MemoryLLM: Plug-n-Play Interpretable Feed-Forward Memory for Transformers
Abstract: Understanding how transformer components operate in LLMs is important, as it is at the core of recent technological advances in artificial intelligence. In this work, we revisit the challenges associated with interpretability of feed-forward modules (FFNs) and propose MemoryLLM, which aims to decouple FFNs from self-attention and enables us to study the decoupled FFNs as context-free token-wise neural retrieval memory. In detail, we investigate how input tokens access memory locations within FFN parameters and the importance of FFN memory across different downstream tasks. MemoryLLM achieves context-free FFNs by training them in isolation from self-attention directly using the token embeddings. This approach allows FFNs to be pre-computed as token-wise lookups (ToLs), enabling on-demand transfer between VRAM and storage, additionally enhancing inference efficiency. We also introduce Flex-MemoryLLM, positioning it between a conventional transformer design and MemoryLLM. This architecture bridges the performance gap caused by training FFNs with context-free token-wise embeddings.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces MemoryLLM, a new way to build and train LLMs so they are easier to understand and more efficient. The authors redesign part of the model called the feed-forward network (FFN) to act like a clear, token-based “memory” that can be studied and even precomputed. They also propose Flex-MemoryLLM, a balanced version that keeps performance high while still offering the benefits of MemoryLLM.
Goals and Questions
The paper asks simple but important questions:
- Can we make the FFN part of a transformer behave like a straightforward memory that answers token-specific queries, without mixing in confusing context?
- If we do that, what does this memory store, how is it accessed by different tokens, and how does it affect performance on different kinds of tasks?
- Can we use this design to make LLMs faster and more memory-friendly during inference (when the model is answering questions), especially on devices with limited VRAM?
- If turning FFNs into memory hurts performance, can we recover that performance while still keeping the interpretability and efficiency benefits?
How It Works (Methods)
Transformers in simple terms
A transformer (the core of many LLMs) processes text in blocks. Each block has two main parts:
- Self-attention: This looks at the current text and decides which words or pieces (“tokens”) matter to each other, like a student looking around the whole paragraph to understand each sentence.
- Feed-forward network (FFN): This applies a learned transformation to the data. The FFN has many parameters (about two-thirds of the model’s total), but its role is less understood.
In standard transformers, FFNs take a mix of the original information plus whatever self-attention adds. That mixture changes layer by layer, so it’s hard to see what exactly the FFN is doing.
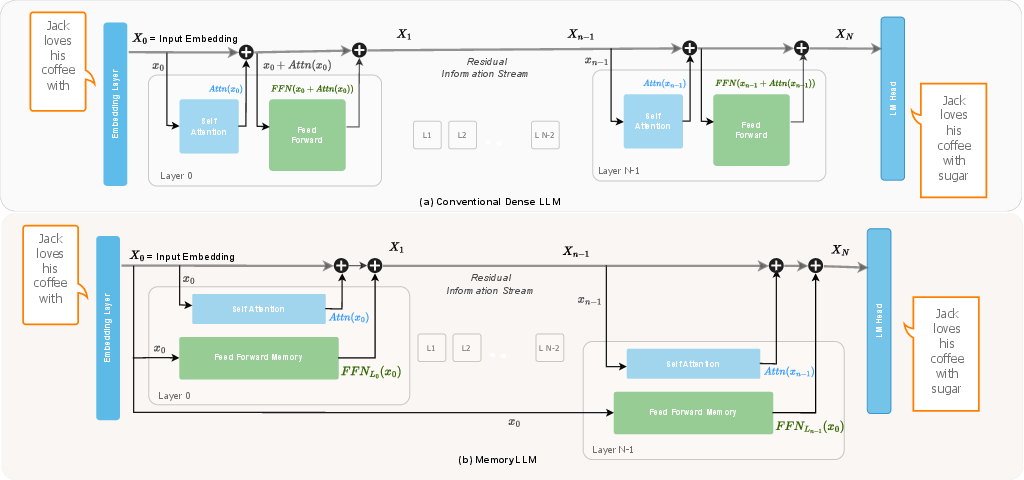
What is MemoryLLM?
MemoryLLM separates the FFN from self-attention. Instead of feeding a changing mixture into the FFN, it feeds the FFN only the static token embeddings—the basic numeric representations of tokens created by the model’s vocabulary. This makes the FFN act like a context-free, token-indexed memory. In each layer:
- Self-attention works as usual on the running “summary” of the text.
- The FFN adds a token-based memory output that depends only on the tokens themselves, not the changing context.
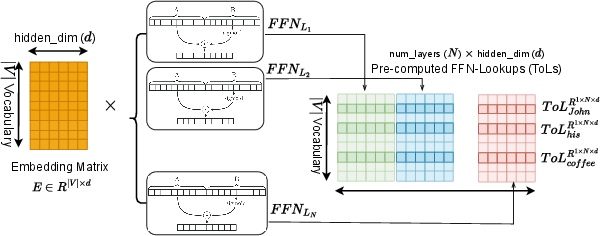
Because the FFN sees only fixed token embeddings, you can precompute its outputs for every token in the vocabulary and store them as token-wise lookups (like a big table). During inference, the model can fetch these precomputed values on demand.
