Asynchronous Reasoning: Training-Free Interactive Thinking LLMs
Abstract: Many state-of-the-art LLMs are trained to think before giving their answer. Reasoning can greatly improve LLM capabilities and safety, but it also makes them less interactive: given a new input, a model must stop thinking before it can respond. Real-world use cases such as voice-based or embedded assistants require an LLM agent to respond and adapt to additional information in real time, which is incompatible with sequential interactions. In contrast, humans can listen, think, and act asynchronously: we begin thinking about the problem while reading it and continue thinking while formulating the answer. In this work, we augment LLMs capable of reasoning to operate in a similar way without additional training. Our method uses the properties of rotary embeddings to enable LLMs built for sequential interactions to simultaneously think, listen, and generate outputs. We evaluate our approach on math, commonsense, and safety reasoning and find that it can generate accurate thinking-augmented answers in real time, reducing time to first non-thinking token from minutes to <= 5s. and the overall real-time delays by 6-11x.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a way to make “thinking” AI LLMs respond in real time. Instead of doing everything in a strict order (first read, then think for a long time, then answer), the authors teach the model to think in the background while it’s already talking. That makes the model more interactive for things like voice assistants or robots that need quick reactions, without retraining the model.
What questions did the researchers ask?
Here are the main questions they explored:
- Can we let a model think and talk at the same time, so it feels more like a real conversation?
- Can we do that without retraining the model (training-free), just by changing how we run it?
- Can we keep most of the accuracy benefits of “chain-of-thought” reasoning but cut the waiting time?
- Can the model decide for itself when to pause talking and think more?
- Can background thinking help with safety (for example, stopping harmful answers) without slowing everything down?
How did they try to solve it?
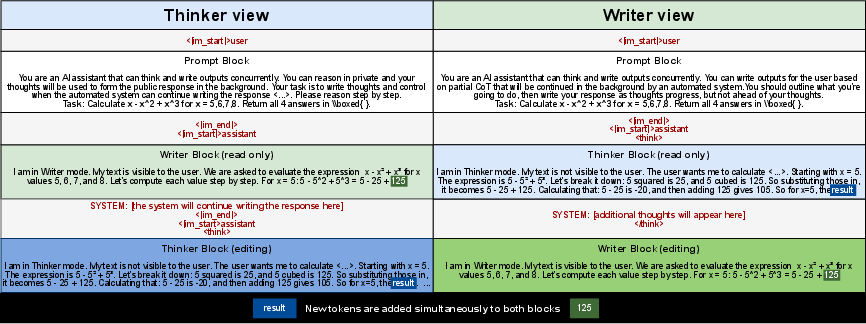
The authors redesigned how the model’s “memory” works during inference (the time when a model generates answers). Think of the model as using three live streams:
- What the user says (input)
- The model’s private thoughts (its hidden “notes,” often marked as
>)- The public response (what the user sees or hears)
Instead of forcing these to happen one after another, they make the model see these streams as if they’re one continuous story, even though they’re being written at the same time.
Key idea: think and talk at the same time
Imagine a student solving a math problem while explaining it to a friend. They might still be working out steps in their head (thinking) while also telling the friend the parts they’ve already figured out (talking). The model does something similar: it keeps filling in its private notes while streaming the answer, and it uses the latest notes to improve what it says next.
How it works under the hood (in simple terms)
Transformers have “attention,” which is like deciding which older words to look at when generating the next word.
- They also keep a “KV cache,” which is a memory of the past that helps speed things up.
- Most modern models use “rotary positional embeddings” (RoPE). You can think of each word’s position as an angle on a clock. Attention cares about the difference between these angles—how far apart two words are—not the absolute angle.
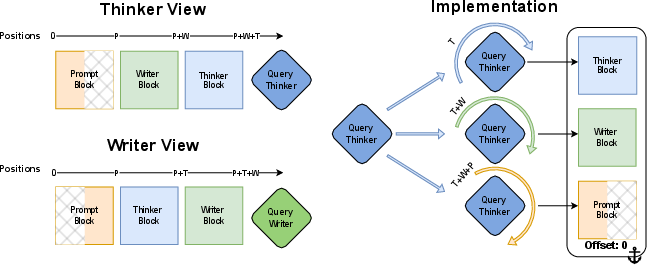
- The trick: instead of moving tokens around in memory, they rotate how the model “looks” at them. By adjusting the angles, the model believes the three streams line up in the right order, so thinking and talking can happen in parallel without duplicating work.
