- The paper introduces a dual chain-of-thought framework that integrates semantic planning with octant-based geometric reasoning to generate coherent 3D models.
- The methodology utilizes a collaborative reinforcement learning strategy with multiple critics to optimize semantic, spatial, and physical coherence.
- Empirical evaluations demonstrate state-of-the-art performance in text-to-3D and image-to-3D generation, with enhanced semantic alignment and geometric fidelity.
CoRe3D: Collaborative Reasoning as a Foundation for 3D Intelligence
Overview and Motivation
CoRe3D presents a unified foundation model for 3D understanding and generation, leveraging an explicit collaborative reasoning paradigm. The framework is constructed around two interdependent chain-of-thought (CoT) streams—semantic reasoning for high-level intent extraction from language, and geometric reasoning for localized spatial synthesis. This design addresses the persistent limitation in prior 3D generative approaches: the inability to faithfully align open-ended linguistic prompts with physically and semantically coherent 3D outputs due to their lack of explicit reasoning. The model unifies both 3D perception and synthesis in a single LLM, capable of bi-directional modality adaptation.
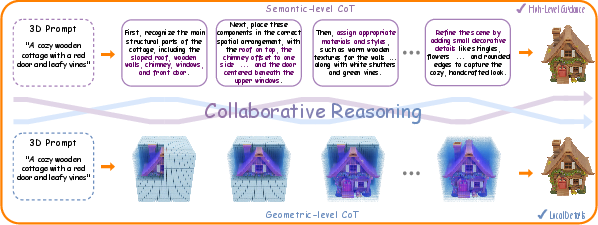
Figure 1: CoRe3D unifies semantic chain-of-thought and octant-based geometric reasoning, enabling interpretable 3D understanding and generation.
Methodology: Architectures and Reasoning Paradigm
Semantic and Geometric Reasoning
CoRe3D introduces a dual reasoning process:
- The semantic reasoning trace expands a textual prompt into a detailed actionable plan, providing explicit descriptions for object category, spatial layout, materials, and visual attributes.
- The geometric reasoning trace operates autoregressively over an octant-based discretization of 3D latent space, facilitating compositional and locality-aware geometry construction via a vector-quantized variational autoencoder (VQ-VAE) that encodes 643 voxel grids into 512 tokens.
This duality ensures both global semantic alignment and local geometric consistency, avoiding the pitfalls of category-fixed part representations and semantically agnostic voxel predictors.
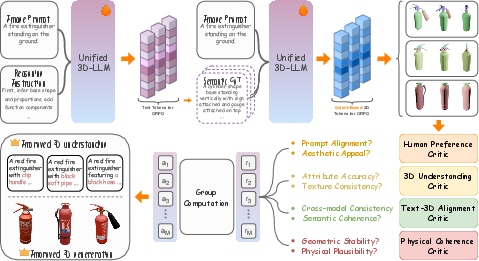
Figure 2: Overview of CoRe3D—semantic and geometric reasoning traces are generated by a unified 3D LLM and evaluated by an ensemble of critics for multi-objective optimization.
Collaborative Optimization via Co-GRPO
The joint optimization employs a collaborative extension of Group Relative Policy Optimization (GRPO), called Co-GRPO. This reinforcement learning strategy utilizes an ensemble of four critics:
- Human Preference: Perceptual quality and prompt relevance.
- 3D Understanding: Attribute and part correctness using pretrained 3D-VQA models.
- Text–3D Alignment: Faithfulness via embedding similarity between semantic traces and geometry.
- Physical Coherence: Analytical rewards enforcing topological stability, rigging continuity, and self-intersection minimization.
Dense scalar rewards from critics are aggregated, and policy updates are driven by normalized advantages in a groupwise trajectory sampling scheme. This ensures robustness and fine-grained credit assignment for both reasoning and synthesis, without explicit gold reasoning supervision.
Octant-Based 3D VQ-VAE
The octant-based representation supports efficient serial generation and locality, quantizing eight adjacent latent voxels into a single octant token. Positional embeddings post-quantization make the model location-aware within content-centric codebooks. Serialization follows Morton (Z-order) curves for spatial locality preservation.
