Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability
Abstract: Can a model learn to escape its own learning plateau? Reinforcement learning methods for finetuning large reasoning models stall on datasets with low initial success rates, and thus little training signal. We investigate a fundamental question: Can a pretrained LLM leverage latent knowledge to generate an automated curriculum for problems it cannot solve? To explore this, we design SOAR: A self-improvement framework designed to surface these pedagogical signals through meta-RL. A teacher copy of the model proposes synthetic problems for a student copy, and is rewarded with its improvement on a small subset of hard problems. Critically, SOAR grounds the curriculum in measured student progress rather than intrinsic proxy rewards. Our study on the hardest subsets of mathematical benchmarks (0/128 success) reveals three core findings. First, we show that it is possible to realize bi-level meta-RL that unlocks learning under sparse, binary rewards by sharpening a latent capacity of pretrained models to generate useful stepping stones. Second, grounded rewards outperform intrinsic reward schemes used in prior LLM self-play, reliably avoiding the instability and diversity collapse modes they typically exhibit. Third, analyzing the generated questions reveals that structural quality and well-posedness are more critical for learning progress than solution correctness. Our results suggest that the ability to generate useful stepping stones does not require the preexisting ability to actually solve the hard problems, paving a principled path to escape reasoning plateaus without additional curated data.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big question: can an AI model that gets “stuck” on hard problems figure out how to teach itself to get better? The authors build a system called SOAR that helps a model create its own practice problems (a learning “curriculum”) so it can improve on tough math questions it couldn’t solve before.
Key Objectives
The paper focuses on three main goals, explained simply:
- Can a model use its hidden knowledge to make useful practice problems for itself, even when it can’t solve the hardest questions?
- Is it better to reward the model based on real progress on the tough questions (grounded rewards) rather than “made-up” points (intrinsic rewards) like “this looks learnable”?
- What matters most in these self-generated practice problems: having the exact correct answer, or having clear, well-structured questions that build the right skills?
How They Did It (Methods in Everyday Terms)
Think of this like a student-athlete and a coach who are actually the same person at different times:
- There are two copies of the same AI model:
- The “teacher” model makes new practice problems with answers.
- The “student” model tries to solve those practice problems and learns from them.
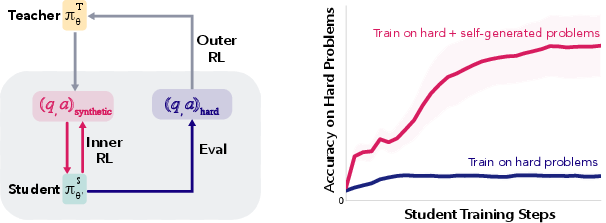
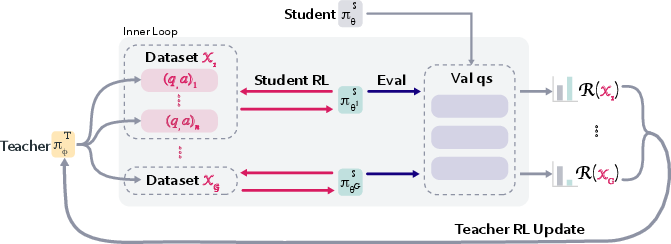
- The teacher gets points only when the student actually improves on a small set of real, very hard math problems. This is called grounded rewards: the teacher’s success is measured by real student progress, not by guesswork.
- The student trains for a short time on the teacher’s practice problems. If the student’s performance improves enough, the system “promotes” the student—making this improved version the new baseline—and keeps the practice problems that helped. The paper calls these Promotion Questions (PQ).
- This setup is like a loop:
- Outer loop: the teacher picks practice problems and gets rewarded based on how much those problems help the student improve on the real hard questions.
- Inner loop: the student trains briefly on those practice problems and then is tested on the hard questions to see if it improved.
- Important details:
- The hard questions are extremely tough—at the start, the model fails all of them in 128 attempts (they call this fail@128).
- The teacher never sees the hard questions directly. It only sees how much the student got better.
- The team tested this on math benchmarks: MATH, HARP, and OlympiadBench, using the Llama-3.2-3B-Instruct model.
