Exploring Reasoning Reward Model for Agents
Abstract: Agentic Reinforcement Learning (Agentic RL) has achieved notable success in enabling agents to perform complex reasoning and tool use. However, most methods still relies on sparse outcome-based reward for training. Such feedback fails to differentiate intermediate reasoning quality, leading to suboptimal training results. In this paper, we introduce Agent Reasoning Reward Model (Agent-RRM), a multi-faceted reward model that produces structured feedback for agentic trajectories, including (1) an explicit reasoning trace , (2) a focused critique that provides refinement guidance by highlighting reasoning flaws, and (3) an overall score that evaluates process performance. Leveraging these signals, we systematically investigate three integration strategies: Reagent-C (text-augmented refinement), Reagent-R (reward-augmented guidance), and Reagent-U (unified feedback integration). Extensive evaluations across 12 diverse benchmarks demonstrate that Reagent-U yields substantial performance leaps, achieving 43.7% on GAIA and 46.2% on WebWalkerQA, validating the effectiveness of our reasoning reward model and training schemes. Code, models, and datasets are all released to facilitate future research.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making AI “agents” better at thinking through multi-step tasks, like searching the web, reading files, writing and running code, or understanding images and audio. The authors created a special “reward model” called Agent-RRM that doesn’t just say whether the final answer is right or wrong. Instead, it looks at the agent’s reasoning process, points out mistakes with helpful comments, and gives a score. Using this richer feedback, they train agents (called Reagent) to reason more clearly and use tools more effectively.
What questions does it ask?
The paper explores three simple questions:
- Can agents learn better if they get feedback on their reasoning steps, not just a final “correct/incorrect”?
- Is it useful to give agents both a number score and a text critique (like a teacher’s notes)?
- What’s the best way to combine these different kinds of feedback during training to boost performance across many tasks?
How did the researchers approach the problem?
Key idea: a “Reasoning Reward Model”
Think of the agent as a student solving a complicated problem with multiple steps. Most current training only says “You got the answer right” or “wrong” at the end. That’s like grading a test without marking any mistakes on the student’s work—it doesn’t help them improve their thinking.
Agent-RRM acts like a thoughtful teacher. For each solution (“trajectory”) the agent produces, Agent-RRM outputs:
- An internal reasoning trace: a short explanation of how it judged the agent’s steps.
- A focused critique: clear, targeted comments highlighting what went wrong and how to fix it.
- An overall score: a number between 0 and 1 capturing the quality of the whole attempt.
These three parts give both “why” and “how” feedback, not just “pass/fail.”
Three ways to use the feedback
The authors tested three training strategies for their agent, named Reagent:
- Reagent-C (text-augmented refinement): The agent first tries a solution. Then it reads the critique and immediately tries again, improving its answer using those tips. No retraining here—just smarter second tries using the critique.
- Reagent-R (reward-augmented guidance): The agent is trained with a mix of two signals: the usual “final answer correctness” plus Agent-RRM’s quality score. This teaches the agent that good reasoning—even if the final answer isn’t perfect—is valuable.
- Reagent-U (unified feedback integration): The agent combines both worlds during training—using text critiques to refine its attempts and using scores to guide overall learning. This is the “best of both” approach.
Data and tools
The agent is trained and tested on large sets of problems across areas like math, knowledge-intensive questions, web browsing, and multimodal tasks. It also learns to use tools such as:
- Web search and browsing
- Python code execution
- File reading
- Image understanding
- Audio transcription
Training follows two steps:
- Supervised fine-tuning: Teach basic skills and tool use with good examples.
- Reinforcement learning: Let the agent try multiple solutions and improve using feedback (scores and critiques).
What did they find?
- Text critiques help at inference time: Even without retraining (Reagent-C), having the agent read and apply the critique to produce a second attempt often improves accuracy. It’s like a student revising their work after seeing teacher comments.
- Scores help during training: Adding Agent-RRM’s numeric score to the usual “correct/incorrect” (Reagent-R) gives the agent denser feedback and improves learning. This helps the agent distinguish “pretty good reasoning but flawed” from “completely off,” which typical pass/fail grading can’t.
