- The paper introduces a novel multimodal memory graph that structures reasoning as a dynamic directed acyclic graph to manage visually dense contexts.
- It employs graph-modulated visual memory encoding to allocate tokens adaptively, effectively pruning irrelevant evidences and preserving critical information.
- Graph-guided policy optimization refines reinforcement learning credit assignment, leading to significant accuracy improvements and reduced inference latency.
VimRAG: Advancing Multimodal Retrieval-Augmented Generation via Multimodal Memory Graphs
Introduction
The proliferation of Multimodal LLMs (MLLMs) has intensified the demand for agentic frameworks capable of effectively handling massive, token-heavy visual contexts in Retrieval-Augmented Generation (RAG) scenarios. However, canonical linear RAG paradigms—characterized by flat histories or sequential summaries—are fundamentally limited when scaling to long-horizon, iterative reasoning tasks involving information-sparse but visually dense data such as images and long videos. This paper presents VimRAG, a novel framework employing a dynamic, directed acyclic multimodal memory graph aligned with human-like reasoning topologies to address these core bottlenecks. VimRAG further introduces adaptive, graph-modulated visual memory encoding and graph-guided policy optimization, collectively enabling explicit state tracking, resource-efficient context management, and fine-grained reinforcement learning credit assignment.
System Overview
VimRAG's system architecture is defined by three pivotal innovations:
- Multimodal Memory Graph: The agent's reasoning process is structured as a dynamic DAG, where each node encapsulates a distinct epistemic state, including agent action, sub-query context, textual summary, and dynamically compressed multimodal observations. This topological organization enables the explicit modeling of temporal and logical dependencies, supporting robust tracking of both exploratory and finalized reasoning paths.
- Graph-Modulated Visual Memory Encoding: Memory encoding integrates temporal, topological, and semantic factors to adaptively allocate token budgets to visual evidence based on node centrality and recursive “energy.” This mimics biological forgetting, pruning irrelevant context and maximizing attention to evidence critical for downstream inference.
- Graph-Guided Policy Optimization (GGPO): Reinforcement learning is enhanced by leveraging the reasoning graph for trajectory segmentation and credit assignment. By masking dead-end explorations in successful runs and exempting valid retrievals in failures from negative gradients, GGPO addresses the credit misalignment endemic to traditional trajectory-level RL rewards, enabling sample-efficient optimization.
The cyclic inference loop—depicting successive cycles of reasoning, evidence retrieval, and memory evolution—is visualized in (Figure 1).
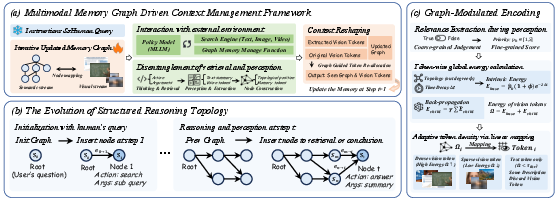
Figure 1: Inference pipeline of VimRAG illustrating the cyclic reasoning/retrieval/memory evolution loop, structured memory graph evolution, and stepwise graph-modulated memory encoding.
Methodology
Structured Reasoning Topology
VimRAG formalizes agentic reasoning as DAG evolution, with action, observation, and memory states encoded per node. The model’s policy interacts with the environment over reasoning steps, performing one of three action types: retrieval (expanding the graph), multimodal perception and memory population (distilling evidence with fine-grained filters), or terminal answer generation. Temporal grounding components extract semantically relevant frames or image regions, maintaining crucial context in visually intensive tasks.
Dynamic Visual Memory Shaping
Key to computational efficiency and effective evidence selection, the memory encoding mechanism allocates vision tokens via an energy-based function that synthesizes semantic saliency, node out-degree (as a proxy for information flow), and temporal recency, augmented with topological feedback to preserve the relevance of early but necessary context. The resulting token allocation is inherently uneven, enabling the agent to avoid context overflow while retaining critical evidence.
Graph-Guided Policy Optimization
To circumvent the policy gradient noise induced by trajectory-level reward sparsity, each agent trajectory is segmented into atomic reasoning cycles corresponding to memory graph nodes. Credit assignment is refined via two mechanisms:
- Pruning false positives (removal of dead-ended nodes from positive samples)
- Pruning false negatives (exempting valid information-retrieval nodes in unsuccessful trajectories based on external evidence alignment)
Gradient updates thus target only valid, constructive states, as represented in (Figure 2).
