EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning
Abstract: LLMs are increasingly deployed as long-term interactive agents, yet their limited context windows make it difficult to sustain coherent behavior over extended interactions. Existing memory systems often store isolated records and retrieve fragments, limiting their ability to consolidate evolving user states and resolve conflicts. We introduce EverMemOS, a self-organizing memory operating system that implements an engram-inspired lifecycle for computational memory. Episodic Trace Formation converts dialogue streams into MemCells that capture episodic traces, atomic facts, and time-bounded Foresight signals. Semantic Consolidation organizes MemCells into thematic MemScenes, distilling stable semantic structures and updating user profiles. Reconstructive Recollection performs MemScene-guided agentic retrieval to compose the necessary and sufficient context for downstream reasoning. Experiments on LoCoMo and LongMemEval show that EverMemOS achieves state-of-the-art performance on memory-augmented reasoning tasks. We further report a profile study on PersonaMem v2 and qualitative case studies illustrating chat-oriented capabilities such as user profiling and Foresight. Code is available at https://github.com/EverMind-AI/EverMemOS.
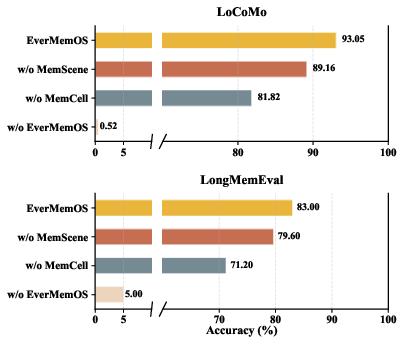
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
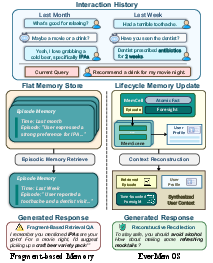
This paper introduces EverMemOS, a “memory operating system” that helps AI chatbots remember and use past conversations better over long periods of time. Instead of just storing scattered notes from chats, it organizes memories into meaningful stories and themes, so the AI can behave more consistently, keep track of user preferences, and avoid mistakes (like recommending alcohol when a user recently said they’re on antibiotics).
Key Questions
The paper asks:
- How can an AI keep a clear, up-to-date understanding of a user over many conversations?
- How can it turn messy chat logs into organized knowledge that’s easy to use later?
- How can it pull just the right pieces of memory for a new question—no more, no less?
How It Works (Methods)
Think of EverMemOS like a smart notebook that:
- writes short, clean summaries of what happened,
- files them into the right folders,
- and pulls out only the pages you need when you ask a question.
The three phases
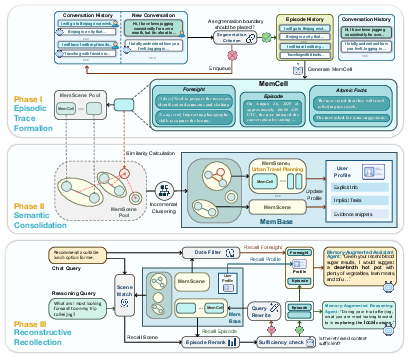
- Episodic Trace Formation: The system turns a chunk of dialogue into a short “episode” (like a journal entry), plus key facts and time-limited notes about plans or temporary states (like “on antibiotics for 10 days”).
- Semantic Consolidation: It groups related episodes into “scenes” (like putting all food-related episodes in a Food folder) and updates a compact user profile (stable preferences, routines, constraints).
- Reconstructive Recollection: When a new question comes in, it finds the most relevant scenes and episodes, filters out expired info (like a plan that’s already over), and assembles a small, focused set of memories that are necessary and sufficient to answer well.
Important building blocks
To make this work, EverMemOS uses structured memory units called MemCells—think of each MemCell as a well-organized index card:
- Episode: a short, third-person summary of what happened (“Alex said they prefer IPA beers”).
- Atomic Facts: tiny, checkable facts pulled from the episode (“User prefers IPA”).
- Foresight: future-looking notes with time windows (“On antibiotics from May 2–May 12; avoid alcohol during this period”).
- Metadata: when it happened and where it came from.
MemCells are then grouped into MemScenes—like folders or photo albums—so the AI sees the bigger picture (themes, repeated patterns, stable preferences).
Finding the right memories when needed
Instead of dumping everything into the AI’s context, EverMemOS follows a “necessary and sufficient” rule: include just enough evidence to answer the question correctly, and nothing extra that could distract it. Imagine packing for a trip: you bring only what you need for the weather and activities, not your entire closet.