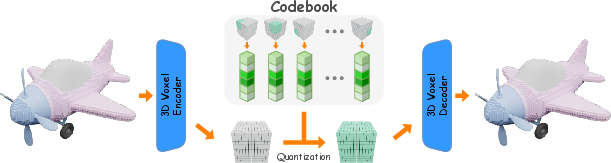
Figure 3: Octant-based 3D VQ-VAE encodes voxel geometry into latent blocks, quantizes via a shared codebook, and reconstructs high-fidelity voxel grids.
Empirical Evaluation
The model is pretrained and finetuned on a large-scale multimodal dataset (3D-Alpaca, ~2.56M samples) covering text-to-3D, image-to-3D, captioning, and editing. CoRe3D is initialized from ShapeLLM-Omni and augmented with octant tokenization.
Quantitative Results
CoRe3D achieves state-of-the-art performance across standard language benchmarks (MMLU, PIQA, GSM8K, SIQA). Notably, it matches or exceeds leading vision-LLMs and specialized 3D LLMs in general conversational and reasoning tasks.
In 3D captioning on Objaverse held-out sets, CoRe3D outperforms prior models on all metrics (BLEU-1, ROUGE-L, METEOR, Sentence-BERT, SimCSE), evidencing the impact of reasoning-centric generative training.
For text-to-3D and image-to-3D generation tasks, CoRe3D yields the top CLIP scores, Frechet Distance, and Kernel Distance, surpassing Structured Latent VQ-VAE baselines (SAR3D, CLAY, Trellis) and outperforming ShapeLLM-Omni, especially in semantic faithfulness and spatial fidelity.
Qualitative Results
The model demonstrates superior geometric fidelity, cleaner topology, and semantic alignment in both image-to-3D and text-to-3D tasks—even for complex or indirect prompts requiring referential inference and world knowledge. CoRe3D interprets ambiguous descriptions, producing objects (e.g., "Statue of Liberty" from symbolic prompts) that align precisely with the intended referent.

Figure 4: CoRe3D produces 3D shapes with strong geometric fidelity and semantic alignment from image prompts, outperforming baselines.

Figure 5: Text-to-3D synthesis shows CoRe3D’s robust prompt-following and interpretative capability.

Figure 6: Challenging prompt synthesis—CoRe3D correctly infers implicit object meaning.

Figure 7: Collaborative reasoning enables fine-grained 3D part editing with faithful instruction comprehension.
Ablation Studies
Removing either semantic or geometric CoT significantly degrades performance: semantic CoT is critical for category and attribute alignment, while geometric CoT governs spatial accuracy. Both are necessary for optimal captioning and generation.

Figure 8: Ablations show that both semantic and geometric CoT contribute significantly, with dual reasoning maximizing final fidelity.
Zero-shot CoT Comparisons
Zero-shot CoT models lacking explicit training produce shallow, generic object descriptions and oversimplified 3D forms, while CoRe3D’s trained semantic-level CoT yields actionable, detailed structural cues and higher-fidelity shapes.
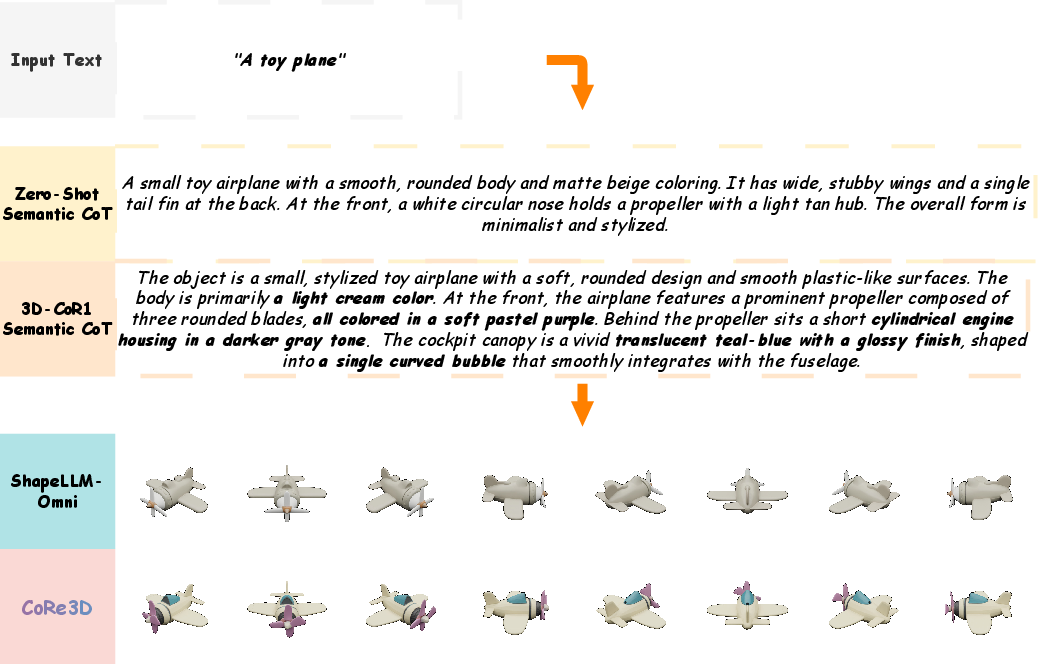
Figure 9: Zero-shot CoT yields generic structural descriptions leading to oversimplified 3D synthesis.
