- The paper introduces a novel framework that converts complex, spatial instructions into executable 3D traces using metric-sensitive reasoning.
- It combines a universal spatial encoder, a scale decoder, and reinforcement fine-tuning to generate collision-free, multi-step trace plans.
- Experimental results demonstrate an 8.6% performance improvement over competitors and validate the approach with high success rates in real-world robotic tasks.
RoboTracer: 3D-Aware Vision-Language Reasoning for Spatial Trace in Robotics
Motivation and Problem Scope
Spatial tracing is a critical competency for embodied robotics, representing the ability to transform complex, spatially-constrained instructions into executable 3D position sequences. Unlike conventional vision-LLMs (VLMs) that operate mainly in 2D pixel space, spatial tracing mandates multi-step, metric-grounded reasoning in 3D environments, encompassing both spatial referring (localization and relational ordering of objects) and spatial measuring (interpretation of metric quantities such as distances and heights). The RoboTracer framework directly addresses the limitations observed in prior methods, where trace generation either lacked compositional depth or failed to bridge the gap between visual perception and actionable 3D plans.
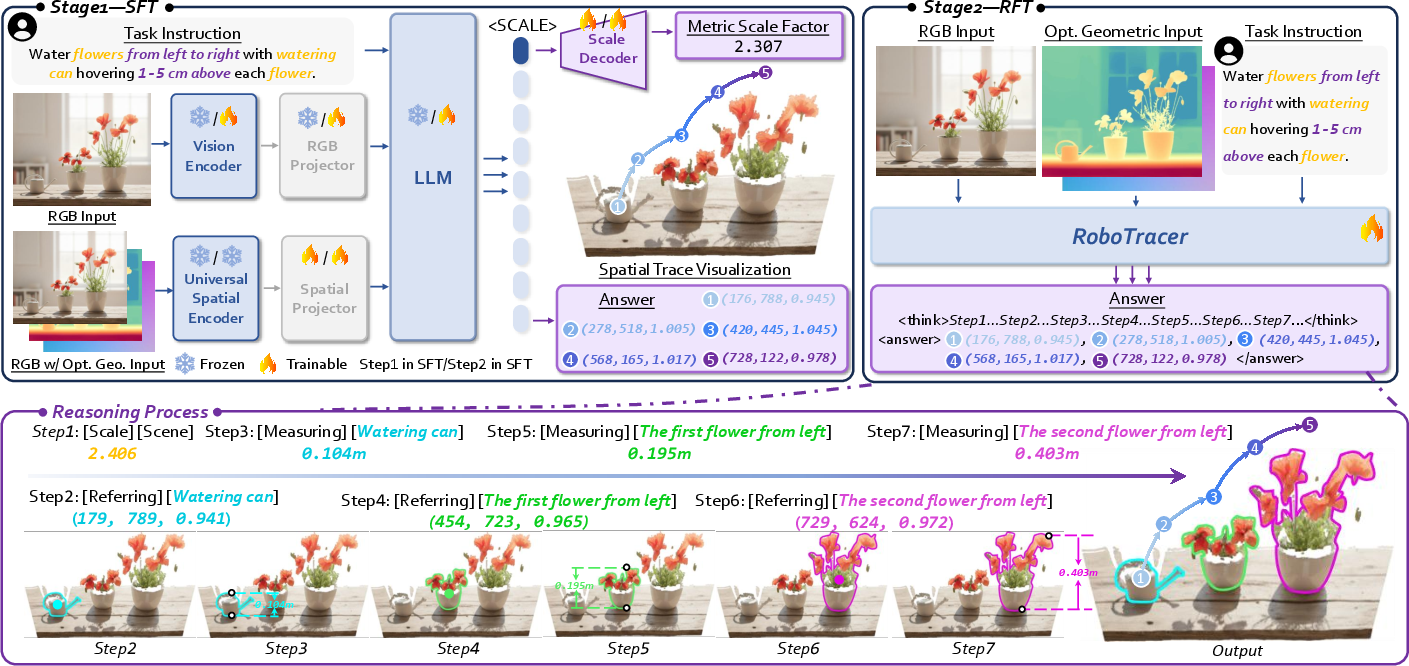
Figure 1: Overview of RoboTracer, illustrating the necessity of 3D spatial reasoning, metric quantification, and multi-step manipulation for scene-constrained robotic actions.
