Accelerating LLM Pre-Training through Flat-Direction Dynamics Enhancement
Abstract: Pre-training LLMs requires immense computational resources, making optimizer efficiency essential. The optimization landscape is highly anisotropic, with loss reduction driven predominantly by progress along flat directions. While matrix-based optimizers such as Muon and SOAP leverage fine-grained curvature information to outperform AdamW, their updates tend toward isotropy -- relatively conservative along flat directions yet potentially aggressive along sharp ones. To address this limitation, we first establish a unified Riemannian Ordinary Differential Equation (ODE) framework that elucidates how common adaptive algorithms operate synergistically: the preconditioner induces a Riemannian geometry that mitigates ill-conditioning, while momentum serves as a Riemannian damping term that promotes convergence. Guided by these insights, we propose LITE, a generalized acceleration strategy that enhances training dynamics by applying larger Hessian damping coefficients and learning rates along flat trajectories. Extensive experiments demonstrate that LITE significantly accelerates both Muon and SOAP across diverse architectures (Dense, MoE), parameter scales (130M--1.3B), datasets (C4, Pile), and learning-rate schedules (cosine, warmup-stable-decay). Theoretical analysis confirms that LITE facilitates faster convergence along flat directions in anisotropic landscapes, providing a principled approach to efficient LLM pre-training. The code is available at https://github.com/SHUCHENZHU/LITE.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making the pre-training of LLMs faster and more efficient. The authors introduce a general add-on method, called LITE, that helps popular training optimizers move more quickly in the parts of the problem where progress really matters, without making training unstable.
What questions are the authors trying to answer?
The authors focus on two simple questions:
- Can we better understand how two common optimizer tools—preconditioning and momentum—work together during training?
- Using that understanding, can we design a way to speed up training by taking bigger, smarter steps where it’s safe (the “flat” directions) and careful steps where it’s risky (the “sharp” directions)?
How did they approach the problem?
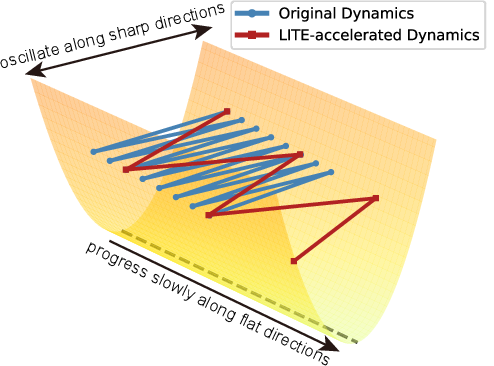
To explain the approach, it helps to picture training like traveling across a landscape.
The terrain analogy: flat vs. sharp directions
- Imagine the loss surface (what the optimizer tries to minimize) as a huge landscape.
- “Sharp directions” are like narrow ridges or steep cliffs—take steps that are too big here and you wobble or fall (training becomes unstable).
- “Flat directions” are like wide, gentle valleys—safe to move faster and farther, but progress can be slow if your steps are tiny.
Many studies suggest that most real progress in reducing loss happens along these flat directions, while sharp directions mostly affect stability.
Preconditioning and momentum in everyday terms
- Momentum: Like pushing a skateboarder—if you keep pushing in the same direction, the board speeds up; if the ground gets bumpy, momentum can cause wobbling. Nesterov-style momentum adds a smart “look-ahead” that reduces wobbling in sharp places.
- Preconditioning: Like changing your shoes to get better grip depending on the ground. A “preconditioner” changes how the optimizer measures and scales steps so it can move more sensibly in different directions.
Simple optimizers such as AdamW adjust each parameter separately (like wearing the same shoes everywhere), which ignores how parameters interact. Newer matrix-based optimizers (like Muon and SOAP) pay attention to these interactions (like wearing terrain-aware shoes), and often train faster. But even these newer methods can end up taking steps that are too similar in size in all directions (too cautious on flat parts, too bold on sharp parts).
Their new plan: LITE
The key idea in LITE is very simple:
- Keep the settings that protect stability in sharp directions.
- Increase the step size and the stabilizing “damping” only along flat directions, where it’s safe and helpful.
- This selectively speeds up the slow-but-important progress in flat areas while keeping the model steady on sharp ridges.
To do this, LITE:
- Uses the optimizer’s own curvature information (from gradients and preconditioners) to estimate which directions are “flat” and which are “sharp.”
- Slightly boosts the learning rate and the “Hessian damping” (a kind of smart friction that reduces oscillations) along flat directions.
