- The paper presents a novel visual memory framework, MemOCR, that transforms structured rich-text into layout-driven images for adaptive long-horizon reasoning.
- It employs a two-stage process combining memory drafting with rich-text formatting and memory reading using OCR techniques to preserve key evidence under budget constraints.
- Experimental results demonstrate superior accuracy and graceful degradation compared to textual memory systems, especially under stringent token budgets.
MemOCR: Visual Memory for Layout-Aware, Budget-Efficient Long-Horizon Reasoning
Scaling agentic reasoning with LLMs inevitably collides with finite context windows: as interaction history accrues, effective reasoning depends on compressing salient information into a constrained working memory. Prevailing sensorized agentic memory paradigms—raw history injection and textual summarization—exhibit uniform information density, wasting budget on low-utility details due to static token allocation.
MemOCR introduces a paradigm shift: recasting serial memory streams as structured rich-text, rendered into a visual memory image, thereby enabling non-uniform, layout-driven information density. This adaptation facilitates explicit budget allocation, with typographic priority amplifying key evidence while compressing secondary details.
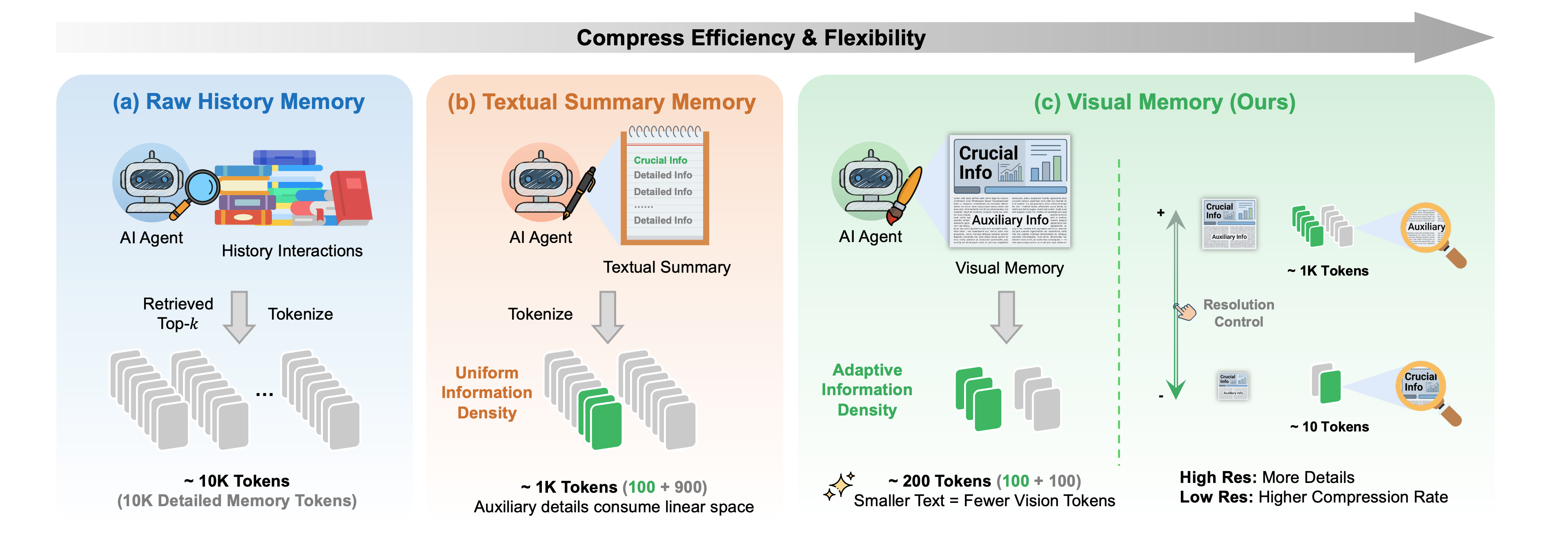
Figure 1: Comparison of memory paradigms: MemOCR’s visual memory enables adaptive information density by allocating token budget via layout, in contrast to raw history and textual summary memory which suffer from redundancy/noise.
