AstraNav-Memory: Contexts Compression for Long Memory
Abstract: Lifelong embodied navigation requires agents to accumulate, retain, and exploit spatial-semantic experience across tasks, enabling efficient exploration in novel environments and rapid goal reaching in familiar ones. While object-centric memory is interpretable, it depends on detection and reconstruction pipelines that limit robustness and scalability. We propose an image-centric memory framework that achieves long-term implicit memory via an efficient visual context compression module end-to-end coupled with a Qwen2.5-VL-based navigation policy. Built atop a ViT backbone with frozen DINOv3 features and lightweight PixelUnshuffle+Conv blocks, our visual tokenizer supports configurable compression rates; for example, under a representative 16$\times$ compression setting, each image is encoded with about 30 tokens, expanding the effective context capacity from tens to hundreds of images. Experimental results on GOAT-Bench and HM3D-OVON show that our method achieves state-of-the-art navigation performance, improving exploration in unfamiliar environments and shortening paths in familiar ones. Ablation studies further reveal that moderate compression provides the best balance between efficiency and accuracy. These findings position compressed image-centric memory as a practical and scalable interface for lifelong embodied agents, enabling them to reason over long visual histories and navigate with human-like efficiency.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (the big idea)
This paper is about teaching a robot (or a virtual agent) to move around indoors and remember what it has seen over many tasks, kind of like how you remember your house after walking around it a few times. The authors build a “long-term memory” that stores many past images the robot has seen, but in a super-efficient, compressed way. This lets the robot explore new places smarter and find things faster in places it already knows.
What questions did the researchers want to answer?
The authors focused on three simple questions:
- How can a robot remember a long history of what it’s seen (hundreds of images) without running out of computer power?
- Is it better to remember whole images (image-centric memory) instead of keeping a complicated list of detected objects (object-centric memory)?
- Can compressing visual information a lot still keep the important details needed for good navigation?
How did they do it? (Methods explained simply)
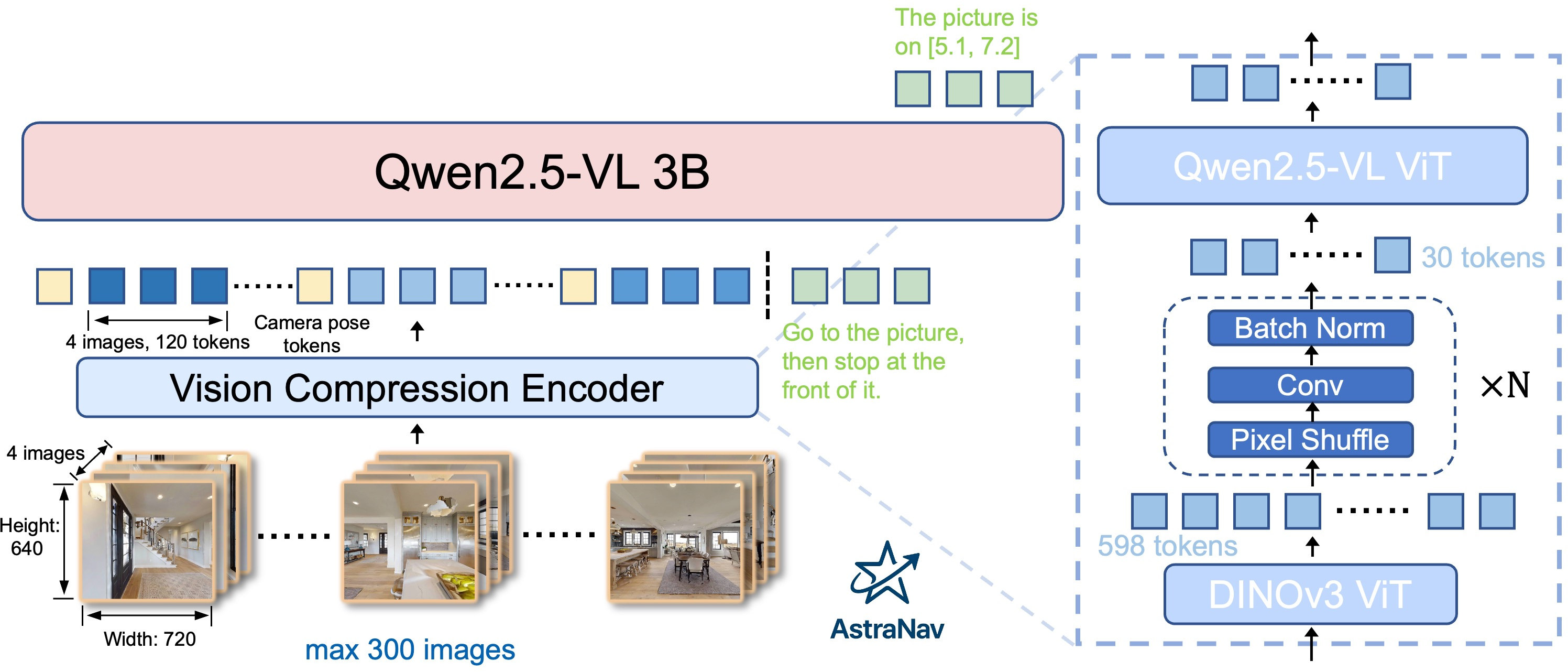
Think of the robot’s memory like a photo album. Normally, each photo is very large and takes up a lot of space, so the robot can only store a few pictures. The authors invent a way to shrink each photo into a handful of “smart stickers” that still capture important stuff like landmarks, room layout, and what objects are where.