- Leaves sharp directions mostly unchanged to avoid instability.
A bit of gentle math modeling (why this makes sense)
The authors also build a “continuous-time” picture of training (a smooth-time movie described by differential equations) on a curved space (a “Riemannian” view). In this picture:
- The preconditioner defines the geometry (how distances and directions are measured), which reduces the problem’s difficulty.
- Momentum acts like direction-aware stabilizing friction.
- This unified view shows how the two work together and explains why turning up the speed and damping in flat directions makes training faster without breaking stability.
What did they find?
The authors tested LITE as an add-on to two strong matrix-based optimizers, Muon and SOAP, across many realistic settings:
- Model types: Dense LLaMA-style models and Mixture-of-Experts (MoE) models
- Model sizes: From about 130 million to 1.3 billion parameters
- Datasets: C4 and The Pile
- Learning rate schedules: Cosine and warmup–stable–decay
What happened:
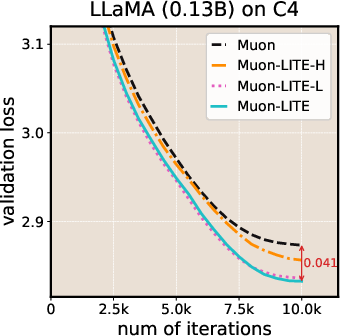
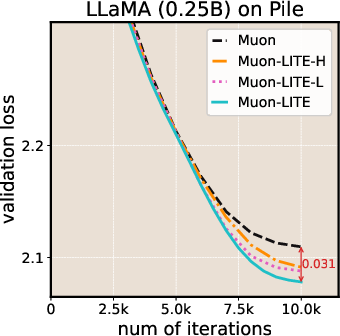
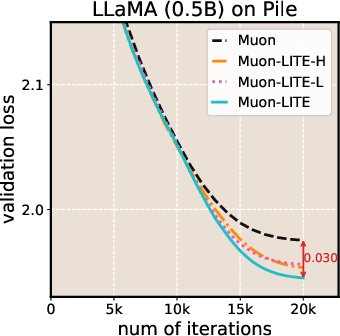
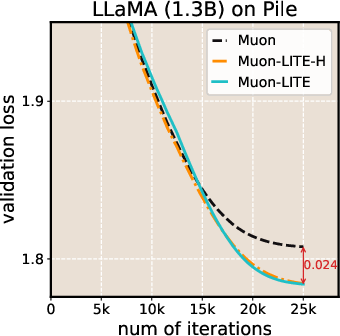
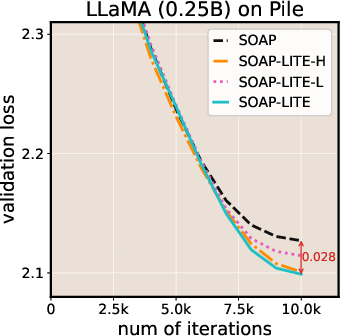
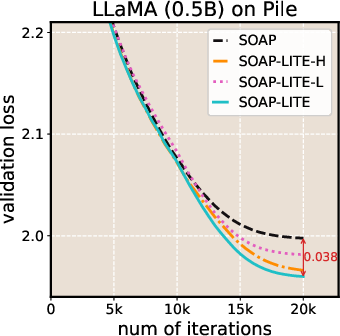
- LITE consistently lowered the final training loss compared to the original Muon and SOAP.
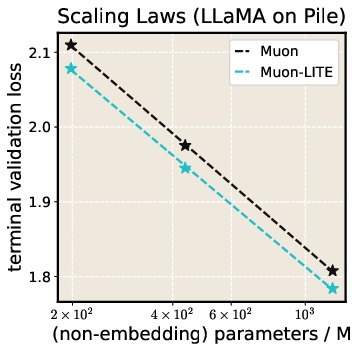
- It showed better “scaling laws,” meaning its advantages held up as models and data got larger.
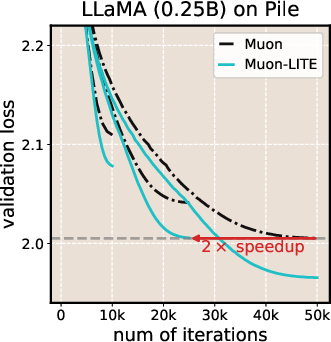
- Over longer training runs, LITE achieved up to about 2× speedup compared to Muon, meaning it reached the same loss in roughly half the steps in those settings.
- An ablation (turning parts on and off) showed that boosting both learning rate and damping specifically in flat directions works best. Doing the same boost in sharp directions hurts performance, confirming the “be fast only where it’s safe” idea.
