General Agentic Memory Via Deep Research
Abstract: Memory is critical for AI agents, yet the widely-adopted static memory, aiming to create readily available memory in advance, is inevitably subject to severe information loss. To address this limitation, we propose a novel framework called \textbf{general agentic memory (GAM)}. GAM follows the principle of "\textbf{just-in time (JIT) compilation}" where it focuses on creating optimized contexts for its client at runtime while keeping only simple but useful memory during the offline stage. To this end, GAM employs a duo-design with the following components. 1) \textbf{Memorizer}, which highlights key historical information using a lightweight memory, while maintaining complete historical information within a universal page-store. 2) \textbf{Researcher}, which retrieves and integrates useful information from the page-store for its online request guided by the pre-constructed memory. This design allows GAM to effectively leverage the agentic capabilities and test-time scalability of frontier LLMs, while also facilitating end-to-end performance optimization through reinforcement learning. In our experimental study, we demonstrate that GAM achieves substantial improvement on various memory-grounded task completion scenarios against existing memory systems.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “General Agentic Memory (GAM) via Deep Research”
What this paper is about
This paper introduces a new way for AI assistants (like smart chatbots) to remember and use information called General Agentic Memory, or GAM. The big idea: instead of trying to pack everything into memory ahead of time (which loses details), the AI keeps a full “library” of what happened and builds the exact context it needs on the spot, right when a question arrives.
Think of it like this:
- Old approach: Pre-pack a tiny backpack with notes from your whole school year. It’s small and fast, but you’ll miss details when a tricky question shows up.
- GAM: Keep a clean, organized home library of everything, plus a small guide of highlights. When you need to answer something, you quickly research the library using the guide to gather the right pages.
What questions the paper tries to answer
The researchers focus on three simple questions:
- Does GAM beat other memory systems at helping AI complete tasks?
- Does GAM stay strong across different types of problems and very long inputs?
- Which parts of GAM matter most, and how can we make it work even better?
How GAM works (in everyday language)
GAM uses two teamwork roles inside the AI:
- The “Memorizer” (offline, when nothing urgent is happening):
- It writes short “memos” that summarize key points from each session or step in the AI’s work.
- It also saves a full record of everything in “pages” inside a big “page-store” (like a searchable library). Each page has a helpful header (like a title and context) so it’s easy to find later.
- Result: a small stack of memos for quick guidance, plus a complete library with no information loss.
- The “Researcher” (online, when a new question arrives):
- It plans what to look for using the memos as a guide.
- It searches the page-store with different tools:
- “Embedding” search: finds similar meanings (like “find pages about coaches” even if the word “trainer” was used).
- “BM25” keyword search: finds exact words.
- “Page-ID” lookup: directly opens specific pages.
- It integrates what it finds into a clear summary for the client AI to use.
- It reflects: “Do I have enough info to answer?” If not, it plans another round and searches again. This loop continues a few times if needed.
This “just-in-time” (JIT) process is like cooking a fresh meal when you order: you get exactly what you need, prepared for your request, instead of reheating a generic dish.
Finally, GAM improves itself with reinforcement learning (RL). That means it practices: when it helps produce better answers, it gets a higher “reward,” and it adjusts its behavior to do more of what works.
What the experiments show and why it matters
The researchers tested GAM on several tough benchmarks where AI needs to handle long conversations and long documents, sometimes with multi-step reasoning:
- LoCoMo: remembers details across many chat sessions.
- HotpotQA: answers questions that require collecting facts from multiple places.
- RULER: tests long-context understanding, retrieval, and multi-step tracing.
- NarrativeQA: answers questions about entire books or movie scripts.
Key takeaways:
- GAM consistently beat both:
- “Long-LLM” methods that try to read everything at once, and
- Memory systems that compress everything ahead of time.
- GAM was especially strong on tasks that need multi-step searching and reasoning, not just simple lookups.
- Simply giving a model a huge context window isn’t enough—too much irrelevant text can confuse it. GAM avoids this by building a focused, tailored context at the moment of need.