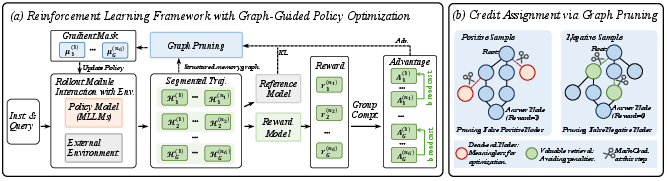
Figure 2: GGPO framework for agentic memory training, showing trajectory segmentation and structural credit assignment via graph pruning and gradient masking.
Experimental Results
Benchmarks and Evaluation
VimRAG's empirical evaluation covers a broad spectrum of general text, image-rich, visually-structured document, and extreme-long video QA benchmarks. The model demonstrates consistently superior performance relative to established RAG and memory-based agentic baselines, including ReAct, VideoRAG, UniversalRAG, MemAgent, and Mem1. On Qwen3-VL-8B-Instruct, VimRAG achieves a notable accuracy improvement (43.6% → 50.1%), with the greatest absolute gains observed in video-corpus and cross-modal retrieval settings. These gains empirically validate the merits of topological trajectory modeling and dynamic evidence preservation.
Ablation studies further dissect contributions from graph-based memory, dynamic token allocation, and GGPO, sequentially affirming that each module confers marked improvements in accuracy and training efficiency.
Robustness, Efficiency, and Latency Analysis
Retrieval robustness—measured as modality-aware hit rates—is significantly enhanced by structured memory. VimRAG’s state tracking obviates the redundancy and inefficiency imparted by linear memory, as supported by the steeper entropy reduction and faster training convergence in (Figure 3b). The breakdown of inference steps (Figure 3c) demonstrates reductions in unnecessary search cycles and re-reading.
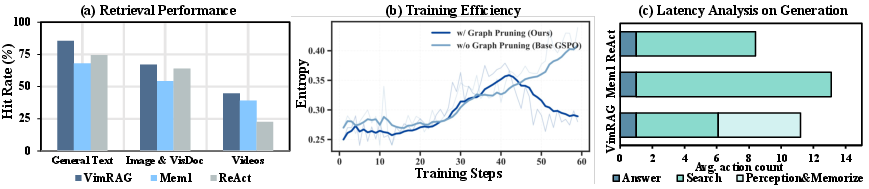
Figure 3: (a) Retrieval hit rate comparison across modalities; (b) Training entropy—VimRAG demonstrates accelerated convergence; (c) Inference step distribution, reflecting VimRAG's reduced redundancy and latency.
Dataset Construction and Case Studies
VimRAG’s capabilities are further underscored by the bespoke construction of XVBench—benchmarks for cross-video, long-horizon multimodal reasoning—using a pipeline designed to sample and annotate fine-grained queries over complex video segments (Figure 4).
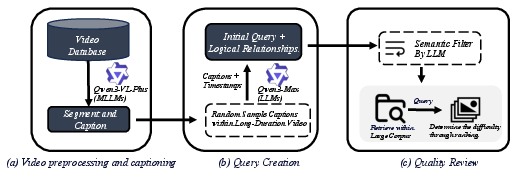
Figure 4: Data construction pipeline for XVBench, illustrating staged video segmentation, multimodal captioning, and query synthesis.
Detailed case studies reveal the system’s ability to dynamically expand, prune, and traverse reasoning graphs while expertly filtering critical evidence and discarding misleading context. The qualitative analysis in Figures 5 and 6 further substantiates VimRAG’s capacity for self-correction and human-like backtracking.

Figure 5: Initialization of the Multimodal Memory Graph in a calculus lecture use case.

Figure 6: Final answer synthesis by traversing the critical memory graph path in a complex query scenario.
Implications and Future Directions
The theoretical impact of VimRAG centers on explicit state/trajetory awareness, decoupling context representation from the inherent shortcomings of sequence-based compression and attentional degradation. Structuring agentic memory as a semantic-topological object enables robust credit assignment, sparse evidence targeting, and interpretability at the level of both intermediate reasoning and final answer synthesis.
Practically, VimRAG’s advances in token efficiency and inference latency signal enhanced deployability for resource-constrained environments, supporting trustworthy, high-recall multimodal AI agents. The approach also lays the groundwork for hierarchical or self-evolving agentic memory structures, potentially catalyzing new research into scalable, multi-agent systems capable of distributed, cross-modal collaborative reasoning.
Future work may extend toward unified, cross-task multi-modal RL pretraining regimes, continual memory evolution, and integration with next-generation large multimodal foundation models.
Conclusion
VimRAG establishes a new standard for multimodal RAG by leveraging structured memory graphs, adaptive token allocation, and graph-based policy optimization to resolve critical inefficiencies present in prior architectures. The results unequivocally demonstrate that explicit reasoning topology modeling and dynamic context management are central to scaling large agentic systems to increasingly complex, visually dense tasks.