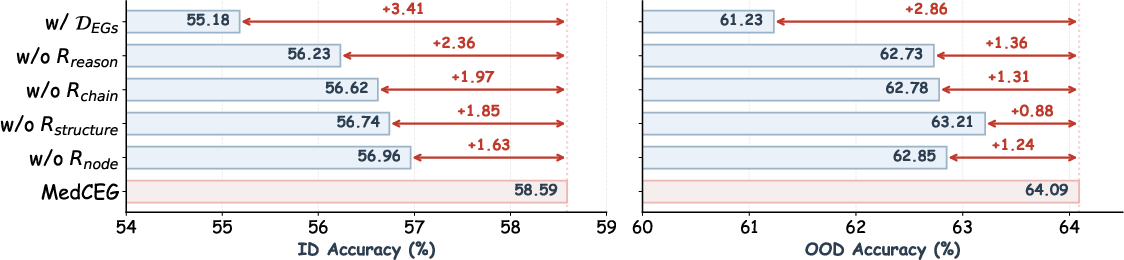
Figure 5: Ablation study of training pipeline and composite reward; substantiating the necessity of each CRP component and the efficacy of CEG over EG supervision.
Theoretical and Practical Implications
By imposing hard graph-structured supervision, MedCEG mitigates shortcut learning, elucidating a new paradigm for RL alignment in high-stakes, logic-intensive domains. The explicit separation of outcome and process rewards ensures both answer fidelity and evidence-grounded reasoning. This framework obviates the need for labor-intensive human feedback, enables scalable expansion, and supplies a collection of verified CEGs for community benchmarking.
Practically, MedCEG enables safer and more explainable clinical AI systems compatible with existing regulatory frameworks. The explicit mapping to causal processes will facilitate downstream auditing and integration into mixed-initiative physician workflows. Theoretically, the CEG paradigm is extensible to other domains where decision processes are compositional and must be verifiable (e.g., scientific discovery, legal reasoning, safety-critical industrial systems).
Conclusions
MedCEG establishes a new direction for model alignment where structured, domain-specific process rewards replace ad hoc, outcome-centric RL objectives. By curating CEGs at scale and integrating them as the central RL reward, MedCEG achieves not only state-of-the-art accuracy across medical NLP benchmarks but—critically—delivers justifications that are logically transparent, evidence-faithful, and structurally correct. The framework marks a substantial step toward verifiable AI reasoning and trustworthy clinical deployment.
Future Directions
Further work is necessary to validate the approach in fully unstructured or heterogeneous clinical environments (e.g., raw EHR data), and to extend graph-based supervision to multi-modal medical decision pipelines. Advances in automated CEG extraction—potentially involving self-improving extraction policies—will also be pivotal for scaling this model alignment paradigm to broader domains and larger deployment contexts.