Here’s the approach in everyday terms:
- Image-centric memory: Instead of writing down a list like “chair at (x,y), table at (x,y)” (which needs perfect object detection), the robot keeps the pictures themselves and learns to interpret them. This is simpler and less fragile.
- Tokens (tiny pieces of information): Modern vision models break an image into many small parts (like cutting a photo into tiny tiles). Each tile becomes a “token,” similar to a word in a sentence. Fewer tokens = less memory and faster thinking.
- Strong compression: The authors reduce each image from about 598 tokens to about 30 tokens (roughly 16–20× smaller). This is like turning a full-page photo into a few powerful stickers that still tell the story.
- How they compress without losing key details:
- They first use a powerful “feature extractor” called DINOv3 (think of it as a very good teacher that turns images into meaningful numbers).
- They then use a trick called PixelUnshuffle, which reorganizes nearby pixels into channels rather than throwing away details—like folding a big quilt neatly instead of cutting pieces off. Small convolution layers clean and arrange the information.
- Finally, they pass these compact tokens into a vision-LLM called Qwen2.5-VL, which reads both the images (as tokens) and the text instruction (like “go to the fridge”) to decide what to do next.
- End-to-end learning: The whole system is trained so the compression keeps exactly the kind of visual clues that help with moving and planning, not just pretty pictures.
Because of this compression, the robot can keep hundreds of past images “in mind” at once, instead of just a few. That long memory helps it reason over time, like remembering where the kitchen was seen earlier.
What did they find? (Main results and why they matter)
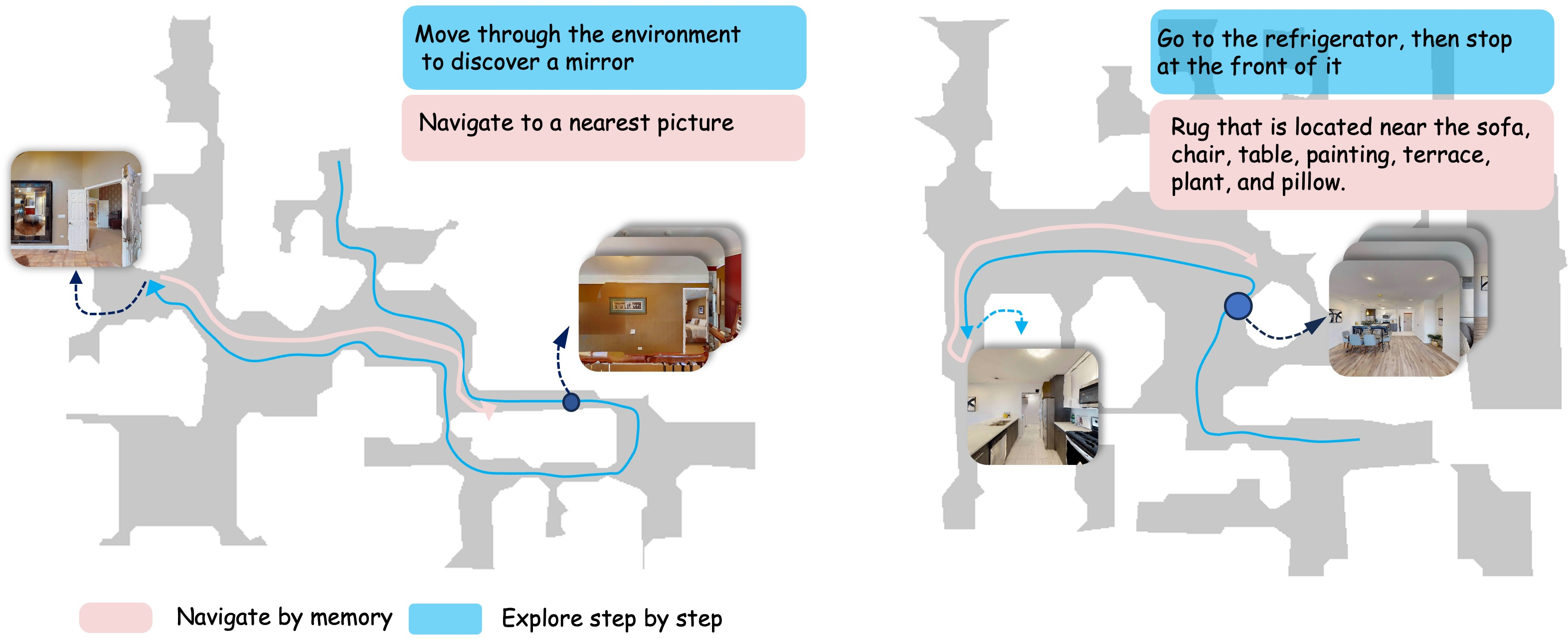
The authors tested their system on two challenging benchmarks where a robot must:
- Explore new houses it hasn’t seen before and find target objects.
