The Pensieve Paradigm: Stateful Language Models Mastering Their Own Context
Abstract: In the world of Harry Potter, when Dumbledore's mind is overburdened, he extracts memories into a Pensieve to be revisited later. In the world of AI, while we possess the Pensieve-mature databases and retrieval systems, our models inexplicably lack the "wand" to operate it. They remain like a Dumbledore without agency, passively accepting a manually engineered context as their entire memory. This work finally places the wand in the model's hand. We introduce StateLM, a new class of foundation models endowed with an internal reasoning loop to manage their own state. We equip our model with a suite of memory tools, such as context pruning, document indexing, and note-taking, and train it to actively manage these tools. By learning to dynamically engineering its own context, our model breaks free from the architectural prison of a fixed window. Experiments across various model sizes demonstrate StateLM's effectiveness across diverse scenarios. On long-document QA tasks, StateLMs consistently outperform standard LLMs across all model scales; on the chat memory task, they achieve absolute accuracy improvements of 10% to 20% over standard LLMs. On the deep research task BrowseComp-Plus, the performance gap becomes even more pronounced: StateLM achieves up to 52% accuracy, whereas standard LLM counterparts struggle around 5%. Ultimately, our approach shifts LLMs from passive predictors to state-aware agents where reasoning becomes a stateful and manageable process.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new kind of AI LLM called StateLM. Unlike most current AIs that just read whatever you give them and try to answer, StateLM can manage its own “memory” while it thinks. The authors compare it to the Pensieve from Harry Potter: the model can decide what to read, what to keep as notes, and what to forget, so it doesn’t get overwhelmed by too much text.
What questions did the researchers ask?
- Can we give AI models the ability to choose what information to keep, summarize, or delete while they work, instead of forcing humans to prepare all the context for them?
- Will this self-managed memory help AI do better on tasks that involve very long texts, long conversations, or deep web research?
- Can a model learn these skills from examples and practice, and use them efficiently across many different tasks?
How did they do it?
The core idea (simple version)
Most AIs have a fixed “context window”—like a short-term memory. If you stuff in too much, the model forgets or fails. StateLM adds a thinking loop where the model:
- reads a bit,
- writes down the important parts as notes,
- deletes the raw, bulky text it no longer needs,
