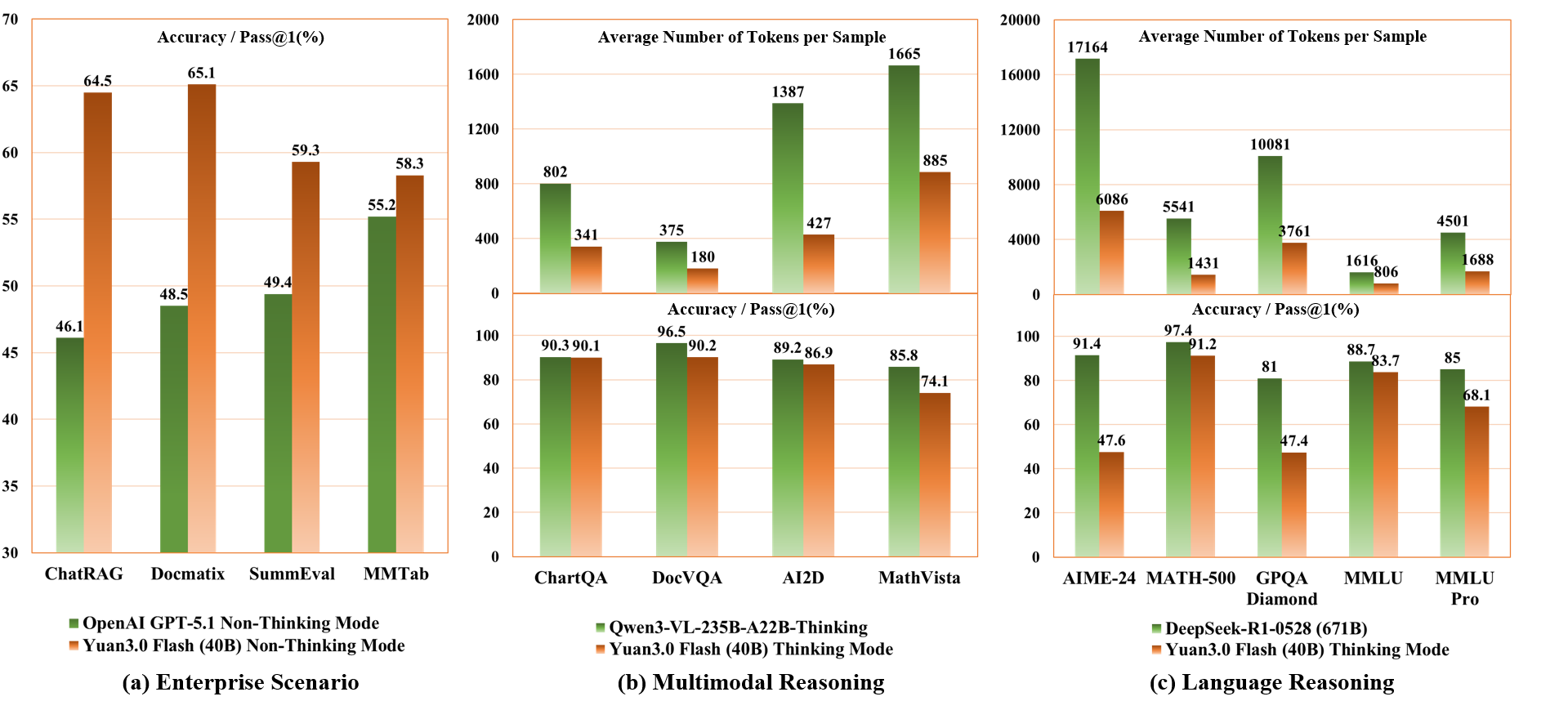- The paper introduces Yuan3.0 Flash, a multimodal MoE LLM with 40B total parameters (3.7B activated) designed for enterprise applications.
- It employs a pretrained visual encoder with an adaptive segmentation mechanism to process high-resolution images and ensure fine-grained multimodal alignment.
- The model leverages reflection-aware RL and optimization techniques like RAPO and ADS to reduce token usage by up to 64% while improving accuracy.