- Navigate efficiently in houses it has already explored (lifelong navigation), using memory to take shorter paths next time.
Key outcomes:
- Much better navigation performance: On GOAT-Bench (a lifelong, multi-goal task), their method reached more goals and used shorter, smarter paths than previous top methods. On the toughest “unseen” split, it beat the previous best by a large margin in both success and path efficiency.
- Works in open-vocabulary settings: On HM3D-OVON (where targets can be any object name, even new ones), it also achieved state-of-the-art results, meaning it generalizes well to many object types and instructions.
- Compression sweet spot: Moderate compression (about 30 tokens per image, roughly 16×) gave the best balance. Compressing too little wastes memory; compressing too much loses details. With the chosen setting, the robot can store hundreds of images and still make good decisions.
- Faster and cheaper to run: With compression, training and inference are much faster and use less GPU memory, making the approach more practical.
Why this matters:
- Long memory is essential for “lifelong” skills. Just like you don’t forget your house layout every day, robots shouldn’t either.
- The method avoids complicated object-detection pipelines, which can break easily and don’t generalize well across different homes or lighting.
- It’s a simple, plug-in compression module that can help many robot tasks, not just navigation.
How to picture the tech (simple analogies for key parts)
- Vision Transformer (ViT): Treats an image as a sequence of tiles (tokens), like reading a comic strip panel by panel.
- DINOv3 features: A smart teacher that turns raw images into meaningful patterns, stable across different rooms and lighting.
- PixelUnshuffle: Instead of shrinking by throwing away pixels, it neatly rearranges 2×2 neighborhoods into channels—like stacking four small tiles into one thicker tile—so fewer tokens are needed, but details are preserved.
- Qwen2.5-VL: The “brain” that reads the compact image tokens and the instruction text to choose actions (move forward, turn, stop).
- Frontier exploration: When the robot doesn’t know an area yet, it explores the boundary between “known” and “unknown” regions—like walking to the edge of a lit room to peek into the darkness.
What are the limitations and what’s next?
The authors noticed that:
- The compressed memory is great at finding big, clear objects (like a fridge or a piano), but can struggle with fine textures or edges (like carpets) where boundary details matter.
- Too much compression (e.g., 64×) drops performance, because important info gets squeezed out.
Future ideas include adding boundary- or mask-level cues (like from segmentation tools) to better capture tricky textures and edges.
Why this research could be a big deal
- It moves robots closer to human-like navigation: explore once, remember well, and move efficiently next time.
- It shows that storing compressed image histories can replace complicated object maps, making systems simpler, more robust, and easier to train.
- It’s practical: faster training, less memory, and strong results in new environments make it promising for real homes, offices, or warehouses.
In short, the paper shows that cleverly compressing images into just the right kind of tokens gives robots a long, useful memory—helping them learn from experience and navigate more like we do.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of gaps the paper leaves unresolved, focused on what is missing, uncertain, or unexplored.
- Real-world deployment and sim-to-real: No validation on physical robots; robustness to camera noise, motion blur, illumination changes, and dynamic scenes (moving people/objects) is untested.
- Pose reliability and encoding: Camera poses are serialized as text tokens without uncertainty modeling; effects of noisy/inaccurate poses and alternative geometry-aware encodings (learned continuous embeddings, SE(3) features) are not evaluated.