- repeats until it has enough to answer.
This makes the model’s memory use look like a sawtooth: it grows while reading, then drops when it cleans up—over and over—so it never overflows.
The model’s “spellbook” (its tools)
- analyzeText and checkBudget: estimate size and see how much memory is left.
- buildIndex and searchEngine: make a searchable map of a long document and find relevant parts.
- readChunk: open just a small, relevant piece.
- note/updateNote and readNote: keep short, useful notes in a notebook the model can access later.
- deleteContext: remove unneeded text from active memory to stay under the limit.
- finish: stop and give the final answer.
Think of it like studying: skim the book, bookmark spots, read a section, write a summary in your notebook, recycle the extra pages, and keep going.
How the model learned these skills
- Stage 1: Supervised learning (learn from examples). A strong “teacher” AI demonstrated good behaviors (when to read, note, delete). The model copied these strategies.
- Stage 2: Reinforcement learning (learn by practicing). The model tried tasks on its own and got rewards for correct, well-formatted answers within limits. Over time, it improved its tool use and timing.
What did they find?
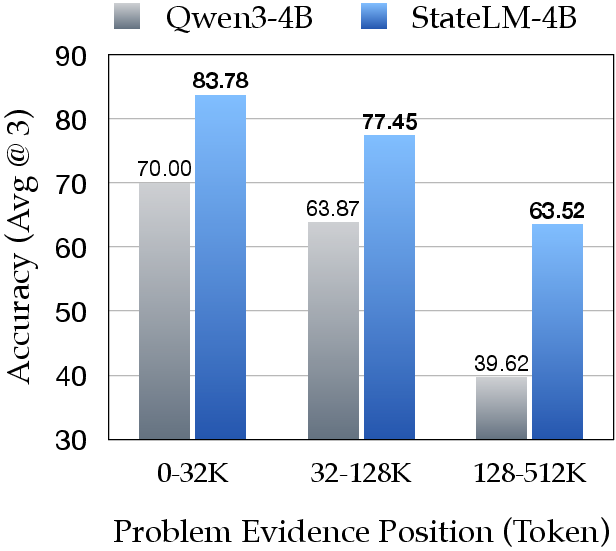
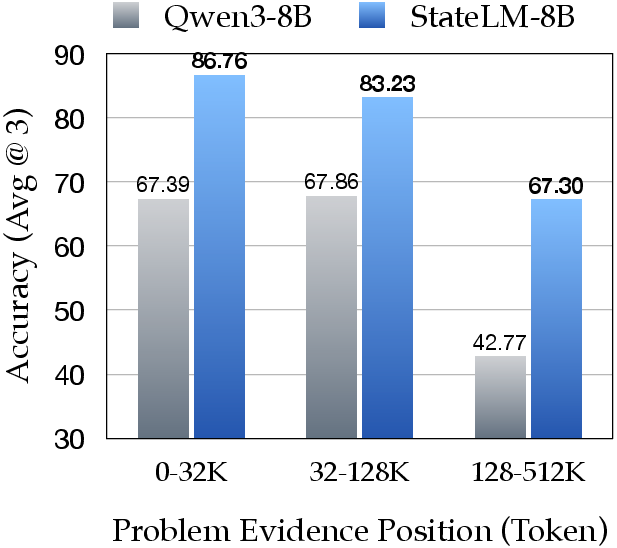
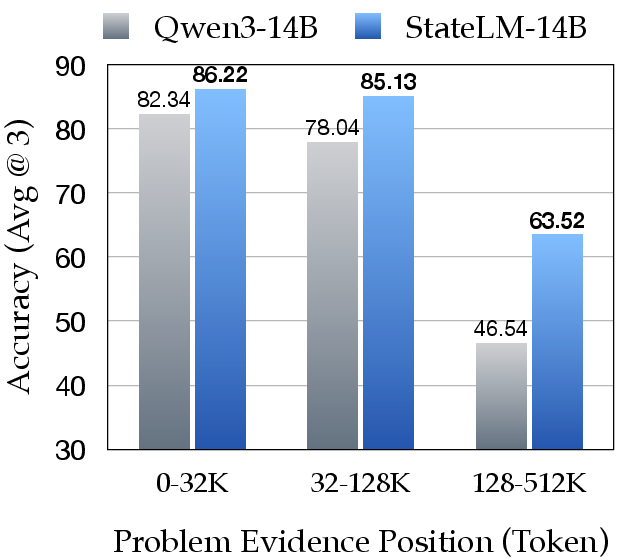
- Better long-document answers: On long-document question answering, StateLM beat standard models of the same size by about 5–12% accuracy on average—while using only about one-quarter of the active context window.
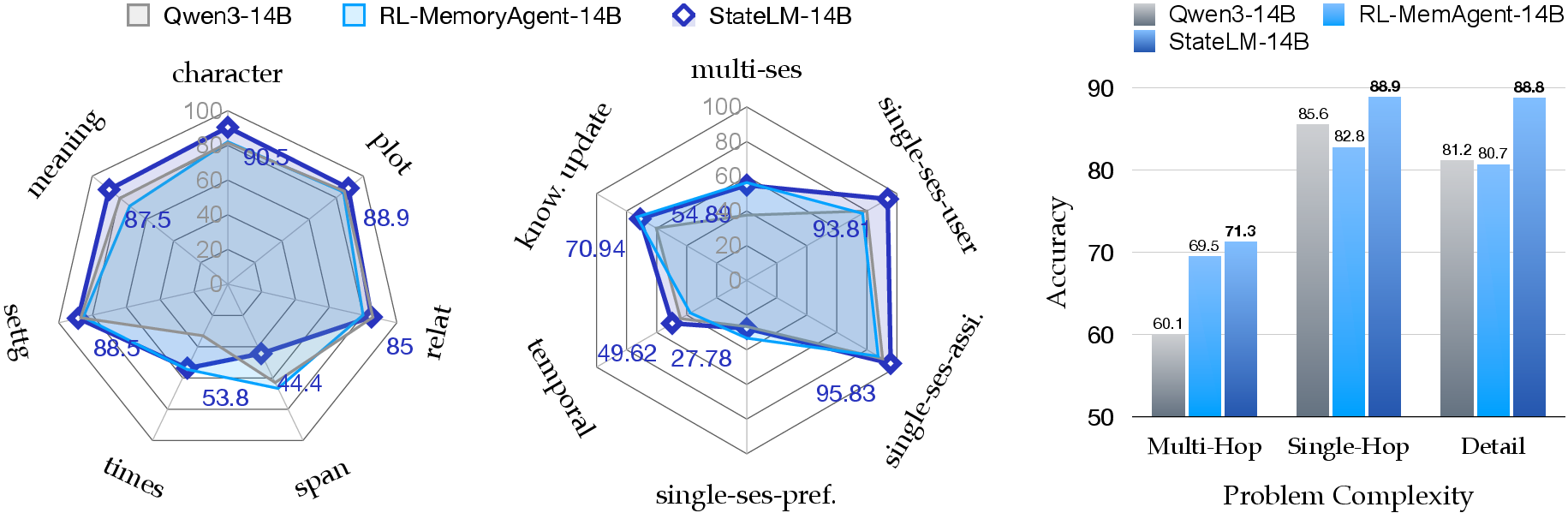
- Stronger chat memory: In multi-turn conversations that need remembering earlier details, StateLM improved accuracy by about 10–20% compared to standard models.
- Big gains in deep research: On a tough research benchmark (BrowseComp-Plus), StateLM reached up to 52% accuracy, while regular models of similar size were around 5%. That’s a huge jump.
- Handles very long inputs: In a “needle-in-a-haystack” test (find one key sentence in up to millions of tokens), StateLM stayed accurate far beyond the normal context limit by scanning, note-taking, and deleting as it went.
- Efficient behavior: The model didn’t overuse its tools. It searched more when texts were longer, took notes when needed, and pruned frequently enough to avoid overload—like a careful, organized reader.
- Learning matters: Simply giving a normal model the tools and a detailed instruction wasn’t enough. Training (examples + practice) was necessary to get reliable, smart context management.
Why does it matter?
- More reliable long tasks: Models can read and reason over books, long reports, and long chats without “forgetting” or getting bogged down.
