LongCat-Flash-Thinking-2601 Technical Report
Abstract: We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces LongCat-Flash-Thinking-2601, a very large open-source AI model built to be an “agent.” That means it doesn’t just think in text — it can plan, use tools, search the web, write and run code, and work inside realistic “practice worlds.” The model focuses on solving real-life tasks by deciding when and how to interact with its environment, then using the feedback to keep improving its reasoning. It performs better than other open-source models on many tests that measure tool use, web browsing, and multi-step problem solving.
The main questions the paper asks
- How can we train an AI not only to think, but to act — to plan, use tools, and handle complex, multi-step tasks in messy, real-world settings?
- How do we create enough diverse “practice worlds” so the AI learns general skills it can transfer to new situations?
- How can we make the AI robust to noise (errors, missing data, broken tools) that often happens in the real world?
- Can we boost the AI’s problem-solving at test time by letting it “think more,” both deeper and in parallel?
How they built and trained the model
A quick note on terms (in everyday language)
- Mixture-of-Experts (MoE): Imagine a team of specialists. Each token the model reads wakes up only some specialists best suited for that piece, so the model is both huge and efficient.
- Agentic reasoning: The AI decides when to search, which tool to call, what to ask next, and how to use feedback to reach a goal.
- Reinforcement learning (RL): Learning by trial and error. The AI tries actions; good outcomes get “rewards” that teach it what to do next.
- Environment: A practice world with rules and tools (like a coding sandbox, a database with tools, or a web browser).
- KV-cache: A memory that helps the model remember what’s been said so far without rethinking everything from scratch.
- Pass@k: A score that checks whether a correct solution appears within k tries.
Step 1: Teach it to handle long, complex inputs
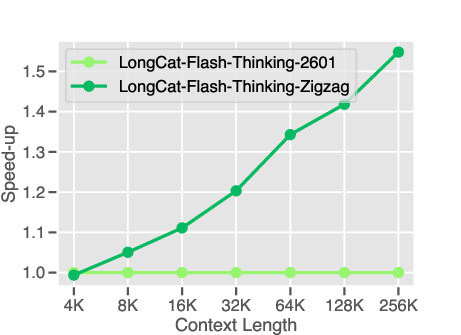
Real agent tasks involve long conversations and many steps. The team trained the model on very long contexts (32K to 256K tokens) so it can keep track of multi-turn tasks without losing important details.
Step 2: Give it “agent” examples to learn from
Real data about tool-using agents is rare, so they created high-quality training examples in two ways:
- From text: They mined tutorials and step-by-step guides, turned hidden procedures into explicit tool calls, and added decision points where the model must choose among multiple actions.
- From executable environments: They built small Python “worlds” with tools and databases, generated tool-use sequences, and verified them by actually running the code to ensure the steps were correct.
They also added planning-focused data, which trains the model to break big problems into parts, explore alternatives, and make early decisions that lead to success.
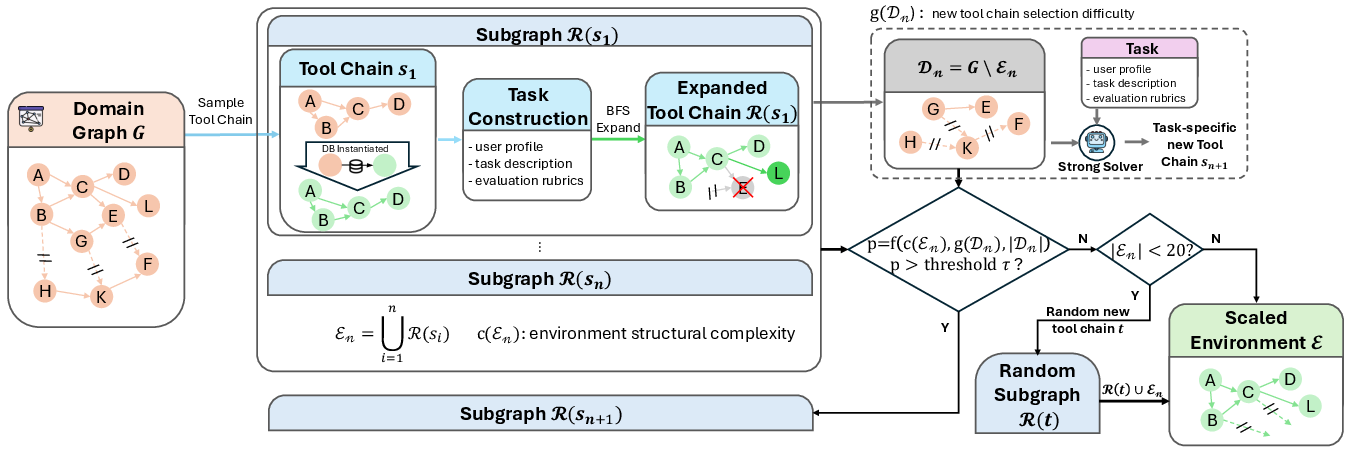
Step 3: Build many practice worlds (environment scaling)
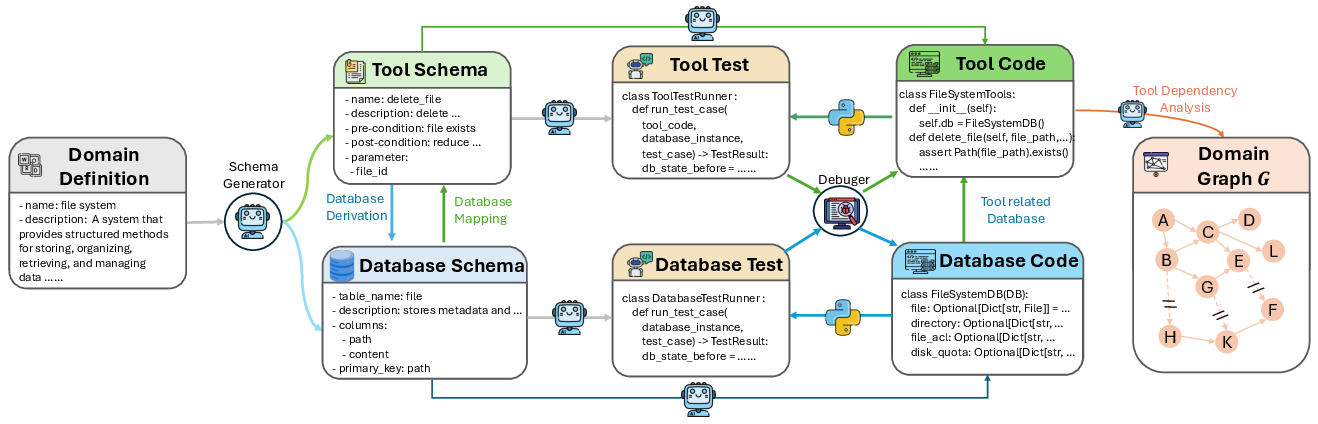
To make the AI generalize, they automatically constructed lots of realistic tool-use environments across 20+ domains (like business, data, travel, etc.). Each domain is turned into:
- A tool graph: which tools exist and how they depend on each other.