- Scaling memory beyond “hundreds of frames”: Attention cost remains quadratic; performance and stability for thousands of frames or day-long missions is not assessed, nor are streaming/recurrent memory mechanisms integrated.
- Memory management strategy: The system accumulates frames but lacks learned forgetting, summarization, or selective retrieval policies; how to evict stale views, prioritize recency, and avoid attention overload is open.
- Content-adaptive/variable-rate compression: Compression is fixed (e.g., 4×/16×/64×); a learned token budget or scene/object-conditioned compression policy could improve retention of critical cues but is unexplored.
- End-to-end tuning of the vision stack: DINOv3 is frozen for stability, yet the trade-off between robustness and task-optimality of joint fine-tuning (backbone + compressor + policy) is not studied.
- Compression training objective: The compressor is trained via navigation supervision only; explicit losses for long-horizon consistency, retrievability (object/room-level), and spatial fidelity are not designed or ablated.
- Early-stage compression bottleneck: The paper notes DINO pre-compression tokens dominate memory; compressing earlier (at patch-embed or pixel level) or using lighter backbones to unlock longer contexts is not attempted.
- Structured retrievability and interpretability: The image-centric memory lacks queryable structure (objects, rooms, topology); how to expose interpretable memory read-outs for planning/debugging remains open.
- Hybrid memory with explicit maps: A principled combination of compressed image-centric memory with lightweight semantic/occupancy maps or object queries (for global planning) is not explored.
- Boundary- and texture-sensitive targets: Known deficits (e.g., carpets, subtle edges) suggest missing boundary/mask cues; integrating segmentation (SAM, panoptic) or edge features and quantifying gains is future work.
- Attention focus and recency bias: Findings suggest difficulty attending in very long contexts; mechanisms like learned recency weighting, keyframe selection, or hierarchical memory indexing are not evaluated.
- Alternative compression architectures: PixelUnshuffle+Conv is effective but narrow; comparisons with learned pooling, cross-attention pooling, token clustering, MoE decoders, or SSM-based compressors are missing.
- Backbone and VLM generality: Results are specific to Qwen2.5-VL-3B and DINOv3; portability to other VLMs (e.g., InternVL, LLaVA, Gemini) and 3D-aware backbones is not demonstrated.
- Evaluation breadth and metrics: Beyond SR/SPL, metrics for collision rate, path smoothness, time-to-first-discovery, memory fidelity (recall accuracy of object locations), and closed-loop stability are absent.
- Language complexity and interaction: Robustness to long, compositional, or ambiguous instructions, multi-step tasks, and interactive corrections (dialog) is not assessed.
- Environment changes and memory staleness: Handling rearrangements (objects moved/removed) and detecting/invalidating outdated memory is not studied.
- Sensor fusion: The approach is RGB-only; benefits and compression strategies for RGB-D, LiDAR, audio, or proprioceptive cues are unknown.
- Edge/embedded efficiency: Although compression reduces GPU load, the system still requires substantial compute; real-time performance on edge hardware (Jetson-class) and energy usage are unreported.
- Control interface and safety: The model outputs textual coordinates; mapping reliability to low-level controls, collision avoidance, and safety guarantees are not evaluated.
- Dataset bias and generalization: Training/evaluation are constrained to HM3D-derived data; cross-dataset generalization (Replica, Gibson, real homes) and category/domain shifts are not tested.
- Memory organization: Frames are stored as a flat sequence; graph-of-views, topological indices, or spatially anchored memory (allocentric maps) that could aid retrieval/planning are not examined.
- CLS/register token removal: The ViT is fed compressed tokens without CLS/register tokens; how these changes affect representation quality and attention dynamics across architectures is not analyzed.
- Moving-object handling: The memory assumes static semantics; detection of transient targets and temporal persistence modeling (e.g., decay, tracking) is not addressed.
- Test-time adaptation and persistence: While lifelong within-scene is supported via context, persistent memory across sessions (beyond context window) via parameter updates or external stores (TTT/Tent/Titans-like) is not explored.
Practical Applications
Immediate Applications
The following applications can be piloted or deployed with current tools and engineering effort, leveraging the paper’s compressed image-centric memory and Qwen2.5-VL–based navigation policy.
- Robotics — household and facilities navigation
- Use case: Memory-aware cleaning and delivery robots (home, office, hotel) that explore once and then take shorter paths for repeated goals (e.g., kitchen → laundry → charging dock).
- Sector: Robotics, smart home, hospitality.