Architecture and Algorithmic Innovations
RoboTracer’s architecture centers around three core components:
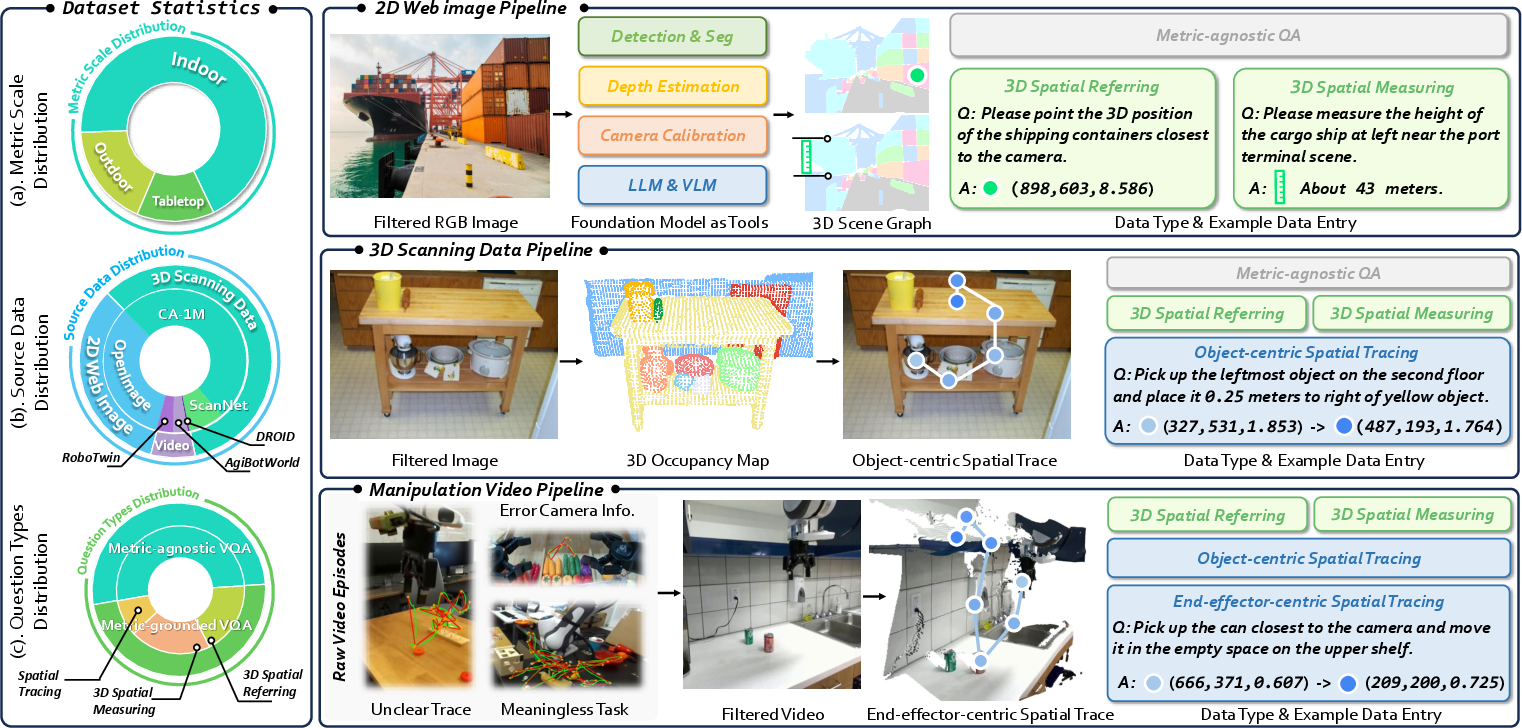
TraceSpatial Dataset and Benchmark Contributions
RoboTracer’s capabilities derive from the TraceSpatial dataset—a large-scale, multi-source corpus comprising 30M QA pairs with 4.5M samples, spanning outdoor, indoor, and tabletop domains. Key characteristics include:
- Rich absolute-scale annotation: 48.2% metric-grounded samples, providing 14x the prior state-of-the-art.
