- The paper introduces Progressive Thought Encoding (PTE) that encodes pruned reasoning tokens into fixed-size latent vectors to sustain performance under constant memory budgets.
- PTE employs a LoRA-style adaptation layer, achieving up to +29.9% accuracy gains and nearly 50% GPU memory reduction compared to standard methods.
- Empirical evaluations on multiple math benchmarks demonstrate PTE’s robust scalability for extended multi-step RL rollouts.
Progressive Thought Encoding for Efficient Training of Large Reasoning Models
Introduction
The paper "Training Large Reasoning Models Efficiently via Progressive Thought Encoding" (2602.16839) addresses a critical limitation in the reinforcement learning (RL) training of large reasoning models (LRMs): prohibitive computational and memory costs incurred by autoregressive decoding during long rollouts necessary for complex outcome-based rewards. While sliding-window cache strategies bound memory, they disrupt long-context reasoning, significantly compromising multi-step problem-solving. The authors introduce Progressive Thought Encoding (PTE), a novel parameter-efficient fine-tuning method, which encodes pruned intermediate reasoning tokens into fixed-size latent vectors, thereby maintaining reasoning efficacy under constant memory budgets during both training and inference.
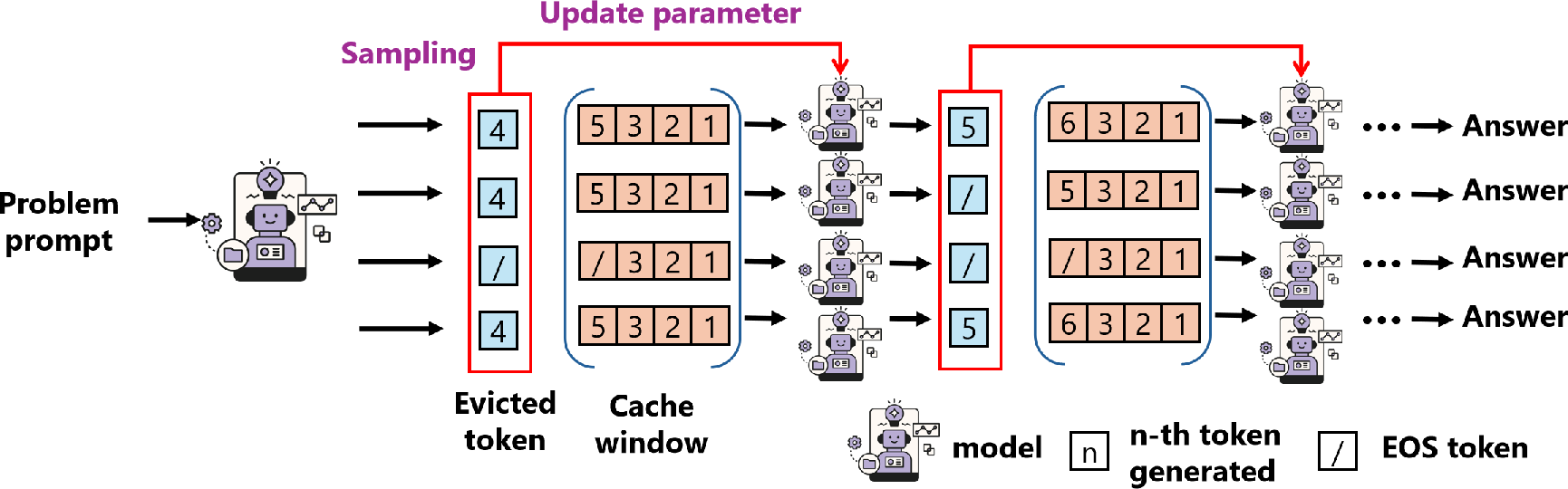
Figure 1: Overview of Progressive Thought Encoding, illustrated as continual learning of dropped tokens to balance generation efficiency and long-term memory.
Methodology
PTE leverages a compact adaptation layer in the form of LoRA-style low-rank matrices, updated dynamically during token eviction. The core innovation lies in aggregating the information from evicted tokens—typically lost with standard sliding-window strategies—into a global query vector qg, which is mapped to a compressed latent state Se and then folded into model parameters for subsequent decoding. This operation is designed to preserve global reasoning signals without backpropagating through the full history, offering constant memory consumption irrespective of rollout length.