Analogy: If you want two paragraphs to look like they’re back-to-back without actually rearranging them, you can tell the reader “pretend paragraph B starts right after paragraph A.” Here, instead of rearranging text, they update the “position labels” so attention acts as if everything is in the right place.
Deciding when to pause and think
Sometimes the model should stop talking briefly to think more. The authors add tiny checkpoints in the thinking stream where the model asks itself a yes/no question like: “Are my thoughts far enough ahead to keep writing?” If “yes,” it keeps talking. If “no,” it pauses the speech and thinks more. There’s also a version that looks at how far ahead the text-to-speech audio buffer is, so it doesn’t talk too far in advance.
What did they find?
The authors tested their method on math problems, mixed school subjects, and safety checks, and also simulated a voice assistant.
Key findings:
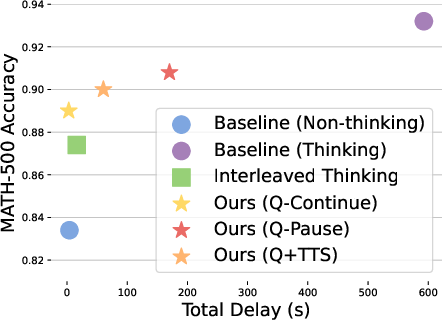
- Much faster first response: time to the first non-thinking word dropped from minutes to about 5 seconds or less.
- Big reduction in total delays: overall “silent time” before or between speech chunks went down by about 6–11×.
- Accuracy trade-offs:
- Full, slow “think first, then answer” was most accurate.
- Asynchronous thinking was slightly less accurate but still much better than “no thinking.”
- In math (MATH-500), for example: no-thinking ≈ 83%, slow thinking ≈ 93%, async thinking ≈ 89%.
- Safety:
- Just adding slow thinking can sometimes make models more vulnerable to tricky prompts (it may over-explain harmful steps).
- Asynchronous thinking with a safety-oriented prompt reduced harmful responses close to the non-thinking baseline, while still keeping good task performance.
- They also found special failure cases, like “race conditions,” where the model starts talking before the safety check finishes. This suggests adding guardrails (like giving the safety checker a head start) can help in sensitive situations.
Why does it matter?
This approach makes “thinking” models feel much more interactive. That’s important for:
- Voice assistants that need to answer quickly while the user keeps talking
- Robots or game agents that must react to changing environments
- Research assistants that should stream useful partial results quickly
- Safer systems that run background checks without long pauses
Best of all, it’s training-free: you don’t have to retrain the model to get these benefits. You can adjust the prompts and the inference engine to balance speed and accuracy for your hardware and app. The authors suggest future work on smarter “pause vs. talk” strategies and stronger safety gates, but the core idea—using positional geometry to make parallel thinking and talking look like a single sequence—already works and can plug into modern inference frameworks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain, missing, or unexplored in the paper, phrased to be concrete and actionable for future research.
- Formal guarantees: Provide a rigorous proof (or counterexamples) that the proposed RoPE-based dual-view query rotation yields attention equivalence to a single contiguous sequence across all layers and heads, including edge cases with large positional offsets, NTK-scaled RoPE, XPos/YaRN variants, and mixed-frequency components.
- Beyond RoPE: Characterize compatibility and derive comparable mechanisms for models that use ALiBi, learned relative position biases, absolute positional embeddings, Transformer-XL–style recurrence, linear attention, or architectures that rotate values in addition to keys/queries.
- Encoder–decoder and multimodal LMs: Extend and validate the method for encoder–decoder models (cross-attention) and for audio/vision LMs where inputs arrive as non-text streams with different positional schemes and modality-specific caches.
- Numerical stability and quantization: Analyze numerical error from large-angle rotations, accumulation across layers, and interactions with KV cache quantization (e.g., KIVI, KVQuant, ZipCache, 2-bit schemes); quantify accuracy/speed trade-offs and identify safe operating regimes.
- Cache editing safety: Systematically evaluate the impact of removing mode-switch prompts from the KV cache on downstream reasoning coherence, stability across turns, and reproducibility in standard inference frameworks (e.g., whether removal causes unintended forgetting or leakage).