Main Findings and Why They Matter
Here are the key findings, explained in simple terms:
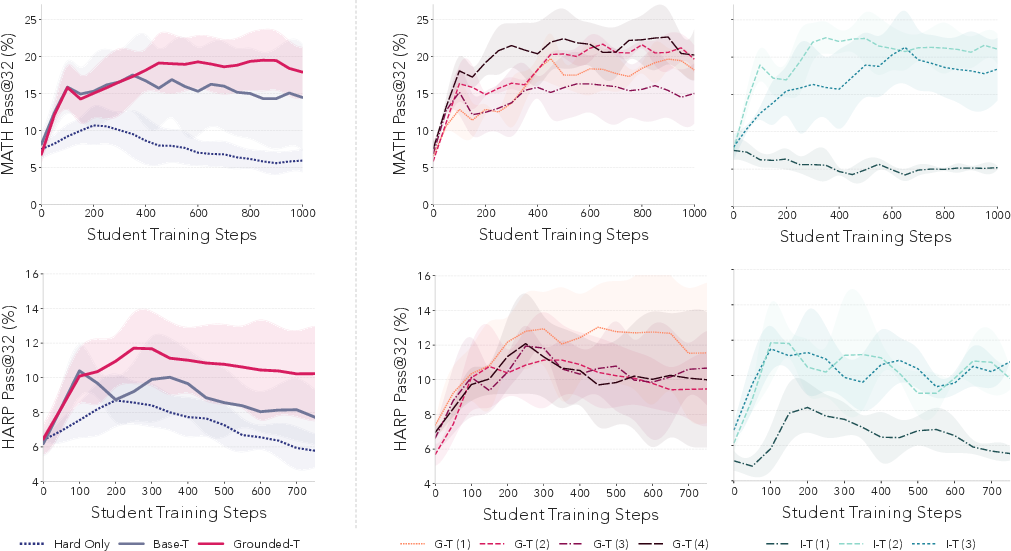
- The model can teach itself by making “stepping-stone” practice problems:
- Even when the model can’t solve the hardest questions, it can still create easier, related problems that help it learn the needed skills.
- This kicked the student out of its “learning plateau” (where it wasn’t improving), leading to clear gains on those tough math sets.
- Real progress beats guesswork:
- Rewarding the teacher based on the student’s real improvement (grounded rewards) worked much better than using intrinsic rewards like “these seem learnable.”
- Systems that used intrinsic rewards tended to be unstable or got stuck making narrow or unhelpful problems, sometimes causing performance to collapse.
- Structure matters more than perfect answers:
- Many of the generated practice problems did not have perfectly correct solutions.
- But if problems were well-posed (clear, coherent, correctly structured) and built the right concepts, they still helped the model learn.
- In other words, good practice problems don’t need to be perfect; they need to be useful and well designed.
- The improvements were real and transferred:
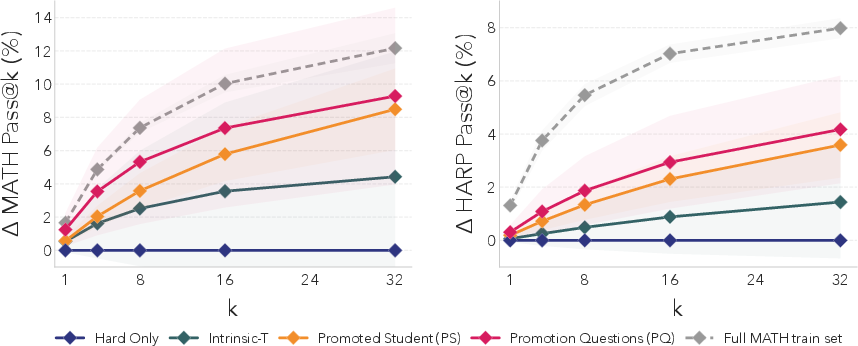
- On the hardest parts of MATH and HARP, the self-generated practice problems led to noticeable gains (for example, roughly doubling pass rates in some settings compared to training only on hard problems).