They also provide theory showing that, in landscapes like those seen in deep learning, LITE speeds up progress in the flat directions that matter most for lowering the loss.
Why does this matter?
Training LLMs is extremely expensive and time-consuming. If we can reach the same quality with fewer steps or less compute:
- Researchers and companies save time and money.
- It becomes easier to train and iterate on large models.
- The environmental footprint can be reduced.
- New ideas can be tested faster, speeding up progress for the entire field.
In short, LITE offers a practical, principled way to make strong optimizers even better by focusing speed where it helps most.
Takeaway
- The paper offers a unified way to understand how preconditioners and momentum work together.
- It introduces LITE, a simple, general strategy that accelerates training by taking bigger, smarter steps along safe, flat directions and keeping careful behavior in sharp ones.
- LITE speeds up leading optimizers (Muon and SOAP) across many LLM setups, with both experimental and theoretical support.
- This could make high-quality LLM training faster, cheaper, and more sustainable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes concrete gaps and unresolved questions that future researchers could address to strengthen, generalize, or validate the paper’s claims.
- Missing wall‑clock efficiency accounting
- Quantify end‑to‑end speedup including per‑step overhead of estimating
P_k/Q_k, soft masks, and matrix operations (e.g., NS iterations). Report throughput (tokens/sec), memory footprint, and FLOPs per step across hardware (GPU/TPU) and distributed setups. - Provide systems benchmarks showing whether the reported “2× speedup in long‑horizon training” persists after accounting for LITE’s extra compute and communication costs.
- Quantify end‑to‑end speedup including per‑step overhead of estimating
- Limited scale and scope of empirical validation
- Extend experiments beyond 1.3B parameters to 7B–70B scale and longer token budgets (>200× params), where curvature estimates, stability, and distributed systems bottlenecks differ substantially.
- Evaluate across a broader set of architectures (e.g., Transformer variants with different norms/activations, deep MLPs, vision transformers, multimodal encoders/decoders) to test generality beyond LLaMA/QwenMoE.
- Include multilingual corpora and domain‑specific datasets (code, scientific text) to probe sensitivity to gradient noise and anisotropy patterns that vary by domain.
- Baseline and fairness concerns in comparisons
- Re‑tune Muon/SOAP baselines per size and dataset (rather than reusing hyperparameters tuned at 0.25B) to ensure fair comparisons; report full search spaces and selection criteria.
- Compare against strong non‑matrix baselines (AdamW/Lion/AdEMAMix/N‑AdamW) under matched schedules and regularizations (weight decay, clip norms), as LITE claims generality to adaptive optimizers.
- Unvalidated assumptions about curvature alignment
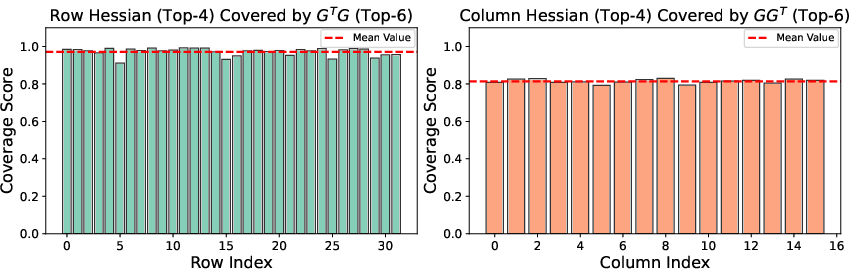
- The core assumption that preconditioners (Shampoo‑like Fisher square root) and Hessian share top eigenspaces is only probed in a toy LLaMA block. Systematically measure subspace alignment across layers, training stages, model sizes, and datasets; quantify misalignment effects on LITE’s masking and updates.
- Sensitivity and adaptivity of hyperparameters
- Provide principled or adaptive rules to choose
d_s(sharp subspace dimension),χ,β_1,β_2, and mask softness across layers/steps. Explore automated tuning via curvature statistics, target damping spectra, or meta‑learning. - Study robustness to misclassification of sharp/flat directions and to rapidly changing curvature; quantify failure modes and recovery strategies.
- Provide principled or adaptive rules to choose
- Treatment of stochasticity and nonconvexity in theory
- The RISHD/river‑valley analysis ignores mini‑batch noise and assumes analytic
f, shared eigen‑bases, monotone LR (\dot{η}_t ≤ 0), and trajectory conservation in an open setU. Relax these assumptions and analyze discrete stochastic dynamics with indefinite Hessians and time‑varying metricsF(w). - Move beyond integral bounds to provide explicit convergence rates (time‑to‑ε) along flat directions under realistic noise; characterize stability regions for
χandβ_2in nonconvex regimes with negative curvature.