- A database schema: what data the tools work with.
- Verified tasks: goals the agent must reach using those tools, with clear rules for what counts as success.
They carefully expand these worlds by adding tools only when their dependencies are satisfied. This keeps the environments executable and prevents hidden errors that would punish the model unfairly.
For coding tasks, they created a standardized coding sandbox that supports common tools (search, file editing, shell commands) and can run at large scale.
Step 4: Create challenging search tasks
They designed two kinds of web-search problems:
- Multi-hop reasoning: Questions that require following chains of relationships between entities (like finding connections between people, places, and events).
- Ambiguity handling: Questions with multiple constraints that could match several answers unless you gather and verify all the evidence.
A pipeline checks quality, prevents shortcuts (like lucky guesses), and makes sure the agent verifies every condition.
Step 5: Train with large-scale, async reinforcement learning
Training an acting agent is hard because:
- Interactions are long and uneven (some tasks take much longer).
- Environments are diverse and can be slow or noisy.
- Hardware has limits (memory, speed).
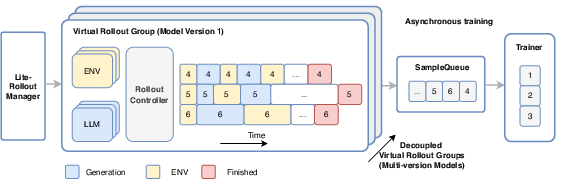
They extended their asynchronous training system (called DORA) to:
- Stream tasks without waiting for batches, keeping devices busy.
- Run up to tens of thousands of environments at the same time across many machines.
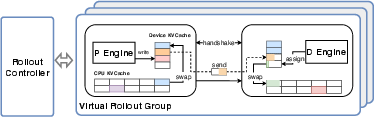
- Separate “prefill” (reading long input) from “decode” (writing answers) so decoding stays fast, while moving memory chunks (KV-cache) smartly between CPU and GPU to avoid re-computation.
Step 6: Train for robustness in noisy settings
Real-world tools break, data is missing, and results can be inconsistent. The team analyzed common “noise” types and injected them gradually during training, so the model learns to handle imperfections without failing.
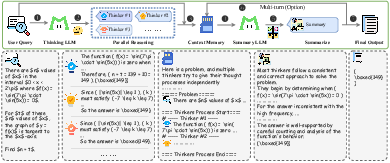
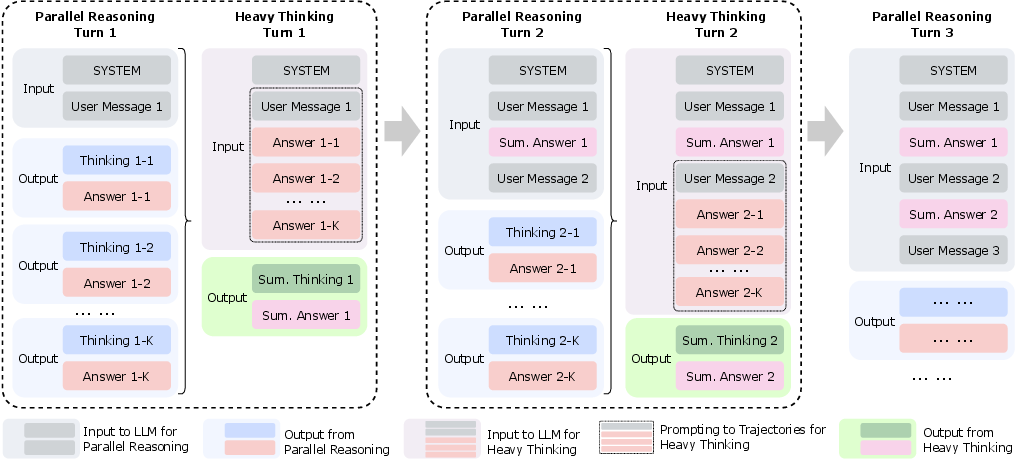
Step 7: Add a Heavy Thinking mode at test time
When a problem is extra hard, the model can “think wider” (try multiple solution paths in parallel) and “think deeper” (refine and combine intermediate results). They also use RL to teach the model to summarize and choose the best ideas from its parallel thoughts.
