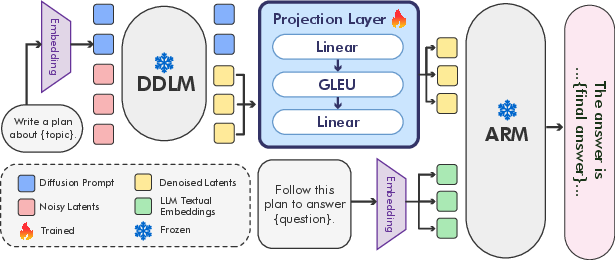
- The paper presents a novel planner-executor framework that integrates DDLMs for planning with ARMs for execution.
- It demonstrates that latent-space collaboration significantly boosts accuracy and reduces token usage on reasoning benchmarks.
- Diagnostic analyses isolate planner and executor errors, guiding future improvements in hybrid AI architectures.
Summary of "Planner and Executor: Collaboration between Discrete Diffusion and Autoregressive Models in Reasoning"
The paper "Planner and Executor: Collaboration between Discrete Diffusion and Autoregressive Models in Reasoning" explores the potential of coupling Discrete Diffusion LLMs (DDLMs) with Autoregressive Models (ARMs) to enhance reasoning tasks. The investigation centers on how these models can complement each other's weaknesses through a planner-executor framework, and compares text-space and latent-space collaboration channels.
Introduction to Hybrid Architectures
Recent advancements in reasoning tasks have been largely dominated by autoregressive models (ARMs) due to their proficiency in generating coherent and human-readable outputs. However, these models are computationally expensive due to their reliance on long token sequences. Discrete diffusion LLMs (DDLMs), with their ability to generate outputs in parallel using fixed steps, present a compelling alternative, especially for complex reasoning and planning tasks. This paper proposes integrating these two paradigms to leverage DDLMs' planning capabilities while utilizing ARMs' execution strength.
Two primary modes of collaboration are analyzed: text-space collaboration, where the planner generates an explicit textual plan for the executor, and latent-space collaboration, which employs a learned projection to communicate plans in a latent form. Initial findings reveal that latent-space collaboration significantly improves accuracy while reducing token consumption compared to text-space efforts and standalone models.
Methodology
Planner-Executor Framework
In this framework, the planner (often a DDLM) is responsible for structuring intermediary reasoning steps, while the executor (an ARM) produces the final answer. The interaction between the planner and executor can occur via:
Experimental Setup
Models and Benchmarks
The study employs two diffusion models, LLada-8B-Instruct and Dream-v0-Instruct-7B, and compares their collaboration with ARMs like Qwen2.5-7B-Instruct and Llama-3.1-8B-Instruct. The models are evaluated across reasoning benchmarks including ARC, MMLU, AIME 2024, and DART.
Diagnostic Analysis
The diagnostic component assesses the failure modes in planner-executor interactions. Setup X and Setup Y identify whether failures originate from planning errors or execution limitations, respectively (Figure 2). This analysis aids in understanding the comparative effectiveness of text-space versus latent-space collaboration, with latent setups showing reduced planner-related errors.
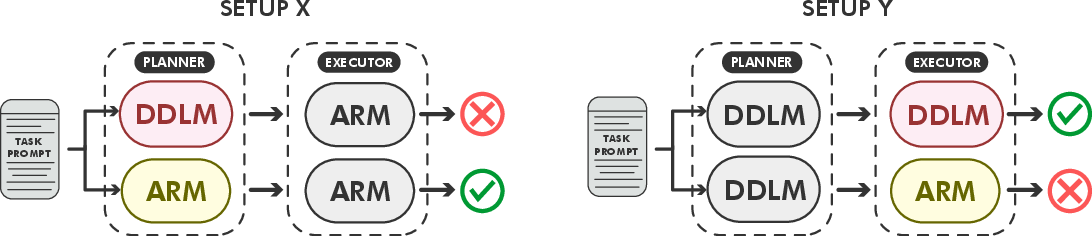
Figure 2: Diagnostic configurations for attributing errors to planner or executor. Setup X tests whether failures stem from the planner: if replacing the diffusion planner (DDLM) with an autoregressive planner (ARM) fixes the output, the error is attributed to the DDLM. Setup Y tests executor reliability: if a diffusion executor succeeds where an ARM executor fails, the limitation lies in the executor.
Results
Text-Space vs Latent-Space Collaboration
The study reveals substantial performance gains with latent-space collaboration. On benchmarks like DART and AIME, latent-space interaction achieves higher accuracy while using substantially fewer tokens, highlighting both the computational efficiency and effectiveness of latent exchange.
