- The paper introduces VTC-R1, a vision-text compression technique that converts intermediate reasoning steps into images to mitigate LLM computational bottlenecks.
- It achieves a 3.4x token compression ratio with significant speedups, demonstrating accuracy improvements up to 11.1% across various benchmarks.
- By integrating rendered optical memory with vision-language models, the approach preserves fine-grained context and supports flexible, iterative reasoning.
Vision-Text Compression for Efficient Long-Context Reasoning: A Technical Overview of VTC-R1
Introduction
VTC-R1 introduces a paradigm shift in efficient long-context reasoning for LLMs by integrating vision-text compression (VTC) into the reasoning process. The principal innovation lies in representing intermediate reasoning segments as rendered images ("optical memory") and feeding these compact visual representations to vision-LLMs (VLMs) during iterative reasoning. This approach directly addresses the efficiency bottleneck of quadratic computational complexity in Transformers for long-context inference, without requiring auxiliary models or additional training stages.
Motivation and Positioning
Existing efficient reasoning techniques either require costly multi-stage training/sampling or leverage strong external models for reasoning trace compression. Both approaches introduce significant overheads and risk discarding essential fine-grained context, which is especially detrimental for mathematical and symbolic reasoning. In contrast, VTC-R1 is both model-free and lightweight: it leverages rendering pipelines to convert preceding textual segments into visual form, which are then tokenized much more efficiently by the VLM’s vision encoder. The approach generalizes prior VTC work—such as Glyph and DeepSeek-OCR—beyond text reconstruction to multi-step reasoning, which had not been systematically evaluated before.
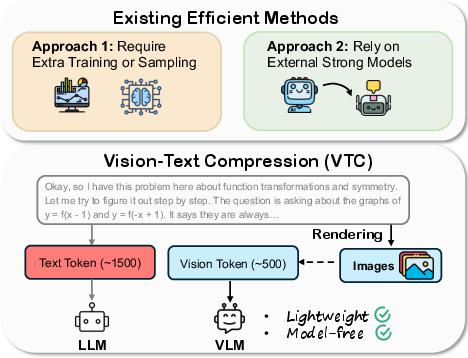
Figure 1: VTC achieves substantial token compression and efficiency relative to prior efficient reasoning techniques, via lightweight rendering of reasoning traces.
Methodology
VTC-R1 reformulates long-context reasoning as a multi-step, iterative process:
- At each iteration, the model generates a reasoning segment conditioned on the input question and a set of rendered images capturing all previous reasoning steps.
- These images are input alongside the question using a dedicated system prompt instructing the model to base further inference on past visual reasoning context.
- The overall process emulates an autoregressive chain-of-thought, but segments prior steps as optical memory, achieving efficient multimodal context accumulation.
Mathematically, for text input T rendered into image set I=Rθ(T) (with configurable layout and typographic parameters), the VLM's vision encoder processes I to produce a compact sequence V of visual tokens. Given Lt (text tokens) and Lv (vision tokens), the compression ratio is ρ=LvLt. In practice, VTC-R1 yields ρ≈3.4, representing significant reduction in memory and compute for fixed reasoning length.
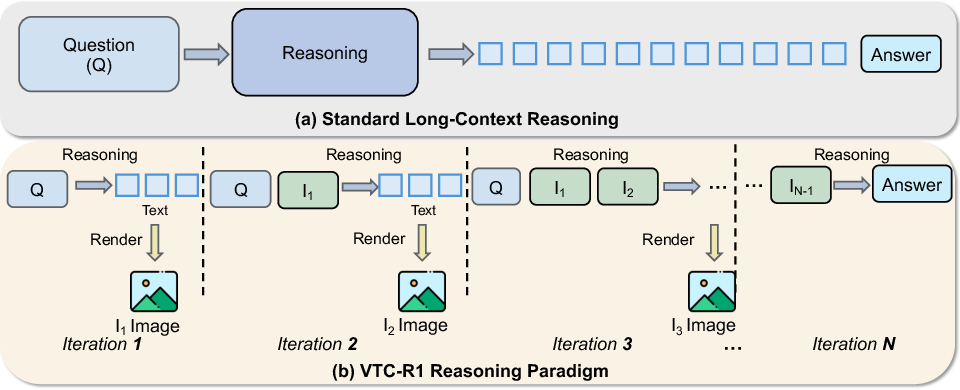
Figure 2: Comparison between standard long-sequence processing and VTC-R1's iterative, optically-compressed context accumulation.
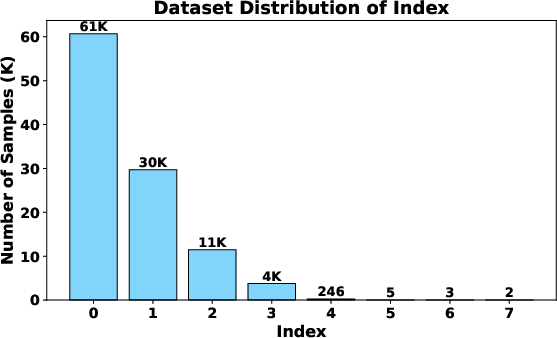
Figure 3: Most problems terminate with only a few reasoning iterations, minimizing overall multimodal token usage.
Dataset Construction and Implementation
The authors construct a large-scale supervised fine-tuning dataset for the VTC-R1 iterative paradigm, using OpenR1-Math-220K, a reasoning-verified math corpus. Reasoning traces are segmented using a fixed maximum length (default: 4K tokens per segment), and preceding segments are rendered to images per predefined rendering pipeline (detailed configuration: DejaVuSans font, 72dpi, A4 layout, etc.). The resulting dataset contains 106K image-text reasoning pairs consuming 181M original text tokens versus 54M vision tokens—a 3.4× compression.
Training employs standard vision-language architectures such as Glyph and Qwen3-VL, which natively support batched multimodal input. The data preparation pipeline ensures variable-length multi-image input to accommodate different problem complexities and reasoning depths.

