SwiReasoning: Switch-Thinking in Latent and Explicit for Pareto-Superior Reasoning LLMs
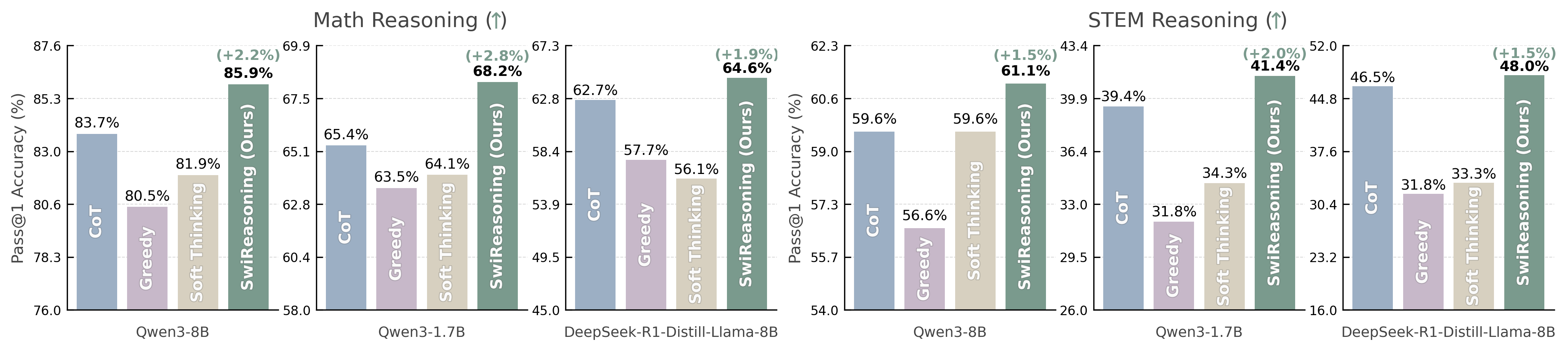
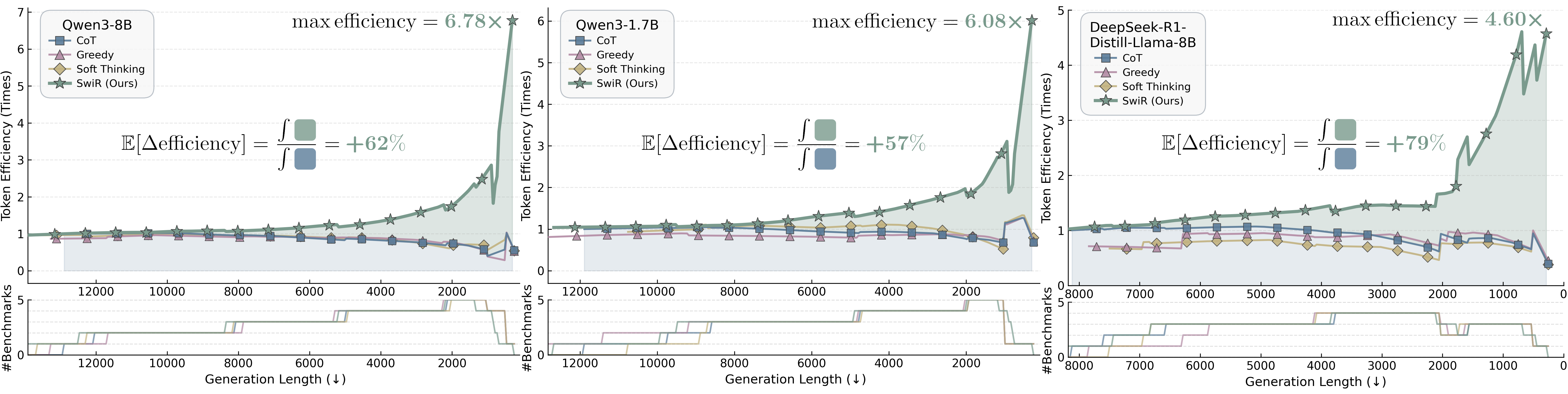
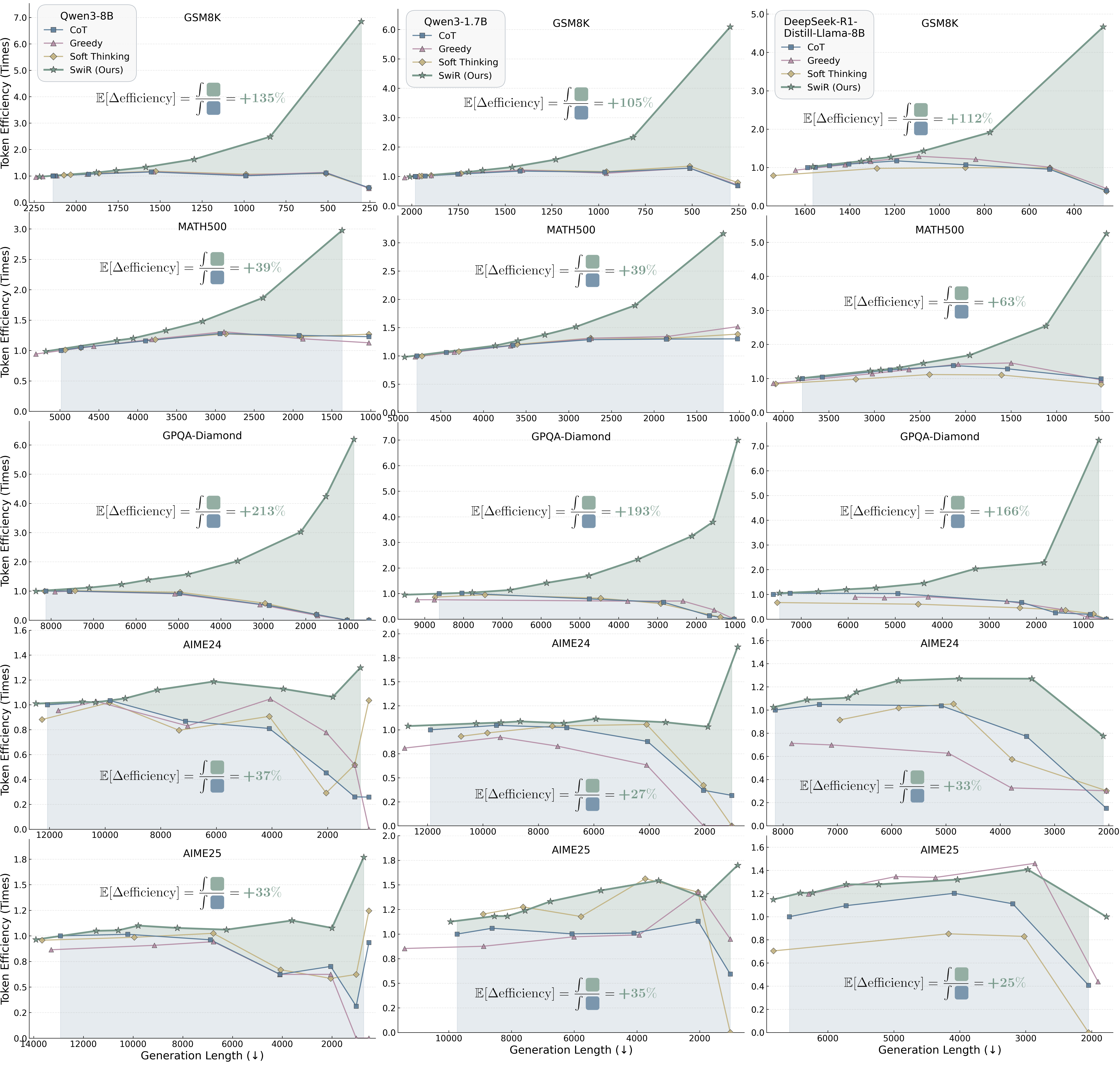
Abstract: Recent work shows that, beyond discrete reasoning through explicit chain-of-thought steps, which are limited by the boundaries of natural languages, LLMs can also reason continuously in latent space, allowing richer information per step and thereby improving token efficiency. Despite this promise, latent reasoning still faces two challenges, especially in training-free settings: 1) purely latent reasoning broadens the search distribution by maintaining multiple implicit paths, which diffuses probability mass, introduces noise, and impedes convergence to a single high-confidence solution, thereby hurting accuracy; and 2) overthinking persists even without explicit text, wasting tokens and degrading efficiency. To address these issues, we introduce SwiReasoning, a training-free framework for LLM reasoning which features two key innovations: 1) SwiReasoning dynamically switches between explicit and latent reasoning, guided by block-wise confidence estimated from entropy trends in next-token distributions, to balance exploration and exploitation and promote timely convergence. 2) By limiting the maximum number of thinking-block switches, SwiReasoning curbs overthinking and improves token efficiency across varying problem difficulties. On widely used mathematics and STEM benchmarks, SwiReasoning consistently improves average accuracy by 1.5%-2.8% across reasoning LLMs of different model families and scales. Furthermore, under constrained budgets, SwiReasoning improves average token efficiency by 56%-79%, with larger gains as budgets tighten.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SwiReasoning, a new way to help LLMs think better and faster. The core idea is simple: let the model switch between two modes while solving a problem—“writing out steps” (explicit reasoning) and “thinking silently in its head” (latent reasoning)—based on how confident it feels. This switching helps the model solve tough math and science questions more accurately while using fewer words (tokens).
What questions does the paper try to answer?
The authors focus on two everyday questions about how LLMs “think”:
- How can we keep the strengths of both styles of thinking—writing clear steps (explicit) and silently exploring many ideas at once (latent)—without getting the downsides of each?
- How can we stop LLMs from “overthinking” (spending too many tokens) and still get reliable answers?