The method is implemented within the Grouped Reinforcement Policy Optimization (GRPO) framework, where candidate completions at each prompt are scored and normalized at the group level. Rollouts are generated under a cache truncation policy D, with pruned reasoning tokens continuously summarized in qg and condensed into adapter weights. The design ensures that question tokens are anchored and always retained, in accordance with practices such as sink-token mechanisms, stabilizing prompt grounding even in lengthy chains-of-thought.
Empirical Evaluation
The efficacy of PTE is evaluated on three LRM architectures—Qwen2.5-3B-Instruct, Qwen2.5-7B-Instruct, DeepSeek-R1-Distill-Llama-8B—across six rigorous math reasoning benchmarks (Math500, OlympiadBench, Minerva Math, AMC, AIME2024, AIME2025). The experiments demonstrate consistent, substantial improvements in reasoning accuracy and computational efficiency:
- PTE achieves up to +19.3% improvement over LoRA-based fine-tuning and +29.9% over non-fine-tuned LRMs (average across benchmarks).
- On AIME2024/2025, accuracy gains reach +23.4 under constrained cache budgets, exemplifying the robustness of PTE in long-context tasks.
- Relative to full-cache RL, PTE reduces peak GPU memory by nearly 50% without sacrificing performance.
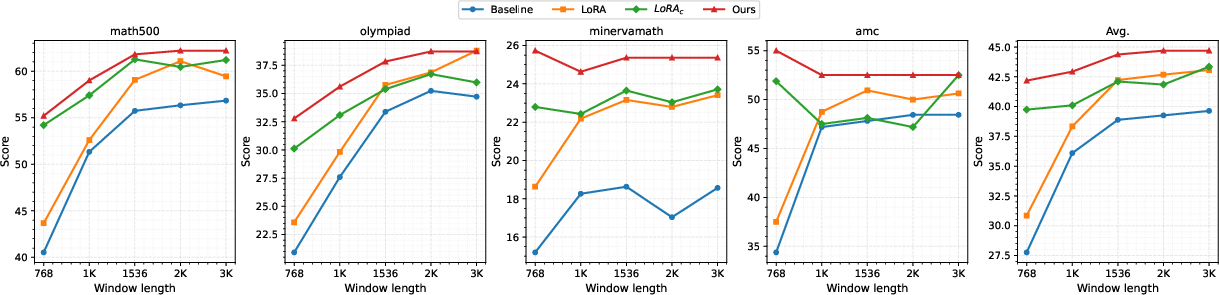
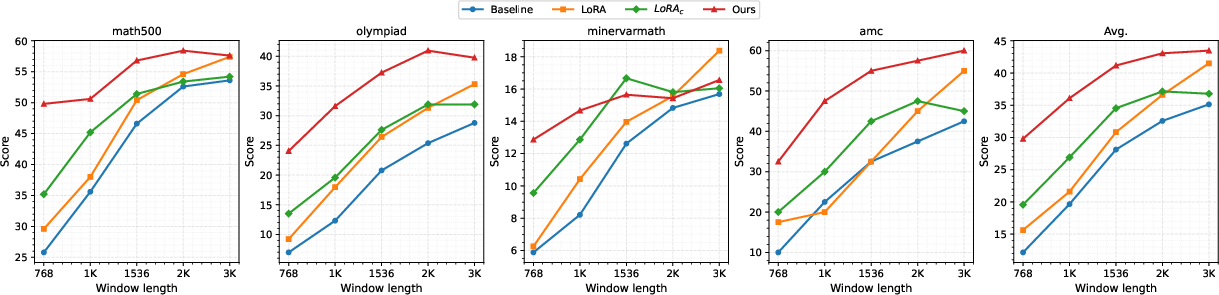
Figure 2: Evaluation results for Qwen2.5-7B-Instruct models showing the superior accuracy of PTE across multiple benchmarks and cache sizes.