The TKV (Token-Key-Value) idea
The authors propose a simple framework to understand FFN memory:
- Think of the FFN as having “keys” and “values,” similar to how a library uses index cards (keys) that point to facts (values).
- Each token acts as a “query” to this memory.
- Keys come from one FFN matrix (often called the up-projection), values from another (down-projection), and a third matrix (the gate) reweights which keys matter for a token.
- The final FFN output for a token is like a weighted combination of values—where weights depend on how well the token “matches” the keys.
Because MemoryLLM uses fixed token embeddings, the query space is clear and finite: it’s the model’s vocabulary. That makes the FFN’s memory easier to study.
Making FFNs into lookups
Since the FFN in MemoryLLM depends only on token embeddings, you can:
- Precompute the FFN outputs for every token across all layers once.
- Store them as token-wise lookups (ToLs) on disk or other storage.
- Load only the most frequent tokens into fast memory (VRAM) and fetch others on demand. This works well because real text follows Zipf’s law: a small number of tokens appear very often, while most tokens are rare.
This design reduces computation and VRAM use during inference, making models more practical on smaller devices.
Flex-MemoryLLM: Bridging performance and interpretability
Turning FFNs entirely into memory can reduce performance compared to a standard transformer with the same total number of parameters. To fix this, the authors introduce Flex-MemoryLLM:
- Split the FFN into two parts:
- FFN-M (memory): still the token-based, context-free memory.
- FFN-C (compute): a standard FFN that operates on the changing context, boosting model capacity.
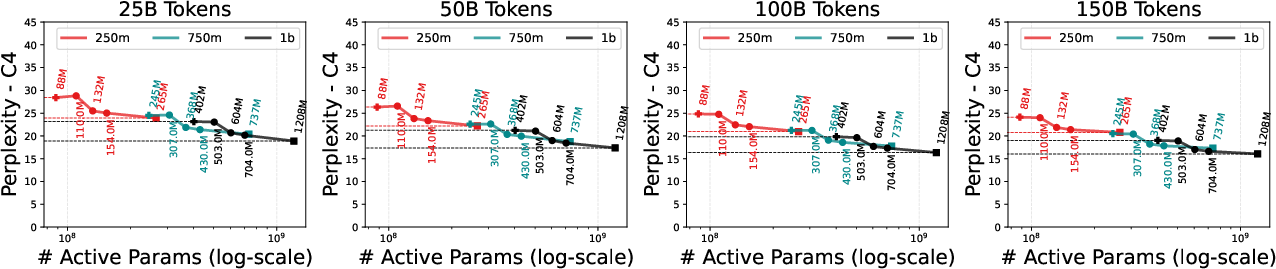
- By adjusting how many parameters go to FFN-M vs. FFN-C, you can balance interpretability and efficiency with performance. The paper shows that with a good split, Flex-MemoryLLM gets close to standard transformer performance while still reducing active parameters and keeping the memory benefits.
Key Findings
The paper reports several important results:
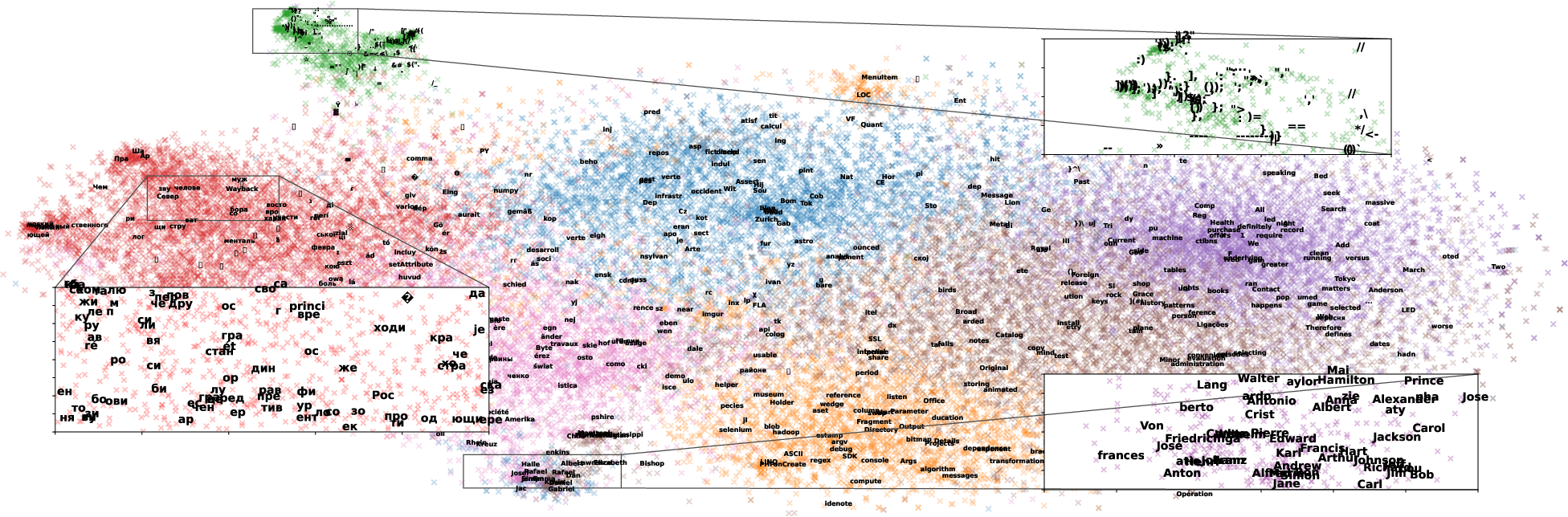
- Similar tokens tend to use similar “keys” in the FFN memory. For example, punctuation, names, and places cluster together in the memory, suggesting the FFN stores organized, interpretable knowledge.