- Cheaper and faster: By keeping the active memory small, models need fewer resources, making them quicker and less expensive to run.
- Smarter assistants and researchers: Personal AI that remembers important details from long conversations, or research agents that can dig deep on the web, can work better and longer.
- A shift in AI design: Instead of humans doing all the “context engineering” (hand-picking what the model sees), the model learns to manage its own memory—planning, summarizing, and pruning as it thinks.
The authors also note current limits: keyword search can miss clues hidden in paraphrases, occasional formatting mistakes can happen, and even small “stubs” left after deletions can pile up over very long sessions. Future improvements could include better search, bigger management windows, and more long-horizon training.
Overall, StateLM points toward AI that’s not just predicting the next word, but actively organizing its own thoughts—like giving the model a wand to use its Pensieve on its own.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, organized by theme to guide future work.
Methodology and Training
- Lack of component ablations: no systematic analysis of which “spells” (e.g.,
deleteContext,note/updateNote,readNote,searchEngine) contribute most to gains; missing variants that disable single tools, vary deletion granularity (delete tool output only vs. full turns), or replace BM25 with dense retrieval and reranking to isolate effects. - Sensitivity to hyperparameters: no study of how deletion aggressiveness, note length/structure, index granularity, or the snapshot count parameter k during RL affect performance and stability.
- RL objective and algorithm choices: no comparison of GRPO-style training to alternatives (PPO, DPO/ORPO, Q-learning variants) nor analysis of variance, sample efficiency, and convergence under long-horizon edits.
- Teacher dependency and reproducibility: reliance on a proprietary teacher (Claude Opus 4.1) without releasing the exact trajectories/prompt templates hinders reproducibility; unclear how teacher quality affects learned behaviors.
- Catastrophic forgetting and general skill retention: no evaluation of whether SFT/RL on Pensieve tasks degrades base abilities (e.g., MMLU, math/code reasoning, harmlessness/helpfulness).
Evaluation and Benchmarks
- Limited baseline coverage: missing comparisons against modern strong RAG/compression pipelines (e.g., dense retrievers ColBERTv2/SPLADE, query expansion like HyDE, cross-encoder rerankers, selective compression like RECOMP) and long-context frontier models (e.g., GPT-4-class, Gemini 1.5, Claude 3.7) to contextualize absolute gains.
- Fairness of comparisons: StateLM uses tool-augmented, self-managed context at 32K while baselines mostly run as plain LLMs at 128K; not clear if baselines would close gaps with equally capable tool access or stronger retrieval/compression.
- LLM-judge reliability: for Chat Memory and BrowseComp-Plus, evaluation depends on LLM judging without reported inter-rater agreement, calibration, or human spot-checks; uncertainty in reported accuracy persists.
- Statistical robustness: small test subsets (e.g., 150 problems on BrowseComp-Plus) and only 3 seeds—no confidence intervals beyond ± values, no power analysis, and no robustness to dataset shifts.
- Coverage gaps: all tasks are English, text-only, and skewed toward long documents and chat memory; no evaluation on multilingual, code, math, legal/biomedical, or multimodal long-context scenarios.
System Design and Tools
- Retrieval limitations: BM25-based
searchEngineunderperforms on paraphrased/implicit queries (acknowledged in error analysis); dense retrieval, hybrid sparse+dense, or learned retrievers/rerankers are not explored. - Indexing assumptions and overhead:
buildIndexpresumably requires full corpus parsing; no measurement of build time, memory footprint, or scalability for very large/streaming corpora and dynamic updates. - Note quality and schema: the structure, factuality, and consistency of notes are not audited; no metrics for hallucination in notes, drift over long horizons, or conflict resolution when notes are updated.
- Recovery from over-deletion: no experiments assessing the model’s ability to detect and recover from premature deletions (e.g., via re-fetching source chunks) and the resulting accuracy/latency trade-offs.
- Stub accumulation: deletion replaces content with stubs that still consume tokens; no mechanism or evaluation for stub compaction/garbage collection to bound growth over very long trajectories.
- Guardrails on deletion: it is unspecified whether
deleteContextcan affect system prompts/tool specs; no guarantees or tests ensuring critical safety/meta-instructions remain immutable.
Robustness, Safety, and Security
- Prompt injection and tool misuse: no assessment of robustness to adversarial content (e.g., retrieval results that instruct the agent to delete notes or system constraints) or to malformed tool responses.
- Tool/environment failures: no experiments on resilience to search/index outages, timeouts, or noisy/incorrect tool outputs; unclear fallback strategies and their impact on performance.
- Privacy and data governance: notes persist across an episode; policies for handling sensitive/personal data, retention limits, and audit logs are unaddressed—especially relevant for chat memory settings.
- Distribution shift: no stress tests under domain shift (e.g., OCR noise, code, tables) or contaminated/incomplete indexes.
Efficiency, Cost, and Practicality
- Compute, latency, and cost accounting: no reporting of wall-clock latency, token usage per turn, number of tool calls, API/index costs, or energy consumption; unclear trade-off between accuracy and operational cost.
- Context “sawtooth” profiling: the paper motivates a compact, sawtooth-shaped context but provides no quantitative traces over time (e.g., prompt length per step, deletions before overflow) or correlation with accuracy.