- Attention masking across streams: Design and test finer-grained visibility controls (e.g., content-level or head-level masks) to prevent writer-stream “context leakage” from private technical details in the thinker-stream, especially in safety-critical scenarios.
- Linker tokens design: Specify, ablate, and open-source the exact linker token patterns and masking used between blocks; quantify their effect on latency, accuracy, and failure modes.
- Batch and system-level scaling: Provide throughput/latency benchmarks (tokens/sec, GPU utilization) and memory profiles for small vs. large batches, diverse GPUs, and distributed inference (tensor/pipeline parallelism); detail integration with Paged Attention and vLLM, and quantify overhead of custom kernels.
- Generalization across model families and sizes: Replicate results on multiple “thinking” LLMs (e.g., DeepSeek-R1, QwQ-32B, Llama-based, proprietary thinking LMs where feasible) and across sizes; report variance in accuracy, TTFT, and delay.
- Mode-switching calibration: Systematically explore and publish ablations over prompt wording, insertion frequency (e.g., T=20), confidence thresholds (e.g., logit margin criteria), temperature/sampling settings, and hysteresis rules to reduce the observed “bias-to-yes” and premature answering.
- Learning-free vs. learned controllers: Compare training-free mode switching (prompt-only) to light-weight learned gating (small classifier head, bandit policy, RL calibration) and quantify gains in accuracy and latency without full finetuning.
- Safety gating protocols: Implement and evaluate strict emission gating (e.g., requiring an explicit “safe-to-speak” signal from the thinker with a head-start window) to eliminate race conditions; measure impact on ASR, TTFT, and user-perceived responsiveness.
- Tool use and agentic concurrency: Integrate asynchronous function calling/tool execution within the dual-stream cache (including delayed tool results) and study scheduling, conflict resolution, and consistency guarantees for the writer while tools are in-flight.
- Truly asynchronous input tests: Design benchmarks where the user or environment injects mid-utterance clarifications/contradictions; measure incorporation latency, correction accuracy, and recovery from partial wrong answers.
- Human-centered evaluation: Conduct user studies for perceived latency, naturalness, and trust in voice assistants; replace heavy TTS (e.g., tortoise-tts) with low-latency neural TTS to disentangle LLM vs. TTS delays and evaluate chunking strategies (token grouping, prosody-aware segmentation).
- Metric robustness: Replace or complement LLM-as-a-judge for math equivalence with symbolic/regex-based canonicalization; report disagreements between judges and ground truth and their effect on conclusions.
- Benchmark breadth: Evaluate on additional challenging reasoning tasks (e.g., GSM8K, long-form commonsense, program synthesis, multi-hop QA) and realistic spoken reasoning benchmarks redesigned to avoid ceiling effects; include multi-turn dialogues.
- Multi-turn cache growth: Study memory growth, fragmentation, and performance over long conversations with repeated asynchronous switches; propose cache compaction or summarization policies compatible with dual views.
- Energy and edge viability: Measure energy consumption and thermal constraints during asynchronous operation on edge devices; quantify the trade-offs between TTFT reductions and total compute.
- Production constraints: Test behavior under batching typical of serving (heterogeneous prompts, shared kernels) and with rate-limits; assess robustness when downstream systems (ASR/TTS/network) introduce jitter.
- Failure-mode mitigation beyond safety: Catalog non-safety failures (e.g., topic drift, coherence breaks, hallucinations from think–write interference) and design diagnostic probes and mitigations (attention audits, content filters, consistency checks).
- Comparison to trained interactive methods: Provide head-to-head evaluations against Plantain and other finetuned interleaved reasoning systems, controlling for hardware and model size, to disentangle the benefits of training-free vs. trained interactivity.
- Parameter sensitivity: Report how TTFT/accuracy trade-offs vary with token generation rate, chunk size for TTS, maximum allowed buffer (e.g., 10s), and the cadence of synchronization; provide practical tuning guidelines.
- Theoretical limits of interactivity: Formalize the accuracy–latency frontier for asynchronous reasoning (e.g., bounds on error as a function of think–write overlap and pause frequency), to guide controller design and deployment policies.