Architecture of MemOCR
MemOCR implements a two-stage lifecycle:
- Memory Drafting (Text Domain): Agents incrementally maintain rich-text memory, encoding semantic priority via Markdown-specific structures (headers, bold, indentation). This decouples relevance from linear token cost during drafting, independent of the runtime memory budget.
- Memory Reading (Vision Domain): Rich-text is deterministically rendered into a 2D memory image. The agent receives this image as its exclusive working memory for question answering, relying on the spatial and typographical layout to access salient information post-compression.
- Budget-Aware Training Objectives (GRPO): MemOCR is trained via reinforcement learning, optimizing both drafting and reading policies under diverse budget constraints. Three QA objectives enforce: global correctness (standard question, sufficient memory), robustness under severe compression (augmented memory), and retrieval of secondary information when adequate tokens permit (augmented question).
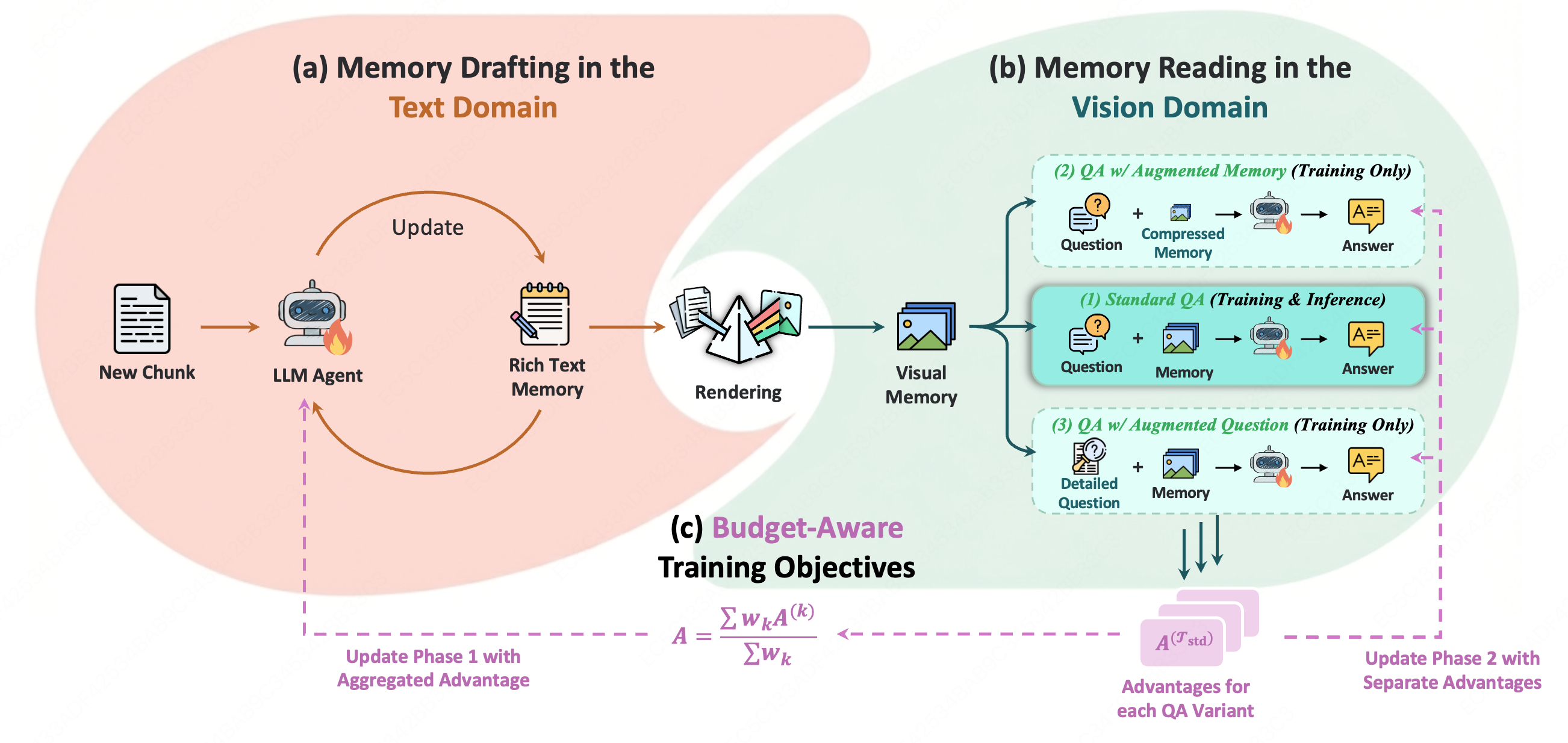
Figure 2: The MemOCR framework: memory drafting with rich-text prioritization; rendering to visual memory; reinforcement learning under budget-aware objectives to jointly optimize layout and reading policies.