- Combining both works best: The unified approach (Reagent-U), which uses both critiques and scores while training, delivers the strongest performance across many benchmarks. For example, Reagent-U reached about 43.7% on GAIA (a tough general assistant benchmark) and 46.2% on WebWalkerQA (a web navigation benchmark), beating other open-source methods with similar model sizes.
Why does it matter?
When agents get feedback only at the end, they can’t tell which steps were good or bad. This paper shows that giving step-aware feedback—both helpful comments and a score—leads to agents that:
- Reason more clearly across long, multi-step tasks
- Use tools more effectively (searching, coding, reading, and understanding media)
- Generalize better across different problem types, not just one narrow task
In everyday terms: a student who gets detailed, constructive feedback learns faster and makes fewer mistakes on complex assignments.
Implications and potential impact
- Better training recipes: Future agents can be trained with “reasoning-aware” feedback, not just final outcomes, making them more reliable in real-world tasks like research, education, and data analysis.
- More transparent evaluation: Because Agent-RRM explains its judgments, developers can see why an agent struggled and fix specific weaknesses.
- Broader abilities: The approach improves not only text-only tasks but also multimodal ones (like combining search with coding and image/audio understanding), pushing agents closer to being genuinely useful assistants.
Overall, this paper suggests a practical way to build smarter, more careful AI agents by treating training like good teaching: show your work, get helpful notes, and learn from both your process and your results.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Scaling to larger models: Does Agent-RRM and Reagent-U continue to deliver gains at 14B–70B+ policy sizes and with larger reward models? Characterize scaling curves, sample efficiency, and stability across model sizes.
- Reward model reliability: How well do Agent-RRM <score> outputs correlate with human judgments across tasks? Provide calibration plots, rank correlations, and inter-annotator agreement with expert raters.
- Reward hacking robustness: Can agents game <score> or <critique> (e.g., via self-praise, instruction injection, or formatting exploits)? Develop adversarial evaluation suites and defenses (e.g., input sanitization, critique vetting).
- Faithfulness of > and <critique>: Are the generated reasons accurate and causally grounded in the trajectory? Conduct human audits to assess explanation faithfulness vs. post-hoc rationalization.
Component ablations: What is the marginal utility of each Agent-RRM output (<think>, <critique>, <score>)? Compare: score-only, critique-only, think-only, think+score, critique+score, and the full triad.