- Tools/products/workflows: Visual tokenizer module integrated with existing ROS stacks; explore-first workflow followed by memory-accelerated target reaching; frontier selection and goal coordinates output via
Qwen2.5-VLpolicy; compressed-token store keyed by pose/time. - Assumptions/dependencies: Reliable pose estimation (SLAM/VIO, IMU + camera), on-device GPU/accelerator for ViT inference, safety-certified motion planner; moderate compression (4×–16×) preferred to avoid severe information loss.
- Warehouse, retail, and office service robots
- Use case: Inventory bots and runners that remember aisle layouts and frequent pick locations, reducing repeated exploration for multi-stop routes; nighttime patrols with learned optimal loops.
- Sector: Logistics, retail, security.
- Tools/products/workflows: “Memory OS” that persists compressed visual tokens across shifts; path planning from remembered coordinates; integration with SKU/object lists via language commands.
- Assumptions/dependencies: Domain finetuning for lighting and occlusions; dynamic environment handling (re-layout detection); data governance for persistent indoor imagery.
- Hospitals and campuses — indoor wayfinding assistance
- Use case: Mobile guides that build a long-term memory of wards, labs, and lecture halls; faster escort routes after first exploration; kiosk or mobile app assistants that recall common paths.
- Sector: Healthcare, education.
- Tools/products/workflows: Agent collects initial visual memory, then serves route plans via language instructions; compression enables hundreds of images in context for large buildings.
- Assumptions/dependencies: Accurate localization indoors (BLE beacons, Wi‑Fi RTT, QR markers, or visual SLAM); privacy compliance for patient areas and sensitive spaces.
- AR navigation on smartphones
- Use case: Mall/airport indoor navigation that compresses past camera frames to maintain long histories locally for low-latency guidance; explore-once then revisit-optimally experience.
- Sector: Mobile software, consumer.
- Tools/products/workflows: On-device compressed-token cache; route prompts to a lightweight policy (Qwen2.5-VL-3B or distilled variant); minimal back-end reliance for retrieval.
- Assumptions/dependencies: Stable app-side pose (ARKit/ARCore), device acceleration (GPU/NPU), careful energy management; user consent for memory persistence.
- Software — vision token compressor SDK
- Use case: Drop-in ViT-native visual tokenizer (PixelUnshuffle+Conv over frozen DINOv3) for any VLM pipeline that needs longer visual contexts with lower cost (navigation, inspection, egocentric QA).
- Sector: Software, developer tools.
- Tools/products/workflows: SDK that outputs ~30 tokens/frame under 16× compression; configurable rates; direct compatibility with Qwen2.5-VL ViT first block; unit tests on GOAT/HM3D subsets.
- Assumptions/dependencies: Task-aligned training or validation to avoid perception-only compression goals; moderate compression for best trade-offs.
- Edge AI optimization for embodied agents
- Use case: Running long-horizon visual histories on Jetson-or-similar edge devices by slashing token counts and memory footprint (observed 2–4× speedups in training/inference in experiments).
- Sector: Energy-efficient computing, robotics.
- Tools/products/workflows: Token compression before LLM attention; on-device memory management with TTL and update policies; streaming integration.
- Assumptions/dependencies: Hardware acceleration (CUDA/TensorRT/OpenVINO); careful scheduling to prevent attention blow-up at very long contexts; compression sweet spots (4×–16×).
- Security and inspection rounds
- Use case: Patrol bots that recall vantage points and anomalies found in previous passes; faster revisits to locations of interest without full rescans.
- Sector: Security, facility management.
- Tools/products/workflows: Anomaly tags in language; coordinate outputs for revisit paths; secured memory stores with access control and audit logs.
- Assumptions/dependencies: Tamper-proof logging; changing lighting and clutter handled via robust DINOv3 features; compliance with surveillance norms.
- Research and education
- Use case: Reproducible pipeline for long-context embodied navigation courses and labs; SOTA baseline on GOAT-Bench and HM3D-OVON; ablation-ready tokenizer.
- Sector: Academia.
- Tools/products/workflows: Teaching kits that include the compressor, policy, datasets (GOAT-1M-*); assignments on compression rate vs. accuracy; habitat/simulator integration.
- Assumptions/dependencies: Simulator-to-real transfer studies; category-level failure modes (carpets, boundaries) openly analyzed and extended with segmentation cues.
Long-Term Applications
The following applications require further research, scaling, and engineering (e.g., robust pose under extreme dynamics, boundary-aware perception, policy safety, multi-agent memory sharing, and regulatory alignment).
- General-purpose household robots with lifelong “home memory”
- Use case: Agents that continuously learn a residence layout, remember object zones (bookshelves, fridge), and optimize multi-goal routines (cleaning, tidying, fetching).
- Sector: Consumer robotics.
