SimpleMem: Efficient Lifelong Memory for LLM Agents
Abstract: To support reliable long-term interaction in complex environments, LLM agents require memory systems that efficiently manage historical experiences. Existing approaches either retain full interaction histories via passive context extension, leading to substantial redundancy, or rely on iterative reasoning to filter noise, incurring high token costs. To address this challenge, we introduce SimpleMem, an efficient memory framework based on semantic lossless compression. We propose a three-stage pipeline designed to maximize information density and token utilization: (1) \textit{Semantic Structured Compression}, which applies entropy-aware filtering to distill unstructured interactions into compact, multi-view indexed memory units; (2) \textit{Recursive Memory Consolidation}, an asynchronous process that integrates related units into higher-level abstract representations to reduce redundancy; and (3) \textit{Adaptive Query-Aware Retrieval}, which dynamically adjusts retrieval scope based on query complexity to construct precise context efficiently. Experiments on benchmark datasets show that our method consistently outperforms baseline approaches in accuracy, retrieval efficiency, and inference cost, achieving an average F1 improvement of 26.4% while reducing inference-time token consumption by up to 30-fold, demonstrating a superior balance between performance and efficiency. Code is available at https://github.com/aiming-lab/SimpleMem.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SimpleMem, a smarter “memory” system for AI chatbots (LLM agents) that talk to people over long periods. The goal is to help these agents remember important details from past conversations without getting confused or wasting time and computer power. SimpleMem keeps the most useful information, organizes it clearly, and retrieves it quickly when needed.
Objectives
In simple terms, the researchers wanted to solve three problems:
- AI agents often keep every message, which leads to a huge, messy history full of repeated or unimportant details.
- Filtering the mess by repeatedly “thinking” about it is slow and expensive.
- Using fixed-size memory chunks doesn’t adapt well: simple questions get too much info, and hard questions get too little.
So they asked:
- Can we compress conversation history so we keep the meaning but remove the fluff?
- Can we combine related memories into clearer summaries over time?
- Can we fetch just the right amount of information depending on how hard the question is?
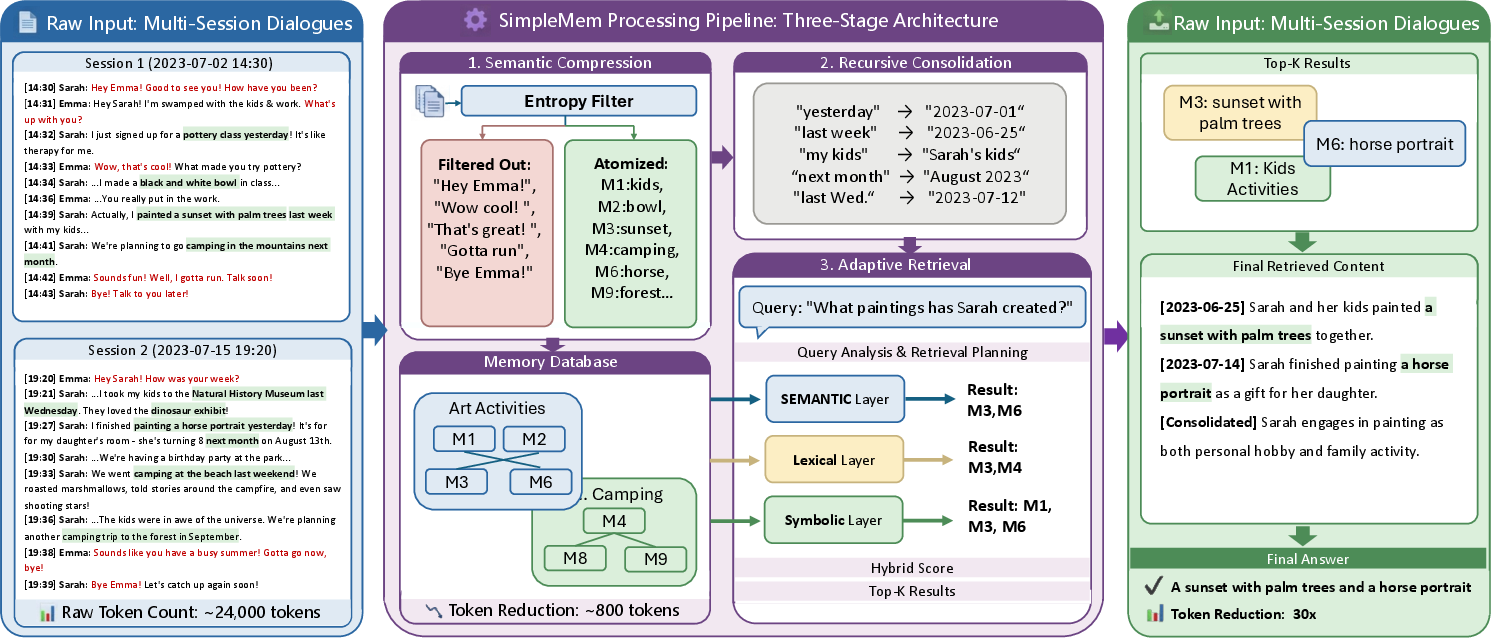
How SimpleMem Works (Methods)
Think of SimpleMem as a tidy library for an AI’s long-term memory. It has three main stages:
1) Semantic Structured Compression
Imagine turning a long chat into clean, reliable notes:
- It looks at the conversation in small “windows” and checks if there’s anything new or important (like new people, facts, or decisions). If a window is mostly chit-chat or repeated info, it’s skipped.
