- The paper introduces a multi-turn synthetic data pipeline that decouples data diversity from volume for enhanced RL performance in code generation.
- It demonstrates that structured curricula and reverse difficulty scheduling mitigate overfitting and optimize learning across varied RL task environments.
- The study shows that environment scaling and diverse synthetic data can outperform larger real-data baselines in both in-domain and out-of-domain benchmarks.
Scaling Reinforcement Learning for Code Generation: Synthetic Data, Curricula, and Environment Diversity
Introduction
This paper presents a rigorous analysis of reinforcement learning (RL) for code generation with LLMs, focusing on the interplay between data scaling strategies, synthetic problem generation, curriculum design, and environment diversity (2603.24202). The work integrates a scalable multi-turn synthetic data pipeline, producing stepping-stone task progressions tailored dynamically to student performance via teacher–student rollouts. This framework enables the decoupling of data diversity from mere data volume, exposing the limitations of current RL post-training practices and advancing state-of-the-art RL pipelines for program synthesis and automated reasoning.
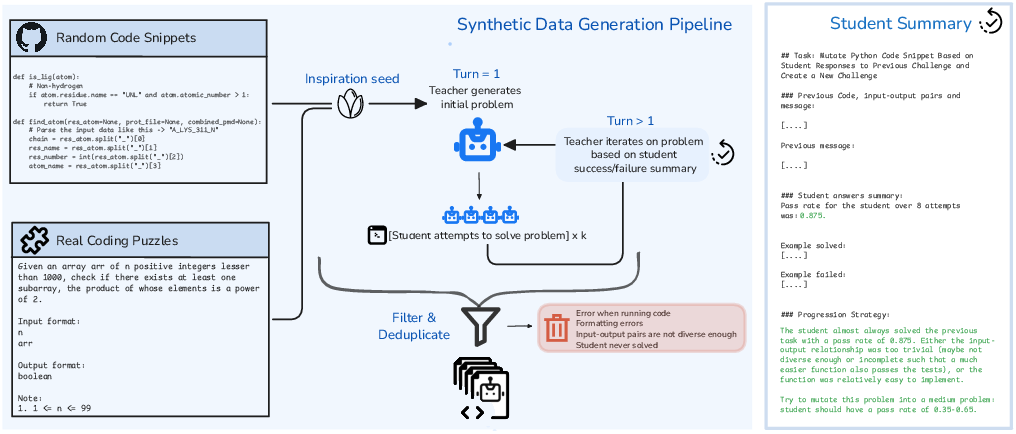
Figure 1: Overview of the multi-turn synthetic data pipeline, illustrating iterative teacher refinement conditioned on student performance for generating valid, structured problem progressions.
Pipeline Architecture: Multi-Turn Generation and Task Environments
The core data engine is a multi-turn teacher–student loop. Unlike single-turn approaches, the teacher receives compact summaries of student performance—including pass rates and solution exemplars—and generates variations with explicitly modulated difficulty levels.

Figure 2: Multi-turn generation adapts task difficulty across iterations in response to learner pass rates, generating tailored stepping stone challenges.
RL task environments explored include:
- Induction: Program synthesis.
- Abduction: Input inference from function/output pair.
- Deduction: Output generation from function/input.
- Fuzzing: Input crafting that produces test failures post type-check.
Inspiration seeds for the teacher are sourced from both solved real problems and random code snippets (e.g., starcoderdata), maximizing coverage of functional idioms and execution semantics.
Synthetic Data as an RL Scaling Axis
Contrary to naive intuitions, RL performance with real data quickly plateaus as the training set is enlarged, highlighting the diminishing returns from simply acquiring more real code-contest tasks.