- Tools/products/workflows: Unified memory interface for perception–language–control; boundary-aware upgrades (e.g., integrating SAM/segmentation for carpets and edges); adaptive compression based on task criticality.
- Assumptions/dependencies: Continual learning stability (catastrophic forgetting mitigation); robust change detection for reconfiguration; family privacy controls.
- Collaborative multi-robot memory sharing
- Use case: Fleets that share compressed visual tokens across robots and shifts to accelerate collective navigation and tasks (inventory, maintenance).
- Sector: Logistics, manufacturing.
- Tools/products/workflows: Distributed memory banks with pose/time indices; conflict resolution for layout changes; federated updates.
- Assumptions/dependencies: Network reliability; consistent pose frames across robots; security of shared data; versioning of environment memory.
- Safety-certified navigation in dynamic public spaces
- Use case: Robots in hospitals, airports, and malls that maintain long memory while handling crowds, occlusions, and frequent rearrangements.
- Sector: Healthcare, transportation, retail.
- Tools/products/workflows: Predictive memory updates; human-aware planners; compliance tooling for safety audits and incident logs.
- Assumptions/dependencies: Stronger domain robustness (lighting, seasonal decor); human–robot interaction policies; fail-safes under memory drift.
- Accessible wayfinding for visually impaired users
- Use case: Wearables or mobility aids that build persistent memory of frequently visited indoor spaces (clinic, workplace) for faster, safer guidance.
- Sector: Accessibility, healthcare.
- Tools/products/workflows: Voice-driven instruction parsing; personal memory vault with user-controlled retention; boundary-sensitive enhancements for floors/obstacles.
- Assumptions/dependencies: Accurate real-time localization; privacy and data rights for assistive devices; defense against memory errors.
- Industrial inspection and digital twins
- Use case: Robots that update plant/facility digital twins by recalling previously scanned areas and focusing on changes; reduced cost for routine inspections.
- Sector: Energy, manufacturing.
- Tools/products/workflows: Change-detection overlays on compressed memory; scheduling of revisit paths; integration into BIM/CAD twins.
- Assumptions/dependencies: High-fidelity mapping alignment; safety zones and compliance; retraining for texture/edge-heavy plant environments.
- Long-video and egocentric analytics with token-efficient VLMs
- Use case: Meeting capture, operations monitoring, and sports analysis where agents need to reason over hundreds/thousands of frames with minimal latency.
- Sector: Enterprise software, media.
- Tools/products/workflows: Task-aligned compression for non-navigation semantics (procedures, participants, events); retrieval and summarization APIs over compressed contexts.
- Assumptions/dependencies: New objectives beyond navigation; careful evaluation of semantic loss under compression; domain pretraining.
- Standardization and policy for persistent embodied memory
- Use case: Governance frameworks for how robots store, retrieve, and share long-horizon indoor visual histories (retention, anonymization, auditability).
- Sector: Policy and regulation.
- Tools/products/workflows: Memory lifecycle standards (TTL, redaction); security baselines for token stores; compliance attestation across sectors.
- Assumptions/dependencies: Multi-stakeholder input (facilities, privacy advocates, vendors); harmonization with regional regulations (HIPAA/GDPR equivalents).
- Lifelong navigation benchmarks and evaluation protocols
- Use case: Community benchmarks that stress-test end-to-end memory (closed-loop consistency, attention noise, retrievability of entities/locations) beyond episodic tasks.
- Sector: Academia, open-source.
- Tools/products/workflows: Expanded GOAT-like suites with dynamic changes, multi-goal sequences, and cross-domain shifts; standardized reporting for SR/SPL under memory length and compression.
- Assumptions/dependencies: Cross-lab reproducibility; real-to-sim transfer kits; shared datasets with controlled privacy.
Notes on feasibility across applications:
- Compression sweet spot: 4×–16× tends to balance efficiency and accuracy; 64× risks severe semantic loss.
- Pose quality is a central dependency; when pose is poor, memory-keyed retrieval and planning degrade.
- Boundary- and texture-sensitive categories remain challenging; integrating segmentation/mask cues (e.g., SAM) is recommended for robust performance.
- Compute and energy budgets improve with compression, enabling more on-device use, but safety-critical deployments still require certified planners and fail-safe control.
Glossary
- 3D occupancy map: A grid-based representation marking explored versus unknown space in an environment. "we maintain a 3D occupancy map that classifies each region as either "explored" or "unknown"."
- 6-DOF (Degrees of Freedom): A pose representation with 3D position and 3D orientation components. "defined by its 6-DOF (Degrees of Freedom) pose."