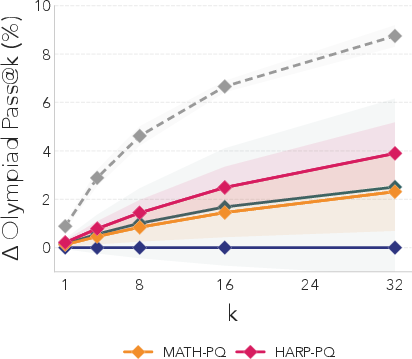
- These benefits also carried over to a different dataset (OlympiadBench), showing that the practice problems were teaching general skills, not just “cheating” for one test.
- Diversity stayed high with grounded rewards:
- The teacher that used grounded rewards kept producing a wide variety of problem types (high diversity), which is healthy for learning.
- The intrinsic-reward teachers often collapsed into making very similar problems, which hurt learning.
Implications and Potential Impact
This work suggests a practical path for improving AI reasoning without needing lots of extra human-curated training data:
- Models can escape learning plateaus by generating their own stepping-stone problems and measuring real progress, much like a smart coach designing drills based on how a player improves.
- This approach could help AI learn in areas where feedback is rare or all-or-nothing (like math proofs), making training more efficient and robust.
- It also hints at a bigger idea: even if a model can’t solve a very hard problem yet, it might still know how to build the right “ladder” of practice steps to get there.
- Limitations: this method uses more computation because it runs both the teacher and student loops. But the paper shows that simply spending extra compute training directly on hard problems doesn’t achieve the same gains—so the teacher-student setup is doing something genuinely useful.
In short, the paper shows that teaching models to teach themselves—grounded in real progress—can help them learn difficult reasoning tasks they couldn’t learn before.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Based on the paper, the following gaps remain unresolved and present concrete opportunities for future work:
- Scaling behavior: The method is only evaluated with Llama‑3.2‑3B; it is unknown how SOAR’s gains, stability, and diversity behave at larger model scales (e.g., 7B, 70B) or with different architectures.
- Domain generality: Experiments focus on math reasoning with binary rewards and no automatic verification; it remains unclear whether SOAR transfers to other symbolic domains (logic, proofs), coding with test-case verifiers, natural language reasoning, or multimodal tasks.
- Cost–benefit tradeoff: The bilevel RL loop is compute-heavy; the paper does not quantify GPU-hours/token budget versus accuracy gains, nor compare to equally costly alternatives (e.g., longer direct RLVR on hard data, or larger batch/group sizes) across a standardized budget.
- Outer/inner loop design sensitivity: Key hyperparameters (group size g, dataset size n=64, inner-loop step count=10, promotion threshold τ=0.01, number of parallel student trainings r) are heuristic; the paper lacks a systematic mapping of how these choices affect reward variance, convergence speed, and final performance.
- Reward signal robustness: The grounded teacher reward uses greedy accuracy improvement on a small, subsampled set of training questions (|Q_R|=64); it is unknown how reward set size, sampling strategy, or repeated reuse of particular questions affects overfitting, variance, and teacher policy stability.
- Convergence guarantees: There is no theoretical analysis or guarantee of convergence for the nested meta-RL loop (teacher RLOO over student RLOO), nor conditions under which the loop avoids reward hacking or collapse.
- Alternative meta-optimization: The study does not compare RLOO against other outer-loop methods (e.g., GRPO, PPO, evolutionary search, Bayesian optimization, meta-gradients) for teacher training efficiency, stability, and sample efficiency.
- Student RL algorithms: The inner loop uses RLOO exclusively; the effect of alternative RLVR methods (e.g., DAPO/GRPO variants, process reward shaping, advantage reweighting) on SOAR’s gains is not explored.
- Promotion mechanism design: The “promotion” strategy (moving-average reward threshold) is heuristic; there is no ablation on different promotion criteria, curriculum accumulation strategies, or checkpoint selection policies, nor analysis of when promotions harm/help.
- Mixing strategy optimization: The choice between curriculum-then-hard and mixed training is fixed per dataset; optimal mixing ratios, schedules, and adaptive policies are not characterized.
- Task diversity vs correctness tradeoff: The finding that structural coherence matters more than answer correctness is qualitative; the paper lacks controlled experiments that vary correctness rates while holding structural features constant (or vice versa) to quantify causal contribution to learning.
- Diversity measurement validity: Vendi Scores are computed using Qwen3 embeddings; robustness of diversity conclusions to different embedding models, distance metrics, and diversity estimators is not established.