Main Findings
The authors tested EverMemOS on two tough benchmarks designed to check whether an AI can remember and reason over very long conversations:
- LoCoMo: questions that sometimes require following timelines or combining clues from different parts of the chat (“multi-hop” and “temporal” reasoning).
- LongMemEval: tests that check if the AI keeps user info up to date and acts consistently across sessions.
What they found:
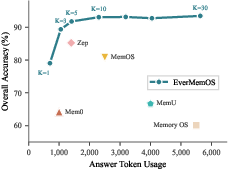
- EverMemOS answered the most questions correctly compared to other memory systems it was tested against.
- It especially improved on harder tasks that needed combining scattered information and keeping track of changes over time.
- It did this efficiently—by retrieving focused, relevant memories rather than flooding the AI with everything.
- In a profile study (PersonaMem v2), adding the consolidated user profile (not just raw episodes) noticeably improved accuracy, showing that “semantic consolidation” (turning episodes into stable knowledge) really helps.
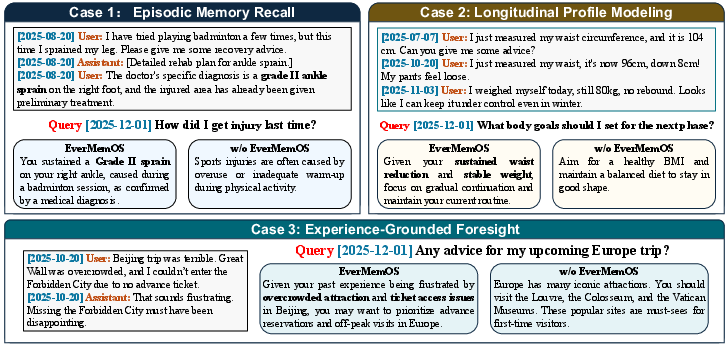
- Case studies showed practical benefits, like making safer recommendations (avoiding alcohol during antibiotics), keeping a stable, accurate picture of the user, and giving proactive advice based on past problems (e.g., buying tickets earlier to avoid crowds).
Why It Matters
This research moves AI assistants closer to being reliable long-term helpers. With EverMemOS:
- Conversations feel more consistent and personal over weeks or months.
- The AI can spot conflicts (new rules overriding old habits) and make safer suggestions.
- It can support ongoing goals (like fitness or learning) by tracking progress and plans.
- It uses memory smartly, keeping costs lower and reducing confusion.
The authors note current limits: the system is tested on text-only chats, it adds some processing time and cost, and we still need better tests for extremely long timelines. Even so, EverMemOS shows a clear path to building assistants that remember like organized humans: summarizing experiences, forming stable knowledge, and recalling just what’s needed at the right moment.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following gaps and open questions that future research could address:
- Multimodal and embodied extension: How to define MemCell/MemScene schemas and pipelines for images, audio, video, sensor data, and actions, and how to evaluate memory in multimodal or embodied long-horizon settings.
- Robustness to noisy or adversarial inputs: How segmentation, narrative synthesis, and fact/foresight extraction behave under noisy, off-topic, or adversarial dialogs; formal stress tests and defenses against memory poisoning and prompt injection.
- Fact verification and uncertainty: Lack of mechanisms to validate Atomic Facts, assign confidence/provenance, quantify uncertainty, and propagate confidence through consolidation and retrieval.
- Conflict resolution policy: The system mentions “conflict tracking” but does not specify algorithms for reconciling conflicting facts (e.g., recency vs reliability weighting, change-point detection) or provide evaluations of conflict handling.
- Temporal reasoning and foresight validity: No formal method to infer, calibrate, or update validity intervals for Foresight (), nor handling of ambiguous/relative time, time zones, or uncertainty over temporal bounds.
- Measuring foresight utility: No dedicated benchmarks or metrics to quantify whether foresight signals improve downstream outcomes (e.g., proactive recommendations) or cause harm via incorrect forecasts.
- “Necessity and sufficiency” retrieval: The principle is not operationalized with metrics or guarantees; there is no evaluation of minimality, redundancy, or counterfactual tests showing which retrieved items were truly necessary/sufficient.
- Retrieval loop risks: The agentic verification and query rewriting loop lacks analysis of failure modes (e.g., oscillation, over-retrieval, false sufficiency), termination criteria, or performance guarantees.