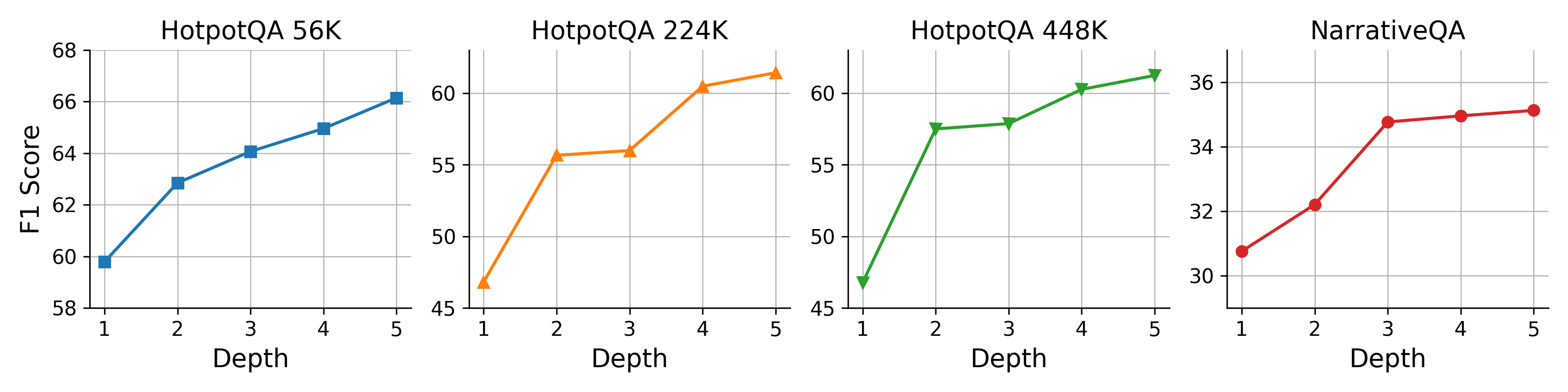
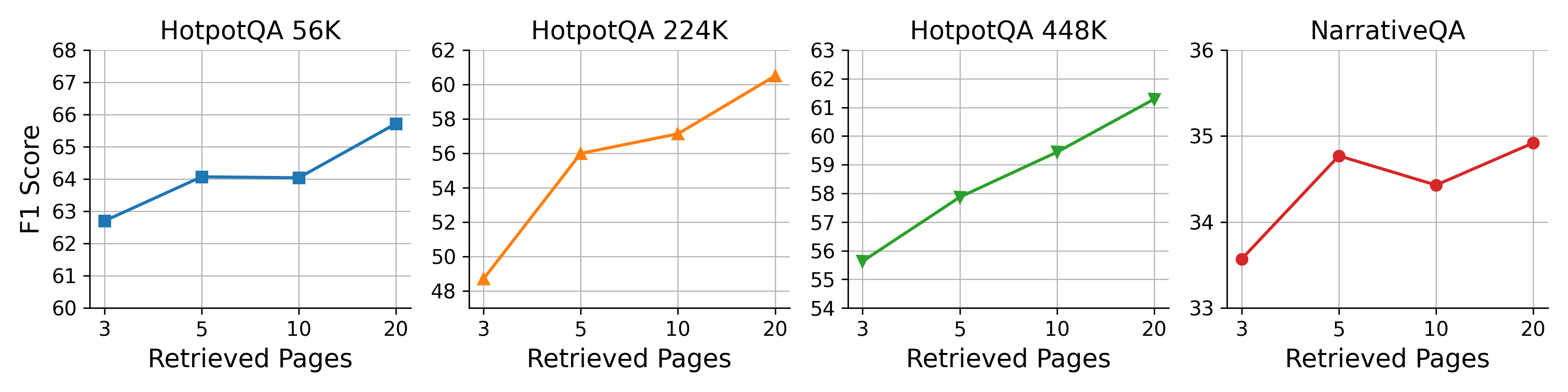
- Doing “more thinking at test time” helps: allowing more reflection steps or retrieving more pages improves accuracy, though returns eventually level off.
- Bigger and better models improve GAM, especially for the Researcher role (planning, searching, reflecting is hard). The Memorizer can be smaller without hurting results too much.
- Using multiple search tools together works better than any single tool alone.
- The combo of both modules (Memorizer + Researcher) is crucial. Using only memory or only search works worse than using both.
- Adding supporting source snippets or pages alongside the final summary can help the client AI keep fine details.
Why this matters: GAM shows a practical way to avoid “information loss” while still being efficient. It makes AI assistants more reliable on long, complex tasks where details matter.
What this could mean in the real world
If widely used, GAM could help AI assistants:
- Handle long-term projects without forgetting important details.