Yuan3.0 Flash: An Open Multimodal MoE LLM Optimized for Enterprise Applications
Model Architecture and Innovations
Yuan3.0 Flash introduces a large-scale Mixture-of-Experts (MoE) multimodal LLM with 40B total parameters (3.7B activated), specifically targeted at high-value enterprise scenarios. The architecture integrates three key modules: a pretrained visual encoder (InternViT-300M), a lightweight MLP projector utilizing SwiGLU activations for efficient visual-token alignment, and a MoE-based Language Decoder with 40 layers and 32 experts, employing Top-K routing for sparse activation. A distinguishing design within the language backbone is the Localizing Filtering-based Attention (LFA), favoring local token dependencies to improve efficiency and linguistic inductive bias.
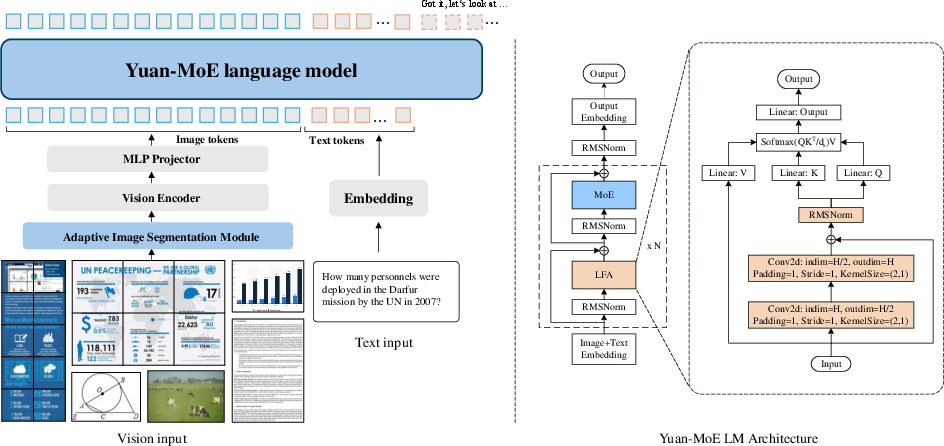
Figure 1: Yuan3.0 Flash’s architecture synergistically unites a ViT encoder, MLP projector, and an MoE language backbone with LFA.
To handle high-resolution visual data, the model employs an adaptive image segmentation mechanism, optimizing input grid configurations to minimize geometric distortion and maintain computational tractability. This segmentation, combined with the robust vision backbone, provides fine-grained multimodal grounding critical for document analysis and enterprise-relevant visual tasks.
Mitigating Overthinking with Reflection-aware RL
Chain-of-thought (CoT) reasoning in current LRMs, while powerful, induces "overthinking": excessive token generation post-solution, especially due to RL with verifiable rewards (RLVR). The authors introduce Reflection-aware Adaptive Policy Optimization (RAPO), featuring the Reflection Inhibition Reward Mechanism (RIRM), a novel RL reward shaping strategy.
RIRM decomposes reasoning outputs to detect the initial correct answer and subsequent "reflection" segments, assigning penalties/rewards based on the number of reflective steps and final correctness. This encourages efficient reasoning—yielding both improved accuracy and drastic token reduction in fields such as mathematical and scientific problem solving.