- Context window interactions: all results are with YaRN-extended models; unclear how Pensieve interacts with native long-context strategies (ALiBi, NTK-aware RoPE) and whether gains persist at 256K–1M native windows.
Generalization and Portability
- Cross-model portability: all main experiments are with Qwen3; it remains open how easily the approach transfers to other LLM families (Llama, Mistral, Phi, etc.) and whether fine-tuning data/tools need adaptation.
- Scaling behavior: results up to 14B (plus one 235B mention) leave open how performance/cost scales at >30B and whether RL remains stable and beneficial at larger scales.
- Lifelong and cross-session memory: Pensieve is per-episode; extending to persistent, cross-session memory raises open questions on retrieval, forgetting policies, privacy, and contamination control.
Analysis and Interpretability
- Decision audits: no instrumentation that explains why/when deletion decisions are made, how uncertainty is handled, or how deletion interacts with note confidence; no human-in-the-loop tools to inspect/edit memory states.
- Error taxonomy depth: while some failure modes are listed, there is no quantitative breakdown by failure type (e.g., retrieval miss vs. over-deletion vs. formatting error) across benchmarks to prioritize fixes.
Open Research Directions
- Learnable retrieval and pruning: jointly learn retrieval, note-taking, and deletion policies end-to-end (e.g., with differentiable retrievers or RL over dense retrievers) and study the resulting stability and gains.
- Verifiable notes and deletions: integrate attribution or “evidence pointers” to allow verification that notes faithfully summarize sources and that deletions do not remove unsupported claims.
- Adaptive budgeting: develop principled controllers for dynamic token budgets that trade off reading, note density, and pruning frequency under latency/cost constraints.
- Safety-aware context editing: formalize immutable regions (system prompts, tool specs), design deletion policies robust to prompt injection, and evaluate under adversarial benchmarks.
- Memory compaction algorithms: design and evaluate stub compaction/garbage collection and hierarchical note structures to bound prompt growth over very long horizons.
- Multilingual and multimodal Pensieve: extend tools and training to non-English and multimodal inputs (images, tables, code), assessing retrieval/indexing and note fidelity in those settings.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging the paper’s released code/models and the “Pensieve” toolkit (buildIndex, searchEngine, readChunk, note/updateNote, readNote, deleteContext, checkBudget, finish). Each bullet notes the sector, the application, the workflow or tool concept, and key assumptions/dependencies.
- Industry — Enterprise Knowledge Assistants for Long Documents
- Application: Contract analysis, compliance audits, policy manuals, SOPs, patent portfolios.
- Workflow/Tool: “Search–Read–Note–Delete” loop; buildIndex over repositories; persistent “Pensieve Notebook” with updateNote; automatic pruning via deleteContext to control context cost.
- Assumptions/Dependencies: Access to document stores (DMS, SharePoint, Confluence); reliable retrieval (BM25 or hybrid dense retrieval); privacy controls; context budget ≥ 32K.
- Finance — Filings and Research Copilot
- Application: Summarize and compare 10-K/10-Q filings, track risk factors, recall client preferences across sessions, monitor regulatory changes.
- Workflow/Tool: Sector-specific indexers; annotated notes per issuer (“issuer notebooks”); checkBudget safeguards; provenance stubs after deletion for auditability.
- Assumptions/Dependencies: Timely ingestion of filings; compliance logging; semantic retrieval for paraphrased clauses; human-in-the-loop validation for material findings.
- Healthcare — Longitudinal Patient and Guideline Summarization
- Application: Summarize multi-visit EHR histories; extract guideline-relevant criteria from long PDFs; maintain patient-specific notes.
- Workflow/Tool: EHR connector; readChunk over large notes; note/updateNote for durable care summaries; deleteContext to keep prompts within strict budget.
- Assumptions/Dependencies: HIPAA-compliant deployment; integration with EHR systems; domain-tuned retrieval for clinical language; clinician oversight.
- Legal — e-Discovery and Brief Assembly
- Application: Sift large corpora to find evidentiary passages, maintain case-specific notebooks, assemble briefs with cited notes.
- Workflow/Tool: Case Pensieve per matter; buildIndex (BM25/Elasticsearch + embeddings); searchEngine for targeted segments; provenance-preserving deleteContext.
- Assumptions/Dependencies: Secure, auditable note storage; robust citation tracking; configurable deletion stubs retained for chain-of-custody.
- Software — Codebase Understanding and RFC/Design Doc Review
- Application: Navigate large monorepos or technical documentation; extract architecture facts and TODOs; retain developer context across sessions.
- Workflow/Tool: repo indexers; file-level readChunk; updateNote for “architecture notebooks”; deleteContext after reading noisy logs.
- Assumptions/Dependencies: Fast code indexing (ctags/LSP/semantic search); policy on storing code-derived notes; access to private repos.
- Customer Support/CRM — Chat Memory with Accurate Recall
- Application: Maintain long-term customer preferences and issue histories during multi-turn chats; reduce repetition and errors.
- Workflow/Tool: CRM-integrated Pensieve; updateNote per ticket; readNote at session start; automatic deletion of transient context to keep costs low.
- Assumptions/Dependencies: PII handling and encryption; consistent schemas for notes; guardrails to avoid hallucinated preferences.
- Education — Course and Textbook Companions
- Application: Summarize chapters, maintain per-student knowledge notebooks, support multi-hop questions across the textbook.