Budget-Aware Training and Adaptive Layout
Linear token-based context mechanisms cannot guarantee the preservation of key evidence under hard budget constraints. MemOCR’s GRPO-based regime leverages data augmentation to simulate compression stress, incentivizing agents to concentrate crucial evidence in visually dominant regions—e.g., headers, bold font—while allocating less token area to auxiliary details.
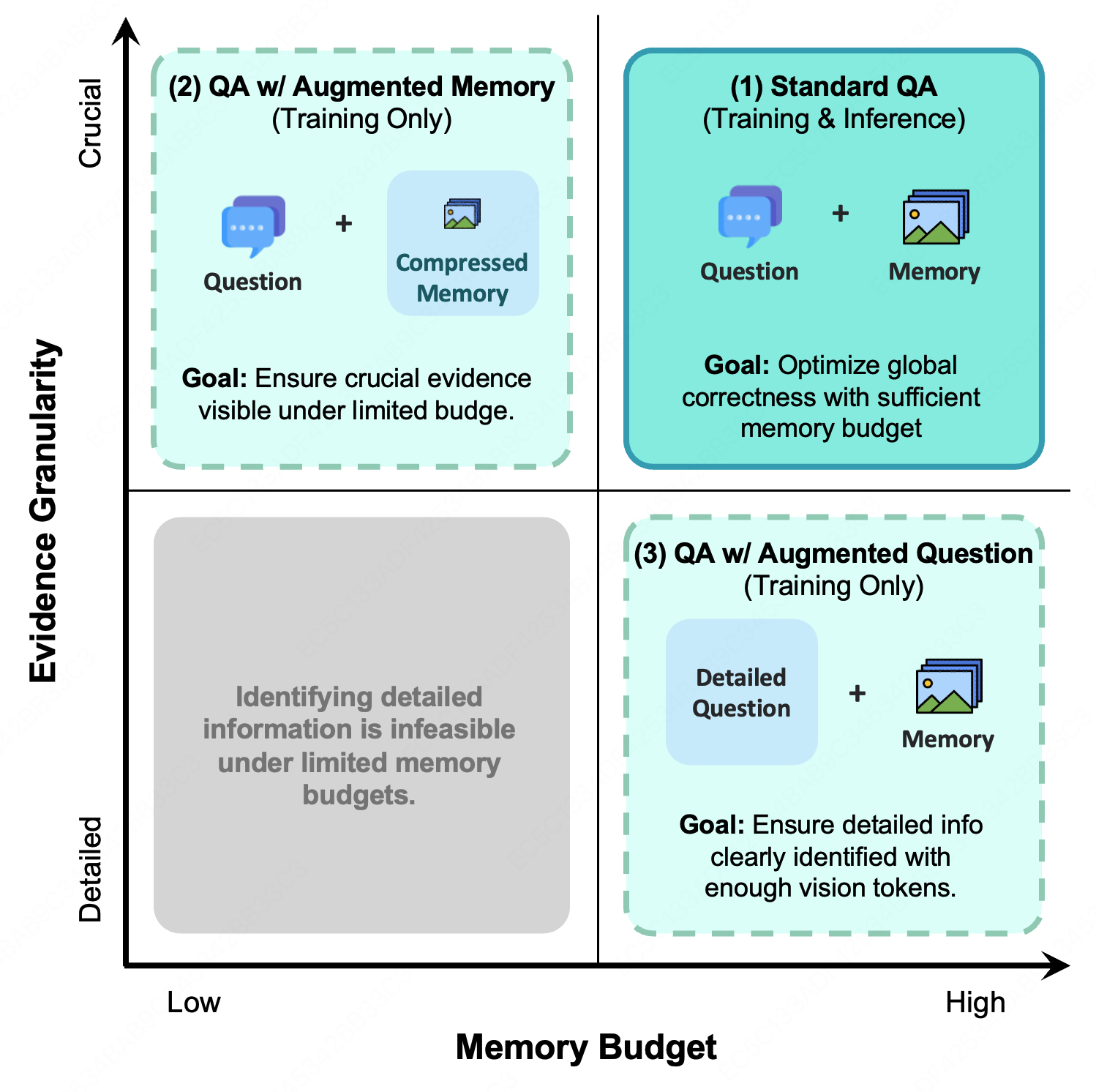
Figure 3: Budget-aware training objectives: standard QA, QA under augmented/compressed memory, and QA with detail-oriented augmented questions, guiding the agent to allocate and recover salient information across varying budget regimes.
Experimental Evaluation
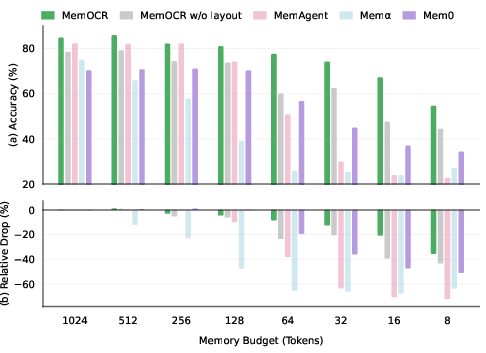
MemOCR is benchmarked on multi-hop (HotpotQA, 2Wiki) and single-hop (NQ, TriviaQA) long-context QA, targeting memory budgets B∈{16,64,256,1024} tokens and context lengths up to 100K. Against state-of-the-art textual memory systems (MemAgent, Memα, Mem0), MemOCR achieves:
Layout-Controlled Robustness and Mechanism Verification
Direct ablation (removing visual layout cues) confirms that MemOCR’s robustness arises predominantly from its explicit layout-based memory allocation rather than visual modality alone. Oracle analysis further verifies compression-resilient preferential placement: injecting ground-truth evidence in high-visibility regions yields larger accuracy gains, particularly in tight budget regimes.
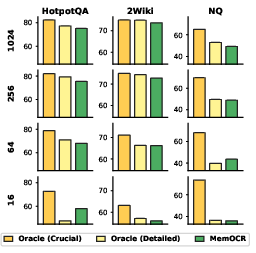
Figure 5: Oracle region analysis: precision injection of evidence in crucial regions is substantially more robust to extreme compression than detailed regions.
Reinforcement learning induces adaptive information density: agents learn to migrate ground-truth evidence into shorter, typographically prominent regions with high retrieval precision while relegating details to longer, less salient regions.