- Answer complex questions by fetching and combining the right info on demand.
- Be more adaptable across many domains (customer support, coding, research, education) without needing hand-crafted rules for each area.
- Improve over time as models get stronger or as we allow more “thinking time” per question.
In short, GAM is a promising blueprint for AI memory: keep everything, keep it organized, and research deeply only when needed. This “just-in-time memory” could become a foundation for smarter, more dependable AI agents.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased so that future researchers can act on it.
- Formalization gap: the memory objective is stated as with , but the agent performance functional and constraints (e.g., cost budget, latency, failure probability) are unspecified; provide a precise formal utility/cost function and theoretical bounds on fidelity and optimality.
- Reward function opacity: the RL reward is not defined per dataset/task (e.g., exact F1/Acc mapping, penalties for verbosity/latency); specify and compare reward designs (task-specific, composite, sparse vs. dense) and their impact on training stability and sample efficiency.
- RL verification missing: although policy gradients for memorizer/researcher are described, experiments do not demonstrate gains from RL versus SFT/no-training baselines; include training curves, ablations (with/without RL), and report episodes, compute, sample efficiency, and convergence behavior.
- Credit assignment across modules: how rewards are attributed to memorizer versus researcher is unclear; evaluate alternative credit assignment strategies (e.g., counterfactual baselines, hierarchical RL, variance reduction techniques) and their effect on end-to-end performance.
- Termination criterion for reflection: the binary indicator for stopping deep research is heuristic and uncalibrated; develop and test principled stopping criteria (e.g., confidence estimation, answerability checks, budget-aware meta-control) and analyze failure/over-search modes.
- Test-time compute allocation: reflection depth and pages-per-iteration are fixed hyperparameters; design adaptive policies that dynamically allocate compute based on uncertainty and marginal utility, and quantify trade-offs between accuracy and latency/cost.
- Page-store scalability: maintaining “complete history” is assumed feasible but untested at real-world scales; analyze storage growth, indexing strategies, deduplication, compaction, and eviction policies and their impact on retrieval accuracy, latency, and cost over months-long agent trajectories.
- Chunking and header construction: page segmentation is fixed at 2,048 tokens and header generation is not studied; perform systematic analyses of chunk size, overlap, header content/length, and landmark-style retrieval on recall/precision, latency, and memory footprint.
- Toolset limitations: researcher tools are restricted to dense embeddings, BM25, and page-id retrieval; evaluate integrating structured retrievers (knowledge graphs, temporal databases), web search, code repositories, and multimodal retrieval, plus tool-selection learning under varying tasks.
- Robustness to concept drift: the system does not address evolving knowledge, conflicting updates, or drift; study memory revision strategies (versioning, provenance tracking, conflict resolution) and their effects on temporal reasoning and long-horizon reliability.
- Safety and prompt-injection risks: retrieving full pages introduces the risk of prompt injection and adversarial content in the optimized context; design and evaluate safety layers (instruction sanitization, meta-verification, content filters, provenance checks).
- Privacy, security, and governance: storing complete user histories raises privacy concerns; define access controls, encryption, retention policies, GDPR/CCPA compliance, and evaluate their overhead and impact on retrieval effectiveness.
- Generalization breadth: evaluation is limited to text QA and conversational memory; test GAM on more diverse agentic tasks (tool use, coding, web navigation, scientific workflows, TAU-Bench, GAIA) and multimodal inputs (images, audio, video).
- Baseline coverage: comparisons exclude state-of-the-art deep research agents (e.g., WebThinker, DeepResearcher, Search-R1) and advanced memory agents (MemGPT, MemoryBank, Zep); add these baselines to isolate gains from the GAM architecture versus more competitive systems.
- Cross-lingual and domain robustness: BGE-M3 and BM25 settings are English-centric; evaluate cross-lingual retrieval/memory, domain-specific jargon, noisy OCR text, and low-resource languages.
- Client–memory co-training: the client is excluded from learning; investigate joint or alternating optimization of client prompting strategies with memory generation to improve end-task utility and reduce context rot.
- Failure analyses: the paper lacks systematic error taxonomies (missed retrievals, hallucinated integrations, wrong temporal linking); produce fine-grained failure analyses and targeted interventions.
- Integration fidelity: while “integration with pages/extractions” improves scores, the fidelity-loss mechanisms during integration are not quantified; measure information loss and design structured integration formats (graphs, tables, citations) to preserve fine-grained facts.
