- The paper introduces agentic RL, transforming LLMs from passive generators into decision-making agents with extended planning and interactive tool use.
- It reviews key methodologies including policy gradient methods, hybrid reward frameworks, and advanced memory and self-improvement mechanisms.
- The survey highlights open challenges in trustworthiness, scaling, and environment design to guide future research on autonomous agents.
The Landscape of Agentic Reinforcement Learning for LLMs
Agentic Reinforcement Learning (Agentic RL) represents a paradigm shift in the intersection of LLMs and reinforcement learning (RL), reframing LLMs from passive sequence generators into autonomous, decision-making agents capable of long-horizon, interactive behaviors. This survey provides a comprehensive synthesis of the theoretical foundations, algorithmic advances, capability taxonomies, domain applications, and open challenges in Agentic RL, consolidating insights from over 500 recent works.
Paradigm Shift: From LLM-RL to Agentic RL
Traditional LLM-RL approaches, such as RLHF and DPO, treat LLMs as static conditional generators, optimizing for single-turn outputs using degenerate, single-step MDPs. In contrast, Agentic RL formalizes LLMs as policies embedded in temporally extended, partially observable MDPs (POMDPs), enabling sequential decision-making, tool use, memory, and adaptive planning in dynamic environments.
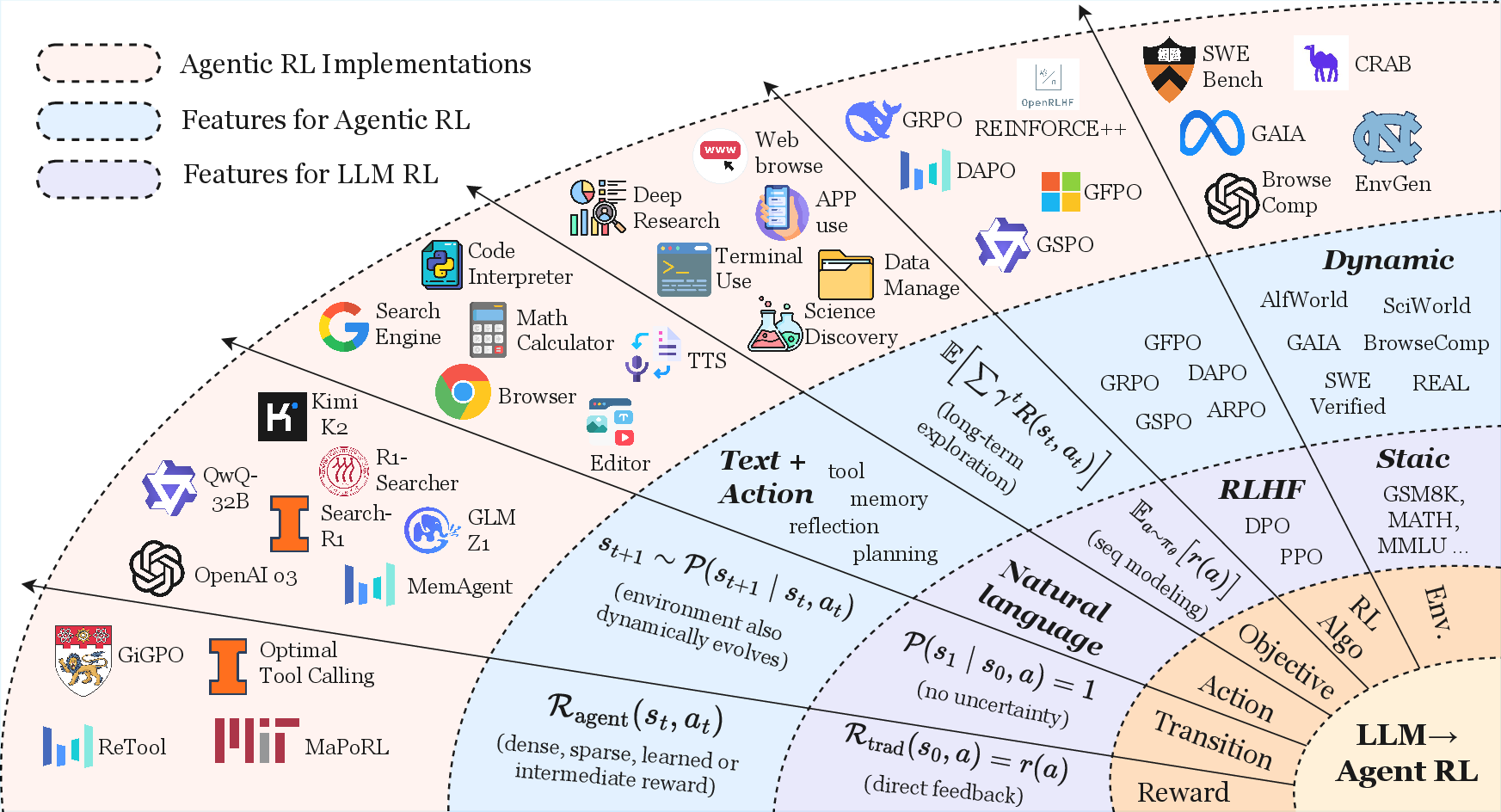
Figure 1: Paradigm shift from LLM-RL to agentic RL.