- Scalability and lifecycle management at true long horizons: No complexity analysis or empirical study of memory growth over months/years, garbage collection/forgetting policies, deduplication, or distributed indexing at million-scale MemCells.
- Latency and online constraints: End-to-end latency budgets, batching/caching strategies, and user-perceived delays are not quantified under realistic concurrency and throughput.
- Generalization across backbones and openness: Heavy reliance on GPT-4.* models; robustness to smaller/open models, model drift, and prompt sensitivity is only lightly explored.
- Multilingual and code-switching: No evaluation in non-English, code-switched, or low-resource languages; unclear how cross-lingual segmentation, consolidation, and retrieval should be handled.
- Evaluation coverage and ecological validity: Benchmarks are synthetic or limited in scope; missing longitudinal, real-user A/B tests, field deployments, and evaluations in safety-critical or tool-augmented tasks.
- Judge bias and reproducibility: Use of LLM-as-a-judge may bias results; need for human evaluation beyond spot checks, inter-annotator agreement reports, release of prompts/seeds, and replication across judges.
- Privacy, security, and compliance: No threat model or mechanisms for PII detection, encryption, access control, tenant isolation, audit logs, or right-to-be-forgotten; compliance with GDPR/CCPA remains unaddressed.
- Safety filters in retrieval: Lack of safeguards against retrieving harmful, sensitive, or unauthorized memory during recollection; no redaction or policy enforcement layer.
- MemScene clustering dynamics: Threshold selection (τ), stability under topic drift, merging/splitting criteria, and prevention of cluster fragmentation or over-aggregation are not specified or evaluated.
- Error propagation and rollback: No explicit versioning, provenance-aware rollback, or repair mechanisms when early MemCell errors are consolidated and amplified into profiles or scenes.
- Interpretability and tooling: Limited transparency into why specific MemScenes/Episodes were retrieved, how profiles were updated, and how foresight was formed; absence of debugging/explainability tools.
- Interoperability with knowledge graphs and external corpora: No mapping between MemScenes and KG structures (entities/relations), or procedures for grounding/aligning with external knowledge sources and RAG corpora.
- Domain and task transfer: Unclear performance and adaptation strategies in technical domains (code, medical, legal), multi-party dialogs, and settings with specialized ontology or structured inputs.
- Dynamic forgetting vs over-consolidation: No principled policy for when to abstract vs retain detail; risks of premature summarization and loss of granular episodes are not studied.
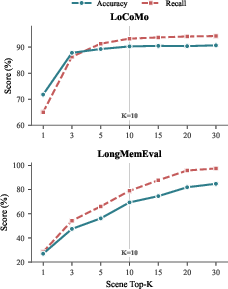
- Hyperparameter auto-tuning: Limited sensitivity analysis beyond N and K; no automatic calibration of τ, RRF fusion weights, re-ranker cutoffs, or adaptive retrieval budgets conditioned on query difficulty.
- Temporal representation beyond intervals: No support for uncertain time distributions, partial ordering, or algebraic temporal relations (e.g., Allen’s interval algebra) that could improve temporal reasoning.
- Multi-user and multi-agent memory: Open questions around diarization, user-specific vs shared memory, access control, and conflict resolution in team or multi-agent settings.
- Storage correctness and reliability: Absent discussion of persistence guarantees (ACID), crash recovery, and consistency semantics for online updates in long-running deployments.
- Learning to retrieve and consolidate: All operations are prompt-based; opportunities to train retrieval/planning policies (e.g., RL, imitation) or learn consolidation strategies are unexplored.
- Alternative scene representations: The benefits of graph-based, hierarchical, or probabilistic scene models over centroid-based clustering are not compared or ablated.
- Measuring profile stability and drift: No standardized metrics for long-term profile accuracy, drift detection, or false update rates on extended timelines beyond PersonaMem v2.
Practical Applications
Immediate Applications
Below are concrete, near-term use cases that can be deployed using the paper’s released code and methods (MemCells, MemScenes, reconstructive recollection with necessity/sufficiency, time-bounded Foresight).
- Customer support and CRM assistants (software, retail, telecom)
- What: Maintain stable, evolving customer profiles; detect conflicts (e.g., preferences vs new constraints); retrieve only necessary/sufficient past context to resolve issues.