- Reproducibility artifacts: Release code/kernels, exact prompts, cache manipulation routines, and experimental scripts; include seeds and detailed configuration for independent verification.
Glossary
- Adjusted delay: A user-centric timing metric that discounts brief pauses in streamed responses to reflect perceived latency; defined as total delay minus a small constant per pause. "Adjusted delay: similar to total delay, but we subtract 1 second from every contiguous pause to account for humans finding short pauses less noticeable."
- Agentic tool use: An LLM capability where the model autonomously decides to call external tools or APIs during reasoning. "such as chain-of-thought reasoning~\cite{cot_wei_2022,zero_shot_cot_Kojima2022LargeLM,tree_of_thought,verify_step_by_step}\nocite{auto_cot_Zhang2022AutomaticCO,muennighoff2025s1} and agentic tool use~\cite{Schick2023ToolformerLM,Yao2022ReActSR,gao2023pal,Shen2023HuggingGPTSA}"
- Asynchronous reasoning: A technique where an LLM thinks and generates responses concurrently, adapting in real time without waiting for reasoning to finish. "In this work, we propose a technique that enables asynchronous LLM reasoning."
- Attack Success Rate (ASR): A safety evaluation metric measuring the proportion of prompts that successfully elicit harmful content from a model. "We compare the Attack Success Rate (ASR) across four setups using the Qwen3-32B model"
- Automated speech recognition (ASR): Technology that converts spoken audio into text for downstream processing by LLMs. "The first strategy pipes automated speech recognition (ASR)~\cite{first_asr_davis1952,kaldi,wav2vec,whisper} into a text-based LLM"
- bfloat16 precision: A floating-point format (brain floating-point) commonly used to speed up deep learning inference with reduced memory while preserving range. "in {bfloat16} precision."
- Causal masked LM attention kernel: The attention implementation in autoregressive LLMs that enforces causality by preventing tokens from attending to future positions. "If a block is not visible on the current view, we give it a large position index so it is ignored by the causal masked LM attention kernel."
- Chain-of-thought reasoning: A prompting or training approach where the model generates intermediate steps or rationale before delivering an answer. "such as chain-of-thought reasoning"
- Clearspeak: A speech-friendly rendering style for mathematical expressions to make LaTeX content comprehensible when spoken. "For tasks involving LaTeX, we convert it into Clearspeak~\cite{speech-rule-engine}."
- Dual thinker/writer view: A concurrent perspective in which the model maintains separate streams for private reasoning and public responses while sharing state. "A dual thinker / writer view of the same reasoning task."
- Embodied LLMs (ELMs): Multimodal models that integrate language understanding with perception and action for controlling robots or agents. "Agents controlling robotic systems use multimodal Embodied LLMs~\cite{vla_Driess2023PaLME,vla_Ahn2022SayCan,vla_Mon-Williams2025ELLMER,vla_Wang2023Voyager,vla_Jiang2023VIMA}"
- Hogwild! Inference: A parallelization approach for LLM inference where token streams or tasks proceed without strict synchronization, often leveraging shared caches. "This optimization is inspired by a similar rotation trick proposed in Hogwild! Inference~\cite{hogwild_inference}."
- Interleaved reasoning: A generation style that alternates short segments of thinking and speaking to improve interactivity. "finetunes reasoning LLMs to solve their task with \underline{interleaved} thinking and talking sub-blocks"
- Key-Value (KV) cache: Stored attention keys and values from previous tokens used to speed up autoregressive inference. "We implement concurrent thinking {paper_content} writing by creating a custom key-value cache"
- LLM-as-a-judge: An evaluation protocol where a strong LLM is used to assess the correctness or safety of another model’s outputs. "using LLM-as-a-judge~\cite{zheng2023llm-as-a-judge}"
- Mode switching: The decision mechanism that controls when the model should continue streaming responses versus pausing to think more. "Mode Switching"
- Paged Attention: An inference optimization (e.g., in vLLM) that manages attention memory in pages to support long contexts efficiently. "In future work, we plan to explore implementing more general kernels for AsyncReasoning based on vLLM's Paged Attention~\cite{kwon2023efficient}."