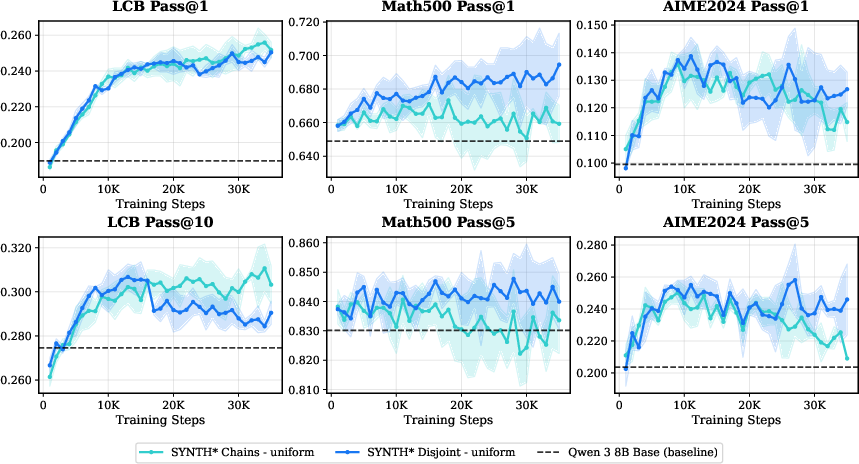
Figure 3: RL training with 25K and 81K real coding tasks under GRPO shows early plateau of learning curves, revealing scaling bottlenecks.
Augmentation with multi-turn synthetic problems—either as an additive corpus or in pure-synthetic RL—yields consistent performance improvements, as assessed both in-domain (LiveCodeBench, LCB) and out-of-domain (Math500, AIME2024) on Qwen and Llama model families.
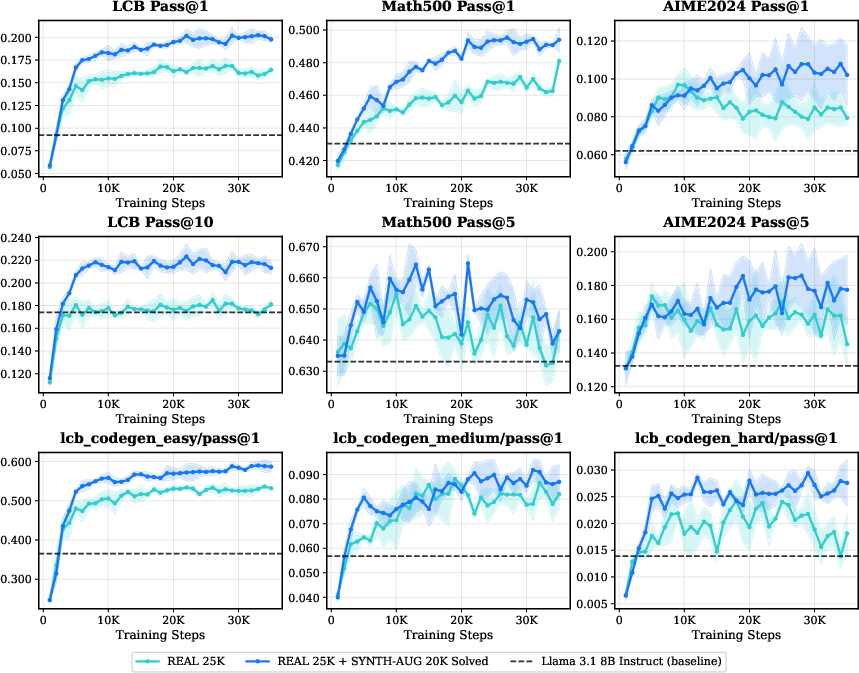
Figure 4: RL training augmented with synthetic data in Llama3.1-8B Instruct improves in/out-of-domain pass rates versus real-only baselines.
Notably, synthetic augmentation can outperform larger real-data-only baselines even with a fixed compute budget, demonstrating that diversity and difficulty structure, not just scale, are critical for RL.