- Cost accounting: efficiency analysis reports time but not token usage, API calls, or dollar cost per query; add comprehensive cost breakdowns (offline/online tokens, calls, GPU-hours) and cost–quality curves versus baselines.
- Resource constraints: experiments use 128K-context LLMs; study GAM under smaller context budgets (e.g., 32K/8K) and with ultra-long models (e.g., LongBench v2, 1M context), to map performance–context window trade-offs.
- Parameter sensitivity: limited ablations on reflection depth/pages; provide broader sensitivity analyses (temperature, tool weights, re-ranking strategies, memo density/structure) and recommend robust defaults.
- Memo quality metrics: memorizer output is not evaluated directly; design memo-level metrics (coverage, specificity, correctness, redundancy) and correlate them with downstream performance to guide memorizer improvements.
- Provenance and citation: integration outputs lack standardized citations to supporting pages/snippets; enforce and evaluate provenance-aware outputs (inline citations, confidence) to enable auditing and trust.
- Concurrency and multi-tenancy: the paper assumes a single client and page-store; explore concurrent clients, shared vs. private stores, and conflict management in multi-agent settings.
- Eviction/forgetting policies: no strategy is provided for forgetting sensitive/obsolete content while retaining task-critical history; design and test selective forgetting, age-based decay, and task-aware retention.
- Theoretical guarantees: claims that “lossless memory can be realized via searching complete history” are not formalized; provide theoretical analyses or empirical upper bounds on recall/precision under practical indexing and search constraints.
- Reproducibility details: prompts are said to be in the appendix, but training seeds, hyperparameters, and RL configurations are not fully specified; add detailed reproducibility artifacts (configs, scripts, logs) and report variance over multiple seeds.
- Distribution shift and contamination: evaluate susceptibility to benchmark contamination and performance under adversarial distractors beyond HotpotQA setups; include controlled contamination checks and stress tests.
- Adaptive page selection vs. fixed top-k: retrieval uses fixed k; test re-ranking, diversity-promoting selection, and budget-aware adaptive k to reduce redundancy and improve coverage.
- Memory structure alternatives: GAM uses “pages + memos”; compare against structured memory representations (temporal knowledge graphs, entity/event stores) and hybrid designs for improved temporal and relational reasoning.
- Long-horizon evaluation: LoCoMo provides multi-session tests but short real-time horizons; establish evaluations over weeks/months of agent operation (e.g., LongMemEval), measuring drift, accumulation, and maintenance overhead.
Glossary
- Ablation studies: controlled experiments that remove or vary components to assess their impact on performance. "We perform ablation studies to analyze other detailed influential factors"
- Ahead-of-Time (AOT) Compilation: precomputing or preparing resources before runtime to serve requests directly from pre-built artifacts. "Most existing memory systems follow the principle of Ahead-of-Time (AOT) Compilation."
- Agentic capabilities: abilities of LLM-based agents to plan, act, and adapt autonomously in complex tasks. "This design allows GAM to effectively leverage the agentic capabilities and test-time scalability of frontier LLMs, while also facilitating end-to-end performance optimization through reinforcement learning."
- Aggregation (AGG.): evaluating the ability to combine information from multiple sources to answer queries. "including retrieval (Retri.), multi-hop tracing (MT), aggregation (AGG.), and question answering (QA)."
- Anthropic contextual retrieval: a retrieval approach that enhances query understanding by leveraging context, improving retrieval accuracy. "This process shares the same principle of BGE landmark retrieval and Anthropic contextual retrieval, which preserve the consistency of page semantics, ensuring that they can be accurately retrieved in subsequent stages."
- BGE landmark retrieval: a retrieval method that uses “landmarks” to preserve semantic coherence across chunks for long-context LLMs. "This process shares the same principle of BGE landmark retrieval~\cite{luo2024landmark} and Anthropic contextual retrieval~\cite{anthropic2023context}"
- BM25 retriever: a classic term-frequency-based ranking function used for keyword search. "an embedding model for vector search, a BM25 retriever for keyword-based search, and an ID-based retriever for direct page exploration."
- Chain-of-thought reasoning: explicit step-by-step reasoning used by LLMs to plan and solve tasks. "Planning, which performs a chain-of-thought reasoning based on the existing memory to analyze the underlying information needed by request ()."