- Fine-grained object referencing: Scene graphs leveraging advanced segmentation (SAM), monocular geometry reconstruction (MoGe-2), and open-vocabulary recognition (RAM++).
- Multi-step reasoning: Up to 9 annotated reasoning steps per sample, supporting compositional policy induction.
- Manipulation-centric traces: Both object-centric and end-effector-centric trajectories, covering diverse robot configurations and control modalities.
To fill the evaluation gap, TraceSpatial-Bench is established—a challenging real-world benchmark of 100 images with ground-truth masks, 3D destination boxes, and complete geometric context, requiring both point-wise localization and collision-free, multi-step trace planning.

Figure 3: TraceSpatial-Bench visualizes diverse spatial tracing tasks with multimodal annotations and metric evaluation points.
Experimental Results and Ablations
RoboTracer achieves state-of-the-art performance across both spatial understanding and manipulation metrics. On spatial understanding, the 8B-SFT variant outperforms Gemini-2.5-Pro by 8.6% on average (85.7% vs. 77.1%) and demonstrates particularly strong gains in 3D measurement tasks (+23.6%).
On TraceSpatial-Bench, RoboTracer delivers a 39% overall success rate (vs. 3-8% for Gemini-2.5-Pro and Qwen3-VL-8B), confirming its ability to generate collision-free, multi-step, metric-trace plans under explicit spatial constraints.

Figure 4: Representative TraceSpatial-Bench rollouts, showing accurate start point masks, endpoint boxes, and predicted traces.
Ablation studies reveal:
- Data synergy: Combined 2D/3D/video data is essential for robust metric reasoning and trace generalization.
- Encoder contributions: Universal spatial encoder is crucial for compositional metric learning and multi-step generalization.
- Supervision regime: Regression loss for scale supervision decisively improves metric-aware prediction over naive next-token objectives.
- Process rewards: Incorporation of intermediate process rewards boosts overall 3D trace accuracy by 4% absolute over outcome-only baselines.
Robotic Generalization: Simulation and Real-World Deployment
RoboTracer’s embodiment-agnostic trace generation enables its integration with a wide range of control policies and hardware settings. On the RoboTwin simulation suite (19 hard tasks), RoboTracer surpasses task-specific baselines by up to 44.4% in unseen scenarios, demonstrating zero-shot transfer from TraceSpatial abstractions. In real-world evaluation, only RoboTracer successfully executes long-horizon, cluttered tasks (e.g., multi-object pick-place and constrained watering) with a practical success rate (60% for UR5, 30% for G1 humanoid), greatly exceeding previous open VLM actors. Model predictions update dynamically at 1.5 Hz, allowing real-time adaptation as the scene changes.

Figure 5: RoboTracer’s real-world predictions—collision-free traces and constraint-satisfying placements in dynamic scenes.
Theoretical and Practical Implications
The introduction of order-invariant process rewards and a regression-based metric supervision regime addresses known weaknesses of VLMs in 3D metric reasoning. The modular architecture ensures geometric adaptability without retraining, implying significant promise for future multi-embodiment and multi-task robotic deployability. The TraceSpatial data pipeline further demonstrates scalable, compositional data synthesis for spatial tasks, which can be adapted for the next generation of embodied instruction tuning.
Future Directions
Despite strong empirical results, key limitations persist: (i) existing VLMs are inherently slower and less suitable for time-sensitive robotic control tasks; (ii) further scaling of 3D metric supervision with dense correspondence (e.g., full scene-level point clouds and depth maps) is needed for fully generalizable 3D spatial intelligence; (iii) scene-level alignment of geometric features and natural language remains challenging.

Figure 6: RoboTwin data visualization. Object- and end-effector-centric traces illustrate RoboTracer’s generalization across embodiments.
Conclusion
RoboTracer systematically advances the capabilities of VLMs for spatially-structured scene understanding and control in robotics. By combining universal geometric encoding, metric-sensitive reasoning, and compositional process supervision—grounded in a meticulously constructed dataset and benchmark—it demonstrably closes the gap from pixel-level perception to actionable, collision-free spatial plans in complex, real-world robotics settings. The methodological framework and data generation apparatus established in RoboTracer will likely serve as foundational primitives for subsequent progress in scalable, instruction-driven embodied AI.