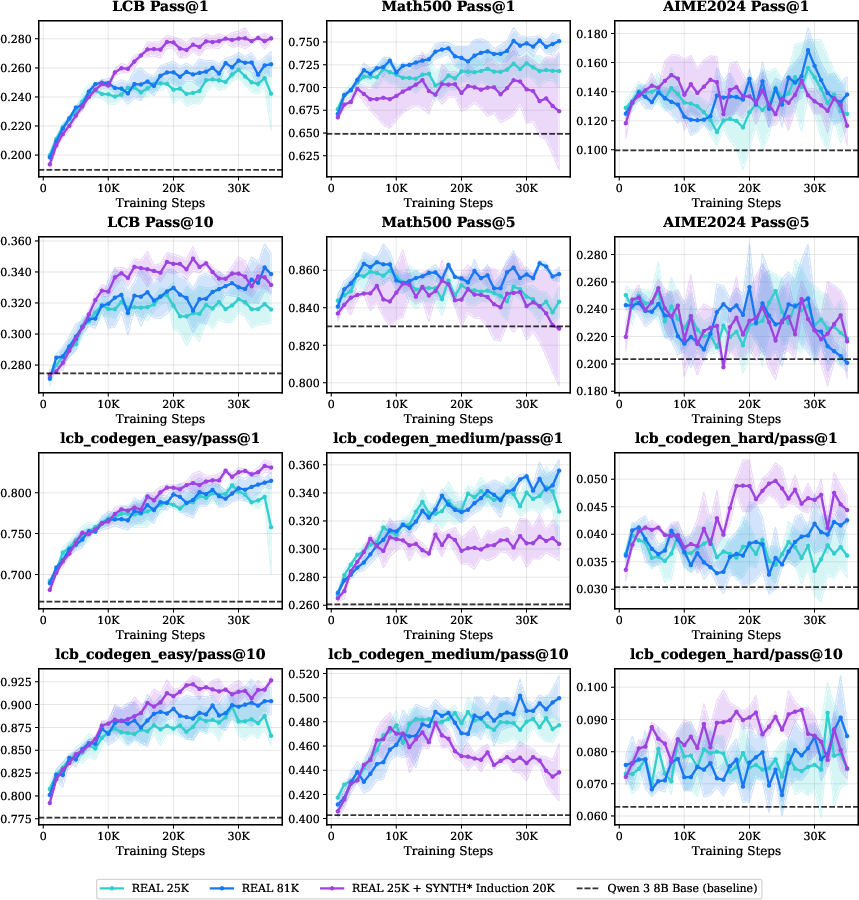
Figure 5: Synthetic augmentation (Real 25K + 20K SYNTH
) exceeds the 81K real-data baseline across all LCB splits except medium.*
Synthetic generation strategies based on random code seeding increase functional heterogeneity and reduce overfitting, sometimes matching or exceeding real-data-seeded augmentation.
Curriculum Learning and Question Difficulty
The study empirically disentangles the roles of curriculum variants, difficulty scheduling, and stepping-stone chains. Key findings include:
- RL on medium-difficulty problems yields the best generalization and minimizes the risk of overfitting compared to "easy-skewed" curricula.
- Reverse curricula (starting with medium or hard) broaden early exploration, mitigating entropy collapse, but aggressive "hard-start" schedules increase optimization variance and slow convergence.