- Context rot: degradation in model performance due to large amounts of distracting or irrelevant information in long contexts. "This also aligns with the recently discussed phenomenon of context rot"
- Context window overflow: exceeding the maximum token capacity that a model can process at once. "The rapidly growing history leads to several crucial challenges, including prohibitive computational costs, context window overflow, and performance degradation."
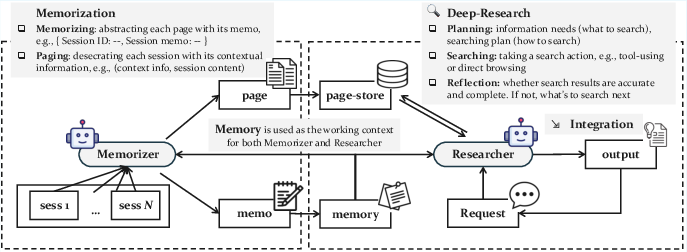
- Deep research: iterative, multi-step search and reasoning over large information spaces to construct tailored contexts at runtime. "At runtime, it performs intensive computation, namely deep research, to generate a customized, high-utility context for its request based on the pre-constructed memory."
- Dense retriever: a retrieval model that uses vector embeddings (dense representations) to find semantically similar documents. "We use BGE-M3~\cite{chen2024bge} as the default dense retriever."
- Domain generalizability: the capability of a system to work effectively across different domains without specialized tuning. "2) Domain generalizability, allowing GAM to operate effectively across general scenarios without relying on domain-specific expertise or handcrafted heuristics."
- End-to-end performance optimization: optimizing the entire system workflow jointly to maximize outcome quality. "A unified end-to-end performance optimization framework is introduced for GAM."
- General Agentic Memory (GAM): a JIT-style memory framework combining a Memorizer and a Researcher to build optimized contexts at runtime. "With this insight, we propose General Agentic Memory (GAM), a novel memory framework for general AI agents following the principle of Just-in-Time (JIT) Compilation."
- Header: contextual preamble added to a session to ensure coherent retrieval and interpretation. "It begins by generating a header for the new session, which contains crucial contextual information from its preceding trajectory."
- High-fidelity and task-adaptability: producing concise memory that preserves detail and adapts to downstream task needs. "1) High-fidelity and task-adaptability, enabling the generation of concise yet highly informative memory tailored to downstream tasks."
- HotpotQA: a multi-hop question answering benchmark over Wikipedia requiring information synthesis across documents. "We jointly leverage the traditional memory benchmark LoCoMo~\cite{locomo}, together with popular long-context benchmarks such as HotpotQA~\cite{memagent}, RULER~\cite{ruler}, and NarrativeQA~\cite{kovcisky2018narrativeqa}."
- ID-based retriever: a tool that fetches documents directly via identifier lookup rather than semantic matching. "an embedding model for vector search, a BM25 retriever for keyword-based search, and an ID-based retriever for direct page exploration."
- Integration result: the synthesized information produced by combining retrieved content to satisfy a request. "The researcher then integrates the information from the union of the retrieved pages together with the last integration result () for the request (), leading to an updated temporal integration result"
- Just-in-Time (JIT) Compilation: creating and optimizing memory or context at runtime to meet current task needs. "a novel memory framework for general AI agents following the principle of Just-in-Time (JIT) Compilation."
- LoCoMo: a benchmark for evaluating long-term conversational memory and recall in multi-session dialogues. "LoCoMo~\cite{locomo}. A widely used memory benchmark for conversational settings, designed to evaluate an agent’s ability to maintain and recall information across extended multi-session dialogues."
- long-LLM baseline: a baseline that attempts to process the entire input within a long-context LLM’s window. "The long-LLM baseline attempts to process the entire input within the model’s context window."
- Memo: a concise, structured snapshot summarizing a session’s key information for incremental memory. "Memorizing, which produces memo () as a concise and well-structured snapshot of the new session."
- Memorizer: the module that compresses key information and builds pages to store complete history offline. "The Memorizer receives the client's streaming history as a sequence of sessions"
- Multi-hop tracing (MT): tasks requiring tracking and reasoning across multiple steps or documents. "GAM achieves over 90% accuracy on the multi-hop tracing (MT) tasks in the RULER benchmark"
- NarrativeQA: a long-context QA benchmark using entire books or scripts as input. "NarrativeQA~\cite{kovcisky2018narrativeqa}. A long-context question answering benchmark that provides an entire book or movie script as the input context for each sample."