- Structural feature taxonomy: Beyond broad categories, there is no fine-grained, model-agnostic taxonomy linking specific structural properties (e.g., subproblem decomposition, variable binding, algebraic form, step-count) to observed student gains.
- Safety of incorrect answers: Synthetic answers are often wrong; the paper does not measure negative transfer, error propagation, or cumulative harm from training on incorrect solutions, nor propose safeguards (filters, consistency checks, process supervision).
- Grounded-vs-intrinsic breadth: The intrinsic baseline uses a learnability signal; comparisons to other intrinsic objectives (self-consistency, reward-model preferences, process quality, uncertainty, entropy regularization) are missing, leaving generality of “grounded > intrinsic” claims untested.
- Hard-problem visibility: The teacher is not shown hard problems; open question: how performance changes if the teacher sees partial information (e.g., problem statements without answers), sampled substructures, or contrastive signals from the hard set.
- Reward design space: Grounded reward is binary accuracy improvement; alternative grounded signals (e.g., process-based metrics, partial credit, trajectory-level improvements, time-to-first success, calibration of difficulty) may reduce variance and compute while preserving stability.
- Sample efficiency and variance: The method averages rewards across r parallel students to stabilize training; there is no analysis of minimal r needed, variance reduction techniques (control variates, baselines), or confidence-weighted updates to improve sample efficiency.
- Overfitting checks: Although evaluated on held-out fail@128 test sets, the risk that teachers exploit idiosyncrasies of the training subset (Q_R) is not quantified (e.g., performance against disjoint hard subsets or fully OOD distributions with different style).
- OOD generalization limits: Transfer to OlympiadBench is shown, but not characterized by category (algebra/geometry/combinatorics), difficulty tier, or stylistic mismatch; generalization failure modes remain uncharted.
- Teacher–solver decoupling: The final teacher does not improve direct inference on hard problems; unexplored is whether distilling the teacher’s generative distribution (or structural priors) into the solver improves zero-shot inference.
- Teacher/student asymmetry: Both are initialized from the same base model; it is unknown whether asymmetry (e.g., larger teacher, different architecture, process-supervised teacher, tool-using teacher) yields stronger curricula.
- Curriculum size and composition: PQ sizes are small (128–256 items); the paper does not examine optimal curriculum length, concept coverage targets, or adaptive selection that maximizes marginal student improvement per item.
- Long-run stability: Training is capped at ~200 outer-loop steps; it remains unknown whether SOAR sustains gains or eventually collapses when run longer, and how to detect and prevent late-stage diversity collapse.
- Evaluation granularity: Gains are reported as pass@k improvements; there is no per-problem analysis (which hard problems become solvable), nor process-level metrics (reasoning step quality, error types reduced).
- Data contamination checks: No systematic assessment of whether synthetic questions inadvertently mirror training-corpus items or target-set content beyond “not showing hard problems”; stricter contamination controls are needed.
- Applicability to non-binary rewards: The approach targets sparse, binary correctness; effectiveness under graded rewards, partial credit, or human feedback remains unexplored.
- Integration with automatic verifiers: For domains with verifiers (e.g., coding), it is unclear whether grounded reward still outperforms intrinsic signals, or whether hybrid reward designs yield better sample efficiency.
- Robustness across seeds and runs: While 6–12 seeds are used, the variability across different random curricula, RL initializations, and sampling temperatures is not fully characterized or bounded.
- Open-source reproducibility: Details needed for end-to-end reproducibility (full code, prompts, parsing/filtering pipelines, trained checkpoints) are not provided, limiting external validation at scale.
Practical Applications
Overview
Below are practical applications that emerge from the paper’s findings and methods, grouped into immediate and long-term opportunities. Each application notes target sectors, potential tools/products/workflows, and assumptions or dependencies affecting feasibility.
Immediate Applications
- Data-free curriculum generation to kickstart RL fine-tuning on stalled domains (software; academia)
- Use SOAR’s teacher–student meta-RL loop to generate synthetic stepping-stone tasks when a model’s initial success rate on a hard dataset is near zero, enabling progress without additional curated data.
- Tools/workflows: “Grounded Self-Play” training pipeline with RLOO for inner/outer loops; promotion mechanism to update the student baseline; pass@k metrics; Vendi diversity checks.