- Tools/workflows: MemScene-per-customer theme; CRM plugin (Salesforce/Zendesk/HubSpot) that writes MemCells from chats/emails; Foresight for warranty windows or planned upgrades; agentic verification to rewrite queries when context is insufficient.
- Assumptions/dependencies: PII governance and consent; hybrid retrieval stack (dense+BM25, RRF); LLM quality comparable to GPT-4.1-mini; acceptable latency/cost.
- Patient-facing triage and education chat (healthcare)
- What: Capture episodic medical interactions as MemCells, extract atomic facts (conditions, meds), and maintain time-valid Foresight (e.g., “on antibiotics until 2026-02-10”); ensure recommendations avoid conflicts (no alcohol with antibiotics).
- Tools/workflows: EHR annotation and patient portal chatbot; medication timelines; scene-driven patient profile updated with recency-aware rules; necessary/sufficient retrieval to minimize overexposure of sensitive history.
- Assumptions/dependencies: HIPAA/GDPR compliance; clinical disclaimers and human-in-the-loop; reliable timestamps; domain-prompts tuned to medical phrasing.
- Personalized tutoring and study companions (education)
- What: Consolidate student episodes (assignments, errors, improvements) into course/topic MemScenes; track atomic facts of mastery and misconceptions; use Foresight for upcoming deadlines and study plans.
- Tools/workflows: LMS plugins (Canvas/Moodle) auto-segment transcripts and submissions; progress dashboards fed by MemScene summaries; contextual retrieval to generate targeted hints.
- Assumptions/dependencies: Access to student data with consent (FERPA/GDPR); fairness and bias monitoring; domain-specific skill taxonomy.
- Meeting memory and project OS (enterprise software)
- What: Turn meeting transcripts into concise Episodes and Atomic Facts, group into project MemScenes, and recall only the necessary past decisions for proposals, briefings, and status updates.
- Tools/workflows: Slack/Teams bots; incremental consolidation into project profiles; change-log MemCells with Foresight (e.g., deprecation windows, release dates).
- Assumptions/dependencies: Availability of transcripts; governance policies; prompt templates tailored to organizational terminology.
- Software engineering assistants (software)
- What: Persist architectural decisions, coding conventions, and deprecations with validity intervals; retrieve just-enough historical context in PRs and code reviews to avoid outdated guidance.
- Tools/workflows: GitHub/Jira integration that creates MemCells from ADRs, PR comments, and incident retros; MemScenes per repo/module; agentic sufficiency checks before suggestions.
- Assumptions/dependencies: Repository access and embeddings for code+text; latency budget for CI; alignment prompts for engineering style guides.
- Financial client support and suitability checks (finance)
- What: Maintain risk profiles and life events as MemScenes; time-bound constraints (e.g., lock-in periods, vesting dates); compose necessary/sufficient context for recommendations and audit trails.
- Tools/workflows: CRM-integrated memory layer; Foresight for cashflow timelines; evidence packs for compliance reviews.
- Assumptions/dependencies: Regulatory compliance (KYC/AML, suitability rules); human supervision; robust logging for audits.
- Travel and lifestyle planning companions (consumer apps)
- What: Use Foresight to anticipate constraints (e.g., crowded dates, ticket windows) and avoid repeating failures; consolidate preferences and past trips for aligned itineraries.
- Tools/workflows: Calendar and booking integrations; MemCells capturing trips and issues; MemScenes per destination/theme; alerting within validity intervals.
- Assumptions/dependencies: Access to calendars/email; user consent; accurate time handling.
- Brand voice, content, and campaign orchestration (marketing)
- What: Preserve brand persona and guidelines as MemScenes; keep campaign facts and schedules with Foresight; retrieve minimal context to ensure cross-channel consistency.
- Tools/workflows: CMS plugins; brief generators pulling Episodes and profile; conflict detection (outdated claims or offers).
- Assumptions/dependencies: Centralized brand assets; channel-specific prompts; review workflows.
Long-Term Applications
Below are applications that would benefit from extending EverMemOS to multimodal inputs, stricter safety/efficiency guarantees, and broader organizational integration.
- Multimodal memory agents and embodied robotics (robotics)
- What: Consolidate audio/video/sensor episodes as MemCells; scene-level organization of environments, tasks, and user interactions; time-valid Foresight for maintenance or charging cycles.
- Dependencies: Multimodal encoders; real-time retrieval; safety certification; on-device memory caches to reduce latency.