- Optimizability: potential for a system to improve performance via scaling and learning, including RL. "3) Optimizability, harnessing advanced LLMs’ agentic capability and test-time scalability for performance optimization, while also facilitating continual improvement through reinforcement learning."
- Page-store: the database of all historical pages preserving complete information for lossless retrieval. "and save all pages into a page-store, ensuring that the historical information is coherently and inclusively preserved."
- Paging: the process of creating a page by decorating a session with a header and storing it. "Paging, which creates pages to maintain the complete information of the agent’s trajectory."
- Policy gradients: a reinforcement learning method that optimizes a policy by ascending the gradient of expected rewards. "Without loss of generality, the policy gradients for the memorizer and researcher are given by"
- Researcher: the module that plans, searches, integrates, and reflects to construct an optimized context online. "The Researcher receives an online request from its client and performs deep research based on the pre-constructed memory to address the client’s needs."
- Retrieval-augmented generation (RAG): generating answers by retrieving relevant documents and conditioning generation on them. "Memory-free methods, including the brute-force long-LLM (long-LLM for brevity) and retrieval-augmented generation (RAG)."
- Reinforcement learning: a learning paradigm where agents optimize actions based on reward feedback. "while also facilitating end-to-end performance optimization through reinforcement learning."
- RULER: a long-context understanding benchmark evaluating retrieval, multi-hop tracing, aggregation, and QA. "RULER~\cite{ruler}. A popular long-context understanding benchmark with four types of evaluation tasks, including retrieval (Retri.), multi-hop tracing (MT), aggregation (AGG.), and question answering (QA)."
- Temporal-reasoning: tasks that require understanding and reasoning about time-dependent information. "We adopt its single-hop, multi-hop, temporal-reasoning, and open-domain tasks in our experiments."
- Test-time scalability: the ability to increase computation at inference to improve performance (e.g., deeper search/reflection). "agentic capabilities and test-time scalability of frontier LLMs"
- Test-time scaling: improving results by allocating more computation during inference (e.g., more reflections or retrieved pages). "which demonstrates GAM’s ability to benefit from test-time scaling, an advantage that baseline methods lack due to their fixed workflows."
- Vector search: retrieving documents by comparing dense embedding vectors for semantic similarity. "an embedding model for vector search"
Practical Applications
Overview
The paper proposes General Agentic Memory (GAM), a dual-agent framework that replaces static, ahead-of-time (AOT) memory with just-in-time (JIT) “deep research” over a complete, paged store of history. GAM comprises:
- A Memorizer that creates a lightweight, structured memory while storing full session content in a page-store with contextual headers.
- A Researcher that plans, searches (embedding, BM25, ID-based), integrates, and reflects iteratively to generate optimized task-specific context at runtime.
Experiments show GAM consistently outperforms both memory-free (long-context LLM, RAG) and AOT-style memory systems across LoCoMo, HotpotQA, RULER, and NarrativeQA, with competitive efficiency and strong test-time scaling (deeper reflection, more retrieved pages).
Below are practical, real-world applications derived from the paper’s findings and design, grouped by deployment horizon and linked to sectors. Each item includes potential tools/workflows and feasibility notes.
Immediate Applications
These applications can be deployed now using GAM’s public repo, existing LLMs (e.g., GPT-4o-mini, Qwen2.5), and standard retrieval tools (BGE-M3, BM25, vector DBs).
- Software engineering (DevTools)
- Use case: Repository-scale assistant for multi-hop code questions, issue triaging, and design decision retrieval across long project histories.
- Product/workflow: “GAM Memory Layer” for IDEs and code review tools; offline page-store built from commits, PRs, issues; Researcher plans queries and searches by file/commit IDs plus embeddings; returns integrated context + source snippets.
- Dependencies/assumptions: High-quality code parsing into pages with consistent headers; access to repo metadata; LLM with sufficient reasoning capacity; latency budget for reflection loops.
- Customer support & CRM
- Use case: Long-term conversational memory for customer histories; just-in-time retrieval of relevant tickets, resolutions, and policies; reduce “context rot” in long threads.
- Product/workflow: CRM copilot with GAM-backed ticket page-store; research over account IDs, product versions, and policy documents; integration yields tailored guidance with citations.
- Dependencies/assumptions: PII governance and consent; standardized ticket schemas; vector DB + BM25 hybrid search; compute budgets to support peak traffic.