- The RISHD/river‑valley analysis ignores mini‑batch noise and assumes analytic
- Role and impact of the Riemannian correction term
R_t- The term
R_tis dropped as “negligible,” butF(w)can vary significantly in practice. QuantifyR_t’s magnitude and its effect on stability/convergence, especially at large scales or with rapidly changing curvature estimates.
- The term
- Discretization choices and numerical stability
- The semi‑implicit Euler discretization with step size
h=1is not compared to alternative schemes (explicit/implicit, higher‑order, adaptive). Evaluate how discretization affects stability, oscillations in sharp directions, and empirical performance.
- The semi‑implicit Euler discretization with step size
- Interaction with common training components
- Investigate how LITE interacts with gradient clipping, weight decay (decoupled), mixed precision (FP16/BF16), quantized training (e.g., 4‑bit), activation checkpointing, and ZeRO‑style optimizer state partitioning.
- Assess compatibility with gradient accumulation and pipeline/tensor model parallelism; measure communication overhead for additional curvature/mask states.
- Generalization and downstream outcomes
- Report validation/test perplexity, calibration, and downstream task performance (e.g., QA, reasoning, code) to ensure optimization gains translate to generalization benefits and do not deteriorate robustness.
- Stability in sharp directions and failure analyses
- While
χ/β_2are held constant in sharp directions, provide formal stability analyses and empirical stress tests (e.g., sudden LR spikes, architectural changes) to confirm LITE does not induce divergence or oscillations.
- While
- Mask estimation and update frequency
- Specify and test the cadence for recomputing
P_k/Q_k(per step vs. per N steps) and the soft mask transition schedule; quantify trade‑offs between responsiveness and overhead.
- Specify and test the cadence for recomputing
- Applicability beyond Muon/SOAP
- Demonstrate how LITE integrates with KFAC, Shampoo, Sophia, PolarGrad and diagonally preconditioned methods (AdamW/Lion). Provide implementation recipes for cases without explicit matrix factors/eigenbases.
- Choice of curvature proxies and numerical stability
- Justify using
G_k^T G_kto precondition gradient terms while masking via\tilde{M}_k^T \tilde{M}_k; compare alternatives (e.g., Fisher EMA, Hessian‑vector products) for accuracy vs. stability and cost. - Analyze how noise, batch size, and EMA parameters affect curvature proxy quality and LITE’s efficacy.
- Justify using
- Comprehensive ablations
- Extend ablations beyond uniform
βto include the effects of varyingd_s, mask softness, projection errors, damping asymmetry (β_2 ≫ β_1), and per‑layer heterogeneity; report sensitivity curves.
- Extend ablations beyond uniform
- Reproducibility and implementation details
- Provide full training configs, optimizer state sizes, mask implementations, NS iteration tolerances, numerical safeguards (e.g., eigenvalue floors), and seed variability to enable exact replication.
- Safety and broader impacts of efficiency gains
- Discuss potential unintended consequences (e.g., lowering compute barriers for misuse) and propose mitigation strategies or evaluation checklists for responsible deployment.
These gaps highlight where theory can be strengthened, systems implications quantified, and empirical coverage broadened to establish LITE as a robust and general acceleration strategy for large‑scale pre‑training.
Practical Applications
Immediate Applications
The following items summarize deployable use cases that can leverage the paper’s findings today. Each bullet highlights sectors, potential tools/workflows, and key dependencies.
- Faster, cheaper LLM pre-training in existing pipelines
- Sectors: software/AI, cloud, foundation-model labs
- What: Integrate LITE into Muon or SOAP optimizers to accelerate convergence along flat curvature directions, cutting wall-clock time and compute cost for token budgets in the 40–200× parameter range (paper reports up to ~2× speedups in long-horizon regimes).
- Tools/workflows: PyTorch + DeepSpeed/Megatron-LM; swap optimizer step with LITE-enabled variant; set flat/“sharp” projection dimension
d_s, learning-rate amplificationχ≥1, and Hessian-dampingβ2≥β1; validate stability on a small token budget, then scale; monitor oscillation on sharp directions and loss curves. - Assumptions/dependencies: Uses matrix-based preconditioners (e.g., Muon, SOAP) with good alignment to curvature; added overhead for subspace estimation must remain small relative to total step time; tested on C4/Pile and LLaMA/QwenMoE (130M–1.3B).