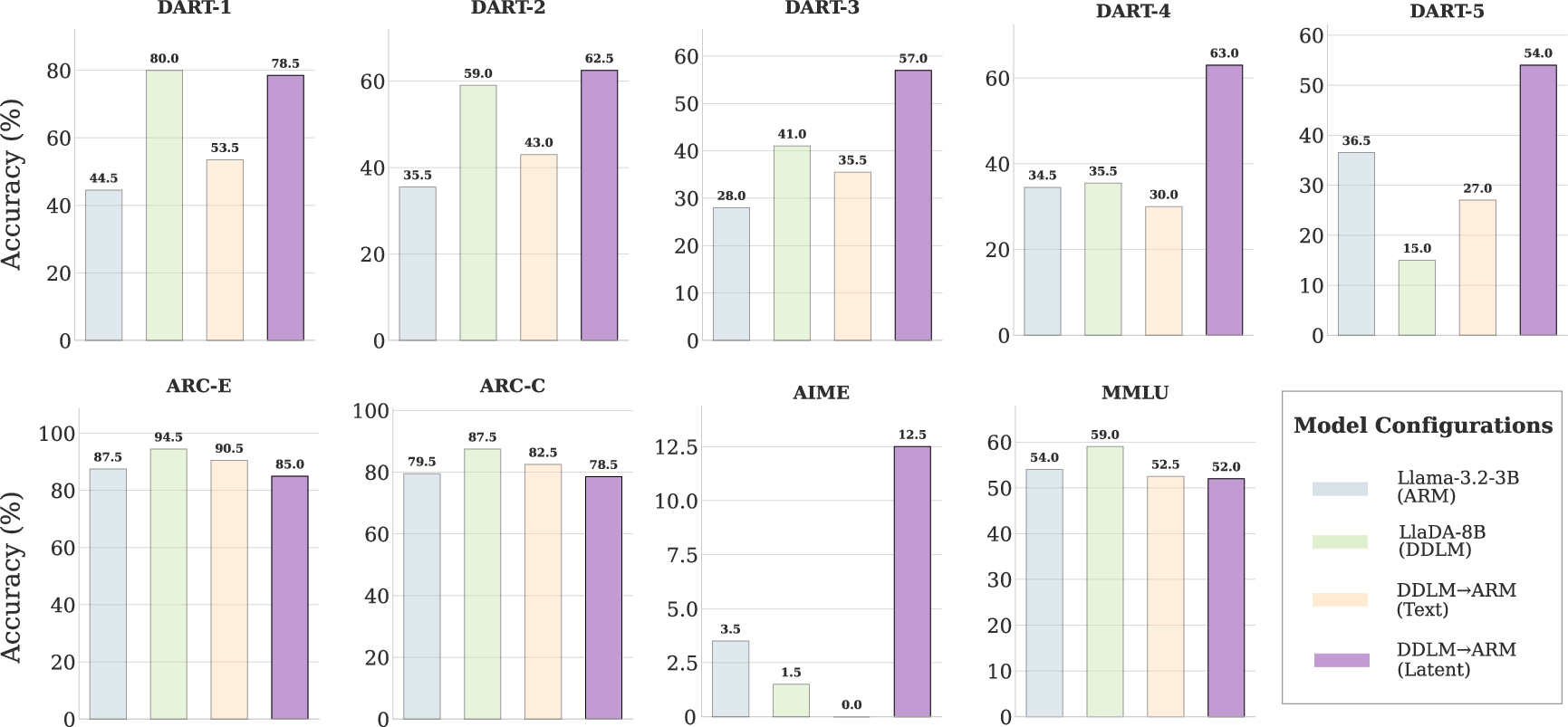
Figure 3: Benchmark comparison of text-space vs.\ latent-space collaboration. Accuracy of isolated models (LLaMA-3.2-3B ARM, LLaDA-8B DDLM) and collaborative configurations. In the latent setting, DDLM (64-token planner) combined with the ARM executor consistently outperforms text-space collaboration on DART and AIME, while maintaining comparable performance on ARC and MMLU.
Latent-space setups surpass even strong reasoning models like Qwen3 in a significantly more token-efficient manner. Specific configurations using 64 planner tokens provide an optimal balance of accuracy and economy, avoiding redundant reasoning steps observed with longer plans.
Discussion
The paper establishes discrete diffusion and autoregressive models as complementary agents in reasoning tasks. The successful implementation of latent-space collaboration shows promise for more efficient and accurate AI architectures. However, the trade-off between interpretability and latent efficiency presents an avenue for future exploration, particularly in enhancing interpretability without sacrificing performance. Furthermore, aligning planner and executor representations through joint training offers another potential advancement path.
Conclusion
Positioning DDLMs as planners and ARMs as executors, with latent-space data exchange, offers an efficient framework for addressing complex reasoning tasks. This study's insights lay a groundwork for future research in hybrid architectures, balancing computational savings with robust performance, thus expanding the horizons of reasoning in large models.