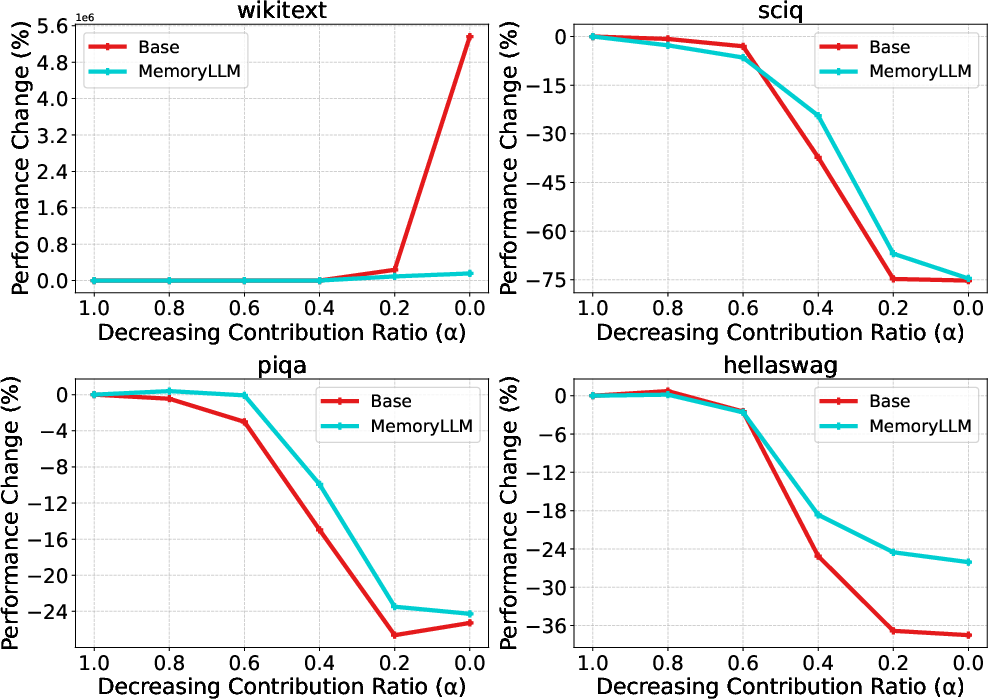
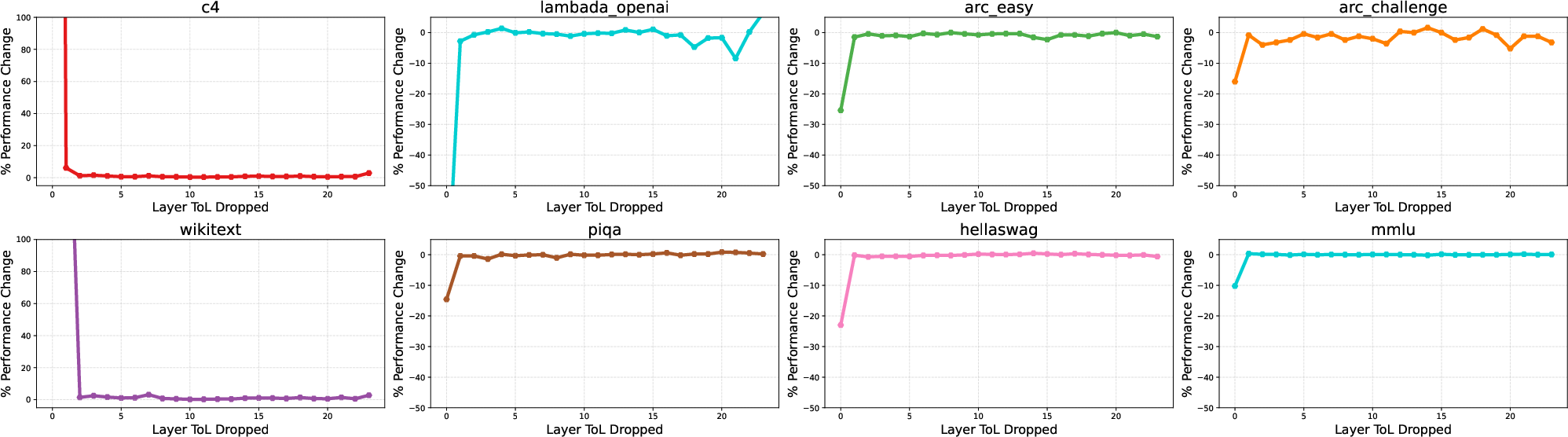
- FFN memory matters more for tasks that require recalling facts or known information (like wikitext or certain QA datasets) than for tasks that need reasoning or logic (like HellaSwag or Winogrande). When the authors reduce the FFN’s contribution, recall-heavy tasks degrade more than logic-heavy tasks.