- Positional encoding: A method to inject token order information into transformer models so they can reason over sequences. "and the only thing that makes them into sequence models is their positional encoding~\cite{relative_pos_emb,press2022trainshorttestlong,su2021roformer}"
- Query-key pairs: The elements in attention computation where queries are matched against keys to produce attention weights over values. "it can be optimized further by only processing the non-masked query-key pairs that actually contribute to the attention output."
- Query rotation trick: A RoPE-based optimization that rotates the query by the relative offset instead of rotating cached keys, enabling flexible views over shared caches. "our implementation consists of the custom KV cache and an attention kernel that uses the query rotation trick above."
- Relative positional information: Encoding schemes where attention depends on position differences rather than absolute indices, aiding generalization across lengths. "Almost all modern LLMs use some form of relative positional information~\cite{relative_pos_emb,su2021roformer,press2022trainshorttestlong}."
- Rotary positional embeddings (RoPE): A relative positional encoding that rotates query/key vectors by an angle proportional to position to encode order. "The most popular variant is rotary positional embeddings (RoPE)~\cite{su2021roformer}"
- Scaled dot product attention: The core transformer operation that computes attention weights via normalized dot products between queries and keys. "before computing the scaled dot product attention."
- Speech LLMs: Models trained to natively process and generate audio, often integrating speech recognition and synthesis. "using Speech LLMs (also Audio and Voice LMs) that are trained to process and generate audio natively"
- Steps Delay: An inference-step-based latency metric counting forward passes that do not yield response tokens. "Steps Delay: The average number of inference steps (forward passes) that do not generate a response token."
- Steps to first token (STFT): The number of forward passes needed before emitting the first non-thinking token, independent of hardware speed. "Steps to first token (STFT): the number of inference steps (LLM forward passes) before the first non-thinking token is generated, GPU-agnostic."
- Text-to-speech (TTS): Technology that converts text outputs from an LLM into spoken audio for real-time interaction. "then feeds its response into a text-to-speech (TTS) system"
- Time to first token (TTFT): The wall-clock delay from input to the first streamed non-thinking token in interactive systems. "Time to first token (TTFT): the wall time delay until the system generates the first non-thinking token."
- Vision-Language-Action (VLA): Model architectures that connect perception (vision), language understanding, and action generation for control tasks. "Vision-Language-Action~\cite{vla_Brohan2023RT2, vla_openVLA, vla_survey} to control the system directly."
- Virtual Context attack: A jailbreak method that injects harmful instructions via simulated or hidden context to bypass safety defenses. "using the Virtual Context attack~\cite{zhou2024virtualcontext}."
Practical Applications
Immediate Applications
Below are applications that can be deployed now with modest engineering, leveraging the paper’s training-free method, custom KV-cache handling, and prompt-based mode switching.
- Real-time voice assistants with background reasoning (Sector: software/consumer tech)
- Use the dual think/write streams to speak continuously while the model privately reasons, reducing time-to-first-spoken-token to seconds.
- Workflow: ASR → LLM (AsyncReasoning with mode-switch prompts) → chunked TTS with buffer-aware pause logic.
- Assumptions/dependencies: LLM supports RoPE and thinking tokens (e.g., > ); access to inference engine internals to modify attention queries and KV-cache; TTS/ASR latency budgets. > > - Contact center and customer support chat that “thinks while replying” (Sector: enterprise software) > - Stream short user-facing responses while maintaining deeper internal analysis, escalating to human or tools only when necessary. > - Workflow: streaming chat UI → AsyncReasoning runtime → safety prompt inserted into the thinker stream → tool calls or summaries in writer stream. > - Assumptions/dependencies: controllable chain-of-thought prompting; guardrail prompts; observability to detect early-answer failure modes. > > - Live coding assistants (Sector: software development) > - Offer immediate code suggestions while a background thinker evaluates edge cases, tests, or security implications; pause output when deeper reasoning is required. > - Workflow: IDE plugin → streaming output pane (writer) → asynchronous internal reasoning (thinker) → TTS optional for audio-first workflows. > - Assumptions/dependencies: RoPE-based model; custom kernel or runtime that supports query