- Workflow/Tool: Class-specific index; search–read–note–delete per chapter; checkBudget to keep sessions responsive on consumer hardware.
- Assumptions/Dependencies: Licensed content; retrieval tuned for pedagogical queries; teacher oversight for assessment generation.
- Research (Academia/Enterprise) — Literature Review at Scale
- Application: Rapid synthesis of long papers; cross-document evidence linking for systematic reviews; deep browsing tasks.
- Workflow/Tool: Corpus index + iterative readChunk; note/updateNote to build durable “review matrices”; context pruning via deleteContext after distillation.
- Assumptions/Dependencies: Quality of retrieval for implicit evidence; citation and quote accuracy checks; domain adaptation for terminology.
- LLMOps — Cost and Latency Reduction via Context Pruning
- Application: Cut token I/O by maintaining “sawtooth” context; keep prompts compact while sustaining accuracy.
- Workflow/Tool: drop-in “Sawtooth Context Manager” middleware around existing LLM pipelines; automated deleteContext hooks; checkBudget telemetry.
- Assumptions/Dependencies: Support for tool-calls and system prompts; logging to validate savings; careful tuning to avoid over-pruning.
- Personal Knowledge Management (PKM) — Email/Document Digest
- Application: Summarize mail threads, distill action items, maintain topic notebooks; declutter prompts by deleting raw text once distilled.
- Workflow/Tool: Inbox indexer; note/updateNote to a personal Pensieve; readNote at task start; deleteContext for stale content.
- Assumptions/Dependencies: User consent; connectors (IMAP/Gmail/Drive); local/on-device modes for privacy.
Long-Term Applications
The following opportunities require further research, scaling, safety validation, or productization beyond current releases. They build on the same Pensieve paradigm and stateful reasoning loop.
- Cross-Session, Lifelong Memory Agents
- Application: Assistants that persist and evolve memory across months/years, adapting to user/team needs.
- Workflow/Tool: Memory OS with schema evolution, versioning, decay/refresh policies; automated “memory governance.”
- Assumptions/Dependencies: Robust summarization fidelity over long horizons; consent and data retention policies; mechanisms to edit/forget memories safely.
- Trustworthy Summarization with Verification
- Application: Verifiable notes where each distilled fact links to sources and can be rechecked.
- Workflow/Tool: Note provenance graphs; “re-verify” tool; calibrated deletion that retains minimal stubs for audit; confidence scoring pipelines.
- Assumptions/Dependencies: Reliable semantic retrieval; factuality metrics; auditor endpoints; standards for provenance metadata.
- Advanced Search Integration (Semantic + Symbolic)
- Application: Superior performance on implicit queries and multi-hop reasoning beyond BM25.
- Workflow/Tool: Hybrid retrievers (dense+BM25), query planning, reasoning-aware search; tool-use policy learning via RLHF/RLAIF.
- Assumptions/Dependencies: High-quality training data for implicit questions; scalable vector DB infra; reward design for search quality.
- Domain-Specific Clinical Decision Support
- Application: State-aware assistants for guideline navigation, longitudinal risk scoring, and case synthesis.
- Workflow/Tool: Medical Pensieve with ontologies (SNOMED/ICD), evidence grading, safety-critical deletion policies.
- Assumptions/Dependencies: Regulatory validation (FDA/CE), clinical trials/sandboxing, bias/harms assessment, explainability.
- Regulatory Policy Analysis at Government Scale
- Application: Analyze large legislative archives, comment corpora, and regulatory impact statements.
- Workflow/Tool: Policy Pensieve with public records index; multi-stakeholder notes; transparent pruning and audit logs.
- Assumptions/Dependencies: Public data normalization; FOIA compliance; impartiality and transparency tooling; governance frameworks.
- Robotics and Long-Horizon Planning
- Application: Agents that manage procedural memory (plans, constraints, maps) while pruning raw sensor logs.
- Workflow/Tool: Multimodal Pensieve (text+vision); task-phase notes; plan-update/deleteContext across execution phases.
- Assumptions/Dependencies: Reliable perception→text distillation; synchronization with planners; safety validation in closed-loop control.
- Collaborative Team Pensieves
- Application: Shared, stateful memory for projects across departments (engineering, product, legal).
- Workflow/Tool: Role-based note permissions; conflict resolution; memory merge/diff; governance dashboards.
- Assumptions/Dependencies: Access control, auditability, policy for redaction/retention; interoperability across tools (Jira, Git, Docs).
- Energy/Infrastructure Operations Intelligence
- Application: Summarize and retain insights from long incident logs, SCADA alerts, and maintenance histories.
- Workflow/Tool: Time-series-aware indexing; anomaly notebooks; deletion stubs for traceability; cross-incident linking.
- Assumptions/Dependencies: Secure connectors; domain retrievers; incident labeling for RL rewards; human operator review.
- Personalized Education with Curricular Memory
- Application: Tutors that adapt over semesters, tracking progress, misconceptions, and personalized interventions.
- Workflow/Tool: Student Pensieve with skill graphs; spaced-repetition notes; pruning policies to avoid bias persistence.
- Assumptions/Dependencies: Fairness controls; educator oversight; data protection for minors; evaluation against learning outcomes.