- Legal (document review and compliance)
- Use case: Clause discovery across contract corpora; multi-hop retrieval over amendments and side letters; audit trail generation.
- Product/workflow: GAM-augmented eDiscovery tool; paging of contracts with headers capturing parties, dates, jurisdictions; Researcher’s “integration with extraction” returns answers + snippets for verification.
- Dependencies/assumptions: Accurate page segmentation and header enrichment; controlled vocabularies for BM25; confidentiality controls; lawyer-in-the-loop.
- Finance (equity research and audit)
- Use case: Analyst assistant for multi-hop due diligence across filings, transcripts, and news, avoiding context window overflow.
- Product/workflow: Page-store of SEC 10-K/10-Q, earnings calls; researcher plans multi-step tracing (e.g., track KPI definitions and changes); provides integrated notes with cited sources.
- Dependencies/assumptions: Timely ingestion pipelines; domain-tuned retrieval; governance for MNPI; measurable latency/SLA management.
- Academia (literature review and grant preparation)
- Use case: Deep research across long PDFs and notes; multi-hop question answering over large corpora; reliable source-linked summaries.
- Product/workflow: GAM plugin for reference managers (e.g., Zotero) to page PDFs (2,048-token segments with contextual headers); researcher config with reflection depth based on task complexity; export integrated context + citations.
- Dependencies/assumptions: Robust PDF parsing, OCR; legal access to content; tuning retrieval tools for academic corpora.
- Education (personal tutoring and LMS memory)
- Use case: Personalized tutor that retains structured session memory and retrieves past explanations/assessments just-in-time.
- Product/workflow: LMS plugin maintaining student page-store of lessons, assignments, feedback; researcher plans queries by topic, date, and assessment results; integrates tips + past examples.
- Dependencies/assumptions: Student privacy; consistent curriculum metadata; controlled compute costs for large classes.
- Enterprise knowledge management
- Use case: “Context OS” for internal documents and meeting logs; memory that withstands long histories and distractions.
- Product/workflow: GAM service for document systems and meeting platforms; page-store per team/project; researcher reflects to refine information needs and deliver targeted briefs with sources.
- Dependencies/assumptions: Connectors to DMS/meeting tools; access controls; hybrid search (embedding + BM25 + artifact IDs).
- Daily life (personal PKM and inbox/meeting assistants)
- Use case: Just-in-time recall over email threads, notes, calendars; summarize prior decisions and action items.
- Product/workflow: Local or cloud GAM integrated with note apps; page-store with headers for dates, participants, tags; researcher produces compact context + links.
- Dependencies/assumptions: Privacy and consent; on-device or secure cloud; model selection to fit battery/latency constraints.
- Media and publishing
- Use case: Editorial assistant answering questions over long manuscripts or script archives (NarrativeQA-style).
- Product/workflow: Page-store of manuscripts; researcher retrieves scenes/chapters and integrates plot facts; outputs with citations or extracted snippets.
- Dependencies/assumptions: Rights management; stable document structures; adequate LLM reasoning capacity.
- Agent frameworks (tool-using AI)
- Use case: Drop-in replacement for static memory in multi-agent systems, enabling deep research with test-time scaling.
- Product/workflow: GAM SDK integration; use of reflection depth and retrieved page limits as tunable knobs; reinforcement learning hooks to optimize memory/research policies per task.
- Dependencies/assumptions: Orchestration compatibility (e.g., LangChain, OpenAI Assistants, custom stacks); observability for research loops; guardrails for cost.
Long-Term Applications
These applications benefit from further research, scaling, domain-specific tuning, or regulatory maturity. They often require multimodal extensions, safety validation, and reinforcement learning optimization.
- Healthcare (clinical decision support)
- Use case: Longitudinal patient memory with JIT retrieval for clinical questions spanning labs, notes, imaging, and medications.
- Product/workflow: Multimodal page-store (text + structured data + images); researcher plans cross-visit reasoning; outputs clinical summaries with source trails.
- Dependencies/assumptions: Regulatory approval (HIPAA, GDPR), medical-grade LLMs, rigorous evaluation for safety/bias, integration with EHR vendors; extensive domain RL (e.g., Memory-R1-style).
- Robotics (long-horizon task memory)
- Use case: Household/industrial robots retrieving past sensor logs, tasks, and failures to plan current actions.