- It rewrites useful parts into short, stand-alone facts called memory units. For example:
- “He agreed” becomes “Bob agreed” (this is called coreference resolution).
- “Next Friday” becomes an exact date like “2025-10-24” (this is called temporal anchoring).
- Result: each memory unit makes sense on its own, without needing the original chat around it.
2) Structured Indexing and Recursive Consolidation
Once the notes exist, SimpleMem files them in a way that makes them easy to find:
- It indexes memory in three ways:
- Semantic (meaning-based, like “latte” being similar to “coffee”).
- Lexical (keyword-based, exact matches for names and terms).
- Symbolic (metadata like time and type, e.g., “person,” “event,” “date”).
- Over time, it merges related notes into summaries. For instance, many entries like “user ordered a latte at 8:00 AM” become “the user regularly drinks coffee in the morning.” The detailed entries aren’t lost; they’re archived. This reduces clutter and speeds up search.
3) Adaptive Query-Aware Retrieval
SimpleMem fetches information differently depending on the question:
- It scores how relevant each memory is using meaning, keywords, and metadata (like filtering by dates or people).
- It estimates how complex the question is. Simple questions (like “What’s Sarah’s job?”) need few, precise memories. Complex questions (like “Based on last week’s plan and today’s update, what should we do tomorrow?”) need more.
- It then retrieves just enough memory—no more, no less—so answers are accurate without wasting tokens (tokens are like the small pieces of text the AI reads and writes).
Main Findings
The team tested SimpleMem on a tough benchmark called LoCoMo, which has long conversations (200–400 turns) and tricky questions (like combining facts across time).
Key results:
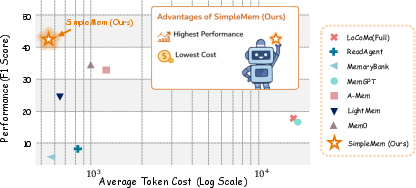
- Better accuracy: SimpleMem improved F1 scores by about 26.4% compared to strong baselines. It did especially well on temporal questions (understanding timelines and “before/after”).
- Much lower cost: SimpleMem used up to 30× fewer tokens than systems that keep the full conversation. It also ran faster when building and searching memory.
- Works on smaller models: Even smaller, cheaper AI models with SimpleMem beat larger models using older memory methods. This means you don’t need a massive AI to get good long-term memory performance.
The researchers also ran ablation studies (turning off parts of SimpleMem to see what breaks):
- Without compression, timeline questions got much worse (because dates and references weren’t cleaned).
- Without consolidation, multi-step reasoning dropped (too many scattered facts).
- Without adaptive retrieval, simple tasks suffered (too much or too little context was fetched).
Why This Matters (Implications)
SimpleMem helps AI assistants be more reliable over long periods—like a helpful friend who remembers the important stuff, summarizes patterns, and finds the right details fast. This matters because:
- It makes AI cheaper and faster by reducing wasted computation.