- Clinical decision support memory layer (healthcare)
- What: Longitudinal consolidation across EHR, labs, imaging; detect conflicts (drug interactions vs comorbidities); provide clinicians with necessary/sufficient evidence slices at point-of-care.
- Dependencies: Rigorous validation and drift monitoring; integration with clinical ontologies; regulatory approval; strong privacy guarantees and auditability.
- Whole-learner educational memory OS (education)
- What: Cross-course MemScenes for competencies; trajectory-aware feedback and interventions; foresight on prerequisite gaps and exam windows.
- Dependencies: Standardized skill graphs; privacy-preserving profiles (federated or on-device); policy compliance; explainability for educators/students.
- Asset maintenance and grid operations memory (energy/industrial)
- What: Consolidate logs, alarms, interventions into MemScenes per asset; Foresight for inspection/maintenance windows; retrieval of necessary/sufficient procedures and hazard notes.
- Dependencies: SCADA/IoT integrations; domain ontologies; offline-first workflows; safety and compliance standards.
- Scientific research copilots and living lab notebooks (academia)
- What: Distill experiments and literature into Episodes and Atomic Facts; detect conflicts across papers; reconstruct sufficient evidence for claims and reproducibility.
- Dependencies: Access to papers/data; citation-aware retrieval; community standards for provenance; integration with ELNs and repositories.
- Legal and policy case management (public sector)
- What: Scene-level organization of cases, statutes, filings; validity intervals for permits/contract clauses; retrieval of necessary/sufficient evidence for briefs and audits.
- Dependencies: Secure, compartmentalized storage; confidentiality controls; human review; jurisdiction-specific prompts.
- Privacy-preserving “memory-as-a-service” (software/platform)
- What: Federated EverMemOS instances across devices/organizations with encrypted MemCells/MemScenes; client-side Foresight and recall.
- Dependencies: Cryptographic protocols, differential privacy; standardized APIs; consent and data portability frameworks.
- Performance, benchmarking, and MLOps ecosystem
- What: Standard long-horizon benchmarks (ultra-long timelines, conflict resolution, foresight efficacy); hardware/software acceleration; asynchronous and cached lifecycle operations.
- Dependencies: Community adoption; reproducible evaluation harnesses; cost/latency budgets; alignment with cloud and on-device runtimes.
Glossary
- Agentic retrieval: An active retrieval process where the agent decides what evidence is necessary and sufficient for a task, rather than passively fetching matches. "Reconstructive Recollection performs MemScene-guided agentic retrieval to compose the necessary and sufficient context for downstream reasoning."
- Agentic Verification: A verification step where an LLM assesses whether retrieved context is sufficient, potentially triggering query rewriting. "Agentic Verification and Query Rewriting"
- Atomic Facts: Discrete, verifiable statements extracted from episodes to enable precise matching and retrieval. "(Atomic Facts): Discrete, verifiable statements derived from for high-precision matching."
- Autoregressive LLMs: LLMs that generate tokens sequentially, each conditioned on previously generated tokens. "Early differentiable memory systems (e.g., NTM/DNC/Key--Value memories) introduced external memory interaction, but scale poorly and are ill-suited to modern autoregressive LLMs."
- BM25: A classical lexical retrieval function used in information retrieval to score document-query relevance. "We first compute relevance between the query and all MemCells by fusing dense and BM25 retrieval over their Atomic Facts via Reciprocal Rank Fusion (RRF)."
- Cohen's kappa: A statistic measuring inter-annotator agreement, corrected for chance. "showing high agreement (Cohen's )."
- Dense retrieval: Retrieval based on learned vector embeddings rather than exact lexical matches. "We first compute relevance between the query and all MemCells by fusing dense and BM25 retrieval over their Atomic Facts via Reciprocal Rank Fusion (RRF)."
- Engram: A theoretical construct denoting the physical or computational trace of memory; here, an organizing principle for lifecycle design. "We introduce EverMemOS, a self-organizing memory operating system that implements an engram-inspired lifecycle for computational memory."
- Episodic Trace Formation: A phase that transforms interaction streams into structured memory units (MemCells) capturing episodes, facts, and foresight. "Episodic Trace Formation converts dialogue streams into MemCells that capture episodic traces, atomic facts, and time-bounded Foresight signals."
- Foresight: Forward-looking inferences (plans, temporary states) tagged with validity intervals to reflect temporal scope. " (Foresight): Forward-looking inferences (prospections; e.g., plans and temporary states) annotated with validity intervals to support temporal awareness."