- Multi-round critique refinement: Does allowing multiple critique-and-revise iterations (vs. a single pass) improve outcomes or induce overfitting/oscillation? Study convergence and diminishing returns.
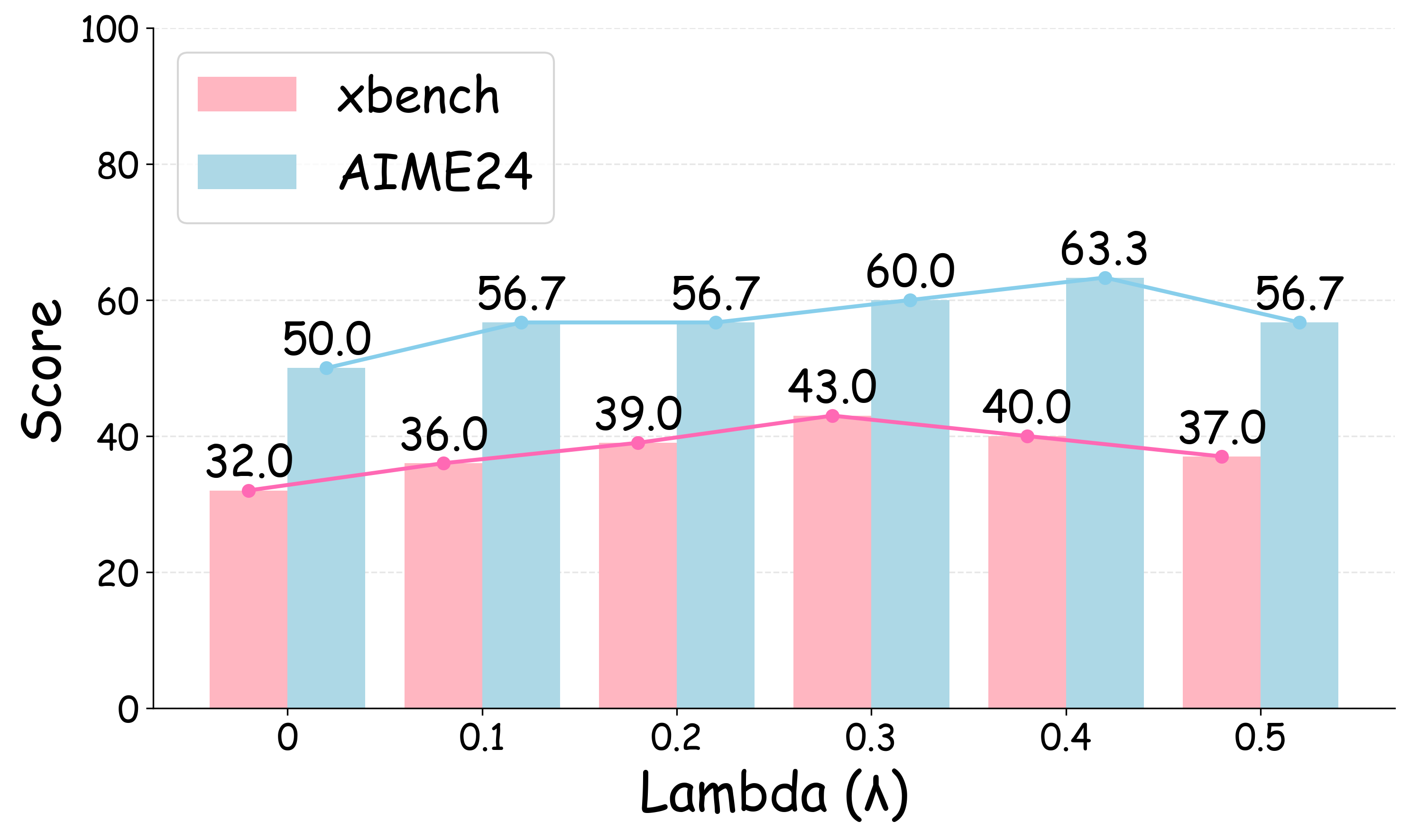
- Adaptive weighting of rewards: Instead of a fixed λ, can task-adaptive or curriculum-learned weights between rule-based and model-based rewards yield better stability and performance across domains?
- Generalization to unseen tools: How does the approach handle new tools or APIs not seen during training? Evaluate zero-shot tool onboarding and robustness to tool failures or latency.
- Broader, real-world environments: Performance on dynamic, noisy, or adversarial web environments (e.g., DOM changes, CAPTCHAs, content drift) remains untested. Establish reproducible, non-deterministic benchmarks.
- Data contamination checks: Quantify overlap between training corpora (Reagent-RL-709K/SFT-55.6K/RRM datasets) and evaluation sets (e.g., AIME, GAIA, WebWalkerQA). Release contamination audits and hashes.
- Judge-model bias and evaluation robustness: Results rely on a single judge (Qwen2.5-72B). How sensitive are conclusions to the choice of judge? Report cross-judge agreement, human validation, and statistical significance.
- Cross-domain and cross-lingual generalization: The work focuses on English, limited domains. Test transfer to non-English settings and domains like scientific workflows, software engineering, or legal reasoning.
- Cost–benefit and compute profiling: What is the additional training/inference cost of Agent-RRM (especially for Reagent-C) relative to accuracy gains? Provide wall-clock, GPU hours, and throughput vs. performance trade-offs.
- Stability and reproducibility: Training curves, run-to-run variance, and sensitivity to seeds/hyperparameters are not reported. Measure stability of GRPO with and without Agent-RRM across multiple seeds.
- Credit assignment in long-horizon tasks: Trajectory-level scores may still mask step-level nuances. Can hybrid credit assignment (e.g., weak step-value estimates from Agent-RRM think/critique) improve learning without high annotation cost?
- Partial correctness and nuanced rewards: Current rule-based rewards appear binary. How does Agent-RRM handle partially correct reasoning or intermediate success? Explore graded outcome rewards and their interplay with <score>.
- Safety and misuse risks: Textual critiques could inadvertently teach harmful strategies or facilitate prompt injection. Develop safety filters for critiques and evaluate on red-teaming benchmarks.
- Robustness to prompt injection in trajectories: Can malicious content within trajectories manipulate Agent-RRM outputs? Evaluate and harden against injection and instruction hijacking.