- Autonomous Deep Research Platforms
- Application: End-to-end research agents conducting iterative web/search exploration, distillation, and synthesis.
- Workflow/Tool: Browsing tool suites; research notebooks with hypothesis tracking; dynamic deletion to manage very long trajectories.
- Assumptions/Dependencies: High-coverage web retrieval; robust anti-hallucination measures; citation fidelity; scaled RL with verifiable rewards.
- Safety, Privacy, and Memory Governance Tooling
- Application: Enterprise-grade controls for what is stored, for how long, and how summaries can be edited or expunged.
- Workflow/Tool: Memory DLP, redaction, consent capture, retention schedules, “right to be forgotten” workflows.
- Assumptions/Dependencies: Policy alignment (GDPR/CCPA/HIPAA); secure audit trails; user interfaces for memory management.
- Model and Toolchain Standardization
- Application: Interoperable “Pensieve APIs” across LLM vendors for notes, indexing, deletion, budget reporting.
- Workflow/Tool: Open standards for memory operations; SDKs; telemetry for context budgets and tool-call health.
- Assumptions/Dependencies: Ecosystem buy-in; cross-model compatibility; benchmarks for stateful reasoning quality.
- On-Device, Privacy-Preserving Pensieves
- Application: Local assistants that maintain durable memory without cloud sharing (phones, laptops).
- Workflow/Tool: Lightweight indexers; quantized StateLM variants; encrypted local notebooks; offline checkBudget.
- Assumptions/Dependencies: Efficient models (≤8–14B quantized); UX for memory edit/forget; secure storage.
- Continuous Self-Improvement via RL in the Wild
- Application: Agents that refine context-management strategies from real usage while respecting safety constraints.
- Workflow/Tool: GRPO/RLAIF pipelines with task-aware rewards; snapshot sampling; drift detection.
- Assumptions/Dependencies: Safe online learning protocols; strong reward signals; opt-in data; monitoring for regressions.
Notes on feasibility across all applications:
- Deliberate training matters: the paper shows agentic prompts alone underperform; SFT+RL is needed for robust context management.
- Retrieval quality is a key dependency: BM25 limitations on implicit queries suggest hybrid or learned retrievers for best results.
- Privacy, auditability, and provenance are essential whenever deletion and distillation occur; stubs and source links help trust.
- Context windows of ≥32K are sufficient for many deployments when combined with “sawtooth” pruning, delivering cost/latency benefits.
Glossary
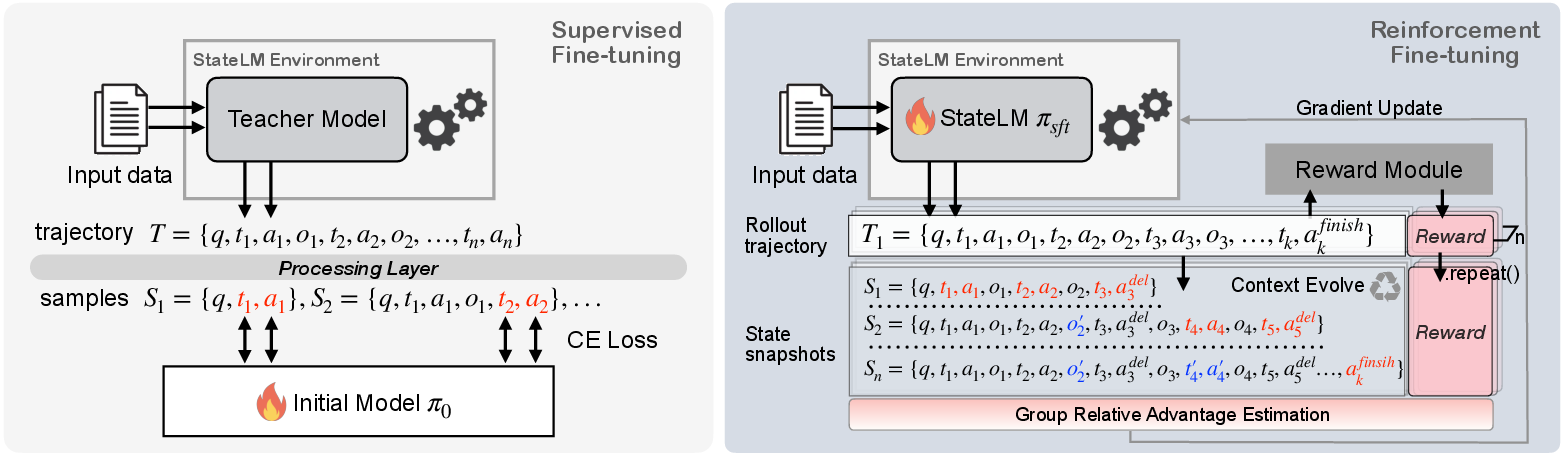
- advantage: In reinforcement learning, the relative performance of an action compared to a baseline, used to reduce variance in policy gradients. "Given this outcome reward, the advantage is computed using a group-based baseline formed across samples from multiple rollout trajectories."
- agentic: Describing LLMs or systems that can actively plan and take tool-using actions, rather than passively predicting text. "StateLM also surpasses prior agentic methods under identical context budgets."
- append-only record: A data structure or log that only grows by appending new entries and never removes old ones. "Rather than treating the interaction state as an append-only record, we endow the policy with the ability to actively control which past elements remain visible."