- It helps avoid the “lost in the middle” problem, where too much context actually confuses the AI.
- It lets smaller models perform well, so more people and projects can use capable, memory-smart AI.
- It’s especially helpful for long-term tasks: personal assistants, project managers, education tutors, or customer support bots that need to remember and reason across weeks or months.
In short, SimpleMem shows that smart memory management—compressing meaning, summarizing patterns, and retrieving adaptively—can make AI agents both stronger and more efficient in real-world, long-term conversations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated, actionable list of what remains missing, uncertain, or unexplored in the paper.
Theory and assumptions
- The paper claims “semantic lossless compression” without a formal definition or guarantee; no information-theoretic bounds or recoverability criteria (e.g., ability to reconstruct original facts/events) are provided.
- No formal analysis of error propagation from preprocessing (coreference resolution, temporal anchoring) to retrieval and reasoning performance; sensitivity to systematic errors (e.g., mis-resolved entities, wrong absolute times) is unquantified.
- Consolidation as “higher-level abstractions” lacks verification guarantees; no mechanisms to detect, quantify, or bound hallucination or overgeneralization introduced by synthesis.
- No conflict-resolution or truth-maintenance framework is defined for contradictory or later-corrected memories; criteria to reconcile inconsistencies across consolidation levels remain unspecified.
Method design and configuration
- Hyperparameters (e.g., α, τ_redundant, τ_cluster, β, λ) are fixed by fiat; there is no sensitivity analysis or adaptive/learned tuning strategy under varying domains, workloads, or memory scales.
- The query-complexity estimator is under-specified (features, labels, training data, objectives); domain transferability, calibration, and robustness to misclassification are not evaluated.
- Consolidation policies (when to trigger, how aggressively to collapse, how to roll back) and archival/retrieval-from-archive criteria are not operationalized or benchmarked.
- Handling of rare-but-critical or low-entropy events is unclear; entropy-based filtering risks dropping safety-critical outliers without protective heuristics (e.g., anomaly-aware gating).
- The multi-view index relies on specific embedding and sparse models; the effects of alternative encoders, cross-encoder re-ranking, and hybrid late-fusion choices are not explored.
Robustness, safety, and security
- No evaluation of robustness to adversarial or poisoned inputs (e.g., prompt-injection stored in memory, entity spoofing, timestamp manipulation) or defensive sanitization of memory.
- Privacy and compliance are unaddressed: how PII is handled, retention policies, encryption-at-rest/in-transit, access control, auditability, and “right to be forgotten” procedures.
- No mechanisms for provenance tracking and fact-level attribution, which are needed to audit consolidated abstractions and to support reversible edits/deletions.
- The paper mentions adversarial success rate in metrics but does not report results; robustness against distractors remains unquantified.
Scalability and systems concerns
- Long-horizon scalability is not stress-tested: behavior with millions of memory units, index maintenance overhead, and consolidation/re-embedding costs over months of usage are unknown.
- Embedding/model drift is not addressed: how index consistency is maintained when encoders or LLM backbones change (re-embedding strategies, versioning, downtime).
- Asynchronous consolidation’s compute budget, scheduling, and impact on interactive latency are not characterized; potential race conditions between retrieval and background updates are unexamined.
- Storage and memory-footprint growth (active vs. archived memories), compaction policies, and associated costs are not reported beyond token counts.
- Concurrency in multi-session or multi-agent settings (consistency, locking, eventual convergence of indexes and abstractions) is not discussed.
Generalization and applicability
- Evaluation is limited to LoCoMo; generalization to other long-term memory benchmarks (e.g., dynamic tool use, task planning, knowledge evolution, multi-document QA) is untested.
- No evidence for multilingual, code-switched, or domain-specific (e.g., clinical, legal) robustness; entity/temporal normalization across languages and calendars/time zones (DST) is not evaluated.
- Applicability to multimodal agent memory (e.g., images, logs, tool outputs) is not explored; how to compress/index non-text signals and align them with symbolic metadata is open.
- Integration with tool-using agents (calendar/CRM updates, environment state) and bi-directional synchronization between external state and memory are unspecified.