rotation; continuous prompt scaffolding. > > - Safety-aware streaming guardrails (Sector: platform safety/policy) > - Run safety checks in the thinker stream concurrently with output; insert refusals or warnings if the thinker detects harm (as shown in HarmBench experiments). > - Workflow: classification/refusal prompts injected into thinker; writer streams normal content unless the thinker signals a pause/refusal. > - Assumptions/dependencies: robust safety prompt design; head-start/gating to prevent race conditions; logs for auditability. > > - TTS-buffer-aware pacing for speech agents (Sector: speech/AI platforms) > - Use the “Q+TTS” mode to dynamically pause writing when audio buffers exceed thresholds, improving perceived interactivity without retraining. > - Workflow: buffer tracking of synthesized speech → pause/resume writer; thinker proceeds regardless. > - Assumptions/dependencies: stable TTS pipeline; token-to-speech duration estimation; access to runtime hooks. > > - Real-time educational tutoring (Sector: education) > - Tutor speaks while privately working through solutions; pauses briefly for complex sub-steps; reads math using Clearspeak or similar. > - Workflow: student voice → ASR → AsyncReasoning tutor → Clearspeak conversion → TTS. > - Assumptions/dependencies: math-aware prompting; LaTeX-to-speech conversion; control of thinker/writer cadence. > > - Operator copilots for monitoring dashboards (Sector: energy/manufacturing/IT operations) > - Provide continuous summaries while reasoning in the background about anomalies or root causes; pause speaking to investigate deeper. > - Workflow: live telemetry → AsyncReasoning → streaming summaries; structured alarms when thinker flags uncertainty/risk. > - Assumptions/dependencies: multimodal input preprocessed to text; mode-switch thresholds tuned to incident severity. > > - Lightweight “Async LLM Runtime” library for existing products (Sector: AI infrastructure) > - Package KV-cache block management, query rotation kernels, and mode-switch prompts as a middleware to add asynchronous reasoning to RoPE LLMs without fine-tuning. > - Workflow: drop-in runtime around popular open-weight reasoning models (e.g., Qwen3-32B), plus SDK for developer prompts. > - Assumptions/dependencies: engineering access to attention kernels; compatibility with BF16/FP16; moderate batch sizes. > > - Embodied and game agents with quick environmental reactions (Sector: robotics/gaming) > - Agents act promptly while thinker refines plans; pause output when plan quality is insufficient. > - Workflow: sensor/game events → AsyncReasoning → action stream (writer) + planning stream (thinker). > - Assumptions/dependencies: latency-sensitive control loop; careful gating to avoid unsafe actions; RoPE-based backbone. > > - Streaming “deep research” assistants (Sector: knowledge work/academia) > - Maintain conversational flow while the thinker evaluates sources, compiles notes, and checks claims; reduce idle time in research sessions. > - Workflow: conversation orchestrator → AsyncReasoning → writer summarization → periodic thinker verification. > - Assumptions/dependencies: retrieval/tool use optional; prompt-engineered verification; logging and citation workflows. > > - A/B evaluation harness for async vs. sequential reasoning (Sector: ML ops/academia) > - Use the paper’s metrics (TTFT, total delay, adjusted delay, steps-based measures) to quantify perceived latency vs. accuracy trade-offs. > - Workflow: test bench integrates AsyncReasoning; evaluate mode-switch strategies (Q-Continue, Q-Pause, Q+TTS). > - Assumptions/dependencies: benchmark scaffolding; LLM-as-a-judge setup for math or QA tasks. > > ## Long-Term Applications > > Below are applications that benefit from further research in mode-switch control, broader positional encoding support, scaled inference kernels, and formal safety gating. > > - Standardized async reasoning support in major inference engines (Sector: AI infrastructure) > - Native vLLM/TensorRT-LLM support for multi-block KV caches with efficient query rotation and paged attention; optimized for large batches. > - Tools/products: “AsyncReasoning kernels” in mainstream runtimes; scheduler primitives for multi-stream generation. > - Assumptions/dependencies: new attention kernels; memory management for block visibility; upstream adoption. > > - Training-time alignment for interleaved/asynchronous thinking (Sector: model development) > - Finetune models (e.g., “Plantain-style” interleaving) to internalize when to pause or continue, reducing early-answer errors and bias in mode-switch prompts. > - Tools/products: datasets and objectives for pause/continue prediction heads; concurrent reason-speak curricula. > - Assumptions/dependencies: curated data; safety-aware loss; evaluation under streaming conditions. > > - Formal safety gating and verification for streaming agents (Sector: policy/safety) > - Architectures