- Ablation study: An experimental analysis that isolates the impact of components or settings by removing or varying them. "Ablation studies further reveal that moderate compression provides the best balance between efficiency and accuracy."
- Attention mechanism: The component in transformers that computes pairwise token interactions; its cost and noise grow with sequence length. "attention mechanisms can be overwhelmed by noise and distractions, making it hard to focus on key information"
- BatchNorm: A normalization layer that stabilizes and accelerates training by standardizing activations. "followed by BatchNorm and SiLU."
- Convolution (Conv): A learnable filter operation over spatial features, often parameterized by kernel size and stride. "the tensor passes through a stride 1, convolution followed by BatchNorm and SiLU."
- Context-window scaling: Techniques to extend the number of tokens a model can process effectively. "Influential directions include context-window scaling (e.g., YaRN, LongRoPE2) and streaming/recurrent attention (e.g., StreamingLLM, Infini-Attention, RMT)"
- DeepSeek-OCR: An OCR system showcasing extreme visual token compression with efficiency techniques like MoE and windowed attention. "DeepSeek-OCR demonstrates industrial-grade efficiency: by leveraging windowed attention, highly compressed convolutional features, and Mixture-of-Experts (MoE) decoding"
- DINOv3: A self-supervised Vision Transformer backbone providing robust mid-level spatial semantics. "DINOv3 is chosen for its strong self-supervised semantics, robustness to domain shifts, and ability to capture mid-level spatial cues without task labels."
- Embodied AI: AI that perceives and acts within simulated or real environments via a physical or virtual agent. "Long-term memory has been extensively explored in LLMs/VLMs and embodied AI"
- Embodied navigation: Agent navigation in 3D environments using visual inputs and actions. "With the recent progress in embodied navigation, the research focus has been shifting towards more complex multi-task navigation settings"
- End-to-end: Training and inference that integrate all components in a single differentiable pipeline. "end-to-end coupled with a Qwen2.5-VL–based navigation policy."
- Flamingo: A multimodal model enabling vision-language conditioning over long contexts. "extended to multimodal settings by Flamingo, LongVILA, LongVLM, LLaMA-VID, and Long-Context SSM Video World Models"
- Frontier-based exploration: A strategy that navigates to boundaries between explored and unknown areas to expand coverage efficiently. "it uses frontier-based exploration to locate the target."
- GOAT-Bench: A benchmark for lifelong, multi-goal navigation in persistent environments. "Experimental results on GOAT-Bench and HM3D-OVON show that our method achieves state-of-the-art navigation performance"
- GraphRAG: A retrieval-augmented approach that structures knowledge as graphs for improved long-context retrieval. "long-document and structured variants such as LongRAG, RAPTOR, GraphRAG, and OS-style MemGPT"
- Habitat-Sim: A high-performance 3D simulator for embodied AI tasks. "Visualization of GOAT-Benchmark in Habitat-Sim"
- HM3D-OVON: An object-goal navigation benchmark with open-vocabulary targets in HM3D environments. "Object-goal navigation results on HM3D-OVON."
- Image-centric memory: A memory design that stores and reasons directly over sequences of images and poses rather than explicit maps. "We propose an image-centric memory framework"
- Implicit memory: Memory integrated within token sequences or parameters without explicit external indices. "achieves long-term implicit memory via an efficient visual context compression module"
- Infini-Attention: A variant of attention designed for streaming or infinite-length sequences. "streaming/recurrent attention (e.g., StreamingLLM, Infini-Attention, RMT)"
- kNN-LM: A language modeling approach that augments predictions by retrieving nearest neighbors from a datastore. "Foundational systems include RAG, REALM, kNN-LM, and RETRO"
- LLaMA-VID: A video-capable multimodal extension of LLaMA for long-context vision-language processing. "extended to multimodal settings by Flamingo, LongVILA, LongVLM, LLaMA-VID, and Long-Context SSM Video World Models"
- Long-Context SSM Video World Models: Sequence state-space models tailored for long-horizon video reasoning. "extended to multimodal settings by Flamingo, LongVILA, LongVLM, LLaMA-VID, and Long-Context SSM Video World Models"
- LongRAG: A retrieval-augmented method optimized for long documents or contexts. "long-document and structured variants such as LongRAG, RAPTOR, GraphRAG, and OS-style MemGPT"
- LongRoPE2: A rotary positional embedding variant for longer context handling. "context-window scaling (e.g., YaRN, LongRoPE2)"
- LongVILA: A long-context vision-LLM supporting extended token sequences. "extended to multimodal settings by Flamingo, LongVILA, LongVLM, LLaMA-VID, and Long-Context SSM Video World Models"
- LongVLM: A long-context vision-LLM enabling extended visual token processing. "extended to multimodal settings by Flamingo, LongVILA, LongVLM, LLaMA-VID, and Long-Context SSM Video World Models"
- MemGPT: An operating-system-style memory manager for LLMs that organizes and persists context. "long-document and structured variants such as LongRAG, RAPTOR, GraphRAG, and OS-style MemGPT"
- Mixture-of-Experts (MoE): An architecture that routes tokens to specialized expert modules for efficiency or specialization. "Mixture-of-Experts (MoE) decoding"
- Multimodal projector: The module that aligns vision features to the LLM’s embedding space. "projected through the multimodal projector, and finally fed into the LM."
