- The paper introduces a plug-and-play Free-Module that actively prunes redundant tokens, preventing context overload and reasoning collapse in LLMs.
- It employs explicit training with expert-generated deletion suggestions to ensure accuracy and efficiency in long-horizon mathematical reasoning.
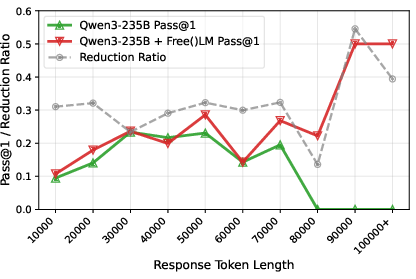
- Empirical results across various benchmarks show enhanced pass@1 scores and reduced response lengths, ensuring robust cross-model performance.
Free()LM: Enabling Active Forgetting to Enhance Long-Horizon Reasoning in Malloc-Only LLMs
The paradigm of augmenting LLM-based reasoning models with increased test-time compute faces a severe architectural bottleneck: excessive accumulation of reasoning tokens results in significant performance degradation and reasoning collapse, rather than continued improvement. The root cause lies in standard LLMs functioning as “malloc-only” engines—continuously appending intermediates and obsolete steps to the context buffer, with no mechanism for discarding irrelevant information. Empirical analyses on large-scale mathematical reasoning trajectories illustrate this degeneration: as token usage grows, the proportion of repetitive loops and context pollution rises, culminating in total collapse on ultra-long paths. This presents a fundamental paradox—scaling “thinking” does not scale intelligence unless models are endowed with a forgetting capability.
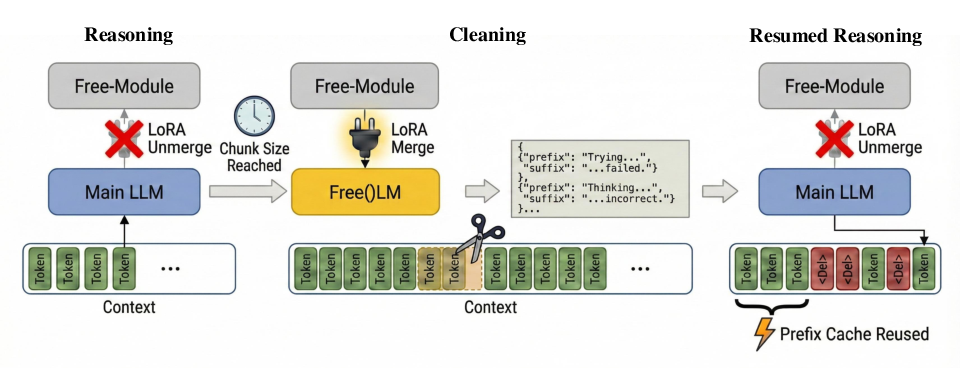
Figure 1: Free()LM inference cycles between reasoning and cleaning modes, with the Free-Module dynamically merged to prune redundant context and maintain compact, noise-free state.
Free()LM Framework
Free()LM introduces an intrinsic self-forgetting mechanism by augmenting the LLM backbone with a plug-and-play LoRA adapter, termed the Free-Module. The core inference workflow alternates between two modes:
- Reasoning Mode (Unmerged): The backbone proceeds with standard token generation, solving the problem step-by-step.
- Cleaning Mode (Merged): Upon reaching a preconfigured chunk limit, the Free-Module activates and scans the context, identifying semantic redundancy and outputting explicit pruning instructions via a structured JSON schema (prefix/suffix anchors).
These commands are programmatically executed to excise redundant spans, after which reasoning resumes on the cleaned context. The design ensures minimal computational overhead, as only anchor tokens are generated to delineate deletions. Context resumption employs re-prefilling of the altered suffix, optimizing compatibility with existing serving frameworks.
Training Methodology
Active context management is not tractable via naive in-context learning or prompt-based supervision—even top-tier LLMs like Gemini-2.5-Pro achieve only marginal gains. Effective memory management necessitates explicit training of the Free-Module, requiring a carefully curated dataset and reward mechanism.
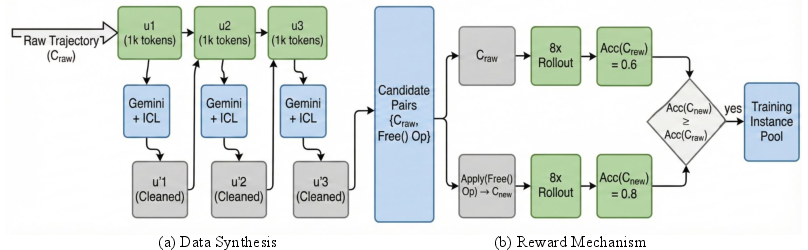
Figure 2: Data construction pipeline employs chunked segmentation, sequential pruning via expert LLMs, and rigorous reward filtering through multi-rollout validation to preserve or improve reasoning accuracy.
Candidate instances are synthesized by segmenting reasoning traces into chunks and prompting Gemini-2.5-Pro for deletion suggestions. Each candidate undergoes rigorous rollouts: only those pruning operations which preserve or improve downstream reasoning accuracy are retained, resulting in a high-precision training corpus. This ensures the Free-Module acquires a robust capability for discriminating truly disposable context from critical logical anchors.
Empirical Results and Analysis
Comprehensive evaluations are conducted on diverse mathematical reasoning benchmarks (AIME2425, BrUMO25, HMMT, BeyondAIME, HLE, IMOAnswerBench) and broad general-purpose tasks. Free()LM is deployed across backbone models ranging from 8B to 685B parameters, as well as cross-model settings with DeepSeek-V3.2-Speciale. Key findings are summarized as follows:
System Impact and Engineering Considerations
The Free()LM framework introduces a moderate latency overhead (~56%) due to decoding and re-prefilling steps, but achieves substantial KV cache savings (up to 45%). Optimizing serving frameworks for direct cache pruning could reduce overhead further, facilitating scalable deployment in bandwidth-constrained environments.
Relation to Prior Work
Free()LM advances the state-of-the-art in memory management, distinctly departing from throughput-centric heuristics in KV cache compression and contexts window expansion. Unlike prior work—predominantly focused on length control or attention-based token importance—Free()LM delivers trainable, logic-aware pruning directly aligned with inference dynamics. It complements architectural advances like ALiBi, LongRoPE, and Ring Attention, but redefines scaling laws by emphasizing the necessity of forgetting as a core ingredient for sustainable intelligence.
Conclusion
Free()LM establishes active forgetting as an indispensable capability for long-horizon reasoning in LLMs. By augmenting malloc-only models with systematized free() operations, the framework reclaims reasoning power, mitigates context pollution, and consolidates concise, noise-free chains of logic. The plug-and-play Free-Module achieves strong empirical gains, cross-model generalization, and memory savings, underscoring both practical and theoretical implications: memory management must be bidirectional—malloc is not enough, free() unlocks scalable intelligence. Future directions encompass universal context-pruning services and further architectural integration for latency minimization.