that guarantee the thinker has a head start; formal constraints so writer cannot stream unsafe content before checks complete; policy-compliant audit trails. > - Tools/products: “safe streaming” governance modules; red-team simulators for race conditions and context leakage. > - Assumptions/dependencies: regulator guidance; risk-tiered gating policies; provable latency budgets. > > - Multimodal async reasoning across text, audio, vision, and actions (Sector: robotics/healthcare/education) > - Unified multi-stream runtime: user speech, environmental video, private thoughts, and public actions all co-exist with correct positional relations. > - Tools/products: multi-stream VLA runtimes; async planners; live “explain while doing” robotic workflows in clinical or warehouse settings. > - Assumptions/dependencies: multimodal encoders with compatible positional schemes; temporal alignment between modalities. > > - Edge deployment of async voice copilots (Sector: consumer devices/IoT) > - On-device speech assistants that think in the background while speaking, with tight energy and memory constraints. > - Tools/products: optimized kernels for mobile NPUs/edge GPUs; KV-cache compression combined with query-rotation tricks. > - Assumptions/dependencies: efficient KV-cache quantization; low-power TTS; privacy-preserving local prompts. > > - Real-time financial and market analysis copilots (Sector: finance) > - Stream insights instantly while deep risk reasoning continues; pause for high-impact decisions (trades, compliance-sensitive outputs). > - Tools/products: async dashboards; compliance-aware thinker prompts; latency-tiered output classes. > - Assumptions/dependencies: strict gating for material non-public information; audit logs; robust fallback-to-human. > > - Assisted clinical triage and telemedicine (Sector: healthcare) > - Maintain bedside conversational flow while private clinical reasoning runs; pause output for complex differential diagnosis; enforce safety gates for medical advice. > - Tools/products: clinician-in-the-loop async assistants; safety verification heads; EHR-integrated streaming. > - Assumptions/dependencies: medical device regulations; data privacy; extensive validation; refusal policies for unsafe advice. > > - Async collaborative multi-agent systems (Sector: software/operations) > - Multiple LLM agents think and act concurrently, coordinating via shared KV-cache views or structured buffers; reduce coordination overhead. > - Tools/products: “group async” schedulers; shared-cache semantics; task decomposition with parallel sub-thinkers. > - Assumptions/dependencies: conflict resolution mechanisms; cache isolation policies; workload-aware routing. > > - Education platforms with adaptive pacing and metacognitive feedback (Sector: education) > - Tutors explain step-by-step while thinking in the background about misconceptions; dynamically pause to address them; provide meta-level “why I paused” reflections. > - Tools/products: async pedagogy engines; pacing policies; misconception classifiers integrated with thinker stream. > - Assumptions/dependencies: student modeling; measurement of pause impact on learning; accessibility features. > > - Standards and best practices for streaming LLM UX (Sector: policy/UX) > - Human factors guidance on acceptable micro-pauses, buffer thresholds, and disclosure of background thinking; standardized interactivity metrics. > - Tools/products: UX benchmarks (TTFT, adjusted delay), recommended prompt templates, safety disclosure labels. > - Assumptions/dependencies: cross-industry collaboration; empirical studies; accessibility and inclusivity requirements. > > ### Notes on Assumptions and Dependencies (cross-cutting) > > - RoPE dependency: The current method relies on rotary positional embeddings; adapting to ALiBi or learned position embeddings will require new geometric tricks. > > - Runtime access: Implementations need access to attention kernels and KV-cache internals to rotate queries and manage block visibility. > > - Model capability: Best results with models that already support chain-of-thought or “thinking” tokens; pure non-thinking models may need prompting/fine-tuning. > > - Batch-size sensitivity: Efficiency benefits are strongest at small to medium batch sizes; large-batch deployments need specialized kernels (e.g., paged attention variants). > > - Safety trade-offs: Asynchronous streaming introduces race conditions and context leakage failure modes; practical deployments need gating and auditability. > > - Hardware and latency budgets: End-to-end perception (ASR), generation (LLM), and synthesis (TTS) must be co-optimized; buffer-aware pacing improves UX. > > - Compliance and privacy: Sectors like healthcare and finance require strict policies, logging, and human-in-the-loop overrides before deployment.
Collections
Sign up for free to add this paper to one or more collections.