Evaluation methodology
- Statistical rigor is limited: no variances, confidence intervals, or significance tests; reproducibility across seeds/runs and robustness across prompts/backends are not reported.
- Baseline parity is unclear: token budgets, retrieval depths, and hyperparameter tuning equality (and whether high-effort baselines were re-optimized) are not substantiated.
- Reported efficiency uses token cost; comprehensive system-level metrics (wall-clock latency under load, memory/CPU utilization, energy) across hardware are missing.
- BLEU-1/F1 may be insufficient for long-context reasoning; human evaluation, exact-match/faithfulness metrics, calibration, and error typologies are not provided.
- The “lost-in-the-middle” mitigation claim is not directly tested with targeted probes; explicit middle-position stress tests are absent.
Failure modes and diagnostics
- Consolidation might suppress important exceptions by over-abstracting behavior patterns; criteria to preserve anomalies or counterfactuals are not defined.
- No diagnostics for when to prefer fine-grained details over abstractions; strategies for uncertainty-aware retrieval (confidence thresholds, fallback to raw logs) are missing.
- Mechanisms to detect and repair consolidation-induced drifts (e.g., incorrect habit inference) or to version/control the evolution of abstractions are not presented.
Reproducibility and artifacts
- Essential training/evaluation details for the query-complexity classifier and normalization modules (datasets, labeling protocols, model configs) are absent.
- Hardware/software environment, index configurations at scale, and data preprocessing specifics (e.g., NER/coref/time normalization tool versions) are insufficient for full replication.
- The code release’s completeness (scripts for consolidation scheduling, re-indexing, and provenance tracking) and licensing constraints of third-party models/embeddings are not clarified.
Open research directions
- Develop formal criteria and metrics for “semantic losslessness,” including bounded reconstruction error and factual faithfulness under compression/consolidation.
- Learnable, uncertainty-aware gating and consolidation policies (e.g., RL/bandit control) that trade off precision, recall, and cost dynamically.
- Provenance-aware, reversible consolidation with confidence scoring, contradiction detection, and truth-maintenance systems for evolving facts.
- Robust, privacy-preserving memory (sanitization, PII redaction, secure deletion), and defenses against memory poisoning/prompt injection.
- Cross-lingual and multimodal extensions with unified temporal/entity normalization and alignment across modalities.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released SimpleMem code and standard LLM/RAG tooling.
- Healthcare (operations-focused): longitudinal intake summarization and care-coordination memory for non-diagnostic workflows
- Description: Convert multi-visit patient communications and notes into normalized, timestamped memory units; consolidate recurring patterns (e.g., medication adherence, appointment attendance); retrieve context adaptively for care coordination and triage.
- Tools/Products/Workflows: EHR connectors or FHIR adapters; medical NER/coreference modules; BM25 + dense embeddings + SQL metadata storage; asynchronous consolidation jobs; adaptive retrieval per query complexity.
- Assumptions/Dependencies: HIPAA/GDPR compliance; domain-tuned entity/temporal normalization; role-based access control; human-in-the-loop review.
- Education: personalized tutoring systems with durable learner profiles
- Description: Track multi-session interactions, normalize references (assignments, skills, errors), and consolidate into higher-level learning patterns; retrieve minimal context for simple recall and expanded context for multi-step reasoning.
- Tools/Products/Workflows: LMS integration; learner model that uses symbolic metadata (skills, timestamps); tri-layer indexing in LanceDB; adaptive k for retrieval based on question type.
- Assumptions/Dependencies: Student privacy and consent; domain-specific tagging; calibrated complexity classifier for queries.
- Customer service/CRM: long-term memory for support agents
- Description: Maintain compact, indexed histories across tickets/chats; resolve coreferences (e.g., “it” → specific product), normalize timelines (“last week” → absolute date), and consolidate into habits/issues (e.g., “recurring login failures on Mondays”).
- Tools/Products/Workflows: Helpdesk connectors; PII redaction pipeline; entropy-aware ingestion gates; hybrid retrieval using semantic, lexical, and symbolic filters.
- Assumptions/Dependencies: Compliance (PII, retention); robust entity extraction; multi-tenant isolation; cost controls via token budgeting.