The key distinctions are:
- State and Observation: Agentic RL operates over evolving world states and partial observations, rather than static prompts.
- Action Space: Actions include both free-form text and structured tool/environment interactions.
- Transition Dynamics: Environment transitions are stochastic and history-dependent.
- Reward Structure: Supports dense, sparse, and learned rewards, enabling long-term credit assignment.
- Learning Objective: Maximizes discounted cumulative reward over trajectories, not just immediate output quality.
This formalization underpins the emergence of LLMs as agentic entities, capable of perceiving, reasoning, planning, and adapting in open-ended tasks.
Agentic RL: Capability-Centric Taxonomy
Agentic RL is best understood through the lens of core agentic capabilities, each of which is transformed from a static module into an RL-optimizable policy:
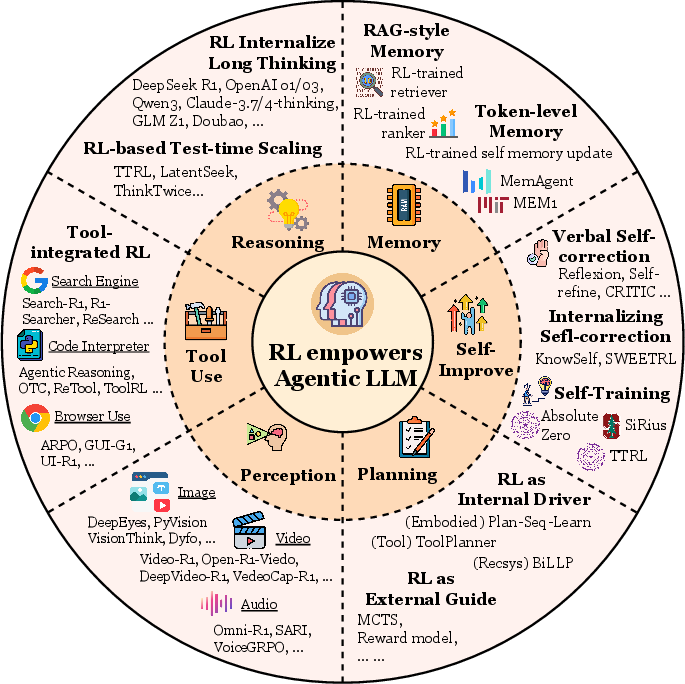
Figure 2: A summary of the overall six aspects where RL empowers agentic LLMs.
Planning
RL enables LLMs to move beyond prompt-based or SFT-mimicked planning, supporting both external search-guided planning (e.g., MCTS with RL-trained heuristics) and direct policy optimization for intrinsic planning strategies. Progressive RL frameworks (e.g., AdaPlan, PilotRL) demonstrate improved long-horizon coordination and adaptability.
The evolution from ReAct-style pipelines to deeply interleaved Tool-Integrated Reasoning (TIR) is driven by RL. RL-trained agents autonomously discover optimal tool invocation strategies, adapt to novel scenarios, and recover from errors. Modern systems (e.g., ToolRL, AutoTIR, VTool-R1) exhibit emergent behaviors such as self-correction and multi-tool composition.