How does it work? (Methods explained simply)
Imagine you’re solving a math problem:
- When you’re unsure, you brainstorm quietly, exploring different ideas.
- When something starts to make sense, you write down clear steps to commit to a solution.
- You don’t want to switch back and forth too often, or you’ll waste time.
SwiReasoning makes an LLM do the same thing.
Two ways an LLM can “think”
- Explicit reasoning (writing): The model prints out step-by-step explanations in plain text—easy to read, but it chooses one token at a time and throws away other possibilities.
- Latent reasoning (silent thinking): The model processes ideas internally without writing every step. This lets it keep multiple possible paths in mind at once—but it can drift, get noisy, or overthink if it never commits.
A confidence meter to decide when to switch
The model uses a confidence score based on its next-token probabilities (called “entropy”). Think of entropy like how “spread out” the model’s options are:
- Low entropy = one option stands out = higher confidence.
- High entropy = many options seem equally likely = lower confidence.
SwiReasoning watches how this confidence changes over short “thinking blocks”:
- If confidence rises: switch to explicit mode to lock in progress and write clear steps.
- If confidence drops and stays low: switch to latent mode to explore alternatives.
To avoid annoying flip-flops, there’s a “dwell time” rule:
- Switching from latent to explicit can happen immediately when confidence rises.
- Switching from explicit to latent requires waiting a few steps, so the model doesn’t panic-switch at tiny hiccups.
Preventing overthinking with a switch limit
To keep things efficient, SwiReasoning also sets a limit on how many times it’s allowed to switch from latent back to explicit. These switch points act like checkpoints. As the limit gets close:
- A “convergence” nudge encourages wrapping up the thinking phase.
- If the limit is exceeded, the model is told to produce the final answer right away (with a small token budget), which saves time on easier problems.
A small extra nudge at switches
When switching modes, the system mixes in tiny signals like “start thinking” or “end thinking.” This acts like a helpful hint to the model so it knows whether it should explore or conclude.
What did they find? (Results)
Across several math and science benchmarks—like GSM8K, MATH500, AIME 2024/2025 (math contest-style problems), and GPQA Diamond (advanced science questions)—SwiReasoning consistently did better than common baselines:
- Higher accuracy:
- About +1.5% to +2.8% average improvement on math tasks.
- About up to +2.0% improvement on STEM tasks.
- Gains were especially strong on harder problems (like AIME), where deeper reasoning is needed.
- Better token efficiency (more correct answers per token used):
- On average, 56%–79% more efficient than standard “write-out-the-steps” methods, with larger gains when token budgets are tight.
- It reached top accuracy with fewer attempts in “Pass@k” tests (fewer samples needed to get the right answer), meaning it’s more sample-efficient too.
In short: the model not only becomes slightly more accurate, but it also gets there with fewer words—especially helpful when you have limited time or cost.
Why does this matter?
SwiReasoning is training-free, meaning it doesn’t require retraining the model. It simply changes how the model thinks at runtime. That makes it:
- Practical: Easy to apply to existing LLMs.
- Cheaper and faster: Uses fewer tokens to reach good answers, saving time and cost.
- More reliable on hard problems: Switches help the model explore when uncertain and commit when confident.
This approach could improve LLM performance on math, science, and other reasoning-heavy tasks used in education, competitions, and research. In the future, combining this switching strategy with training could push reasoning abilities even further.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
The following list captures what remains missing, uncertain, or unexplored in the paper, stated concretely to guide future research:
- Lack of theoretical guarantees: no formal analysis of when entropy-trend–based switching improves correctness or convergence compared to single-mode reasoning, nor conditions under which it can harm accuracy.
- Confidence proxy validity: next-token entropy is assumed to reflect “confidence” but not empirically validated—no correlation analyses with correctness, calibration curves, or cross-model robustness tests (temperature/top‑k/top‑p variations).
- Baseline entropy design: using the first-step entropy in a block as the sole reference lacks robustness; alternatives like moving averages, exponential smoothing, change-point detection, or slope thresholds are unexplored.
- Hyperparameter sensitivity: many knobs (W_E→L, W_L→E, C_max, B, α_0, β_0) with partial ablations only; no comprehensive sensitivity maps, interaction effects, or automated tuning strategies.
- Asymmetric window choice untested: W_L→E is fixed to 0 without ablation; potential oscillation or premature collapsing to explicit mode is not assessed.
- Instance-level adaptivity: the method uses fixed global budgets and windows; no mechanism to adjust C_max, W_E→L, α_0, β_0 per instance based on early-run statistics or problem features.
- Early-answer forcing risks: convergence/termination triggers may cause premature answers; failure modes and trade-offs (accuracy loss vs token savings, regret curves) are not quantified.
- Dependence on special “think” tokens: method assumes availability and semantics of > and ; generalization to models lacking these tokens or with different thought-format APIs is not evaluated.
- Practical deployability of soft embeddings: many inference stacks do not permit feeding mixed embeddings; system-level constraints, cache behavior, latency, and memory impacts are unmeasured.