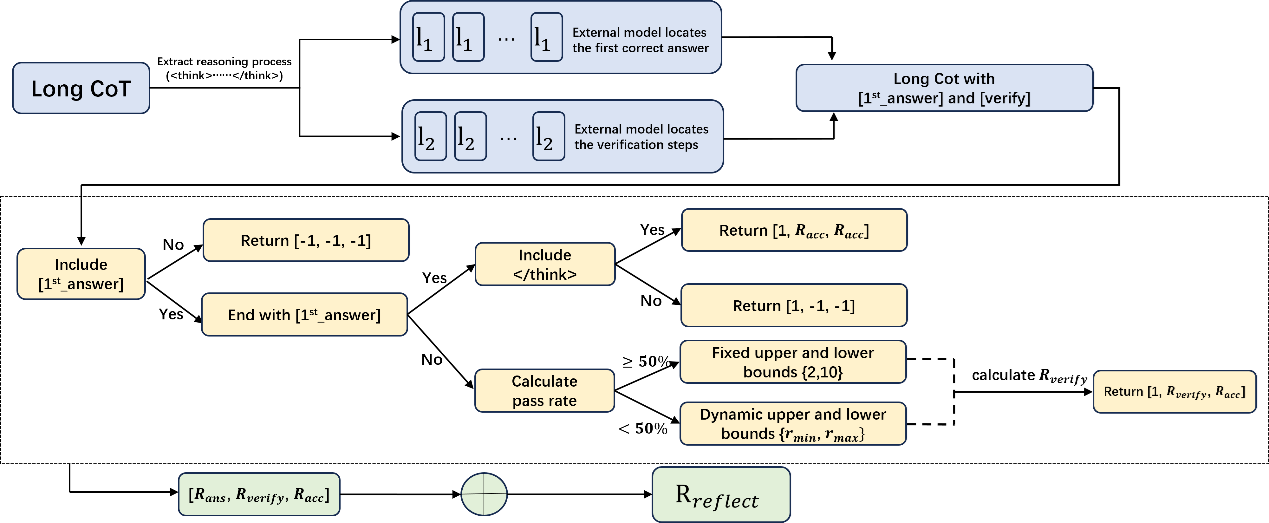
Figure 2: Schematic of RIRM, annotating correct-answer appearance and reflection phases for reward shaping during RL.
Empirical analysis on DeepseekR1-Distill-1.5B (AIME 2024, MATH-500) demonstrates that RIRM can drive up to 64% lower average token consumption, with a 90.58% reduction during reflection, while raising maximum task accuracy by 52.37%.
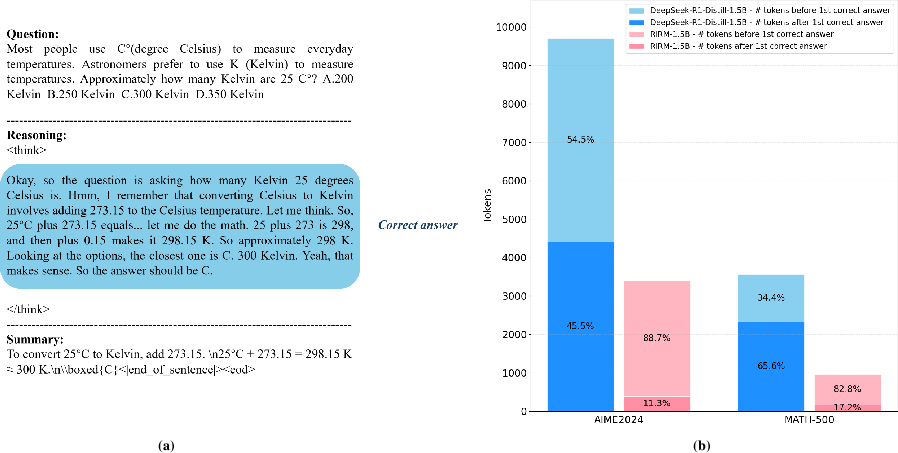
Figure 3: RL with RIRM results in briefer, more direct reasoning traces and significantly lower token usage.
RL Training Optimizations and Unified Strategies
Beyond RIRM, the training protocol advances RL efficiency and stability via an improved DAPO (Direct Actor Policy Optimization) framework. Key innovations include:
- Adaptive Dynamic Sampling (ADS): Refines batch construction by prioritizing high-pass-rate prompts, slashing generation and iteration time by 52.91%.
- 80/20 Rule for MoE Stability: Gradient updates utilize only the top 20% highest-entropy tokens per response, enhancing stability in deep MoE settings.
- Optimized Dual-Clip: Addresses gradient explosion from high-probability ratio transitions, using targeted clipping for negative-advantage trajectories.
- Mixed Training Modalities: Unlike prior strict dual-model approaches, Yuan3.0 Flash unifies both deep thinking (reasoning, code, science) and non-thinking (RAG, QA, summarization) objectives in a single model, with strategic alternation and task-specific output controls.
