- The paper introduces a feed-forward 3D reconstruction method that infers metric-scale scene geometry from RGB images and robot states, eliminating the need for depth sensors.
- It employs a transformer-based architecture with masked point heads and keypoint-based PnP to achieve sharp, robust 3D reconstructions and precise camera pose estimation.
- Experimental results show up to tenfold error reduction and higher success rates in robotic manipulation, imitation learning, and sim-to-real tasks.
Robo3R: Enhancing Robotic Manipulation with Accurate Feed-Forward 3D Reconstruction
Introduction and Motivation
Accurate 3D spatial perception is critical for robotic manipulation, serving as the foundation for robust policy learning, grasp synthesis, and collision-free planning. Conventional approaches leverage depth sensors, which frequently exhibit noise, poor metric consistency, and susceptibility to failure in scenarios involving challenging materials (transparent, reflective, or small objects). Recent advances in feed-forward 3D reconstruction represent a promising alternative but have not achieved the geometric precision and metric fidelity required for manipulation-centric downstream tasks.
Robo3R addresses these deficiencies by introducing a manipulation-ready, feed-forward 3D reconstruction framework that directly infers accurate, metric-scale scene geometry from RGB images and robot states in real time, eliminating the need for depth sensors and explicit calibration.
Model Overview and Architecture
Robo3R fuses visual and proprioceptive information through a transformer backbone with an alternating global and frame-wise attention mechanism. The encoders process both monocular or binocular RGB images and robot joint states, projecting them into a unified embedding space for the transformer.
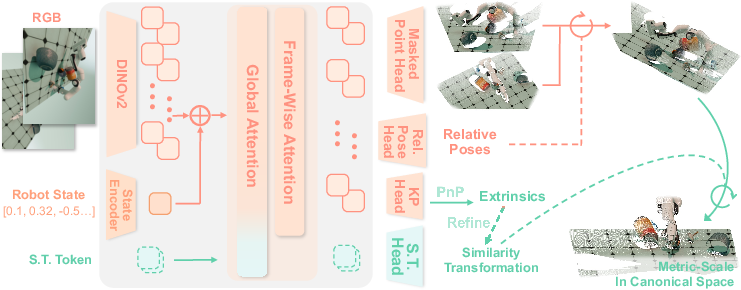
Figure 1: Robo3R method overview—multi-modal encoding, transformer-based feature propagation, and specialized decoding heads produce scale-invariant local geometry and metric-aligned point clouds in the robot's canonical frame.
A distinctive feature is the masked point head that decomposes dense point predictions into depth, normalized image coordinates, and binary masks. This addresses the over-smoothing issue typical in dense regression, yielding sharp, fine-grained geometry even with sparse views.

Figure 2: The masked point head decomposes point prediction into depth, coordinates, and mask to produce sharp, detailed point clouds.
Robo3R includes a relative pose head for estimating camera extrinsics via relative translation and rotation, enhancing consistent registration of multi-view observations. Furthermore, S.T. (similarity transformation) tokens in the transformer enable the prediction of a global similarity transformation, facilitating the mapping of locally reconstructed points into a metric-scale 3D canonical robot frame. This is further refined by a keypoint-based PnP extrinsic estimation module, which leverages robot kinematics and detected image keypoints for robust camera pose estimation.
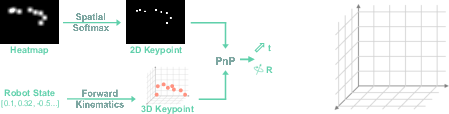
Figure 3: The extrinsic estimation module extracts robot keypoints and refines camera extrinsics through a PnP solution.
Synthetic Dataset and Training Paradigm
Effective scale-robust 3D reconstruction necessitates a curated data regime. The Robo3R-4M dataset comprises 4M synthetic frames rendered with extensive randomization spanning objects, textures, environmental conditions, robot states, and camera parameters. This dataset was tailored to maximize generalization to real manipulation scenarios and encapsulate critical edge cases such as transparent/reflective materials and diminutive objects.