- Compute/time efficiency: the paper reports token efficiency but not wall‑clock time, throughput, energy, or memory overhead relative to CoT and latent-only baselines.
- Baseline breadth: comparisons omit stronger or widely used baselines (self‑consistency CoT, best‑of‑n reranking, Tree‑of‑Thought, ReAct/tool-augmented reasoning, search), so Pareto superiority is not established against state-of-the-art inference methods.
- Statistical robustness: results lack confidence intervals, multiple seeds, and significance testing; run-to-run variance (especially under sampling) is not reported.
- Domain generalization: evaluation is limited to math/STEM; performance on code generation (with unit tests), commonsense, multi-hop QA, legal/medical reasoning, multilingual tasks, and open-ended dialogue is unknown.
- Tool-in-the-loop compatibility: behavior with external tools (retrieval, calculators, program execution) and integration of mode switching with action-selection policies is unexplored.
- Scaling behavior: tested only on up to 8B models; scaling to larger (≥70B–405B) and smaller (<1B) models, and associated hyperparameter regimes, is not studied.
- Pass@k coverage: Pass@k analysis is limited to one model and two datasets; broader evaluation across models/datasets and theoretical/sample-efficiency analysis are missing.
- Failure case analysis: no qualitative categorization of errors where SwiReasoning underperforms (e.g., oscillations, semantic drift, premature convergence), hindering targeted fixes.
- Answer formatting reliability: injection of “The final answer is” may bias output formatting; effects on tasks requiring strict formats (numeric-only, multiple-choice labels) are not measured.
- Temperature dependence of entropy: entropy is sensitive to decoding temperature/top‑p; the exact settings used for entropy computation (raw logits vs post‑temperature probabilities) and their impact are not clarified.
- Distributional mismatch in latent inputs: models are not trained for soft embeddings; the extent of mismatch, its effect on hidden-state dynamics, and mitigation via adapters or finetuning are not analyzed.
- Learning the switch policy: integration with RL or supervised training to learn when/how to switch (instead of hand-crafted entropy rules) is proposed but not attempted.
- Alternative confidence signals: exploration of logit margins, mutual information, ensemble variance, hidden‑state norms, attention entropy, or consistency across heads/layers as switch signals is absent.
- Difficulty-aware scheduling: methods to predict problem difficulty early and set C_max/W_E→L/β_0 accordingly (meta-controller or heuristic) are not developed.
- Tokenization effects: entropy magnitude depends on vocabulary size and tokenization; normalization schemes and cross-tokenization comparability across model families are not addressed.
- Prompt/style robustness: sensitivity to different CoT templates, instruction styles, temperatures, and sampling policies is not systematically evaluated.
- Reproducibility details: although code links are provided, specifics such as seeds, exact prompt templates, dataset splits, and preprocessing needed for full replication are not exhaustively documented.
- Safety and reliability assessment: the claim of “no safety concerns” is untested; potential impacts on hallucination rates, adversarial robustness, and reliability in safety-critical settings are unmeasured.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented with today’s open-weight reasoning LLMs (e.g., Qwen, DeepSeek) and common inference stacks, leveraging SwiReasoning’s training-free, inference-time switch between latent and explicit thinking and its switch-count control.
- LLM serving efficiency layer for cost/latency reduction (Software/Cloud)
- What: Wrap decoders in vLLM, TGI, or llama.cpp to add entropy-based switching, dwell windows, soft-embedding inputs, and a switch-count controller to curb overthinking.
- Outcome: Lower average tokens per correct answer and shorter tail latencies while preserving or improving accuracy; improved throughput for multi-tenant GPU clusters.
- Tools/Products: “SwiR Controller” SDK; middleware plugin for vLLM/TGI; Grafana dashboards showing token efficiency and switch-count histograms.
- Assumptions/Dependencies: Access to model logits and embedding matrix; ability to feed soft embeddings; availability of “think”/“/think” or equivalent delimiter tokens (or substitutes); per-task hyperparameter tuning (C_max, window size, α0/β0).
- Cost-aware coding copilots in IDEs and CI (Software Engineering)
- What: Use a “fast think” mode (small C_max) for routine completions and a “deep think” mode (larger C_max) when tests fail or coverage is low.
- Outcome: Faster iterations and reduced inference cost without sacrificing solution quality; fewer samples needed to reach peak performance (lower Pass@k).
- Tools/Products: VS Code/JetBrains extensions; CI gates that dynamically adjust C_max and dwell windows.
- Assumptions/Dependencies: Access to logits/embeddings in self-hosted or on-device models; for closed APIs, a degraded variant can still use entropy gating and early-stop policies (explicit-only).
- Math and STEM tutoring at scale (Education)
- What: Integrate SwiReasoning into tutoring systems to solve multi-step math/physics problems with fewer tokens and higher accuracy.
- Outcome: Lower per-student cost; consistent results on GSM8K, AIME-like problems; adjustable budgets by difficulty.