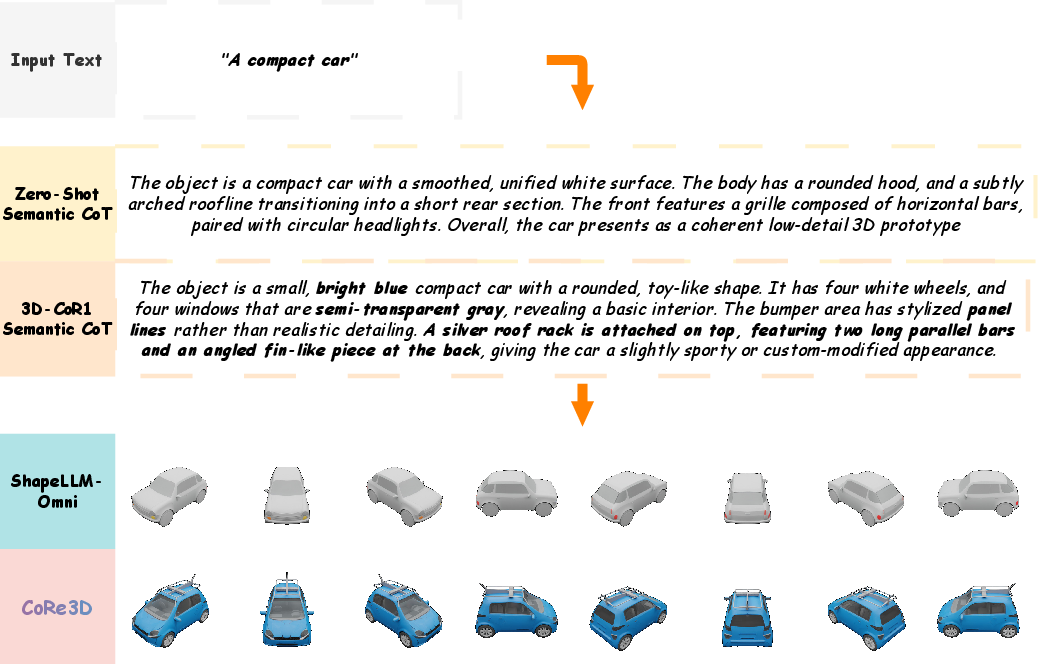
Figure 10: Trained CoRe3D CoT provides richer structural guidance for semantic fidelity.
Additional Image-to-3D Results
CoRe3D demonstrates robust reconstruction even for visually complex inputs, maintaining spatial coherence and color consistency.