Main findings and why they matter
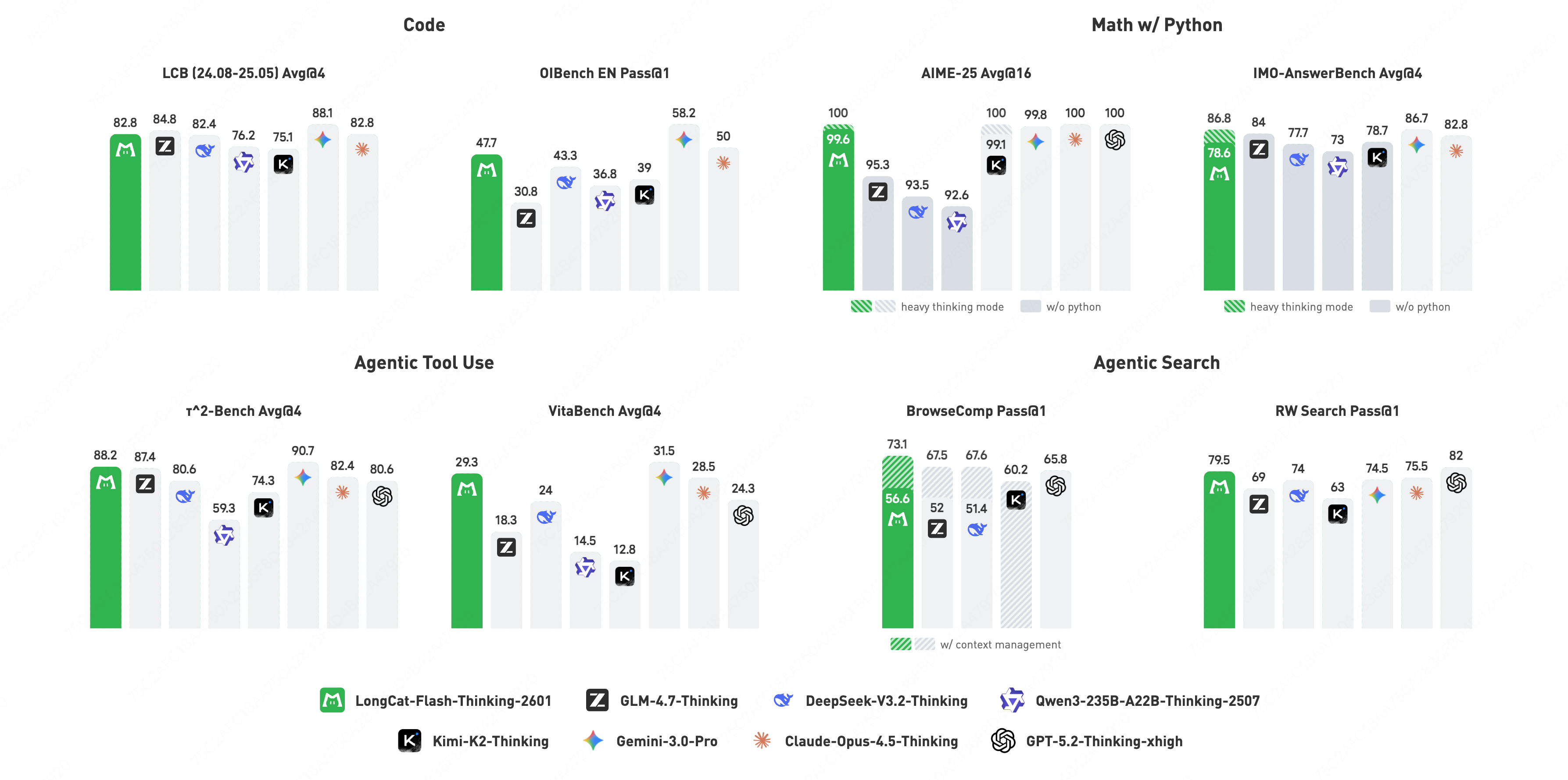
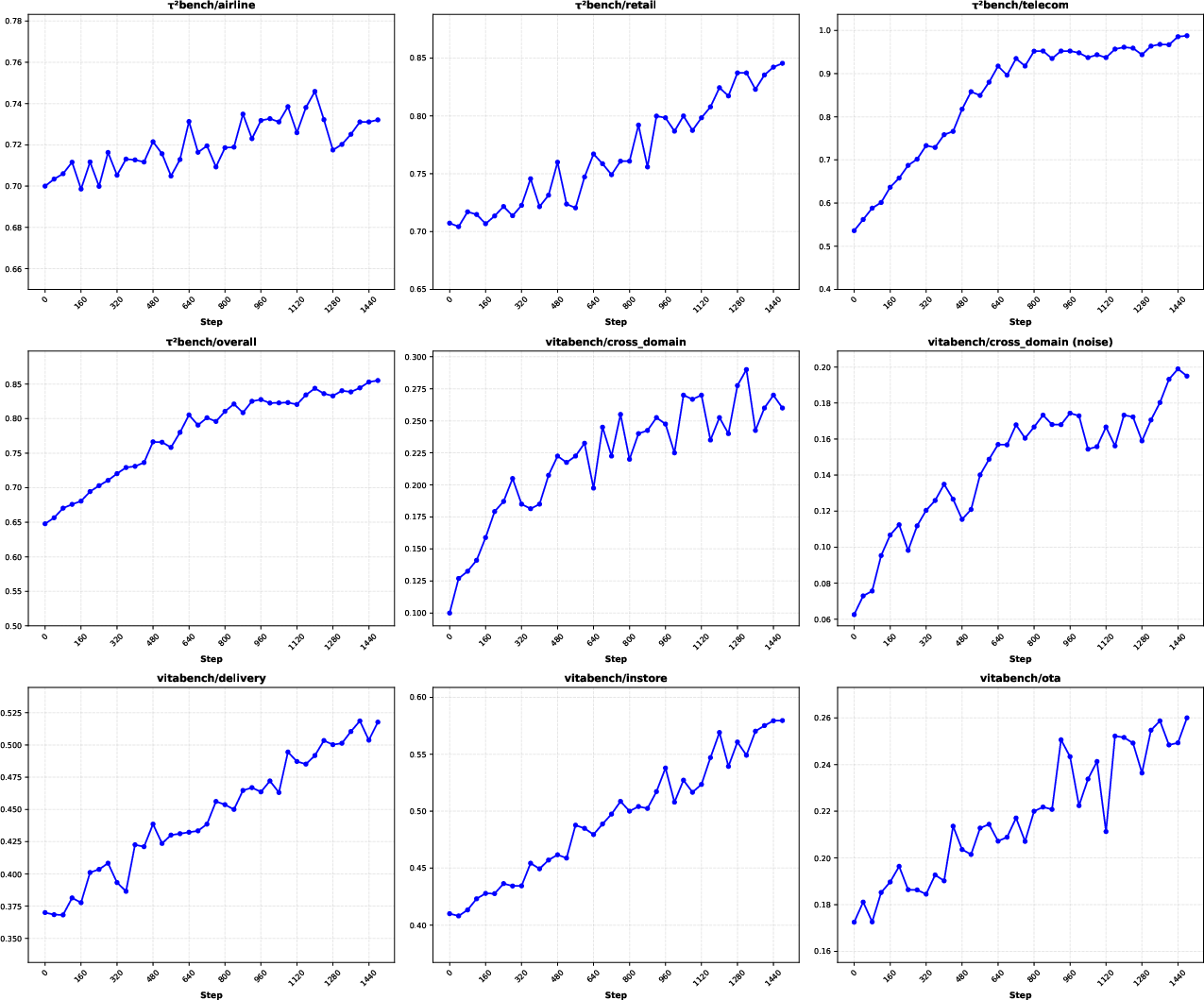
- It leads among open-source models on key agentic benchmarks:
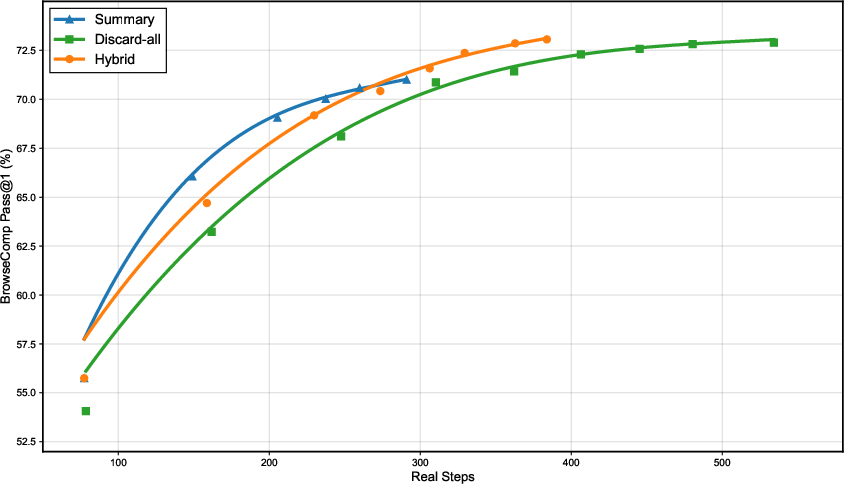
- BrowseComp: 73.1%
- RWSearch: 77.7%
- τ²-Bench: 88.2%
- VitaBench: 29.3%
- It generalizes well to new, unseen environments and stays robust when tools or data are noisy.
- The Heavy Thinking mode improves performance on complex, multi-step tasks.
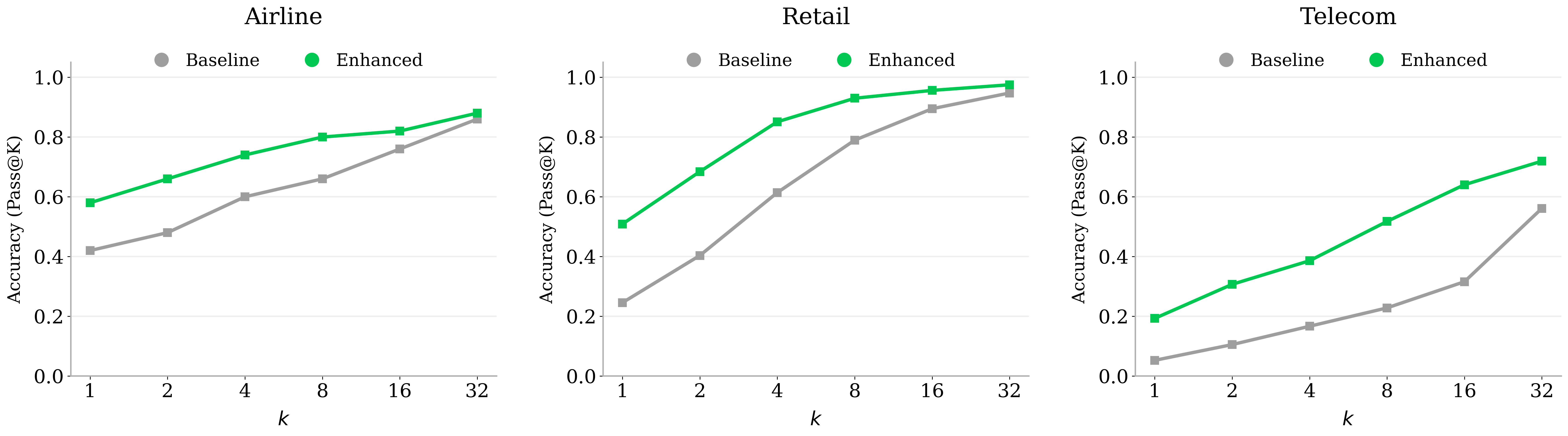
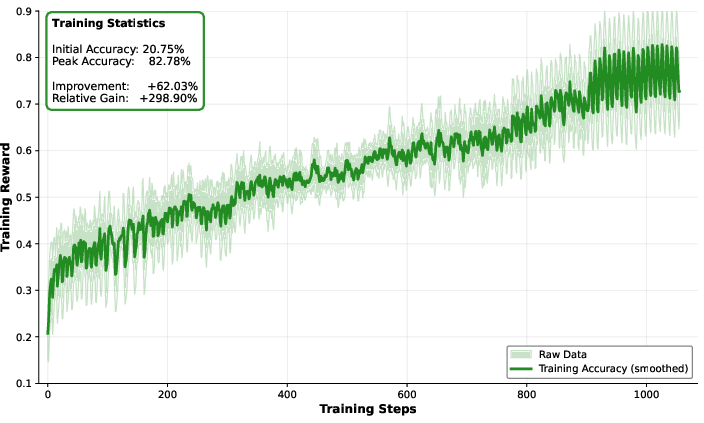
- Mid-training with agentic trajectories and planning data raises the model’s ability to solve tool-intensive problems, as shown by better pass@k scores.
Why this matters:
- Many real tasks need an AI that can plan, use tools, and verify results, not just chat. This model shows how to train that kind of capability at scale.
- Robustness to noise means it’s more reliable outside perfect lab conditions.
- Generalization across domains means it can adapt, not just memorize.
What this could mean in the future
- Smarter assistants that can run code, search, and use tools to complete real tasks, like debugging software, planning trips, analyzing business data, or helping with research.
- More trustworthy behavior in messy, real-world settings where things often go wrong.