- Tools/Products: Classroom LMS plugin with a “budget knob”; on-device tutors using 1.7B–8B models.
- Assumptions/Dependencies: Open-weight model integration for soft-embedding latent steps; ensure content safety and pedagogy alignment.
- Customer support and policy assistants (Enterprise Knowledge/Support)
- What: Use entropy trends to switch modes; trigger early answer checkpoints; when uncertainty rises, either switch to latent exploration or, in a RAG stack, trigger retrieval before continuing.
- Outcome: Fewer long, meandering answers; faster time-to-resolution; lower serving costs.
- Tools/Products: RAG orchestrators that add “retrieve-on-uncertainty” hooks; contact-center copilots with token budgets per ticket.
- Assumptions/Dependencies: RAG connectors; mapping “/think” trigger to retrieval or tool calls; domain calibration for entropy-confidence alignment.
- Academic evaluation harnesses with lower sampling budgets (Academia)
- What: Use SwiReasoning for Pass@k evaluations to reach peak accuracy with fewer samples (k* significantly smaller than CoT).
- Outcome: Lower compute cost for benchmarking and ablation studies; more experiments per dollar.
- Tools/Products: Open-source evaluation scripts for GSM8K/MATH/AIME/GPQA; Hugging Face Spaces demos.
- Assumptions/Dependencies: Open models; reproducible seeds; evaluation protocols that accept non-text latent steps.
- Multi-tenant GPU scheduling and SLO controls (Platform/ML Ops)
- What: Expose C_max as a serving-time SLO (e.g., “respond in N switches”); auto-tune dwell windows by queue pressure.
- Outcome: Predictable latency/cost envelopes; graceful degradation under load while preserving accuracy.
- Tools/Products: Admission control policies; autoscalers that optimize token efficiency (accuracy-per-token) AUC.
- Assumptions/Dependencies: Serving infrastructure access; telemetry for entropy and switch counts.
- On-device and edge assistants (Mobile/IoT)
- What: Deploy 1.7B–8B models with SwiReasoning for offline assistants, calculators, and travel planners.
- Outcome: Reduced battery/compute cost; fewer hallucinations due to confidence-aware switching.
- Tools/Products: Llama.cpp-based mobile SDKs; automotive HMI assistants with “fast vs deep think” controls.
- Assumptions/Dependencies: Embedding-mixing support in the runtime; memory/compute headroom on device.
- Lightweight language planners for robots (Robotics)
- What: Enable simple task planning/step decomposition with small C_max for real-time responses; switch back to latent exploration only when uncertainty persists.
- Outcome: More reliable, low-latency reasoning on resource-constrained hardware.
- Tools/Products: ROS nodes incorporating SwiR; planning pipelines that bound thinking steps.
- Assumptions/Dependencies: Safety guardrails; limited domain complexity; open models with embedding access.
- Legal and compliance triage (Legal/Finance)
- What: First-pass contract/policy checks under strict token budgets; prompt a deeper pass only if uncertainty remains high across dwell windows.
- Outcome: Lower review costs; faster triage while preserving accuracy on straightforward cases.
- Tools/Products: “Efficiency-first” review bots; human-in-the-loop escalation based on entropy trends.
- Assumptions/Dependencies: Human oversight; compliance with privacy/security constraints; domain calibration of confidence signals.
- Rapid prototyping for tool-augmented agents (General AI Agents)
- What: Use the convergence trigger to end “thinking” and commit to action; use entropy spikes to branch latent exploration or call a tool.
- Outcome: Fewer action loops and reduced overthinking; clearer delineation between deliberation and execution.
- Tools/Products: ReAct/ToT frameworks patched with switch-count control; agent dashboards showing confidence trajectories.
- Assumptions/Dependencies: Tool-calling hooks; guardrails to avoid premature termination on hard tasks.
- Procurement and governance pilots for efficient AI (Policy/Enterprise IT)
- What: Adopt token-efficiency (accuracy-per-token) as a procurement KPI in pilots; use SwiR as the default decoding policy for reasoning benchmarks.
- Outcome: Comparable or better accuracy with materially lower operating costs; standardized efficiency reporting.
- Tools/Products: Policy templates and evaluation checklists including AUC of token-efficiency.
- Assumptions/Dependencies: Agreement on metrics and test suites; transparent logging of decoding signals.
- Privacy-preserving internal analytics assistants (Enterprise Analytics)
- What: Inference-time-only modification allows on-prem deployment without retraining on sensitive data; switch-count control constrains output verbosity.
- Outcome: Lower data exposure and cost; bounded responses that are easier to monitor.
- Tools/Products: On-prem LLM boxes with SwiR decoding; audit logs of entropy/switch decisions.
- Assumptions/Dependencies: Open-weight models; security hardening; compliance review.
Long-Term Applications
These applications are promising but require further research, integration work, or ecosystem support (e.g., model/provider features, hardware/runtime changes, or domain validation).