- Assumptions/dependencies: Access to a verifiable hard evaluation set for grounding rewards; moderate compute budget for bi-level training; base model with latent domain knowledge.
- Stabilizing LLM self-play training with grounded rewards (software; academia)
- Replace intrinsic learnability/self-consistency rewards with student-progress-based grounded rewards to avoid instability and diversity collapse in synthetic data generation loops.
- Tools/workflows: Reward-backend that evaluates student improvement on a held-out hard subset; variance reduction via parallel student trainings.
- Assumptions/dependencies: Reliable measurement infrastructure; consistent evaluation metrics; careful group-size tuning to mitigate variance.
- Auto-curated stepping-stone datasets for math and formal reasoning tutors (education; daily life)
- Generate well-posed, structurally coherent practice problems that adapt to learner ability, with rewards grounded in observed student improvement (scores, time-to-solve).
- Tools/products: “Curriculum Engine” for edtech platforms; adaptive tutor integrating promotion logic; analytics layer for grounding signal (A/B testing).
- Assumptions/dependencies: Feedback loops that measure learning outcomes; human review where safety/age appropriateness matters; alignment with curricular standards.
- Bootstrapping coding assistants on sparse test or spec regimes (software)
- When unit tests or specs are insufficient, use a teacher agent to synthesize simpler, well-posed sub-problems (e.g., targeted API usage or bug-isolation tasks), rewarding teacher policies on improvements in pass rates over a hard coding benchmark.
- Tools/workflows: Synthetic test generation + grounded evaluation on a small set of verifiable hard tasks; curriculum mixing strategy (curriculum first, then hard tasks).
- Assumptions/dependencies: Some verifiable test cases for grounding; guardrails against reward hacking; domain-specific parsing and filtering of synthetic tasks.
- Internal upskilling and compliance training content generation (enterprise L&D; policy/regulated industries)
- Generate stepping-stone question sets that target known failure modes in staff assessments (e.g., policy comprehension, risk controls), grounded by improvements on a fixed, hard evaluation set.
- Tools/workflows: LMS integration; analytics to compute improvement-based rewards; content filters for legal/regulatory compliance.
- Assumptions/dependencies: High-quality, verifiable evaluation items; oversight for factual correctness and ethical constraints; data privacy.
- Benchmark augmentation and testbed construction for reasoning research (academia)
- Build hard-subset benchmarks with synthetic stepping stones to study plateau-breaking dynamics; use PQ (Promotion Questions) to probe generalization (e.g., cross-dataset transfer).
- Tools/workflows: Systematic fail@k filtering; synthetic dataset generation and diversity analysis (Vendi Score); early-stopping based on smoothed reward gradients.
- Assumptions/dependencies: Standardized evaluation protocols; compute for multiple seeds and nested loops; reproducibility infrastructure.
- Process optimization for RL teams: reallocate compute from naïve resampling to grounded meta-RL (software; academia)
- Demonstrated that more sampling on hard-only data yields limited gains relative to SOAR’s grounded meta-RL; reconfigure training budgets accordingly.
- Tools/workflows: Cost–benefit dashboards; pipeline templates for bi-level RL; promotion gating (τ) tuning.
- Assumptions/dependencies: Access to training telemetry; willingness to adopt meta-RL complexity in exchange for better returns.
Long-Term Applications
- Cross-domain autonomous curricula for complex reasoning (science/engineering; academia; software)
- Scale SOAR-like frameworks to domains beyond math (e.g., theorem proving, scientific hypothesis generation, complex design), where correctness is hard to verify but well-posed structural tasks can still provide signal.
- Tools/products: General-purpose “Curriculum-as-a-Service” platform; domain-specific teacher policies; reusable promotion/evaluation modules.
- Assumptions/dependencies: Domain-appropriate grounding signals; robust parsers/validators; larger models and compute to handle domain complexity.
- Personalized adaptive learning systems with outcome-grounded reward loops (education; daily life)
- Fully integrated AI tutors that autonomously generate stepping-stone curricula, calibrate difficulty, and update teaching policy based on measurable student progress (grades, retention, mastery profiles).
- Tools/products: Adaptive LMS; student-model telemetry; explainable task generation; difficulty calibration engines.