- Faster progress in agentic AI research, because the model and checkpoints are open-source and the training methods are clearly documented.
- Practical systems that combine strong reasoning with action, moving beyond pure text chat to real problem solving.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of the specific gaps, uncertainties, and open questions the paper leaves unresolved that future researchers could address.
- MoE architecture transparency: the report lacks concrete model specifications (number of experts per layer, routing/top‑k policy, load‑balancing losses, expert sizes, activation distribution, gate regularization). Action: release full architecture configs and conduct ablations on expert count, routing, and auxiliary losses to quantify utilization and gate collapse risks.
- RL algorithm details: the learning objective, value/advantage estimation, KL/entropy regularization, off‑policy handling, and credit assignment across multi‑turn trajectories are unspecified. Action: compare PPO/actor‑critic variants, reward shaping strategies, and credit assignment mechanisms for long‑horizon agentic tasks.
- Reward design and supervision: beyond rubric‑based outcome checks, the form of rewards (sparse vs dense, intermediate verification signals, penalties for unsafe/invalid tool calls) is unclear. Action: design and evaluate dense intermediate rewards (e.g., constraint satisfaction, tool‑call correctness) and safety penalties to reduce spurious behaviors.
- Heavy Thinking mode specifics: the number of parallel trajectories, aggregation mechanism (voting, learned aggregator, reranking), objective for the “additional RL stage,” and compute/latency trade‑offs are not described. Action: quantify accuracy vs latency/compute scaling curves; ablate aggregation strategies and dynamic budget allocation.
- Generalization measurement: claims of strong OOD generalization lack formal protocols for holdout domains, unseen tools/APIs, and zero‑shot transfer. Action: establish standardized cross‑domain, unseen‑graph, and real‑system evaluation suites with strict train/test separations.
- Environment scaling function and thresholds: the environment growth decision function f, threshold τ, and selection heuristics (c(E), g(D)) are underspecified, making replication and tuning difficult. Action: publish the exact functions/parameters and perform sensitivity analyses on environment complexity vs training stability and performance.
- Environment failure modes: the reported ~95% tool implementation success rate lacks characterization of the remaining 5% (types of failures, nondeterminism, cyclic dependencies, state drift). Action: release diagnostics and mitigation strategies for graph cycles, dynamic dependencies, and cross‑tool state inconsistencies.
- Noise modeling curriculum: the taxonomy, distributions, and curriculum schedule for multi‑type/multi‑level environmental noise are not enumerated. Action: benchmark robustness under controlled noise types (latency spikes, stale states, partial observability, API rate limits) and validate alignment of synthetic noise to real‑world frequencies.
- Data synthesis validity and contamination: reliance on LLM‑as‑judge and synthetic trajectories risks spurious correlations and benchmark leakage; no contamination audit is reported. Action: perform contamination checks against BrowseComp/RWSearch/τ²/VitaBench; ablate text‑driven vs environment‑grounded vs planning‑centric data contributions.
- Cold‑start policy quality: qualitative diversity of reasoning paths and format stability are asserted but not measured. Action: introduce quantitative metrics (trajectory entropy, tool‑use diversity, prompt adherence, exploration efficiency) and correlate them with downstream RL gains.
- Tool‑use realism: environments are limited to synthesized tool graphs and Python databases; real‑world constraints like authentication, quotas, rate limits, partial failures, and schema drift are not modeled. Action: integrate live or emulated APIs with realistic constraints and evaluate robustness under operational variability.
- Safety and security: there is no discussion of unsafe tool calls, sandbox escapes, secret exfiltration, or harmful actions during agentic interactions. Action: adopt safety policies, red‑teaming, capability constraints, and runtime monitors; report safety incident rates and mitigation efficacy.
- Long‑context scaling behavior: staged training to 256K context is described, but inference memory limits, accuracy vs context length scaling laws, and failure rates under KV‑swap are not quantified. Action: publish context‑length scaling curves for agentic tasks and the impact of KV‑cache swapping on accuracy/latency.
- PD disaggregation trade‑offs: the overhead of KV‑cache chunk transfer and CPU swapping, optimal watermarks, and conditions under which recomputation is avoided are not measured. Action: provide detailed throughput/latency/utilization ablations across request length distributions and device memory budgets.
- Asynchronous multi‑version training staleness: policy lag, sample staleness bounds, and off‑policy correction mechanisms within DORA are not documented. Action: analyze stability with staleness metrics; test V‑trace/importance sampling corrections and their impact on convergence.
- Benchmarking protocol transparency: evaluation settings (prompt templates, tool access, Heavy Thinking usage, temperature, seeds) and statistical significance are not reported. Action: release reproducible evaluation kits with fixed seeds, prompts, tool configurations, and report confidence intervals.
- Expert utilization and forgetting: risks of expert specialization causing catastrophic forgetting of general reasoning are not analyzed. Action: track expert activation entropy, inter‑domain utilization, and perform continual‑learning/regularization ablations to mitigate forgetting.
- Dependency graph coverage: BFS‑style expansion may underrepresent cyclic or dynamic dependencies and concurrency. Action: extend environment construction to include cycles, temporal dependencies, and concurrent tool interactions; measure agent performance under these complexities.
- Real‑time performance: deployment under strict latency budgets and high‑variance environment delays is not evaluated. Action: measure end‑to‑end response distributions, introduce latency‑aware scheduling, and assess accuracy under time constraints.
- Multilingual capability: the model’s agentic performance across languages and cross‑cultural domains is unreported. Action: build multilingual tool‑use/search environments and evaluate zero‑shot/transfer performance.
- Code sandbox reproducibility and provenance: OS/package pinning, network isolation, SBOM tracking, and long‑term reproducibility are not detailed. Action: provide container images, version locks, provenance metadata, and reproducibility checks across machines.
- Robustness metrics beyond pass@k: chain‑of‑thought faithfulness, tool‑call correctness rates, hallucination in environment descriptions, and error recovery are not measured. Action: define and report standardized robustness/faithfulness metrics for agentic interactions.
- Release completeness and licensing: checkpoints are released, but data, environments, tools, and licenses are not clearly specified. Action: clarify licensing, release environment generators and task sets, and document usage constraints.