- Co-trained switch policies via RL or SFT (Software/ML)
- What: Learn adaptive dwell windows, α/β schedules, and C_max policies end-to-end with reinforcement learning or supervised signals.
- Outcome: Stronger gains than training-free switching, especially on hard, domain-specific tasks.
- Dependencies: Access to training data; compute for fine-tuning; reward shaping for efficiency and accuracy.
- Hardware/runtime support for latent-step decoding (Systems)
- What: Native kernels for soft-embedding formation and mixing; KV-cache and speculative decoding co-designed for mode switching.
- Outcome: Lower overhead for latent steps; higher throughput; better Pareto frontier.
- Dependencies: TensorRT/AITemplate/FlashAttention integrations; model runtime changes.
- Tool/RAG orchestration driven by entropy trends (Enterprise/Agents)
- What: Treat entropy spikes as triggers to search, retrieve, or call calculators/symbolic solvers; close loops when confidence recovers.
- Outcome: Fewer wasted tool calls; better end-to-end cost-effectiveness on complex pipelines.
- Dependencies: Unified orchestrators; per-domain calibration of confidence thresholds.
- Safety-critical deployments with calibrated confidence (Healthcare/Legal/Finance)
- What: Pair entropy-based switching with calibrated uncertainty estimates and human oversight; validate on domain datasets.
- Outcome: Trustworthy reasoning with bounded overthinking; consistent escalation to human experts.
- Dependencies: Formal validation; risk management and regulatory approvals; strong auditability.
- Multi-agent systems with inter-agent mode specialization (Agents/Research)
- What: One agent explores in latent mode while another consolidates explicitly; switch governance based on shared confidence signals.
- Outcome: Improved diversity and correctness with fewer parallel samples (lower Pass@k).
- Dependencies: Communication protocols; arbitration strategies; stability analysis.
- Standardization of efficiency-first KPIs in public-sector AI (Policy)
- What: Include token-efficiency AUC, Pass@k at fixed budgets, and switch-count budgets in procurement frameworks.
- Outcome: Public deployments that are both accurate and cost-efficient.
- Dependencies: Industry consensus; public benchmarks; transparent reporting.
- Adaptive, difficulty-aware switching (Research)
- What: Online estimation of instance difficulty to set C_max, dwell windows, and α/β per query.
- Outcome: Better performance across easy vs. hard instances without manual tuning.
- Dependencies: Reliable difficulty predictors; continual learning safeguards.
- Tight integration with programmatic solvers (STEM/DevTools)
- What: Use entropy triggers to hand off subproblems to SAT/SMT/ CAS or code execution; return results to explicit steps.
- Outcome: Higher accuracy on long-horizon tasks; reduced token usage.
- Dependencies: Secure sandboxing; robust I/O schemas; error handling.
- Automotive, aerospace, and industrial edge reasoning (Robotics/Embedded)
- What: On-device planning/diagnostics with strict latency and power constraints; adaptive switch budgets under system load.
- Outcome: Real-time, reliable reasoning in constrained environments.
- Dependencies: Domain-specific safety cases; certification; optimized runtimes.
- Provider-level “soft tokenization” APIs (Cloud AI Platforms)
- What: Cloud APIs offering latent-step inputs (soft embeddings) and entropy telemetry for third-party apps.
- Outcome: Broader adoption beyond open-weight models; standardized knobs for budgeted reasoning.
- Dependencies: Provider support; API standardization; security controls.
- Developer UX for “think depth” and “confidence trajectories” (Product)
- What: Expose sliders for C_max and dwell windows; visualize entropy trendlines and switch events.
- Outcome: Human-controllable speed/quality trade-offs; better observability.
- Dependencies: Front-end integration; user education; defaults that avoid misuse.
Cross-cutting assumptions and dependencies to consider
- Logit and embedding access: Full benefits require access to next-token distributions and the embedding matrix to form soft embeddings. Closed-model APIs may necessitate an explicit-only variant (entropy-based early stopping and temperature/Top-k adjustments).
- Tokenization cues: The method assumes “thinking” delimiters (e.g., > , ) or semantically similar tokens. If absent, replacements and prompt conventions must be chosen and tested.
- Calibration: Entropy is an informative but imperfect proxy for correctness. Domain-specific calibration and monitoring are recommended, particularly in safety-critical settings.
- Hyperparameters: Window size, α0/β0 schedules, and C_max need per-task tuning; adaptive or learned policies would reduce this burden.
- Governance: In regulated domains, human-in-the-loop oversight and auditable logs of switching decisions are necessary prior to high-stakes deployment.
Glossary
- Area-under-curve (AUC): A performance summary that aggregates efficiency (or accuracy) across a range of budgets, often used to compare methods’ overall trade-offs. "These improvements are not confined to a single budget: the area-under-curve (AUC) advantage persists across a broad range of small to moderate budgets."