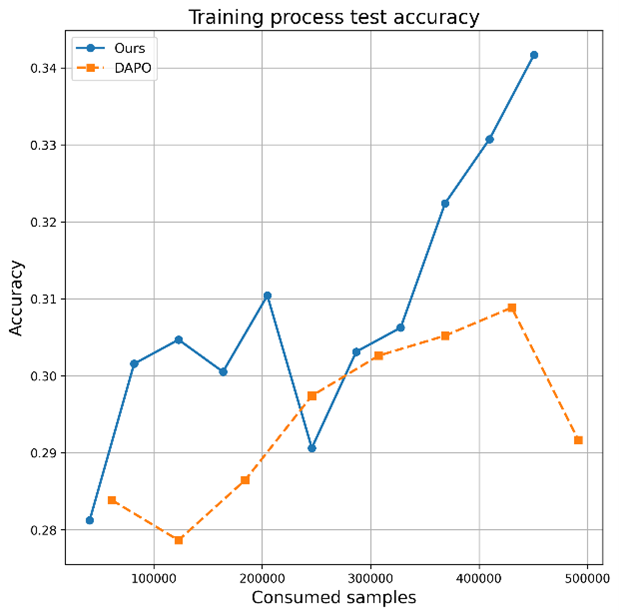
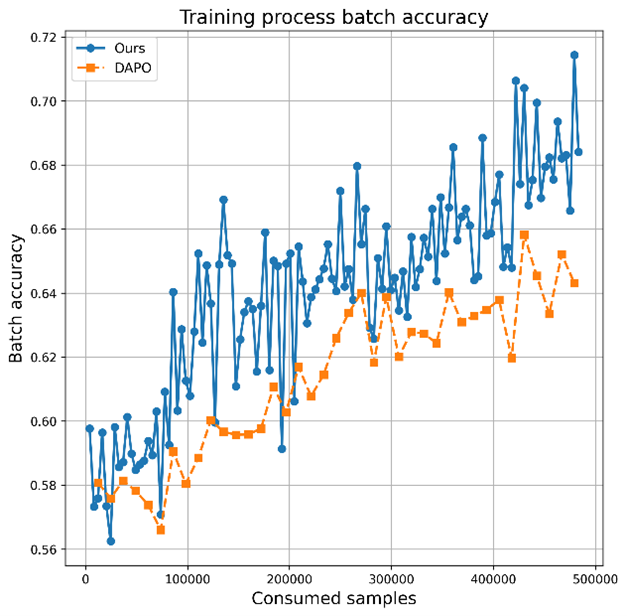
Figure 4: DAPO with ADS leads to smoother, faster convergence and higher test accuracy.
These reinforcement strategies enable a high-throughput, dependable RL pipeline that enhances learning signals for both deductive and retrieval-augmented workloads.
Pre-training, Fine-tuning, and RL Data Construction
Yuan3.0 Flash's pre-training corpus exceeds 3.5TB tokens from filtered web, academic, code, and specialized domains, with explicit down-weighting of low-value and noisy domains (e.g., ads, entertainment). For multimodal pretraining, 1.5B curated image-text pairs magnify cross-domain alignment.
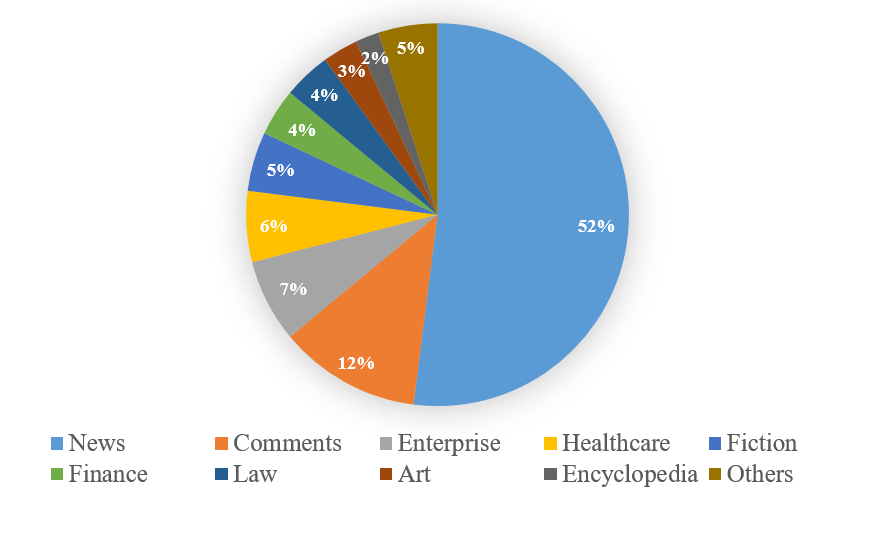
Figure 5: Proportional breakdown of domains within the web-crawled corpus ensuring enterprise-tailored knowledge bias.