- Curriculum adaptivity: the noise and task difficulty curricula are static; adaptivity to agent performance is unexplored. Action: test performance‑adaptive curricula (e.g., bandit‑based task sampling, noise escalation policies) and their effect on sample efficiency.
- Cost‑effectiveness and distillation: compute/energy costs and carbon footprint are not quantified; pathways to smaller models with similar agentic capability are not explored. Action: measure training/inference cost and investigate distillation/sparse routing to improve efficiency.
- Autonomy control for tool invocation: learning when to interact vs think internally is not explicitly modeled. Action: train a meta‑controller for tool‑use decisions and evaluate its impact on efficiency and accuracy.
- Planning‑centric augmentation effects: claimed improvements (e.g., τ² pass@k) lack cross‑task validation and magnitude. Action: run controlled ablations isolating planning data and report improvements across diverse agentic benchmarks.
- Scaling laws with environment count: performance gains vs number/complexity of environments are not characterized. Action: derive scaling curves and identify diminishing returns/optimal diversity.
- Failure taxonomy and diagnostics: no systematic analysis of typical agentic failure modes (tool misuse, partial verification, state inconsistency, over‑exploration). Action: publish a taxonomy, error dashboards, and targeted fixes to guide future work.
Glossary
- Agent-based QA Synthesis: A data-generation method where multiple agents collaborate (with tools) to create and validate question–answer pairs under controlled constraints. "Agent-based QA Synthesis:"
- Agentic coding: Tasks where an agent interacts with an executable programming environment and tools to solve coding problems. "we specifically introduce two particularly challenging types of environments in agentic tasks: agentic coding and agentic tool-use."
- Agentic reinforcement learning: Reinforcement learning focused on multi-turn interactions with environments and tools to acquire agent-like behaviors. "agentic reinforcement learning further requires a reliable and scalable environment foundation to support long-horizon, interaction-driven training."
- Agentic reasoning: The capability to solve problems via adaptive interaction with external environments, integrating feedback into reasoning. "agentic reasoning can be understood as the ability to solve complex problems through adaptive interaction with external environments."
- Agentic search: An agent-driven, multi-step web or knowledge-base search process guided by iterative reasoning and verification. "agentic search, agentic tool use, and tool-integrated reasoning."
- Agentic tool-use: Multi-step interaction with heterogeneous tools and databases to accomplish a task through planning and execution. "agentic search and agentic tool-use tasks."
- Asynchronous reinforcement learning: RL where rollouts, environment steps, and updates proceed without strict synchronization to improve throughput and stability. "we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training."
- Code sandbox: An isolated, executable environment for running code and interacting with developer tools safely and reproducibly. "the agent must operate within an executable code sandbox and interact with various terminal tools in real time."
- Cold-start: The initialization phase where a policy is primed with basic behaviors before large-scale RL. "The cold-start stage serves a critical role in initializing the policy for subsequent reinforcement learning stage."
- Curriculum-based reinforcement learning: A training strategy that progressively increases task or noise difficulty to improve stability and robustness. "A curriculum-based reinforcement learning strategy is adopted to progressively increase noise complexity, substantially improving robustness and performance under imperfect conditions."
- Domain-parallel expert training: Training specialized expert models in parallel across domains before merging into a general model. "domain-parallel expert training with subsequent fusion"
- Domain-specific tool graph: A graph of tools and their dependencies tailored to a particular domain for constructing executable environments. "we construct a collection of domain-specific tool graphs covering over 20 domains."
- DORA (Dynamic ORchestration for Asynchronous Rollout): A multi-version asynchronous training system for scalable, stable agentic RL. "Dynamic ORchestration for Asynchronous Rollout (DORA)"
- End-to-end co-design: Joint design of data, environments, algorithms, and infrastructure to achieve a unified training objective. "an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training."
- Environment-grounded synthesis: Data generation directly from executable environments to ensure logical correctness and execution consistency. "Environment-grounded synthesis"
- Environment scaling: Automated expansion and diversification of environments to cover many domains and difficulty levels while preserving executability. "we design an automated environment scaling pipeline to construct complex and diverse environments"
- Expert parallelism: Parallelizing different experts (sub-networks) across devices to efficiently serve Mixture-of-Experts models. "we employ a high degree of expert parallelism together with graph-level compilation for decode."
- Experience-Maker: A component that generates and manages trajectories for training within the RL framework. "a Trainer (which manages the Experience-Maker and training stage)."
- Evaluation rubrics: Structured criteria used to verify correctness and quality of task outcomes. "evaluation rubrics"
- Graph-based QA Synthesis: A pipeline that builds relational graphs (e.g., from Wikipedia) and generates multi-hop reasoning questions from connected subgraphs. "Graph-based QA Synthesis:"
- Heavy Thinking Mode: A test-time reasoning mode that expands both width and depth via parallel exploration and iterative refinement. "Heavy Thinking Mode for Test-Time Scaling."
- K-Center-Greedy (KCG): A selection algorithm used to choose diverse, informative samples based on distance and uncertainty. "K-Center-Greedy (KCG) selection algorithm guided by perplexity (PPL)"
- KV-cache: Cached key–value attention tensors used to speed up transformer decoding; may be swapped between device and CPU. "CPU-resident KV-cache"
- LLM-as-a-judge: Using an LLM to automatically evaluate intermediate steps or outputs for correctness and quality. "LLM-as-a-judge approach"
- Long-horizon trajectories: Interaction sequences requiring many steps of planning, acting, and reasoning before reaching a goal. "Agentic tasks typically involve long-horizon trajectories with proactive tool invocations."
- Long-tailed generation: Output length and latency distributions where a small fraction of very long generations dominate resource usage. "To optimize long-tailed, skewed generation and multi-turn agentic interactions"
- Model-level and data-level merging: Consolidating multiple domain experts into one model via both parameter/model fusion and curated data mixing. "consolidated into a single general model through both model-level and data-level merging."
- Multi-version asynchronous training: Training where rollouts from multiple model versions are produced and consumed asynchronously to stabilize learning. "our DORA system enables multi-version asynchronous training"
- Pass@k: An evaluation metric measuring probability that at least one of k sampled attempts solves a task. "pass@k on the -Bench."