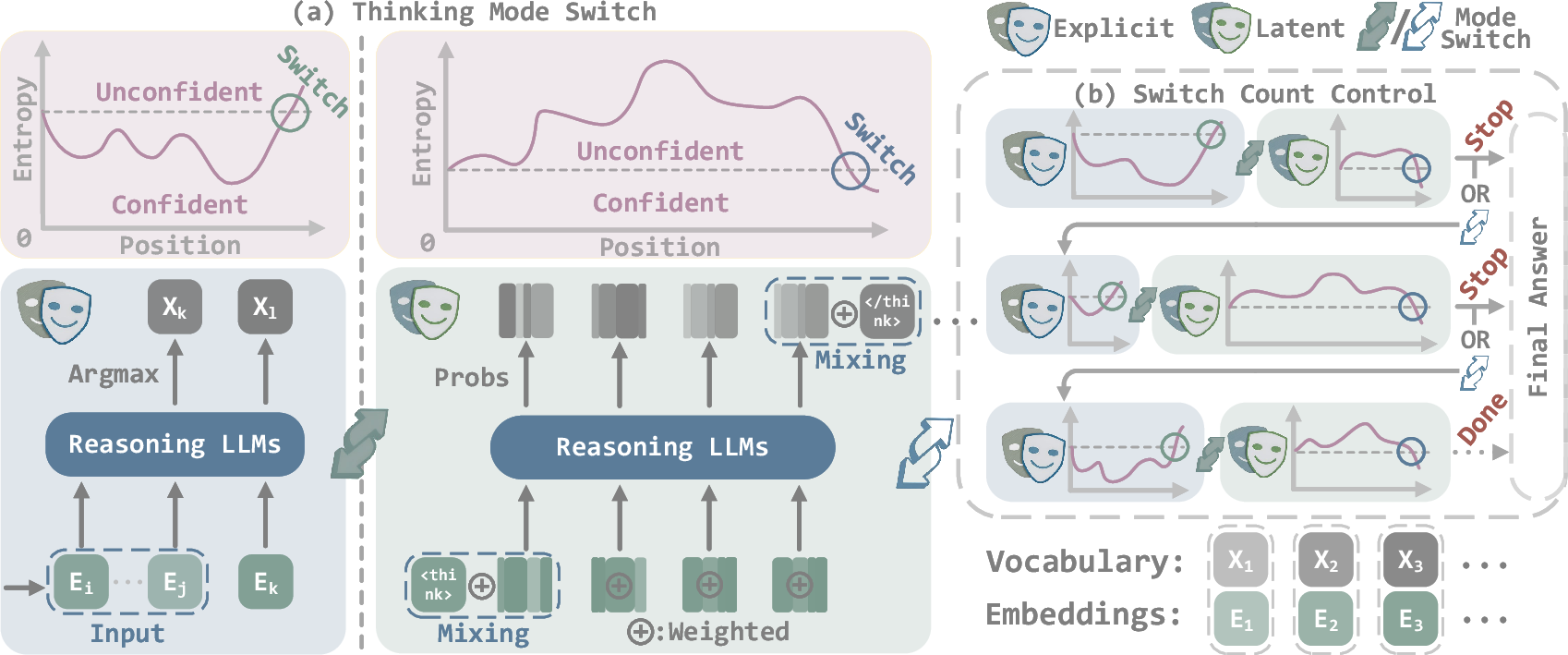
- Block-wise confidence: A confidence estimate computed over a contiguous “thinking block,” often derived from entropy trends of next-token distributions. "SwiReasoning dynamically switches between explicit and latent reasoning, guided by block-wise confidence estimated from entropy trends in next-token distributions"
- Chain-of-thought (CoT): A prompting/decoding style that elicits explicit, step-by-step reasoning in natural language during inference. "A key limitation of the dominant reasoning approach, explicit chain-of-thought (CoT)~\citep{wolf2020transformers, wei2022chain, yao2023tree, goyalthink, pfau2024let}, lies in the reliance on discrete tokens during inference."
- Convergence trigger: A policy mechanism that, after enough switches, forces the model to conclude its thinking phase and begin answer generation. "Convergence trigger (at on transitions): force the next token to be ."
- Dwell window: A minimum number of steps the model must remain in a mode before switching, used to prevent oscillatory switching. "To avoid oscillations, we impose dwell windows upon the mode switch criterion."
- Embedding hull: The convex set spanned by token embeddings; soft inputs stay within this convex hull, preserving distributional information. "The convexity of Eq.~\ref{eq:soft-embed} ensures lies in the embedding hull of , retaining all first-order uncertainty in , which reduces information discards and increases robustness to local noise."