- Precomputing FFN outputs as token-wise lookups can significantly reduce VRAM and computation during inference, without breaking the model’s flow.
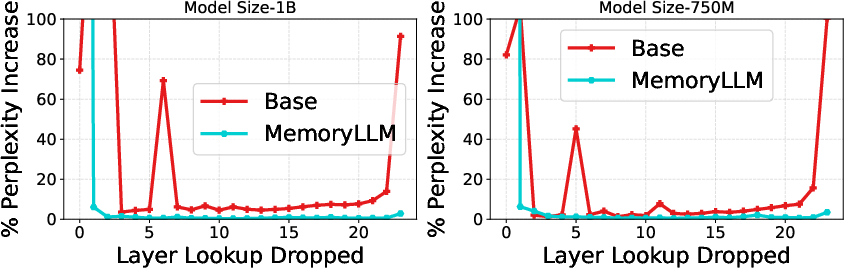
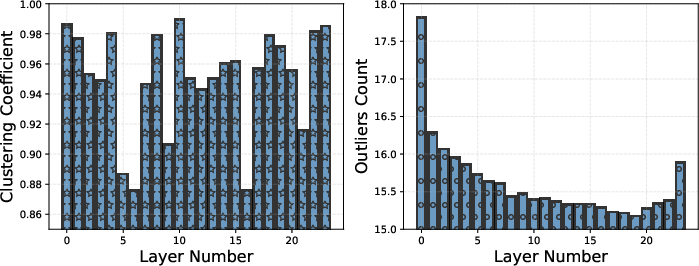
- Not all layers’ FFN memory is equally important. Early layers contribute more in MemoryLLM, and later layers can sometimes be offloaded with little impact, helping further reduce memory usage.
- Flex-MemoryLLM narrows the performance gap with standard transformers. With well-chosen splits, it can closely match or even surpass dense models at the same active parameter counts.
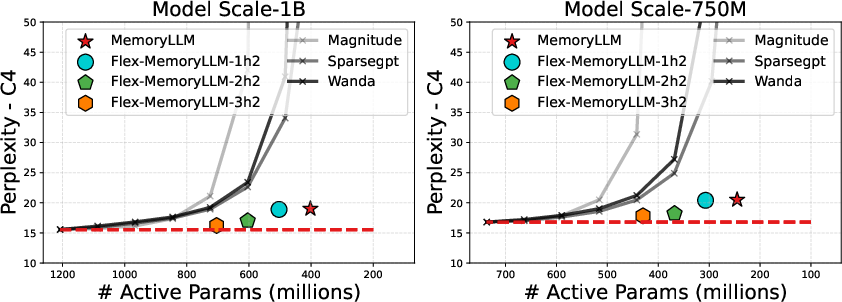
- Compared to training a normal model and then pruning it to reduce parameters, MemoryLLM and Flex-MemoryLLM achieve better performance at the same number of active parameters. This suggests designing for memory and efficiency from the start can beat pruning later.
Why It Matters (Implications)
This research shows a practical and understandable way to treat part of an LLM as a token-based memory:
- It helps researchers and engineers see what the FFN stores and how tokens access it, improving interpretability.
- It enables faster, cheaper inference by precomputing and offloading FFN outputs, which is valuable for phones, laptops, or edge devices with limited VRAM.
- It clarifies that FFN memory is especially important for recall tasks, guiding future model design: use FFN memory for stored knowledge and let self-attention and compute handle reasoning.
- Flex-MemoryLLM offers a flexible path to high performance without giving up the benefits of token-based memory, suggesting new standards for building efficient, transparent LLMs.
- Overall, the work points toward LLMs that are not only powerful but also easier to understand, control, and deploy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps and open questions that remain unresolved in the paper and could guide future research.
- Scalability beyond 1B parameters: Assess whether MemoryLLM and Flex-MemoryLLM retain their interpretability, efficiency, and performance advantages at larger scales (e.g., 7B–70B+) and with longer contexts.
- End-to-end efficiency quantification: Provide rigorous measurements of end-to-end latency, throughput, and energy for ToL-based inference (including PCIe/NVMe bandwidth limits, prefetch latency, cache miss penalties, and batch-size effects) on real hardware.
- Storage footprint and bandwidth budgeting: Quantify the total ToL storage size for , layers, and hidden size (e.g., GB/TB), and determine the IO bandwidth required to avoid becoming memory-bound at inference time.
- ToL compression strategies: Explore quantization, low-rank factorization, token clustering, and layer-sharing for ToLs to reduce storage/IO without hurting accuracy; provide empirical trade-offs.