- Acceleration for Mixture-of-Experts (MoE) pre-training
- Sectors: AI platforms, recommender systems, speech/vision-language (where MoE is adopted)
- What: Apply LITE to MoE training (e.g., QwenMoE), improving throughput and iteration cadence.
- Tools/workflows: Retain existing gating and load-balancing; enable LITE in the optimizer step; follow the warmup–stable–decay or cosine LR schedules validated in the paper.
- Assumptions/dependencies: Subspace identification remains stable under MoE-induced nonstationarity; careful hyperparameter setting is required.
- Compute and energy cost reduction for model developers and cloud providers
- Sectors: energy, sustainability, cloud-finops
- What: Fewer GPU-hours/token for pre-training translates to lower energy bills and emissions.
- Tools/workflows: Couple LITE-enabled training with energy tracking tools (e.g., CodeCarbon) and FinOps dashboards to quantify per-token CO₂e and cost reductions.
- Assumptions/dependencies: Gains depend on maintaining training stability; benefits scale with total pre-training tokens.
- Academic labs: more experiments per budget
- Sectors: academia, education
- What: Faster convergence lets labs run more ablations, hyperparameter sweeps, and scaling experiments under fixed GPU quotas.
- Tools/workflows: Open-source repo (linked in paper) provides a starting point; integrate with standard research training stacks; use small LLaMA-based models to validate.
- Assumptions/dependencies: Best results require Muon/SOAP (not pure AdamW); modest extra implementation complexity for flat-direction projections.
- Domain pre-training for vertical LLMs (e.g., legal, code, scientific)
- Sectors: enterprise software, healthcare (non-clinical pre-training), finance
- What: Reduced training times for domain-specific corpora (e.g., legal briefs, code repositories) enable faster iteration on foundation/domain models.
- Tools/workflows: Integrate LITE in existing Muon/SOAP setups; maintain data governance; monitor downstream perplexity and scaling-law slopes.
- Assumptions/dependencies: Domain losses exhibit similar anisotropy; dataset quality remains a dominant factor.
- Optimizer benchmarking and curriculum design in research
- Sectors: academia, industrial research
- What: Use the unified Riemannian ODE framework to analyze and compare optimizers; design curricula and schedules that exploit flat-direction dynamics (e.g., adjust
χ,β2during stable phases). - Tools/workflows: Build small-scale Hessian/curvature probes (PyHessian or layer-wise spectra proxies from gradients); schedule hyperparameters by phase.
- Assumptions/dependencies: Approximations rely on stable curvature estimates and EMA.
- Hyperparameter tuning with curvature-aware knobs
- Sectors: AutoML, MLOps
- What: Expand tuning spaces to include flat-direction learning-rate amplification (
χ) and damping (β2) alongside standard LR/β/weight decay. - Tools/workflows: Bayesian optimization or bandits over
{χ, β1, β2, d_s}; early-stopping based on validation loss curvature. - Assumptions/dependencies: Needs efficient subspace estimation with limited overhead.
- Training recipe enhancement for existing teams
- Sectors: software/AI product teams
- What: A concrete recipe—retain baseline stability settings in sharp directions, selectively increase
χandβ2in flat directions; apply to cosine or warmup–stable–decay schedules. - Tools/workflows: Add projection step per parameter block; audit numerical stability (mixed precision/FP8/TF32).
- Assumptions/dependencies: Implementation care for fused kernels, checkpointing, and ZeRO/TP/PP compatibility.
- Faster iteration cycles for productized LLMs
- Sectors: general software, search, assistants
- What: Shorter pre-training cycles enable quicker releases and reduced time-to-value.
- Tools/workflows: Integrate LITE into continuous pre-training pipelines; adjust CI/CD training orchestration with shorter booking windows.
- Assumptions/dependencies: Organizational willingness to adjust optimizer stack; proper validation to prevent regressions.
- Sustainability reporting and compliance
- Sectors: ESG reporting, regulatory compliance
- What: Leverage measured energy savings from LITE to support corporate sustainability metrics for AI training footprints.
- Tools/workflows: Couple training logs with ESG tooling; report emissions per token/model.
- Assumptions/dependencies: Auditable measurement pipelines; consistent estimator baselines.
Long-Term Applications
These use cases are promising but require further research, scaling experiments, or system support before broad deployment.
- Scaling to very large models (>10B–100B+) and token budgets (trillions)
- Sectors: foundation model labs, cloud
- What: Validate stability and speedups at frontier scales; quantify end-to-end savings including communication overheads (DP/TP/PP).