- Entropy: A measure of uncertainty in the next-token probability distribution; lower entropy indicates higher confidence. "We refer to the reasoning content between two consecutive switches as a thinking block and estimate its confidence by entropy"
- Entropy trends: Temporal changes in entropy used to decide whether to explore (latent) or exploit (explicit) during reasoning. "SwiReasoning dynamically switches between explicit and latent thinking, based on block-wise confidence inferred from entropy trends of next-token distributions"
- Explicit reasoning: Reasoning that is externalized as discrete tokens (natural language steps), trading off richness for stability and readability. "explicit thinking provides readability but may discard useful information beyond chosen tokens"
- Greedy decoding: A decoding strategy that always selects the highest-probability token at each step without sampling. "SwiReasoning consistently achieves higher Pass@1 accuracy than CoT with sampling, CoT with greedy decoding, and Soft Thinking."
- Injection queue: A queue of tokens forcibly inserted into the generation stream to enforce convergence or termination behaviors. "Triggers are implemented as short injection queues that overwrite future-generated tokens."
- Latent reasoning: Reasoning conducted directly in continuous hidden representations instead of explicit tokens. "Latent reasoning operates in the continuous representation space rather than discrete natural language space used by explicit reasoning."
- Latent space: The continuous vector space of hidden representations where models can “think” without emitting tokens. "LLMs can also reason continuously in latent space, allowing richer information per step and thereby improving token efficiency."
- Logits: Pre-softmax scores output by the model that determine the token probability distribution. "At step , the model yields logits and ."
- Mode switch criterion: The rule that determines when to switch between explicit and latent reasoning modes. "Mode Switch Criterion."
- Overthinking: Excessive or unnecessary continuation of internal reasoning that wastes tokens without improving accuracy. "overthinking persists even without explicit text, wasting tokens and degrading efficiency."
- Pareto frontier: The set of solutions that optimally trade off competing objectives (e.g., accuracy vs. tokens) such that no objective can be improved without worsening another. "Across models and benchmarks, SwiReasoning consistently attains improved Pareto frontiers."
- Pareto-superior: Describes a method that improves one criterion without hurting another relative to a baseline. "SwiReasoning: Switch-Thinking in Latent and Explicit for Pareto-Superior Reasoning LLMs"
- Pass@1 accuracy: The probability that the first sampled solution is correct. "Pass@1 accuracy under unlimited token budgets."
- Pass@k accuracy: The probability that at least one of k sampled solutions is correct. "Pass@k accuracy () evaluation with Qwen3-8B on AIME 2024 and 2025 benchmarks."
- Reference entropy: The baseline entropy recorded at the start of a thinking block against which subsequent entropy is compared. "the framework first tracks a reference entropy within each thinking block to reflect block-wise confidence."
- Self-consistency: An approach that aggregates multiple reasoning chains to improve robustness and accuracy. "Subsequent work increases robustness by aggregating multiple CoT trajectories through self-consistency"
- Soft embedding: A continuous input vector formed as the probability-weighted sum of token embeddings, preserving uncertainty. "Given the next-token distribution , it forms a soft embedding"
- Soft Thinking: A training-free latent reasoning method that feeds mixtures of token embeddings as inputs during inference. "Training-free approaches like Soft-Thinking \citep{zhang2025softthinking}, which form a probability-weighted mixture of token embeddings as inputs, operate directly at inference time without incurring additional training costs."
- Switch count control: A mechanism that caps the number of mode switches to suppress overthinking and improve efficiency. "a switch count control mechanism limits the maximum number of thinking-block transitions, suppressing overthinking before the final answer."
- Switch window size: The minimal dwell duration (in steps) enforced before allowing a mode switch to avoid rapid oscillations. "Switch Window Size."
- Termination trigger: A mechanism that enforces immediate answer generation once the switch budget is exceeded. "Termination trigger (at on a subsequent transition): inject a concise answer prefix $s_{\text{final}$, ``\text{\textbackslash n\textbackslash n The final answer is}'', then allow at most additional tokens for the final answer."
- Thinking block: A contiguous segment of reasoning between two consecutive mode switches. "We refer to the reasoning content between two consecutive switches as a thinking block"
- Thinking-related signal mixing: The practice of blending special tokens like > or into embeddings at switch boundaries to guide the model’s reasoning phases. "Thinking-Related Signal Mixing."
- Token budget: A limit on the number of tokens (or steps) allowed for reasoning and answering. "Token efficiency (accuracy per token compared to standard CoT), under limited token budgets."
- Token efficiency: Accuracy per token, often normalized to a baseline to compare cost-effectiveness. "Token efficiency (accuracy per token compared to standard CoT), under limited token budgets."
- Top-k/Top-p sampling: Stochastic decoding strategies that limit sampling to the k most likely tokens or to a nucleus of tokens whose cumulative probability is p. "\text{Sampling: } \text{Top-}k/\text{Top-}p \text{ with temperature }\tau."
- Training-free latent reasoning: Latent reasoning methods that do not require additional training or fine-tuning, operating purely at inference time. "Although training-free latent reasoning eliminates the need for costly retraining, operating purely in the latent space also presents significant challenges."
- Tree-of-thought (ToT): A search-augmented reasoning approach that branches over partial rationales to explore multiple solution paths. "Tree-of-thought that branches over partial rationales"
Collections
Sign up for free to add this paper to one or more collections.