- Product/workflow: Multimodal page-store (vision, audio, proprioception) with contextual headers; researcher plans across time; integrates instructions and prior attempts.
- Dependencies/assumptions: Robust multimodal modeling, real-time constraints, safety guarantees, simulation-to-real transfer.
- Autonomous software maintenance
- Use case: Agents that reason over large codebases to propose patches, migrations, and refactors using GAM’s deep research.
- Product/workflow: Page-store of code, test results, deployment incidents; researcher traces dependencies; suggests changes with evidence.
- Dependencies/assumptions: Tool execution integration (build/test CI), strong code LLMs, human review loops, rollback safety.
- Enterprise-wide “Memory OS”
- Use case: Organization-scale memory fabric spanning teams and systems; unified JIT context for every agent and employee.
- Product/workflow: Managed GAM services with connectors (ERP, CRM, CMS, BI); role-based access, auditing; test-time scaling based on task criticality.
- Dependencies/assumptions: Data governance at scale, schema alignment, lineage tracking, cross-domain retrieval tuning, budget-aware orchestration.
- Government/policy (legislative analysis and drafting)
- Use case: Deep research over bills, amendments, case law, and historical debates to inform drafting and oversight.
- Product/workflow: Page-store with jurisdictional headers; conflict-aware meta-verification (e.g., future integration with Co-Sight-like modules) to check consistency; outputs with transparent citations.
- Dependencies/assumptions: High-quality digitization; verifiable reasoning; public record access; accountability frameworks.
- Energy and critical infrastructure (operations memory)
- Use case: Operators retrieve incidents, maintenance logs, and telemetry history to support risk assessment and incident response.
- Product/workflow: Multimodal page-store for logs + time series; researcher performs multi-hop tracing over incidents (RULER-style MT and AGG tasks).
- Dependencies/assumptions: Real-time integration, fail-safe design, domain RL for reliability, certified audit trails.
- Education (lifelong learner record and pathway planning)
- Use case: Cross-institution learner memory supporting personalized curricula and skill tracing over years.
- Product/workflow: Federated page-stores across schools and platforms; researcher plans JIT pathways; outputs with provenance.
- Dependencies/assumptions: Interoperability standards, privacy-preserving federation, fairness audits.
- Scientific discovery agents
- Use case: End-to-end deep research agents that iteratively form hypotheses, retrieve literature/data, and produce reproducible outputs.
- Product/workflow: RL-trained GAM policies (e.g., Search-R1, DeepResearcher) with domain rewards; integration with data repositories and lab notebooks; source-linked findings.
- Dependencies/assumptions: Reliable evaluation benchmarks, domain-specific toolkits, reproducibility infrastructure, expert oversight.
- Compliance and continuous audit
- Use case: Continuous monitoring of controls and changes across policies, logs, and communications, with verifiable evidence.
- Product/workflow: Compliance page-store; researcher with meta-verification; outputs combining integrated analysis with extracted source snippets.
- Dependencies/assumptions: Legal/regulatory alignment, strong correctness guarantees, red-team testing for adversarial inputs.
- Personal knowledge cloud (privacy-first PKM)
- Use case: Cross-app memory that can operate on-device to retrieve notes, documents, and activities, generating JIT contexts.
- Product/workflow: Lightweight GAM with small LLMs for the memorizer and stronger cloud/on-device models for researcher; adaptive reflection depth under battery/SLA constraints.
- Dependencies/assumptions: Efficient models (edge-capable), federated learning for personalization, robust local storage and encryption.
Notes on Cross-Cutting Assumptions and Dependencies
- Model capacity: The researcher is more sensitive to LLM scale than the memorizer; smaller backbones degrade deep research quality.
- Retrieval quality: Best performance arises from combining embedding, BM25, and ID-based retrieval; page header quality is crucial.
- Latency and cost: Reflection depth and number of retrieved pages improve performance but increase serving time; configure per SLA.
- Data policy and privacy: Page-stores often contain sensitive history; enforce access controls, encryption, and consent.
- Evaluation and safety: For high-stakes domains (healthcare, energy, policy), require domain-specific benchmarks, human oversight, and auditability.
- Integration effort: Success depends on reliable ingestion (paging, headers), connectors to existing systems, and schema consistency.
- Reinforcement learning: End-to-end optimization via rewards can yield gains but needs careful design, compute, and safety constraints.
Collections
Sign up for free to add this paper to one or more collections.