- Enterprise knowledge management: meeting assistants and project memory
- Description: Turn long meeting logs and project threads into self-contained, time-anchored facts; consolidate repetitive updates into abstract patterns (e.g., “weekly risk updates for Module A”); adapt retrieval depth per query.
- Tools/Products/Workflows: Integrations with calendar, conferencing, issue trackers (Jira, GitHub); tri-layer index; background consolidation; query complexity classifier; minimal tokens for single-hop lookups.
- Assumptions/Dependencies: Access permissions; time zone normalization; entity linking across tools; governance for memory retention.
- Software development: code/project-aware assistants
- Description: Index commit messages, issues, PR discussions, and build logs into normalized memory units tied to files/functions; consolidate recurring incidents (e.g., flaky test after releases); retrieve with symbolic constraints (file paths, timestamps).
- Tools/Products/Workflows: IDE plugin; repo and CI integrations; code embeddings + BM25; metadata (file, module, timestamp); adaptive retrieval for debugging vs quick lookups.
- Assumptions/Dependencies: High-quality code embeddings; reliable entity resolution for identifiers; organizational policies on source-code handling.
- Personal digital assistants (daily life)
- Description: Maintain lightweight, structured personal memory (preferences, schedules, routines); consolidate habits (e.g., “morning coffee” pattern) for efficient recall and planning.
- Tools/Products/Workflows: Calendar/notes/email integrations; on-device or private cloud LanceDB; time normalization; adaptive retrieval to minimize token cost on simple queries.
- Assumptions/Dependencies: Opt-in consent; privacy-first storage; robust temporal resolution across locales; user controls for retention.
- Finance (customer advisory and support)
- Description: Maintain long-term client interaction memory; consolidate spending/saving patterns; retrieve targeted, time-bound context for recommendations without bloating prompts.
- Tools/Products/Workflows: CRM/transaction feed connectors; tri-layer index; symbolic filters for entities/accounts/time; controlled retrieval depth per task.
- Assumptions/Dependencies: Regulatory compliance (KYC/AML, data retention); domain-specific normalization; auditable metadata.
- Security and prompt-cost optimization for LLM apps (cross-sector)
- Description: Reduce attack surface and token costs by pruning irrelevant history and enforcing symbolic constraints (e.g., entity/timestamp filters); mitigate “lost-in-the-middle” issues via high-density memory units.
- Tools/Products/Workflows: Memory middleware for LangChain/LlamaIndex; policy-aware filters; token budgeting dashboards; SimpleMem adapters for existing RAG pipelines.
- Assumptions/Dependencies: Accurate query scoring; monitoring for retrieval drift; robust guardrails.
- Research/academia: reproducible evaluation of long-term memory mechanisms
- Description: Use SimpleMem on LoCoMo and similar datasets to study efficiency/accuracy trade-offs, ablate components, and develop domain-specific memory normalization.
- Tools/Products/Workflows: GitHub codebase; LanceDB; ablation harness; complexity classification experiments; cross-model benchmarking.
- Assumptions/Dependencies: Compute availability; careful metric selection; domain adaptation of normalization modules.
Long-Term Applications
The following applications will benefit from further research, domain adaptation, large-scale deployment engineering, and/or regulation and standardization.
- Clinical decision support (diagnostics and treatment planning)
- Description: Move beyond operations to clinically impactful memory that consolidates longitudinal histories (labs, imaging, notes) into abstract patient trajectories; enable multi-hop temporal reasoning for care decisions.
- Tools/Products/Workflows: Medical ontologies; fine-tuned clinical NER/coref; audit trails from symbolic metadata; adaptive retrieval tuned for medical query complexity.
- Assumptions/Dependencies: Rigorous validation and regulatory approval; bias/fairness auditing; integration with EHR standards (FHIR); human oversight; robust error handling.
- Autonomous robots and vehicles: lifelong episodic memory for planning
- Description: Store task/environmental experiences, normalize temporal references, consolidate routines and edge-case patterns; retrieve memory under real-time constraints for planning and safety.
- Tools/Products/Workflows: On-device memory substrate; efficient embeddings; hardware acceleration; concurrency-safe consolidation; symbolic filters tied to maps/objects/time.