- Dependencies: Robust subspace estimation under extreme parallelism; fused kernels for projection and preconditioner operations.
- Dynamic, online adaptation of flat/“sharp” projections
- Sectors: optimizer R&D, AutoML
- What: Controllers that adjust
d_s,χ, andβ2online using curvature signals to maximize progress while maintaining stability. - Dependencies: Low-variance curvature proxies; minimal extra latency; theory-guided control (Riemannian ODE) for stability guarantees.
- Generalizing beyond language: vision, speech, and multimodal pre-training
- Sectors: robotics, AV/ADAS, media, healthcare imaging
- What: Apply LITE to diffusion models, ViTs, and multimodal architectures; assess anisotropy patterns in those landscapes.
- Dependencies: Empirical confirmation of time-scale separation and Fisher–Hessian alignment in new modalities.
- Robustness under nonstationary objectives (e.g., RLHF/DPO/online RL)
- Sectors: assistants, content safety, personalization
- What: Extend LITE to non-convex, shifting reward landscapes where curvature varies rapidly.
- Dependencies: Adaptive damping schedules; safety guards against instability during policy improvement.
- Low-precision and memory-constrained training (8-bit optimizers, ZeRO-3)
- Sectors: cost-sensitive training, edge/cloud continuum
- What: Fuse LITE’s projections with low-precision preconditioners and memory-optimized sharding.
- Dependencies: Numerically stable root-inverse/NS iterations in low precision; error-compensation techniques.
- Hardware/software co-design for curvature-aware optimizers
- Sectors: chip vendors, systems software
- What: Accelerator kernels for Kronecker-factor operations, top-eigenspace selection, and masked preconditioning; compiler support for fusion.
- Dependencies: Vendor libraries (CUDA, ROCm) and graph compilers (XLA, Triton) support; maintain portability.
- Policy and governance: compute grants and carbon standards
- Sectors: public funding agencies, regulators
- What: Incorporate optimizer-level efficiency (e.g., LITE-class methods) into grant criteria and carbon accounting standards for AI training.
- Dependencies: Standardized benchmarks for optimizer-induced savings; auditable reporting protocols.
- Training job schedulers that exploit optimizer speedups
- Sectors: MLOps, cloud schedulers
- What: Schedulers predict shorter training windows with LITE and pack jobs more efficiently; dynamic token allocation based on measured convergence rates.
- Dependencies: Reliable predictive models linking curvature metrics to wall-clock savings; integration with cluster managers.
- Automated optimizer discovery using the Riemannian ODE framework
- Sectors: optimizer research, AutoML
- What: Use the framework to search for new preconditioner–momentum couplings and damping strategies beyond Muon/SOAP.
- Dependencies: Meta-optimization infrastructure; theoretical stability guarantees.
- Sector-specific pre-training at lower cost barriers
- Sectors: healthcare (de-identified corpora), finance (public filings), education (textbooks)
- What: Broaden access to high-quality domain LLMs by lowering compute thresholds; enable more frequent refresh cycles.
- Dependencies: Confirmed generality across sector datasets; governance for data privacy and compliance.
- End-user benefits via faster model iteration
- Sectors: consumer apps, enterprise SaaS
- What: Shorter iteration loops translate into quicker feature rollouts and improved model quality in daily-use apps.
- Dependencies: Product teams’ ability to absorb faster training cadences; strong evaluation pipelines to avoid regressions.
Cross-cutting Assumptions and Risks
- Landscape anisotropy: The approach presumes a spectrum with many flat directions dominating loss reduction; benefits may shrink if this structure weakens.
- Curvature alignment: LITE assumes good alignment between Shampoo-like preconditioners (Fisher approximations) and Hessian top eigenspaces at the block level.
- Stability sensitivity: Over-aggressive
χorβ2can destabilize sharp directions; the paper fixes sharp-direction hyperparameters and amplifies only flat directions. - Overhead management: Projection estimation and eigen-subspace tracking must not erase gains; use efficient, state-light approximations as proposed.
- Generality: Proven on LLaMA/QwenMoE with C4/Pile; transferability to other architectures/datasets requires validation.
- Systems compatibility: Must work with distributed training (DP/TP/PP), mixed precision, and optimizer state sharding; thorough testing is needed for production.
Glossary
- AdamW: An adaptive optimizer with decoupled weight decay widely used in deep learning. "Currently, AdamW~\cite{kingma2014adam,loshchilov2017decoupled} serves as the standard in most LLM pre-training pipelines, favored for its simplicity and efficiency."