- Length extrapolation: Techniques enabling models trained on shorter sequences to generalize to much longer inputs. "Prior work extends context via sparse attention \cite{beltagy2020longformer,zaheer2020bigbird}, recurrence \cite{dai2019transformer,bulatov2022recurrent}, and length extrapolation \cite{chen2024clex,chen2025longpo}."
- Lost-in-the-Middle phenomenon: Degradation where models fail to use information situated in the middle of very long contexts. "Expanding context windows is a direct approach, but ultra-long contexts still degrade in performance (e.g., the ``Lost-in-the-Middle'' phenomenon) and incur prohibitive computational costs"
- Memory Operating System: A system-level framework that unifies memory storage, retrieval, filtering, and updating for LLM agents. "Memory Operating Systems that unify storage, retrieval, filtering, and updating"
- MemCell: The atomic memory unit in EverMemOS encapsulating an episode, atomic facts, foresight, and metadata. "At the core of EverMemOS is the MemCell, the atomic unit bridging low-level data and high-level semantics."
- MemScene: A higher-level, thematic aggregation of MemCells used for consolidation, retrieval, and profile updates. "Semantic Consolidation organizes MemCells into MemScenes, distilling stable semantic structures and updating user profiles."
- Multi-hop (reasoning): Tasks requiring reasoning over multiple pieces of evidence or steps across a conversation/history. "LoCoMo contains 1{,}540 questions over 10 ultra-long dialogues (9K tokens each), spanning Single-hop, Multi-hop, and Temporal questions."
- Necessity and sufficiency (principle of): A retrieval principle aiming to include only the evidence required and enough to answer a query correctly. "Second, reconstructive recollection, guided by the principle of necessity and sufficiency, actively composes only the grounded context required for a given query, rather than indiscriminately retrieving all potentially relevant records."
- Parametric approaches: Methods that store knowledge inside model parameters (e.g., fine-tuning, editing), as opposed to external memory. "Parametric approaches (e.g., PEFT, continual learning, and model editing) internalize information, yet often suffer from forgetting and instability"
- PEFT: Parameter-Efficient Fine-Tuning methods that adapt a model using a small number of additional parameters. "Parametric approaches (e.g., PEFT, continual learning, and model editing) internalize information, yet often suffer from forgetting and instability"
- Prospection: The cognitive process of imagining or inferring future states; here, forward-looking signals stored as foresight. "(prospections; e.g., plans and temporary states)"
- Recency-aware updates: Profile or memory updates that weight recent information more heavily while tracking conflicts. "We maintain a compact profile of explicit facts (including time-varying measurements) and implicit traits, updated online from scene summaries with recency-aware updates and conflict tracking (Appendix~\ref{sec:profile_example})."
- Reciprocal Rank Fusion (RRF): A method for combining ranked lists (e.g., dense and BM25 results) into a single ranking. "We first compute relevance between the query and all MemCells by fusing dense and BM25 retrieval over their Atomic Facts via Reciprocal Rank Fusion (RRF)."
- Reconstructive Recollection: A retrieval phase that actively composes context guided by scenes and the necessity–sufficiency principle. "Reconstructive Recollection performs MemScene-guided retrieval under the principle of necessity and sufficiency."
- Retrieval-augmented generation (RAG): A paradigm where external documents are retrieved to supplement the model’s context during generation. "Retrieval-augmented generation (RAG) \cite{lewis2020retrieval} externalizes memory to alleviate window limits, but its reliability depends on retrieval quality"
- Semantic Boundary Detector: A mechanism that segments continuous interaction streams into coherent episodes by detecting topic shifts. "a Semantic Boundary Detector processes interactions via a sliding window."
- Semantic Consolidation: The process of organizing episodic traces into stable, higher-level structures (MemScenes) and updating profiles. "Semantic Consolidation organizes MemCells into thematic MemScenes, distilling stable semantic structures and updating user profiles."
- Systems consolidation: A neuroscience-inspired process where transient memories stabilize into long-term representations; adapted here for computational memory. "Inspired by systems consolidation \cite{mcgaugh2000memory}, EverMemOS employs an online mechanism that organizes MemCells into higher-order structures to transition from transient episodes to stable long-term knowledge."
- Validity intervals: Time bounds associated with foresight or facts indicating when they are applicable. "annotated with validity intervals to support temporal awareness."
Collections
Sign up for free to add this paper to one or more collections.