- Assumptions/Dependencies: Real-time performance; multimodal integration (vision, lidar); formal verification; safety certification.
- Government and public services: citizen case memory and auditability
- Description: Standardized, auditable memory formats for helplines and case management across years; symbolic metadata for transparent filtering (entities, time, jurisdiction).
- Tools/Products/Workflows: Inter-agency memory mesh; retention/purge policies; audit dashboards; adaptive retrieval minimizing token costs and exposure of sensitive data.
- Assumptions/Dependencies: Policy frameworks; privacy-by-design; interoperability standards; fairness and accessibility requirements.
- Legal sector: case law and matter management with temporal/logical normalization
- Description: Normalize multi-year case histories; consolidate patterns across filings and hearings; leverage symbolic constraints for time-bounded retrieval and entity-specific queries.
- Tools/Products/Workflows: Legal ontologies; court/firm system integrations; memory governance; adaptive retrieval tuned for legal tasks.
- Assumptions/Dependencies: Domain-specific normalization quality; evidentiary audit trails; conflict-of-interest safeguards.
- Enterprise multi-agent systems: shared, consistent memory fabric
- Description: A “memory mesh” enabling agents to read/write normalized facts and consolidated abstractions; concurrency control (CRDTs), consistency, and provenance via symbolic metadata.
- Tools/Products/Workflows: Memory OS/SDK; streaming ingestion; background consolidation services; cross-agent query complexity coordination.
- Assumptions/Dependencies: Access control; scalability; consistency guarantees; organizational governance.
- Memory-first edge computing and hardware acceleration
- Description: Lightweight, on-device memory substrates that use semantic compression to operate under constrained compute/storage; efficient retrieval for local assistants.
- Tools/Products/Workflows: Embedded LanceDB-like stores; compact embeddings; hardware-accelerated similarity search; incremental consolidation.
- Assumptions/Dependencies: Energy constraints; privacy requirements; limited model sizes; robust offline operation.
- Standards and policy for AI memory normalization and retention
- Description: Define interoperable formats for context-independent memory units (entities, timestamps, metadata); standardize consolidation and retrieval auditing; govern retention and portability.
- Tools/Products/Workflows: Industry consortia; reference implementations; compliance testing suites; policy templates.
- Assumptions/Dependencies: Cross-sector coordination; regulatory adoption; measurable auditability and safety criteria.
- Multimodal and chain-of-thought integration
- Description: Extend SimpleMem’s pipeline to images/audio/video and couple with controllable CoT compression to minimize tokens while preserving reasoning quality over complex, long-horizon tasks.
- Tools/Products/Workflows: Multimodal embeddings; temporal alignment across modalities; CoT compression controllers; adaptive retrieval tuned to multimodal query complexity.
- Assumptions/Dependencies: Faithfulness guarantees; robustness to distribution shifts; model support for multimodal reasoning.
- Training memory-aware models end-to-end
- Description: Co-train LLMs with memory normalization, consolidation objectives, and retrieval policies; reduce reliance on external heuristics and improve generalization.
- Tools/Products/Workflows: Curriculum design for lifelong memory; synthetic long-horizon datasets; differentiable memory modules; evaluation suites for memory robustness.
- Assumptions/Dependencies: Significant compute; dataset quality; safety/fairness guardrails; alignment with downstream domains.
Cross-cutting assumptions and dependencies for feasibility
- Quality of preprocessing: domain-tuned NER, coreference resolution, and temporal normalization are critical for converting raw text into reliable, context-independent memory units.
- Indexing stack: performance and relevance hinge on embedding selection, BM25 configuration, and expressive symbolic metadata; LanceDB or equivalent must scale to long-lived stores.
- Query complexity estimation: the classifier that adjusts retrieval depth must be calibrated to domain/task distributions.
- Privacy, security, and governance: PII handling, retention policies, and auditability are essential across sectors; symbolic metadata can aid enforcement and transparency.
- Resource constraints: asynchronous consolidation requires background compute; edge deployments need compact models and efficient similarity search.
- Model compatibility: benefits are shown across GPT and Qwen backbones; domain adaptation may be needed to maintain gains with specialized or smaller models.