- Anisotropic: Having direction-dependent properties; here, referring to loss landscapes where behavior varies across directions. "The optimization landscape is highly anisotropic, with loss reduction driven predominantly by progress along flat directions."
- Block-Diagonal Structure: A matrix structure composed of square blocks along the diagonal, used to reduce computational complexity in preconditioning. "Block-Diagonal Structure: To manage computational complexity, is generally treated as a block-diagonal matrix, where each block corresponds to the parameter tensor of a specific layer;"
- Cotangent space: The dual space to the tangent space at a point on a manifold, hosting gradients as covectors. "The cotangent space is defined as the dual space to , which is equipped with the norm $\|\cdot\|_{F(w)^{-1}$ and is also isomorphism to ."
- Covariant derivative: A generalization of directional derivatives to curved spaces, respecting the manifold’s geometry. "Leveraging Levi-Civita connection to generalize the Euclidean derivatives to the covariant derivatives, we can extend the Euclidean ISHD \eqref{agf-2-order} to the Riemannian ISHD (RISHD) on :"
- Eigen-directions: Directions corresponding to eigenvectors of a matrix (e.g., the Hessian), often used to analyze curvature. "of comparable scale across different Hessian eigen-directions."
- Exponential Moving Average (EMA): A weighted moving average giving more weight to recent observations, used in momentum and curvature estimates. "Constrained by the simple linear nature of Exponential Moving Average (EMA), which inherently imposes an isotropic damping effect, existing momentum schemes inadequately exploit second-order information, leaving them susceptible to ill-conditioned curvature."
- Fisher-type metric: A curvature metric based on the Fisher information, often approximated in adaptive methods. "most adaptive algorithms aim to approximate the Fisher-type metric $\hat{F}(w) = (\mathbb{E}[gg^\top])^{\frac{1}{2}$, where is the stochastic gradient of a specific block."
- Gauss-Newton component: An approximation to the Hessian derived from first-order terms, commonly used for curvature estimation. "the Fisher matrix and Shampoo-like preconditioners effectively approximates the Gauss-Newton component, the dominant term in the Hessian."
- Heavy Ball momentum: A classical momentum method corresponding to inertial dynamics without Hessian damping. "Discretizing this system recovers various momentum methods: specifically, setting yields Heavy Ball momentum, while corresponds to Nesterov-type momentum."
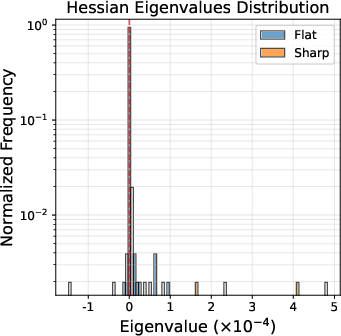
- Hessian: The matrix of second-order partial derivatives of a function, describing local curvature. "Specifically, the Hessian spectrum is dominated by a massive bulk of near-zero and negative eigenvalues (referred to as flat directions), while the large positive eigenvalues are significantly greater in magnitude but sparse in number (referred to as sharp directions),"
- Ill-conditioned landscape: An optimization setting where curvature varies greatly across directions, causing numerical or convergence issues. "This behavior is suboptimal in the ill-conditioned landscape, which is too cautious along flat directions while potentially aggressive along sharp ones."
- Inertial system with Hessian damping (ISHD): A continuous-time dynamical system modeling momentum with curvature-dependent damping. "Further, \cite{Shibin2021understanding,Attouch2022} introduced an inertial system with Hessian damping (ISHD) that can depict the momentum-based algorithms in higher resolution, which takes the form"
- Isotropy: Uniformity across directions; here referring to update magnitudes being similar across eigen-directions. "update magnitudes often tend towards isotropic, i.e., of comparable scale across different Hessian eigen-directions."
- Kronecker factorization: Decomposing matrices using Kronecker products to enable efficient preconditioning. "approximate the square root of the Fisher matrix via Kronecker factorization,"
- Kronecker product: A matrix operation producing block matrices, used in curvature and preconditioner constructions. "The symbol represents the element-wise product, and denotes the Kronecker product."
- Lagrangian mechanics: A reformulation of classical mechanics that naturally extends to curved spaces, used to interpret optimization dynamics. "The corresponding physical background shifts from Newtonian mechanics to Lagrangian mechanics \cite{arnold1989mathematical}, yet the same conclusions hold."