- Perplexity (PPL): A language modeling uncertainty metric; lower values indicate better predictive fit. "perplexity (PPL)"
- PrefillâDecode (PD) Disaggregation: Splitting prefill and decode across device groups to improve throughput; includes KV-cache transfer/swap mechanisms. "we introduce PrefillâDecode (PD) Disaggregation in RL training"
- Request load ratio: A utilization metric for generation devices indicating the fraction of request capacity in use over time. "Request load ratio is a continuous value ranging from 0 to 1, aggregated over all generation devices across the entire rollout period."
- Sliding-window PPL: A perplexity variant that computes max average PPL over fixed-length windows to capture localized difficulty. "sliding-window PPL"
- Streaming RPC: Request–response calls that stream data continuously to reduce idle time and improve pipeline overlap. "based on streaming RPC"
- tau2-Bench: A benchmark for evaluating agentic reasoning/tool-use performance and generalization. "88.2\% on -Bench"
- Test-time scaling: Increasing compute or reasoning steps during inference to boost accuracy without retraining. "test-time scaling of reasoning"
- Tool dependency graph: A directed graph where nodes are tools and edges encode parameter/data dependencies among tools. "tool dependency graph"
- Tool-integrated reasoning: Reasoning that interleaves tool calls and natural language thinking to solve tasks. "agentic search, agentic tool use, and tool-integrated reasoning."
- Tool schema: A formal specification of tool interfaces (inputs/outputs) used to standardize and generate tool implementations. "tool schema implementations"
Practical Applications
Immediate Applications
Below is a concise set of deployable applications that directly leverage the paper’s released model and training/inference methods.
- Agentic IDE Copilot for Debugging and Refactoring (Software)
- What: A developer assistant that operates inside an IDE, invoking a code sandbox to reproduce bugs, run tests, edit code, and verify fixes end-to-end.
- Tools/Products/Workflows: VS Code/JetBrains plugin; integration with CI/CD; “Agentic Test-and-Fix” workflow using the paper’s code sandbox, rubric-based verification, and Heavy Thinking mode for hard issues.
- Assumptions/Dependencies: Access to reproducible build/test environments, permissioned repository access, reliable unit/integration tests, and sufficient inference compute (560B MoE; PD disaggregation and KV-cache swapping recommended).
- Enterprise Knowledge and Compliance Research Assistant (Legal/Policy/Enterprise)
- What: Multi-hop agentic search across internal knowledge bases and open web to compile evidence-backed memos (e.g., regulatory change tracking, policy comparisons).
- Tools/Products/Workflows: “Browse–Verify–Summarize” pipeline; graph-based QA and FSM-based synthesis patterns for query decomposition and ambiguity resolution; LLM-as-judge checks.
- Assumptions/Dependencies: Secure connectors to enterprise content and web, audit logging, guardrails for privacy/compliance; human-in-the-loop approval for external-facing outputs.
- Robust Customer Support Agent with Tool Use (Customer Ops/CRM)
- What: A ticket triage and resolution agent that can call heterogeneous tools (CRM, ticketing, knowledge base) under noisy, incomplete inputs; gracefully handles errors and retries.
- Tools/Products/Workflows: Tool dependency graph orchestration; rubric-validated outcomes; curriculum-based noise robustness from training.
- Assumptions/Dependencies: Stable API connectors, permissioning, error budget and rollback policies, incident playbooks, and supervision for escalation paths.
- Data Operations Orchestrator for ETL and Reconciliation (Data/Finance/Back-office)
- What: Automates multi-step data quality checks, reconciliation across systems, and small “fix” operations by chaining validated tools and databases.
- Tools/Products/Workflows: Domain-graph-based tool orchestration; verifiability-preserving environment expansion; turn-level loss masking for reliable action learning.
- Assumptions/Dependencies: Well-defined tool schemas and evaluation rubrics; access controls; transaction safety and audit trails.
- Heavy Thinking Inference Service for Complex Reasoning (Cross-sector)
- What: On-demand “test-time scaling” for hard tasks (e.g., complex planning, scenario analysis) via parallel exploration and iterative refinement.
- Tools/Products/Workflows: API exposing Heavy Thinking mode; configurable depth/width; aggregation reinforcement to improve final answer quality.
- Assumptions/Dependencies: Higher latency/cost tolerance; scheduler that balances parallel trajectories; monitoring for hallucination and consistency.
- Academic Benchmarking and Agentic Evaluation Suite (Academia/ML)
- What: Use the released model and pipelines to evaluate agentic search/tool-use on BrowseComp, RWSearch, τ²-Bench, VitaBench; extend to lab-specific tasks.
- Tools/Products/Workflows: Standardized benchmark harnesses; environment-grounded synthesis; pass@k tracking with multi-version asynchronous rollouts (DORA).
- Assumptions/Dependencies: Access to the checkpoints; reproducible environment spins; cluster or cloud resources for multi-environment runs.
- Test Scenario Generation for QA and Reliability (Software QA)
- What: Automatically synthesize complex, executable test environments and tasks to stress product tool chains and verify failure modes.
- Tools/Products/Workflows: Automated domain graph construction; BFS-style environment expansion that maintains executability; rubric-based acceptance.
- Assumptions/Dependencies: Well-specified tool interfaces; seed tasks; unit tests; sandbox isolation to prevent side effects.
- Education: Tool-Integrated Tutoring for STEM and Coding (Education)
- What: Tutors that perform step-wise reasoning, call tools (calculators, interpreters, sandboxes), and demonstrate planning, verification, and error correction.
- Tools/Products/Workflows: Planning-oriented data augmentation; multi-turn agentic trajectories; Heavy Thinking for difficult problems.
- Assumptions/Dependencies: Classroom-safe browsing/tool connectors; content controls; accommodations for latency/cost and curriculum integration.
- Incident Response Triage Assistant (Cybersecurity/IT Ops)
- What: Guided triage that runs diagnostic commands, queries logs (SIEM), correlates signals, and proposes next actions with evidence.
- Tools/Products/Workflows: Code/command execution sandbox; tool dependency graphs (ticketing, alerting, CMDB); “verify-final-state” rubrics to avoid spurious fixes.