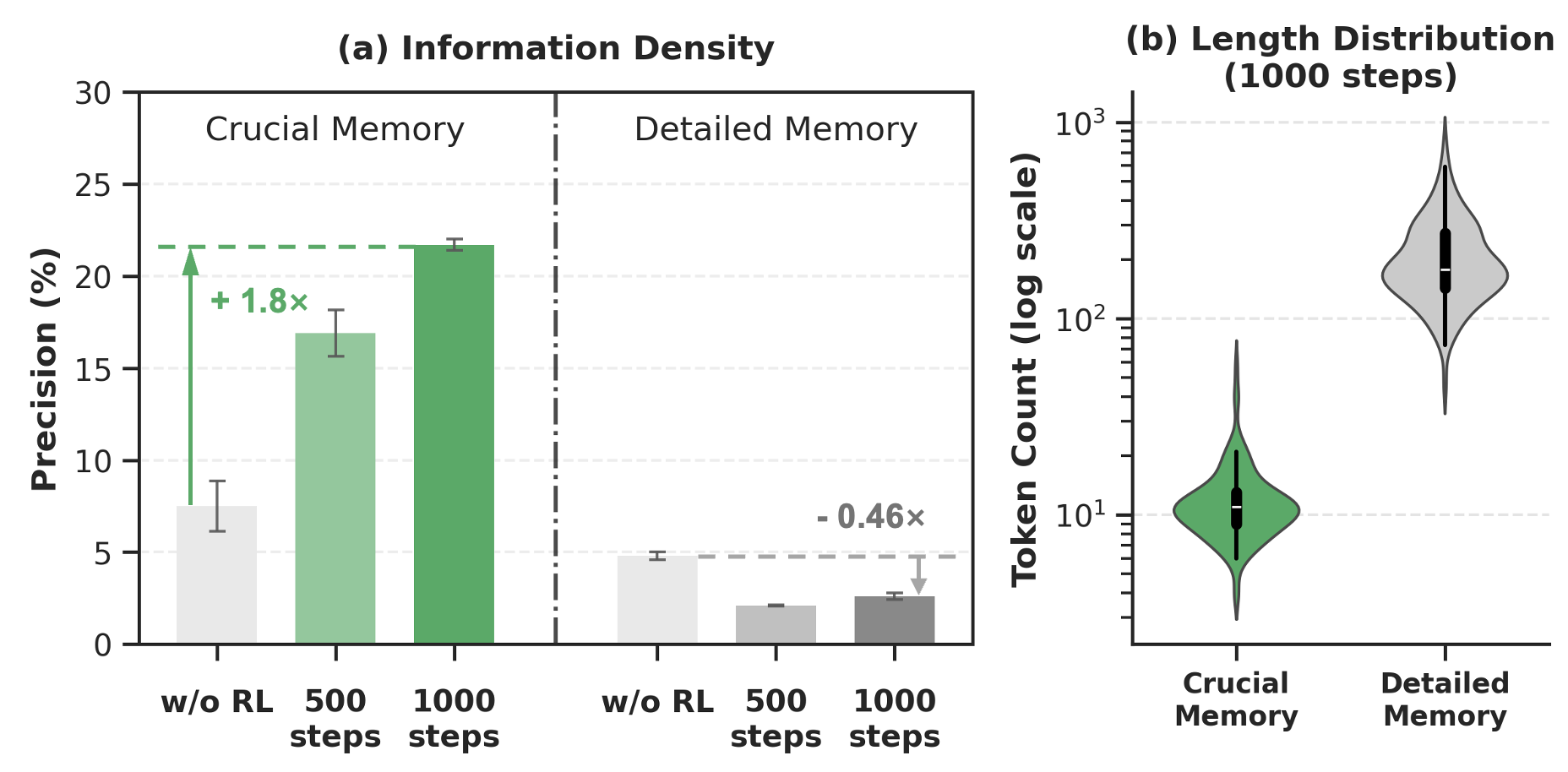
Figure 6: RL training concentrates evidence in crucial (short, prominent) regions and reduces density in detailed (long, secondary) regions.
Case and Failure Mode Analysis
MemOCR demonstrates exceptional resilience at extreme budgets—where textual baselines fail via hard truncation, and layout-free visual modalities collapse into pixel noise, MemOCR isolates and preserves critical strings for successful QA.