- BM25-based keyword retrieval: A classical information retrieval ranking function used to score and retrieve documents by keyword relevance. "The current BM25-based keyword retrieval often misses evidence for implicit or paraphrased queries due to limited semantic coverage."
- BrowseComp-Plus: A deep research benchmark evaluating iterative search and reasoning abilities of agents. "On the deep research task BrowseComp-Plus, the performance gap becomes even more pronounced:"
- chat templating function: A function that serializes an interaction state into a tokenized prompt with roles, system instructions, and tool specs. "the LLM operates on a textual prompt obtained by applying a chat templating function "
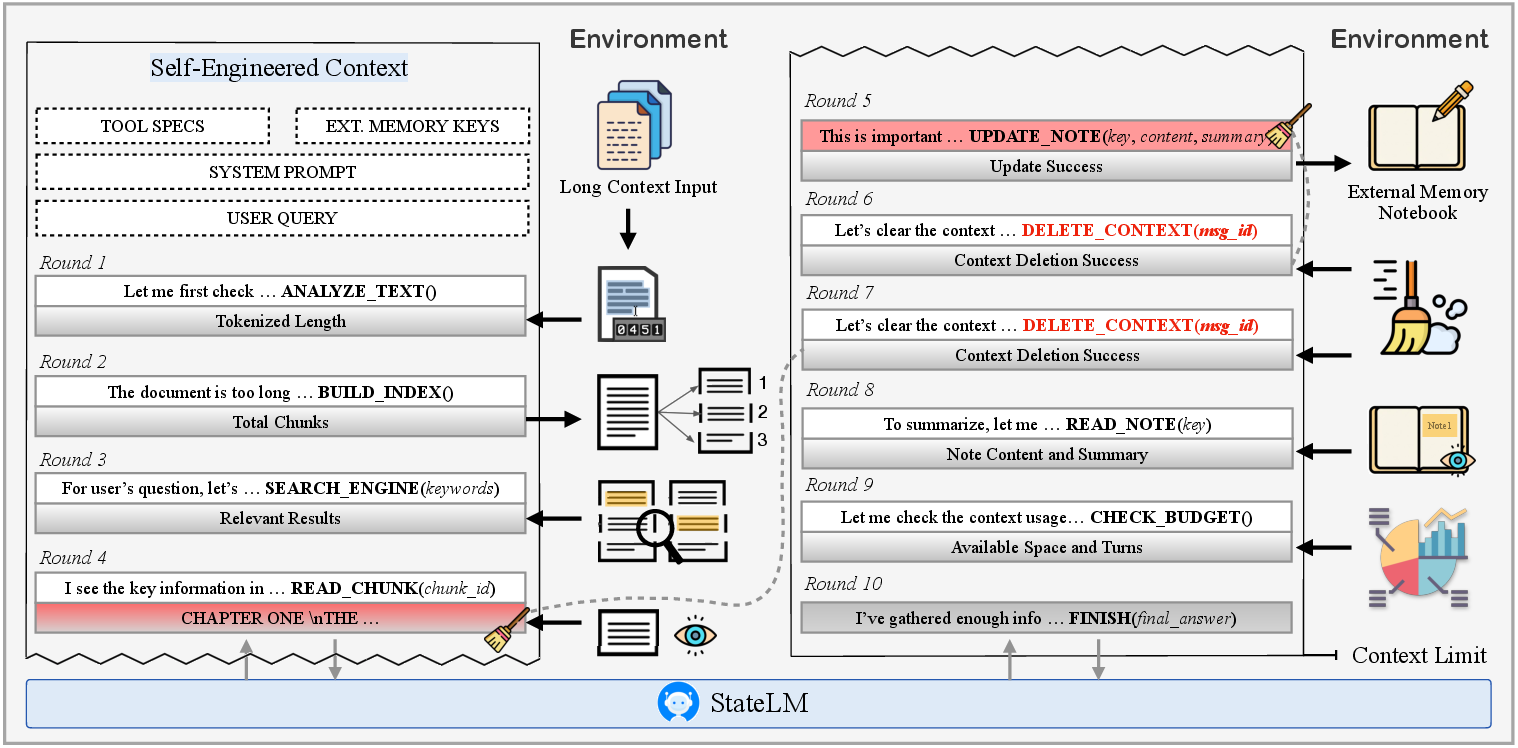
- checkBudget: A tool/action that reports the remaining interaction or context capacity to the model. "Throughout the interaction, checkBudget provides explicit feedback on the remaining context capacity."
- context budget: The fixed limit on how many tokens can be kept in the model’s active prompt. "Earlier reasoning steps and raw tool outputs persist in the prompt and continuously consume the model's fixed context budget, eventually leading to context exhaustion and performance degradation."
- context engineering: The practice of carefully selecting and arranging information in the prompt to guide model behavior. "This paradigm of external control is defined by Andrej Karpathy as ``context engineering'':"
- context exhaustion: The failure mode where accumulated tokens exceed the model’s prompt capacity, harming performance. "Earlier reasoning steps and raw tool outputs persist in the prompt and continuously consume the model's fixed context budget, eventually leading to context exhaustion and performance degradation."