Glossary
- Adaptive Pruning: A mechanism to limit retrieved context to the most relevant entries to save tokens while preserving information density. "This validates the efficacy of our Entropy-based Filtering and Adaptive Pruning, which strictly control context bandwidth without sacrificing information density."
- Adaptive Query-Aware Retrieval: A retrieval strategy that adjusts the number and granularity of memory entries based on the estimated complexity of the query. "Adaptive Query-Aware Retrieval, which dynamically adjusts retrieval scope based on query complexity to construct precise context efficiently."
- Adversarial Success Rate: A robustness metric indicating how often a system resists distractors or misleading inputs. "We report: F1 and BLEU-1 (accuracy), Adversarial Success Rate (robustness to distractors), and Token Cost (retrieval/latency efficiency)."
- Affinity score: A combined measure of semantic similarity and temporal closeness used to cluster related memory units. "For two memory units and , we define an affinity score as:"
- BM25: A classic sparse lexical relevance function used for keyword-oriented retrieval. "BM25 for sparse lexical indexing"
- BLEU-1: An accuracy-style metric (1-gram BLEU) used to evaluate text generation quality. "We report: F1 and BLEU-1 (accuracy), Adversarial Success Rate (robustness to distractors), and Token Cost (retrieval/latency efficiency)."
- Complementary Learning Systems (CLS): A cognitive theory inspiring the design of dual-process memory systems with fast episodic storage and slow consolidation. "To address these limitations, we introduce SimpleMem, an efficient memory framework inspired by the Complementary Learning Systems (CLS) theory"
- Context inflation: The accumulation of low-information dialogue that bloats context length and harms retrieval and reasoning. "A primary bottleneck in long-term interaction is context inflation, the accumulation of raw, low-entropy dialogue."
- Context window: The maximum token span an LLM can attend to in a single pass of inference. "However, constrained by fixed context windows, existing agents exhibit significant limitations when engaging in long-context and multi-turn interaction scenarios"
- Coreference resolution: The process of replacing ambiguous pronouns with specific entity names to make statements self-contained. "a coreference resolution module ($\Phi_{\text{coref}$)"
- Dense cluster: A group of memory units with high pairwise affinity indicating they should be consolidated. "When a group of memory units forms a dense cluster "
- Dense vector space: A continuous embedding space in which semantic similarity is measured via vector operations. "we map the entry to a dense vector space using embedding models"
- Entropy-aware filtering: A method that prioritizes high-utility information and discards low-entropy content during memory construction. "Semantic Structured Compression, which applies entropy-aware filtering to distill unstructured interactions into compact, multi-view indexed memory units"
- Entropy-based significance threshold: A cutoff value controlling which windows of dialogue are considered informative enough to store. "set the entropy-based significance threshold to "
- Episodic records: Raw, turn-by-turn memory of interactions before consolidation into higher-level abstractions. "Rather than accumulating episodic records verbatim, related memory units are recursively integrated into higher-level abstract representations"
- F1 score: The harmonic mean of precision and recall used as an accuracy metric for retrieval or QA tasks. "As shown in Figure~\ref{fig:tradeoff}, our empirical experiments demonstrate that SimpleMem establishes a new state-of-the-art with an F1 score"
- Fuzzy matching: Retrieval that uses semantic similarity to match conceptually related items rather than exact keywords. "which captures abstract meaning and enables fuzzy matching (e.g., retrieving "latte" when querying "hot drink")."
- Graph-based memory systems: Memory architectures that represent knowledge as graphs and often incur traversal overheads at retrieval time. "the latency of graph-based memory systems."
- Hybrid scoring function: A relevance function combining dense semantic similarity, sparse lexical matching, and symbolic constraints. "we propose a hybrid scoring function for information retrieval, "
- ISO-8601 timestamps: Standardized absolute time format used to normalize relative time expressions in memory units. "into absolute ISO-8601 timestamps."
- Indicator function: A logical function that enforces hard constraints (e.g., metadata matches) during ranking. "and the indicator function enforces hard symbolic constraints such as entity-based filters."