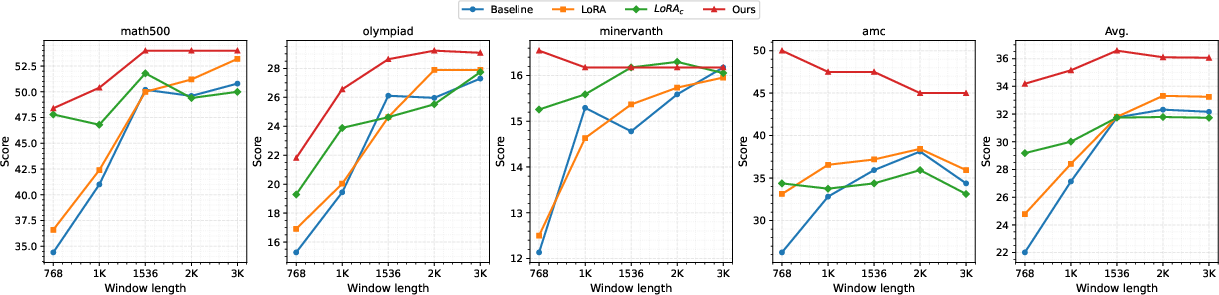
Figure 3: Evaluation results for Qwen2.5-4B-Instruct models, highlighting the stability and scaling of PTE under strict cache constraints.
Ablation and Analysis
Detailed ablation studies scrutinize the role of global tokens, cache-eviction ratios, and integration with advanced token-dropping strategies (e.g., H2O, PyramidKV, HeadKV). Empirical findings indicate:
- Disabling global tokens or minimizing their number impairs performance, but excessive global tokens do not further enhance results under tight cache windows.
- Advanced token dropping at inference marginally improves reasoning accuracy, though at a considerable computational cost; sliding-window eviction remains optimal for large-batch RL rollouts.
- PTE’s progressive encoding mechanism consistently enables longer and more stable reasoning trajectories, maintaining high accuracy as generation lengths and sequence complexity scale.
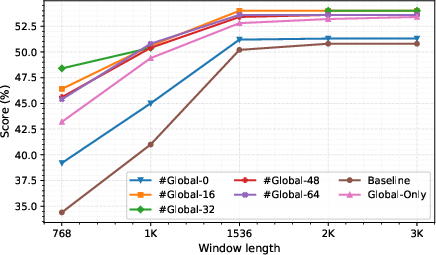
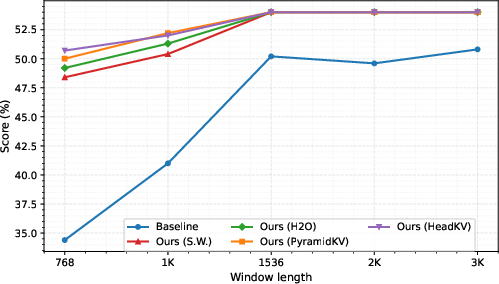
Figure 4: Use of global tokens facilitates robust performance across variable memory budgets; moderate token counts yield best tradeoff.
Implications and Future Directions
The outcomes of this work have several practical and theoretical implications:
- PTE establishes a new regime for memory-efficient RL fine-tuning of LRMs, enabling extended reasoning chains with constant resource overhead. This is pivotal for real-world deployment on limited hardware and in scenarios demanding model scaling.
- The mechanism of compressing evicted context into latent adaptive weights is inherently extensible, supporting further research into dynamic and importance-based token selection, multi-modal reasoning, and inference-time optimization.
- The contradiction of standard cache truncation and reasoning quality is directly addressed; the model achieves a performance envelope previously unattainable under rigid memory constraints, suggesting new approaches to scalable RL for foundation models.
- Future directions include adaptive eviction strategies, integration with parameter-efficient multimodal adapters, and augmentation with retrieval-enhanced generation.
Conclusion
Progressive Thought Encoding delivers parameter-efficient, cache-aware RL training that consistently improves reasoning accuracy and computational efficiency for LRMs. By encoding the semantics of evicted tokens into compact latent states, the method sustains multi-step reasoning under stringent memory budgets, with demonstrable gains across a spectrum of mathematical benchmarks and model architectures. The approach enables longer, more effective RL rollouts, and lays the groundwork for further advancements in scalable and adaptive reasoning model training.