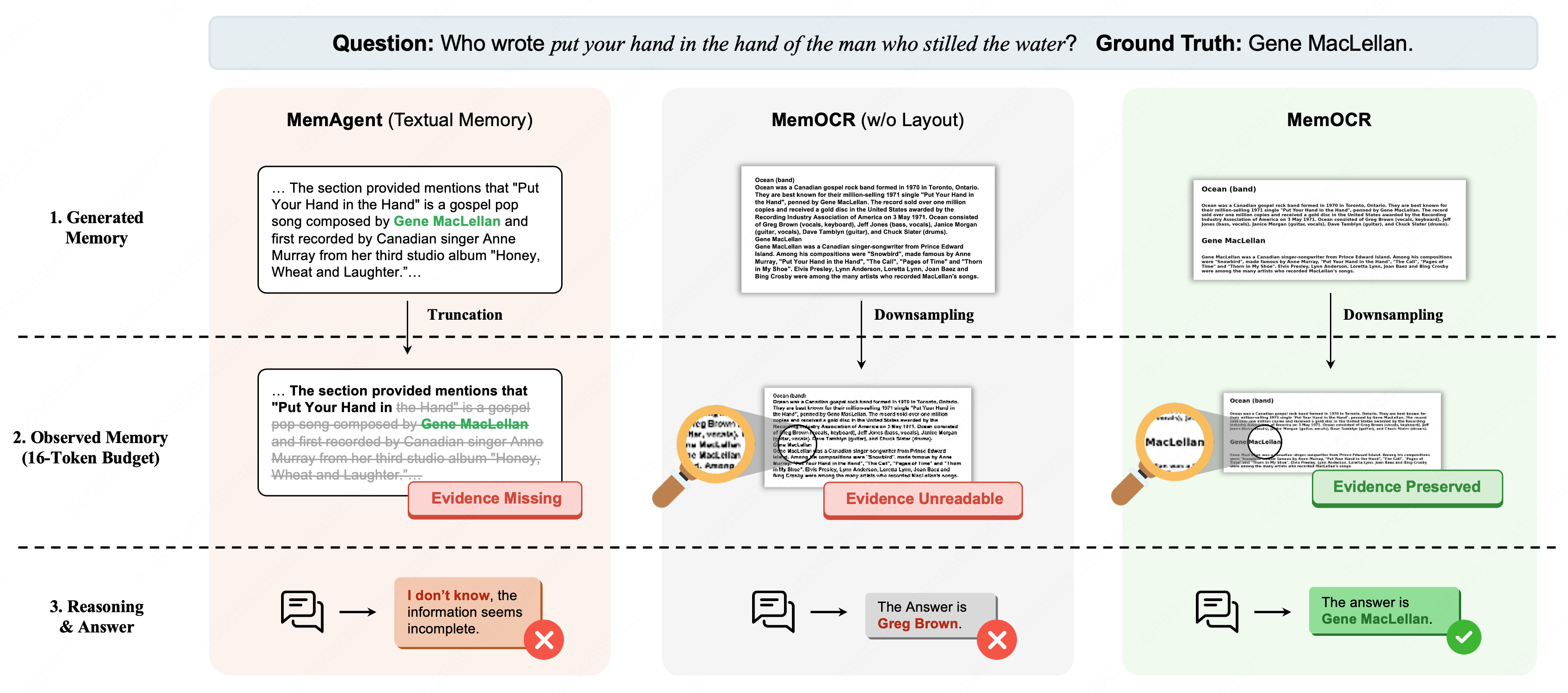
Figure 7: Case study at 16-token budget: only MemOCR’s layout-aware rendering preserves the string “Gene MacLellan” enabling correct discrimination post-compression.
Failure modes are documented: in comparative reasoning, header priority may leave attributes unreadable, and excessive memory length can trigger font scaling below encoder resolution, causing information loss.