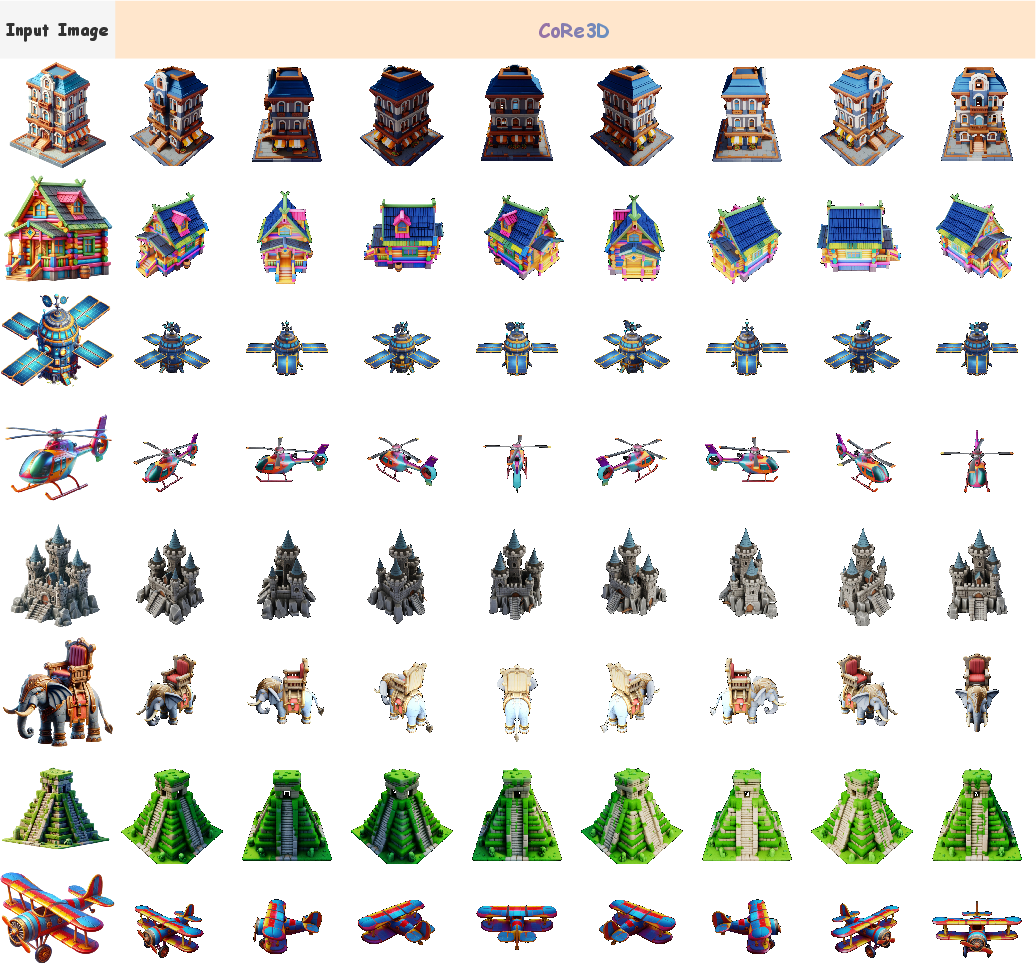
Figure 11: CoRe3D delivers stable and coherent 3D shapes for challenging image prompts.
Implications and Future Directions
CoRe3D establishes collaborative reasoning as an effective foundation for general 3D intelligence. Its explicit dual chain-of-thought architecture provides interpretable, controllable, and locally precise generation, advancing the prospects of interactive 3D asset manipulation, reciprocal 3D-to-text understanding, and high-fidelity reconstruction in diverse applications—robotics, simulation, and digital twins.
Practically, the model’s multi-critic RL optimization architecture enables robust transfer across tasks and data domains. Theoretically, integrating explicit reasoning into spatial generation bridges the gap between linguistic intent and geometric procedural synthesis, providing a scalable approach toward unified multimodal intelligence.
Further research could extend CoRe3D's reasoning traces to hierarchical octree tokenization, multi-agent collaborative planning, and more complex scene-level synthesis—accelerating progress in grounded cognitive modeling and embodied AI.
Conclusion
CoRe3D unifies semantic planning and geometric construction in 3D reasoning via a dual chain-of-thought and collaborative RL paradigm. The model achieves superior performance in 3D understanding and generation, successfully aligning linguistic prompts with spatially faithful and physically coherent 3D outputs. The collaborative reasoning pipeline, validated by ablations and multi-objective evaluation, establishes a scalable and interpretable foundation for general 3D intelligence.