- LanceDB: A vector database used to implement multi-view memory indexing. "Memory indexing is implemented using LanceDB with a multi-view design"
- Lexical Layer: The sparse keyword-based index focusing on exact matches and proper nouns. "Second, the Lexical Layer generates a sparse representation focusing on exact keyword matches and proper nouns"
- LoCoMo benchmark: A dataset designed to evaluate long-term conversational memory and reasoning in LLM agents. "Comparison of Average F1 against Average Token Cost on the LoCoMo benchmark."
- Lost-in-the-Middle effect: A phenomenon where LLMs degrade on tasks when relevant information is buried in long contexts. "the “Lost-in-the-Middle” effect \cite{liu2023lost,kuratov2024case}"
- Memory unit: A self-contained factual or event-level statement extracted and normalized from dialogue. "compact, multi-view indexed memory units"
- Multi-Hop Reasoning: Questions that require synthesizing information across multiple disjoint turns. "Multi-Hop Reasoning: Questions requiring the synthesis of information from multiple disjoint turns (e.g., ``Based on what X said last week and Y said today...'');"
- Multi-view indexing: Storing memory entries with complementary semantic, lexical, and symbolic projections to enable flexible retrieval. "structured multi-view indexing for immediate access"
- Non-linear gating mechanism: A function that gates which windows of dialogue enter memory based on an information score. "we employ a non-linear gating mechanism, "
- Open Domain: Questions requiring general knowledge grounded in the conversation context. "Open Domain: General knowledge questions grounded in the conversation context;"
- Pairwise semantic similarity: The cosine similarity between embeddings used to measure relatedness of memory units. "average pairwise semantic similarity within a memory cluster exceeds $\tau_{\text{cluster}=0.85$."
- Phatic chit-chat: Social talk that carries low task-relevant informational content. "phatic chit-chat or redundant confirmations"
- Query complexity: An estimate of how difficult a query is, guiding how much and which memory to retrieve. "based on estimated query complexity"
- Recursive Consolidation: An asynchronous process that merges related memory units into higher-level abstractions to reduce redundancy. "(2) Recursive Consolidation incrementally organizes related memory units into higher-level abstract representations, reducing redundancy in long-term memory."
- Retrieval depth: The dynamically chosen number of memory entries to fetch based on query complexity. "the retrieval depth is dynamically adjusted based on estimated query complexity"
- Retrieval-Augmented Generation (RAG): A technique where external memory is retrieved and fed into an LLM to improve answers. "RAG-based methods \cite{lewis2020retrieval,asai2023self,jiang2023active}"
- Semantic divergence: A measure of difference in meaning between a window and prior context used in the information score. "entity-level novelty and semantic divergence."
- Semantic lossless compression: A compression principle aiming to preserve all task-relevant semantics while reducing tokens. "an efficient memory framework based on semantic lossless compression."
- Semantic Structured Compression: A pipeline stage that filters noise and restructures dialogue into compact, indexed memory units. "Semantic Structured Compression filters redundant interaction content and reformulates raw dialogue into compact, context-independent memory units."
- Sliding window: Overlapping fixed-length spans of recent interaction used for evaluating information density. "incoming dialogue is segmented into overlapping sliding windows of fixed length"
- Sparse representation: A keyword-oriented vector form emphasizing exact matches in the lexical index. "The Lexical Layer generates a sparse representation focusing on exact keyword matches and proper nouns"
- Symbolic Layer: Metadata-based indexing (e.g., timestamps, entity types) enabling hard-filter constraints. "Third, the Symbolic Layer extracts structured metadata, such as timestamps and entity types, to enable deterministic filtering logic."
- Temporal anchoring: Normalizing relative time expressions to absolute timestamps for context-independent memory. "a temporal anchoring module ($\Phi_{\text{time}$)"
- Temporal proximity: A bias that groups events occurring close in time during consolidation. "biases the model toward grouping events with strong temporal proximity."
- Token consumption: The number of tokens used during retrieval and inference, a key efficiency metric. "reducing inference token consumption by 30×"
- Virtual context methods: Approaches that extend interaction length via paging/streaming while storing raw logs. "Virtual context methods, including MemGPT \cite{Packer2023MemGPTTL}, MemoryOS \cite{memoryos}, and SCM \cite{wang2023enhancing}, extend interaction length via paging or stream-based controllers"
Collections
Sign up for free to add this paper to one or more collections.