- Levi-Civita connection: The unique torsion-free, metric-compatible connection used to define covariant derivatives and Hessians on Riemannian manifolds. "Levi-Civita connection provides a rigorous tool for differentiating vector fields on Riemannian manifolds, generalizing the concept of directional derivatives from Euclidean space to curved geometries."
- LITE: A generalized acceleration strategy that amplifies learning rates and damping in flat directions to speed up pre-training. "we propose LITE, a generalized acceleration strategy that enhances training dynamics by applying larger Hessian damping coefficients and learning rates along flat trajectories."
- Manifold optimization: Optimization where variables lie on (or are viewed as) manifolds with non-Euclidean geometry. "Manifold optimization deals with variables constrained to a Riemannian manifold."
- Muon: A matrix-based optimizer leveraging curvature information for large-scale LLM training. "a new wave of matrix-based optimizers, such as Muon \cite{jordan2024muon} and SOAP \cite{vyas2025soap}, has emerged, achieving significant performance gains over AdamW."
- Nesterov-type momentum: A momentum variant with lookahead gradients, often modeled via Hessian damping in continuous-time. "the term yields a Nesterov-type momentum."
- Ordinary Differential Equation (ODE): A continuous-time mathematical model used to analyze optimizer dynamics. "we first establish a unified Riemannian Ordinary Differential Equation (ODE) framework that elucidates how common adaptive algorithms operate synergistically"
- Preconditioner: A matrix used to transform gradients, improving conditioning and convergence behavior. "the preconditioner induces a Riemannian geometry that mitigates ill-conditioning,"
- Projection matrix: A matrix that maps vectors onto a subspace, here used to isolate sharp or flat directions. "we construct the projection matrix onto the top- eigenspace of ,"
- Riemannian damping: A momentum-induced damping term defined relative to a manifold’s metric, promoting stable convergence. "momentum serves as a Riemannian damping term that promotes convergence."
- Riemannian geometry: The study of curved spaces with smoothly varying inner products, underpinning curvature-aware optimization. "the preconditioner induces a Riemannian geometry that mitigates the landscape's ill-conditioning,"
- Riemannian gradient: The gradient vector field obtained by mapping the Euclidean gradient through the inverse metric. "the Riemannian gradient is obtained by mapping it back to the tangent space via ."
- Riemannian Hessian: The second derivative operator on manifolds defined via the Levi-Civita connection. "Levi-Civita connection is essential for defining the Riemannian Hessian, which is given by for any vector field ."
- Riemannian ISHD (RISHD): The manifold generalization of ISHD, modeling momentum and damping under a preconditioner-induced metric. "we can extend the Euclidean ISHD \eqref{agf-2-order} to the Riemannian ISHD (RISHD) on :"
- Riemannian manifold: A smooth manifold equipped with an inner product (metric) on each tangent space. "as a Riemannian manifold equipped with metric at each ."
- River: The low-curvature manifold in the River-Valley landscape where slow, loss-reducing dynamics occur. "the set (referred to as River)"
- Semi-implicit Euler discretization: A numerical scheme for ODEs that improves stability by treating certain terms implicitly. "Applying a semi-implicit Euler discretization scheme to \eqref{eq:tangent} and \eqref{eq:cotangent} with step size and yields the discrete formulation \eqref{2-ode0-d}."
- Shampoo: A matrix-based preconditioning method that uses curvature estimates for faster convergence. "algorithms like Shampoo~\cite{pmlr-v80-gupta18a,shi2023distributeddataparallelpytorchimplementation} and KFAC~\cite{pmlr-v37-martens15} introduce matrix-based preconditioners to capture richer geometric structures,"
- SOAP: A matrix-based optimizer designed for LLM training that explicitly parameterizes curvature via eigen-decompositions. "a new wave of matrix-based optimizers, such as Muon \cite{jordan2024muon} and SOAP \cite{vyas2025soap}, has emerged, achieving significant performance gains over AdamW."
- Tangent space: The vector space of possible directions (velocities) at a point on a manifold. "the tangent space represents the vector space of all possible directional velocities (or parameter perturbations)."
- Time-scale separation: The phenomenon where dynamics evolve at different rates along sharp versus flat directions. "the anisotropic landscape induces a distinct {\em time-scale separation} in the training dynamics"
- Warmup-stable-decay schedule: A learning-rate schedule that warms up, stays stable, then decays, used in large-scale training. "datasets (C4, Pile), and learning-rate schedules (cosine, warmup-stable-decay)."
Collections
Sign up for free to add this paper to one or more collections.