- Assumptions/Dependencies: Strict isolation and permissions; SOC approval steps; risk controls for command execution; robust logging and replay.
- Agentic RL Orchestration for Internal Models (ML Platform Engineering)
- What: Adopt DORA-based asynchronous RL training with multi-environment rollouts to elicit tool-use competence in organization’s own models.
- Tools/Products/Workflows: RolloutManager/SampleQueue/Trainer split; CPU-idleness-aware RPC; PD disaggregation plus CPU KV-cache swapping to keep decodes efficient.
- Assumptions/Dependencies: Access to mid-range accelerators/cluster; engineering investment to port training code; policy for multi-version training stability.
Long-Term Applications
These use cases are feasible but require further research, scaling, domain adaptation, or regulatory clearance before broad deployment.
- Clinical Decision Support with Verified Tool Use (Healthcare)
- What: Multi-step diagnostic and treatment planning assistant that queries EHR, guidelines, and literature; verifies conditions and constraints.
- Tools/Products/Workflows: Domain-specific tool graphs (labs, imaging, meds); rubric-based outcome verification; Heavy Thinking for differential diagnosis.
- Assumptions/Dependencies: Regulatory compliance (HIPAA, FDA), clinically validated environments, bias/safety audits, strict human oversight.
- Autonomous Laboratory Agent for Experiment Planning and Execution (Science/Pharma)
- What: Plan experiments, operate instruments via APIs, collect data, adjust protocols, and maintain reproducible records in noisy lab conditions.
- Tools/Products/Workflows: Environment-grounded synthesis mapped to digital twins of lab equipment; curriculum-based noise robustness; multi-turn tool orchestration.
- Assumptions/Dependencies: Rich instrument APIs and simulators; safety interlocks; validation datasets; expert supervision; significant integration engineering.
- Industrial Operations Copilot across Heterogeneous Tool Chains (Manufacturing/Energy)
- What: Agentic orchestration for maintenance scheduling, anomaly investigation, and workflow optimization across SCADA, CMMS, ERP.
- Tools/Products/Workflows: Executable domain graphs representing operational tools; verifiability-preserving expansion; agentic search on incident data.
- Assumptions/Dependencies: Secure integrations; real-time constraints; safety certification; robust failover and rollback; digital twin availability.
- Financial Risk and Scenario Analysis Assistant (Finance)
- What: Multi-hop reasoning over portfolios, market data, and regulations; tool-integrated stress testing and compliance verification.
- Tools/Products/Workflows: Planning-centric trajectories; Heavy Thinking to explore diverse scenarios; rubric-based validation for constraints.
- Assumptions/Dependencies: Data entitlements; model risk management; auditability; latency budgets; human review for material risk decisions.
- Cross-App Enterprise RPA with Verifiable Agentic Tool Use (Enterprise Automation)
- What: Replace brittle scripts with agents that adapt to changing schemas, verify outcomes, and handle noise (timeouts, partial failures).
- Tools/Products/Workflows: Domain graph synthesis per app stack; controlled expansion to keep databases consistent; outcome rubrics.
- Assumptions/Dependencies: Stable enterprise APIs; change management; security; rollback; extensive monitoring.
- Multi-Agent Collaborative Systems with FSM Orchestration (General AI Platforms)
- What: Teams of specialized agents (extraction, verification, answering, judgment) coordinated via FSM for complex tasks with ambiguity resolution.
- Tools/Products/Workflows: FSM-based agentic search pipeline; agent-based QA synthesis; automated difficulty grading and conflict resolution.
- Assumptions/Dependencies: Reliable inter-agent protocols; conflict resolution policies; throughput/cost management; guardrails for emergent behavior.
- Agent Tool Marketplace with Standardized Schemas (Ecosystem/Developer Platforms)
- What: A marketplace of verified tools conforming to unified schemas, enabling plug-and-play agentic capabilities across domains.
- Tools/Products/Workflows: Schema-level definitions; automated code generation with unit tests and debugging agents; dependency graph validation.
- Assumptions/Dependencies: Community standards; certification processes; versioning and compatibility policies; security reviews.
- City-Scale Policy Analysis and Planning Assistant (Public Sector)
- What: Integrate noisy datasets (transport, housing, health outcomes) for scenario analysis, policy comparisons, and evidence-backed recommendations.
- Tools/Products/Workflows: Robust agentic training under noise; multi-domain environment training for generalization; Heavy Thinking for complex trade-offs.
- Assumptions/Dependencies: Data access agreements; transparency/accountability mechanisms; fairness metrics; public consultation and oversight.
- Autonomous Robotics Task Planning via Tool-Like Abstractions (Robotics)
- What: Treat robot skills/sensors as “tools” in a domain graph; plan long-horizon tasks with verification of state transitions and contingencies.
- Tools/Products/Workflows: Environment-grounded synthesis mirrored in simulators; BFS expansion while maintaining executability; rubric-validated outcomes.
- Assumptions/Dependencies: High-fidelity simulators; safe real-world transfer; perception uncertainty handling; certification; substantial R&D.
- Distilled Agentic Models and Edge Deployment (Edge/Embedded)
- What: Compress Heavy Thinking and tool-use capabilities into smaller models for on-prem or edge devices while retaining robustness to noise.
- Tools/Products/Workflows: Knowledge distillation from 560B MoE; curriculum noise injection; test-time scaling approximations (budgeted parallelism).
- Assumptions/Dependencies: Effective distillation recipes; domain-specific datasets; hardware constraints; careful evaluation of retained capabilities.
Notes on feasibility across applications:
- Compute and cost: The 560B MoE model with 27B active params per token is resource-intensive; PD disaggregation and CPU KV-cache swapping are important for efficient inference; cost-aware routing to Heavy Thinking mode is recommended.
- Safety and governance: Human-in-the-loop review, audit logs, and explicit outcome rubrics are essential to mitigate errors in tool-use and search.
- Data and integration: Success depends on stable, permissioned APIs, reproducible environments/sandboxes, and clear evaluation rubrics for “correctness.”
- Generalization: Multi-domain environment training and noise-robust curriculum improve transfer to real-world variability but do not eliminate domain-specific adaptation needs.
Collections
Sign up for free to add this paper to one or more collections.