- context window: The maximum number of tokens a model can condition on at once. "Frameworks like MemGPT~\citep{packer2024memgptllmsoperatingsystems} and MemOS~\citep{li2025memosoperatingmemoryaugmentedgeneration} introduce operating-system-like memory hierarchies to page information in and out of the context window."
- context-management actions: Explicit operations that modify what parts of the interaction history remain visible to the model. "StateLM may emit context-management actions of the form"
- context pruning: Removing non-essential or redundant content from the working prompt to stay within budget. "We equip our model with a suite of memory tools, such as context pruning, document indexing, and note-taking"
- cross-entropy loss: A standard loss function for classification and language modeling that measures divergence between predicted and target distributions. "the cross-entropy loss is computed only over the tokens of the final assistant turn corresponding to step ."
- deleteContext: A tool/action that removes selected past messages from the visible prompt. "The cornerstone of this mechanism is the deleteContext tool"
- dense retriever: A neural retrieval component that maps queries and documents into a vector space to retrieve by semantic similarity. "using a dense retriever to search a vector database (the Pensieve) for relevant text chunks"
- document indexing: Building a searchable structure over a long text to enable targeted retrieval of segments. "We equip our model with a suite of memory tools, such as context pruning, document indexing, and note-taking"
- environment dynamics: The rules governing how the environment responds to agent actions in an interaction loop. "The environment then returns an observation , where denotes the environment dynamics."
- finish action: A termination tool/action signaling the end of reasoning and outputting the final answer. "The episode terminates when the model determines that the accumulated notes are sufficient and emits the finish action."
- GRPO-style objective: A reinforcement learning objective related to group-relative policy optimization for updating policies from rollouts. "The training algorithm builds on a GRPO-style objective, with adaptations specific to StateLM"
- group-based baseline: A baseline computed from a group of samples (e.g., trajectories) to stabilize advantage estimation. "the advantage is computed using a group-based baseline formed across samples from multiple rollout trajectories."
- interaction state: The structured record of the query, past actions, and observations that the agent conditions on. "At each round , the agent conditions on an interaction state"
- long-horizon: Referring to tasks or settings with many sequential steps, requiring extended reasoning and memory. "this monotonic accumulation becomes a critical limitation in long-horizon settings."
- monotonic accumulation: A pattern where context only grows over time without deletion, often leading to overflow. "StateLM (right) maintains a ``sawtooth'' context-use profile, rather than monotonic accumulation (left)."
- Needle-in-a-Haystack: A benchmark setup embedding a small key fact within very long distractor text to test retrieval. "we follow the Needle-in-a-Haystack setup from prior work"
- note-taking: Writing distilled summaries or key facts into an external memory for later reuse. "We equip our model with a suite of memory tools, such as context pruning, document indexing, and note-taking"
- Outcome-based Reject Sampling: A data filtering strategy that keeps only trajectories producing correct final answers. "Outcome-based Reject Sampling."
- Pensieve paradigm: A design using persistent external memory plus deletion operations to manage context like extracting and storing distilled notes. "The core mechanism enabling this transformation for the agentic loop is the Pensieve paradigm"
- policy: In RL/decision-making, the mapping from states to action distributions that the agent samples from. "we endow the policy with the ability to actively control which past elements remain visible."
- Process-based Reject Sampling: A filtering strategy that removes trajectories with poor intermediate behavior even if final answers are correct. "Process-based Reject Sampling."
- RAG: Retrieval-Augmented Generation; a pipeline that retrieves external text and inserts it into the prompt for generation. "The most prevalent form of context engineering is RAG"
- reinforcement learning fine-tuning: Post-SFT training where the model improves via trial-and-error guided by rewards. "we employ reinforcement learning fine-tuning to further improve StateLMs"
- rollout trajectories: Full sequences of generated actions and observations sampled from the current policy during RL training. "After collecting the rollout trajectories, we assign a scalar reward to each trajectory"
- serialization: Converting structured state into a linearized, tokenized prompt form. "For clarity, we omit this serialization step in the subsequent discussion."
- state snapshot: A saved copy of the current interaction state at specific points (e.g., after context edits) for training. "We collect a state snapshot whenever a context-editing action is taken."
- Stateful LLM (StateLM): A LLM that can modify and manage its own context/history during reasoning. "we introduce Stateful LLMs (referred to as StateLMs, or SLMs), a new class of foundation models endowed with a learned capability to self-engineering their context."
- state-update function: A function that transforms the interaction state when new actions and observations occur, including edits. "where is a state-update function that may append new interactions or modify the visible context"
- supervised fine-tuning (SFT): Training initialized models on labeled demonstrations to learn desired behaviors before RL. "Following behavior initialization through supervised fine-tuning, we employ reinforcement learning fine-tuning"
- tool invocation: Executing a specified external tool/function as part of the model’s action. "Each action consists of a natural-language reasoning trace followed by either a tool invocation or a termination signal."
- vector database: A storage system that indexes embeddings to enable similarity search over large text corpora. "using a dense retriever to search a vector database (the Pensieve) for relevant text chunks"
- YaRN: A method for extending usable context length (e.g., via rope scaling) to larger token windows. "we utilize YaRN~\citep{peng2023yarn} to obtain the recommended 128K context window for both StateLM and the Qwen3 instruct baselines."
Collections
Sign up for free to add this paper to one or more collections.