- Cache policy design: Systematically evaluate token-frequency–aware caching (Zipf-based), eviction policies, and prefetch heuristics; quantify hit-rate vs performance curves and cold-start penalties for rare tokens.
- Training stability at scale: Analyze optimization dynamics and convergence when FFNs are trained on context-free embeddings only; ablate the necessity and form of per-layer layer norms (); test for gradient conflicts between attention and FFN branches.
- In-context learning (ICL) and few-shot prompting: Measure how context-free FFNs affect ICL, instruction following, chain-of-thought, and compositional generalization relative to conventional transformers.
- Broader evaluation coverage: Extend beyond perplexity and a few benchmarks to include MMLU, BBH, GSM8K, HumanEval, long-context reasoning, non-English tasks, and open-ended generation quality (including human evaluations).
- Knowledge editing and updates: Develop concrete methods to locate, edit, and evaluate specific FFN “memory cells” (keys/values) for targeted knowledge updates; study interference, locality, and unintended side effects post-edit.
- Continual and domain-adaptive learning: Devise procedures to update ToLs (and/or FFN-M) for new domains or newly introduced vocabulary without full retraining; measure stability and catastrophic forgetting.
- Tokenizer dependence: Quantify how different tokenizers (BPE vs SentencePiece vs byte-level) impact FFN memory quality, ToL size, interpretability, and cross-lingual generalization; explore OOV handling and tokenizer changes post-training.
- Rare token handling: Investigate strategies to mitigate poor performance on rare tokens (e.g., shared memory cells, smoothing, backoff to subtoken composition); report targeted evaluations.
- Inter-layer redundancy and sharing: Measure redundancy of FFN-M across layers and explore shared or factorized memory across layers to reduce total ToL size and training cost.
- Gating sparsity/control: Introduce and test regularizers to induce sparsity or structured activation in (e.g., entropy penalties, top-k gating), and quantify the trade-off between interpretability and performance.
- Capacity and theoretical analysis: Formalize the capacity of FFN-M as a function of , , and ; derive or empirically validate scaling laws for memory capacity, interference, and generalization.
- Interaction with attention: Characterize how moving contextual computation to attention impacts gradient flow, layer-wise contributions, and representation synergy; identify optimal balancing (or schedules) between FFN-C and FFN-M.
- Flex-MemoryLLM design guidance: Provide principled criteria to choose (split between FFN-C and FFN-M) for a given compute/memory budget and task profile; explore dynamic reallocation during training.
- Comparison to MoE/RAG: Benchmark MemoryLLM/Flex-MemoryLLM directly against MoE and retrieval-augmented baselines on knowledge-intensive tasks, including cost-normalized performance and interpretability comparisons.
- Robustness and safety: Evaluate adversarial robustness (prompt injection, jailbreaks), toxicity/bias concentration in FFN-M, and test whether targeted memory edits can mitigate harms without collateral damage.
- Privacy and security of ToLs: Assess risks of exfiltration or membership inference from on-disk ToLs; study encryption, secure enclaves, and authenticated IO to protect parametric memory during deployment.
- Alignment and post-training: Examine how SFT/DPO/RLHF affects FFN-M vs FFN-C; determine whether alignment objectives distort or overwrite memorized knowledge and how to guard against it.
- Long-context behavior: Test performance and scaling for 32k–1M token contexts; characterize whether pushing context-dependence to attention alone degrades long-context reasoning or retrieval.
- Integration with KV caching: Analyze interactions between ToL prefetching and attention KV caches (memory layout, bandwidth contention, scheduling); propose joint optimization strategies.
- Training-time compute and memory: Report training-time resource usage and throughput when FFNs are decoupled; assess whether the approach reduces or increases training cost relative to dense and MoE baselines.
- Post-finetune ToL maintenance: Quantify the cost of recomputing ToLs after finetuning and propose incremental update methods to avoid full re-precomputation.
- Fair pruning/compression baselines: Compare to state-of-the-art pruning with retraining/fine-tuning, low-rank/sparse hybrids, and quantization-aware training under matched active-parameter and training budgets.
- Failure mode analysis: Provide qualitative error analyses (e.g., where static memory misleads attention or harms compositional generalization) to guide targeted architectural or training fixes.
- Multimodal extension: Explore whether token-indexed FFN memory can extend to multimodal LMs (e.g., image/vision tokens), and how ToLs interact with modality-specific tokenization and embeddings.
- License and reproducibility: Release code, training configs, and checkpoints, and provide detailed hyperparameters (e.g., , gating setup, optimizer settings) to enable rigorous replication and ablation studies.