- Domain shift for reward modeling: Agent-RRM is trained on trajectories from a set of specific models and tasks. How well does it generalize to trajectories from different families or novel task distributions?
- Tool-specific diagnostics: Which tools benefit most from reasoning rewards and critiques (search, browsing, code, vision, audio)? Provide per-tool ablations and error taxonomies.
- Unified feedback design choices: In Reagent-U, is advantage normalization across initial and refined pools optimal? Compare alternative pooling/normalization strategies and credit assignment across stages.
- Inference-time usage policies: Reagent-U drops critiques at inference; Reagent-C uses them. When do inference-time critiques pay off vs. hurt latency/throughput? Characterize deployment regimes.
- Open-ended tasks without ground-truth: For tasks lacking verifiable outcomes, how should rule-based rewards be defined and combined with <score>? Formalize training recipes for such settings.
- Reward model capacity and pretraining: Does a larger or differently pretrained Agent-RRM improve supervision quality? Explore capacity scaling, instruction-tuning strategies, and domain-specialized RRM variants.
- Error mode analysis: Provide detailed case studies of failure types (e.g., hallucinated tool outputs, mis-parsed pages, brittle code). Quantify how critiques and scores address each error class.
- Data licensing and reproducibility constraints: Some resources (e.g., Bing, GPT-OSS-120B annotations) may limit replication. Provide alternatives or instructions for reproducing results without proprietary dependencies.
- Long-term effects of critique-based training: Does integrating critiques during training cause distributional drift or reduced robustness on out-of-domain tasks? Track post-training generalization over time.
- Interaction with alternative RL algorithms: Is GRPO uniquely effective here? Compare PPO, DPO-style objectives, and off-policy methods for stability, sample efficiency, and final performance.
- Pass@k and decoding strategies: Most results emphasize pass@1 with fixed sampling. Explore the interaction between critique/reward signals and decoding temperature, beam search, or reranking strategies.
Practical Applications
Overview
The paper introduces Agent-RRM, a multi-faceted reasoning reward model that produces an explicit reasoning trace, targeted critiques, and a scalar score for agent trajectories, and integrates it into agents via three strategies: Reagent-C (inference-time critique/refinement), Reagent-R (reward-augmented RL), and Reagent-U (unified scalar + textual feedback in RL). This enables denser, more actionable supervision for long-horizon, tool-using agents across search, coding, and multimodal tasks.
Below are practical applications grounded in these findings, organized by deployment horizon and linked to relevant sectors, tools/products, workflows, and feasibility assumptions.
Immediate Applications
These applications can be deployed now using Agent-RRM and Reagent-C/Reagent-R with modest engineering effort, leveraging existing agent stacks and tool APIs.
- Critique-as-a-Service for existing LLM agents (software, knowledge work)
- Description: Wrap current agents with Agent-RRM to generate targeted critiques and a quality score before finalizing answers; use Reagent-C to perform training-free, in-context refinement.
- Tools/Products/Workflows: “Critique Plugin” for LangChain/LlamaIndex, an Agent-RRM API endpoint; add a pre-answer “coach” step that uses <critique> to repair reasoning and tool calls.
- Assumptions/Dependencies: Access to Agent-RRM weights; latency budget for an extra critique pass; prompt and context management to avoid token overruns; monitoring to prevent reward hacking behaviors.
- Deep web research assistants for literature reviews and due diligence (academia, finance, journalism, policy)
- Description: Use Search + Web Browse tools with Agent-RRM critiques to reduce logical errors and improve evidence chaining and citation quality.