- Assumptions/dependencies: Reliable outcome measures; long-term privacy-preserving analytics; pedagogical QA; equitable access and fairness audits.
- Safety-conscious synthetic data generation across sensitive domains (healthcare; policy; finance)
- Use well-posed, structured synthetic cases to train clinical decision support, risk assessment, or policy reasoning systems, with rewards grounded in improvements on curated, verified evaluation datasets.
- Tools/workflows: Governance layer for quality assurance; correctness-independent training that prioritizes well-posedness and structural diversity; human-in-the-loop review for critical errors.
- Assumptions/dependencies: Regulatory approvals; high-fidelity evaluation sets; bias/safety checks; strict data governance.
- Robotics and planning: curriculum generation for sparse, binary success tasks (robotics)
- Teacher models generate structured planning sub-tasks that improve success on hard goals, grounded in simulator or real-world success rates; emphasis on well-posedness over perfect solutions.
- Tools/workflows: Simulator-integrated reward computation; hierarchical curricula; transfer learning to real systems.
- Assumptions/dependencies: Accurate simulators; metrics for grounded rewards (task completion); domain adaptation and sim-to-real pipelines.
- Energy systems diagnostics and forecasting (energy)
- Generate intermediate diagnostic scenarios (fault localization, grid stability cases) to train models stuck on sparse failures; reward grounded in improvements on hard evaluation subsets.
- Tools/workflows: Synthetic scenario generator; evaluation on historical incident subsets; difficulty calibration to avoid collapse.
- Assumptions/dependencies: Access to high-quality incident datasets; reliable outcome metrics (precision/recall under extreme conditions); compliance with infrastructure security policies.
- Finance scenario analysis and complex reasoning (finance)
- Teacher agents produce structured “what-if” stepping-stone scenarios (liquidity stress, market microstructure anomalies) to improve model performance on hard evaluation tasks like backtests or stress tests.
- Tools/workflows: Scenario generation engines; grounded reward via out-of-sample backtesting; diversity monitoring to prevent reward hacking.
- Assumptions/dependencies: Reliable backtesting frameworks; guardrails to avoid unrealistic or manipulative scenarios; compliance and audit trails.
- Platform-level “Grounded Self-Play SDK” and training orchestration services (software; academia; enterprise)
- Productize bi-level meta-RL with built-in promotion, evaluation, diversity monitoring, and safety filters; support plug-and-play integration across domains.
- Tools/products: SDK/APIs; orchestration layers for nested RL; monitoring dashboards; auto-tuning of τ, group sizes, and curriculum mixing strategies.
- Assumptions/dependencies: Broad developer adoption; integration with existing ML stacks; standardized evaluation adapters for different sectors.
Key Assumptions and Dependencies (cross-cutting)
- Grounded reward availability: Requires a small but reliable set of hard, verifiable problems or outcome metrics to measure genuine progress.
- Compute and operational complexity: Bi-level RL with parallel student trainings increases cost; however, gains can exceed those from naïve resampling on hard-only data.
- Latent knowledge in base models: Success relies on pretrained models containing enough domain knowledge to generate useful, well-posed tasks even when they cannot solve the hardest problems outright.
- Safety and correctness management: Since many synthetic answers can be incorrect, workflows should prioritize well-posedness and structural diversity, add filters for ambiguity, and include human oversight in high-stakes domains.
- Diversity preservation: Monitor conceptual diversity (e.g., via Vendi Scores) to avoid collapse; grounded rewards help maintain diversity relative to intrinsic-only setups.
- Transferability: Synthetic curricula showed promising cross-dataset transfer in math; domain transfer may require adapters, validators, and recalibration of rewards.
Glossary
- Asymmetric teacher-student: A setup where the teacher and student have different roles; the teacher generates tasks and the student learns from them. "We initialize asymmetric teacher and student models from the same base model."
- Backpropagation through time (BPTT): Gradient computation through sequential models by unrolling the computation graph over time. "which requires backpropagation through time (BPTT), unrolling the inner loop and taking meta-gradients."
- Bilevel optimization: An optimization with nested objectives where the inner solution affects the outer objective. "We formulate this problem as a bilevel optimization problem."