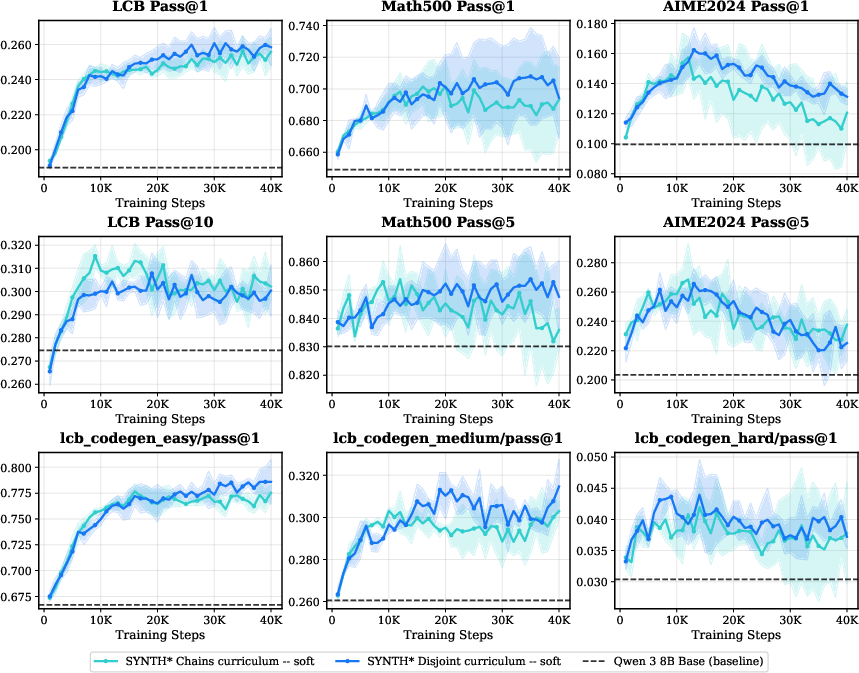
Figure 6: Training restricted to medium split achieves balanced in/out-of-domain performance; easy-only overfits, hard-only suffers from sparse rewards.
Figure 7: Reverse curriculum (medium→easy–medium) outperforms classic (easy→medium→hard) and uniform baselines, especially on harder benchmarks.
Stepping-stone question chains, automatically constructed in the multi-turn pipeline, provide incremental subgoals that facilitate efficient progression through the difficulty spectrum. The effect is most pronounced under hard or staged curricula, with diminishing returns in highly mixed-difficulty schedules.
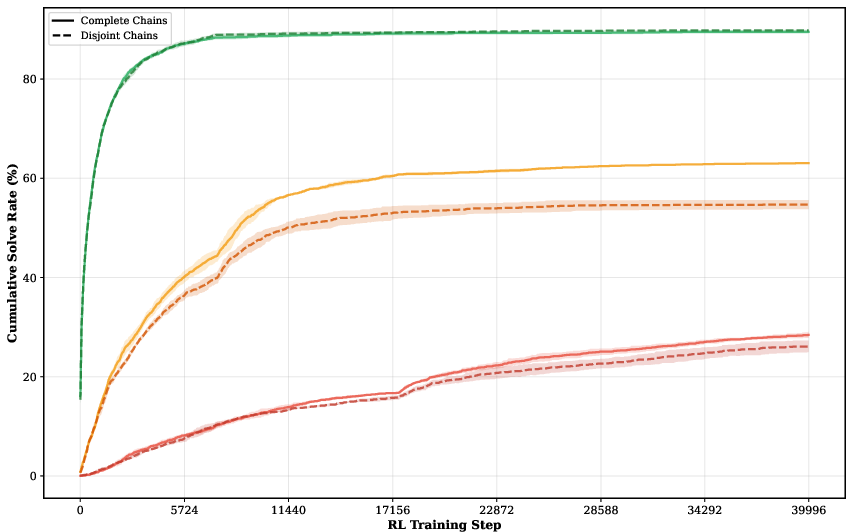
Figure 8: Explicit easy–medium–hard chains in hard curricula show solid solve-rate improvements over disjoint, diversity-matched baselines.
Scaling Along the Environment Axis
Data diversity is further extended via environment scaling: distributing a fixed RL budget across functionally disjoint environments (induction, abduction, deduction, fuzzing) yields robust generalization on code and math tasks, exceeding gains achieved by increasing sampling from a single environment.
Figure 9: Multi-environment RL leads to higher out-of-domain pass rates and increases in-domain pass@10, compared to induction-environment only training.
Notably, these improvements are realized using less total data than the real-task-only baselines, indicating that structural diversity is a dominant scaling factor for RL alignment in LLMs.