- Tools/Products/Workflows: “Evidence Builder” workflow with Bing search, page fetch, chain-of-thought inspection via > , and refinement via <critique>. > - Assumptions/Dependencies: Reliable search and scraping APIs; domain-specific guardrails (e.g., citation style, fact-checking); handling paywalled content and source provenance. > > - Math tutoring and auto-grading with rubric-style feedback (education) > - Description: Provide step-by-step critiques and holistic scoring for student solutions; use <critique> to suggest corrections and <score> to grade consistency. > - Tools/Products/Workflows: Tutor app, LMS integration; “rubric generator” based on Agent-RRM; practice mode using Reagent-C for student refinement. > - Assumptions/Dependencies: Alignment to curricula and exam policies; mitigation of hallucinations; accessibility considerations; clear disclaimers (non-proctored, advisory feedback). > > - Code troubleshooting assistant with sandboxed execution (software) > - Description: Combine Python Code Interpreter with Agent-RRM feedback to detect logical errors, missing edge cases, and suboptimal algorithms; automatically refine patches. > - Tools/Products/Workflows: IDE extension (VS Code/JetBrains) that runs tests, captures traces to <think>, and applies <critique>-guided fixes. > - Assumptions/Dependencies: Secure, sandboxed runtime; test data availability; version control integration; compute limits for execution-heavy tasks. > > - Multimodal helpdesk triage (IT operations, customer support) > - Description: Use Image Descriptor and Audio Converter plus Agent-RRM to assess troubleshooting steps and produce a scored diagnostic pathway. > - Tools/Products/Workflows: Ticket assistant that ingests screenshots/logs/audio, generates a <think> diagnosis and <critique> of gaps, then proposes next actions. > - Assumptions/Dependencies: Privacy and PII handling; secure file ingestion; ability to redact sensitive content; organizational SOP alignment. > > - Agent trajectory QA and compliance auditing (enterprise, public policy) > - Description: Employ Agent-RRM to audit agent trajectories, producing a transparent reasoning trace and a quality score for compliance, reproducibility, and post-mortems. > - Tools/Products/Workflows: “Agent QA Dashboard” that logs <think>/<critique>/<score>, flags risky tool calls, and supports manager/judge reviews. > - Assumptions/Dependencies: Policy/standard definitions; storage and audit trails; reviewer workflows; calibration of scoring thresholds. > > - Reward-augmented training for domain-specific agents (software, industry) > - Description: Use Reagent-R to integrate <score> with rule-based rewards, reducing reward sparsity and accelerating policy improvement in specialized domains (e.g., customer support, internal search). > - Tools/Products/Workflows: RL pipeline with GRPO, joint rule + model rewards, λ tuning; reference model monitoring to avoid drift. > - Assumptions/Dependencies: GPU budget; domain training data; clear outcome validation (for rule-based rewards); careful λ calibration to balance process and outcome signals. > > - Personal research/planning assistant with iterative refinement (daily life) > - Description: Apply Reagent-C to improve travel planning, product comparisons, and multi-step tasks; <critique> highlights missing constraints and inconsistencies. > - Tools/Products/Workflows: Browser-based assistant with two-pass responses; checklist generation via <critique>; consolidated summary with <score>-based confidence. > - Assumptions/Dependencies: Reliable browsing; user privacy; handling dynamic content; UX for presenting critiques without overwhelming users. > > ## Long-Term Applications > > These applications require further research, scaling, domain adaptation, or regulatory clearances; they benefit most from Reagent-U’s unified training and from larger/reliable base models and richer environments. > > - Healthcare evidence synthesis and clinical research assistants (healthcare) > - Description: Long-horizon agents that ingest papers, clinical guidelines, and multimodal data to produce verified syntheses with transparent <think>/<critique> trails. > - Tools/Products/Workflows: EHR-integrated research companion; systematic review automation; critique-driven counterargument generation. > - Assumptions/Dependencies: Strict privacy/regulatory compliance (HIPAA/GDPR), medical accuracy thresholds, domain-finetuned reward models, clinical validation before use. > > - Financial compliance and due diligence automation (finance) > - Description: Agents reading filings, contracts, and market data with structured critiques of risk and compliance gaps; <score> calibrates assurance levels. > - Tools/Products/Workflows: “Compliance copilot” that produces audit-ready traces; exception handling using critique-guided remediation. > - Assumptions/Dependencies: Access to proprietary datasets; auditability; model calibration against regulatory frameworks; human-in-the-loop governance. > > - Government policy analysis and procurement audits (public policy) > - Description: Multi-document reasoning agents performing accountability checks with traceable critique