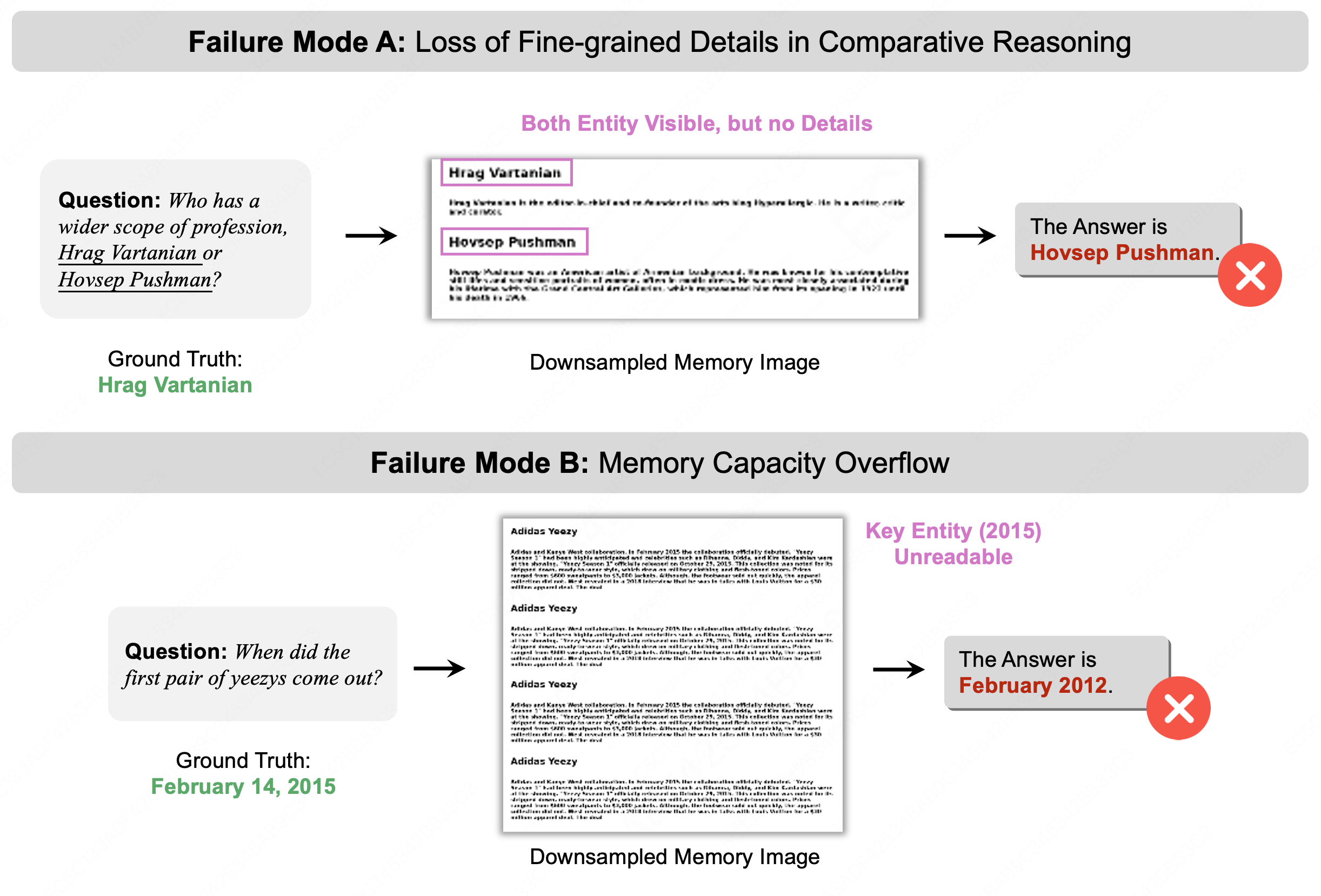
Figure 8: Failure analysis: comparative questions lose detailed attributes, and overlong memory triggers font scaling below perceptual threshold, causing total data loss.
Theoretical and Practical Implications
MemOCR’s pipeline introduces negligible computational overhead relative to text-based memory, maintaining linear scaling in context length. The architecture generalizes the spatial-aware context compression paradigm, signaling future directions for agentic memory: multimodal, resolution-adaptive memory for planning, tool integration, and lifelong learning.
On an ethical frontier, stronger long-horizon memory systems elevate privacy and robustness concerns, especially if visual representations introduce new failure possibilities in OCR or layout perception, warranting focused mitigation strategies.
Conclusion
MemOCR proposes and validates layout-aware, visual memory for agentic LLMs, demonstrating dominant efficiency and robustness in compressed long-horizon reasoning. The explicit decoupling of information density from token cost via structured layout and RL-induced prioritization sets a precedent for future multimodal memory architectures and suggests promising generalizations for persistent autonomous agents.
(2601.21468)