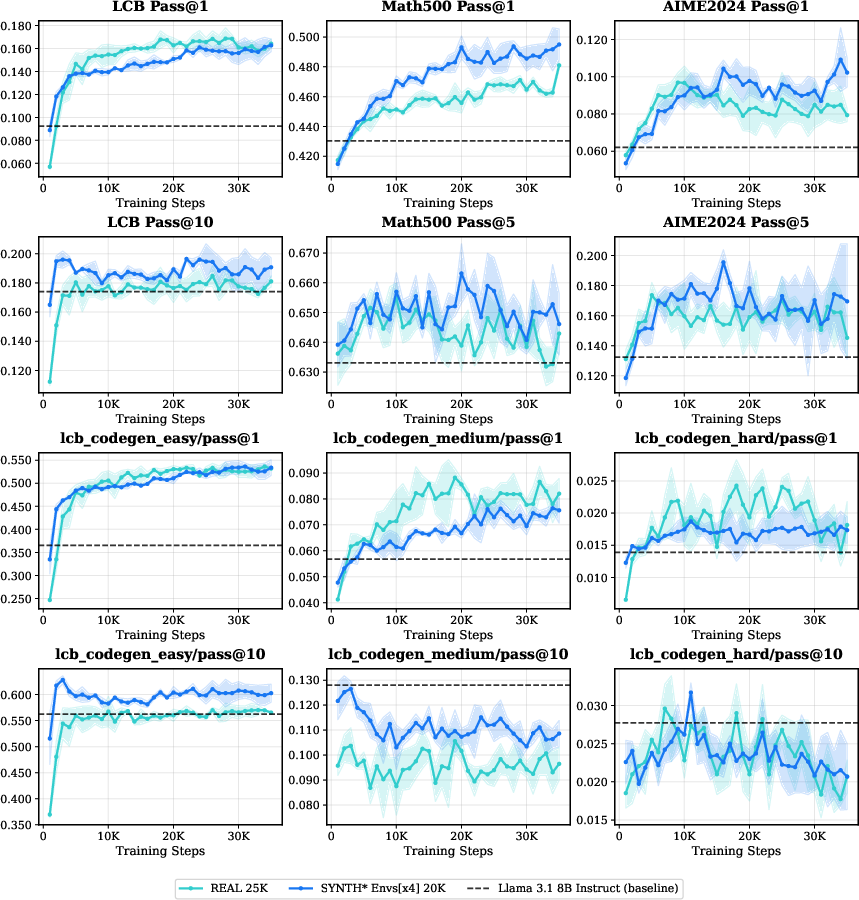
Figure 10: For Llama3.1-8B Instruct, multi-environment synthetic RL surpasses both in-domain and out-of-domain benchmarks with data efficiency.
Empirical Insights and Theoretical Implications
Strong empirical claims from the study include:
- Synthetic RL data, generated via multi-turn pipelines and seeded with diverse program types, is at least as effective as real code-contest data for in/out-of-domain generalization.
- Curriculum design critically mediates the utility of stepping stones and the efficacy of RL optimization, with reverse curricula showing reduced overfitting and enhanced hard-task learning.
- Environment scaling—viewed as an additional data-structuring axis—can match or exceed data augmentation gains without additional data volume.
- Mixing difficulty levels or environments too aggressively can result in gradient/interference phenomena that attenuate ideal learning dynamics, as seen in uniform and mixed curricula ablations.
Future Directions
This study lays the groundwork for principled RL post-training regimes, suggesting that future development of code-specialized LLMs should combine multi-turn synthetic data pipelines, explicit curriculum control, and cross-environment data mixing. Potential future directions include:
- Coupling the teacher with a live-updated student in an online, feedback-driven setting.
- Extending the stepping-stone pipeline for transfer to other domains requiring compositional reasoning, such as theorem proving or tool composition.
- Developing new environment abstractions that encode richer execution semantics and adversarial evaluation regimes.
Conclusion
This work provides a comprehensive framework for RL scaling in code generation, demonstrating that data diversity, structured curricula, and environment multiplicity are essential for overcoming the limitations of RL post-training with LLMs. Practical implementation of these principles can lead to more robust, generalizing code models and inform the design of future RL and synthetic-data pipelines for LLM reasoning systems.
(2603.24202)