Glossary
- ARC-Easy: A multiple-choice question answering benchmark focusing on elementary-level science. "ARC-Easy()"
- Attn (self-attention): The transformer mechanism that computes weighted context from input sequences via query-key-value projections. "self-attention (Attn)"
- BoolQ: A yes/no reading comprehension benchmark assessing factual understanding. "BoolQ()"
- C4: A large cleaned web text dataset commonly used for LLM pretraining and evaluation. "C4"
- Clustering coefficient (CC): A metric indicating how strongly items (here, token memory patterns) form clusters. "empirically quantify it with the clustering coefficient (CC)"
- Down-projection: The value matrix in SwiGLU FFNs that maps expanded hidden states back to model dimension. "down-projection ()"
- FFN (feed-forward network): The per-token MLP component in transformers that transforms representations independently from attention. "FFNs, while holding approximately two-thirds of the LLMs' parameters, have been relatively underexplored"
- FFN Compute (FFN-C): The portion of Flex-MemoryLLM’s FFN that operates on the residual flow to increase computational capacity. "FFN Compute (FFN-C): a linear dense module which operates on residual flow and increases the computational capability of MemoryLLM"
- FFN Memory (FFN-M): The context-free, token-indexed memory part of Flex-MemoryLLM trained directly on embeddings. "FFN Memory (FFN-M): a context-free neural memory similar to FFNs in MemoryLLM trained with token embeddings with no connection to residual flow"
- Flex-MemoryLLM: A hybrid architecture that partitions FFN parameters into compute and memory components to bridge performance and interpretability. "We also introduce Flex-MemoryLLM, positioning it between a conventional transformer design and MemoryLLM."
- Gate-projection: The gating matrix in SwiGLU FFNs that modulates the contribution of keys/values during memory retrieval. "gate-projection ()"
- HellaSwag: A commonsense reasoning benchmark requiring selection of plausible continuations. "HellaSwag()"
- Interpolation scaler: A scalar that linearly scales FFN contribution to study its impact on performance. "we control the contribution of FFNs with an interpolation scaler as "
- K-Means clustering: An unsupervised method to group tokens by similar memory key contributions. "t-SNE plot with K-Means clustering of vectors"
- Key-value memory: A representation where FFN parameters act as keys and values enabling content-addressable retrieval. "FFNs in pretrained LLMs serve as neural key-value memory"
- LAMBDA: A benchmark (often language understanding) used to evaluate retrieval or recall capabilities. "LAMBDA()"
- LayerNorm: Layer normalization applied to token embeddings before FFN memory computation. ""
- LLaMa-3.1 tokenizer: The tokenization system used to map text into discrete token IDs for the study. "for a large-scale LLaMa-3.1 tokenizer \citep{grattafiori2024llama}"
- Magnitude (pruning): A pruning technique that removes parameters with the smallest absolute values. "three pruning techniques (Magnitude, SparseGPT, Wanda)"
- MemoryLLM: A transformer variant with FFNs trained context-free on token embeddings, interpreted as neural memory and enabling precomputed lookups. "MemoryLLM achieves context-free FFNs by training them in isolation from self-attention directly using the token embeddings."
- Mixture-of-experts (MoE): An architecture that routes inputs to specialized expert networks, often via a learned router. "in mixture-of-experts (MoE)"
- MoLE: A specific MoE approach showing many experts can be trained directly on token-level embeddings. "MoLE \citep{jie2025mixture} illustrates that in mixture-of-experts (MoE), the majority of experts can be trained directly with token-level input embeddings."
- Outlier coefficients: Dominant key weights in FFN memory contributing disproportionately to the retrieved output. "Since, outlier coefficients dominate in building memory output"
- Perplexity (PPL): A measure of LLM uncertainty; lower values indicate better predictive performance. "Percentage increase in perplexity when FFN computation for layer is dropped in and MemoryLLM."
- PIQA: A physical commonsense reasoning benchmark focused on procedural knowledge. "PIQA()"
- Plug-n-Play (PnP): A design enabling on-demand loading/unloading of precomputed FFN memory between storage and VRAM. "plug-n-play (PnP) memory transfer from storage devices under resource constraints."
- Residual flow: The additive pathway accumulating outputs across transformer components; disruption affects model performance. "doesn't disrupt the residual flow as significantly as model"
- Residual information flow perspective: A viewpoint that tracks how information accumulates through residual additions across layers. "illustrates a residual information flow perspective \citep{elhage2021mathematical}"
- Residual stream: The running representation passed through layers to which attention and FFN outputs are added. "adds it back to the residual stream"
- Router (MoE): The component that selects experts based on context, often using self-attention outputs. "from a router trained with self-attention output."
- SiLU: The Sigmoid Linear Unit activation function used within SwiGLU FFNs. "$\mathrm{SiLU}\!\left(\tilde{X}_L W_{\mathrm{Gate}^\top\right)$"
- SiQA: A social commonsense reasoning benchmark involving everyday situations. "SiQA()"
- SparseGPT: A pruning method tailored to LLMs for efficient sparsification. "three pruning techniques (Magnitude, SparseGPT, Wanda)"
- SwiGLU: A gated linear unit variant combining SiLU with linear gating in FFNs. "SwiGLU \citep{Shazeer2020GLUVI} based FFNs in modern LLMs"
- t-SNE: A dimensionality reduction technique used for visualizing token memory clusters. "t-SNE plot with K-Means clustering"
- TKV (token-key-value) framework: A scheme interpreting FFN up/down projections as keys/values accessed by token queries. "We present a TKV (token-key-value) framework to investigate how FFNs construct a persistent context-free memory over the model's vocabulary."