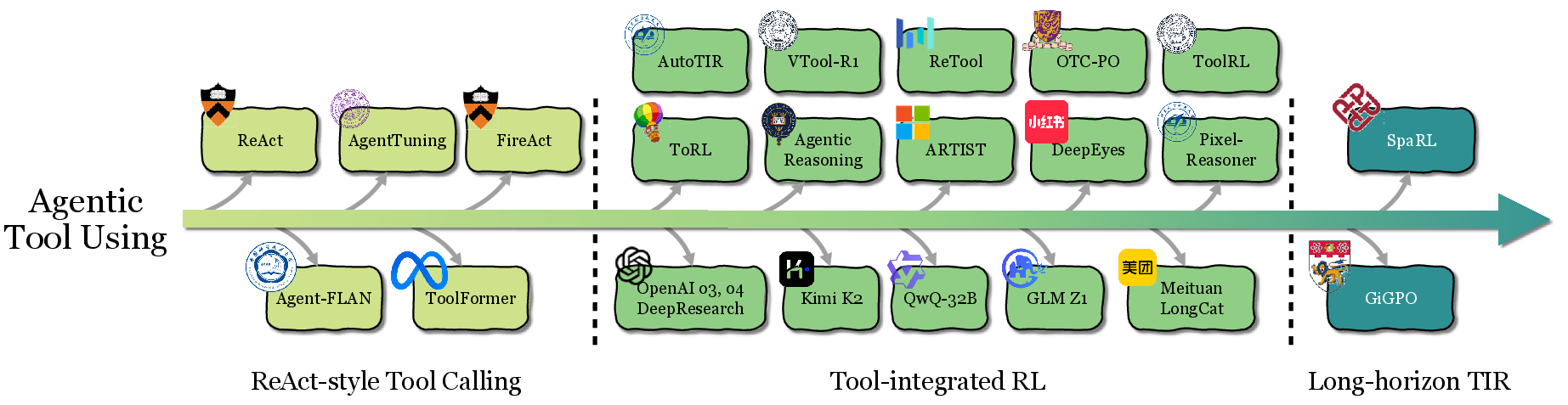
Figure 3: The development of agentic tool use, highlighting representative milestones.
Memory
RL transforms memory from a passive store (RAG) into an active, policy-controlled subsystem. RL-based memory managers (e.g., Memory-R1, MemAgent) learn to add, update, or delete memory entries, optimizing retrieval and compression for downstream performance. The frontier lies in RL-driven structured memory (e.g., temporal graphs, atomic notes).
Self-Improvement
Agentic RL supports both verbal self-correction (e.g., Reflexion, Self-Refine) and internalized, gradient-based self-improvement (e.g., KnowSelf, Reflection-DPO, R-Zero). Advanced agents autonomously generate curricula, synthesize problems, and bootstrap their own learning via self-play and execution-guided feedback.
Reasoning
RL enables the transition from fast, heuristic-driven reasoning to slow, deliberate, multi-step reasoning. RL-based methods (e.g., GRPO, DAPO, R1-style RL) incentivize chain-of-thought, verification, and planning, yielding higher accuracy and robustness in knowledge-intensive domains.
Perception
RL is critical for aligning vision-language(-action) models (VLMs, LVLMs) with complex, multi-step reasoning objectives. RL-based approaches (e.g., Vision-R1, VLM-R1, SVQA-R1) move beyond passive perception to active visual cognition, grounding reasoning in visual evidence, tool use, and imagination.
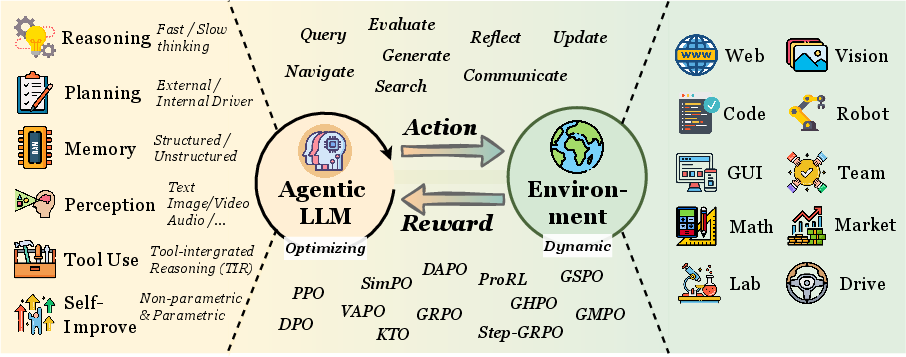
Figure 4: The dynamic interaction process between agentic LLMs and the environment.