Fine-tuning datasets are expert-filtered for both general and enterprise-targeted dialogues, RAG, table understanding, API screenshots, and synthesized low-frequency concepts. RL data generation includes standardized extraction, active pass/fail grading by Yuan3.0 SFT, and a suite of verifiable or generative reward systems to holistically score outputs, whether via string-matched correctness or learned reward models for subjective, open-ended tasks.
Multi-stage Training Pipeline
A four-stage pipeline is employed:
- Massive-scale pre-training (3T tokens)
- Unified multimodal adaptation on 256M image-text pairs
- Supervised fine-tuning for multimodal instruction and reasoning
- Large-scale RL, blending thinking/non-thinking capabilities and dynamic output truncation
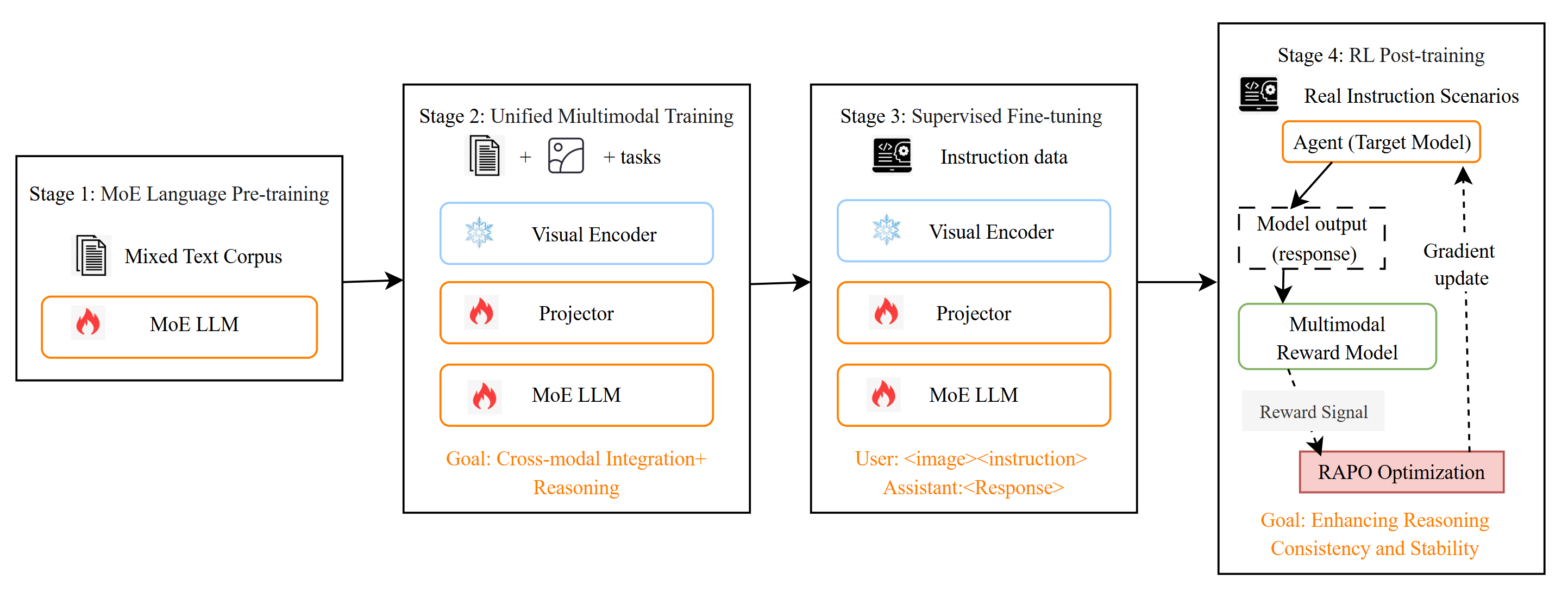
Figure 6: The multi-stage collaborative multimodal training pipeline aligning visual and linguistic capacities throughout.