Figure 4: Robo3R-4M dataset exhibits massive diversity in object classes, materials, camera parameters, and scene compositions, supporting generalization and robustness.
Training is supervised via a multi-task loss: point cloud loss (with scale normalization), normal vector alignment, mask cross-entropy, relative pose, similarity transformation, and keypoint regression, balanced to drive both local geometric fidelity and global metric consistency.
Reconstruction Quality and Analysis
Quantitative experiments demonstrate that Robo3R achieves a monocular point error of 0.006—a tenfold improvement over the strongest baseline, and monocular scale error of 0.007, reflecting near-perfect metric consistency. Relative translation and rotation errors (0.014, 0.013) are substantially lower than competing models, with 95.1% translation accuracy at a 3cm threshold.
Qualitative evaluation in real-world settings further solidifies these outcomes. Robo3R successfully reconstructs fine structures (down to 1.5mm) and resolves geometry in cases where depth sensors and all prior feed-forward models (e.g., VGGT, MapAnything, DA3, π3) fail—especially with transparent, reflective, or cluttered environments.
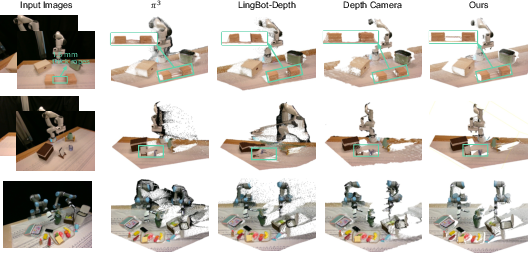
Figure 5: Robo3R qualitatively surpasses preceding techniques and depth sensors in finely detailed, robust point cloud generation, even under challenging optical conditions.
Downstream Robotic Manipulation: Imitation Learning, Sim-to-Real, Grasp Synthesis
Imitation Learning: A suite of manipulation tasks (Sweep Bean, Insert Screw, Breakfast, BiDex Pour) were used to evaluate downstream efficacy. Robo3R-based 3D policies consistently delivered higher success rates compared to those operating on RGB images or direct depth camera inputs. Notably, Robo3R achieved 14/16 and 15/16 successes in "Sweep Bean" and "Insert Screw" (compared to 10/16, 2/16 with RGB-only input), directly highlighting the necessity of accurate 3D geometry for fine manipulation.
Figure 6: Illustration of representative imitation learning tasks used for downstream evaluation.
Sim-to-Real Transfer: Robo3R narrows the sim-to-real visual gap by generating a domain-invariant 3D representation from RGB, outperforming both depth and RGB sensor-based baselines in "Push Cube" and "Pick Cube" (16/16 and 12/16 successes, respectively).

Figure 7: Depiction of sim-to-real tasks demonstrating cross-domain robustness enabled by reconstructed 3D geometry.
Grasp Synthesis & Collision-Free Motion Planning: Integrating Robo3R with established planning and grasping frameworks (e.g., AnyGrasp, cuRobo) yields higher success rates in handling transparent, reflective, and tiny objects—scenarios traditionally problematic for metric sensors and scene reconstruction networks.
Architectural Ablations and Generalization
Key architectural studies show that explicit keypoint-based PnP extrinsic estimation yields lower absolute translation/rotation errors and higher pose accuracy compared to direct regression. Fusion of robot state with visual features additionally provides quantifiable improvements in both point cloud and pose prediction accuracy.
Robo3R further demonstrates cross-embodiment generalization and adaptability in non-standard robots and environments, as illustrated by successful reconstructions in scenarios outside the training domain.

Figure 8: Detailed reconstructions in diverse, previously unseen scenarios validate model generalization capacity.
Limitations and Outlook
Robo3R currently specializes in pinhole camera models and a limited selection of robot embodiments. Extending its capabilities towards fisheye/panoramic imaging and broader embodiment coverage remains future work. Incorporation of real or hybrid data and further architectural refinements may facilitate scaling to more unconstrained and tactile manipulation domains.
Conclusion
Robo3R demonstrates that feed-forward, transformer-based 3D reconstruction, when paired with massive high-quality synthetic data and manipulation-centric design, outperforms both depth sensors and prior reconstruction models in delivering accurate, robust 3D perception for robotics. The model shows notable gains in real-world manipulation tasks, establishes state-of-the-art downstream performance, and points toward a future where accurate 3D reconstruction from monocular RGB is foundational for scalable, general-purpose manipulation. Future developments may shift towards more diverse camera models, embodiment types, and richer real-world domains powered by modular, data-scalable architectures.