- Token-wise lookups (ToLs): Precomputed FFN outputs indexed by token that can be stored and fetched during inference. "pre-computed as token-wise lookups (ToLs)"
- Up-projection: The key matrix in SwiGLU FFNs expanding inputs to a higher-dimensional space for retrieval. "up-projection ()"
- VRAM: GPU memory used during inference; MemoryLLM allows offloading FFN memory to reduce VRAM usage. "on-demand transfer between VRAM and storage"
- Wanda: A pruning approach evaluated against MemoryLLM and Flex-MemoryLLM baselines. "three pruning techniques (Magnitude, SparseGPT, Wanda)"
- Wikitext-2: A standard language modeling dataset used for perplexity evaluation. "Wikitext-2"
- Zipf's law: The empirical distribution where a few tokens occur very frequently and many occur rarely. "The token distribution of modern LLM-generated content adheres to Zipf's law irrespective of tokenizer"
Practical Applications
Immediate Applications
The paper introduces MemoryLLM and Flex-MemoryLLM, enabling context-free, token-indexed FFN memory and precomputed token-wise lookups (ToLs). These capabilities can be deployed now in several concrete settings:
- VRAM- and latency-efficient LLM inference on edge and cloud
- Sector: software, mobile/edge AI, automotive, AR/VR, IoT
- Use cases:
- Serve LLMs on GPUs with tight VRAM by offloading FFN outputs as ToLs to SSD/NVMe and caching frequent tokens (Zipf-aware caching).
- Ship compressed “memory packs” (ToLs) with on-device assistants (smartphones, headsets) to reduce active parameters and energy use.
- Scale cloud throughput by reducing active parameters per instance; more sessions per GPU at similar latency.
- Potential tools/workflows: ToL precomputation pipeline; ToL quantization and packing; a runtime ToL cache manager with LRU/Zipf predictors; layer-wise FFN drop/toggle controller.
- Assumptions/dependencies: Storage bandwidth sufficient for ToL streaming; stable tokenizer; acceptable accuracy trade-offs for some tasks; integration into existing inference stacks (vLLM/TensorRT/etc.).
- Modular “plug-n-play” memory management for deployment
- Sector: MLOps, enterprise software
- Use cases:
- Dynamically load/unload FFN memory for later layers with minimal performance degradation, based on observed lower FFN importance in later layers.
- Offer SKUs with tiered memory profiles (e.g., “full memory,” “lite memory”) by selecting which ToLs to keep in VRAM.
- Potential tools/workflows: Memory policy engine that measures layer/token access patterns; hot-swappable ToL bundles per domain; alpha-scaling knob for FFN contribution.
- Assumptions/dependencies: Monitoring of cache hit rates and latency; careful evaluation on target workloads.
- Domain-specialized memory overlays (“memory packs”)
- Sector: healthcare, legal, finance, enterprise search, software engineering
- Use cases:
- Build domain-specific ToLs aligned to vocabulary (e.g., ICD codes, legal citations, tickers) to improve recall-heavy tasks (QA, entity grounding, summarization).
- Customize enterprise LLMs by training or fine-tuning only FFN-M on domain lexicons without retraining full models.
- Potential tools/workflows: Domain tokenizer maps; ToL construction and validation suites; pack/merge tools with conflict resolution.
- Assumptions/dependencies: Availability of high-quality domain text and vocabulary; robust evaluation for domain shifts; consistent tokenizer across base and overlays.
- Interpretability and safety audits via the TKV framework
- Sector: AI safety/compliance, academia, regulated industries
- Use cases:
- Token-level mapping of FFN “keys” and “values” to audit memorized knowledge, identify clusters (names, locations) and assess privacy risks.
- Targeted mitigation of toxicity/PII by editing or reweighting specific keys/values rather than blunt filtering.
- Potential tools/workflows: “TKV Inspector” for visualizing distributions, clusters, and per-token contributions; “FFN Memory Editor” for surgical key/value adjustments with regression tests.
- Assumptions/dependencies: Safe editing strategies without destabilizing performance; governance frameworks for audit trails; staff skilled in interpretability.
- Cost-aware model development with Flex-MemoryLLM
- Sector: model development, model providers
- Use cases:
- Train models to a fixed active-parameter budget that still match dense baselines (using FFN-C + FFN-M split).
- Replace conventional pruning baselines with Flex-MemoryLLM to achieve superior PPL vs. active-parameter trade-offs.
- Potential tools/workflows: “Flex-Memory Trainer” that allocates to FFN-C and to FFN-M; automated sweeps to find optimal for given budgets.
- Assumptions/dependencies: Training-from-scratch or early adoption in new training runs; access to comparable training recipes and token budgets.
- Rapid A/B tests of memorization vs reasoning dependence
- Sector: product analytics, safety evaluation
- Use cases:
- Use -scaling of FFN-M contribution to quantify how much a product feature depends on recall vs reasoning; design guardrails accordingly.
- Potential tools/workflows: On-the-fly control in inference to measure task sensitivity (retrieval tasks degrade more as shown).
- Assumptions/dependencies: Monitoring to avoid quality regression in user-facing traffic; offline evaluation first.