Agentic RL: Task-Centric Taxonomy
Agentic RL has been instantiated across a broad spectrum of domains, each presenting unique challenges and opportunities:
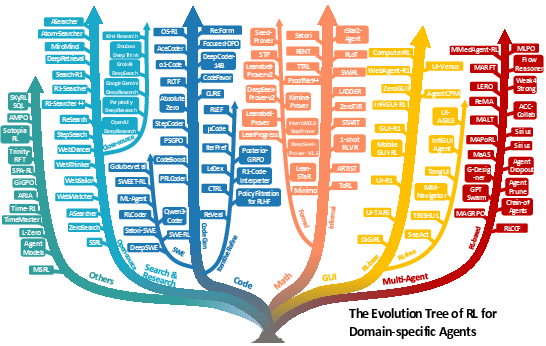
Figure 5: The evolution tree of RL for domain-specific agents.
- Search/Research Agents: RL optimizes multi-turn search, reasoning, and synthesis, outperforming prompt-based and SFT-only baselines in open-domain research tasks.
- Code Generation and Software Engineering: RL with outcome/process rewards enables robust code synthesis, debugging, and full-stack software engineering, leveraging verifiable execution signals.
- Mathematical Reasoning: RL is essential for both informal (natural language, symbolic computation) and formal (theorem proving) mathematics, supporting tool-integrated reasoning and proof search.
- GUI/Web Agents: RL enables robust, long-horizon interaction in dynamic GUI and web environments, surpassing SFT in grounding, planning, and recovery.
- Vision/Multimodal Agents: RL aligns multimodal reasoning, grounding, and tool use, supporting both perception and generation tasks.
- Embodied Agents: RL is critical for navigation and manipulation in real/simulated environments, supporting generalization and compositionality.
- Multi-Agent Systems: RL enables dynamic coordination, role allocation, and collaborative reasoning in LLM-based MAS.
RL Algorithms and Scaling
The survey provides a detailed taxonomy of RL algorithms for LLMs, including:
- Policy Gradient Methods: REINFORCE, PPO, GRPO, and their variants, with trade-offs in sample efficiency, stability, and computational cost.
- Preference Optimization: DPO, IPO, KTO, and step-wise extensions, enabling alignment without explicit reward models.
- Hybrid/Process-Based Methods: Integration of outcome and process rewards, expert iteration, and curriculum learning.
Scaling RL for agentic LLMs requires advances in:
- Compute and Data Efficiency: Distributed, asynchronous RL frameworks (e.g., AREAL, SkyRL, AgentFly) and curriculum generation.
- Environment Complexity: Dynamic, adaptive environments and automated reward/curriculum generation.
- Algorithmic Stability: Robust credit assignment, reward shaping, and hybrid SFT+RL pipelines.
Open Challenges and Future Directions
The survey identifies three grand challenges:
- Trustworthiness: RL amplifies risks of reward hacking, hallucination, and sycophancy. Mitigation requires robust sandboxing, process-based rewards, adversarial training, and continuous monitoring.
- Scaling Agentic Training: Efficient scaling of compute, data, and model size is essential. Hybrid training recipes, meta-learning, and principled difficulty calibration are promising directions.
- Scaling Agentic Environments: Co-evolution of agents and environments, automated reward/curriculum design, and procedural content generation are critical for robust generalization.
Conclusion
Agentic RL marks a fundamental shift in the design and training of LLM-based agents, enabling the emergence of scalable, general-purpose AI systems with adaptive, robust, and interactive capabilities. RL is the critical mechanism for transforming static modules into dynamic, optimizable policies, supporting planning, tool use, memory, reasoning, perception, and self-improvement across diverse domains. The field is rapidly evolving, with open challenges in trustworthiness, scaling, and environment design that will shape the trajectory of general-purpose agentic intelligence.