Figure 4: Default rendering configuration reliably produces visually structured, information-dense images from stepwise reasoning text.
Experimental Results
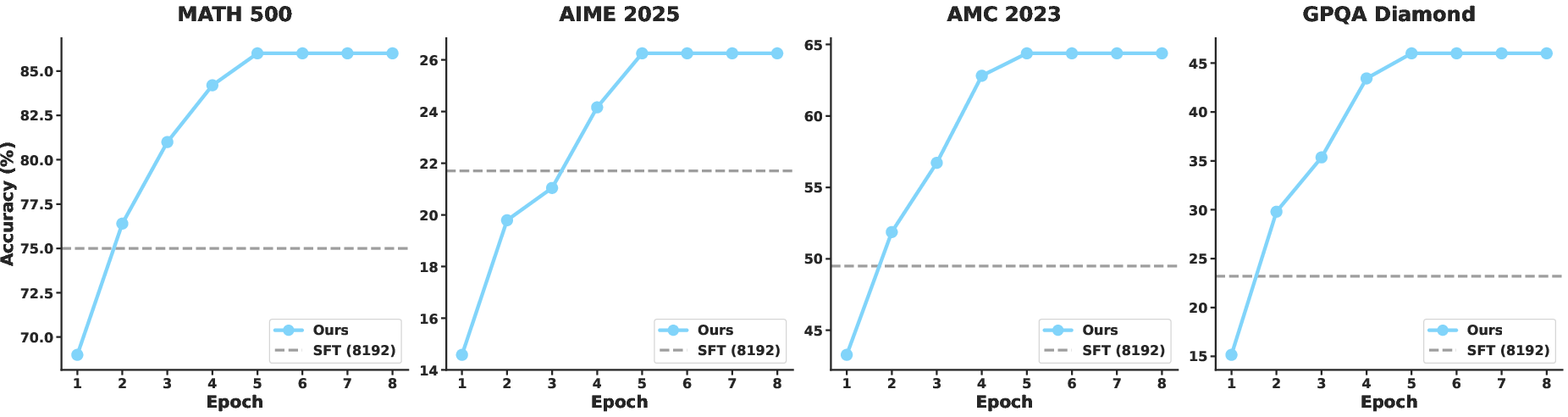
Evaluation spans mathematical reasoning datasets (GSM8K, MATH500, AIME25, AMC23) and out-of-distribution (OOD) generalization (GPQA-Diamond). Metrics include pass@1 accuracy, average token count, and end-to-end latency.
Accuracy and Efficiency
Ablation and Analysis
Removing image memory from the input at each iteration leads to a dramatic accuracy drop (up to 25% on GPQA-Diamond), quantifying the critical role of optical memory in preserving context during iterative reasoning. Experiments with segment length show $4K$ token segments deliver the best trade-off between accuracy and latency; longer segments asymptotically revert to standard long-sequence inefficiency.
Training time with VTC-R1 is nearly halved relative to full long-context SFT, as training is distributed over multiple short context windows rather than a few extended sequences. Rendering and image processing overheads are negligible (<4% of total inference time). Generated images are small enough (<0.1MB each) for real-time deployment.
Qualitative Case Studies
VTC-R1 supports nuanced multi-step behaviors: reasoning verification, solution summarization, contradiction-driven error correction, and direct continuation—all by conditioning subsequent steps on prior rendered reasoning segments. This demonstrates not only efficient compression but also high-fidelity information retention and flexible stepwise inference for complex mathematical chains-of-thought.

Figure 6: Example 1—Further verification of an intermediate solution step, leveraging prior visual context.

Figure 7: Example 2—Final answer derived by summarizing optically encoded context.

Figure 8: Example 3—Error correction performed by reflecting on contradictions in prior optical memory.

Figure 9: Example 4—Direct continuation using accumulated visual history to incrementally solve the problem.
Implications and Future Directions
The VTC-R1 framework proves that visual rendering and vision-language encoding can effectively support complex stepwise, long-context reasoning in multimodal LLMs, without the inefficiencies of long text context processing. By eliminating auxiliary compressors and retraining, VTC-R1 offers a scalable, adaptable framework, particularly beneficial for reasoning-intensive domains like mathematics, programming, and closed-book QA.
Future research directions opened by this work include:
- End-to-end optimization of rendering parameters for maximal compression while maintaining reasoning fidelity.
- Scaling VTC-R1 to multi-modal (beyond text) chain-of-thought reasoning or agent-based control tasks.
- Joint training of rendering and vision-token representations for even greater compactness and resilience to distribution shift.
- Integration with lightweight planning and reflection for adaptive iteration budgeting.
Conclusion
VTC-R1 establishes vision-text compression as a practical, theoretically principled alternative to standard long-context processing for LLM reasoning. Dense, optically compressed context delivered via iterative rendering yields strong empirical gains in both accuracy and efficiency across challenging benchmarks, generalizes well out-of-distribution, and sets a foundation for advanced scalable reasoning in vision-LLMs (2601.22069).