- Air-gapped/offline deployments with updateable memory
- Sector: government, defense, industrial
- Use cases:
- Ship ToLs as signed, updatable artifacts for on-prem or offline environments; patch memory (facts) without touching attention weights.
- Potential tools/workflows: Secure ToL packaging, signing, and versioning; differential ToL updates; rollback mechanisms.
- Assumptions/dependencies: Careful compatibility management between base model and ToLs; security-hardening.
- Research and education
- Sector: academia, developer education
- Use cases:
- Course labs on interpretability using token-indexed query space; reproducible studies of clustering, outlier keys, and task sensitivities.
- Potential tools/workflows: Open datasets of vectors; notebooks and dashboards for cluster exploration.
- Assumptions/dependencies: Availability of open weights or research-friendly checkpoints; licensing.
Long-Term Applications
These opportunities are promising but likely require additional research, scaling, tooling, or ecosystem support:
- Hardware–software co-design for ToL-centric inference
- Sector: semiconductors, systems
- Concepts:
- Controllers for high-throughput ToL streaming from flash/NVMe; near-storage compute for aggregation of ToLs; memory-hierarchy optimizations aligned with Zipf distributions.
- Assumptions/dependencies: Vendor support; standardized ToL formats; sustained demand for memory-offloaded LLMs.
- Standards and policy for “memorization audits”
- Sector: policy/regulation, compliance
- Concepts:
- Regulatory requirements for reporting parametric memory footprints and auditability (e.g., right-to-be-forgotten workflows by editing ToL keys/values).
- Assumptions/dependencies: Consensus on audit metrics and methods; legal frameworks recognizing token-level editability as adequate remediation.
- Personalized and privacy-preserving memory overlays
- Sector: consumer AI, enterprise SaaS
- Concepts:
- Per-user or per-tenant ToLs to capture preferences and lexicons without retraining core weights; fast revocation by deleting overlays.
- Assumptions/dependencies: Secure isolation between overlays; latency-neutral overlay composition; privacy guarantees.
- Continual learning and hotfix pipelines via ToL edits
- Sector: model maintenance, knowledge management
- Concepts:
- Push “knowledge patches” (new facts, policy changes) by updating targeted keys; rollback when necessary; CI/CD for memory.
- Assumptions/dependencies: Robust validation to prevent collateral drift; tooling for dependency analysis among keys.
- Hybrid RAG architectures with explicit parametric memory
- Sector: information retrieval, enterprise search
- Concepts:
- Treat ToLs as a fast parametric cache complementing external retrieval; learn routing between FFN-M (parametric recall) and retrievers based on task signatures.
- Assumptions/dependencies: New training curricula and routers; calibration for trade-offs between latency and faithfulness.
- Federated and multi-tenant learning via ToL sharing
- Sector: healthcare, finance, cross-institution collaborations
- Concepts:
- Share or aggregate only memory overlays (ToLs) across sites to avoid raw data exchange; privacy and governance layers atop FFN-M.
- Assumptions/dependencies: Secure aggregation protocols; align tokenizers across participants; legal agreements.
- Safety-by-design through targeted key/value control
- Sector: AI safety, content moderation
- Concepts:
- Proactive suppression of toxic clusters or unsafe categories using interpretable keys; automated detection + mitigation policies.
- Assumptions/dependencies: Reliable mapping from harmful behaviors to specific keys; minimal impact on helpful capabilities.
- Localization and multilingual adaptation by swapping memory packs
- Sector: global products, education
- Concepts:
- Language-specific ToLs for rapid localization; mix-and-match memory packs for dialects or domain vocabularies per region.
- Assumptions/dependencies: Multilingual tokenizers and alignment; cultural/linguistic validation; scalable pack curation.
- Security and provenance for model memory
- Sector: cybersecurity, supply chain
- Concepts:
- Watermark/fingerprint ToLs; detect tampering or unauthorized edits; audit provenance of memory packs in marketplaces.
- Assumptions/dependencies: Robust watermarking schemes; governance and enforcement mechanisms.
- Edge robotics and command understanding with low active parameters
- Sector: robotics, industrial automation
- Concepts:
- Deploy language-driven control on embedded hardware using ToL offload and Flex-MemoryLLM; preserve low-latency instruction following.
- Assumptions/dependencies: Real-time guarantees for ToL streaming; integration with control stacks.
- Sector-specific regulated deployments (e.g., clinical decision support)
- Sector: healthcare, finance
- Concepts:
- Curated, auditable parametric memory aligned to approved vocabularies and guidelines; easier validation and certification due to interpretability.
- Assumptions/dependencies: Rigorous clinical/financial validation; regulatory acceptance of interpretability claims; risk management for residual errors.
These applications leverage the paper’s core innovations—decoupled, interpretable FFN memory; precomputed token-wise lookups; and the flexible split between computation and memory—to create new deployment patterns, interpretability tooling, and cost/performance regimes across sectors. Feasibility depends on storage bandwidth, tokenizer stability, domain vocabulary quality, and the ability to manage accuracy trade-offs, especially for reasoning-heavy tasks.
Collections
Sign up for free to add this paper to one or more collections.