outputs, enabling transparent decisions and public reporting. > - Tools/Products/Workflows: Policy assessment pipelines; reproducible audit trails with <think>/<critique>; dashboards for oversight committees. > - Assumptions/Dependencies: Data access; fairness and bias audits; standardized evaluation rubrics; legal vetting. > > - Scientific automation and “AI for science” assistants (science/engineering) > - Description: Agents coordinating code execution, data analysis, and file-based reasoning to design experiments, critique methods, and refine analyses. > - Tools/Products/Workflows: Lab notebook automation; experiment planning with critique-driven refinements; provenance-preserving pipelines. > - Assumptions/Dependencies: Instrument APIs; dataset licensing; rigorous verification protocols; domain-specific reward calibration. > > - Robotics high-level planning with reasoning rewards (robotics) > - Description: Use multimodal reasoning rewards to correct task plans and tool-use sequences, offering language-based critiques of plans before execution. > - Tools/Products/Workflows: Planning layer that combines <score> with <critique> to adjust routes, task decomposition, and safety checks. > - Assumptions/Dependencies: Sim-to-real transfer; integration with motion planners; safety certifications; step-level reward robustness. > > - Enterprise agent governance platforms (software/enterprise) > - Description: Centralized “Reasoning Reward Service” that evaluates, critiques, and scores trajectories from all internal agents for safety, quality, and performance. > - Tools/Products/Workflows: Organization-wide APIs, policy templates, dashboards; SLA-based governance with automatic escalation. > - Assumptions/Dependencies: Standardized logging schemas; cross-team adoption; incident response integration; cost controls. > > - Personalized learning platforms with adaptive critique shaping (education) > - Description: Curriculum-aligned agents that adapt difficulty and guidance based on <score> trajectories and targeted <critique> feedback over time. > - Tools/Products/Workflows: Adaptive lesson planners; learner modeling; mastery tracking with transparent reasoning traces. > - Assumptions/Dependencies: Longitudinal evaluation; data privacy for learners; educator co-design; bias mitigation. > > - Safety oversight and red-teaming for agents (cross-sector) > - Description: Use Agent-RRM to detect unsafe tool calls, deception, or brittle reasoning; <critique> serves as explainable flags for human review. > - Tools/Products/Workflows: Continuous red-teaming pipelines; safety scorecards; pre-deployment audits across tasks and modalities. > - Assumptions/Dependencies: Safety datasets; policy definitions for unacceptable behaviors; regular calibration and adversarial testing. > > ### Notes on Feasibility and Assumptions > > - Model scale and domain transfer: The paper focuses on ~8B models; scaling to larger models or specialized domains may amplify gains but requires finetuning, calibration, and more compute. > > - Tool availability and reliability: Applications depend on robust access to search, browsing, code execution, file reading, and multimodal processing; sandboxing and API quotas are critical constraints. > > - Training data and rewards: Rule-based outcome validation is essential for RL; the λ parameter must be tuned to balance process vs outcome rewards; guard against reward hacking via audits. > > - Safety, privacy, and compliance: Sectors like healthcare and finance require stringent oversight, data governance, and human-in-the-loop review before operational deployment. > > - Latency and cost: Critique/refinement adds an extra pass; batch inference and caching can mitigate costs; prioritize where quality gains justify overhead. > > - Evaluation and auditing: Transparent <think>/<critique>/<score> traces enable human review, but scoring calibration and judge consistency must be maintained across domains.
Glossary
- Advantage: A normalized measure of how much better an output’s reward is relative to its group, used to stabilize policy updates in RL. "The advantage is computed by normalizing the rewards within the group :"
- Agent Reasoning Reward Model (Agent-RRM): A multi-faceted evaluator that produces structured feedback for agent trajectories, including reasoning, critique, and a score. "we introduce Agent Reasoning Reward Model (Agent-RRM), a multi-faceted reward model that produces structured feedback for agentic trajectories..."
- Agentic Reinforcement Learning (Agentic RL): Reinforcement learning focused on training agents to act in dynamic environments with tools and multi-step reasoning. "Agentic Reinforcement Learning (Agentic RL) has achieved notable success in enabling agents to perform complex reasoning and tool use."
- Decoding temperature: A sampling parameter controlling randomness in generation; lower values are more deterministic. "unless otherwise specified, we report pass@1 using a decoding temperature of 0.6 and top-p of 0.95."
- Difficulty-aware sampling: A data selection approach that accounts for problem difficulty to improve training distribution. "and (3) difficulty-aware sampling."