Enterprise-level and Multimodal Benchmarks
Yuan3.0 Flash consistently achieves state-of-the-art or competitive results in critical enterprise benchmarks:
Long-context (128K) and General Reasoning Robustness
Yuan3.0 Flash maintains perfect retrieval and reasoning up to 128K tokens (NIAH benchmark), essential for enterprise-scale document analysis.
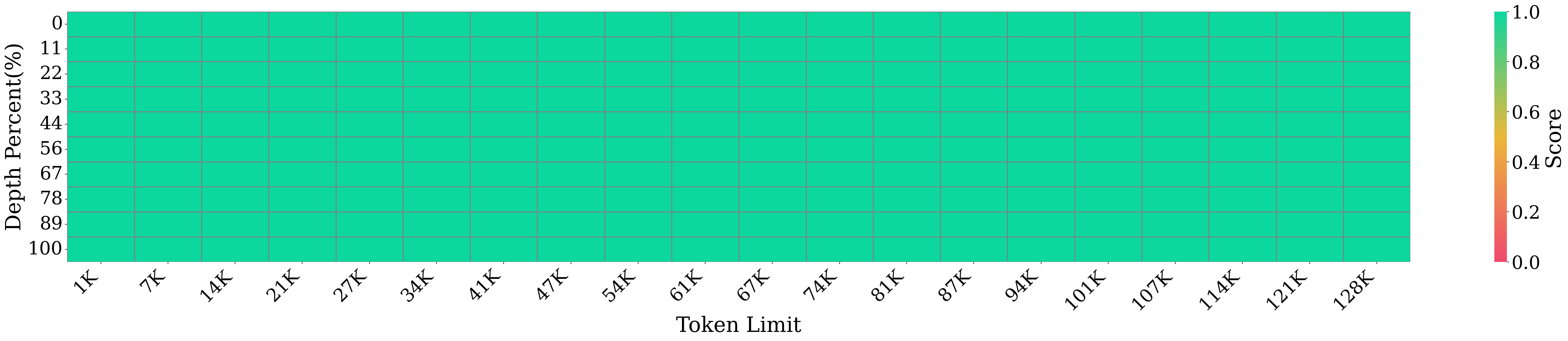
Figure 8: NIAH test confirms stable, accurate retrieval over ultra-long contexts.
In mathematical/coding/scientific reasoning, Yuan3.0 Flash delivers comparable accuracy to much larger models (DeepSeek-V3 671B, Qwen3 232B) but with just 1/4–1/2 token generation, accentuating practical efficiency especially in "thinking" mode. For visual-language benchmarks (e.g., ChartQA, DocVQA, AI2D, MathVista), the model matches or closely approaches SOTA models in both non-thinking and thinking settings while substantially reducing token footprints.
Implications and Future Prospects
The architecture and training pipeline adopted in Yuan3.0 Flash highlight critical trends for future enterprise LLMs:
- Efficient, Unified Multimodality: MoE and adaptive alignment modules offer scalable, enterprise-deployable multimodal performance without incurring excessive resource burden.
- Reflection-aware RL: Addressing overthinking represents a key axis in making LLMs cost-effective and practically deployable, especially for high-frequency inferencing in enterprise settings.
- Unified Mixed-task Models: A single model robustly handling both slow, deep thinking and fast retrieval demonstrates a practical design, reducing deployment complexity versus dual-model or mode-switching approaches.
Further research may improve domain-adaptive reward models, expand generalization to even larger context windows, and optimize sparse MoE inference at scale for resource-constrained enterprise use-cases.
Conclusion
Yuan3.0 Flash establishes a new technical paradigm for open-source, enterprise-focused multimodal LLMs: achieving state-of-the-art accuracy in complex reasoning, retrieval, and multimodal tasks at a fraction of the computational footprint. The integration of RIRM and advanced RL techniques yields both higher answer quality and dramatically greater efficiency, setting a precedent for future LLM deployment in industry-critical scenarios.