- Object-centric memory: A memory approach that stores explicit object maps, coordinates, and categories. "Object-centric memory can be explicit or implicit"
- Open-vocabulary object navigation (OVON): Navigating to targets specified by unconstrained category names. "Open-vocabulary object navigation data (OVON)."
- Patch-merger: A token-reduction operation that aggregates neighboring patch tokens (e.g., 2×2) within ViTs. "built-in 2×2 patch-merger"
- PixelUnshuffle: A rearrangement operation moving local spatial neighborhoods into channels to reduce spatial resolution without pooling. "PixelUnshuffle moves each local neighborhood into channels"
- Positional encodings (2D): Learned or fixed embeddings that inject spatial location information into tokens. "On the downsampled grid, we add 2D positional encodings."
- Qwen2.5-VL-3B: A 3-billion-parameter vision-LLM used as the navigation backbone. "Qwen2.5-VL-3B ViT"
- Quaternion: A four-parameter rotation representation used for 3D orientation. "an orientation represented as a quaternion "
- RAG (Retrieval-Augmented Generation): An approach that augments generation with retrieved external knowledge. "Foundational systems include RAG, REALM, kNN-LM, and RETRO"
- REALM: A retriever-backed LLM integrating latent knowledge retrieval into training and inference. "Foundational systems include RAG, REALM, kNN-LM, and RETRO"
- RETRO: A retrieval-augmented transformer that conditions on nearest neighbor chunks from a large corpus. "Foundational systems include RAG, REALM, kNN-LM, and RETRO"
- RMT: A recurrent memory transformer enabling long-horizon sequence processing via internal memory. "streaming/recurrent attention (e.g., StreamingLLM, Infini-Attention, RMT)"
- SAM (Segment Anything Model): A general-purpose segmentation model that can provide boundary/mask cues. "by integrating features from segmentation models such as SAM into the compressed visual representation."
- Self-supervised semantics: Representations learned without labels that capture semantic structure. "DINOv3 is chosen for its strong self-supervised semantics"
- SiLU: The Sigmoid Linear Unit activation function used in modern vision backbones. "followed by BatchNorm and SiLU."
- SPL (Success weighted by Path Length): A navigation metric combining success and path efficiency. "We evaluate models using Success Rate (SR) and Success weighted by Path Length (SPL)."
- SR (Success Rate): The percentage of navigation episodes that reach within a distance threshold of the target. "We evaluate models using Success Rate (SR) and Success weighted by Path Length (SPL)."
- StreamingLLM: A technique for processing continuous streams by maintaining rolling context or recurrent states. "streaming/recurrent attention (e.g., StreamingLLM, Infini-Attention, RMT)"
- Token compression: Reducing the number of visual tokens to extend context length and lower computation. "various token compression and structured pooling schemes have emerged"
- Token pruning and sparsification: Methods that remove or down-weight low-information tokens to reduce load. "Pruning and sparsification. TokenCarve, SparseVLM, and FocusLLaVA remove or down-weight low-information tokens"
- Visual tokenizer: A module that converts images into compact token sequences for a VLM. "our visual tokenizer supports configurable compression rates"
- Vision Transformer (ViT): A transformer architecture operating on image patches as tokens. "Built atop a ViT backbone with frozen DINOv3 features and lightweight PixelUnshuffle+Conv blocks"
- VisionPatchEmbed: The patch embedding layer that turns image pixels into patch tokens for ViTs. "Vanilla Qwen2.5-VL uses VisionPatchEmbed (patch=14)"
- Vision-LLMs (VLMs): Models that jointly process and reason over visual and textual inputs. "Long-term memory has been extensively explored in LLMs/VLMs and embodied AI"
- Windowed attention: An attention variant limiting interactions to local windows to improve efficiency. "by leveraging windowed attention, highly compressed convolutional features, and Mixture-of-Experts (MoE) decoding"
Collections
Sign up for free to add this paper to one or more collections.