- Ensemble of models: Combining outputs or trajectories from multiple models to cover diverse error patterns or behaviors. "We sample reasoning trajectories from an ensemble of models including Qwen3-8B/14B, Qwen3-ARPO-DeepSearch (8B/14B), Qwen2.5-7B-ARPO, Qwen2.5-WebDancer (7B/32B), and DeepSeekV3.1..."
- GRPO (Group Relative Policy Optimization): An RL algorithm where multiple samples per query are jointly optimized using group-relative advantages and KL regularization. "In Group Relative Policy Optimization (GRPO)~\cite{shao2024deepseekmath}, for a query sampled from the dataset , the policy generates a group of outputs such that:"
- Holistic quality score: A single overall score assessing the total quality of a trajectory beyond binary correctness. "and (3) a holistic quality score."
- Importance sampling ratio: The ratio between current and old policy probabilities used to correct for distribution shift in policy updates. "Let $r_i(\theta) = \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}(o_i|q)}$ denote the importance sampling ratio."
- In-context prompting: Guiding a model’s behavior at inference time by supplying examples or instructions within the prompt. "applied directly to the Qwen3-8B via in-context prompting."
- KL divergence: A regularization term measuring how much the current policy deviates from a reference policy. "and denotes the KL divergence between current policy and reference model for the -th output:"
- Long-horizon agentic tasks: Tasks requiring many steps and tool interactions where intermediate reasoning quality matters. "This design is inherently limiting for long-horizon agentic tasks requiring multi-step tool utilization~\cite{feng2025group,liu2025agentic,zhang2025rlvmr}."
- Natural language critique: Textual feedback explaining errors and providing guidance to refine reasoning or actions. "leaving the natural language critique \cite{zhang2025critique} largely unexplored, which could provide more granular guidance for agentic policy."
- Pair-wise preferences: A reward modeling approach that compares two candidate trajectories to decide which is better. "existing reasoning-based Reward Models focus on pair-wise preferences~\cite{li2025one, liu2025agentic, hu2025openreward}, which frequently introduces inherent biases..."
- Pass@1: The metric reporting the success rate when only the top single generated answer is considered. "unless otherwise specified, we report pass@1 using a decoding temperature of 0.6 and top-p of 0.95."
- Process Reward Model: A model that evaluates intermediate steps in a trajectory according to principles or rubrics. "PPR~\cite{xu2025hybrid} employs a process reward model to evaluate trajectory steps based on a predefined principle set."
- Reward hacking: Exploiting flaws in a reward function to achieve high scores without genuinely solving the task. "they are often plagued by prohibitive annotation costs~\cite{rahman2025spark} and a susceptibility to reward hacking~\cite{zhang2025linking}."
- Reward sparsity: The issue where feedback is only provided at the end (e.g., final correctness), offering little guidance during multi-step reasoning. "To explore whether dense model-based rewards can alleviate reward sparsity in agentic RL, we evaluate Reagent-R..."
- Rule-based rewards: Rewards derived from deterministic checks like final answer correctness or adherence to predefined rules. "The reward is defined as a combination of rule-based correctness and model-based quality evaluation:"
- Supervised Fine-tuning (SFT): Training a model on labeled data to learn desired behaviors before RL. "For Supervised Fine-tuning (SFT), we prioritize the holistic quality of reasoning trajectories."
- Textual critiques: Language-based feedback used to identify and correct errors in generated trajectories. "textual critiques are utilized exclusively during the training phase to internalize reasoning capabilities;"
- Top-p: Nucleus sampling parameter that limits sampling to the smallest set of tokens whose cumulative probability exceeds p. "unless otherwise specified, we report pass@1 using a decoding temperature of 0.6 and top-p of 0.95."
- Unified Feedback Integration: A training scheme that combines scalar rewards with critique-driven refinement into a single RL loop. "Unified Feedback Integration, which harmonizes multi-source rewards with critique-augmented sampling."
- Verifiable Reward (RLVR): An RL paradigm where rewards are grounded in verifiable signals, improving reliability and reasoning. "Reinforcement Learning with Verifiable Reward (RLVR) has achieved remarkable success in improving the reasoning capabilities of LLMs \cite{liu2025understanding, feng2025onethinker, tang2025rethinking, chen2025advancing, chen2025ares}."
Collections
Sign up for free to add this paper to one or more collections.