- Black-box reward signal: A guiding signal based only on observed outcomes, without exposing task internals. "we use the difficult training dataset as a black-box grounding reward signal to guide the teacher towards producing useful questions for the student."
- Bootstrap subsampling: A resampling method with replacement to estimate metrics and variability. "All metrics are standardized to 128 questions via bootstrap subsampling ( iterations)."
- Curriculum learning: Training that orders tasks from easy to hard to improve learning efficiency. "Inspired by methods from self-play and curriculum learning, we propose SOAR"
- Dataset distillation: Optimizing a small synthetic dataset so training on it yields strong target performance. "in dataset distillation, where an outer loop optimizes a generally small dataset that allows an inner training loop to achieve good target performance"
- Diversity collapse: A failure mode where generated outputs lose variety and converge to narrow modes. "reliably avoiding the instability and diversity collapse modes they typically exhibit."
- Fail@128: A subset of problems with zero successes out of 128 generations, used to define hard tasks. "We call these subsets fail@128 datasets."
- Greedy accuracy: Accuracy measured using the model’s single deterministic output without sampling. "best greedy accuracy"
- Greedy success: Success rate assessed on the model’s deterministic output rather than sampled outputs. "The dataset-level reward is then the average greedy success"
- Grounded rewards: Rewards based on real task performance rather than internal proxies. "Critically, SOAR grounds the curriculum in measured student progress rather than intrinsic proxy rewards."
- Hyperparameter learning: Meta-optimization of hyperparameters to improve training outcomes. "hyperparameter learning \citep{maclaurin2015hyperopt}"
- Intrinsic rewards: Self-generated or proxy signals not tied to external task outcomes. "Grounding teacher rewards in student progress on real problems improves performance over intrinsic rewards common in self-play, which are prone to instability and collapse of question diversity."
- Learnability objective: A reward that favors tasks of moderate difficulty to maximize learnability. "replace the grounded signal with a learnability objective \citep{zhao2025absolute, sukhbaatar2017asymmetric} that rewards questions of moderate difficulty."
- Meta-RL: Reinforcement learning that optimizes learning processes or policies that help other learners. "we design SOAR: A self-improvement framework designed to surface these pedagogical signals through meta-RL."
- Pass@k: The probability that at least one of k sampled outputs is correct; a common reasoning metric. "We report the pass@k accuracy on the held-out fail@128 test set for "
- Promotion mechanism: A procedure to replace the baseline student with an improved version upon sufficient progress. "we introduce a promotion mechanism to accumulate student improvement across inner loops."
- Reinforcement learning fine-tuning: Adapting a pretrained model via RL objectives to improve task performance. "Breaking the sparse-reward plateau in RL fine-tuning."
- Reinforcement learning with verifiable rewards (RLVR): RL where rewards can be automatically checked for correctness. "Reinforcement learning with verifiable rewards (RLVR) has recently spurred an impressive rise in LLM reasoning capabilities~\citep{deepseek2025r1,kimiteam2025kimi}, particularly in mathematics and programming."
- Reward hacking: Exploiting the reward function to gain high reward without genuine task mastery. "prone to reward hacking, or the decoupling of the intrinsic reward from actual task mastery"
- RLOO: A variance-reduction technique using grouped rollouts and leave-one-out baselines in policy gradients. "we train the teacher with RLOO \citep{ahmadian-etal-2024-back} to generate synthetic question-answer pairs."
- Self-play: Training where agents generate their own tasks/opponents to learn without external data. "inspired by self-play~\citep{silver2018alphazero,sukhbaatar2017asymmetric,openai2021asymmetricselfplay}"
- Semantic diversity: The variety of concepts present in a dataset, often quantified with embeddings. "we measure the semantic diversity of datasets from different teachers with the Vendi Score () \citep{friedman2022vendi}"
- Teacher-student setup: A framework where a teacher generates data/guidance and a student learns from it. "Our framework adopts a teacher-student setup, inspired by asymmetric self-play, to ``kickstart'' learning on datasets where the initial success rate is too low for successful training."
- Vendi Score: A metric estimating the effective number of unique semantic concepts in a dataset. "we measure the semantic diversity of datasets from different teachers with the Vendi Score () \citep{friedman2022vendi}"
Collections
Sign up for free to add this paper to one or more collections.